LeetCode刷题笔记(三)——初级算法——链表
目录
- 删除链表中的节点
- 删除链表的倒数第N个节点
- 反转链表
- 合并两个有序链表
- 回文链表
- 环形链表
在师妹的强力带领下,leetcode刷题终于进展到了第三部分——链表!
链表这种东西就涉及到数据结构的知识了,然鹅我还没学。。。
不过总不能拉下进度,就边刷边学吧。
❤ 2021.9.25 ❤
今天的题目是:
删除链表中的节点


我的思路:
没有思路。。。
在看到这个题之前我只听说过链表这个词,再多一点就是知道他是一种线性的数据结构,至于他的定义特点实现形式一点都不了解。。。
为了弄清楚什么是链表,怎么实现链表,我去看了数据结构课程,看了数据结构书,查了好多资料,大概弄明白了。
首先就是定义一个链表的节点:
typedef struct ListNode {
int val;
struct ListNode* next;
}LNode, * LinkList;
这个定义的方法不是leetcode题目里面给的,里面给的是这样的
struct ListNode {
int val;
struct ListNode* next;
};
关于这两种方式有什么区别,我可是纠结了好久啊。。。
终于在这个老哥的文章里看明白了
C语言之单链表初始化
除了上面这篇其实我还参考了其他的文章
百度百科——typedef
struct和typedef struct彻底明白了
对了除此之外,还要注意在C语言和C++里面用typedef的区别!
简单来说
1、
struct ListNode {
int val;
struct ListNode* next;
};
仅仅是定义了一个结构体,在程序里使用的时候需要用这个结构体先定义一个变量,这样
struct ListNode MyList;
2、
struct ListNode {
int val;
struct ListNode* next;
}MyList;
这种方法和第一种差不多,区别是在结尾定义好了一个变量,相当于第一种方法两个语句的集成。
3、
typedef struct ListNode {
int val;
struct ListNode* next;
}LNode, * LinkList;
这种方法也是两个语句的集成,首先定义一个结构体,然后用typedef语句将整个结构体定义指令重新定义成了两个新的指令,相当于
struct ListNode {
int val;
struct ListNode* next;
};
typedef struct ListNode LNode, * LinkList;
至于为啥要定义成两个新指令呢,我查了一下
链表中关于Node,*LinkList区别
转——链表中LinkList L与LinkList *L的区别
大概意思就是,这俩是完全等价的!
之所以定义成两个,我猜呢是为了在定义链表(或者说头结点)时加以区分,用LinkList定义出来的直接就是指针,用来代表链表,用LNode*定义出来的是节点的地址,代表节点。
定义完成了,然后就是链表的创建
c语言中链表的创建我参考了这位老哥的方法
C语言实现单链表的初始化、创建、遍历等操作
除此之外,下面这位老哥的方法也很有参考价值,但是不知道我哪里弄得不对,程序一直报错
初始化建立链表的两种方法
另外这位老哥的文章也很详细,有一定的参考价值
数据结构(链表初始化和常见操作)
总结来说,链表的创建有两种方法:
1、在在内存中创建好链表然后返回头地址。
2、创建一个头结点,然后将头结点指针作为变量传递给链表创建函数。我用的就是这样的方法。
首先是链表初始化函数
LinkList Init_LNode()
{
LNode* L;
L = (LinkList)malloc(sizeof(LNode));
if (L == NULL)
{
printf("初始化失败!\n");
exit(-1);
}
L->next = NULL;
return L;
}
作用是创建一个头结点的内存空间,然后返回其地址。
据说c语言用malloc()函数分配内存时有可能会分配到null,所以有必要进行判断。
然后是链表创建函数
void Creat_List(LNode* L,int* inputArray, int n)
{
LNode* p, * pnew;
p = L;
for (int i = 0; i < n; i++)
{
pnew = (LinkList)malloc(sizeof(LNode));
if (pnew == NULL)
{
printf("初始化失败!\n");
exit(-1);
}
pnew->val = inputArray[i];
p->next = pnew;
p = pnew;
}
p->next = NULL;
}
函数的三个参数是(头结点地址,创建链表的顺序数组地址,数组元素数量),之所以这样是为了方便刷题嘿嘿
然后根据本题的题意,我需要删除指定值得节点,而传入函数的参数是对应节点的地址,然而问题来了,我怎么知道地址呢?
于是我写了一个查询函数,输入值为需要删除的节点对应的值,返回值为该节点的地址
LNode* Query_List(LinkList L, int val)
{
LNode* p = (LNode*)malloc(sizeof(LNode));
p = L->next;
while (p->val != val)
{
p = p->next;
if (p == NULL)
return NULL;
}
return p;
}
哦了,接下来是主函数
int main()
{
LinkList L = Init_LNode();
int n = 4;
int sample[] = { 4,5,1,9 };
Creat_List(L, sample, n);
deleteNode(Query_List(L,5));
LNode* p = L;
for (int i = 0; i < n - 1; i++)
{
p = p->next;
printf("%d ", p->val);
}
}
呼,终于搭建好了测试环境,接下来该看题了。。。。
嗯。。。其实我直接看的答案,看大家的反应就是——原来是个脑筋急转弯!
因为单链表不能访问上一个节点,所以无法改变上一个节点的值,于是就把当前节点伪装成下一个节点,然后跳过下一个节点!
妙啊!!!
void deleteNode(struct ListNode* node) {
node->val = node->next->val;
node->next = node->next->next;
}

呼呼,一共两行的答案,折腾了我好几天才搞明白,果然太弱了。。。
对了我在调试过程中遇到了一个错误,使我得到的地址是0xCCCCCCCC,这就很奇怪啊,查了一下才知道原来这是vs的一种特殊的报警机制,见:
内存中常见异常值的解释( 比如0xcccccccc、0xcdcdcdcd和 0xfeeefeee 异常值 )
至于这“烫烫烫。。。”和“屯屯屯。。。”。。。
下面试一试c++
#include 总体来说c++实现起来比c要简单一些,主要是在分配内存上面,c++直接用new指令分配内存的同时,在构造函数的作用下同时完成了节点的初始化操作。但是这并没有发挥出c++面向对象的特点,按照这位老哥的文章来看,c++中应该把所有的元素都封装在一个类中。
↓↓↓
C++单链表的初始化,插入,删除,反转操作
❤ 2021.9.28 ❤
今天的题目是:
删除链表的倒数第N个节点
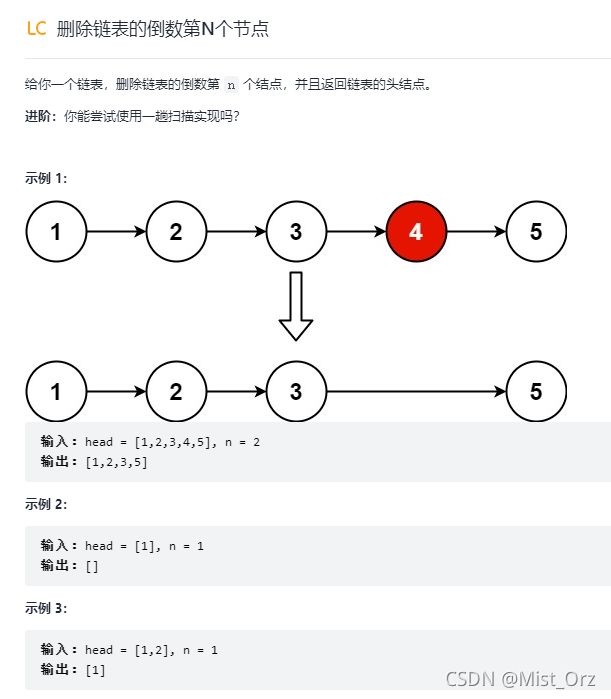
我的思路:
首先得知道链表一共有几个节点。先用while判断到没到null,并计数,然后第二次扫描在倒数n+1个节点修改next指向下下个。
先不管进阶要求,使用两遍扫描。
而且相较于上一题,我对链表的理解已经达到了新的层次(咳咳),于是我把链表初始化函数自己整理了一下
LinkList Init_LNode(int* inputArray,int n)
{
LNode* L = (LinkList)malloc(sizeof(LinkList));
if (L == NULL)
exit(-1);
L->next = NULL;
LNode* r = L;
for (int i = 0; i < n; i++)
{
LNode* pnew = (LinkList)malloc(sizeof(LinkList));
pnew->val = inputArray[i];
r->next = pnew;
r = pnew;
}
r->next = NULL;
return L;
}
删除结点的函数
struct ListNode* removeNthFromEnd1(struct ListNode* head, int n) {
struct ListNode* p = (struct ListNode*)malloc(sizeof(struct ListNode));
int counter = 0;
p = head->next;
while (p != NULL)
{
counter++;
p = p->next;
}
p = head;
counter -= n;
while (counter>0)
{
p = p->next;
counter--;
}
p->next = p->next->next;
return head;
}
在vs里测试一切正常,然后在leetcode上一跑,喜闻乐见的报错了。。。
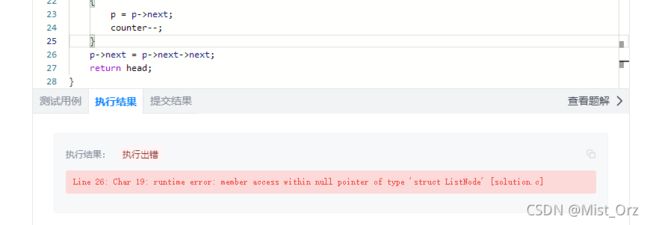
经过多次测试得知,leetcode上面用的链表是不带头结点的,于是我把整个程序改了改
链表初始化函数
LinkList Init_LNode(int* inputArray, int n)
{
LNode* Head = (LinkList)malloc(sizeof(LinkList));
if (Head == NULL)
exit(-1);
Head->val = inputArray[0];
LNode* r = Head;
for (int i = 1; i < n; i++)
{
LNode* pnew = (LinkList)malloc(sizeof(LinkList));
pnew->val = inputArray[i];
r->next = pnew;
r = pnew;
}
r->next = NULL;
return Head;
}
删除节点函数
struct ListNode* removeNthFromEnd(struct ListNode* head, int n) {
struct ListNode* p = (struct ListNode*)malloc(sizeof(struct ListNode));
int counter = 0;
p = head;
while (p != NULL)
{
counter++;
p = p->next;
}
p = head;
counter -= n ;
if (counter == 0)
{
head = head->next;
return head;
}
while (counter > 1)
{
p = p->next;
counter--;
}
p->next = p->next->next;
return head;
}
结构一改思路就变了好多,counter等于0的时候是直接把head赋为下一个节点的地址,这里就不能用p了,切记。。。

下面是激动人心的看答案时间
芜湖,原来还可以这样玩!
首先呢,答案里介绍了一个叫“哑结点”的概念,就是当链表没有单独的头结点时,就给他一个,然后再处理链表的时候就可以不用像我的程序里那样对第一个节点设置特殊的判断条件了。

然后介绍了三种解题方法:
1、暴力法,先判断链表长度,然后再删除对应节点。
2、使用“栈”,先依次把节点地址压入栈里,然后再弹出第n个就是要删除的那个节点。
3、双指针法(快慢指针),因为n是确定的,所以使两个指针之间间隔n-2个节点,当快指针判断到链表结尾时,慢指针对应的就是要删掉的节点。
不得不说,第三种方法又简洁又高效,而且容易实现,但是被双指针沐浴了良久的我咋就没想到。。。。。。
实现起来挺简单,我就不再写一遍了,直接把代码抄过来

struct ListNode* removeNthFromEnd(struct ListNode* head, int n) {
struct ListNode* dummy = malloc(sizeof(struct ListNode));
dummy->val = 0, dummy->next = head;
struct ListNode* first = head;
struct ListNode* second = dummy;
for (int i = 0; i < n; ++i) {
first = first->next;
}
while (first) {
first = first->next;
second = second->next;
}
second->next = second->next->next;
struct ListNode* ans = dummy->next;
free(dummy);
return ans;
}
作者:LeetCode-Solution
链接:https://leetcode-cn.com/problems/remove-nth-node-from-end-of-list/solution/shan-chu-lian-biao-de-dao-shu-di-nge-jie-dian-b-61/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
❤ 2021.9.28 ❤
今天的题目是:
反转链表
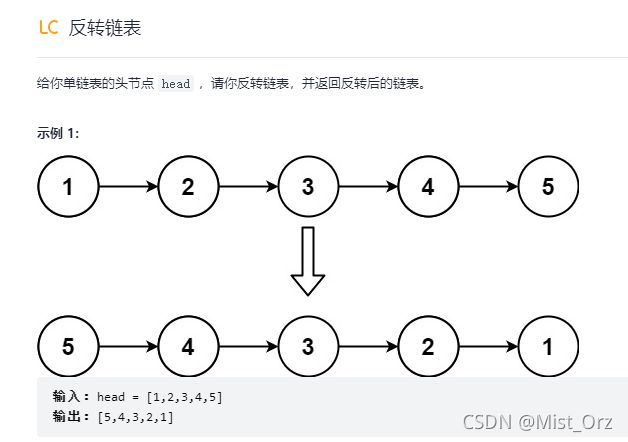

我的思路:
我首先想到的是,先把节点的数值存储到数组里,然后再反向赋值哈哈哈。。。
还是算了。。。
我觉得比较可行的方法是从最后一个节点开始入手,将其指向前一个节点,但是因为后一个节点无法直接找到前一个节点,所以需要一个临时指针变量来存储前一个节点的值,这样的话如果不用递归的方法就得建立一个和节点数相同的指针数组来存储地址。。。
所以决定了,就用递归!
struct ListNode* reverseList1(struct ListNode* head) {
struct ListNode* p = (struct ListNode*)malloc(sizeof(struct ListNode));
struct ListNode* pBack = (struct ListNode*)malloc(sizeof(struct ListNode));
p = head;
if (head == NULL || head->next == NULL)
return head;
if (head->next->next != NULL)
{
pBack = reverseList1(head->next);
}
else
{
pBack = head->next;
}
head->next->next = p;
head->next = NULL;
return pBack;
}
速度还不错,思路大概是这样的

首先排除空链表和只有一个元素的情况,然后不断递归寻找当前元素的->next->next为空指针的情况,也就是找到倒数第二个元素,并返回->next作为新链表的头结点,然后将->next->next指向当前元素,并将当前元素的->赋为空(这样做的目的是确保新链表的最后一个元素的->next指向空,不然会形成一个环。。。)
然后是激动人心的看答案时间。
答案介绍了两种方法,一种是递归,一种是迭代。
迭代的方法思路和我的差不多,但是代码比我的简洁很多
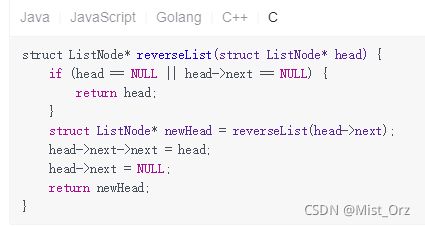
我对比了一下,答案的代码把判断链表为空和单元素的情况,以及搜索到链表结尾并返回其地址的情况进行了合并,而且并没有像我一样多此一举的申请了内存地址来保存head,因为是递归嘛,每次操作的元素都是head,而且在函数里也没有对head本身的操作,只有读取,所以确实没必要再新建个指针保存head。
嗯嗯学到了学到了。
然后关于迭代的方法

我分析了一下,大概是这样的
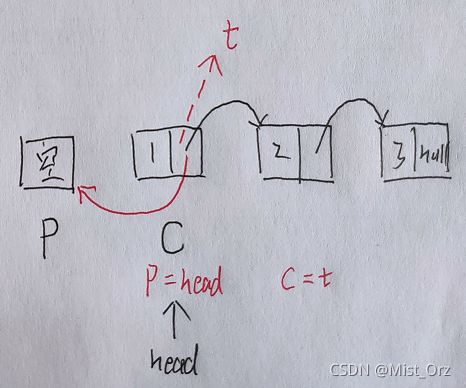
用双指针的方法,指针C指向当前元素,指针P指向前一个元素(当前元素为head时,P为空),先将当前元素的->next存进临时指针t,然后将当前元素指向前一个元素(也就是->next等于P),然后两个指针同时向后移动一个元素(也就是P=head,C=t),over。
这个方法吧,整理出来感觉挺好理解的,但是代码里面不断地连续替换地址让人第一眼看着很头大。于是我又想出了一个新的方法。

首先我新建一个哑结点,让他指向head,然后新建一个指针p,指向head->next,我要做的就是每次迭代中,先将dummy指向的节点地址存入临时指针t,然后使dummy指向p所指向的节点,并使p所指向的节点指向dummy之前指向的节点(也就是p指向的前一个节点,p->=t)。需要注意的是要在进入迭代前将head指向为空,不然会行程环,最后返回dummy->next。
struct ListNode* reverseList(struct ListNode* head) {
struct ListNode* p = (struct ListNode*)malloc(sizeof(struct ListNode));
struct ListNode* dummy = (struct ListNode*)malloc(sizeof(struct ListNode));
if (head == NULL || head->next == NULL)
return head;
dummy->val = 0;
dummy->next = head;
p = head->next;
head->next = NULL;
while (p != NULL)
{
struct ListNode* t = (struct ListNode*)malloc(sizeof(struct ListNode));
t = dummy->next;
dummy->next = p;
p = p->next;
dummy->next->next = t;
}
return dummy->next;
}
❤ 2021.9.30 ❤
今天的题目是:
合并两个有序链表
我的思路:
就很简单嘛!
我用两个指针指向两个链表,一对一对的比较,让返回的链表指针指向小的那个节点不就行了~!
struct ListNode* mergeTwoLists(struct ListNode* l1, struct ListNode* l2) {
struct ListNode* dummy = (struct ListNode*)malloc(sizeof(struct ListNode));
struct ListNode* p = dummy;
struct ListNode* p1 = l1;
struct ListNode* p2 = l2;
while (p1 != NULL && p2 != NULL)
{
if (p1->val <= p2->val)
{
p->next = p1;
p1 = p1->next;
}
else
{
p->next = p2;
p2 = p2->next;
}
p = p->next;
}
if (p1 == NULL)
{
p->next = p2;
}
else
{
p->next = p1;
}
return dummy->next;
}
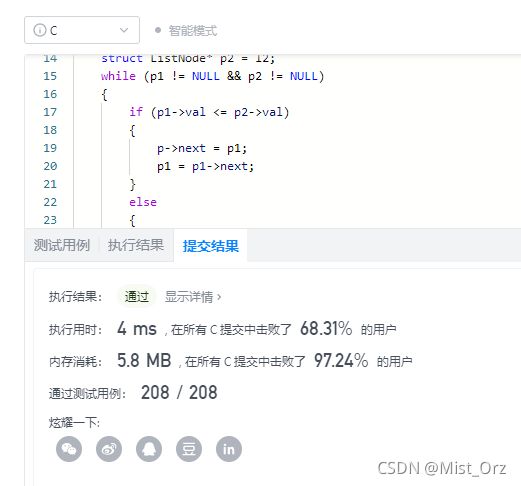
锵锵~一次通过!
然后我看了看答案,确实这是方法之一,和答案稍有不同的是,答案里并没有定义那么多指针,而是直接用参数的指针来迭代,毕竟不管用不用这两条链表都被改变了,所以没影响。
然后另一种方法就是很有意思的递归了!
思想就是对比两个链表当前节点的值,哪个比较小就返回那个节点的地址,然后将那个节点的->next和另一个链表的当前节点再次送入递归函数,直到某一个链表的节点的为NULL为止,此时返回另一个节点的当前地址。
我用c++写了一下
class Solution {
public:
ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {
if (l1 == nullptr)
return l2;
else if (l2 == nullptr)
return l1;
else if (l1->val < l2->val)
l1->next = mergeTwoLists(l1->next, l2);
else
l2->next = mergeTwoLists(l2->next, l1);
return (l1->val < l2->val ? l1 : l2);
}
};
嗯。。。代码简洁思路清晰,递归是个好东西。。。
然后呢我还搜了一下,c语言的NULL和c++的nullptr有啥区别
C++中NULL和nullptr的区别
学到了学到了
❤ 2021.10.2 ❤
今天的题目是:
回文链表

我的思路:
这个题吧,第一反应是先把链表存成数组,然后再判断是不是回文数组,但是吧。。。就有点傻感觉,所以一定有更好的办法。
或者可以先判断链表的长度,然后把后半段链表用之前题目的方法先反转,然后再比较,嗯。。。
好主意。。。
链表反转的方法就用上一题的双指针法。
struct ListNode* reverse(struct ListNode* L)
{
struct ListNode* p = NULL, * c = L;
while (c != NULL)
{
struct ListNode* t = c->next;
c->next = p;
p = c;
c = t;
}
return p;
}
bool isPalindrome(struct ListNode* head) {
struct ListNode* p1, * p2;
p1 = head;
p2 = head->next;
while (p2 != NULL && p2->next != NULL)
{
p1 = p1->next;
p2 = p2->next->next;
}
if (p2 == NULL)
return false;
p2 = reverse(p1->next);
p1 = head;
while (p2 != NULL)
{
if (p1->val != p2->val)
return false;
p1 = p1->next;
p2 = p2->next;
}
return true;
}
然后一跑出问题了
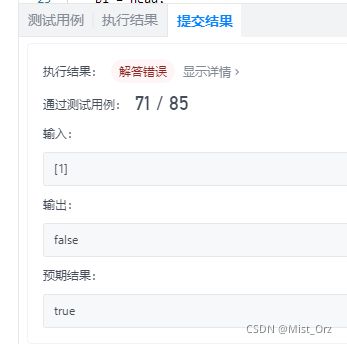
也就是说,奇数个元素也有可能是回文链表,而且单个元素必是回文链表,那我改一下
struct ListNode* reverse(struct ListNode* L)
{
struct ListNode* p = NULL, * c = L;
while (c != NULL)
{
struct ListNode* t = c->next;
c->next = p;
p = c;
c = t;
}
return p;
}
bool isPalindrome(struct ListNode* head) {
struct ListNode* p1, * p2;
p1 = head;
p2 = head->next;
if (head->next == NULL)
return true;
while (p2 != NULL && p2->next != NULL)
{
p1 = p1->next;
p2 = p2->next->next;
}
p2 = reverse(p1->next);
p1 = head;
while (p2 != NULL)
{
if (p1->val != p2->val)
return false;
p1 = p1->next;
p2 = p2->next;
}
return true;
}
OK,下面是激动人心的看答案时间。
首先震惊的是,把链表的值提取到数组里居然也是官方给的解法之一!!!而且代码简洁,实现简单,毕竟5000个元素的数组在计算机里也没有多大。。。
然后就是我用的方法了,找到中间值然后反转后本部分链表,不过答案里提到一个细节就是在反转之后最好把链表再反转回来,因为反转改变了链表的结构,而是用这个函数的人应该不希望链表的结构被改变。。。而且用这种方法的话还要在函数调用过程中锁定其他程序对链表的访问,毕竟结构被改变了。。。
最后就是递归的方法了,这个方法就挺巧妙的,首先递归的方法天然的生成了从后往前的判断顺序,这里新建一个递归函数,用一个递归函数以外的变量存储递归中的节点地址,并将其值与链表顺序值进行比较,判断是否为回文。
我用c++试着实现了一下
class Solution {
public:
bool recursion(ListNode* p, ListNode** f) {
bool b = true;
if (p->next != nullptr)
{
b = recursion(p->next, f);
}
if (b == false)
return false;
if ((*f)->val != p->val)
return false;
(*f) = (*f)->next;
return true;
}
bool isPalindrome(ListNode* head) {
ListNode** f = &head;
return recursion(head, f);
}
};
首先我建立了一个递归函数,用它去寻找链表的尾结点,然后从后往前依次和链表头结点从前往后比较,那么就需要将头结点的地址逐层传递到最深一层递归函数中,然后每返回一层,就将其指向下一个节点地址,但是我们知道,如果我们只是传递指针参数,只能保证其一直指向头结点地址,如果对头结点地址进行操作就会改变原链表,那么就达不到使用递归方法的目的了,而如果对指针本身进行操作则无法将其传递回上一层递归里,于是这里我用了二重指针,使其指向指向头结点地址的指针,
这样就可以使用取内容运算符来操作指向头结点地址的指针了!
在调试的过程中我犯了个错误,我把判断进入递归的语句最开始用成了while,于是造成了不断地进入递归又不断地返回。。。

嗯呢,反正是通过了。
然后我看了看答案,和我写的基本差不多,但是他在函数之外定义了个结构体存放头节点的地址,这样在整个循环里就可以当做全局变量来操作了,啊这。。。这不是我初学编程的时候最喜欢干的事情么!!
不过呢思路还是很值得学习。
❤ 2021.10.3 ❤
今天的题目是:
环形链表

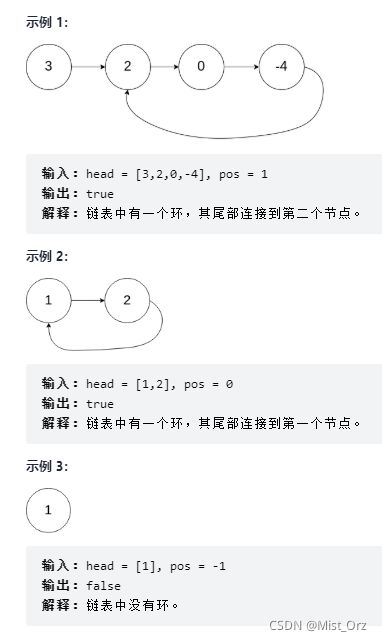
我的思路:
这什么东西。。。
乱七八糟的。。。
不过整理下思路大概明白了,就是我先造一个里面有环的链表,然后再把链表传进我写的函数里,让函数判断里面是不是有环。
嗯。。。
所以我先得建立一个链表,然后按照pos的数值让他变成一个环
LinkList Init_LinkList(int* inputArray, int n, int pos)
{
LNode* head = (LinkList)malloc(sizeof(LinkList));
head->val = inputArray[0];
LNode* r = head;
LNode* ppos = head;
for (int i = 1; i < n; i++)
{
LNode* p = (LinkList)malloc(sizeof(LinkList));
p->val = inputArray[i];
r->next = p;
r = p;
}
if (pos == -1)
{
r->next = NULL;
return head;
}
for (int i = 0; i < pos; i++)
{
ppos = ppos->next;
}
r->next = ppos;
return head;
}
判断节点是不是被访问过,我的第一反应是用哈希表(虽然不会用。。。),但是这道题作为标签的是地址,而不是下标,就挺长的,之前用过的数组下标作为索引建立类似哈希表的方法貌似不太管用,如果用的话就得用真正的哈希表了,就挺麻烦的。。。
我转念一想,那我就直接判断链表里有没有指向NULL的指针呗,但是如果链表里有环,那不就死循环了么?题目里面给出的链表长度是有限的,就是说最大循环次数超过链表的最大长度,那么就说明链表有环!但是这个方法总觉得有点不正常,面试的时候这样写会不会被劝退。。。
于是我看了看网友们的答案。。。
好家伙,还真有我这样的想法的!

在这里整理一下:
1、不正经方法:寻找NULL,循环超过10000次说明有环
2、正经方法:哈希表
3、不正经方法:遍历时修改val值为一个不在取值范围的特殊值,当再次出现这个值时说明有环
4、不太正经的方法:遍历时修改->next值使其指向head,如果遍历到了head说明有环,这种方法虽然可行但是破坏了链表
5、最最最正经的方法:快慢指针法,快指针每次移动两个节点,慢指针每次移动一个节点,如果有环则两个指针必定会相遇。
好吧,还是最后一种方法靠谱一点。
bool hasCycle(struct ListNode* head) {
struct ListNode* f = head, * s = head;
while (f != NULL && f->next != NULL && s != NULL)
{
f = f->next->next;
s = s->next;
if (f == s)
return true;
}
return false;
}
嗯。。。大概意思就是这样,关于while里面的判定条件,其实没必要判断慢指针是否到了NULL,因为快指针一定比慢指针先到。