Transformer合集1
最近Transformer文章太多了 索性一起发了得~~ 以后关于这个的都不单发了
如何提高ViT的效率?可以是让模型更容易训练,减少训练时间,也可以减少模型部署在硬件上的功耗等等。本文主要讲inference time的效率问题,简单说就是如何让模型更快,同时性能不掉太多甚至反升。
如何提高ViT的效率?可以是让模型更容易训练,减少训练时间,也可以减少模型部署在硬件上的功耗等等。本文主要讲inference time的效率问题,简单说就是如何让模型更快,同时性能不掉太多甚至反升。
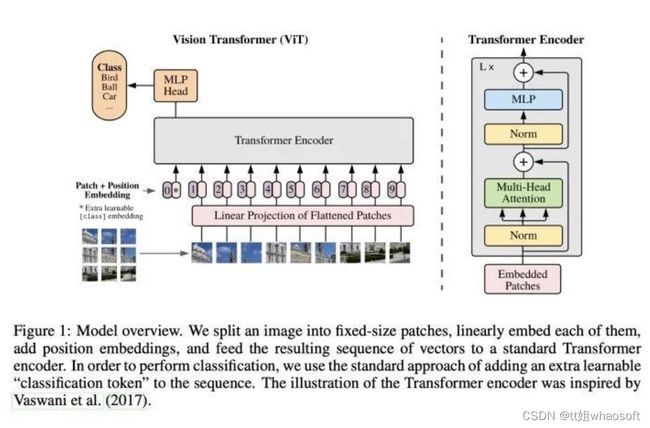
背景
2021开年后,Transformer在CV任务中大放光彩,Google的初版Vision Transformer(ViT)虽然方法简单,但通过大量的实验证明了Transformer在计算机视觉(CV)任务上,特别是image classification上的可能性。论文展示,ViT经过large-scale pretrain之后在ImageNet上可以达到和CNN媲美的性能。
然而,CV的任务可不止image classification,给一个图片预测一个label就结束了。对于大量dense prediction的任务而言, 比如object detection和segmentation,Transformer都有其局限性,而其中最关键的有两点,
-
缺少金字塔特征(Pyramid Feature Map)。 层级特征对物体的检测很重要,特别是小物体,因为feature map的scale如果比较小的话,小物体相当于直接被忽视了。常见的CNN,如ResNet将网络划分四个stage,每个stage处理一种scale的feature map, 如1/4,1/8, 1/16,1/32。这样出来的层级特征可以送入FPN进行处理,然后作为输入给detection或者segmentation的head。而ViT只处理1/16这个scale下的feature map,直观上来看是对dense prediction任务不利的。
-
Multi-head Self-attention(MSA)计算开销问题。 MSA是一个quadtic complexity的模块,小图还好,但是遇到分辨率大的时候,无论是显存占用还是计算速度都会大打折扣。然而像detection和segmentation这种任务,图片一般都比较大,如512x512。按照ViT的patch embedding划分,图片会分成 (512/16)x (512/16) = 1024。此时ViT-Base的单层MSA会消耗4G FLOPs。然而整个ResNet-50也才消耗4G FLOPs. 因此MSA的计算开销限制了ViT在高分辨率图像上的效率。
对于第一个问题,一个自然的想法就是给ViT引入pyramid feature map, 这也是ICCV 2021积极涌现的idea,如Swin, PVT。然而,引入结构上的hierarchy造成了前期feature map的scale比较大,此时MSA的计算开销上涨。这使得efficient attention在ViT上成为了必需品,正如Swin用到的local window attention和PVT的spatial reduction attention,当然后面有更多的architecture,更多的attention,在此就不一一举例了。
自此,ViT适配下游任务已经基本没有了大的障碍。大致结构上和CNN保持一致,如划分stage,逐渐对feature map做downsampling。得益于attention的结构, ViT在各个task上性能都保证的不错。那接下来的主要问题就是对ViT在CV任务中进行优化。
什么最影响ViT的速度?
影响一个模型速度的东西无非是两个大方面,一是结构,二是处理的数据规模,剩下基本是工程上的优化。从个人观点来看,对于ViT来说,影响结构效率的有两个,
-
Efficient General Architecture. 整体结构上的设计需要变得有效并且scalable
-
Efficient Multi-head Self-attention. 注意力机制必须足够efficient
对于处理的数据规模问题,这个CNN也有,但有一个明显区别于CNN的是,ViT对input是permutation-invariant的,只要加入了positional encoding就可以无视2D spatial order。所以针对ViT而言,减少input tokens是可以做推理加速的,如本人在ICCV 2021上的工作HVT: Scalable Vision Transformers with Hierarchical Pooling(https://arxiv.org/abs/2103.10619)。
结构上怎么设计最合理?- LITv1
HVT之后,我们曾经的一个想法是进一步对token做一个dynamic的选取,因为直觉上来讲dynamic要比unifrom的pooling要好,了解这一领域的同学可能有点耳熟,没错,这个思路就是DynamicViT(https://arxiv.org/abs/2106.02034)。
然而,实验过程中的一个发现,使得我们展现给大家的是LIT, Less is More: Pay Less Attention in Vision Transformers(https://arxiv.org/abs/2105.14217) (AAAI 2022)。
和DynamicViT利用pretrained weights和plain ViT不一样,我们直接从hierarchical Vision Transformer入手并且train from scratch,如PVT,用几层FC对前两个stage中每个block的input tokens做一个dynamic的选取,使得前期MSA只需要处理1/4, 1/8 scale下选取的部分token。这个思路听起来感觉没什么问题,可视化效果也确实不错,如下面是去年基于PVT-S做sparse选取token做的一个可视化:
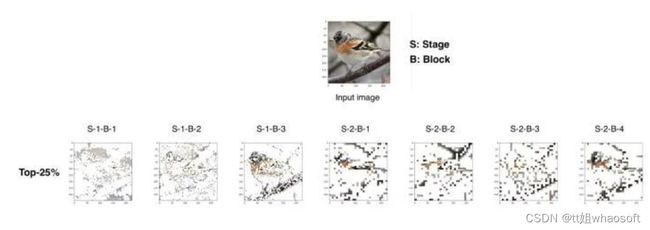
虽然但是,当我们对比random sampling的baseline时,发现性能差距并不大,一番分析之后,我们直接训练了一个完整的基于原始MSA的PVT-Small,通过可视化attention head, 我们发现前期的head只能关注于很小的local区域,尤其是第一个stage的MSA,attention weight基本都在关注自己,我们进一步在论文给出了理论上的解释。
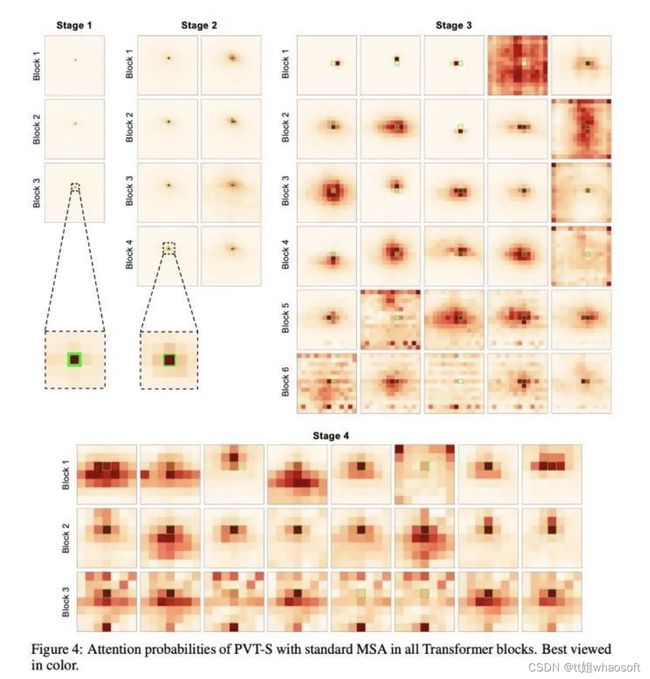
基于这个发现,我们做了一个在当时来看(2021.05)比较大胆的决定,直接拿掉前两个stage的所有MSA layer,这样前期的Transformer block中只剩下了FFN, 而后期的两个stage直接采用最原始的MSA。这使得我们模型的整体结构看起来非常简单,如下面所示。
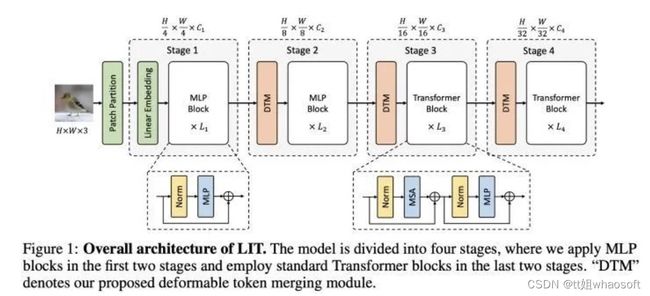
我们把这种设计原则在Swin Transformer和PVT上做了验证,结果显示这种方案不仅不降性能,还因为避开了前期MSA的计算开销,减小了理论复杂度,大幅度加快了推理速度。
| Model | Params (M) | FLOPs (G) | Throughputs (imgs/s) | ImageNet@Top-1 |
|---|---|---|---|---|
| PVT-S | 25 | 3.8 | 1,058 | 79.8 |
| PVT-S w/ remove early MSAs | 19 | 3.6 | 1,388 | 80.4 |
| Swin-Ti | 28 | 4.5 | 960 | 81.3 |
| Swin-Ti w/ remove early MSAs | 27 | 4.1 | 1,444 | 81.3 |
另外我们在LIT中提出了一个Deformable Token Merging module (DTM),使得feature map在下采样时可以动态的根据前景信息对token做选取。经过可视化发现学习到的offset十分精准地捕捉到了前景物体信息。相关可视化代码已公开在https://github.com/ziplab/LIT。

上面每张图片中,绿框代表最后一个scale下(1/32)的某个位置的token,红色点表示DTM在downsample时最终选取的1/4 scale的token
阶段总结: LIT在结构上主要陈述了一个事情,backbone前期采用MSA的效益并不高。即使是擅长global attention的MSA也依然重点关注local区域,何况前面的feature map比较大,MSA处理高分辨图像的开销很大,即使采用efficient attention也难以避开这部分计算。
所以我们看到后来的Uniformer, MobileViT,EfficientFormer都是这种前面local后面global的结构。想要快,前面还是得尽量避开MSA。
Architecture和Attention一起优化 - LITv2
在前期的工作中,我们定下了ViT的Architecture设计原则,但第一版LIT有两个问题影响实际推理速度,
-
RPE虽然能涨点,但对于LIT来说,由于后面需要动态根据input大小做插值,所以对速度影响很大。
-
后两个stage的原始MSA针对高分图像还是会有很大的计算开销。
基于此,我们提出了LITv2:Fast Vision Transformers with HiLo Attention(https://arxiv.org/abs/2205.13213) (NeurIPS 2022), 主要对LIT做了两点改进,
-
去掉了relative positional encoding (RPE), FFN中加入depthwise convolution来引入conditional positional embedding。通过引入depthwise conv不仅能引入positional encoding, 还能同时增大网络前期的receptive field。(因为LIT前面两个stage只有FFN)
-
换上了全新的attention方法,HiLo。
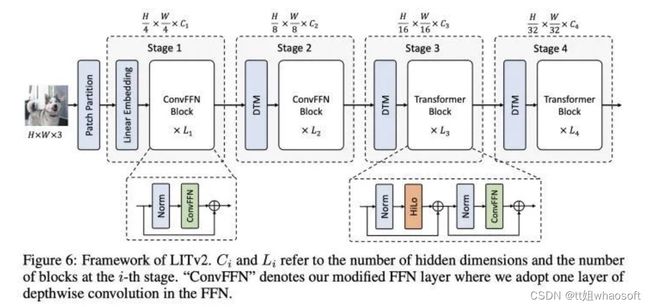
Attention还能更快
直接影响ViT在高分辨率图像上的效率的还是attention。从21年到现在,这一领域已经针对ViT提出了不少attention的变种,如SRA(https://arxiv.org/abs/2102.12122)(ICCV-21),local window(https://arxiv.org/abs/2103.14030)(ICCV-21), focal attention(https://arxiv.org/abs/2107.00641)(NeurIPS-21), QuadTree(https://arxiv.org/abs/2201.02767) (ICLR-22)。和MSA相比,这些方法都能保证更优的理论复杂度。但是我们注意到FLOPs只能反映理论复杂度,而真正想在CV任务中beat过纯CNN的话,除了性能,实测速度也十分关键,因为理论复杂度并不能反应GPU和CPU上的实际速度。影响实测throughput/latency的还有memory access cost和其他难以被统计进FLOPs的因素,如for-loop。
以实测速度为核心,我们在LITv2中提出了HiLo。HiLo的设计理念很简单: 在信号处理中,高频关注local detail, 因此就用部分head做local window attention去捕获,而低频关注global structure,对local detail并不太在乎,所以另一部分head只需处理average pool的低频信号,这样高低频同时捕捉,实现单层MSA同时抓取local和global信息。相对应的branch,我将它命名为Hi-Fi和Lo-Fi,如下图所示。
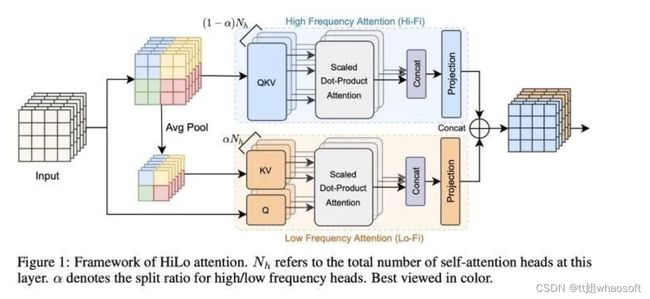
为了保证实际速度,HiLo避开了一些不能算到FLOPs但损害速度的运算,如overlapping window和interpolation。基于此,HiLo在实测速度,memory占用,以及性能上都超越了SOTA方法。
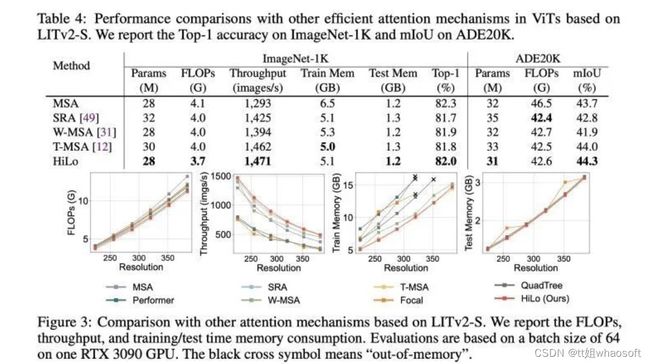
在CPU和GPU上,单层HiLo的推理速度非常快
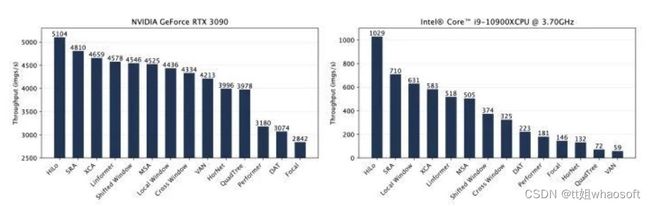
上图的测试结果可以参考我的vit-attention-benchmark(https://github.com/HubHop/vit-attention-benchmark)仓库。 whaosoft aiot http://143ai.com
又快,又好,又容易训练的LITv2
LITv2共推出了三个变种,small, medium, base, 为了公平对比,三个模型的宽度和深度和Swin Transformer一样,超参seed一点没调。LITv2整体在ImageNet-1K上效果占优,同时降低了训练显存要求,推理速度更快。
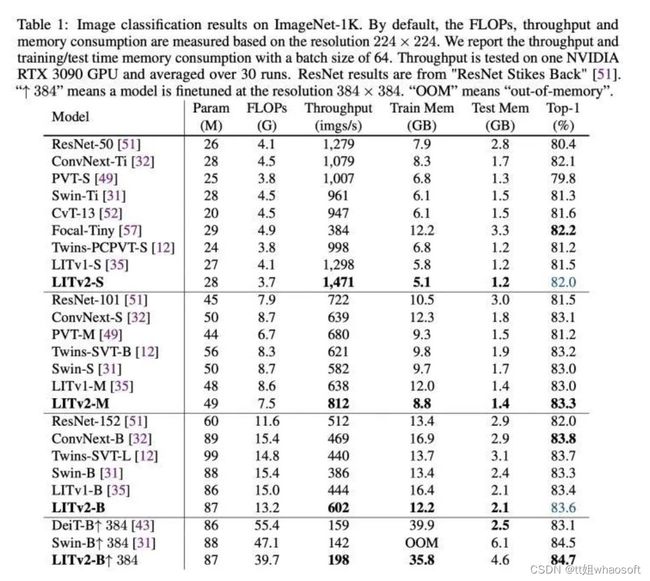
由于资源实在有限,对比Swin-Large和ImageNet-22k上的setting确实没法跑。。。。
另外我们在多个GPU平台上测试了推理速度(来自reviewer的意见)。对比ResNet-50和其他11个最近的ViT模型,相似参数量下,LITv2-S在速度和理论复杂度上实现了全面超越,同时ImageNet的Top-1 accuracy在第一梯队。
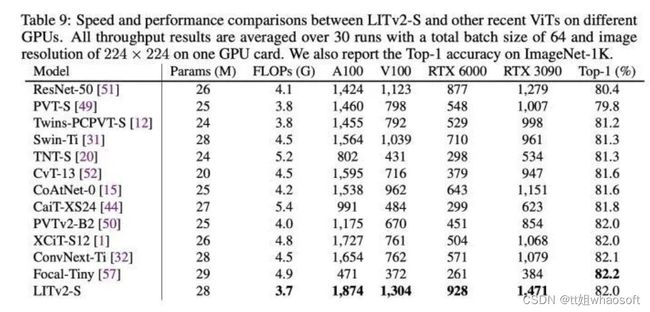
上面关于LITv2的Speed测试和运行示例都已公开在:https://github.com/ziplab/LITv2,欢迎大家尝试。
未来还能做什么
Vision Transformer的故事还在继续,今年NeurIPS投稿也能看到大家陆续也在关注实测速度了,如TRT ViT,EfficientFormer, 但实际上ViT的工业落地相比CNN可能还是会有障碍。如量化上,ViT还是在低bit上还有很大提升空间。除此之外,我们组(https://ziplab.github.io/)也在探索Transformer的其他efficiency问题,比如
ViT的Training efficiency还有很大的空间。 ViT普遍难训练,需要的显存大,训练时间长。特别是backbone的公认setting是1024的batch size + 8 GPUs,使得很多小组连ViT跑都跑不起来(8卡 32GB V100不是所有人都有的),针对这一问题我们提出了一个针对Transformer的一个memory-efficient的训练框架: Mesa: A Memory-saving Training Framework for Transformers(https:arxiv.org/abs/2111.11124). 和普通训练相比,Mesa可以做到显存节省一半,同时与checkpointing和gradient accumulation等技术方案不冲突。
Transformer的能源消耗也是一个问题,特别是当下很多大组在跑以Transformer为backbone的大模型,训练时所造成的电力损耗,碳排放对Green AI这一长远目标不利。针对Energy efficiency,我们组在NeurIPS 2022最新的工作 EcoFormer: Energy-Saving Attention with Linear Complexity(https://arxiv.org/abs/2209.09004) 提出了一个Transformer二值化的全新方案,全新设计的EcoFormer是一个general的efficient attention, 性能和功耗上都优于一众线性复杂度的Linformer, Performer等,同时在45nm CMOS microcontroller上能耗更低,速度更快。
至于CNN和Transformer哪个好的问题,这个答案其实不必再过多讨论了,因为两者互补。通过合理地配置CNN和MSA在Backbone中的位置,可以让网络得到双倍的快乐。更不用说Convolution和MSA两者之间本身存在一种联系,比如我们组的另一篇工作:Pruning Self-attentions into Convolutional Layers in Single Path(https://arxiv.org/abs/2111.11802), 巧妙地通过参数共享将计算复杂度较高的attention layer剪成更为efficient的convolutional layer,工程细节可以参考:https://github.com/ziplab/SPViT。
个人主页:Zizheng Pan:https://link.zhihu.com/?target=https%3A//zizhengpan.github.io/
下面在说一下torch创始人的看法
2017 年 Transformer 首次亮相,便迅速在 AI 领域扩散开来,CV、NLP 等任务都有其身影,越来越多的研究人员投入其中。
要说 Transformer 有多厉害,比如 OpenAI 重磅推出的 GPT-3,就是基于 Transformer 实现的。至于传播速度方面,短短 5 年,Transformer 便在 TensorFlow 、PyTorch 等主流深度学习框架支持的 AI 程序中占据一席之地。
可别小看这 5 年,假如我们把机器学习比作一个世界,毫不夸张地说,它们的 5 年相当于我们的半个世纪。
不过与高调宣传 Transformer 的学者不同,这次 PyTorch 创始人、Meta 杰出工程师 Soumith Chintala 却唱起了反调,并警告说,Transformer 如此流行,可能是一把双刃剑,Transformer太火很不好,AI易撞墙。
他认为,到今天为止, Transformer 已经 5 年了,这期间还没有可替代的研究出现。他表示,对占主导地位的 AI 方法(此处指 Transformer)的强烈认可,可能会产生意想不到的后果,越来越多的 Transformer 专用硬件可能会使新策略更难以流行。 
看吧一个阿三大哥... 他们还是挺厉害的 其实
至于 Soumith Chintala 为何会有上述结论,他首先从硬件进行举例。
专用 AI 硬件不断出现,其他技术将很难出头
Transformer 自从在论文《 Attention Is All You Need 》中被首次提出,之后便在很多地方都能看到它的身影。
相应地,为 AI 定制专门的硬件开始流行起来。在 GPU 方面,英伟达一直占据重要地位,他们还发布了一个名为 Hopper 的架构,其名称来自于计算机科学先驱 Grace Hopper,该架构专门用于 Transformer。
英伟达甚至还基于 Transformer,专门优化了 H100 加速卡的设计,提出了 Transformer Engine,它集合了新的 Tensor Core、FP8 和 FP16 精度计算,以及 Transformer 神经网络动态处理能力,可以将此类机器学习模型的训练时间从几周缩短到几天。
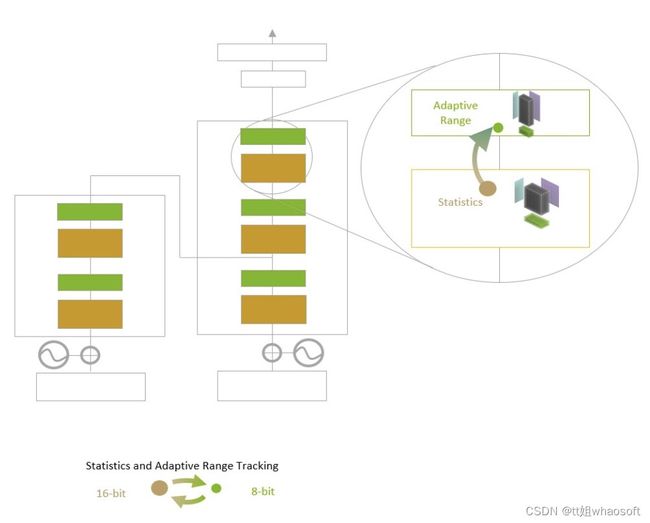
Transformer Engine 使用每层统计分析来确定模型每一层的最佳精度(FP16 或 FP8),在保持模型准确率的同时实现最佳性能。
英伟达首席执行官黄仁勋在最近的财报电话会议上表示,Hopper 将是其战略的重要组成部分(不过,可以肯定的是,英伟达是一家规模庞大的公司,其产品远不止 Hopper)。黄仁勋还表示:预计 Hopper 将成为未来增长的下一个跳板。他还表示 Transformer 这个新模型的重要性不能被低估,也不能被夸大。
不过,英伟达一方面推出了专为 Transformer 设计的产品,同时也提供了一系列适合多种不同型号的产品,而且可能已经为新技术的出现做好了准备。尽管如此,硬件专业化仍存在锁定现代用例的风险,而不是启用新兴用例。
Chintala 对此表示,如果像英伟达这样的供应商将硬件定制得更适用于当前范式,那么其他想法将更难出头。
不止硬件,更多定制和特定于领域的技术不断出现,如谷歌的张量处理单元、Cerebras Wafer Scale 引擎等都被提出来,这进一步限制了其他技术的发展。
Chintala 还提到,最近一段时间,AI 圈一直流行着这样一种说法「PyTorch 在受欢迎程度上超越谷歌的 TensorFlow 」,对于这一结论,Chintala 是拒绝的。
Chintala 表示,PyTorch 不是为了抢走 TensorFlow 的「午餐」而诞生的,它们有各自的优点,这两种框架各自擅长不同的任务。在研究界,PyTorch 有很好的市场份额,但在其他领域,就很难说了。
不过,谷歌也意识到了 PyTorch 的威胁,他们悄悄地开发一个机器学习框架,JAX(曾是「Just After eXecution」的首字母缩写,但官方说法中不再代表任何东西),许多人将其视为 TensorFlow 的继承者。
曾一度有传言说谷歌大脑和 DeepMind 在很大程度上放弃了 TensorFlow,转而使用 JAX。谷歌很快出来打假,表示「我们继续开发 TensorFlow ,并将其作为一流的应用 ML 平台,与 JAX 并肩推动 ML 研究发展。」
至于 JAX,其擅长将复杂的机器学习任务分散到多个硬件上,极大地简化了现有工具,使其更容易管理日益庞大的机器学习问题。
Chintala 表示:「我们正在向 JAX 学习,我们也在 PyTorch 中添加了这些内容。显然,JAX 在某些方面做得更好。Pytorch 确实擅长很多事情,这就是它成为主流的原因,人们用它可以做很多事情。但作为主流框架并不意味着它可以覆盖所有内容。」
-----
上面提到了.DeepMind 这里仔细说瞎
强化学习发现矩阵乘法算法,DeepMind再登Nature封面推出AlphaTensor
DeepMind 的 Alpha 系列 AI 智能体家族又多了一个成员——AlphaTensor,这次是用来发现算法。
数千年来,算法一直在帮助数学家们进行基本运算。早在很久之前,古埃及人就发明了一种不需要乘法表就能将两个数字相乘的算法。希腊数学家欧几里得描述了一种计算最大公约数的算法,这种算法至今仍在使用。在伊斯兰的黄金时代,波斯数学家 Muhammad ibn Musa al-Khwarizmi 设计了一种求解线性方程和二次方程的新算法,这些算法都对后来的研究产生了深远的影响。
事实上,算法一词的出现,有这样一种说法:波斯数学家 Muhammad ibn Musa al-Khwarizmi 名字中的 al-Khwarizmi 一词翻译为拉丁语为 Algoritmi 的意思,从而引出了算法一词。不过,虽然今天我们对算法很熟悉,可以从课堂中学习、在科研领域也经常遇到,似乎整个社会都在使用算法,然而发现新算法的过程是非常困难的。
现在,DeepMind 用 AI 来发现新算法。
在最新一期 Nature 封面论文《Discovering faster matrix multiplication algorithms with reinforcement learning》中,DeepMind 提出了 AlphaTensor,并表示它是第一个可用于为矩阵乘法等基本任务发现新颖、高效且可证明正确的算法的人工智能系统。简单来说,使用 AlphaTensor 能够发现新算法。这项研究揭示了 50 年来在数学领域一个悬而未决的问题,即找到两个矩阵相乘最快方法。
-
论文地址 :https://www.nature.com/articles/s41586-022-05172-4
-
GitHub 地址:https://github.com/deepmind/alphatensor
AlphaTensor 建立在 AlphaZero 的基础上,而 AlphaZero 是一种在国际象棋、围棋和将棋等棋盘游戏中可以打败人类的智能体。这项工作展示了 AlphaZero 从用于游戏到首次用于解决未解决的数学问题的一次转变。
矩阵乘法
矩阵乘法是代数中最简单的运算之一,通常在高中数学课上教授。但在课堂之外,这种不起眼的数学运算在当代数字世界中产生了巨大的影响,在现代计算中无处不在。
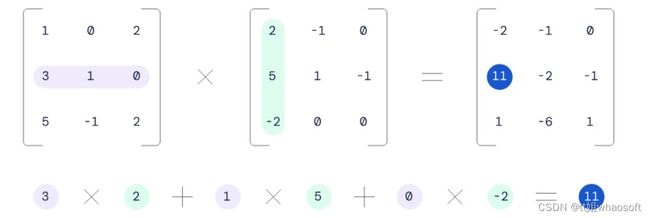
两个 3x3 矩阵相乘的例子。
你可能没注意到,我们生活中处处隐藏着矩阵相乘,如智能手机中的图像处理、识别语音命令、为电脑游戏生成图形等都有它在背后进行运算。遍布世界各地的公司都愿意花费大量的时间和金钱开发计算硬件以有效地解决矩阵相乘。因此,即使是对矩阵乘法效率的微小改进也会产生广泛的影响。
几个世纪以来,数学家认为标准矩阵乘法算法是效率最高的算法。但在 1969 年,德国数学家 Volken Strassen 通过证明确实存在更好的算法,这一研究震惊了整个数学界。

标准算法与 Strassen 算法对比,后者少进行了一次乘法运算,为 7 次,而前者需要 8 次,整体效率大幅提高。
通过研究非常小的矩阵(大小为 2x2),Strassen 发现了一种巧妙的方法来组合矩阵的项以产生更快的算法。之后数十年,研究者都在研究更大的矩阵,甚至找到 3x3 矩阵相乘的高效方法,都还没有解决。
DeepMind 的最新研究探讨了现代 AI 技术如何推动新矩阵乘法算法的自动发现。基于人类直觉(human intuition)的进步,对于更大的矩阵来说,AlphaTensor 发现的算法比许多 SOTA 方法更有效。该研究表明 AI 设计的算法优于人类设计的算法,这是算法发现领域向前迈出的重要一步。
算法发现自动化的过程和进展
首先将发现矩阵乘法高效算法的问题转换为单人游戏。其中,board 是一个三维度张量(数字数组),用于捕捉当前算法的正确程度。通过一组与算法指令相对应的所允许的移动,玩家尝试修改张量并将其条目归零。
当玩家设法这样做时,将为任何一对矩阵生成可证明是正确的矩阵乘法算法,并且其效率由将张量清零所采取的步骤数来衡量。
这个游戏非常具有挑战性,要考虑的可能算法的数量远远大于宇宙中原子的数量,即使对于矩阵乘法这样小的情况也是如此。与几十年来一直是人工智能挑战的围棋游戏相比,该游戏每一步可能的移动数量要多 30 个数量级(DeepMind 考虑的一种设置是 10^33 以上。)
为了解决这个与传统游戏明显不同的领域所面临的挑战,DeepMind 开发了多个关键组件,包括一个结合特定问题归纳偏置的全新神经网络架构、一个生成有用合成数据的程序以及一种利用问题对称性的方法。
接着,DeepMind 训练了一个利用强化学习的智能体 AlphaTensor 来玩这个游戏,该智能体在开始时没有任何现有矩阵乘法算法的知识。通过学习,AlphaTensor 随时间逐渐地改进,重新发现了历史上的快速矩阵算法(如 Strassen 算法),并且发现算法的速度比以往已知的要快。
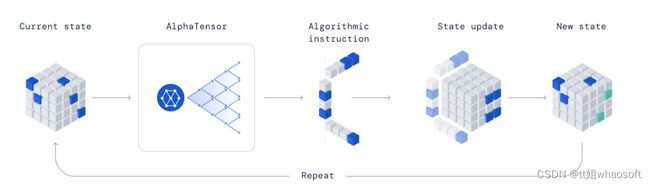
AlphaTensor 玩的单人游戏,目标是找到正确的矩阵乘法算法。游戏状态是一个由数字组成的立方数组(灰色表示 0,蓝色表示 1,绿色表示 - 1),它代表了要完成的剩余工作。
举例而言,如果学校里教的传统算法可以使用 100 次乘法完成 4x5 与 5x5 矩阵相乘,通过人类的聪明才智可以将这一数字降至 80 次。与之相比,AlphaTensor 发现的算法只需使用 76 次乘法即可完成相同的运算,如下图所示。


除了上述例子之外,AlphaTensor 发现的算法还首次在一个有限域中改进了 Strassen 的二阶算法。这些用于小矩阵相乘的算法可以当做原语来乘以任意大小的更大矩阵。
AlphaTensor 还发现了具有 SOTA 复杂性的多样化算法集,其中每种大小的矩阵乘法算法多达数千,表明矩阵乘法算法的空间比以前想象的要丰富。
在这个丰富空间中的算法具有不同的数学和实用属性。利用这种多样性,DeepMind 对 AlphaTensor 进行了调整,以专门发现在给定硬件(如 Nvidia V100 GPU、Google TPU v2)上运行速度快的算法。这些算法在相同硬件上进行大矩阵相乘的速度比常用算法快了 10-20%,表明了 AlphaTensor 在优化任意目标方面具备了灵活性。
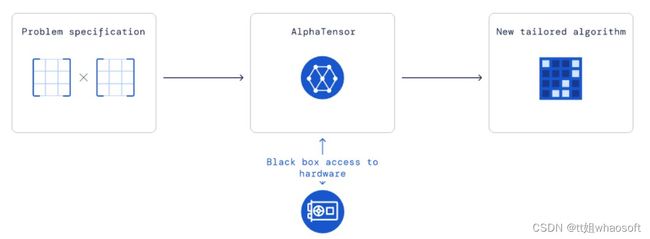
AlphaTensor 具有一个对应于算法运行时的目标。当发现正确的矩阵乘法算法时,它会在指定硬件上进行基准测试,然后反馈给 AlphaTensor,以便在指定硬件上学习更高效的算法。
对未来研究和应用的影响
从数学的角度来看,对于旨在确定解决计算问题的最快算法的复杂性理论而言,DeepMind 的结果可以指导它的进一步研究。通过较以往方法更高效地探索可能的算法空间,AlphaTensor 有助于加深我们对矩阵乘法算法丰富性的理解。
此外,由于矩阵乘法是计算机图形学、数字通信、神经网络训练和科学计算等很多计算任务的核心组成部分,AlphaTensor 发现的算法可以显著提升这些领域的计算效率。
虽然本文只专注于矩阵乘法这一特定问题,但 DeepMind 希望能够启发更多的人使用 AI 来指导其他基础计算任务的算法发现。并且,DeepMind 的研究还表明,AlphaZero 这种强大的算法远远超出了传统游戏的领域,可以帮助解决数学领域的开放问题。
未来,DeepMind 希望基于他们的研究,更多地将人工智能用来帮助社会解决数学和科学领域的一些最重要的挑战。