前言
本文围绕这三个话题来学习索引下推:
SELECT语句执行过程- 什么是索引下推?
- 索引下推限制
SELECT 语句执行过程
MySQL 数据库由 Server 层和 Engine 层组成:
Server层: 有SQL分析器、SQL优化器、SQL执行器,用于负责SQL语句的具体执行过程。Engine层: 负责存储具体的数据,如最常使用的InnoDB存储引擎,还有用于在内存中存储临时结果集的TempTable引擎。
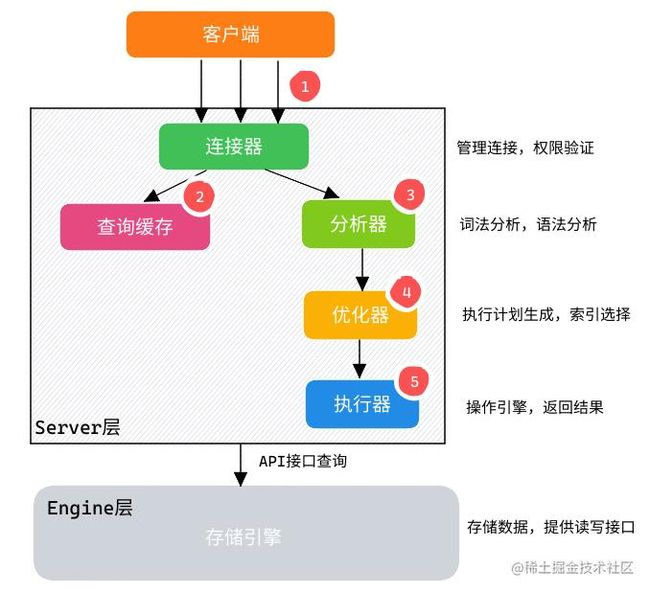
通过客户端/服务器通信协议与
MySQL建立连接。查询缓存:
- 如果开启了
Query Cache且在查询缓存过程中查询到完全相同的SQL语句,则将查询结果直接返回给客户端; - 如果没有开启
Query Cache或者没有查询到完全相同的SQL语句则会由解析器进行语法语义解析,并生成解析树。
- 如果开启了
分析器生成新的解析树。
查询优化器生成执行计划。
查询执行引擎执行
SQL语句,此时查询执行引擎会根据SQL语句中表的存储引擎类型,以及对应的API接口与底层存储引擎缓存或者物理文件的交互情况,得到查询结果,由MySQL Server过滤后将查询结果缓存并返回给客户端。若开启了
Query Cache,这时也会将SQL语句和结果完整地保存到Query Cache中,以后若有相同的SQL语句执行则直接返回结果。
Tips:MySQL 8.0 已去掉 query cache(查询缓存模块)。
因为查询缓存的命中率会非常低。 查询缓存的失效非常频繁:只要有对一个表的更新,这个表上所有的查询缓存都会被清空。
什么是索引下推?
索引下推(Index Condition Pushdown): 简称 ICP,通过把索引过滤条件下推到存储引擎,来减少 MySQL 存储引擎访问基表的次数 和 MySQL 服务层访问存储引擎的次数。
索引下推 VS 覆盖索引: 其实都是 减少回表的次数,只不过方式不同
覆盖索引: 当索引中包含所需要的字段(
SELECT XXX),则不再回表去查询字段。索引下推: 对索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表的行数。
要了解 ICP 是如何工作的,先从一个查询 SQL 开始:
举个栗子:查询名字 la 开头、年龄为 18 的记录
SELECT * FROM user WHERE name LIKE 'la%' AND age = 18;
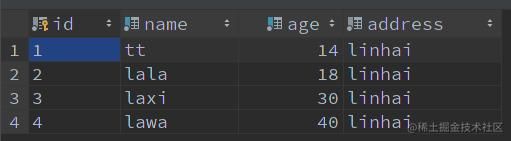
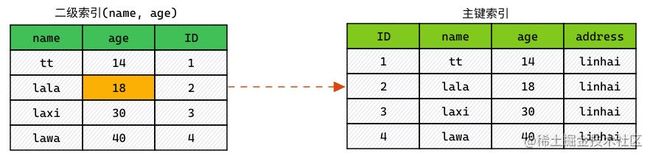
有这些记录:
不开启 ICP 时索引扫描是如何进行的:
- 通过索引元组,定位读取对应数据行。(实际上:就是回表)
- 对
WHERE中字段做判断,过滤掉不满足条件的行。
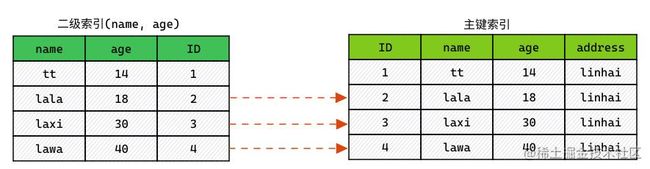
使用 ICP,索引扫描如下进行:
- 获取索引元组。
- 对
WHERE中字段做判断,在索引列中进行过滤。 - 对满足条件的索引,进行回表查询整行。
- 对
WHERE中字段做判断,过滤掉不满足条件的行。
动手实验:
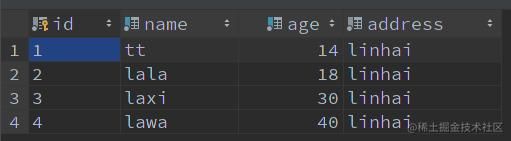
实验:使用 MySQL 版本 8.0.16
-- 表创建 CREATE TABLE IF NOT EXISTS `user` ( `id` VARCHAR(64) NOT NULL COMMENT '主键 id', `name` VARCHAR(50) NOT NULL COMMENT '名字', `age` TINYINT NOT NULL COMMENT '年龄', `address` VARCHAR(100) NOT NULL COMMENT '地址', PRIMARY KEY (id) ) ENGINE=InnoDB DEFAULT CHARSET utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT '用户表'; -- 创建索引 CREATE INDEX idx_name_age ON user (name, age); -- 新增数据 INSERT INTO user (id, name, age, address) VALUES (1, 'tt', 14, 'linhai'); INSERT INTO user (id, name, age, address) VALUES (2, 'lala', 18, 'linhai'); INSERT INTO user (id, name, age, address) VALUES (3, 'laxi', 30, 'linhai'); INSERT INTO user (id, name, age, address) VALUES (4, 'lawa', 40, 'linhai'); -- 查询语句 SELECT * FROM user WHERE name LIKE 'la%' AND age = 18;
新增数据如下:
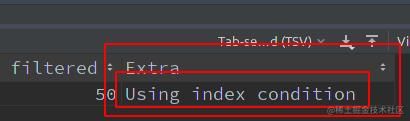
- 关闭
ICP,再调用EXPLAIN查看语句:
-- 将 ICP 关闭 SET optimizer_switch = 'index_condition_pushdown=off'; -- 查看确认 show variables like 'optimizer_switch'; -- 用 EXPLAIN 查看 EXPLAIN SELECT * FROM user WHERE name LIKE 'la%' AND age = 18;

- 开启
ICP,再调用EXPLAIN查看语句:
-- 将 ICP 打开 SET optimizer_switch = 'index_condition_pushdown=on'; -- 查看确认 show variables like 'optimizer_switch'; -- 用 EXPLAIN 查看 EXPLAIN SELECT * FROM user WHERE name LIKE 'la%' AND age = 18;
![]()
由上实验可知,区别是否开启 ICP: Exira 字段中的 Using index condition
更进一步,来看下 ICP 带来的性能提升:
通过访问数据文件的次数
-- 1. 清空 status 状态 flush status; -- 2. 查询 SELECT * FROM user WHERE name LIKE 'la%' AND age = 18; -- 3. 查看 handler 状态 show status like '%handler%';
对比开启 ICP 和 关闭 ICP: 关注 Handler_read_next 的值
-- 开启 ICP flush status; SELECT * FROM user WHERE name LIKE 'la%' AND age = 18; show status like '%handler%'; +----------------------------|-------+ | Variable_name | Value | +----------------------------|-------+ | Handler_commit | 1 | | Handler_delete | 0 | | Handler_discover | 0 | | Handler_external_lock | 2 | | Handler_mrr_init | 0 | | Handler_prepare | 0 | | Handler_read_first | 0 | | Handler_read_key | 1 | | Handler_read_last | 0 | | Handler_read_next | 1 | <---重点 | Handler_read_prev | 0 | | Handler_read_rnd | 0 | | Handler_read_rnd_next | 0 | | Handler_rollback | 0 | | Handler_savepoint | 0 | | Handler_savepoint_rollback | 0 | | Handler_update | 0 | | Handler_write | 0 | +----------------------------|-------+ 18 rows in set (0.00 sec) -- 关闭 ICP flush status; SELECT * FROM user WHERE name LIKE 'la%' AND age = 18; show status like '%handler%'; +----------------------------|-------+ | Variable_name | Value | +----------------------------|-------+ | Handler_commit | 1 | | Handler_delete | 0 | | Handler_discover | 0 | | Handler_external_lock | 2 | | Handler_mrr_init | 0 | | Handler_prepare | 0 | | Handler_read_first | 0 | | Handler_read_key | 1 | | Handler_read_last | 0 | | Handler_read_next | 3 | <---重点 | Handler_read_prev | 0 | | Handler_read_rnd | 0 | | Handler_read_rnd_next | 0 | | Handler_rollback | 0 | | Handler_savepoint | 0 | | Handler_savepoint_rollback | 0 | | Handler_update | 0 | | Handler_write | 0 | +----------------------------|-------+ 18 rows in set (0.00 sec)
由上实验可知:
- 开启
ICP:Handler_read_next等于 1,回表查 1 次。 - 关闭
ICP:Handler_read_next等于 3,回表查 3 次。
这实验跟上面的栗子就对应上了。
索引下推限制
根据官网可知,索引下推 受以下条件限制:
当需要访问整个表行时,
ICP用于range、ref、eq_ref和ref_or_nullICP可以用于InnoDB和MyISAM表,包括分区表InnoDB和MyISAM表。对于
InnoDB表,ICP仅用于二级索引。ICP的目标是减少全行读取次数,从而减少I/O操作。对于InnoDB聚集索引,完整的记录已经读入InnoDB缓冲区。在这种情况下使用ICP不会减少I/O。在虚拟生成列上创建的二级索引不支持
ICP。InnoDB支持虚拟生成列的二级索引。引用子查询的条件不能下推。
引用存储功能的条件不能被按下。存储引擎不能调用存储的函数。
触发条件不能下推。
不能将条件下推到包含对系统变量的引用的派生表。(
MySQL 8.0.30及更高版本)。
小结下:
ICP仅适用于 二级索引。ICP目标是 减少回表查询。ICP对联合索引的部分列模糊查询非常有效。
拓展:虚拟列
CREATE TABLE UserLogin ( userId BIGINT, loginInfo JSON, cellphone VARCHAR(255) AS (loginInfo->>"$.cellphone"), PRIMARY KEY(userId), UNIQUE KEY idx_cellphone(cellphone) );
列 cellphone :就是一个虚拟列,它是由后面的函数表达式计算而成,本身这个列不占用任何的存储空间,而索引 idx_cellphone 实质是一个函数索引。
好处: 在写 SQL 时可以直接使用这个虚拟列,而不用写冗长的函数。
举个栗子: 查询手机号
-- 不用虚拟列 SELECT * FROM UserLogin WHERE loginInfo->>"$.cellphone" = '13988888888' -- 使用虚拟列 SELECT * FROM UserLogin WHERE cellphone = '13988888888'
总结
到此这篇关于MySQL索引下推的文章就介绍到这了,更多相关MySQL索引下推内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!