贝叶斯定理
目录
一、概念
1.贝叶斯方法的提出
2.简要思想
二、贝叶斯定理
三、贝叶斯的应用
1. 计算P( Julw | Judy )
2. 计算P(Julw|July)和P(Julw|Jula)
3.计算P(word|Julw)
一、概念
朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法 。最为广泛的两种分类模型是决策树模型(Decision Tree Model)和朴素贝叶斯模型(Naive Bayesian Model,NBM)。
和决策树模型相比,朴素贝叶斯分类器(Naive Bayes Classifier,或 NBC)发源于古典数学理论,有着坚实的数学基础,以及稳定的分类效率。同时,NBC模型所需估计的参数很少,对缺失数据不太敏感,算法也比较简单。理论上,NBC模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为NBC模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的,这给NBC模型的正确分类带来了一定影响。
1.贝叶斯方法的提出
托马斯·贝叶斯Thomas Bayes(1702-1763)在世时,并不为当时的人们所熟知,很少发表论文或出版著作,与当时学术界的人沟通交流也很少,用现在的话来说,贝叶斯就是活生生一民间学术“屌丝”,可这个“屌丝”最终发表了一篇名为“An essay towards solving a problem in the doctrine of chances”,翻译过来则是:机遇理论中一个问题的解。你可能觉得我要说:这篇论文的发表随机产生轰动效应,从而奠定贝叶斯在学术史上的地位。
事实上,上篇论文发表后,在当时并未产生多少影响,在20世纪后,这篇论文才逐渐被人们所重视。对此,与梵高何其类似,画的画生前一文不值,死后价值连城。
2.简要思想
长久以来,人们对一件事情发生或不发生的概率,只有固定的0和1,即要么发生,要么不发生,从来不会去考虑某件事情发生的概率有多大,不发生的概率又是多大。而且概率虽然未知,但最起码是一个确定的值。比如如果问那时的人们一个问题:“有一个袋子,里面装着若干个白球和黑球,请问从袋子中取得白球的概率是多少?”他们会想都不用想,会立马告诉你,取出白球的概率就是1/2,要么取到白球,要么取不到白球,即θ只能有一个值,而且不论你取了多少次,取得白球的概率θ始终都是1/2,即不随观察结果X 的变化而变化。
这种频率派的观点长期统治着人们的观念,但是: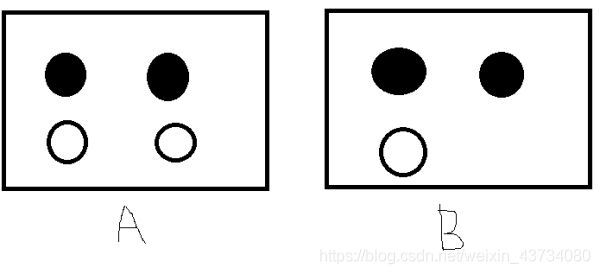
假设我们有如下的7个球在A,B两个框中,如果我们随便取一个球,已知取到的球来自B框中,那么这个球是白球的概率是多少呢?或者问去除的球是白色,那么取自B框的概率是多少呢?这个问题不是很好解决,直到后来Thomas Bayes的人物出现。
回到上面的例子:“有一个袋子,里面装着若干个白球和黑球,请问从袋子中取得白球的概率θ是多少?”贝叶斯认为取得白球的概率是个不确定的值,因为其中含有机遇的成分。比如,一个朋友创业,你明明知道创业的结果就两种,即要么成功要么失败,但你依然会忍不住去估计他创业成功的几率有多大?你如果对他为人比较了解,而且有方法、思路清晰、有毅力、且能团结周围的人,你会不由自主的估计他创业成功的几率可能在80%以上。这种不同于最开始的“非黑即白、非0即1”的思考方式,便是贝叶斯式的思考方式。
继续深入讲解贝叶斯方法之前,先简单总结下频率派与贝叶斯派各自不同的思考方式:
频率派把需要推断的参数θ看做是固定的未知常数,即概率θ虽然是未知的,但最起码是确定的一个值,同时,样本X 是随机的,所以频率派重点研究样本空间,大部分的概率计算都是针对样本X 的分布;
而贝叶斯派的观点则截然相反,他们认为参数θ是随机变量,而样本X 是固定的,由于样本是固定的,所以他们重点研究的是参数θ的分布。
相对来说,频率派的观点容易理解,所以下文重点阐述贝叶斯派的观点。
贝叶斯派既然把θ看做是一个随机变量,所以要计算θ的分布,便得事先知道θ的无条件分布,即在有样本之前(或观察到X之前),θ有着怎样的分布呢?
比如往台球桌上扔一个球,这个球落会落在何处呢?如果是不偏不倚的把球抛出去,那么此球落在台球桌上的任一位置都有着相同的机会,即球落在台球桌上某一位置的概率服从均匀分布。这种在实验之前定下的属于基本前提性质的分布称为先验分布,或无条件分布。
至此,贝叶斯及贝叶斯派提出了一个思考问题的固定模式:
先验分布 π(θ)+ 样本信息χ⇒ 后验分布π(θ|x)
上述思考模式意味着,新观察到的样本信息将修正人们以前对事物的认知。换言之,在得到新的样本信息之前,人们对的认知是先验分布 π(θ),在得到新的样本信息后χ,人们对θ的认知为π(θ|x)。
而后验分布π(θ|x)一般也认为是在给定样本χ的情况下θ的条件分布,而使达到最大的值称为最大后θMD验估计,类似于经典统计学中的极大似然估计。
综合起来看,则好比是人类刚开始时对大自然只有少得可怜的先验知识,但随着不断是观察、实验获得更多的样本、结果,使得人们对自然界的规律摸得越来越透彻。所以,贝叶斯方法既符合人们日常生活的思考方式,也符合人们认识自然的规律,经过不断的发展,最终占据统计学领域的半壁江山,与经典统计学分庭抗礼。
此外,贝叶斯除了提出上述思考模式之外,还特别提出了举世闻名的贝叶斯定理。
二、贝叶斯定理
在引出贝叶斯定理之前,先学习几个定义:
边缘概率(又称先验概率):某个事件发生的概率。边缘概率是这样得到的:在联合概率中,把最终结果中那些不需要的事件通过合并成它们的全概率,而消去它们(对离散随机变量用求和得全概率,对连续随机变量用积分得全概率),这称为边缘化(marginalization),比如A的边缘概率表示为P(A),B的边缘概率表示为P(B)。
联合概率表示两个事件共同发生的概率。A与B的联合概率表示为P(A∩B)或者P(A,B)。
条件概率(又称后验概率):事件A在另外一个事件B已经发生条件下的发生概率。条件概率表示为P(A|B),读作“在B条件下A的概率”。
接着,考虑一个问题:P(A|B)是在B发生的情况下A发生的可能性。
-
首先,事件B发生之前,我们对事件A的发生有一个基本的概率判断,称为A的先验概率,用P(A)表示;
-
其次,事件B发生之后,我们对事件A的发生概率重新评估,称为A的后验概率,用P(A|B)表示;
-
类似的,事件A发生之前,我们对事件B的发生有一个基本的概率判断,称为B的先验概率,用P(B)表示;
-
同样,事件A发生之后,我们对事件B的发生概率重新评估,称为B的后验概率,用P(B|A)表示。
贝叶斯定理便是基于下述贝叶斯公式:
![]()
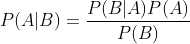
上述公式的推导其实非常简单,就是从条件概率推出。
根据条件概率的定义,在事件B发生的条件下事件A发生的概率是
![]()
同样地,在事件A发生的条件下事件B发生的概率
![]()
整理与合并上述两个方程式,便可以得到:
![]()
同时可以这样理解
P(规律|现象)=P(现象|规律)P(规律)/P(现象)
三、贝叶斯的应用
经常在网上搜索东西的朋友知道,当你不小心输入一个不存在的单词时,搜索引擎会默认按照正确的词帮你搜索,比如当你在Google中输入“Julw”时,系统会猜测你的意图是搜索“July”。谷歌在墙外,我们暂时百度做为案例,如下图所示:
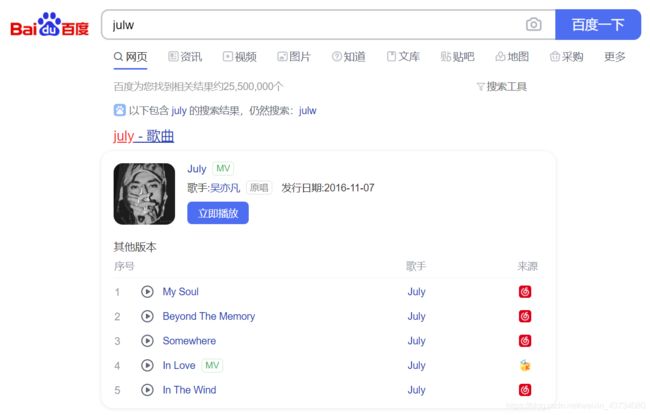
这叫做拼写检查。根据谷歌员工写的一篇文章,拼写检查是基于贝叶斯方法。下面让我们看看如何使用贝叶斯实现'拼写检查'。原文:How to Write a Spelling Corrector
首先我们先要制作一个词典。我们将全网的大量文章收集起来,整理出里面出现过的单词,并标记每个词出现的次数(频数)。这有点像大学考四六级的时候死记硬背的《四六级词汇分频速记手册》。

用户输入一个单词时,我们先看看用户输入的这个词字是不是在词典里面。如果不存在,那就要找出每个候选词,并且比较他们的符合条件的概率,将概率最大的推荐给用户。如下图所示,用户输入“julw”,程序没有在字典中找到相应的词,但找出了3个候选的正确词。
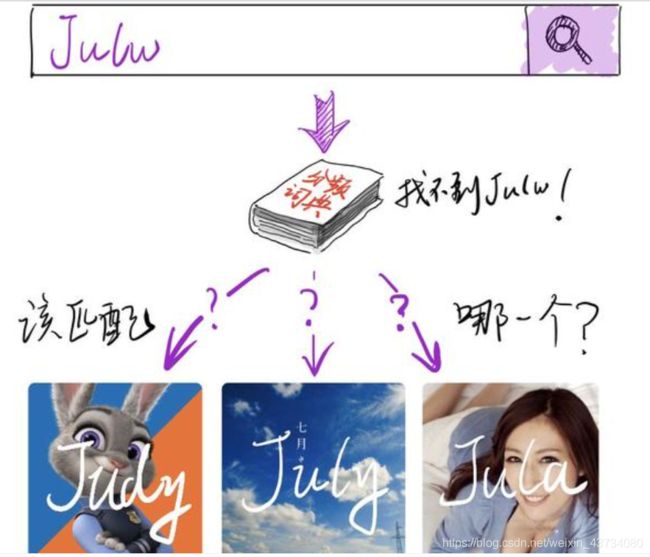
Judy:朱迪,迪士尼动画明星,词频是1000
July:七月,词频是900
Jula:Jula,演员, 2015年参演电影《城堡》。
从词频上看,Judy出现最多,Jula出现得最少。那么是不是应该推荐“Judy”这个词给用户呢?显然也是有问题的,我们肉眼可以明显看出“July”与“Julw”的这个词会更加接近。但是如何严谨地判断呢?
我们切换到数学思维,这个问题本质上就是在用户输入“julw”的条件下,比较每个备选词的出现的概率,找出概率最大那个推荐给用户。也就是求![]() ,这就要用到贝叶斯定理了。
,这就要用到贝叶斯定理了。
![]()
每个备选词在词典中概率,可以通过该词的词频除以所有词频来计算,我们用Q代表词频,如下面公式:
![]()
因为用户输入是统一的,词典也是统一的,把式子化简后惊喜地发现,我们只要知道P( 备选词 | Julw )和Q(备选词)就好了。如下图:
![]()
![]()
![]()
比较![]() 大小,就转化为比较
大小,就转化为比较 ![]() 大小问题。因为词频是词典已知的,那现在核心问题就是怎么计算
大小问题。因为词频是词典已知的,那现在核心问题就是怎么计算![]() :
:
1. 计算P( Julw | Judy )
Judy 变成要Julw要有两步,分别把d和y变成l和w,利用我们上个博客讲到的编辑距离算法,得到结果就是2:
def minEditDist(sm,sn):
m,n = len(sm)+1,len(sn)+1
# create a matrix (m*n)
matrix = [[0]*n for i in range(m)]
matrix[0][0]=0
for i in range(1,m):
matrix[i][0] = matrix[i-1][0] + 1
for j in range(1,n):
matrix[0][j] = matrix[0][j-1]+1
cost = 0
for i in range(1,m):
for j in range(1,n):
if sm[i-1]==sn[j-1]:
cost = 0
else:
cost = 1
matrix[i][j]=min(matrix[i-1][j]+1,matrix[i][j-1]+1,matrix[i-1][j-1]+cost)
return matrix[m-1][n-1]
mindist=minEditDist("Judy","Julw")
mindist我们可以设想一个抽奖机,拉动开关以后,除自己以外的25个字母随机轮换然后停下。把y变成w的概率为 1/25;同理把d变成l概率也是 1/25。故![]()
2. 计算P(Julw|July)和P(Julw|Jula)
July和Jula变成Julw需要一步——换掉最后一个字母变成w,这步操作的概率为1/25
![]()
3.计算P(word|Julw)
![]()
![]()
![]()
![]()
我们根据计算结果重新排个序:
 因此,我们会推荐“July”给用户。
因此,我们会推荐“July”给用户。