使用pytorch实现的yolov4训练自己的数据集,并进行推理
参考:https://github.com/Tianxiaomo/pytorch-YOLOv4/
对该仓库的步骤详细描述了一下,并解决了部分问题。
一 应用场景
在x86 ,ubuntu18.04(cpu)上,使用pytorch实现的yolov4训练自己的数据集,并进行推理。
二 环境准备
该样例依赖以下环境:
numpy==1.18.2
tensorboardX==2.0
scikit_image==0.16.2
matplotlib==2.2.3
tqdm==4.43.0
easydict==1.9
Pillow==7.1.2
opencv_python
pycocotools
pytorch==1.4(注意不要直接下)
onnx
onnxruntime
为了方便安装,我已经写了一个环境安装脚本enviroment.sh,所以配置环境时仅需:
$ ./enviroment.sh
安装结束,运行环境即完成配置
三 数据集准备
先将获取你的样本图片放入特定文件夹之后获取标签索引文件。
该样例支持的标签索引文件格式如下:

# train.txt
image_path1 x1,y1,x2,y2,id x1,y1,x2,y2,id x1,y1,x2,y2,id ...
image_path2 x1,y1,x2,y2,id x1,y1,x2,y2,id x1,y1,x2,y2,id ...
...
…
为得到该文件,你需要先把你的图片进行标注,制作成voc数据集,因为我之前已经有voc数据集了
得到voc数据集后(应在./data/my_data路径下)

生成类别文件mushroom.names(./data/my_data)

使用我写好的脚本Voc_yolov4_pytorch.py(./data/my_data)
展示代码:
# coding: utf-8
import xml.etree.ElementTree as ET
import os
names_dict = {}
cnt = 0
f = open('./voc_names.txt', 'r').readlines()
for line in f:
line = line.strip()
names_dict[line] = cnt
cnt += 1
voc_07 = 'VOC2007'
#voc_12 = './VOC2012'
anno_path = [os.path.join(voc_07, 'Annotations')]
img_path = [os.path.join( voc_07, 'JPEGImages')]
trainval_path = [os.path.join(voc_07, 'ImageSets/Main/train.txt')]
test_path = [os.path.join(voc_07, 'ImageSets/Main/trainval.txt')]
def parse_xml(path):
tree = ET.parse(path)
img_name = path.split('/')[-1][:-4]
height = tree.findtext("./size/height")
width = tree.findtext("./size/width")
objects = [img_name]
for obj in tree.findall('object'):
difficult = obj.find('difficult').text
if difficult == '1':
continue
name = obj.find('name').text
bbox = obj.find('bndbox')
xmin = bbox.find('xmin').text
ymin = bbox.find('ymin').text
xmax = bbox.find('xmax').text
ymax = bbox.find('ymax').text
name = str(names_dict[name])
# objects.extend([xmin, ymin, xmax, ymax, name])
objects.extend([f'{xmin},{ymin},{xmax},{ymax},{name}'])
if len(objects) > 1:
return objects
else:
return None
test_cnt = 0
def gen_test_txt(txt_path):
global test_cnt
f = open(txt_path, 'w')
for i, path in enumerate(test_path):
img_names = open(path, 'r').readlines()
for img_name in img_names:
img_name = img_name.strip()
# print (anno_path)
xml_path = anno_path[i] + '/' + img_name + '.xml'
objects = parse_xml(xml_path)
if objects:
objects[0] = img_name + '.jpg'
temp = img_path[i] + '/' + img_name + '.jpg'
if os.path.exists(temp):
# objects.insert(0, str(test_cnt))
# test_cnt += 1
objects = ' '.join(objects) + '\n'
f.write(objects)
f.close()
train_cnt = 0
def gen_train_txt(txt_path):
global train_cnt
f = open(txt_path, 'w')
for i, path in enumerate(trainval_path):
img_names = open(path, 'r').readlines()
for img_name in img_names:
img_name = img_name.strip()
xml_path = anno_path[i] + '/' + img_name + '.xml'
objects = parse_xml(xml_path)
if objects:
objects[0] = img_name + '.jpg'
temp = img_path[i] + '/' + img_name + '.jpg'
if os.path.exists(temp):
# objects.insert(0, str(train_cnt))
# train_cnt += 1
objects = ' '.join(objects) + '\n'
print(objects)
f.write(objects)
f.close()
gen_train_txt('train1.txt')
gen_test_txt('val1.txt')修改以下部分来完成获取标签索引文件:
1 修改为你的索引文件所在路径
![]()
2 修改为你的数据集文件所在路径
![]()
3 分别修改为你的标签索引文件名
![]()
在./data/my_data路径下运行
$ python3 Voc_yolov4_pytorch.py生成标签索引文件
train.txt和val.txt
将其复制到到./data文件夹下,数据集准备完毕。
四 预训练模型准备
需要用darknet2pytorch将原来的darknet模型转换为pt模型,这里使用转换完毕的pytorch模型。
下载地址:百度网盘
yolov4.pth(https://pan.baidu.com/s/1ZroDvoGScDgtE1ja_QqJVw Extraction code:xrq9)
下载完成后放置于./路径下。
五 训练参数配置
修改dataset.py的以下部分:
1 get_image_id函数定义中的

因为id这里要取整数,所以
part[-1][15:-4]这里代表你的图片名里只含有数字的那一部分,根据你个人的数据集实际情况进行修改。
修改cfg.py的以下部分:
1 不使用cfg的配置
![]()
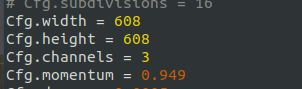
2 修改以下部分使得batch-size=batch//subvisions=3
![]()
3 修改标签索引文件路径对应你的路径
![]()
修改train.py的以下部分:
![]()
1 因为本来就只有cpu训练,所以将数据加载的worker关闭,num_workers=0,根据自己电脑情况修改
参数配置完毕。
六 模型训练
在./路径下执行:
$ python3 train.py -l 0.001 -pretrained ./yolov4.pth -classes 1 -dir ./data/my_data/VOC2007/JPEGImages/参数解释:
1 -l 0.001 训练的的学习率:0.001
2 -pretrained ./yolov4.pth 预训练模型:./yolov4.pth
3 -class 1 数据集总类别数:1
4 -dir 数据集图片存放路径
开始训练,训练中产生的模型会存放在./checkpoint/
日志会存放在./log/
训练时间可能较长,可尝试nohup后台训练
查看打印的日志:
最后一次训练的各ap值:(效果一般,不过只有cpu也玩不起了)
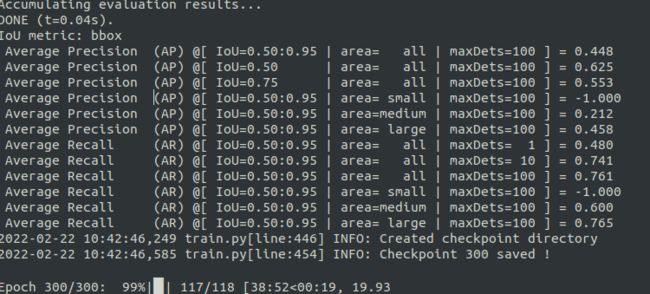
可以看到最后一个epoch模型文件已存放于checkpoints/文件夹

七 模型推理
这里我们使用models.py进行推理
需要对脚本进行以下修改:
对models.py进行修改:
![]()
将torch.device后面修改为如下
将use_cuda后面改为如下:

下面predictions.jpg根据个人需求修改路径

对./tools/utils.py里的plot_boxes_cv2函数定义的以下部分修改为如下:

修改完成后就开始预测。
在./路径下运行:
$ python3 models.py 1 checkpoints/Yolov4_epoch300.pth jpg/test1.jpg 608 608 data/mushroom.names参数解释为:
python3 models.py 类别数 预测模型路径 预测图片路径 指定图片宽 指定图片高(宽高保持和训练时的一致即可) 类别文件路径
开始推理:在命令行可以看到处理时间
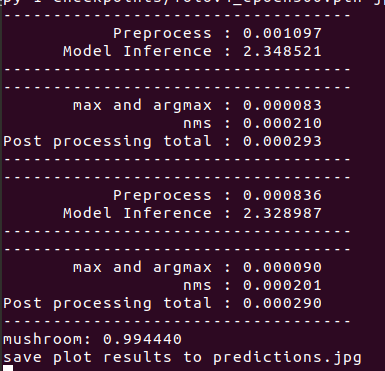
推理效果。


其他推理图片展示:
