Python 数据可视化学习笔记 之高维数据可视化及其方法
一、高维数据
高维数据泛指高维(multidimensional) 和多变量(multivariate)数据
-- 高维是指数据具有多个独立属性 -- 多变量是指数据具有多个相关属性
高维数据可视化的挑战:
如何呈现单个数据点的各属性的数据值分布,以及比较多个高维数据点之间的属性关系,从而提升高维数据的分类、聚类、关联、异常点检测、属性选择、属性关联分析和属性简化等任务的效率。
说明:
1.聚类:聚类是一种无监督学习的手段,其目的是使相似数据点分布在同一类中,而不同数据点处于不同类中或者噪声中
2.利用关联分析的方法可以发现联系如关联规则或频繁项集。
关联分析需要处理的关键问题:
- 从大型事务数据集中发现模式可能在计算上要付出很高的代价。
- 所发现的某些模式可能是假的,因为它们可能是偶然发生的
高维数据可视化方法分类:

方法之间的比较:
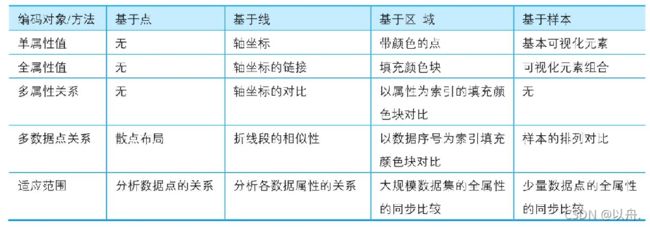
当需要把高维数据以一种可视化的形式展现出来是,则需要对高维数据进行一些处理——降维
2.降维
使用线性或非线性变换把高维数据投影到低高维空间中,去掉冗余属性,同时尽可能地保留高维空间的重要信息和特征
方法分类:
线性方法:主成分分析PCA、多维尺度分析MDS、非矩阵分解NMF,等
非线性方法:等距特征映射ISOMAP、局部线性嵌套LLE,等
2.1主成分分析法(PCA)
详细:(31条消息) 主成分分析(PCA)原理详解_Microstrong-CSDN博客_pca
主成分分析法采用一个线性变换将高维数据变换到一个新的坐标系统中,使得任何数据点投影到第一个坐标(第一主成分)的方差最大,在第二个坐标(第二主成分)的方差为第二大,依次类推。
优点:主成分分析可以减少数据的维数,并保持对方差贡献最大的特征,相当于保留低阶主成分,忽略高阶主成分
特点:一组二维数据,采用主成分分析检测到的前两位综合指标,正好指出数据点的两个主要方向(正交)
作业:使用进行数据集:iris(安德森鸢尾花卉数据集)绘制
iris数据集介绍
iris数据集有150个观测值和5个变量,分别是sepal length、sepal width、petal length、petal width、species,其中species有3个取值:setosa、virginica、versicolor,反正就是鸾尾花的3个不同品种吧,各有50个观测值。具体见下表。

import pandas as pd
import numpy as np
from plotnine import*
from sklearn.decomposition import PCA
from sklearn import datasets
iris=datasets.load_iris()
data = PCA(n_components =2).fit_transform(iris.data) #对数据进行降维处理
target= pd.Categorical.from_codes(iris.target,iris.target_names)
df= pd.DataFrame(dict(pca1=data[:,0],pca2 = data[:,1],target= target))
base_plot=(ggplot(df,aes('pca1','pca2',fill='factor(target)'))+
geom_point(alpha=1,size= 3,shape='o',colour='k') +
#绘制透明度为0.2的散点图
stat_ellipse ( geom="polygon",level =0.95, alpha=0.2) +
#绘制椭圆标定不同的类型
scale_fill_manual(values= ("#00AFBB", "#E7B800", "#FC4E07"),name='group')+
theme(
axis_title= element_text(size= 15,face= "plain",color= "black"),
axis_text= element_text(size= 13,face= "plain" ,color="black"),
legend_text = element_text(size= 11,face="plain",color= "black"),
figure_size =(5,5),
dpi = 100))
print(base_plot)
1.Categorical:categorical 实际上是计算一个列表型数据中的类别数,即不重复项,它返回的是一个CategoricalDtype 类型的对象,相当于在原来数据上附加上类别信息 , 具体的类别可以通过和对应的序号可以通过 codes 和 categories 来查看:
在实际应用中 我们常常是结合他的 codes 属性来一起使用的 , 即
pd.Categorical( list ).codes 这样就可以直接得到原始数据的对应的序号列表,通过这样的处理可以将类别信息转化成数值信息 ,这样就可以应用到模型中去了 另外更加详细的功能参考官网。
其实看到这里 可以发现 Categorical 的功能和 之前在机器学习 数据处理部分提到的 LabelEncoder (https://blog.csdn.net/weixin_38656890/article/details/80849334)
的功能是一样的, 不过 Categorical 是对自己编码 ,而LabelEncoder 是通过通过一个样本 制成标准 然后 对其他样本编码,因而相对的更加灵活。
2.pd.Categorical.from_codes用于类别替换
原来版本是pd.Factor,新版本换成了pd.Categorical.from_codes(),功能都一样;
实例:
pd.Categorical.from_codes(iris.target, iris.target_names)
原来的target是这样的:
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
现在变成了这样:
[setosa, setosa, setosa, setosa, setosa, ..., virginica, virginica, virginica, virginica, virginica] Length: 150 Categories (3, object): [setosa, versicolor, virginica]
2.2 t-SNE算法
Manifold Learing是一种非线性降维的手段,可以看作一种生成类似PCA的线性框架,不同的是可以对数据中的非线性结构敏感。虽然存在监督变体,但是典型的流式学习问题是非监督的:它从数据本身学习高维结构,不需要使用既定的分类。 t-SNE是一种工具。
非线性降维算法 基于在邻域图上随机游走的概率分布来找到数据的内部结构 基本思想:若两个数据在高维空间中是相似的,则降维至2维空间时它们应该离得很近(用条件概率来描述两个数据之间的相似性)TSNE的实现总体上并不复杂,麻烦的是其超高的浮点运算和大型矩阵的操控。
t-SNE(t分布随机邻域嵌入)是一种用于探索高维数据的非线性降维算法。通过基于具有多个特征的数据点的相似性识别观察到的簇来在数据中找到模式,将多维数据映射到适合于人类观察的两个或多个维度。本质上是一种降维和可视化技术。使用该算法的最佳方法是将其用于探索性数据分析。
from sklearn.manifold import TSNE
iris_embedded = TSNE(n_components=2).fit_transform(iris.iloc[:,:-1])
pos = pd.DataFrame(iris_embedded, columns=['X','Y'])
pos['species'] = iris['species']
ax = pos[pos['species']=='virginica'].plot(kind='scatter', x='X', y='Y', color='blue', label='virgnica')
pos[pos['species']=='setosa'].plot(kind='scatter', x='X', y='Y', color='green', label='setosa', ax=ax)
pos[pos['species']=='versicolor'].plot(kind='scatter', x='X', y='Y', color='red', label='versicolor', ax=ax)import pandas as pd
import numpy as np
from plotnine import *
from sklearn import manifold, datasets
df=pd.read_csv('D:\Tsne_Data.csv')
df=df.set_index('id')
num_rows_sample=5000
df = df.sample(n=num_rows_sample)
tsne = manifold.TSNE(n_components=2, init='pca', random_state=501)
X_tsne = tsne.fit_transform(df.iloc[:,:-1])
df=pd.DataFrame(dict(DistributedY1=X_tsne[:, 0],DistributedY2=X_tsne[:, 1],target=df.iloc[:,-1]))
base_plot=(ggplot(df, aes('DistributedY1','DistributedY2',fill='target')) +
geom_point (alpha=1,size=2,shape='o',colour='k', stroke=0.1)+
scale_fill_hue(s = 0.99, I= 0.65, h=0.0417,color_space='husl')+
xlim(-100,100))
print(base_plot)
1.set_index( ) 将 DataFrame 中的列转化为行索引。
2.sample(序列a,n)
功能:从序列a中随机抽取n个元素,并将n个元素生以list形式返回。
参考:
基于Python的数据可视化:从一维到多维 - 简书 (jianshu.com)
(31条消息) pd.Categorical 的用法_code_new_life的博客-CSDN博客_pd.categorical
pd.Categorical.from_codes()用于类别替换 - 小小喽啰 - 博客园 (cnblogs.com)