深度学习之目标检测(一)——Faster RCNN
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、目标检测前言
-
- 1.1 目标检测网络的分类
- 二、R-CNN
-
- 2.1 R-CNN算法流程
-
- 2.1.1 候选区域的生成
- 2.1.2 深度网络提取特征
- 2.1.3 SVM分类器判断类别
- 2.1.4 回归器精细修正候选框位置
- 2.2 R-CNN框架
- 2.3 R-CNN中存在的问题
- 三、Fast R-CNN
-
- 3.1 Fast R-CNN 步骤
- 3.2 详细流程
-
- 3.2.1 一次性计算整张图像特征
- 3.2.2 ROI Pooling Layer
- 3.2.3 分类器
- 3.2.4 边界框回归器
- 3.3 Fast R-CNN损失函数
-
- 3.3.1 分类损失
- 3.3.2 边界框回归损失
- 3.4 Fast R-CNN框架
- 四、Faster R-CNN
-
- 4.1 Faster R-CNN步骤
- 4.2 RPN
-
- 4.2.1 采样
- 4.2.2 RPN损失
- 4.3 Faster R-CNN训练
- 4.4 Faster R-CNN框架
- 五、FPN
前言
提示:这里可以添加本文要记录的大概内容:
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
提示:以下是本篇文章正文内容,下面案例可供参考
一、目标检测前言
1.1 目标检测网络的分类
-
One-Stage: SSD,YOLO
1)基于anchors直接进行分类以及调整边界框
优点:检测速度快 -
Two-Stage:Faster-RCNN
- 通过专门的模块去生成候选框(RPN),寻找前景以及调整边界框(基于anchors)(前景即需要检测识别的目标,其余的称为背景)
2)基于之前生成的候选框进行进一步的分类以及调整边界框(基于proposals)
优点:检测准确率较高
二、R-CNN
原论文:Rich feature hierarchies for accurate object detection and semantic segmentation
R-CNN可以说是利用深度学习进行目标检测的开山之作。
2.1 R-CNN算法流程
RCNN算法流程可以分为4个步骤:
1.一张图像生成1k-2k个候选区域(使用Selective Search方法)
2.对每个候选区域,使用深度网络提取特诊
3.特征送入每一类的SVM分类器,判别是否属于该类
4.使用回归器精细修正候选框位置
2.1.1 候选区域的生成
利用Selective Search算法通过图像分割的方法得到一些原始区域,然后使用一些合并策略将这些区域合并,得到一个层次化的区域结构,而这些结构就包含着可能需要的物体。
2.1.2 深度网络提取特征
将2000候选区域缩放到227227pixel,接着将候选区域输入到事先训练好的AlexNet CNN网络获取4096维的特征得到20004096维矩阵。

2.1.3 SVM分类器判断类别
将2000* 4096维特征与20个svm组成的权值矩阵409620相乘,获得2000 20维矩阵表示每个建议框是某个目标分类的得分。分别对上述2000* 20维矩阵中的每一列即每一类进行非极大值抑制剔除重叠建议框,得到该列即该类中得分最高的一些建议框。
(这里一Pascal 数据集为例,存在20个类别)

非极大值抑制:
IoU:
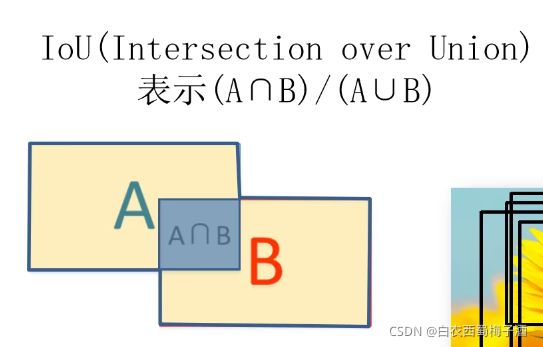
非极大值抑制剔除重叠建议框的具体步骤:
1)寻找得分最高的目标
2)计算其他目标与该目标的iou值
3)删除所有iou值大于给定阈值的目标
2.1.4 回归器精细修正候选框位置
对NMS处理后剩余的建议框进一步筛选,接着分别用20个回归器对上述20个类别中剩余的建议框进行回归操作,最终得到每个类别的修正后的得分最高的bounding box。
举例如下:

2.2 R-CNN框架

2.3 R-CNN中存在的问题
1.测试速度慢:
测试一张图片约53s(CPU),用Selective Search 算法提取候选框用时约2秒,一张图像内候选框之间存在大量重叠,提取特征操作冗余。
2.训练速度慢:
过程极其繁琐。
3.训练所需空间大:
对于SVM和bbox回归训练,需要从每个图像中的每个目标候选框提取特征,并写入磁盘。对于非常深的网络,如VGG16,从VOC07训练集上的5k图像上提取的特征需要数百GB的存储空间。
三、Fast R-CNN
原论文:Fast R-CNN
Fast R-CNN是作者Ross Girshick继R-CNN后的又一力作。同样使用VGG16作为网络的bacckbone,与R-CNN相比训练时间快乐9倍,测试推理时间快213倍,准确率从62%提升到了66%(Pascal VOC数据集上)。
3.1 Fast R-CNN 步骤
1)一张图像商城1k-2k个候选区域(使用Selective Search方法)
2)将图像输入网络得到相应的特征图,将ss算法生成的候选框投影到特征图上获得相应的特征矩阵
3)将每个特征矩阵通过POI pooling层缩放到7*7大小的特征图,接着将特征图展平通过一系列全连接层得到预测结果
(ROI ——Region of Interest 感兴趣区域)

3.2 详细流程
3.2.1 一次性计算整张图像特征
Fast-RCNN将整张图像送入网络,紧接着从特征图像上提取相应的候选区域。这些候选区域的特征不需要再重复计算。

3.2.2 ROI Pooling Layer
将候选区域图像分为77,对每块区域采用maxpooling,从而得到77的特征矩阵。
3.2.3 分类器
输出N+1个类别的概率(N为检测目标的种类,1为背景)共N+1个节点
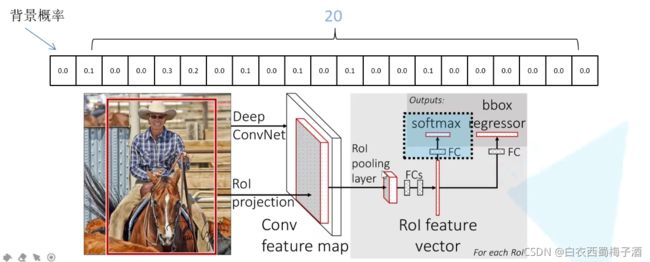
3.2.4 边界框回归器
输出对应的N+1个类别的候选边界框回归参数(dx,dy,dw,dh),共(N+1)*4个节点

如何获得具体的边界框:

相应的参数需要进行训练得到。
3.3 Fast R-CNN损失函数
多任务的损失:

3.3.1 分类损失

3.3.2 边界框回归损失

艾弗森括号:当u>=1时等于1,否则等于0,可以认为当为负样本时,此时不存在边界框损失。
补充:smooth L1 函数可参考如下:
回归损失函数
3.4 Fast R-CNN框架

四、Faster R-CNN
Faster R-CNN是作者Ross Girshick 继Fast R-CNN后的又一力作。同样使用VGG16作为网络的backbone,推理速度在GPU上达到5fps(包括候选区域的生成),准确率也有进一步的提升。在2015年的ILSVRC以及COCO竞赛中获得多个项目的第一名。
4.1 Faster R-CNN步骤
1)将图像输入网络得到对应的特征图
2)使用RPN结构生成候选框,将RPN生成的候选框投影到特征图得到对应的特征矩阵。
3)将每个特征矩阵通过ROI pooling 层缩放到7*7大小的特征图,接着将特征图展平通过一系列的全连接层得到预测结果。
(RPN+Fast R-CNN)
4.2 RPN
对于特征图上的每个3*3的滑动窗口,计算出滑动窗口中心点对应原始图像上的中心点,并计算出k个anchor boxes。
(其中k个anchor boxes 是给定的固定大小的边框)
对于每个窗口都会生成对应的2k个scores,即前景或者背景。
同时也会生成4k个边界框参数。
对应的anchor 面积和比例:
{128^2,
256^2
512 ^2 }
{1:1,1:2,2:1}
所以共有九个anchor。
由上述,可知对于一张10006003的图像,大约由60409(20k)个anchor,忽略跨越边界的anchor以后,剩下约6k个anchor。对于RPN生成的候选框之间存在大量重叠,基于候选框的cls得分,采用非极大值抑制,IoU设为0.7,这样每张图片只剩下2k个候选框。
4.2.1 采样
在训练中从所有anchor中选择256个样本,即128个正样本和128个负样本,如果正样本不够,则用负样本填充。
正样本的定义:与ground-truth box 的IoU大于0.7或者与其中某个ground-truch box有着最大的IoU。
负样本:与所有的ground-truth box 的IoU都小于0.3
4.2.2 RPN损失

分类损失:

边界框回归损失:

4.3 Faster R-CNN训练
直接采用RPN Loss +Fast R-CNN Loss的联合训练方法
原论文中采用的是分别训练RPN以及Fast R-CNN的方法
1)利用ImageNet预训练分类模型初始化前置卷积层网络参数,并开始单独训练RPN网路参数
2)给定RPN网络独有的卷积层和全连接层参数,在利用ImageNet预训练模型参数初始化前置卷积网络参数,并利用RNP网络生成的目标建议框去训练Fast RCNN网络参数
3)固定利用Fast RCNN训练好的前置卷积网络层参数,去微调RPN网络独有的卷积层和全连接层参数
4)同样保持固定前置卷积网络层参数,去微调Fast RCNN网络的全连接层参数,最后RPN网络和Fast RCNN网络共享前置卷积网络层参数,构成一个统一的网络。
4.4 Faster R-CNN框架


五、FPN
原论文: Feature Pyamid Networks for Object Detection