一份互联网大厂的消息中间件生产技术方案总结,快收藏!
目录:
- 前情回顾
- 基于消息中间件的队列消费模型
- 基于消息中间件的“Pub/Sub”模型
- RabbitMQ中的exchange到底是个什么东西?
- 默认的exchange
- 将消息投递到fanout exchange
- 绑定自己的队列到exchange上
- 整体架构图
1、前情回顾
上一篇文章:《给你一份精心设计的消息中间件高扩展架构,赶紧写进简历吧!》,我们分析了如何利用消息中间件对两系统进行解耦处理。
同时,我们也提到了,使用消息中间件还有利于一份数据被多个系统同时订阅,供多个系统用于不同目的。
目前的一个架构如下图所示。

在这个图里,我们可以清晰的看到,实时计算平台发布的一份数据到消息中间件里,然后接下来:
- 数据查询平台会订阅这份数据,并落入自己本地的数据库集群和缓存集群里,接着对外提供数据查询的服务
- 数据质量监控系统会对计算结果按照一定的业务规则进行监控,如果发现有数据计算错误,则会立马进行报警
- 数据链路追踪系统会采集计算结果作为一个链路节点,同时对一条数据的整个计算链路都进行采集并组装出来一系列的数据计算链路落地存储,最后如果某个数据计算错误了,就可以立马通过计算链路进行回溯排查问题
通过以上回顾,我们已经清楚,在上述场景中,使用消息中间件一来可以解耦,二来可以实现消息“Pub/Sub”模型,实现消息的发布与订阅。
这篇文章,咱们就来落地实践一把,基于RabbitMQ消息中间件,如何实现一份数据被多个系统同时订阅的“Pub/Sub”模型?
2、基于消息中间件的队列消费模型

上图其实就是采用的RabbitMQ最基本的队列消费模型的支持,你可以理解为RabbitMQ内部有一个队列,生产者不断的发送数据到队列里,消息按照先后顺序进入队列中排队。
现在假设队列里有4条数据,我们有2个消费者一起消费这个队列的数据。
此时每个消费会均匀的分配到2条数据,也就是说4条数据会均匀的分配给各个消费者,每个消费者只不过是处理一部分数据罢了,这个就是典型的队列消费模型。
ps:如果有同学对基于RabbitMQ如何实现还不太清楚,可以参考之前的一些文章:
- 《RabbitMQ是如何收发消息的?(通俗易懂)》
- 《车祸现场!线上突然宕机,一条订单消息丢失了…》
- 《RabbitMQ宕机后,消息100%不会丢失吗》
这几篇文章给出了上述那个最基本的队列消费模型的RabbitMQ代码实现,以及如何保证消费者宕机时数据不丢失,如何让RabbitMQ集群对queue和message都进行持久化,整体代码实现比较完整,可以参考一下。
3、基于消息中间件的“Pub/Sub”模型
除了上述的基本模型外,消息中间件还可以实现一种“Pub/Sub”模型,也就是“发布/订阅”模型,Pub就是Publish,Sub就是Subscribe。
这种模型可以支持多个系统同时消费一份数据,也就是说你发布出去的每条数据,都会广播给每个系统,看下图:
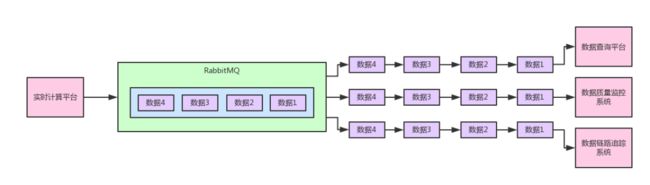
也就是说,我们想要实现的上图的效果:实时计算平台发布一系列的数据到消息中间件里,然后数据查询平台、数据质量监控系统、数据链路追踪系统,都会订阅数据,都会消费到同一份完整的数据,每个系统都可以根据自己的需要使用数据。
那么这个所谓的“Pub/Sub”模型,基于RabbitMQ应该怎么来处理呢?
4、RabbitMQ中的exchange到底是个什么东西?
实际上,在RabbitMQ里面是不允许生产者直接投递消息到某个queue(队列)里的,而是只能让生产者投递消息给RabbitMQ内部的一个特殊组件,叫做“exchange”,你大概可以理解为一种消息路由组件。
也就是说,实时计算平台发送出去的message到RabbitMQ中都是由一个exchange来接收的。
然后这个exchange会根据一定的规则决定要将这个message路由转发到哪个queue里去,这实际上就是RabbitMQ中的一个核心的消息模型。
大家看下面的图来理解一下。
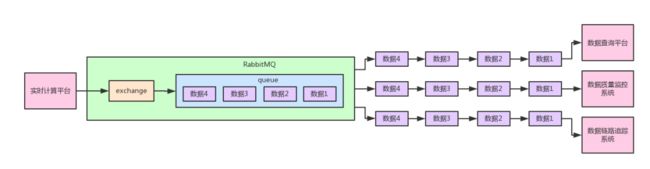
5、默认的exchange
你也许会说,我投递消息到RabbitMQ的时候,也没有用什么exchange,但是为什么还是把消息投递到了queue里去呢?
那是因为你使用了默认的exchange,他会直接把消息路由到你指定的那个queue里去,所以如果简单用队列消费模型,就省去了exchange的概念。

上面这段就是之前给大家展示的,让消息持久化的一种投递消息的方式。
大家注意里面的第一个参数,是一个空的字符串,这个空字符串的意思,就是说投递消息到默认的exchange里去,然后他就会路由消息到我们指定的queue里去。
6、将消息投递到fanout exchange
在RabbitMQ里,exchange这种组件有很多种类型,比如说:direct、topic、headers以及fanout,本文我们来看最后一种fanout。
这种exchange组件其实非常的简单,你可以创建一个fanout类型的exchange,然后给这个exchange绑定多个queue,接着只要你投递一条消息到这个exchange,他就会把消息路由给他绑定的所有queue。
使用下面的代码就可以创建一个exchange,比如说在实时计算平台(生产者)的代码里,可以加入下面的一段,创建一个fanout类型的exchange。
第一个参数我们叫做“rt_compute_data”,这个就是exchange的名字,rt就是“RealTime”的缩写,意思就是实时计算系统的计算结果数据。
第二个参数就是定义了这个exchange的类型是“fanout”。
channel.exchangeDeclare(“rt_compute_data”, “fanout”);
接着我们就采用下面的代码来投递消息到我们创建好的exchange组件里去:
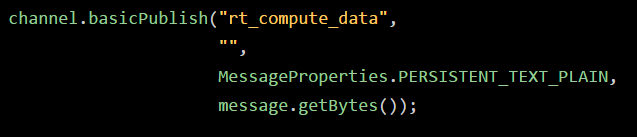
大家会注意到,此时消息就是投递到指定的exchange里去了,但是路由到哪个queue里去呢?此时我们暂时还没确定,要让消费者自己把自己的queue绑定到这个exchange上去才可以。
7、绑定自己的队列到exchange上
对消费者的代码也进行修改,之前我们在这里关闭了autoAck机制,然后每次都是自己手动ack。
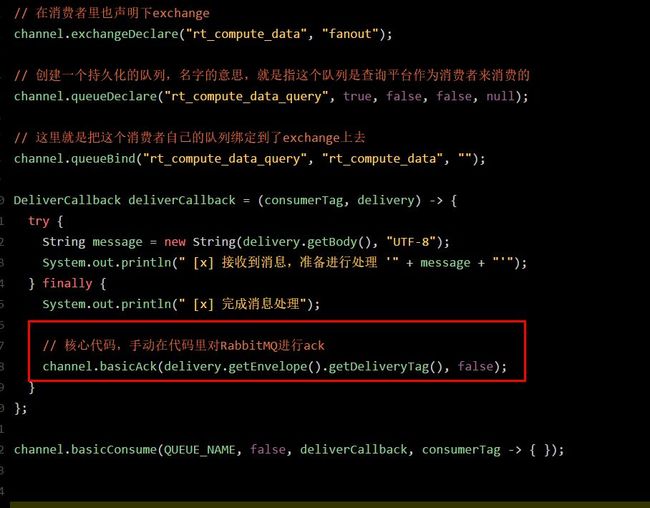
上面的代码里,每个消费者系统,都会有一些不一样,就是每个消费者都需要定义自己的队列,然后绑定到exchange上去。
比如说数据查询平台的队列是“rt_compute_data_query”,数据质量监控平台的队列是“rt_compute_data_monitor”,数据链路追踪系统的队列是“rt_compute_data_link”。
这样每个订阅这份数据的系统其实都有一个属于自己的队列,然后队列里被会被exchange路由进去实时计算平台生产的所有数据。
而且因为是多个队列的模式,每个系统都可以部署消费者集群来进行数据的消费和处理,非常的方便。
8、整体架构图

如上图所示,实时计算平台会投递消息到“rt_compute_data”这个“exchange”里去,但是他没指定这个exchange要路由消息到哪个队列,因为这个他本身是不知道的。
接着数据查询平台、数据质量监控系统、数据链路追踪系统,就可以声明自己的队列,都绑定到exchange上去。
因为queue和exchange的绑定,在这里是由要订阅数据的平台自己指定的。而且因为这个exchange是fanout类型的,他只要接收到了数据,就会路由数据到所有绑定到他的队列里去,这样每个队列里都有同样的一份数据,供对应的平台来消费。
而且针对每个平台自己的队列,自己还可以部署消费服务集群来消费自己的一个队列,自己的队列里的数据还是会均匀分发给各个消费服务实例来处理,每个消费服务实例会获取到一部分的数据。
这样是不是就实现了不同的系统订阅一份数据的“Pub/Sub”的模型?
当然,RabbitMQ还支持各种不同类型的exchange,可以实现各种复杂的功能,后续我们再来给大家通过实际的线上系统架构案例,来阐述消息中间件技术的用法。
另外推荐儒猿课堂的1元系列课程给您,欢迎加入一起学习~
互联网Java工程师面试突击课(1元专享)
SpringCloudAlibaba零基础入门到项目实战(1元专享)
亿级流量下的电商详情页系统实战项目(1元专享)
Kafka消息中间件内核源码精讲(1元专享)
12个实战案例带你玩转Java并发编程(1元专享)
Elasticsearch零基础入门到精通(1元专享)
基于Java手写分布式中间件系统实战(1元专享)
基于ShardingSphere的分库分表实战课(1元专享)