(全面)矩阵分解相关知识总结
前言
第一次进行综合性的知识总结,作为一个参考手册供需要的时候进行查阅
矩阵分解
文章目录
-
-
-
- 前言
-
-
- 矩阵分解
-
- 矩阵分解介绍
- 一、特征值分解
-
- 1.1 简介
- 1.2 定义和说明
-
- 1.2.1 特征值和特征向量
- 1.2.2 求解特征值和特征向量
- 1.2.3 特征值分解
- 1.2.4 直观理解特征值分解
- 1.3 局限
- 二、奇异值分解
-
- 2.1 简介
- 2.2 定义和说明
-
- 2.2.1 奇异值分解
- 2.2.2 直观理解奇异值分解
- 2.2.3 奇异值分解计算
- 2.3 紧奇异值分解和截断奇异值分解
-
- 2.3.1 紧奇异值分解
- 2.3.2 截断奇异值分解
- 2.3.3 二者关系比较
- 2.4 应用
-
- 2.4.1 主成分分析(PCA)
- 2.4.2 潜在语义分析(LSA)
- 三、三角分解
-
- 3.1 LU分解
-
- 3.1.1 定义
- 3.1.2 计算
- 3.1.3 求解线性方程组的应用
- 3.1.4 求解线性方程组的复杂度讨论
- 3.2 LDU分解
- 3.3 其他三角分解
- 四、极分解
-
- 4.1 定义
- 4.2 与奇异值分解的关系
- 4.3 应用
矩阵分解介绍
矩阵分解(Matrix decomposition),是将一个矩阵拆解为数个矩阵的乘积的运算。通过矩阵分解,将一个复杂的矩阵用更小更简单的几个矩阵来表示,简化计算,从复杂的数据中提取出相对重要的特征信息,实现信息抽象。在图像处理,模式识别,自然语言处理中应用广泛。依照使用目的和适用范围不同,大致分为如下几种:
- 特征值分解(EVD)
- 奇异值分解(SVD)
- 三角分解
- 极分解
一、特征值分解
1.1 简介
特征值分解(Eigenvalue decomposition,EVD),又称为谱分解(Spectral decomposition),是将矩阵(特指方阵)分解为由其特征值和特征向量表示的矩阵乘积的方法.
1.2 定义和说明
1.2.1 特征值和特征向量
对于 n n n维非零向量 v v v, n × n n\times n n×n矩阵( n n n阶方阵) A A A,如果满足 A v = λ v (1) Av=\lambda v \tag{1} Av=λv(1) 那么 v v v被称为矩阵A的特征向量,而 λ \lambda λ被称为特征向量 v v v对应的特征值,一个矩阵的一组特征向量是彼此正交的。
我们再来从几何的角度来理解一下特征值和特征向量的意义:矩阵对应一个线性变换,矩阵乘法 A v Av Av类似于施加在向量 v v v上的一个函数,对 v v v进行旋转、伸缩的变化产生一个新向量。如果矩阵对某一个向量或某些向量只发生伸缩变换,不对这些向量产生旋转的效果,那么这些向量就称为这个矩阵的特征向量,伸缩的比例就是特征值。
1.2.2 求解特征值和特征向量
对 A v = λ v Av=\lambda v Av=λv做一个简单变形有 ( A − λ I ) v = 0 (A - \lambda I)v=0 (A−λI)v=0,其中 I I I为 n × n n \times n n×n的单位矩阵。我们知道,该公式有非零解,需要系数矩阵的秩小于 n n n,系数行列式
∣ A – λ I ∣ = ∣ a 11 − λ a 12 ⋯ a 1 n a 21 a 22 − λ ⋯ a 2 n ⋮ ⋮ ⋮ a n 1 a n 2 ⋯ a n n − λ ∣ = 0 (2) \begin{array}{l}|A – \lambda I| =\begin{vmatrix} a_{11}-\lambda & a_{12} & \cdots & a_{1n}\\ a_{21} & a_{22}-\lambda & \cdots & a_{2n}\\ \vdots & \vdots & & \vdots \\ a_{n1} & a_{n2} & \cdots & a_{nn}-\lambda \end{vmatrix}\end{array}=0\tag{2} ∣A–λI∣=∣ ∣a11−λa21⋮an1a12a22−λ⋮an2⋯⋯⋯a1na2n⋮ann−λ∣ ∣=0(2)
通常, ∣ A − λ I ∣ |A- \lambda I| ∣A−λI∣称为矩阵A的特征多项式,求解出的$\lambda_i, i=1,2,…,n $即为矩阵A对应的特征值。
对每个特征值 λ i \lambda_i λi,代入 ( A − λ i I ) v = 0 (A-\lambda_i I)v=0 (A−λiI)v=0,即可求出特征向量。每个特征值可对应多个特征向量(方向相同,模长不同),在实际应用中我们通常使用模长为1的单位特征向量。
1.2.3 特征值分解
上面已经求出了 A A A的特征值和特征向量,矩阵的特征值分解过程就非常简单了。
特征值分解就是将方阵 A A A分解成如下形式 A = Q Σ Q − 1 (3) A=Q\Sigma Q^{-1}\tag{3} A=QΣQ−1(3)其中, Σ \Sigma Σ 是对角阵,对角元从左上到右下依次为矩阵 A A A的特征值从大到小的排列, Q Q Q 是将单位化的特征向量作为列向量的可逆矩阵,即 Q T Q = I Q^TQ=I QTQ=I或者说 Q T = Q − 1 Q^T=Q^{-1} QT=Q−1,也就是说 Q Q Q为酉矩阵。特征值分解是存在的,我们把式(3)换一种形式就很好理解: A Q = Q Σ AQ=Q\Sigma AQ=QΣ。
从式(3)可以看出,其实特征值分解就是一个基变换, Q Q Q是过渡矩阵,将 A A A变换到以特征向量为基的空间上,而 Σ \Sigma Σ就是 A A A矩阵表达的线性变换在以特征向量为基的空间上的表达,因为一组基必须是正交的,所以要求A是对称矩阵,而对称矩阵一定是方阵。
1.2.4 直观理解特征值分解
首先再次明确,一个矩阵其实就是一个线性变换,所以一个矩阵乘一个向量后得到的向量,相当于是这个向量进行了线性变换。而线性变换一般有以下两种:
- 旋转
- 伸缩
一个矩阵表示的线性变换结果就是以上两种变换的合成。而特征值分解刚好可以将这两种变换的作用分解开来。
我们以一个二阶方阵进行举例,方便在平面上表示出来:
A = ( 2 − 1 − 1 2 ) = Q Σ Q − 1 = ( − 2 2 2 2 2 2 2 2 ) ( 3 0 0 1 ) ( − 2 2 2 2 2 2 2 2 ) A=\begin{pmatrix} 2 & -1 \\ -1 & 2 \\ \end{pmatrix} =Q\Sigma Q^{-1}=\begin{pmatrix} -\frac{\sqrt{2}}{2} & \frac{\sqrt{2}}{2} \\ \frac{\sqrt{2}}{2} & \frac{\sqrt{2}}{2} \\ \end{pmatrix}\begin{pmatrix} 3 & 0 \\ 0 & 1 \\ \end{pmatrix}\begin{pmatrix} -\frac{\sqrt{2}}{2} & \frac{\sqrt{2}}{2} \\ \frac{\sqrt{2}}{2} & \frac{\sqrt{2}}{2} \\ \end{pmatrix} A=(2−1−12)=QΣQ−1=(−22222222)(3001)(−22222222)
我们将 Q − 1 Q^{-1} Q−1的两个列向量单独拿出来,记作 i ⃗ = ( − 2 2 2 2 ) T \vec{i}=(-\frac{\sqrt{2}}{2} \quad\frac{\sqrt{2}}{2})^T i=(−2222)T, j ⃗ = ( 2 2 2 2 ) T \vec{j}=(\frac{\sqrt{2}}{2} \quad\frac{\sqrt{2}}{2})^T j=(2222)T,因为它们彼此正交,所以以它们作为基,构成坐标系,如下图所示。
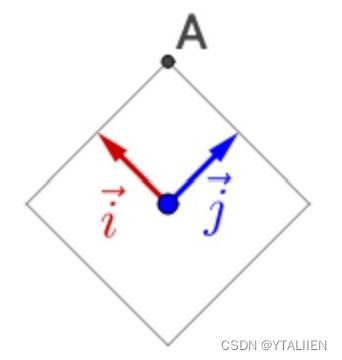
接下来对这组基构成的坐标系进行线性变换,左乘 Q = ( − 2 2 2 2 2 2 2 2 ) Q=\begin{pmatrix} -\frac{\sqrt{2}}{2} & \frac{\sqrt{2}}{2} \\ \frac{\sqrt{2}}{2} & \frac{\sqrt{2}}{2} \\ \end{pmatrix} Q=(−22222222),相当于对 i ⃗ \vec{i} i, j ⃗ \vec{j} j做了旋转变换,如下图所示
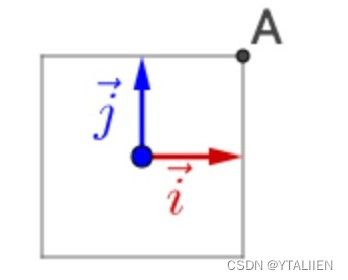
再左乘对角矩阵 Σ = ( 3 0 0 1 ) \Sigma=\begin{pmatrix} 3 & 0 \\ 0 & 1 \\ \end{pmatrix} Σ=(3001),相当于对 i ⃗ \vec{i} i, j ⃗ \vec{j} j作了拉伸变换,如下图所示
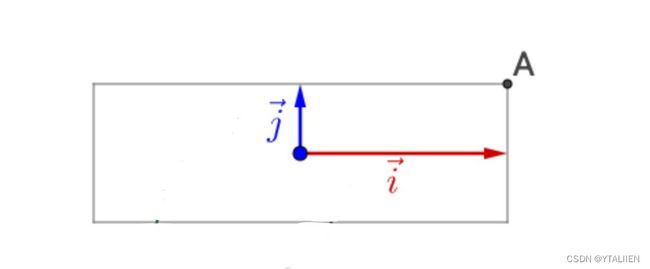
也就是说,矩阵 A A A就是拉伸、旋转变换的合成,对 A A A的特征向量够成一组基进行变换。所以对于特征值分解,我们可以这样理解:
- 特征值:伸缩的大小(伸缩系数)
- 特征向量:伸缩的方向(旋转变换)
我们通过特征值分解得到某个变换的 n n n个特征向量,这 n n n个向量对应了这个矩阵的最重要的 n n n个变化(伸缩变换)的方向,而我们利用这 n n n个方向,就可以近似这个矩阵,也就提取到了这个矩阵的最重要的特征。
- 特征值:该特征的重要程度
- 特征向量:该特征是什么
1.3 局限
由于要保证式(3)中 Q Q Q的列向量彼此正交,因此 A A A必须是对称阵,也就是说,特征值分解中变换的矩阵 A A A必须是方阵。这在实际应用中局限较大。
二、奇异值分解
2.1 简介
由于在实际应用中,很多情况下都无法保证待分解矩阵为方阵,因为需要一种更加一般的方式进行矩阵分解。
奇异值分解(singular value decomposition,SVD),就是这样一种分解方法。它是特征值分解在任意矩阵上的推广。复杂矩阵所代表的线性变换可由若干个简单矩阵所代表的线性变换组合起来,使用SVD能找到这些简单矩阵。
2.2 定义和说明
2.2.1 奇异值分解
对于一个非零的$m\times n 实矩阵 实矩阵 实矩阵A$,可以表示为以下形式
A = U Σ V T (4) A=U \Sigma V^T \tag{4} A=UΣVT(4)
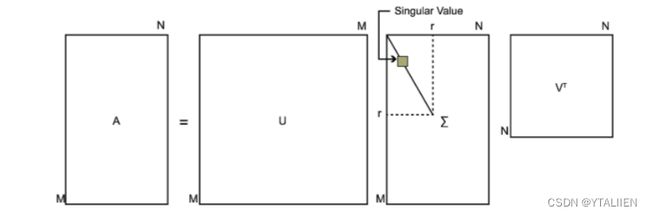
则 U Σ V T U \Sigma V^T UΣVT称为矩阵A的奇异值分解,其中, U U U 是 m m m阶正交矩阵,且其列向量称为 A A A的左奇异向量, V V V 是 n n n阶正交矩阵,且其列向量称为 A A A的右奇异向量, Σ \Sigma Σ 是由 A A A的奇异值 σ i ( i = 1 , 2 , . . . , n ) \sigma_i(i=1,2,...,n) σi(i=1,2,...,n)降序排列的$m\times n 对角矩阵。 对角矩阵。 对角矩阵。U 和 和 和V 都是酉矩阵,即满足 都是酉矩阵,即满足 都是酉矩阵,即满足UTU=I,VTV=I$。下图可以很形象的看出上面SVD的定义:
2.2.2 直观理解奇异值分解
一个$m\times n 矩阵 矩阵 矩阵A ,表示一个从 ,表示一个从 ,表示一个从n 维空间到 维空间到 维空间到m 维空间的一个线性变换 维空间的一个线性变换 维空间的一个线性变换T:x\to Ax ,其中, ,其中, ,其中,x$ 是 n n n维空间的向量, A x Ax Ax 是 m m m维空间的向量。
我们知道(4)对应的线性变换可以分解成三个简单的变换:一个坐标系的旋转变换、一个坐标轴的伸缩变换、另一个坐标系的旋转变换,而奇异值分解就是保证对于任意一个矩阵,这样的分解一定存在,并且不是唯一的。
由式(4)我们知道, V V V的列向量 ( v 1 v 2 . . . v n ) (v_1\quad v_2 \quad... \quad v_n) (v1v2...vn)可以构成一组标准的正交基, v i T = ( v i 1 , v i 2 , . . . , v i m ) v_i^T=(v_{i1},v_{i2},...,v_{im}) viT=(vi1,vi2,...,vim)表示在一个 n n n维空间中正交坐标系的旋转变换,类似地, U U U的列向量 ( u 1 u 2 . . . u m ) (u_1\quad u_2\quad...\quad u_m) (u1u2...um)也可以构成一组标准正交基,表示一个 m m m维空间中正交坐标系的旋转变换,而 Σ \Sigma Σ的对角元素 σ 1 , σ 2 , . . . , σ n \sigma_1,\sigma_2,...,\sigma_n σ1,σ2,...,σn是一组非负实数,表示 n n n维空间中原始正交坐标系坐标轴的对应伸缩系数的伸缩变换.
而对于式(4)的分解过程,可以这样理解,原始空间( n n n维)的标准正交基,经过坐标系 V T V^T VT的旋转变换,再经过坐标轴 Σ \Sigma Σ的伸缩变换,然后再经过 U U U的旋转变换,最后得到和线性变换 A A A等价的效果,一个二维的正交坐标系变换如下图所示

在上图中,黄色和红色表示原始的正交坐标系,先经 V T V^T VT的旋转变换,再经过 Σ \Sigma Σ的伸缩变换(黑色的 σ 1 和 σ 2 \sigma_1 和\sigma_2 σ1和σ2 表示各坐标轴的伸缩系数),最后再经 U U U的旋转变换,得到直接和A变换相同的结果。
2.2.3 奇异值分解计算
那么如何求出SVD分解后的 U , Σ , V U,Σ,V U,Σ,V这三个矩阵呢?
对于任意矩阵 A A A,如果我们将 A T A^T AT和 A A A做矩阵乘法,那么会得到 n × n n×n n×n的一个方阵 A T A A^TA ATA。既然 A T A A^TA ATA是方阵,那么可以进行特征值分解,得到的特征值和特征向量满足下式:
( A T A ) v i = λ i v i (5) (A^T A)v_i=\lambda_i v_i \tag{5} (ATA)vi=λivi(5)
这样就可以得到矩阵 A T A A^TA ATA的 n n n个特征值和对应的 n n n个特征向量 v v v了。将 A T A A^TA ATA的所有特征向量张成一个 n × n n×n n×n的矩阵 V V V,就是SVD公式里面的 V V V矩阵了。一般将 V V V中的每个特征向量叫做 A A A的右奇异向量。
如果我们将 A A A和 A T A^T AT做矩阵乘法,那么会得到 m × m m×m m×m的一个方阵 A A T AA^T AAT。既然 A A T AA^T AAT是方阵,那么可以进行特征分解,得到的特征值和特征向量满足下式:
( A A T ) u i = λ i u i (6) (AA^T)u_i=\lambda_iu_i \tag{6} (AAT)ui=λiui(6)
这样就可以得到矩阵 A A T AA^T AAT的 m m m个特征值和对应的 m m m个特征向量 u u u了。将 A A T AA^T AAT的所有特征向量张成一个 m × m m×m m×m的矩阵 U U U,就是SVD公式里面的 U U U矩阵了。一般将 U U U中的每个特征向量叫做 A A A的左奇异向量。
上面其实很容易证明,我们以 V V V矩阵的证明为例:
A = U Σ V T ⇒ A T = V Σ T U T ⇒ A T A = V Σ T U T U Σ V T = V Σ 2 V T (7) A=U\Sigma V^T \Rightarrow A^T=V\Sigma^T U^T \Rightarrow A^TA = V\Sigma^T U^TU\Sigma V^T = V\Sigma^2V^T\tag{7} A=UΣVT⇒AT=VΣTUT⇒ATA=VΣTUTUΣVT=VΣ2VT(7)
可以看出 A T A A^TA ATA的特征向量组成的的确就是SVD中的 V V V矩阵。类似的方法可以得到 A A T AA^T AAT的特征向量组成的就是SVD中的 U U U矩阵。
进一步还可以看出 A A T AA^T AAT的特征值矩阵等于奇异值矩阵的平方,也就是说特征值和奇异值满足如下关系:
σ i = λ i , i = 1 , 2 , . . . , n (8) \sigma_i=\sqrt{\lambda_i},\quad i=1,2,...,n \tag{8} σi=λi,i=1,2,...,n(8)
以上 σ i \sigma_i σi构成 Σ \Sigma Σ的各个元素,得到 Σ = d i a g ( σ 1 , σ 2 , . . . , σ n ) \Sigma=diag(\sigma_1,\sigma_2,...,\sigma_n) Σ=diag(σ1,σ2,...,σn)。
另外,注意到:
A = U Σ V T ⇒ A V = U Σ V T V ⇒ A V = U Σ ⇒ A v i = σ i u i (9) A=U\Sigma V^T \Rightarrow AV=U\Sigma V^TV \Rightarrow AV=U\Sigma \Rightarrow Av_i = \sigma_i u_i \tag{9} A=UΣVT⇒AV=UΣVTV⇒AV=UΣ⇒Avi=σiui(9)
也可以由 v i v_i vi和 λ i \lambda_i λi来求 u i u_i ui:
u i = 1 σ i A v i , i = 1 , 2 , . . . , r (10) u_i=\frac{1}{\sigma_i}Av_i,\quad i=1,2,...,r\tag{10} ui=σi1Avi,i=1,2,...,r(10)
其中, r r r表示 A A A的前 r r r个正奇异值,可以得到 U 1 = ( u 1 u 2 . . . u r ) U_1=(u_1\quad u_2 \quad ...\quad u_r) U1=(u1u2...ur)。再求 A T A^T AT的零空间的一组标准正交基 { u r + 1 , u r + 2 , . . . , u m } \{u_{r+1},u_{r+2},...,u_m\} {ur+1,ur+2,...,um}, 可以得到 U 2 = ( u r + 1 u r + 2 . . . u m ) U_2=(u_{r+1}\quad u_{r+2} \quad ...\quad u_m) U2=(ur+1ur+2...um),最终可以得到 U = ( U 1 U 2 ) U=(U_1\quad U_2) U=(U1U2)。
2.3 紧奇异值分解和截断奇异值分解
由式(8)可知,奇异值的减少呈幂函数形式下降,而根据大多是实际应用数据可知,在很多情况下,前10%甚至1%的奇异值的和就占了全部的奇异值之和的99%以上,因此,在具体应用中往往并不会如式(4)所示进行矩阵的完全奇异值分解,而常以以下两种形式出现。
2.3.1 紧奇异值分解
对于 m × n m\times n m×n实矩阵A, 满足 r a n k ( A ) = r , r ≤ m i n { m , n } rank(A)=r, r\leq min\{m,n\} rank(A)=r,r≤min{m,n},则称 A = U r Σ r V r T (11) A=U_r\Sigma_rV_r^T \tag{11} A=UrΣrVrT(11)为A的紧奇异值分解(compact singular value decomposition),其中, U r U_r Ur 是 m × r m\times r m×r 矩阵, V r V_r Vr 是 n × r n\times r n×r 矩阵, Σ r \Sigma_r Σr 是 r r r阶对角矩阵,可分别由式(4)中的 V V V, U U U的前 r r r 列得到,和 Σ \Sigma Σ的前 r r r 个对角线元素得到。
2.3.2 截断奇异值分解
对于 m × n m\times n m×n实矩阵A, 满足 r a n k ( A ) = r , 0 < k < r rank(A)=r, 0
在实际应用中,截断奇异值分解方法应用较多,一般在实际应用中提到的奇异值分解,通常就是指截断奇异值分解。一般来说, k k k比 r r r小很多,所以,使用截断奇异值分解,我们可以将一个大的、复杂的矩阵,分解成三个小的矩阵,是一个常见的降维方法。
2.3.3 二者关系比较
奇异值分解是在平方损失(弗罗贝尼乌斯范数,Frobenius norm)意义下对矩阵的最优近似。紧奇异值分解对应着无损压缩,而截断奇异值分解对应有损压缩。
2.4 应用
因为奇异值分解的特性,SVD可以用于PCA(见2.4.1)降维,用于数据压缩和去噪;也可以用于推荐算法,将用户的喜好与对应的矩阵做特征分解,进而得到隐含的用户需求来做推荐;还可用于自然语言处理,如潜在语义分析(见2.4.2),应用在推荐系统、图像处理以及生物信息学等领域。
2.4.1 主成分分析(PCA)
主成分分析(principle component analysis,PCA),常用的无监督学习方法,利用正交变换把线性相关变量表示的观测数据转换为少数几个线性无关变量表示的数据,这些线性无关的变量称为主成分。
在主成分分析中,一般遵循以下操作步骤
其中, k < < r k<
通过主成分分析,可以利用主成分近似地表示原始数据,把复杂的原始数据交给少量的主成分来表述,实现数据降维。
2.4.2 潜在语义分析(LSA)
潜在语义分析(latent semantic analysis,LSA)是一种无监督学习方法,通过矩阵分解发现文本与单词之间的基于话题的语义关系。
主要利用矩阵的奇异值分解,对单词-文本矩阵进行奇异值分解,如式(12)所示,将 U k U_k Uk作为话题空间,将 Σ k V k T \Sigma_k V_k^T ΣkVkT作为文本在话题空间的表示,从而进行潜在语义分析。
三、三角分解
3.1 LU分解
3.1.1 定义
将 n × n n\times n n×n矩阵(特指方阵) A A A分解成 L L L(下三角)矩阵和 U U U(上三角)矩阵的乘积。 A = L U (13) A=LU\tag{13} A=LU(13)其中, A A A如果能分解,应该满足: A A A的前 n − 1 n-1 n−1阶顺序主子式 Δ k ≠ 0 ( k = 1 , 2 , . . . , n − 1 ) \Delta_k\neq 0(k=1,2,...,n-1) Δk=0(k=1,2,...,n−1)。
3.1.2 计算
使用矩阵的三个初等变换可以得到上(下)三角矩阵。
- 用非零常数 c c c乘矩阵 A A A的第 i i i行
- 矩阵 A A A的第 j j j行的 k k k倍加到第 i i i行
- 互换矩阵 A A A的第 i i i行和第 j j j行
3.1.3 求解线性方程组的应用
在数值计算中,要求解形如 A x = b (14) Ax=b\tag{14} Ax=b(14)这样的非齐次线性方程组,我们知道,应该尽量避免计算 A − 1 A^{-1} A−1,所以需要找一个能够替代 x = A − 1 b x=A^{-1}b x=A−1b 的方案,就可以使用 L U LU LU分解。先把 A A A分解成 L U LU LU即 L U x = b LUx=b LUx=b,然后通过求解线性方程组 L y = b (15) Ly=b\tag{15} Ly=b(15) 可以求解出 y y y,最后再通过 U x = y (16) Ux=y\tag{16} Ux=y(16)求解 x x x。
下面看一个更直观的展示:
- 正向代入求 y y y
L y = ( l 11 0 0 0 l 21 l 22 0 0 l 31 l 32 l 33 0 l 41 l 42 l 43 l 44 ) ( y 1 y 2 y 3 y 4 ) = ( l 11 y 1 l 21 y 1 + l 22 y 2 l 31 y 1 + l 32 y 2 + l 33 y 3 l 41 y 1 + l 42 y 2 + l 43 y 3 + l 44 y 4 ) = ( b 1 b 2 b 3 b 4 ) Ly=\begin{pmatrix} l_{11} & 0& 0&0 \\ l_{21} & l_{22}& 0& 0 \\ l_{31} & l_{32}&l_{33}& 0\\l_{41} & l_{42}&l_{43}&l_{44}\\\end{pmatrix} \begin{pmatrix} y_1\\y_2\\y_3\\y_4 \\ \end{pmatrix}= \begin{pmatrix} l_{11}y_1\\ l_{21}y_1 + l_{22}y_2\\ l_{31}y_1 + l_{32}y_2+l_{33}y_3\\l_{41}y_1 + l_{42}y_2+l_{43}y_3+l_{44}y_4\\\end{pmatrix}=\begin{pmatrix} b_1\\b_2\\b_3\\b_4 \\ \end{pmatrix} Ly=⎝ ⎛l11l21l31l410l22l32l4200l33l43000l44⎠ ⎞⎝ ⎛y1y2y3y4⎠ ⎞=⎝ ⎛l11y1l21y1+l22y2l31y1+l32y2+l33y3l41y1+l42y2+l43y3+l44y4⎠ ⎞=⎝ ⎛b1b2b3b4⎠ ⎞ - 反向代入求 x x x
U x = ( u 11 u 12 u 13 u 14 0 u 22 u 23 u 24 0 0 u 33 u 34 0 0 0 u 44 ) ( x 1 x 2 x 3 x 4 ) = ( u 11 x 1 + u 12 x 2 + u 13 x 3 + u 14 x 4 u 22 x 2 + u 23 x 3 + u 24 x 4 u 33 x 3 + u 34 x 4 u 44 x 4 ) = ( y 1 y 2 y 3 y 4 ) Ux=\begin{pmatrix} u_{11} & u_{12}& u_{13}&u_{14} \\ 0 & u_{22}& u_{23}&u_{24} \\ 0 & 0 & u_{33}&u_{34}\\0 & 0 & 0 &u_{44}\\\end{pmatrix} \begin{pmatrix} x_1\\x_2\\x_3\\x_4 \\ \end{pmatrix}= \begin{pmatrix} u_{11}x_1 + u_{12}x_2+ u_{13}x_3+u_{14}x_4 \\ u_{22}x_2+ u_{23}x_3+u_{24}x_4 \\ u_{33}x_3+u_{34}x_4\\u_{44}x_4\\\end{pmatrix}=\begin{pmatrix} y_1\\y_2\\y_3\\y_4 \\ \end{pmatrix} Ux=⎝ ⎛u11000u12u2200u13u23u330u14u24u34u44⎠ ⎞⎝ ⎛x1x2x3x4⎠ ⎞=⎝ ⎛u11x1+u12x2+u13x3+u14x4u22x2+u23x3+u24x4u33x3+u34x4u44x4⎠ ⎞=⎝ ⎛y1y2y3y4⎠ ⎞
3.1.4 求解线性方程组的复杂度讨论
n × n n\times n n×n矩阵A分解成 L U LU LU的过程,复杂度为 O ( n 3 ) O(n^3) O(n3)。而上述求解线性方程组的计算,前向代入中,第一行计算1个乘法,第二行计算2个乘法和1个加法,以此类推,可以得到复杂度为 O ( n 2 ) O(n^2) O(n2).
这样的复杂度在计算像式(14)那样的线性方程组时,如果不考虑 A A A,只有方程右边的 b b b发生变化的话,那么计算复杂度从 O ( n 3 ) O(n^3) O(n3)下降为 O ( n 2 ) O(n^2) O(n2),实现了一个级次的降低。而如果要计算 A − 1 A^{-1} A−1的话,根据高斯消元法的复杂度,是 O ( n 3 ) O(n^3) O(n3),因此这种方法在实际应用中,对于复杂的计算速度大大提高。
3.2 LDU分解
将 n × n n\times n n×n矩阵 A A A分解成 A = L D U (17) A=LDU\tag{17} A=LDU(17)
其中, L L L为单位下三角矩阵, U U U为单位上三角矩阵, D D D是 n n n阶对角矩阵,满足 D = d i a g ( d 1 , d 2 , . . . , d n ) D=diag(d_1,d_2,...,d_n) D=diag(d1,d2,...,dn) d k = Δ k Δ k − 1 = a k k ( k ) , k = 1 , 2 , . . . , n (18) d_k=\frac{\Delta_k}{\Delta_{k-1}}=a_{kk}^{(k)},\quad k=1,2,...,n\tag{18} dk=Δk−1Δk=akk(k),k=1,2,...,n(18)并且,矩阵 A A A应该满足: A A A的前 n − 1 n-1 n−1阶顺序主子式 Δ k ≠ 0 ( k = 1 , 2 , . . . , n − 1 ) \Delta_k\neq 0(k=1,2,...,n-1) Δk=0(k=1,2,...,n−1)。
3.3 其他三角分解
杜立特/克劳特分解 :将 n × n n\times n n×n矩阵 A A A分解成 A = L U (19) A=LU\tag{19} A=LU(19)其中,如果 L L L是单位下三角矩阵, U U U是上三角矩阵,则式(18)称为杜立特(Doolittle)分解;如果 L L L是下三角矩阵, U U U是单位上三角矩阵,则式(19)称为克劳特(Crout)分解。
Cholesky分解 :如果对 n n n阶对称正定矩阵 A A A,存在对 A A A的分解 A = L L T (20) A=LL^T\tag{20} A=LLT(20)
其中,如果限定下三角矩阵 L L L对角元素为正,则该分解是唯一的。
PLU分解 : A A A为 n n n阶方阵,存在对 A A A的分解 A = P L U (21) A=PLU\tag{21} A=PLU(21)
其中, L L L是单位下三角矩阵, U U U是上三角矩阵, P P P是置换矩阵.任何方阵都存在这样的分解。
PLU分解的提出主要是为了解决LU、LDU分解中可能出现的不稳定性问题,如果在初等变换高斯消元中作为被除数的 a k k ( k ) a_{kk}^{(k)} akk(k)很小的话,就会最终分解矩阵结果中出现很大的数,导致分解结果不稳定。
LDLT分解 : 如果对 n n n阶对称半正定/半负定矩阵 A A A,存在对 A A A的分解 A = L D L T (22) A=LDL^T\tag{22} A=LDLT(22)
其中,L为单位下三角矩阵,U为上三角矩阵;A如果能分解,应该满足:A的前 n − 1 n-1 n−1阶顺序主子式 Δ k ≠ 0 ( k = 1 , 2 , . . . , n − 1 ) \Delta_k\neq 0(k=1,2,...,n-1) Δk=0(k=1,2,...,n−1)。
LDLT分解是对Cholesky分解的改进,在Cholesky计算过程中涉及开方计算,而该法避免了这一计算。
QR分解: A A A为 m × n m \times n m×n矩阵,存在对 A A A的分解 A = Q R (23) A=QR\tag{23} A=QR(23)
其中, Q Q Q是正交矩阵, R R R是上三角矩阵,任何方阵都存在这样的分解,但若A不是方阵,非方阵的列满秩矩阵A也存在这样的分解,称为约化QR分解。
四、极分解
4.1 定义
- 实方阵的极分解:设 A A A是 n n n阶实方阵,则A可以分解为 A = Q T (24) A=QT\tag{24} A=QT(24)
其中, Q Q Q是正交矩阵, T T T是唯一的半正定矩阵,并且当 A A A可逆时, Q Q Q也是唯一的(此时 T T T是正定的)。
- 复方阵的极分解:设 A A A是 n n n阶复方阵,则A可以分解为 A = U T (25) A=UT\tag{25} A=UT(25)
其中, U U U是酉矩阵, T T T是唯一的半正定Hermite矩阵,并且当 A A A可逆时, U U U也是唯一的(此时 T T T是正定Hermite矩阵)。
4.2 与奇异值分解的关系
下面我们探讨一下式(24)和式(4)之间的关系.
根据式(4),我们取$Q=UV,T=V^T \Sigma V $ ,则显然可以得到二者之间的关系。
4.3 应用
介质力学中使用极分解来将形变分解成拉伸和旋转两个部分,一般式(24)和式(25)中的 T T T表示拉伸, Q Q Q和 U U U分别表示在实空间和复空间的旋转部分。