python层次聚类法画图_原理+代码|详解层次聚类及Python实现
前言
聚类分析是研究分类问题的分析方法,是洞察用户偏好和做用户画像的利器之一。聚类分析的方法非常多,能够理解经典又最基础的聚类方法 —— 层次聚类法(系统聚类) 的基本原理并将代码用于实际的业务案例是本文的目标,同时这也会为理解后续与聚类相关的推文如 K-Means 等打下基础是。
本文将详细介绍如何 利用 Python 实现基于层次聚类的客户分群,主要分为两个部分:层次聚类详细原理介绍
Python 代码实战讲解
原理部分
原理介绍
既然它们能被看成是一类的,所以要么它们距离近,要么它们或多或少有共同的特征。拿到数据集后,直接根据特征或指标来将样本分类的做法其实更适合业务能力比较强的人或有了十分明确的指标如男女各一类等硬性要求,所以本文以样本之间的距离为聚类指标。为了能够更好地深入浅出,我们调整了一下学习顺序,将小部分数学公式往后放,先从聚类结果的显示与分析入手。
下面是有关层次聚类的几个常见问题。
1、为什么都说层次树是层次聚类法独有的聚类结果图?
因为树形图的横坐标会将每一个样本都标出来,并展示聚类的过程。几十个样本时候层次树就已经 “无法” 查看了,更何况成百上千的数据样本。
2、层次树是怎么建立的?建立的基本步骤?
其实层次树的建立过程表示的就是聚类的过程,只不过通过层次树我们可以看出类之间的层次关系(这一类与那一类相差多远),同时还可以通过层次树决定最佳的聚类个数和看出聚类方式(聚类顺序的先后)
基本步骤比较简洁,只要短短的 3 步:计算每两个观测之间的距离
将最近的两个观测聚为一类,将其看作一个整体计算与其它观测(类)之间的距离
一直重复上述过程,直至所有的观测被聚为一类
建立层次树的三个步骤虽然简洁,但其实也有令人迷惑的地方,所以为了让各位更好的从整体上去理解聚类过程而不是圄于细节,这里先直接放一个聚类过程图和对应的层次树
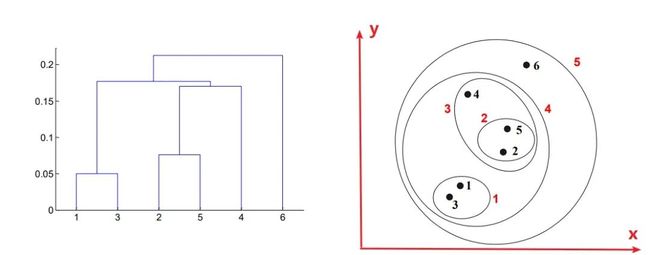
3、怎么从层次树中看出聚类过程?
这一个简短的问题中其实暗含不少门道,第一:**当两个点被分为一类时,是从横坐标出发向上延伸,后形成一条横杠;当两个类被分为一类时,是横杠中点向上延伸。**这第一点中,横杠的数量就表示当所有的点都被圈为一类的时候经过了多少次聚类。

同样,横杠距离横坐标轴的高度也有玄机,毕竟每生成一个横杠就表示又有一次聚类了,所以我们可以通过横杠的高度判断聚类的顺序,结合上图右半部分的圆圈和数字标号也可以看出。
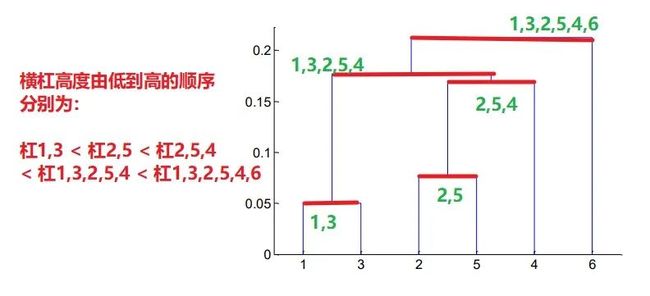
所以聚类顺序便如下表:
聚类次数被聚为一类的点第1次1和3 → 1,3
第2次2和5 → 2,5
第3次2,5 和 4 → 2,5,4
第4次2,5,4 和 1,3 → 1,3,2,5,4
第5次1,3,2,5,4 和 6 → 1,3,2,5,4,6(所有点被聚为一类)
第二,整棵层次树是由一棵棵小树组成,每棵小树代表了一个类,小树的高度即是两个点或两个类之间的距离,所以两个点之间的距离越近,这棵树就越矮小。
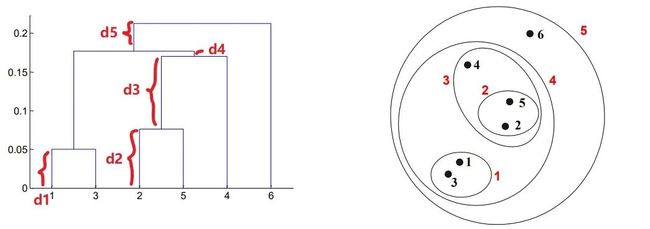
下面这一段仔细阅读的话对理解点与点,类与类,点与类之间的距离是如何在层次树上体现很有帮助。先从最矮的高度只有 d1 小树说起,这就是类 1,3 中两个孤立的点 1 和 3 之间的距离;同理,d2 为类2,5 中点 2 和 5 之间的距离。
而至于 d3, d4, d5 这三个距离,他们并不像 d1 和 d2 那般表示的是一棵完整的树的高度,而更像是 “ 生长的枝干 ”,因为从第一点中的 “ 当两个类被分为一类时,是横杠中点向上延伸。” 可以看出 d3 是从类 2,5 横杠的中点往上延伸的,所以它表示会与另外的类聚成一起并形成一棵更大的树,图中即类 2,5 和点 4 被聚成一个新的类 2,5,4。
同理:d4 表示类 2,5,4 与类 1,3 聚成新类 1,3,2,5,4
d5 表示类 1,3,2,5,4 与点 6 聚成类 1,3,2,5,4,6
4、怎么从层次树中看出聚类情况?可以通过决定纵轴分界线可决定这些数据到底是分成多少类
 定好分界线后,只需要看距离这条线横杠和单独的竖线即可,上图中距离红线的横杠有两条(分别表示类1,2 和类2,5),单独的竖线也有两条,从横坐标轴 4 和 6 上各延伸出的一条。同理可用到下图
定好分界线后,只需要看距离这条线横杠和单独的竖线即可,上图中距离红线的横杠有两条(分别表示类1,2 和类2,5),单独的竖线也有两条,从横坐标轴 4 和 6 上各延伸出的一条。同理可用到下图
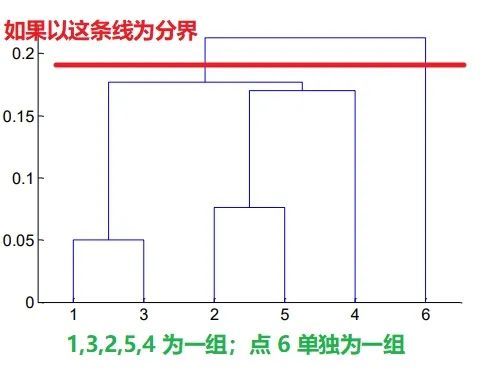
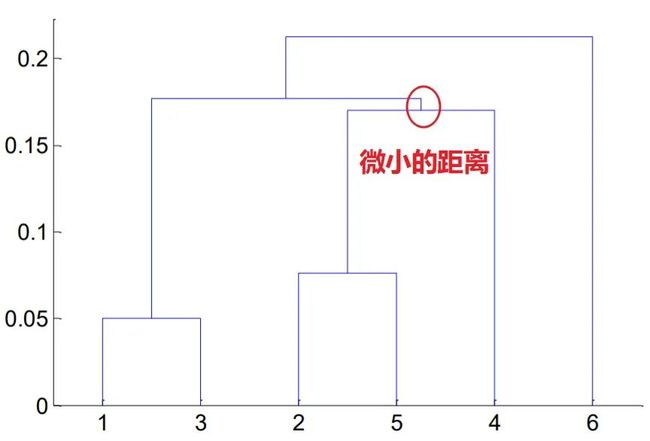
为什么最好不要分成 3 组:13,254,6 呢?
因为树的高度表示两个点之间的距离,所以 4 到 类25 的距离只比到 类13 的距离要多如下图所示的一点点,所以硬是把 4 跟 25 分成一类就有点牵强了,正因为这种牵强的分类方式可能会让我们忽略 4 这个点单独的价值,所以我们不如直接将 4 看成单独的一类。
推导与计算
接下来就是需要更加动脑的数学原理和公式部分了,我们需要知晓点与点,类与类,点与类这三种距离如何计算。

最包罗万象的是明考斯基距离,因为 q 分别取 1 和 2 的时候就表示是绝对值距离和欧氏距离。点与点的距离很好求,我们一般用的都是欧氏距离,即初中学习的直角三角形三边关系,上图右上角点AC之间的距离(ab² + bc²) 后再开根号
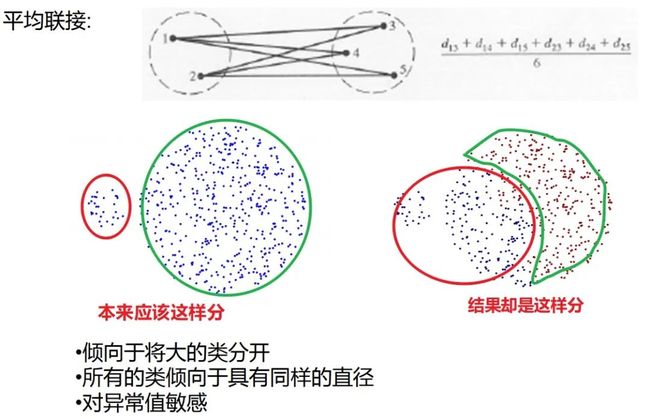
而至于类与类之间的距离求法,其实经过了一个演变,篇幅原因本文只会一笔带过那些不常用的方法并将重心放在最常用和主流的方法上。

平均联接和重心法都已经比较少用了,现大多采用较少受异常值影响且不知数据分布的情况下依然能有较好表现的 Ward 法。
其实 Ward 法的公式与方差分析相似,都是通过组间距离来定夺点点/点类/类类间的距离,Ward 法许多详细的数学推导在网上有很多,这里我们直接展示最容易理解的一种:
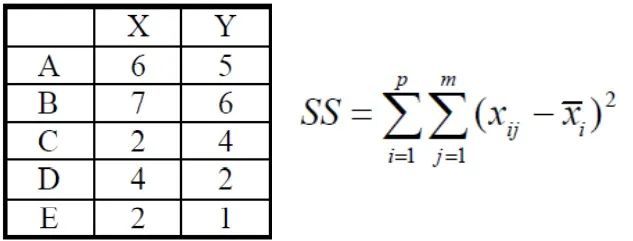 上图为已知的五个点和它们 x,y 轴坐标,SS 为 Ward 最小方差法的公式。
上图为已知的五个点和它们 x,y 轴坐标,SS 为 Ward 最小方差法的公式。

当两个点被聚为一类时,这一类的组间差异 SS 便为其中一点的某一坐标与另外的所有坐标加加减减的一系列操作(通俗解释,其实直接看上图的 SS 计算过程已经可以理解。)
了解 Ward 最小方差法的基本求解公式后,我们可以从最简单的聚类形式开始:5个点聚成4类。这意味着其中两个点会被聚在一起,剩下三个点各自为一类,所以总共会出现 C52 = 10 中情况,每种情况的组内 SS 分别如下表:
 同理,如果这 5 个点聚成 3/2/1 类的情况如下表:
同理,如果这 5 个点聚成 3/2/1 类的情况如下表:
 需要注意的是:聚成两类后计算出 AB 这两个的利方差最小后,在后续聚成3类,2类的时候就直接把A和B两个看成是同一个个体了,所以不会再出现A和B分开的局面。
需要注意的是:聚成两类后计算出 AB 这两个的利方差最小后,在后续聚成3类,2类的时候就直接把A和B两个看成是同一个个体了,所以不会再出现A和B分开的局面。
结合两个表,我们便可以得出如下结论:如果需要被聚成 4 类,AB为一类,剩下3个点各为一类最好(SS 最小)
如果需要被聚成 3 类,AB,DE为一类,剩下的 C 单独为一类最好
如果需要被聚成 2 类,AB,CDE各位一类
如果需要被聚成 1 类,对不起,我觉得没什么分析的必要
在进入代码实战前,我们简单总结一下原理部分提到的知识点:层次树的阅读
两个点之间的距离公式
Ward 法求类内的组间差异,用以决定聚出的类别个数
代码实战
在正式实战前,需要注意以下几点,首先原始数据通常需要经过处理才能用于分析:缺失值
异常值(极大或极小)
分类变量需要转化为哑变量(0/1数值)
分类变量类别不宜过多
其次由于变量的量纲的不一样引起计算距离的偏差,我们需要对数据进行标准化。同时不同的统计方法对数据有不同的要求:决策树和随机森林允许缺失值和异常值
聚类分析和回归模型则不支持缺失值
在处理数据时,也有两个问题值得关注,
1、聚类的时候,所有的 X 必须都是连续变量,为什么?
分类变量无法计算距离,如某个变量表示的是性别,男和女;教育程度为小学,初中,高中,大学,那该变量在各个个体之间的距离怎么计算?所以做聚类分析时尽可能用分类变量。
2、那这些分类变量的价值难道就无法利用了吗?
可以先根据其他的连续变量聚类,而后对分出来的类做描述性统计分析,这时候就可以用上分类变量的价值了。另外一种方法是可以在第一步就把分类变量也用上的聚类方法,不过需要结合实际业务。
以市场客户调研为例,属于 “ 客户的需求与态度 ” 这个分支,目的是依据调查问卷结果针对需求的数据分群,而调查分卷的问题中回答 “yes” 或者 “no” 类型的问题通常又会占一大部分,这时候我么可以通过合并多个问题回答的结果来将多个分类变量组合,生成一个连续变量,以电信客户的使用和需求情况为例:
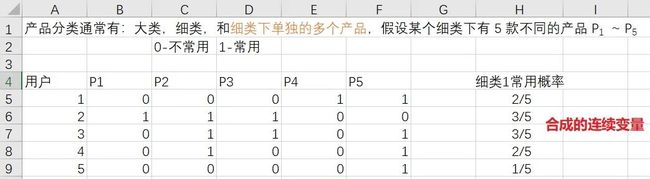 当然也还可以计算分类变量之间的 cos 相似度,即直接把分类变量设成距离。总之,分类变量在聚类当中是一定需要处理的。
当然也还可以计算分类变量之间的 cos 相似度,即直接把分类变量设成距离。总之,分类变量在聚类当中是一定需要处理的。
现在终于到了正式的代码阶段,如果前面的原理都理解好了,代码的理解则可不费吹灰之力。这里我们使用一份公开的城市经济数据集,参数如下:AREA:城市名称
Gross:总体经济情况指数
Avg:平均经济情况指数import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rc('font', **{'family': 'Microsoft YaHei, SimHei'}) # 设置中文字体的支持
plt.rcParams['axes.unicode_minus'] = False
# 解决保存图像是负号'-'显示为方块的问题
df = pd.read_csv('城市经济.csv')
df
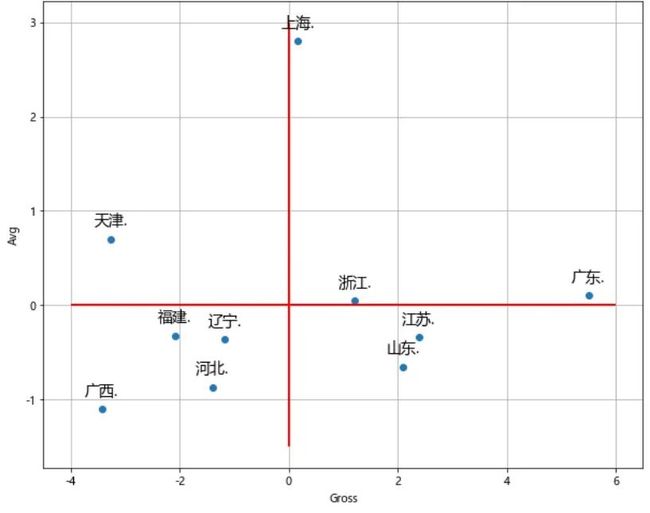 这些城市的指标分布如下波士顿矩阵图,篇幅原因绘图代码省略,后台回复关键字获取的源程序会一并提供。
这些城市的指标分布如下波士顿矩阵图,篇幅原因绘图代码省略,后台回复关键字获取的源程序会一并提供。
 sklearn 里面没有层次聚类的函数,所以从 scipy 中导入import scipy.cluster.hierarchy as sch
sklearn 里面没有层次聚类的函数,所以从 scipy 中导入import scipy.cluster.hierarchy as sch
# 生成点与点之间的距离矩阵, 这里用的欧氏距离: euclidean
## X:根据什么来聚类,这里结合总体情况 Gross 与平均情况 Avg 两者
disMat = sch.distance.pdist(X=df[['Gross', 'Avg']], metric='euclidean')
# 进行层次聚类: 计算距离的方法使用 ward 法
Z = sch.linkage(disMat,method='ward')
下面是层次聚类可视化:层次树# 将层级聚类结果以树状图表示出来并保存
# 需要手动添加标签。
P = sch.dendrogram(Z, labels=df.AREA.tolist())
plt.savefig('聚类结果.png')

最后说一下,未来还会有 K-Means 等聚类方法的推文。作为深入浅出聚类方法的开端,我们只需知道层次聚类相比 K-Means 的好处是它不用事先指定我们需要聚成几类 (K-Means 算法代码中的参数 k 指定)
这样一来,我们只需要把计算全权交给程序,最终能得出一个比较精准的结果。但缺点是随之而来的计算复杂度的增加。
所以层次聚类更适合小样本;K-Means 更适合大样本,在数据挖掘中也更常见,本文分享就到这里,我们下期决策树见~