3.elasticsearch文档查询dsl
【README】
1.本文elasticsearch版本是 7.2.1;
2.文档查询语句叫做 DSL, domain structure language, 领域特定语言;dsl,参见 Query DSL | Elasticsearch Guide [7.2] | Elastic
3.elasticsearch 基于json 提供了完整的查询 DSL 语句(Domain Specific Language-领域特定语言)来定义查询,把查询的dsl看做一种查询的抽象语法树,包含两种类型的查询;
- 1.叶子查询子句:叶子查询子句在特定字段中寻找特定值,如匹配(match),术语(term)或范围查询(range) ;
- 2.复合查询子句: 复合查询子句包裹了其他叶子查询或复合查询,并以逻辑方式组合多个查询(如bool,dis_max 查询),或变更他们的行为(如 constant_score 不计算评分);
4.查询子句的行为不同,具体取决于它们是用于查询上下文还是过滤器上下文。
- 查询上下文:若查询条件的字段类型是字符串,则计算文档相关性分数;
- 过滤器上下文:若查询条件的字段类型是字符串,则不计算文档分数;
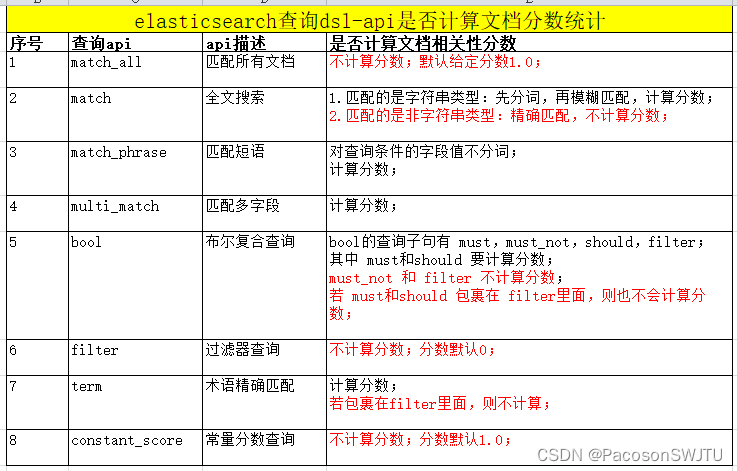
5.查询dsl api分类(包括但不限于,本文仅列出常用查询api);
- match_all,查询所有文档;
- match,全文检索(若字段是非字符串,则精确匹配,若是字符串类型,则是模糊匹配);
- match_phrase,短语匹配;
- multi_match,多字段匹配;
- bool,组合多个查询子句的复合查询,子句包括 must, must_not, should, filter 等;
- filter过滤器查询(不计算文档评分);
- term,术语查询(精确匹配);
- constant_score,常量分数查询(不计算文档分数);
6.本文es文档数据来源于 content-elasticsearch-deep-dive/accounts.json at master · linuxacademy/content-elasticsearch-deep-dive · GitHubMyles Elastic Certified Engineer Course. Contribute to linuxacademy/content-elasticsearch-deep-dive development by creating an account on GitHub. https://github.com/linuxacademy/content-elasticsearch-deep-dive/blob/master/sample_data/accounts.json,批量导入,参见 2.elasticsearch文档批量操作-bulk api_PacosonSWJTU的博客-CSDN博客
https://github.com/linuxacademy/content-elasticsearch-deep-dive/blob/master/sample_data/accounts.json,批量导入,参见 2.elasticsearch文档批量操作-bulk api_PacosonSWJTU的博客-CSDN博客
中的 “【2】bulk 批量导入样本数据章节”;
7.elasticsearch查询 dsl api 是否计算文档分数统计表:
【1】match_all ,查询所有文档
0)match_all 查询所有文档,给定文档分数为1.0 (不计算文档分数,给定1.0);
1)分页查询银行账户索引文档;
// 【sql】
Select firstname, balance
From bank
Order by balance desc
Limit 5 offset 0/5
// elasticsearch match_all api
Post localhost:9200/bank/_search
{
"_source":["firstname", "balance"]
,"query":{
"match_all":{}
}
, "sort":[
{
"balance":"desc"
}
]
, "from":5/0 // 文档偏移量为5 或者 0
, "size":5 // 每页5个文档
}
【2】match-全文检索
match匹配结果:返回与提供的文本、数字、日期或布尔值匹配的文档。
- 若匹配的字段类型是字符串,则在匹配之前会对查询条件的字符串进行分词(如hello world 会分词为 hello和 world两个单词);
- 匹配查询是执行全文搜索的标准查询,包括模糊匹配选项。
【2.1】精确匹配
1)match 匹配非字符串类型字段,就是精确匹配;
- 因为非字符串类型字段的值没有建立倒排索引(分词),值就是它本身;
2)查询余额等于 49568 的客户信息文档
Post localhost:9200/bank/_search
{
"_source":["firstname", "balance"]
,"query":{
"match":{
"balance":49568
}
}
}
{
"took": 18,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.0, // 评分默认为1,没有计算文档评分
"hits": [
{
"_index": "bank",
"_type": "account",
"_id": "168",
"_score": 1.0, // 评分默认为1,没有计算文档评分
"_source": {
"firstname": "Carissa",
"balance": 49568
}
}
]
}
}
【2.2】match-模糊匹配(计算文档评分)
0)match匹配字符串类型字段,就是模糊匹配;
1)查询地址包含 Kings 的银行客户文档
Post localhost:9200/bank/_search
{
"_source":["firstname", "balance","address"]
,"query":{
"match":{
"address":"Kings"
}
}
}
{
"took": 7,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 5.9908285,// 显然计算了文档评分
"hits": [
{
"_index": "bank",
"_type": "account",
"_id": "20",
"_score": 5.9908285,
"_source": {
"firstname": "Elinor",
"address": "282 Kings Place",
"balance": 16418
}
},
{
"_index": "bank",
"_type": "account",
"_id": "722",
"_score": 5.9908285,
"_source": {
"firstname": "Roberts",
"address": "305 Kings Hwy",
"balance": 27256
}
}
]
}
}
【小结】match的字段类型是字符串时 (注意match的字段类型是非字符串,则是精确匹配)
- 全文检索按照评分进行排序;
- 全文检索会对检索条件进行分词匹配;
【3】match_phrase 短语匹配 (不分词)
1)match_phrase短语匹配:把需要匹配的值当做一个整体单词(不分词)进行检索;
- 而match 模糊匹配: 把需要匹配的值先进行分词,然后检索;
2)match 全文检索例子(查询结果有19个文档)
Post localhost:9200/bank/_search
{
"_source":["firstname", "balance","address"]
,"query":{
"match":{
"address":"mill lane"
}
}
}
【解析】
- match 全文检索,会把 mill lane 分为2个单词,查询出包含2个单词中的一个即可;
3)match_phrase:短语匹配例子 (查询结果只有1个文档)
Post localhost:9200/bank/_search
{
"_source":["firstname", "balance","address"]
,"query":{
"match_phrase":{
"address":"mill lane"
}
}
}
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 9.507477,
"hits": [
{
"_index": "bank",
"_type": "account",
"_id": "136",
"_score": 9.507477,
"_source": {
"firstname": "Winnie",
"address": "198 Mill Lane",
"balance": 45801
}
}
]
}
}
【解析】match_phrase:把 mill lane 当做一个整体,不分词,送入es查询包含 mill lane的文档;
【4】multi_match 多字段匹配
1)场景: 查询出 state或address字段包含 mill 的文档;
Post localhost:9200/bank/_search
{
"_source":["firstname", "balance","address","state"]
,"query":{
"multi_match":{
"query":"mill"
, "fields":["state", "address"]
}
}
}
// 查询结果
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 5.4032025,
"hits": [
{
"_index": "bank",
"_type": "account",
"_id": "970",
"_score": 5.4032025,
"_source": {
"firstname": "Forbes",
"address": "990 Mill Road",
"balance": 19648,
"state": "AK"
}
},
......
}【4.1】多字段匹配给定的分词条件
1)场景: 查询出 state或address字段包含 mill 或 KY的文档;
{
"_source":["firstname", "balance","address","state"]
,"query":{
"multi_match":{
"query":"mill KY"
, "fields":["state", "address"]
}
}
}【5】bool复合查询(组合多个查询条件 )
【5.1】定义
1)bool 用来做复合查询;
- bool复合查询可以合并任何其他查询语句,包括复合语句;
- 复合语句之间可以相互嵌套,可以表达非常复杂的逻辑;
2)bool 复合查询可以包含的查询子句
- ① must(计算文档分数)
- ② must_not(不计算文档分数)
- ③ should(计算文档分数)
- ④ filter (不计算文档分数)
【5.2】bool复合查询例子
1)场景: 查询gender等于M,state等于KY,且 age不等于28,或者 lastname等于 Hancock的文档;
- should表示或者,如果匹配,则评分更高;
Post localhost:9200/bank/_search
{
"query":{
"bool":{
"must":[
{"match":{"gender":"M"}}
,{"match":{"state":"KY"}}
]
,"must_not":[
{"match":{"age":"28"}}
]
,"should":[
{"match":{"lastname":"Hancock"}}
]
}
}
}
// 查询结果
{
"took": 8,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 6,
"relation": "eq"
},
"max_score": 11.173532,
"hits": [
{
"_index": "bank",
"_type": "account",
"_id": "640",
"_score": 11.173532, // 计算文档得分
"_source": {
"account_number": 640,
"balance": 35596,
"firstname": "Candace",
"lastname": "Hancock",
"age": 25,
"gender": "M",
"address": "574 Riverdale Avenue",
"employer": "Animalia",
"email": "[email protected]",
"city": "Blandburg",
"state": "KY"
}
},
............................ 【6】filter过滤器(不计算文档分数)
1)filter 不计算文档分数 ;
- Bool复合查询中的must,should,must_not 被称为查询子句;
- 其中 must或should会计算相关性评分以表示一个文档对查询条件的匹配程度;分数越高,文档就越匹配查询条件;
- 但 must_not 被当做一个过滤器,过滤器不会计算文档匹配的分数;
【6.1】不用filter过滤器查询例子 (计算评分)
1)不用filter的查询(计算分数)
场景:查询年龄大于等于18,且小于等于30,且address包含mill的文档;
注意: match:{"address":"mill"} 表示的是 address包含mill,并不是address等于mill;
Post localhost:9200/bank/_search
{
"query":{
"bool":{
"must":[
{
"range":{
"age":{"gte":18,"lte":30}
}
}
, {
"match":{"address":"mill"}
}
]
}
}
}
// 查询结果
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 6.4032025,
"hits": [
{
"_index": "bank",
"_type": "account",
"_id": "970",
"_score": 6.4032025,// 计算分数
"_source": {
"account_number": 970,
"balance": 19648,
"firstname": "Forbes",
"lastname": "Wallace",
"age": 28,
"gender": "M",
"address": "990 Mill Road",
"employer": "Pheast",
"email": "[email protected]",
"city": "Lopezo",
"state": "AK"
}
}
]
}
}
【6.2】用filter过滤器查询(不计算分数)
1)用filter过滤器查询,就不会计算文档的相关性分数;
- 因为filter不计算分数,filter的查询性能优于 match匹配查询;
2)场景:查询年龄大于等于18,且小于等于30,且address包含mill的文档;
查询结果的分数为0.0,显然 filter不会计算分数;
Post localhost:9200/bank/_search
{
"query":{
"bool":{
"filter":[
{
"range":{
"age":{"gte":18,"lte":30}
}
}
, {
"match":{"address":"mill"}
}
]
}
}
}
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.0,
"hits": [
{
"_index": "bank",
"_type": "account",
"_id": "970",
"_score": 0.0, // 没有计算得分
"_source": {
"account_number": 970,
"balance": 19648,
"firstname": "Forbes",
"lastname": "Wallace",
"age": 28,
"gender": "M",
"address": "990 Mill Road",
"employer": "Pheast",
"email": "[email protected]",
"city": "Lopezo",
"state": "AK"
}
}
]
}
}
【6.3】把 filter 作为bool的查询子句
1)场景:查询 gender等于M,且state等于KY,且age不等于28,或者 lastname等于 Hancock,且 age在25到30之间的文档;
- 其中 must,should子句计算评分, must_not, filter 不计算评分;
Post localhost:9200/bank/_search
{
"query":{
"bool":{
"must":[
{"match":{"gender":"M"}}
,{"match":{"state":"KY"}}
]
,"must_not":[
{"match":{"age":"28"}}
]
,"should":[
{"match":{"lastname":"Hancock"}}
]
, "filter":{
"range":{
"age":{"gte":"25","lte":"30"}
}
}
}
}
}
// 查询结果
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 11.173532,
"hits": [
{
"_index": "bank",
"_type": "account",
"_id": "640",
"_score": 11.173532,
"_source": {
"account_number": 640,
"balance": 35596,
"firstname": "Candace",
"lastname": "Hancock",
"age": 25,
"gender": "M",
"address": "574 Riverdale Avenue",
"employer": "Animalia",
"email": "[email protected]",
"city": "Blandburg",
"state": "KY"
}
}
]
}
}
2)如何使得上述bool查询中的must,should 不计算分数呢 ?将其嵌套在 filter 里面,如下:
post localhost:9200/bank/_search
{
"query":{
"bool":{
"filter":{
"bool":{
"must":[
{"match":{"gender":"M"}}
,{"match":{"state":"KY"}}
]
,"must_not":[
{"match":{"age":"28"}}
]
,"should":[
{"match":{"lastname":"Hancock"}}
]
, "filter":{
"range":{
"age":{"gte":"25","lte":"30"}
}
}
}
}
}
}
}
// 查询结果
{
"took": 368,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.0,
"hits": [
{
"_index": "bank",
"_type": "account",
"_id": "640",
"_score": 0.0, // 显然没有计算文档分数
"_source": {
"account_number": 640,
"balance": 35596,
"firstname": "Candace",
"lastname": "Hancock",
"age": 25,
"gender": "M",
"address": "574 Riverdale Avenue",
"employer": "Animalia",
"email": "[email protected]",
"city": "Blandburg",
"state": "KY"
}
}
]
}
}【7】term查询(术语查询),精确匹配
1)定义:
- term查询返回给定字段包含精确值的文档;
2)注意:
- ① 避免对 text 字段进行term查询;
- ② 默认情况下,Elasticsearch 会在分析过程中更改文本字段的值(分词)。 这会使查找文本字段值的精确匹配变得困难。
- ③ 要查询 text字段,使用match(模糊查询);
3)term 与 match 区别:
- ① term: 精确查询(不分词);
- ② match: 模糊查询(查询字段的类型是字符串,要分词);
【7.1】term查询例子
1)场景1:查询 address 等于 574 Riverdale Avenue 的文档 ;
es文档中的address被分词了,而term查询对 574 Riverdale Avenue 进行精确查询(不分词),所以查无记录。
{
"query":{
"term":{
"address":"574 Riverdale Avenue"
}
}
}
// 为空。2)场景2:查询 address.keyword 等于 574 Riverdale Avenue 的文档 (查询 address不分词时 等于 574 Riverdale Avenue 的文档 )
{
"query":{
"term":{
"address.keyword":"574 Riverdale Avenue" // 这里匹配的是 address的keyword属性
}
}
}
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 6.5032897,
"hits": [
{
"_index": "bank",
"_type": "account",
"_id": "640",
"_score": 6.5032897,// 显然 term 要评分
"_source": {
"account_number": 640,
"balance": 35596,
"firstname": "Candace",
"lastname": "Hancock",
"age": 25,
"gender": "M",
"address": "574 Riverdale Avenue",
"employer": "Animalia",
"email": "[email protected]",
"city": "Blandburg",
"state": "KY"
}
}
]
}
}
【结果分析】
- 显然term精确匹配会计算评分,其经常嵌套在 filter里面,以不计算评分;
【7.2】address.keyword 与 match_phrase 区别
1)address.keyword 查无记录;因为是精确匹配(不分词);
场景:查询地址等于 574 Riverdale 的文档;
{
"query":{
"term":{
"address.keyword":"574 Riverdale"
}
}
}
// 查无记录 2)match_phrase 是部分匹配,包含 574 Riverdale 即可(有值);
{
"query":{
"match_phrase":{
"address":"574 Riverdale"
}
}
}
// 查询结果
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 12.492344,
"hits": [
{
"_index": "bank",
"_type": "account",
"_id": "640",
"_score": 12.492344,
"_source": {
"account_number": 640,
"balance": 35596,
"firstname": "Candace",
"lastname": "Hancock",
"age": 25,
"gender": "M",
"address": "574 Riverdale Avenue",
"employer": "Animalia",
"email": "[email protected]",
"city": "Blandburg",
"state": "KY"
}
}
]
}
}
【小结】
- 若是查询非 text字段,则使用term做精确查询;
- 若是查询 text字段,则使用 match来全文检索;
- 若使用match做精确匹配,则使用 field.keyword 进行;
- 若是查询 text字段的部分匹配(短语匹配,不对字符串不分词),则使用 match_phrase ;
【8】constant_socre 常量分数查询
1)constant_score 不计算分数;
2)constant_score 参数有2个:filter 和 boost;
- filter:必须有;filter查询不会计算相关性分数;为了加速性能,elasticsearch自动缓存频繁使用的 filter查询;
- boost:可选,浮点型,用于指定每个文档的分数,默认为1.0;
场景:查询年龄在大于等于25,且小于等于30的文档;
post localhost:9200/bank/_search
{
"query":{
"constant_score":{
"filter":{
"range":{
"age":{"gte":"25","lte":"30"}
}
}
}
}
}
// 查询结果
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 273,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "bank",
"_type": "account",
"_id": "13",
"_score": 1.0, // 显然,文档分数默认为1.0
"_source": {
"account_number": 13,
"balance": 32838,
"firstname": "Nanette",
"lastname": "Bates",
"age": 28,
"gender": "F",
"address": "789 Madison Street",
"employer": "Quility",
"email": "[email protected]",
"city": "Nogal",
"state": "VA"
}
},
......
} 参考自: Constant score query | Elasticsearch Guide [7.2] | Elastic https://www.elastic.co/guide/en/elasticsearch/reference/7.2/query-dsl-constant-score-query.html
https://www.elastic.co/guide/en/elasticsearch/reference/7.2/query-dsl-constant-score-query.html