ElasticSearch入门教程(1)
目录
1.1ElasticSearch是什么?
2.1Elasticsearch安装
2.1.1 下载软件
2.2.2使用Postman客户端工具
2.2.3数据格式
正(排)向索引
倒排索引
2.2.4.1基本使用
(1)创建索引
(2)获取索引
(3)删除索引
2.2.4.2 文档操作
(1)添加文档数据
(2)查询文档数据
(3)修改文档数据(全量修改和局部修改)
局部数据的修改
(4)条件查询&分页查询
条件查询
分页查询
排序和隐藏
(5)多条件查询&范围查询(难点)
多条件查询
范围查询
(6)全文检索&完全匹配&高亮查询
(7)聚合查询
(8)映射关系
1.1ElasticSearch是什么?
ElasticSearch是一个分布式,RestFul风格的搜索和数据分析的引擎,能够解决不断涌出的各种用例。作为Elastic Stack的核心,他集中存储您的数据,帮助您发现意料之中以及医疗之外的情况。
The Elastic Stack,包括Elasticsearch,Kibana,Beats和Logstash(也好吃能为ELK Stack),能够安全可靠的获取任何来源,任何格式的数据,然后实时的对数据进行搜索,分析和可视化。ElasticSearch简称ES,是一个开源的高扩展的分布式全文搜索引擎,是整个Elastic Stack技术栈的核心,他可以实时存储,检索数据,本身扩展性很好,可以扩展到上百台服务器,处理OB级别的数据。
2.1Elasticsearch安装
2.1.1 下载软件
ElasticSearch的官网地址:https://www.elastic.co/cn/
我们选择7.8.0版本(主要学习es和java客户端的使用)
解压后,进入bin文件夹目录,点击elasticsearch.bat启动ES服务
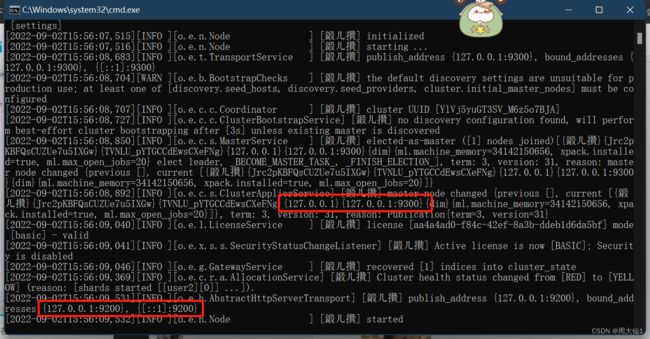
注意:9300端口号为ES集群之间组件的通信端口,9200端口为浏览器访问http协议的Restful端口
打开浏览器,输入http://localhost:9200
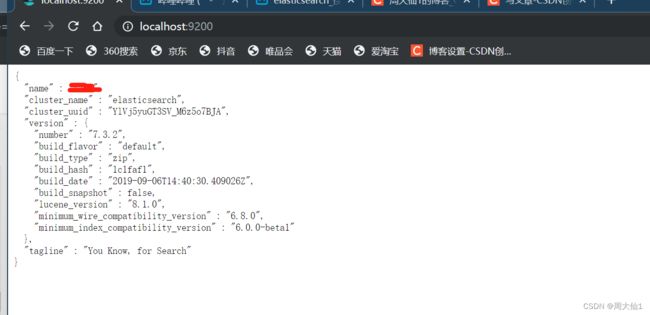
如何所示,es启动成功
可能会出现的错误:
1.es是使用java开发的,且7.8版本es需要jdk为1.8版本以上,默认安装包带有jdk环境,如果系统配置饿了JAVA_HOME,那么使用系统默认的JDK。
2.双击闪退-----可能是因为空间不足,修改config/jvm.options配置文件

2.2.2使用Postman客户端工具
如果直接通过浏览器向ES服务器发送请求,name需要在发送的请求中包含HTPP的标准方法,而HTTP大部分特性仅支持GET和POST,所以为了方便,使用Postman软件
Postman官网: https://www.getpostman.com
2.2.3数据格式
ES是面向文档型数据库,一条数据在这里就是一个文档,为了方便大家理解,我们将ES里存储文档数据和Mysql存储数据的概念进行一个类比

ES里的Index可以看做一个数据库,Type相当于表,Documents相当于行,Fields相当于列
正(排)向索引
id content
-----------------------------
1001 my name is zhang san
1002 my name is li si
根据文章编号,能够快速查询到文章内容。文章编号为主键
当需要查到文章内容包含zhang san 时,需要用到模糊查询,大小写问题,这种情况正向索引的效率就慢了很多。场景比如(百度上搜zhang san),这个时候倒排索引出现了
倒排索引
keyword id
---------------------------------
name 1001,1002
zhang 1001
li 1002
正向索引是根据id跟内容绑定,倒排索引是关键字和id绑定,再去查文章内容。上结构中name在序号为1001和1002的文章内容中都出现过,所以下面以此类推.统称为倒排索引,查询效率相对较快,表的作用已经弱化了。
2.2.4.1基本使用
(按我的理解:这种使用就是个入门,当个字典翻翻就可以)
(1)创建索引
对比Mysql中,创建索引就等于创建数据库
在postman中,向ES服务器发送PUT请求:http://127.0.0.1:9200/shopping
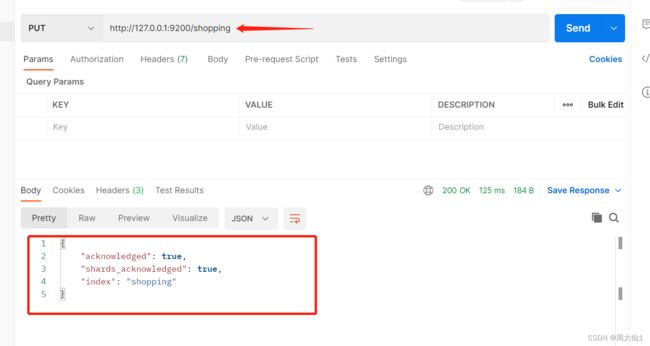
如果再次创建,同名就会报错。shopping已经存在了

(2)获取索引
只需要把请求方式变为GET

如果想展示出所有的索引信息,修改urlhttp://127.0.0.1:9200/_cat/indices?v

我这边两个索引,user2和shopping
(3)删除索引
请求方式改为DELETE,url为:http://127.0.0.1:9200/shopping

后续可以去验证一下是否删除成功.
2.2.4.2 文档操作
(1)添加文档数据
请求方法为POST. http://127.0.0.1:9200/shopping/_doc
_doc表示给索引中添加文档数据。文档数据的请求体不能为空(请求体里面就是添加的数据,如果数据都没有肯定报错),添加的数据以json串形式

可以自定义上面图中的返回值_id.请求url修改为: http://127.0.0.1:9200/shopping/_doc/1001

(2)查询文档数据
只需要改为GET请求
http://127.0.0.1:9200/shopping/_doc/1001 查询id为1001的文档数据
如果想查询shopping索引下的所有文档数据
http://127.0.0.1:9200/shopping/_search
(3)修改文档数据(全量修改和局部修改)
比如我全量修改上面id为1001的数据
http://127.0.0.1:9200/shopping/_doc/1001
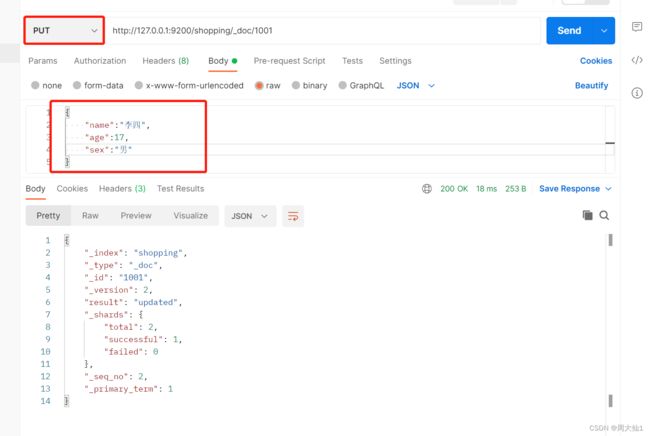
这个时候,1001的数据全被修改了。小伙伴们可以去验证一下,不展示了。
局部数据的修改
请求为POST http://127.0.0.1:9200/shopping/_update/1001 _doc改为update,不然服务器以为我们要新增数据
局部数据修改,所以请求体中,改哪个写哪个。删除的话,大家自己按着这个思路走就行了

(4)条件查询&分页查询
条件查询
请求为GET http://127.0.0.1:9200/shopping/_search?q=name:张三
其中q的意思为query查询。查询索引中所有文档name为张三的信息

条件查询有一个弊端,url中'张三'容易乱码,所以请求参数写在请求体里面

其中url后面的参数不要,请求体中的参数 query为查询,match为匹配。匹配的是name为张三的数据,这样就容易理解了。
分页查询
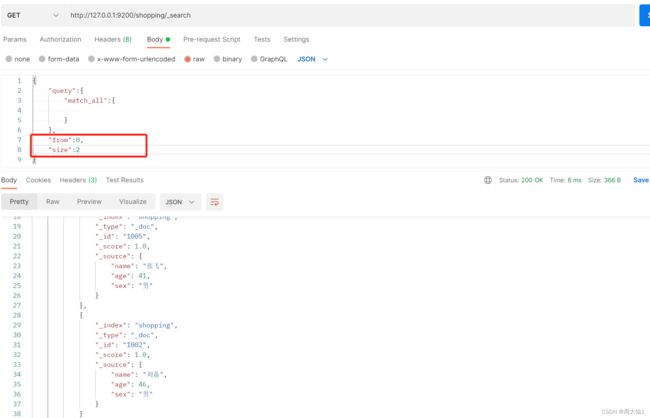
其中,size是每页2条数据,from后面的值有一个公式。从第几页开始:(页数-1)*每页几条数据
比如从1页开始 from : 0
2页 from : 2
3页 from : 4
排序和隐藏

其中,_source后面表示我只需要显式name字段,其他字段就隐藏了。sort表示排序,json串是根据哪个字段---age,age内是升序降序。最终的结果

(5)多条件查询&范围查询(难点)
多条件查询

query:查询,bool:多个条件,must:等于sql语句中的and,两者都。(should表示sql中的or),match:匹配
用mysql:select * from 表名 where name ="张三" and sex ="男"
结果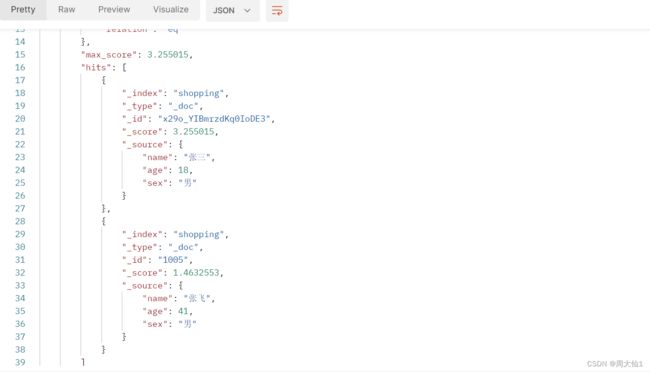
结果出现两条,张飞也出来了,百思不得其解。这时候想起来可能和倒排索引,分词那块有关系,我又把name换成 "三",只出来一个"张三"这一条数据,又将name换成了"飞三",张飞和张三都查出来了。有点类似于模糊查询了.后来才知道,想要完全匹配match改成match_phrase
范围查询
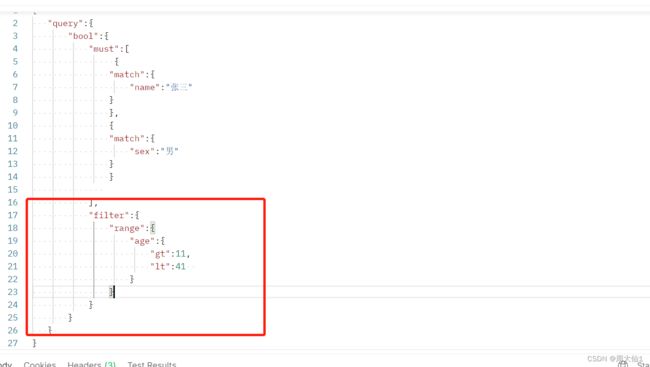
filter:过滤,range:范围 gt:大于 lt:小于
等价于 select ........from where .......... and age>11 and age<41,下图是结果

(6)全文检索&完全匹配&高亮查询


highlight就是高亮查询,查询出来的结果就是em标签体那栏
(7)聚合查询
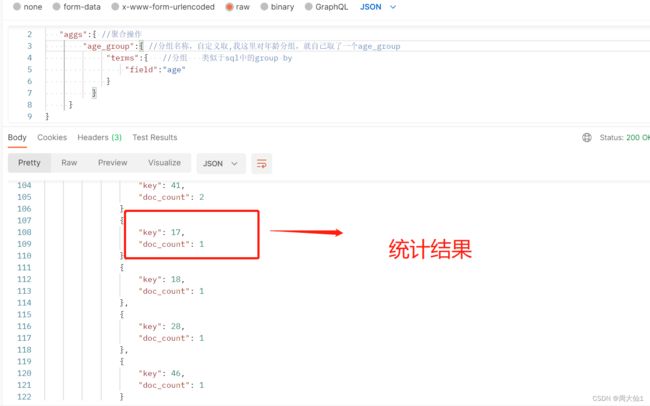
不仅可以分组,求年龄的平均值也可以

(8)映射关系
ES的映射关系类似于Mysql中表结构,字段长度等等信息。比如我们有时候查询一个name:"飞三" 会出现张飞和张三,可以设置ES的配置信息,控制分词效果。
先创建索引user

给user添加配置信息
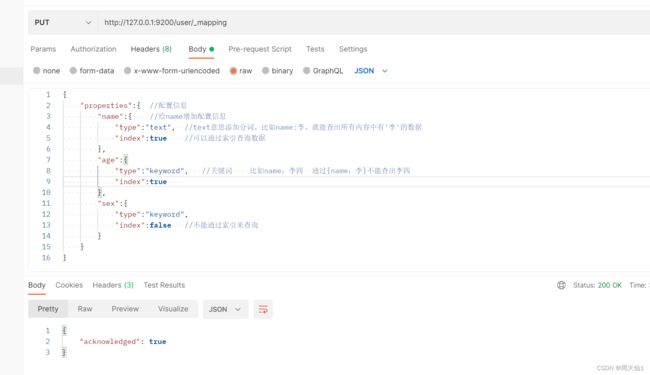
添加数据..........
测试结果1: type:text生效。index:true生效

测试结果2: type:keyword 生效 index 生效

测试结果3: index:false 生效,不能根据索引去查询性别字段数据

最后感兴趣的小伙伴们可以去仔细了解一下倒排索引和分词。看一下上面mysql和es的对照表。就容易理解了