【玩转yolov5】使用bdd100k数据集训练行人和全车模型
这是一篇yolov5的实操作文章,前提是你对yolov5框架本身有了一个基本的认识。实操的内容也正好是最近要做的一个任务,训练一个全车和行人检测的模型。数据集的话我想就直接先用BDD100k,它是BAIR(加州大学伯克利分校AI实验室)于2018年5月发布的一个目前最大规模、内容也最具多样性的公开驾驶数据集。BDD100K数据集包含了10万段高清(1280x720p)视频,每个视频约40秒,30fps的帧率。对每个视频的第10秒抽取关键帧,以此得到10万张图片,并加以标注。关于BDD100k的详细介绍,可以参见这篇文章。因为我主要是用来做目标检测,所以就只关注他检测部分的标注信息。数据集中的GT框总共包含10个类别,分别是:Bus、Light、Sign、Person、Bike、Truck、Motor、Car、Train、Rider。
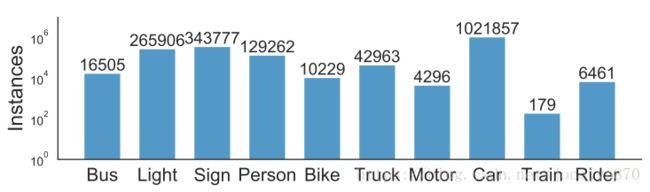
可见行人和车辆的标注框数量还是比较多的,单就Car一类就有超100万的标注框。因为BDD100k的标注信息是以json的格式保存的,所以在正式使用之前我还得先将其转换为yolov5框架支持的格式,下面是一个bdd100k到yolov5的标注转换代码。其中我把'car','bus','truck'这三个类合并为了一类,'person'单独作为一类,其它类我就忽略了。另外,我加了一个过滤的功能,将夜晚的图片也过滤了。另外,考虑到我不需要关注过分小的小目标,我还加了一个根据标注框面积过滤的步骤。这也是bdd100k的一大亮点,它的标注信息中包含图片的多个属性信息,如:天气、场景、时间、目标遮挡情况等。所以,你如果要做图片属性分类,这也是一个很好的数据集。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# Copyright @ 2021 zuosi <[email protected]>
# Distributed under terms of the MIT license
import re
import os
import json
def search_file(data_dir, pattern=r'\.jpg$'):
root_dir = os.path.abspath(data_dir)
for root, dirs, files in os.walk(root_dir):
for f in files:
if re.search(pattern, f, re.I):
abs_path = os.path.join(root, f)
#print('new file %s' % absfn)
yield abs_path
class Bdd2yolov5:
def __init__(self):
self.bdd100k_width = 1280
self.bdd100k_height = 720
self.select_categorys=["person", "car", "bus", "truck"]
self.cat2id = {
"person": 0,
"car": 1,
"bus": 1,
"truck": 1
}
@property
def all_categorys(self):
return ["person", "rider", "car", "bus", "truck", "bike",
"motor", "traffic light", "traffic sign","train"]
def _filter_by_attr(self, attr=None):
if attr is None:
return False
#过滤掉晚上的图片
if attr['timeofday'] == 'night':
return True
return False
def _filter_by_box(self, w, h):
#size ratio
#过滤到过于小的小目标
threshold = 0.001
if float(w*h)/(self.bdd100k_width*self.bdd100k_height) < threshold:
return True
return False
def bdd2yolov5(self, path):
lines = ""
with open(path) as fp:
j = json.load(fp)
if self._filter_by_attr(j['attributes']):
return
for fr in j["frames"]:
dw = 1.0 / self.bdd100k_width
dh = 1.0 / self.bdd100k_height
for obj in fr["objects"]:
if obj["category"] in self.select_categorys:
idx = self.cat2id[obj["category"]]
cx = (obj["box2d"]["x1"] + obj["box2d"]["x2"]) / 2.0
cy = (obj["box2d"]["y1"] + obj["box2d"]["y2"]) / 2.0
w = obj["box2d"]["x2"] - obj["box2d"]["x1"]
h = obj["box2d"]["y2"] - obj["box2d"]["y1"]
if w<=0 or h<=0:
continue
if self._filter_by_box(w,h):
continue
#根据图片尺寸进行归一化
cx,cy,w,h = cx*dw,cy*dh,w*dw,h*dh
line = f"{idx} {cx:.6f} {cy:.6f} {w:.6f} {h:.6f}\n"
lines += line
if len(lines) != 0:
#转换后的以*.txt结尾的标注文件我就直接和*.json放一具目录了
#yolov5中用到的时候稍微挪一下就行了
yolo_txt = path.replace(".json",".txt")
with open(yolo_txt, 'w') as fp2:
fp2.writelines(lines)
#print("%s has been dealt!" % path)
if __name__ == "__main__":
bdd_label_dir = "./BDD100K/train"
cvt=Bdd2yolov5()
for path in search_file(bdd_label_dir, r"\.json$"):
cvt.bdd2yolov5(path)
数据就这样准备好了,接下来就是yolov5框架上根据自己的数据集做一些配置文件的调整了。
├── data
│ ├── coco128.yaml
│ ├── coco.yaml #默认的coco数据配置文件
│ ├── diamond.yaml #我自己的
│ ├── hyp.diamond.yaml #我自己的
│ ├── hyp.finetune.yaml #默认的超参数配置文件
│ ├── hyp.scratch.yaml
│ ├── images
│ ├── scripts
│ └── voc.yaml
├── detect.py
├── Dockerfile
├── hubconf.py
├── LICENSE
├── models
│ ├── common.py
│ ├── experimental.py
│ ├── export.py
│ ├── hub
│ ├── __init__.py
│ ├── __pycache__
│ ├── yolo.py
│ ├── yolov5l.yaml
│ ├── yolov5m.yaml
│ ├── yolov5s_diamond.yaml #我自己的网络架构配置文件
│ ├── yolov5s.yaml #默认的网络架构配置文件
│ └── yolov5x.yaml
├── runs #各子目录下用来存放训练,测试,推理中间或结果文件
│ ├── detect
│ ├── test
│ └── train
├── test.py
├── train.py
├── tutorial.ipynb
├── utils
├── weights我给我这个项目起了个名字叫diamond,用以区别yolov5中默认的coco。兵马未动粮草先行嘛,首先就是数据配置文件,我copy了一份data/coco.yaml为data/diamond.yaml。
# download command/URL (optional)
# download: https://github.com/ultralytics/yolov5/releases/download/v1.0/coco128.zip
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: /home/zw/zuosi/projects/yolov5-v4.0/dataset/diamond/images/train
val: /home/zw/zuosi/projects/yolov5-v4.0/dataset/diamond/images/val
# number of classes
nc: 2 #类别数这里,coco是80类,我只有两类
# class names
# 同样,coco这里类别名有80个,我只有两类
names: [ 'pedestrian', 'car']然后是超参数配置文件,同样copy了一份data/hyp.scratch.yaml为data/hyp.diamond.yaml。这个超参数文件第一次训练的时候你完全可以不做任何改动,就用默认的就可以了。我这里只改了mosaic配置参数,将默认的1.0的概率改为了0.0,也就是禁用了mosaic数据增量方式。马赛克数据增强确实能有效解决模型训练中最头疼的“小对象问题”,即小对象不如大对象那样准确地被检测到。我去掉是因为我发现bdd100k整个数据集小目标偏多,mosaic数据增量进一步增大了小目标的分布,而我的任务并不过于关注小目标,我暂且先关掉。
# Hyperparameters for COCO training from scratch
# python train.py --batch 40 --cfg yolov5m.yaml --weights '' --data coco.yaml --img 640 --epochs 300
# See tutorials for hyperparameter evolution https://github.com/ultralytics/yolov5#tutorials
lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
lrf: 0.2 # final OneCycleLR learning rate (lr0 * lrf)
momentum: 0.937 # SGD momentum/Adam beta1
weight_decay: 0.0005 # optimizer weight decay 5e-4
warmup_epochs: 3.0 # warmup epochs (fractions ok)
warmup_momentum: 0.8 # warmup initial momentum
warmup_bias_lr: 0.1 # warmup initial bias lr
box: 0.05 # box loss gain
cls: 0.5 # cls loss gain
cls_pw: 1.0 # cls BCELoss positive_weight
obj: 1.0 # obj loss gain (scale with pixels)
obj_pw: 1.0 # obj BCELoss positive_weight
iou_t: 0.20 # IoU training threshold
anchor_t: 4.0 # anchor-multiple threshold
# anchors: 3 # anchors per output layer (0 to ignore)
fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
hsv_v: 0.4 # image HSV-Value augmentation (fraction)
degrees: 0.0 # image rotation (+/- deg)
translate: 0.1 # image translation (+/- fraction)
scale: 0.5 # image scale (+/- gain)
shear: 0.0 # image shear (+/- deg)
perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
flipud: 0.0 # image flip up-down (probability)
fliplr: 0.5 # image flip left-right (probability)
mosaic: 0.0 # image mosaic (probability) #我就只改了这一个地方,把mosaic增量方式默认的1.0改为了0.0,也就是完全禁用了mosaic方式,说到底还是我不是过分关注小目标
mixup: 0.0 # image mixup (probability)最后是网络结构配置文件,yolov5默认提供了s,l,m,x四种网络结构,我这里选用yolov5s模型,拷贝一份models/yolov5s.yaml为models/yolov5s_diamond.yaml。你也只需要改动配置文件中的类别参数,由coco的80类改为自己的2类。
# parameters
nc: 2 # number of classes,改为自己的两类
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, C3, [1024, False]], # 9
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]这样就差不多ok了,为了方便训练我写了一个.sh文件,train_diamon.sh,内容如下。
python3.8 train.py --data data/diamond.yaml \
--hyp data/hyp.diamond.yaml \
--cfg models/yolov5s_diamond.yaml \
--name "yolov5s_diamond_20210128" \
--batch-size 8 你可以通过tensorboard查看自己的训练过程中的一些指标,其实yolov5收敛是很快的,我因为就用笔记本自带的gpu训练的,速度比较慢。按照yolov5的建议是要训练300个epoch,我这里才训了9个epoch。就训练本身而言的话你可以使用yolov5提供的coco上的预训练的模型进行finetune,也可以从头到尾进行训练。finetune的话收敛速度会相对快点,我这里因为bdd100k的训练数据集本身已经比较大了,这么大的训练集我直接从头训也是没有问题的。训练中间结果及权重文件会保存在runs/train/yolov5s_diamond(你自己当然不是这个名字,但肯定在runs/train下面)这个目录下,拿到权重文件你就可以调用detect.py进行测试了。这里有一个不好的地方就是整个训练过程就只保存了最后一个权重文件以及最好的那个权重文件,如果你想多保存几个貌似要稍改一下代码。
➜ train git:(69be8e7) ✗ tree yolov5s_diamond -L 2
yolov5s_diamond
├── events.out.tfevents.1611806057.zw-Legion-Y7000P-2019-PG0.4804.0
├── hyp.yaml #保存训练过程中的超参数
├── labels_correlogram.jpg
├── labels.jpg
├── opt.yaml
├── results.txt #保存测试结果
├── train_batch0.jpg #前3次迭代的训练图片以及gt框会合成为一张图片保存在此,这个主要是方便你难训练数据有没有什么问题
├── train_batch1.jpg
├── train_batch2.jpg
└── weights #这里就保存了你最后一个epoch的权重文件和到目前为止在验证集上表现最好的权重文件(best.pt)
├── best.pt #你是最棒的
└── last.pt #你是最后的