我对Swin Transformer V2的理解
Swin Transformer V2: Scaling Up Capacity and Resolution
一、前言
1.综述
本文提出一种升级版SwinTransformerV2,最高参数量可达3 Billion,可处理大尺寸图像。通过提升模型容量与输入分辨率,SwinTransformer在四个代表性基准数据集上取得了新记录。
2.要解决的问题
-
视觉模型通常面临尺度不稳定问题;
-
下游任务需要高分辨率图像,尚不明确如何将低分辨率预训练模型迁移为高分辨率版本 ;
-
当图像分辨率非常大时,GPU显存占用也是个问题。
3.改进方案
- 提出后规范化(Post Normalization)技术与可缩放(Scaled)cosine注意力提升大视觉模型的稳定性;
- 提出log空间连续位置偏置技术进行低分辨率预训练模型向高分辨率模型迁移;
- 我们还共享了至关重要的实现细节 ,它可以大幅节省GPU显存占用以使得大视觉模型训练变得可行。
二、方法
1.A Brief Review of Swin Transformer
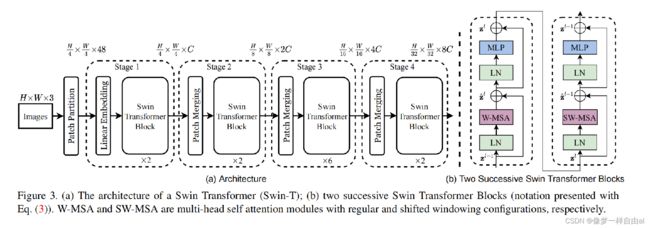
Normalization Configuration 众所周知,规范化技术对于更深架构的训练非常重要。原始的SwinTransformer采用了常规的预规范化技术,见下图:

Relative position bias 它是原始SwinTransformer的一个关键成分,它引入了一个额外参数化偏置,公式如下:
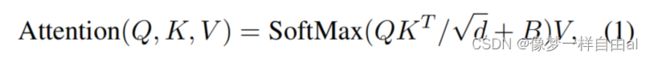
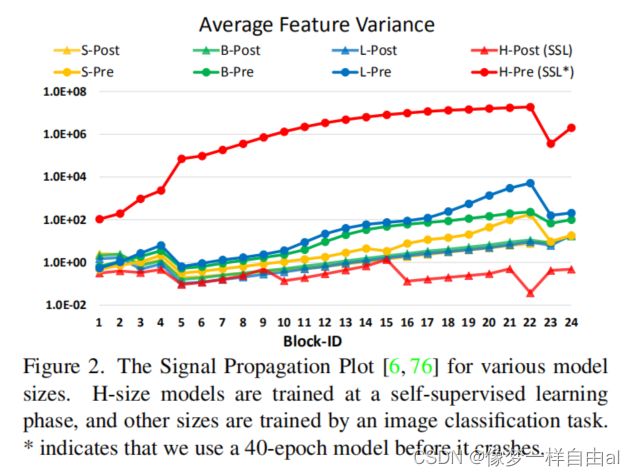
Issues in scaling up model capacity and window resolution 在对SwinTransformer进行容量与窗口分辨率缩放过程中,发现以下两个问题:
- 容量缩放过程中的不稳定问题,见下图:

- 跨分辨率迁移时的性能退化问题,见下表:

2.Scaling up Model Capacity

Post Normalization 为缓解该问题,我们提出了Post Normalization(后规范化):每个残差模块的输出先进行规范化再与主分支进行合并,因此主分支的幅值不会逐层累积。从上面的Figure2可以看到:使用后规范化的模型激活幅值更温和。
Scaled Cosine Attention 在原始自注意力计算过程中,像素对的像素性通过query与key的点积计算。我们发现:在大模型中,某些模块与head的注意力图会被少量像素对主导 。为缓解该问题,我们提出了Scaled Cosine Attention(SCA),公式如下:

3.Scaling Up Window Resolution
接下来,引入一种log空间连续位置偏置方法以使得相对位置偏置跨窗口分辨率平滑迁移。
Continuous Relative Position Bias 不同于直接对偏置参数直接优化,连续位置偏置方法采用了针对相对坐标的元网络:

注:G是一个很小的网络
它对任意相对坐标生成偏置参数,因而可以自然地进行任意可变窗口尺寸的迁移。
Log-space Coordinates 当跨大窗口迁移时,有较大比例的相对坐标范围需要外插。为缓解该问题,采用了对数空间坐标:

通过对数空间坐标,在进行块分辨率迁移时,所需的外插比例会更小。
Table 1则给出了不同位置偏置下的迁移性能对比,可以看到:当向更大窗口尺寸迁移时,对数空间连续位置偏置性能最佳 。
4. Implementation to Save GPU Memory
大分辨率输入与大容量模型存在的另一个问题是GPU显存占用不可接受问题 。
本文采用了以下实现改善该问题:
- Zero-Redundancy Optimizer(ZeRO): 采用ZeRO优化器减少GPU显存占用,对整体训练速度影响极小;
- Activation check-pointing:采用checkpoint技术节省GPU占用,但会降低30%训练速度;
- Sequential Self-attention computation:采用串式计算,而非batch模式,对整体训练速度影响极小。
5. Model Configurations
本文保持与SwinTransformer相同的stage、block以及通道配置得到了四个版本的SwinTransformerV2:
T(Tiny),S(Small),B(Base),L(Large)
SwinV2-T: C=96, layer number= {2,2,6,2}
SwinV2-S: C=96, layer number= {2,2,18,2}
SwinV2-B: C=128, layer number= {2,2,18,2}
SwinV2-L: C=192, layer number= {2,2,18,2}
我们进一步对SwinV2进行更大尺寸缩放得到了658M与3B参数模型:
SwinV2-H: C=352, layer number={2,2,18,2}
SwinV2-G: C=512, layer number={2,2,42,2}
三、实验结果
本文主要在ImageNetV1、ImageNetV2、COCO检测、ADE20K语义分割以及Kinetics-400视频动作分类方面进行了实验。
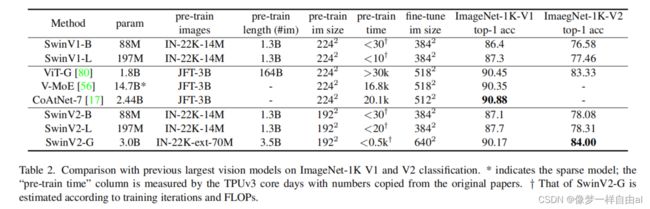
上表给出了ImageNet分类任务上的性能对比,可以看到:
- 在ImageNetV1数据上,SwinV2-G取得了90.17%的精度;
- 在ImageNetV2数据上,SwinV2-G取得了84.0%的精度,比之前最佳高0.7%;
- 相比SwinV1,SwinV2性能提升约0.4~0.8%。

上表比较了COCO检测任务上的性能,可以看到:所提方案取得了63.1/54.4的box与mask mAP指标,比此前最佳高1.8/1.4 。

上表比较了ADE20K语义分割任务上的性能,可以看到:所提方案取得了59.9mIoU指标,比此前最佳高1.5 。

上表比较了Kinetics-400视频动作分类任务上的性能,可以看到:所提方案取得了86.8%的精度,比此前最佳高1.4% 。
Reference:
1.屠榜各大CV任务!最强骨干网络:Swin Transformer V2来了
2.【论文阅读】Swin Transformer V2: Scaling Up Capacity and Resolution
3.Swin-Transformer网络结构详解