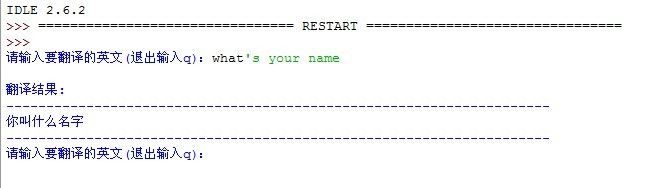
python实现的翻译脚本
今天突然有一个想法,就是想自己写一个翻译脚本。可惜Google提供的API是供网络应用的。刚好在《dive into python》里面这本书里面看到如何从HTML文档中提取出来自己想要的内容,那这样的话,可不可以模拟浏览器来发送想翻译的句子,然后再接收返回结果后的HTML源码,最后从中提取出翻译的结果呢? 其实是行的,因为利用python可以模拟浏览器的行为,向Google翻译的主页发送想要翻译的句子。下面是具体的代码:
2
3 values = { 'hl' : 'zh-CN' , 'ie' : 'utf8' , 'text' : text , 'langpair' : "en|zh-CN" }
4 url = 'http://translate.google.cn/translate_t'
5 data = urllib . urlencode( values)
6 req = urllib2 . Request( url , data)
7 req . add_header( 'User-Agent' , "Mozilla/5.0+(compatible;+Googlebot/2.1;++http://www.google.com/bot.html)")
8 response = urllib2 . urlopen( req)
上面最关键的是text这个变量,值为想翻译的句子。后面的langpair的值是语言对,这里是英文翻译成简体中文,可以自由改动。下面就要实现一个类来取出我们想要的翻译结果,这个类要从SGMLParser派生出来,SGMLParser是在sgmllib.py中包含的。
02
03 class URLLister( SGMLParser ):
04 def reset( self ):
05 SGMLParser . reset( self)
06 self . result = []
07 self . open = False
08 def start_div( self , attrs ):
09 id = [ v for k , v in attrs if k == 'id' ]
10 if 'result_box' in id :
11 self . open = True
12 def handle_data( self , text ):
13 if self . open :
14 self . result . append( text)
15 self . open = False
当调用feed方法时,就会寻找开始标记为div的片段,当找到时,它会调用一个自身内部的方法,其实最终也就是调用到start_div跟handle_data这两个方法来找出我们想要的翻译结果,具体的就不说了。下面是完整的代码:
01 import urllib,urllib2
02 from sgmllib import SGMLParser
03
04 class URLLister(SGMLParser):
05 def reset(self):
06 SGMLParser.reset(self)
07 self.result = []
08 self.open = False
09 def start_div(self, attrs):
10 id = [v for k, v in attrs if k=='id']
11 if 'result_box' in id:
12 self.open = True
13 def handle_data(self, text):
14 if self.open:
15 self.result.append(text)
16 self.open = False
17
18 while True:
19 text = raw_input("请输入要翻译的英文(退出输入q):")
20 if text=='q':
21 break;
22 values={'hl':'zh-CN','ie':'utf8','text':text,'langpair':"en|zh-CN"}
23 url='http://translate.google.cn/translate_t'
24 data = urllib.urlencode(values)
25 req = urllib2.Request(url, data)
26 req.add_header('User-Agent', "Mozilla/5.0+(compatible;+Googlebot/2.1;++http://www.google.com/bot.html)")
27 response = urllib2.urlopen(req)
28 parser = URLLister()
29 parser.feed(response.read())
30 parser.close()
31 print "翻译结果:"
32 for i in parser.result:
33 i = unicode(i,'utf-8').encode('gbk');
34 print i