期中汇总(概论+应用层+运输层)
期中汇总
- 概论
-
- 1.1互联网
- 1.2网络边缘
- 1.3网络核心
- 1.4接入网络和物理媒体
- 1.5互联网结构和ISP
- 1.6分组时延、丢失和吞吐量
- 1.7协议层次及服务模型
- 应用层
-
- 2.1应用层协议原理
- 2.2Web和HTTP
- 2.3FTP
- 2.4Email
- 2.5DNS
- 2.6P2P应用
- 2.7CDN
- 2.8TCP套接字(Socket)编程
- 2.9UDP套接字编程
- 传输层
-
- 3.1概述和传输层服务
- 3.2多路复用与解复用
概论
1.1互联网
- 从具体构成
网络由结点和边组成
计算机网络:由联网的计算机构成的网络
节点:
主机节点——数据的源、数据的目标;
数据交换节点——路由器(工作在网络层)、交换机(工作在链路层)(它们既不是源也不是目标)数据中转节点
边:通信链路
接入网链路——把主机和交换节点
主干链路——交换节点和交换节点连在一起
协议:支持互联网工作的标准,控制发送、接收消息(TCP、IP、HTTP、PPP)
互联网:网络的网络
主机=端系统,运行网络应用程序
通信链路:传输速率=带宽(bps)
分组交换设备:转发分组(路由器、交换机)
协议定义了在两个或多个通信实体之间交换的报文格式和次序,以及在报文传输和/或接收或其他事件方面所采取的动作。
- 从服务角度
- 使用通信设施进行通信的分布式应用
- 通信基础设施为apps提供编程接口(通信服务)
无连接不可靠服务UDP
面向连接的可靠服务TCP
- 网络结构
- 网络边缘(主机;应用程序:客户端和服务器):目标主机把数据发给网络核心
- 网络核心(互连着的路由器;网络的网络):数据交换作用,将数据传到目标主机
- 接入网、物理媒体(有线或者无线通信链路):将网络边缘接入网络核心
1.2网络边缘
三种模式:
- 端系统(主机):运行应用程序
- 客户/服务器模式(主从模式):扩展性差,达到阈值断崖式下降
- 对等(peer-peer)模式:每个节点即是服务器也是客户端,下载速度快,同时从不同的服务器请求(一个文件可以从多个服务器下载不同的片段)
两种服务:
-
采用网络设施的面向连接服务(只有端系统维护连接、链路不知道)
目的:在端系统之间传输数据
在数据传输之前——握手(打招呼,作准备,确认两个通信主机之间为连接建立状态,再进行数据传输)
TCP服务:
可靠地(请求,确认,查询过去,查询结果返回。4步)、按顺序传送数据;
流量控制(协调接收方速度和发送方速度,速度需要匹配,不超过处理能力);
拥塞控制(网络拥塞时,发送方降低发送速率,减缓拥堵) -
采用基础设施的无连接服务
目标:在端系统之间传输数据
无需握手——直接发送数据(上来就发送,对方直接回应)
UDP-用户数据报协议:
无连接(查询过去,查询结果返回。2步);
不可靠数据传输;
无流量控制;
无拥塞控制;
1.3网络核心
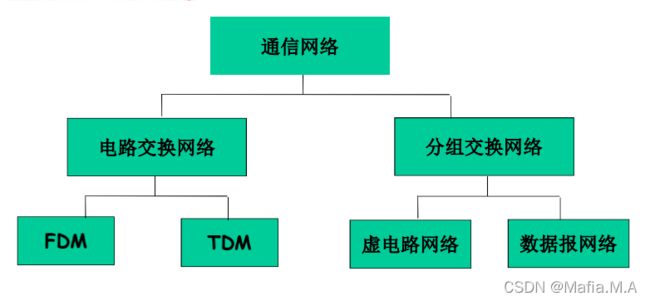
网络核心:路由器的网状网络
数据通过网络传输2中方式:
- 电路交换(每个呼叫预留一条专有电路)
端到端的资源被分配给从源端到目标端的呼叫“call”
独享资源;
若无数据传输,被发配的资源会被浪费,因为该线路不能被别人使用,此时空闲
使用时将带宽分成片:
频分FDM、
时分TDM(周期)、
波分
不适合计算机之间通信
- 分组交换(数据分组,存储转发)
以分组为单位存储-转发方式(带宽不分片,数据被分组)
资源共享,按需使用(存储、转发:分组每次移动一跳):转发之前,节点必须接收到整个分组,延迟较大,需要排队时间
排队和延迟:
到达速率>链路的输出速率
分组排队,等待传输;若路由器缓存用完,分组被抛弃。
网络核心的关键功能
路由:决定分组采用的源到目标路径(全局,找到路径)
转发:将分组从路由器的输入链路到输出链路
由转发和路由相互配合,原主机将目标能够放出去,目标主机能够收到
分组交换:统计多路复用(时分复用链路资源,但划分时间片的方式不是固定的)
分组交换(按照网络层是否有连接)分成两种方式:
数据报方式:每一个分组携带目标主机完整地址,每个节点根据该完整地址存储转发,两个主机在通讯之前不需要握手,每个分组传递都是独立的。
虚电路:主机和目标主机通信前握手,之间的交换节点保持通信的状态,建立起一条虚拟的线路,每个分组携带一个虚电路号,节点根据虚电路号存储转发,每个节点都有相应标识
1.4接入网络和物理媒体
- 接入网:将网络边缘接入网络核心
两个注意点:
接入网络的带宽;
接入线路是独享or共享。
三种接入方式:
1.住宅接入:modem (猫),通过电话线调制解调;不能同时上网和打电话
2.DSL:仍使用电话线,1-4kHz保留通话,剩余带宽分为上行和下行()
3.线缆网络:用有线电视信号线缆(本身只能下行,保留电视信号,剩下带宽改造为上下行。HFC:上下行非对称,用户共享接入网)
- 物理媒体:将两者连在一起的物理介质
分成两类:
1.导引性媒体:看得见摸得着的(电缆、光线,信号都局限在导体内部,传的远)
2.非导引性媒体:看不见摸不着(开放空间传电磁波,信号会向周边辐射,传的近)
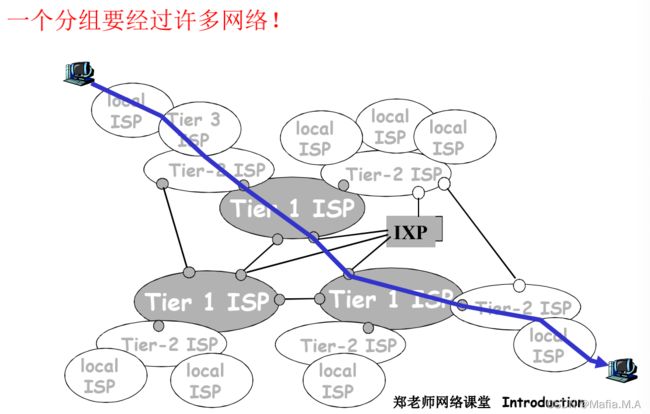
1.5互联网结构和ISP
互联网结构,有两种划分方式:
1.按照上文划分方式(按照节点和链路的类型划分):网络边缘、核心、接入网
2.把关系比较密集,在一个网络中的设备,称之为一个ISP的网络,互联网由很多ISP网络构成;任何一个端系统都是通过接入到ISP接入到互联网。建立全局ISP,将所有ISP接入其中。

松散的层次结构:
中心:第一层ISP,国家/国际覆盖(直接与其他第一层ISP相连,与大量第二层ISP和其他客户网络相连)
第二层ISP:更小些的(区域性)ISP(与第一层ISP相连,也可能与其他第二层ISP相连)
第三层ISP与其他本地ISP:接入网(与端系统最近)
1.6分组时延、丢失和吞吐量
-
分组丢失原因:路由器缓冲区已满,后来到达的分组被丢掉。
-
时延:分组到达链路的速率超过了链路输出能力,分组等待排到队头、被传输。
四种分组延时:
1.节点处理延时:检查bit是否出错,查去向(路由表)
2.排队延时:在输出链路上等待传输的时间,排到队头的时间(取决于路由器的拥塞程度)
3.传输延时:存储转发延时(将队头分组从路由器传出);R = 链路带宽,L = 分组长度,将分组发送到链路上的时间 = L/R
4.传播延时:在链路上的传播时间;d = 物理链路的长度,s = 在媒体上的传播速度(~2x10^8 m/sec),传播延时 = d/s
排队延时取决于流量强度:R=链路带宽,L=分组长度,a=分组到达队列的平均速率;流量强度 = La/R,不能超过1

丢失的分组可能会被前一个路由重传(链路提供可靠的服务),也可能不重传(链路提供不可靠的服务)。如果使用TCP,在链路提供不可靠服务时,由源主机重传。
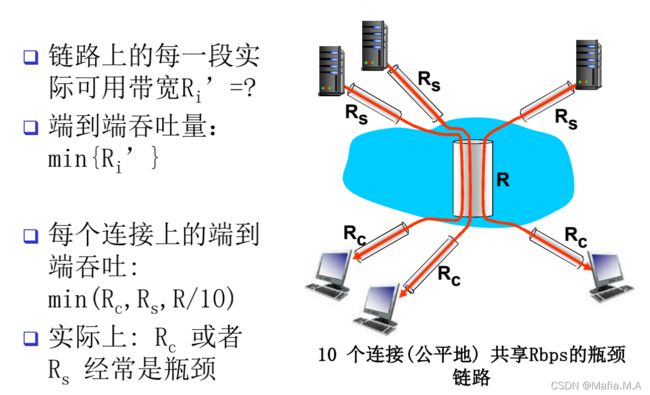
- 吞吐量:
在源端和目标端之间传输的速率(数据量/单位时间)
-瞬间吞吐量:在一个时间点的速率
-平均吞吐量:在一个长时间内平均值
瓶颈链路:端到端路径上,限制端到端吞吐的链路
1.7协议层次及服务模型
- 分层化方法实现复杂网络功能:
将网络复杂的功能分成功能明确的层次,每一层实现其中一个或一组功能;
本层的服务:借助下层服务实现的本层协议实体之间交互带来的新功能(上层可以利用的)+更下层所提供的服务
协议实现的目的:通过接口为上层提供更好的服务;
1.服务:低层实体向上层实体提供它们之间的通信的能力
2.原语:上层使用下层服务的形式,高层使用低层提供的服务,以及低层向高层提供服务都是通过服务访问原语来进行交互的——形式
3.服务访问点SAP:上层使用下层提供的服务通过层间的接口——地点
-
服务的类型
面向连接的服务:TCP方式交互,需要握手。
无连接的服务:两个应用程序采用UDP方式交互,不需要握手。 -
服务和协议
1.区别:
服务:低层实体向上层实体提供它们之间的通信的能力,通过原语操作(垂直);
协议:对等层实体之间在互相通信过程中,需要遵循的规则和集合(水平)
2.联系:
本层协议的实现要靠下层提供的服务来实现;
本层实体通过协议为上层提供更高级的服务。
- 分层处理和实现复杂系统的好处
对付复杂的系统
概念化:结构清晰,便于标示网络组件,以及描述其相互关系(分层参考模型)
结构化:模块化更易于维护和系统升级(改变某一层服务的实现不影响系统中的其他层次;如改变登机程序并不影响系统的其他部分)
- 互联网协议栈
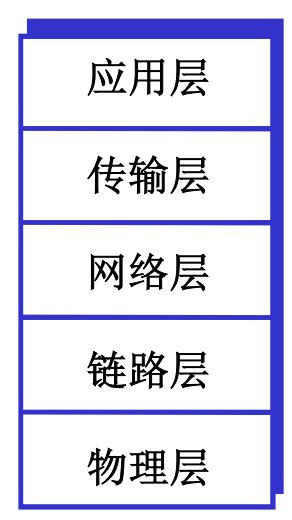
应用层:网络应用(SMTP、HTTP、DNS、FTP)
传输层(运输层):主机之间的数据传输(TCP、UDP)
网络层:为数据报从源到目的选择路由
链路层:相邻网络节点间的数据传输
物理层:在线路上传送bit
应用层——报文
传输层——报文段(进程到进程之间的区分、提供可靠数据传输)
网络层——数据报(传输以分组为单位,源主机到目标主机端到端传输)
链路层——帧(解决相邻两点的传输)
物理层——bit(把数字数据转换成物理信号)

应用层
2.1应用层协议原理
网络应用的体系结构:
- 客户-服务器模式(C/S)
服务器:一直运行;固定IP地址和周知端口号;扩展性,服务器场,扩展性差
客户端:主动与服务器通信;与互联网有间歇性的连接;可能是动态IP地址;不直接与其他客户端通信 - 对等模式(P2P)
几乎没有一直运行的服务器;任意端系统之间可以进行通信;每一个节点即是客户端又是服务器;参与的主机间歇性连接可以改变IP地址 - 混合体:客户-服务器和对等体系结构
Napster:文件搜索——集中(主机在中心服务器上注册其资源,主机向中心服务器查询资源位置);文件传输——P2P(任意Peer节点之间传输文件)
即时通信:在线检测——集中(用户上线时,向中心服务器注册其IP地址;当用户与中心服务器联系,以找到其在线好友的位置);两个用户聊天之间——P2P
进程通信:
进程:在主机上运行的应用程序
1.同一个主机内,使用进程间通信机制通信(操作系统)
2.不同主机间,通过交换报文来通信
客户端进程:发起通信的进程
服务器进程:等待连接的进程
分布式进程通信需要解决的问题:
1.进程标示和寻址问题(服务用户)
主机IP、TCP/UDP、相应端口号
2.传输层-应用层提供服务时如何(服务)
传输层提供的服务需要穿过层间的信息(应用层向传输层)
层间接口必须要携带:传输的报文;谁传的;传给谁;
传输层实体(tcp或udp实体)根据这些信息进行TCP报文段(UDP数据报)的封装:源端口号、目标端口号、数据等
使用socket简化传输的信息(源端口号ip和目的端口号ip不变,这四个信息不变,用一个代号标示通信双发或单方:socket)
tcp的socket是4元组的一个具有本地意义的标示
udp的socket(2元组):本IP,本端口;但传输报文时,需要提供对方ip和port
3.如何使用传输层提供的服务,实现应用进程之间的报文交换,实现应用(用户使用服务)
定义应用层协议:报文格式、解释、时序等
定义了:运行在不同端系统上的应用进程如何相互交换报文(类型、语法、语义、响应规则)
如何描述传输层的服务:数据丢失率、吞吐、延迟、安全性
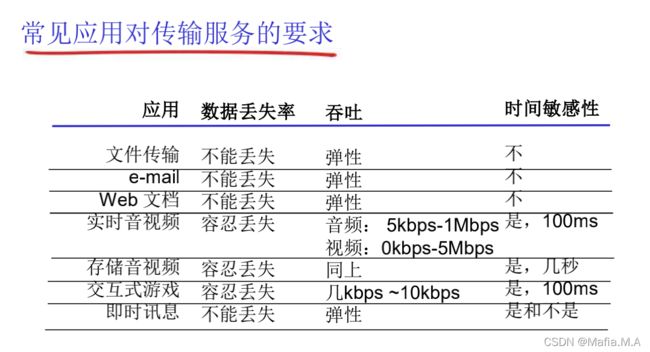
互联网传输层提供的服务(两种)
1.TCP:可靠的传输服务,流量控制,拥塞控制,不能提供的服务:时间保证、最小吞吐保证,面向连接;
2.UDP:不可靠数据传输,不提供的服务:可靠、流量控制、拥塞控制、时间、带宽保证、建立连接。
UDP存在的必要性:
1.能够区分不同的进程
2.无需建立连接 :省去建立连接时间,适合事务性的应用
3.不做可靠性的工作:适合对实时性要求高对正确性要求不高的应用
4.没有拥塞控制和流量控制,应用能够按照设定的速度发送数据
TCP和UDP都不提供安全性,TCP加上SSL保证安全(如https)。
SSL在TCP上面实现,提供加密的TCP链接,私密性,数据完整性,端到端的鉴别
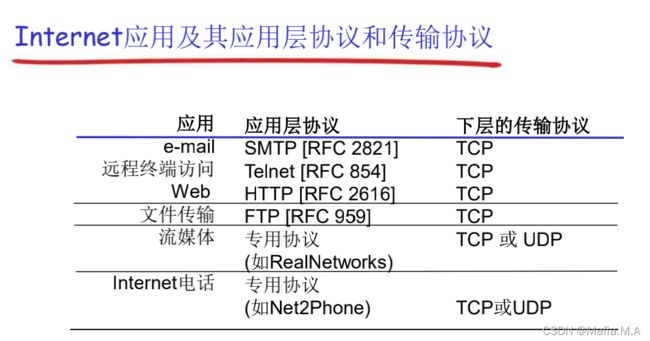
2.2Web和HTTP
-
Web页:含有一个基本的HTML文件,该基本HTML文件包含若干对象的引用(链接,通过URL对每个对象进行引用)
web页:由一些对象组成
URL格式:访问协议、用户名、口令字、端口等;

-
Web的应用层协议:HTTP协议——超文本传输协议
使用TCP协议,端口号80
客户/服务器模式:
客户:请求、接收和显示Web对象的浏览器(HTTP request)
服务器:对请求进行响应,发送对象的Web服务器(HTTP response) -
HTTP建立在TCP之上:
客户发起一个与服务器的TCP链接(建立套接字),端口号为80。
HTTP使用无状态服务器:不维护关于客户的任何信息(简单),不知道之前是否建立过连接,也不知道后续是否要建立连接,能支持更多的客户端。
维护状态的协议很复杂:需要维护历史信息;若服务器/客户端死机,导致二者信息状态可能不一致,二者必须一致;无状态服务器能支持更多的客户端 -
HTTP连接(类型)
非持久HTTP(HTTP/1.0):最多只有一个对象在TCP连接上发送(发送完一个对象,连接就关闭了,若要发多个需要开启新的TCP连接)
持久HTTP(HTTP/1.1):多个对象可以在一个TCP连接上传输(建立连接后不着急关闭,可以一直使用,发送多个对象) -
响应时间模型
往返时间RTT:一个小的分组从客户端到服务器,在回到客户端的时间(传输时间忽略)
非持久HTTP:每个对象要2个RTT
响应时间:一个RTT用来发起TCP连接,一个RTT用来HTTP请求并等待HTTP响应,文件传输时间;响应时间一共为2RTT+传输时间
非流水方式的持久HTTP:每个引用对象花费一个RTT 客户端只能在收到前一个响应后,才能把新的请求发出去
流水方式的持久HTTP:所有引用(小)对象只花费一个RTT是可能的 客户端遇到一个引用对象就立即产生一个请求,不用等待收到前一个响应再发送。
HTTP/1.1的默认模式
- HTTP请求报文
有两种类型:请求报文、响应报文
HTTP请求报文:ASCII(人能阅读)
提交表单输入:
Post方式:包含在实体主体(entity body)中的输入被提交到服务器
URL方式:方法GET,输入通过请求行的URL字段上载
方法类型:
HTTP/1.0:GET、POST、HEAD(要求服务器在响应报文中不包含请求对象,用于故障跟踪)
HTTP/1.1:GET、POST、HEAD、PUT(将实体主体中的文件上载到URL字段规定的路径)、DELETE(删除URL字段规定的文件)
HTTP响应报文:
格式:状态行(协议版本、状态码、相应状态信息);首部行;数据(如HTML文件)
-
cookies维护用户-服务器状态(因为本身HTTP协议是无状态服务器)
4个组成部分:在HTTP响应报文中有一个cookies的首部行;在HTTP请求报文含有一个cookie的首部行;在用户端系统中保留有一个cookie文件,由用户的浏览器管理;在Web站点有一个后端数据库 -
Web缓存
目标:不访问原始服务器,就满足客户的请求
缓存即是客户端又是服务器
用户设置浏览器:通过缓存访问Web
浏览器将所有HTTP请求发给缓存:若对象在缓存中,直接返回;若不在,缓存请求原始服务器,然后再将对象返回给客户端
使用缓存的原因:降低客户端请求响应时间;减少一个机构内部网络与Internet进入链路上的流量;互联网大量采用缓存,可以使较弱的ICP也能够有效提供内容
条件GET方法:
目的:如果缓存器中的对象拷贝是最新的,就不要发送对象;
缓存器在HTTP请求中指定缓存拷贝的日期;
服务器:如果缓存拷贝陈旧,则响应报文没有包含对象
2.3FTP
使用TCP协议,端口号21
FTP:文件传输协议
向远程主机上传输文件或从远程主机接收文件
客户/服务器模式
使用TCP传输协议
且是有状态协议
FTP命令、响应:控制连接以ASCII码文本
控制连接与数据连接分开:
客户端通过控制连接获得身份确认
客户端通过控制连接发送命令浏览远程目录
收到一个文件传输命令时,服务器打开一个到客户端的数据连接
一个文件传输完成后,服务器关闭连接
服务器打开第二个TCP数据连接用来传输另一个文件
“带内”传数据;“带外”传指令
2.4Email
SMTP使用TCP协议,端口号25
电子邮件3个主要组成部分:用户代理(客户端软件)、邮件服务器、简单邮件传输协议:SMTP
邮件服务器:
邮箱中管理和维护发送给用户的邮件;
输出报文队列保持待发送邮件报文
邮件服务器之间的SMTP协议:发送email报文(客户:发送方邮件服务器;服务器:接收端邮件服务器)
-
邮件发送协议SMTP
直接传输:从发送方服务器到接收方服务器
传输3阶段:握手,传输报文,关闭
命令:ASCII文本;响应:状态码和状态信息
报文必须为7位ASCII码
使用持久连接(建立一次连接后,可以发多个邮件)
SMTP:多个对象包含在一个报文中(HTTP:每个对象封装在各自的响应报文中) -
邮件访问协议POP3/IMAP
从服务器访问邮件
POP:邮局访问协议(用户身份确认) 本地管理文件,在会话中无状态
IMAP:Internet邮件访问协议(在服务器上处理存储的报文)远程管理文件,在会话中保留用户状态
HTTP:Hotmail,Yahoo!Mail等
POP3协议:两个阶段
用户确认阶段:客户端命令、服务器响应
事务处理阶段,客户端
2.5DNS
提供域名和IP地址的转换(DNS是域名解析系统,给其他应用使用,属于基础设施)
DNS存在必要性原因:IP地址标识主机、路由器,IP不好记忆,人们记忆“域名”,它把域名转换为IP地址。
DNS的主要思路:
1.分层的、基于域的命名机制
2.若干分布式的数据库完成名字到IP地址的转换
3.运行在UDP之上端口号为53的应用服务
4.核心的Internet功能,但以应用层协议实现
DNS主要目的:
1.实现主机名-IP地址的转换
2.其他目的:主机名到规范名字的转换;邮件服务器别名到邮件服务器正规名字的转换;负载均衡
DNS域名结构:
采用层次树状结构的命名方法;
Internet根被划为几百个顶级域:通用的(.com .edu);国家的(.cn .us .nl)
每个(子)域下面可划分为若干子域;
树叶是主机。
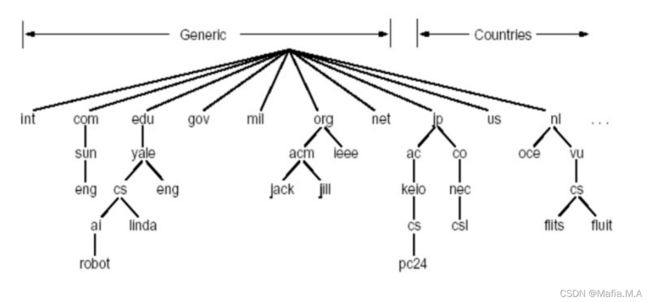
DNS名字空间
1.域名:从本域往上,直到树根;中间使用“.”间隔不同级别;域的域名:可以用于表示一个域;主机的域名:一个域上的一个主机
2.域名的管理:一个域管理其下的子域(.jp被划分为ac.jp co.jp);创建一个新的域,必须征得它所属域的同意。
3.域与物理网络无关:域遵从组织界限,而不是物理网络(一个域的主机可以不在一个网络;一个网络的主机不一定在一个域);域的划分是逻辑的,而不是物理的
名字服务器:
1.不能使用一个名字服务器:单点故障、通信容量、远距离的集中式数据库不方便操作。
2.使用区域(每个区域有一个名字服务器):区域的划分由区域管理者自己决定;将DNS名字空间划分为互不相交的区域,每个区域是树的一部分;名字服务器:每个区域都有一个名字服务器,维护它所管辖区域的权威信息;名字服务器允许放置在区域之外,保障可靠性
区域名字服务器维护资源记录
1.资源记录:
作用:维护 域名-IP地址的映射关系
位置:Name Server的分布式数据库中
DNS协议、报文
查询和响应的报文格式相同
使用缓存——提高性能,效率
一旦名字服务器学到一个映射,就将该映射缓存起来;如果情况变化,缓存结果可能和权威记录不一致,使用TTL(默认两天)
新增一个域:
在上级域的名字服务器中增加两条记录,指向这个新增的子域的域名 和 域名服务器的地址
在新增子域 的名字服务器上运行名字服务器,负责本域的名字解析:名字 到 IP地址
2.6P2P应用
没有(极少)一直运行的服务器;任意端系统都可以直接通信;利用peer的服务能力;peer节点间歇上网,每次IP地址都有可能变化
文件分发问题(文件分发时间)
从一台服务器分发文件(大小F)到N个peer需要多少时间?
- C/S模式
服务器传输:都是由服务器发送给peer,服务器必须顺序传输(上载)N个文件拷贝
发送1个copy: F / u s F/u_s F/us
发送N个copy: N F / u s NF/u_s NF/us
客户端:每个客户端必须下载一个文件拷贝
d m i n = 客 户 端 最 小 的 下 载 速 率 d_min = 客户端最小的下载速率 dmin=客户端最小的下载速率
下载带宽最小的客户端下载的时间: F / d m i n F/d_min F/dmin
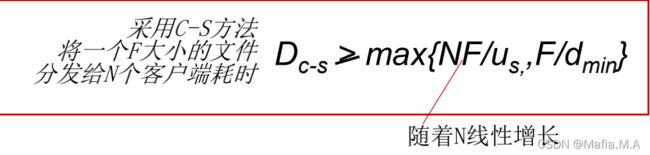
- P2P模式
服务器传输:最少需要上载一份拷贝
发送一个拷贝的时间: F / u s F/u_s F/us
客户端:每个客户端必须下载一个拷贝
最小下载带宽客户单耗时:F/d_min

P2P文件分发:
- BitTorrent
文件被分为一个个块256KB,网络中的这些peers发送接收文件块,互相服务。
Torrent(洪流):节点的组,之间交换文件块;
tracker:跟踪torrent中参与节点 - P2P文件共享
非结构化P2P(三种方案)
方案1:集中式目录 (非结构化P2P)
有中心服务器。当对等方连接时,它告知中心服务器:IP地址,内容
可能存在的问题:单点故障,性能瓶颈,侵犯版权;文件传输时分散的,而定位内容则是高度集中的
方案2:查询洪泛(Gnutella)(非结构化)
全分布式:没有中心服务器
开放文件共享协议
向自己所有 的邻居查询,邻居再查询邻居
Gnutella协议:在已有的TCP连接上发送查询报文;对等方转发查询报文;以反方向返回查询命中报文
方案3:利用不匀称性(KaZaA)(非结构化)
每个对等方要么是一个组长,要么隶属于一个组长(对等方与其组长之间有TCP连接,组长对之间有TCP连接)
组长跟踪其所有的孩子的内容
组长与其他组长联系(转发查询到其他组长,获得其他组长的数据拷贝)
Kazaa小技巧:
1.请求排队(限制并行上载的数量;确保每个被传输的文件从上载节点接收一定量的带宽)
2.激励优先权(鼓励用户上载文件;加强系统的扩展性)
3.并行下载(从多个对等方下载同一个文件的不同部分,HTTP的字节范围首部,更快地检索一个文件)
HDT(结构化P2P)
哈希表、树状、环状
2.7CDN
视频流化服务和CDN
如何向大规模用户同时提供视频服务,每个节点的带宽和上下载能力不同需求不同(异构性)
解决方案:分布式的,应用层面的基础设施CDN
视频
固定速度显示的图像序列
网络视频特点:高码率(高的网络带宽需求);可以被压缩;需求量大(90%以上的网络流量是视频)
数字化图像:像素的阵列
编码:使用图像内和图像间的冗余来降低编码的比特数
DASH——多媒体流化服务
1.服务器:
将视频文件分割成多个块;
每个块独立存储,编码于不同码率;
告示文件——提供不同块的URL
2.客户端:
先获取告示文件
周期性地检测服务器到客户端的带宽
查询告示文件,在一个时刻请求一个块,HTTP头部指定字节范围(如果带宽足够,选择最大码率的视频块;会话中的不同时刻,可以切换请求不同的编码块,取决于当时的可用带宽)
2.8TCP套接字(Socket)编程
2.9UDP套接字编程
传输层
3.1概述和传输层服务
传输服务和协议:
为运行在不同主机上的应用进程提供逻辑通信
传输协议运行在端系统
发送方:将应用层的报文分成报文段,然后传给网络层;
接收方:将报文段重组成报文,然后传递给应用层。
有多个传输层协议可选择(TCP和UDP)
- 可靠的、保序的传输:TCP
多路复用、解服用
拥塞控制
流量控制
建立连接 - 不可靠、不保序的传输:UDP
多路复用、解服用
没有尽力而为的IP服务添加更多的其他额外服务 - 都不提供的服务:
延时保证
带宽保证
3.2多路复用与解复用
在发送方主机多路复用
从多个套接字接收来自多个进程的报文,根据套接字对应的IP地址和端口号等信息对报文段用头部加以封装
在接收方主机解复用
根据报文段的头部信息中的IP地址和端口号将收到的报文段发给正确的套接字(和对应的应用进程)
- 多路解复用工作原理
解复用作用:TCP或者UDP实体采用哪些信息,将报文段的数据部分交给正确的socket,从而交给正确的进程
主机收到IP数据报:
每个数据报有源IP地址和目标地址
每个数据报承载一个传输层报文段
每个报文段有一个端口号和目标端口号
主机联合使用IP地址和端口号将报文段发送给合适的套接字
-
无连接UDP多路解复用
创建套接字
在接收端,UDP套接字用二元组标识(目标IP地址、目标端口号)
当主机收到UDP报文段(检查报文段的目标端口号;用该端口号将报文定位给套接字)
如果两个不同源IP地址/源端口号的数据报,但有相同的目标IP地址和端口号,则被定位到相同的套接字 -
面向连接TCP多路复用
TCP套接字:四元组本地标识(源、目的IP地址,源、目的端口号)
解复用:接收主机用这四个值来将数据报定位到合适的套接字
服务器能够在一个TCP端口上同时支持多个TCP套接字