竞赛获奖系统解读:VPC2022语音隐私保护赛NWPU-ASLP说话人匿名化系统
语音隐私保护竞赛(VoicePrivacy Challenge, VPC)始于2020年,旨在为语音技术研发隐私保护解决方案,促进匿名化和假名化解决方案的发展,这些解决方案旨在抑制语音中包含的个人身份信息,同时保留语言内容、音质和自然度。VPC竞赛具有通用数据集、严格的规则和评估排名指标,成为语音隐私保护技术的国际基准。第二届VPC竞赛于2022年3月开始,参赛者的任务是开发满足以下要求的说话人匿名(speaker anonymization)系统:(a)输出语音waveform;(b)隐瞒说话人的身份;(c)保持语言内容和副语言属性不变;(d)确保来自给定说话人的所有数据均由同一个虚假说话人发出,而来自不同说话人的测试语音由不同的虚假说话人发出。
ASLP实验室多位同学组队参加了竞赛,提交了说话人匿名化系统。最终竞赛结果发布于9月23-24日INTERSPEECH2022语音通信安全和隐私研讨会,实验室提交系统在官方四个条件(condition)指标上均取得了第一名,姚继珣博士研究生在研讨会上在线宣读了提交系统的系统描述论文。
具体竞赛信息请访问竞赛官网:
https://www.voiceprivacychallenge.org/

图1 姚继珣同学在研讨会上讲解实验室提交竞赛的方案
本届VPC竞赛关注在特定场景下语音数据的隐私保护,其中包括(1)数据类型:waveform;(2)敏感个人信息,包括:说话人身份,特征,所处环境等;(3)下游任务场景:语音交流,模型训练等;(4)攻击者可访问的数据:未被保护数据、半保护数据,完全保护数据;(5)攻击者的先验知识:隐私保护方法、原始数据等。从用户和攻击者的角度出发,不同场景下需要不同的隐私保护方法。VPC竞赛假定用户需要最大程度保护自己隐私数据,同时允许实现所需的下游目标;而攻击者则专注于利用不同场景下的数据识别用户的身份。
在本次竞赛中,我们提出了一种不涉及额外的声纹识别(ASV)模型或和x-vector池的匿名方法。该系统由四个模块组成,包括特征提取器、声学模型、匿名化模块和神经声码器。首先,特征提取器从输入语音信号中提取语音后验图 (PPG) 和基频。而后,我们在说话人查找表 (LUT) 中保留一个伪说话人ID,将其输入说话人编码器生成不对应于任何真实说话人的伪说话人向量。为了确保伪说话人是可区分的,我们使用将随机选择的说话人向量与伪说话人向量加权平均,生成最终的匿名说话人向量。综合上述方法,提交系统(T11)在此次竞赛的四个条件(condition)上均取得了第一名,在WER指标上明显优于基线系统,如图2所示。

图2 VPC2022竞赛官方公布的竞赛结果(在满足4个不同EER区间条件的同时,WER越低越好)
论文题目:NWPU-ASLP System for the VoicePrivacy 2022 Challenge
作者列表:姚继珣,王晴,张丽,郭鹏程,梁宇颢,谢磊
论文链接:https://arxiv.org/pdf/2209.11969.pdf

图3 竞赛系统描述论文截图
1. 背景动机
由于虚拟助手、语音通信和语音支付的出现,互联网上的语音数据呈指数级增长。这类应用将个人数据发送到集中服务器存储和处理。然而,语音数据中包含丰富的个人敏感信息,可能被识别系统获取和攻击,其中包括例如年龄、性别、健康状况和宗教信仰等。因此,随着欧盟通用数据保护条例(GDPR)等新法规的出台,如何加强对个人隐私数据的保护,抑制说话人的身份信息泄露的同时保持语言内容不变成为一个亟待解决的问题。
说话人匿名化(speaker anonymization)是一种有效保护个人隐私的技术。大多数匿名化方法的灵感来自基于x-vector的平均匿名化策略及其扩展。这些方法依赖于额外的ASV模型或x-vector池,并增加匿名说话人向量的类内距离。与上述方法不同,我们的系统不涉及额外的ASV模型或x-vector池,这也降低了可能由ASV模型泛化性不足带来的风险以及匿名化的计算复杂度。我们提出的方法使用说话人编码器生成的两种说话人向量加权得到,一种是由保留的伪说话人ID生成的伪说话人向量,可以确保匿名结果不对应于任何真实说话人;另一种是对随机选择的说话人向量进行平均。

图4 个人敏感信息
2. NWPU-ASLP匿名化系统
如图5所示,我们的匿名化系统是一个具有匿名化模块的语音转换(voice conversion)系统,由四个模块组成:特征提取、声学模型、匿名化模块和声码器。特征提取模块从输入语音中提取基频(F0)、PPG和说话人ID。声学模型将F0、PPG和匿名化说话人向量转换为梅尔谱,最后由声码器生成语音。

图5 NWPU-ASLP说话人匿名系统框架
我们的匿名化方法结合平均说话人向量和伪说话人向量产生最终的匿名向量。在训练过程中,所有训练数据的说话人ID都存储在查找表(LUT)中,用作说话人向量池。从LUT中随机选择K个说话人向量平均得到平均说话人向量。在我们的匿名策略中,平均说话人向量类似于从x-vector池中随机选择的一组x-vector进行平均,但是我们的方法不需要x-vector池,LUT就相当于x-vector池的作用。LUT中保留了一个伪说话人ID,它与训练数据中的任何真实说话人均不对应。这意味着伪说话人ID不参与模型的训练优化,真实说话人ID和伪说话人ID在推理过程中会产生不同的说话人向量分布。最后,平均说话人向量和伪说话人向量加权生成最终的匿名向量,作为语音转换模型的条件。平均说话人向量是为了保证来自特定说话人的每条语音由相同的伪说话人产生,而来自不同说话人的语音由不同的伪说话人产生。
3. 实验
本届VPC竞赛的排名主要关注两个指标:作为隐私保护的指标的等说话人错误率(EER)和作为主要效用的指标——词错误率(WER)。用于验证的基础ASV和ASR系统在LibriSpeech-train-clean-360上进行训练,并在LibriSpeech-train-clean的语句级匿名数据上进行微调。为了权衡隐私和效用,根据最小目标EER指标将结果分为四个条件,给定EER条件下的WER指标越低,匿名系统的效果就越好。四个最小目标EER条件是15%、20%、25%和30%,图6示意了在四个EER条件下不同系统的排名。竞赛数据集构成如表1所示。
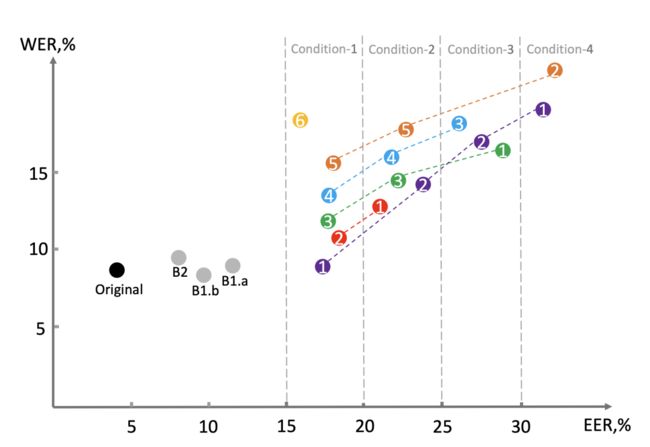
图6 竞赛评测计划书中提供的排名方案示意
表1 数据集构成

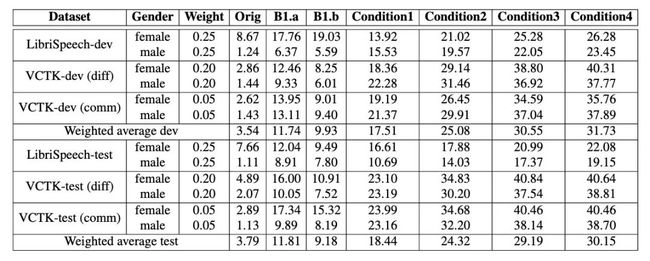
不同条件下的隐私保护结果如表2所示,原始语音和两个基线结果分别表示为Orig、B1.a和B1.b。可以观察到,我们的匿名化方法满足所有条件下的EER要求,并相应取得了18.44%、24.32%、29.19%和30.15%的平均EER。与B1.a相比,我们的方法的平均EER相比B1.a增加18.34%,与B1.b相比增加20.97%,这表明我们的匿名化方法可以更有效的保护说话人隐私。同时,我们发现在Librispeech语料库上针对不同性别的结果表现相似,而基线系统则有显著的差异。
表2 不同条件下的EER结果
如表3所示,我们在所有EER条件下的WER指标都优于两个基线系统,在LibriSpeech-test数据集上WER略有下降,而在VCTK-test数据集则有显著下降。Librispeech-test和VCTK-test上的最低WER分别为3.84%和7.78%。平均WER分别比B1.a和B1.b低2.47%和1.74%,这表明我们的匿名化方法可以实现比基线系统更好的效用性。
表3 不同条件下的WER结果

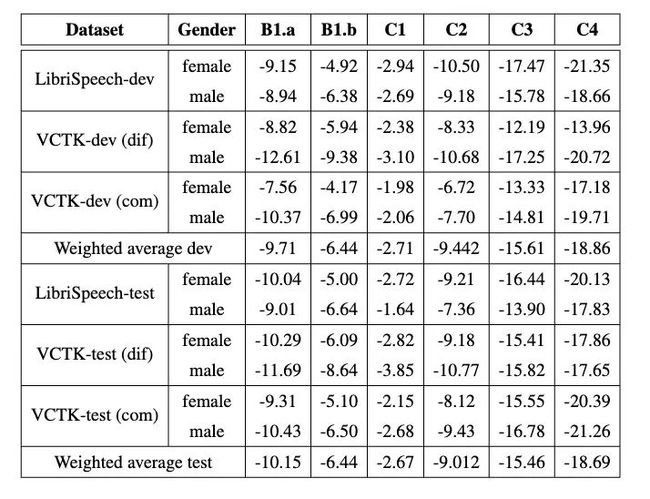
表4和表5中展示了另外两个不参与排名的指标上的结果。可以清楚地发现,我们的匿名数据的音高相关性超过了竞赛规定的最小阈值,并且在每种条件下与基线系统取得了相当的结果。在condition1中实现了最高的音高相关性。GVD的结果表明,语音独特性随着EER的升高而恶化。这可能是由于匿名嵌入中伪嵌入的比例越来越大导致的。
表4 不同条件下音高相关性指标结果
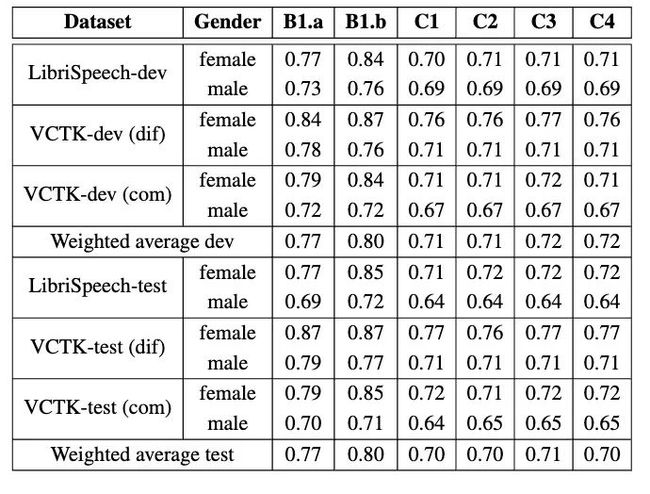
图5 不同条件下语音独特性(GVD)指标结果
4. 结论
本文介绍了西工大ASLP实验室参加第二届VPC竞赛的匿名化系统。我们提出的系统无需声纹识别模型或x-vector池,巧妙地利用了平均说话人向量作为伪说话人向量的条件,以产生最终的匿名说话人向量。在本届VPC竞赛中,我们的系统分别达到了30.15%和5.82%的最佳平均EER和WER,在竞赛设定的四个条件上均取得了最好成绩,这表明我们的匿名化方法可以抑制语音信号中的个人身份信息,并在语言信息保留上优于基线系统。