左手Python右手Excel,玩转数据透视表哪家强?
数据透视表
什么是数据透视表?对于大多数才开始使用Excel组件的用户来说,可能只是听说过数据透视表,至于数据透视表具体用来做什么,以及它会给实际工作带来什么便利,估计就有很多人不是很清楚了。
数据透视表是一种可以快速汇总、分析和处理大量数据的交互式工具。
简单来说,数据透视表可以从不同角度对相同的数据进行处理和分析,以查看不同层面的数据结果,从而得到想要的数据信息。
形象点来说, 数据透视表就像一个万花筒,通过旋转这个特别的万花筒,可以从中获得不断变化的事物细节,但是事物的本身其实并未发生变化,数据透视表这个特别的万花筒只是一个工具,只不过通过该工具可以获得普通事物的独特视图。
适用场景:
表格中数据量较大时
表格中的数据结构不断变化时
当需要源数据与分析结果的更新保持一致时
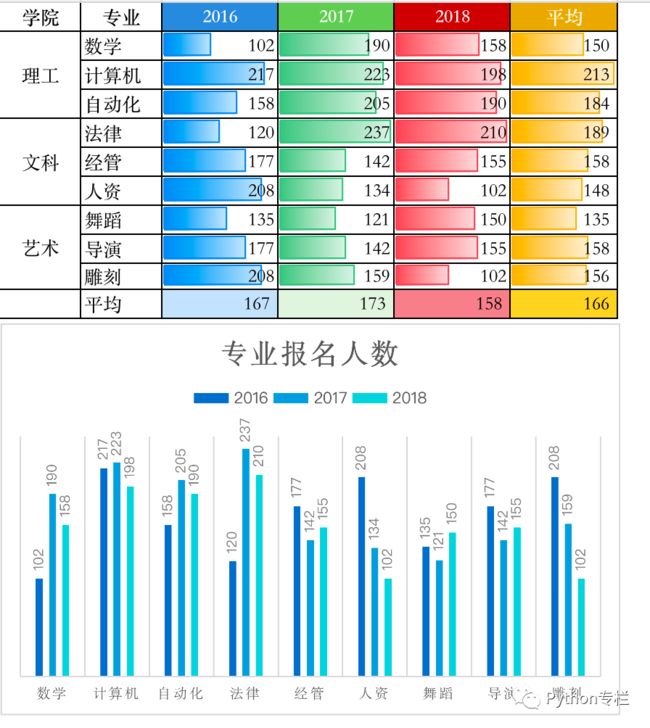
数据透视表我们给大家区分了一下段位(青铜、黄金、钻石、王者),本次从小白到青铜段位。先来一波效果图
黄金段位:
钻石段位:
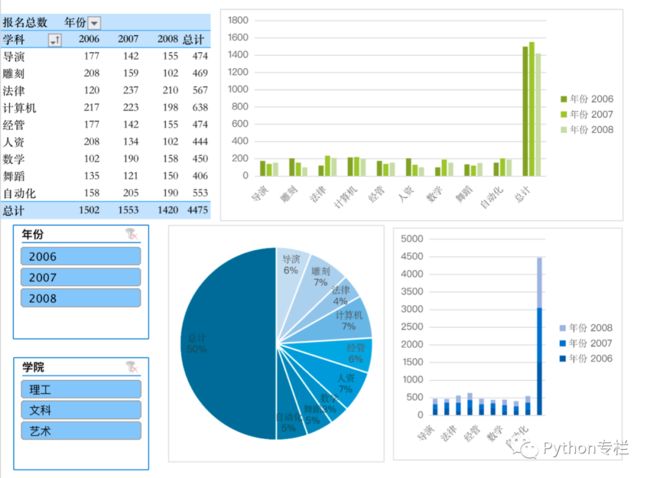
王者段位:

透视表术语介绍
-
数据源
指的是用来创建数据透视表的原始数据内容,原始数据既可以来自现有工作表,也可以从外部数据库中获取。
比如下图就是一部分数据源(也有称作:源数据):
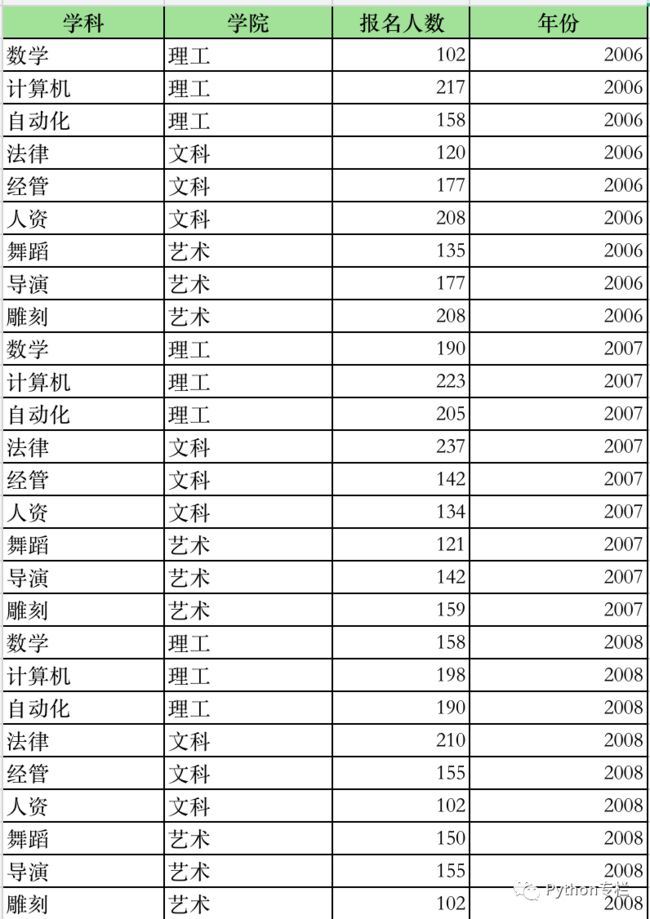
-
字段
在上图中每一列的第一个单元格内容都为该列的数据分类,在生成数据透视表后,这些数据就是我们所说的字段
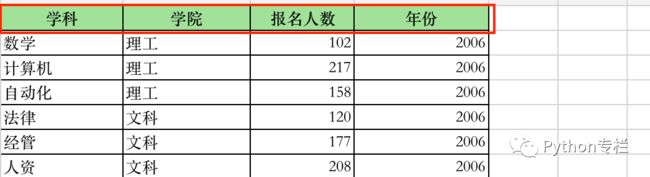
-
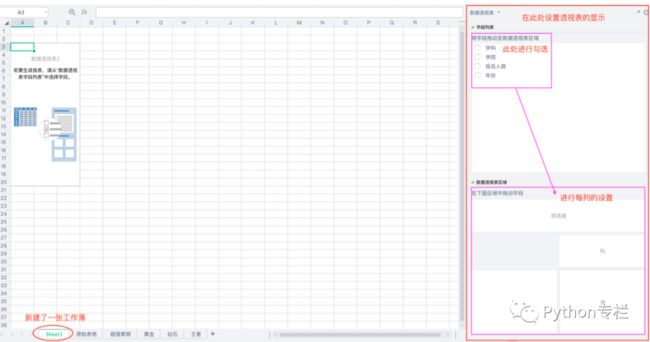
字段列表和字段设置区域
在插入了一个数据透视表后,工作表的右侧会同时出现一个名为“数据透视表字段”的任务窗格。(没有安装office,此处以wps为例介绍)

Excel的数据透视表使用
我们将上面的数据在Excel表格中创建一个透视表具体使用步骤如下:
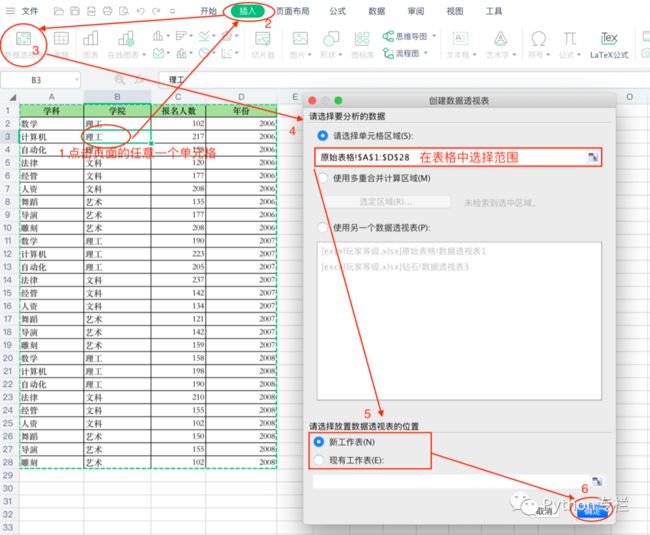
接下来会打开一张表格:
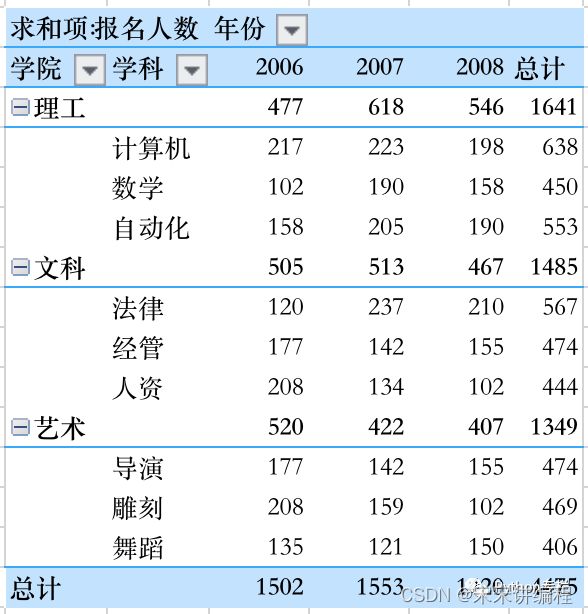
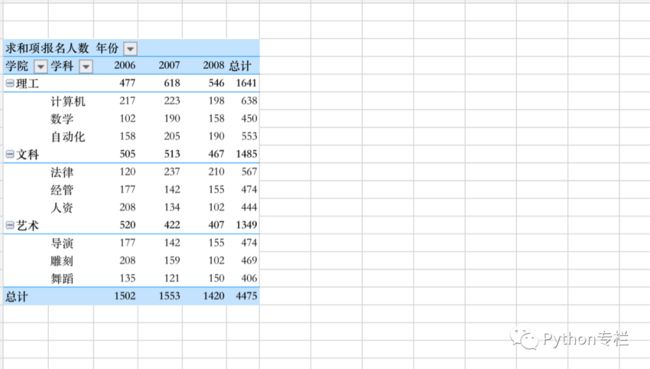
比如我们要得到的最终结果是:
则需要在数据透视表的设置区域进行如下操作:
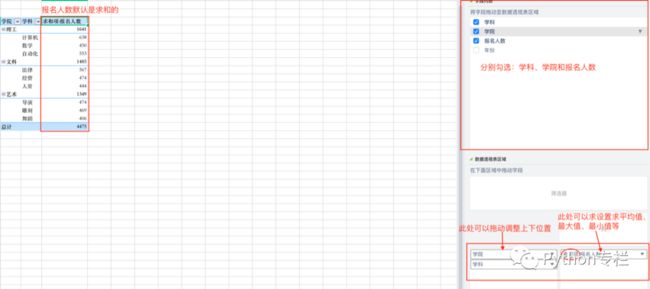
接下来是年份的设置,大家可以看到最终的结果图是将年份内容设置到了列上。
最终效果:
Python操作这些数据最大的亮点是:数据量非常多的时候更有优势。
Python操作数据实现透视表功能
数据透视表的制作我们使用Pandas中的pivot_table完成,具体语法如下:
pivot_table(data, # DataFrame
values=None, # 值
index=None, # 分类汇总依据
columns=None, # 列
aggfunc='mean', # 聚合函数
fill_value=None, # 对缺失值的填充
margins=False, # 是否启用总计行/列
dropna=True, # 删除缺失
margins_name='All' # 总计行/列的名称
)
首先读取数据:
import os
import numpy as np
import pandas as pd
df = pd.read_excel('excel玩家等级.xlsx', sheet_name='原始表格' )
df
结果:

通过pivot_table来制作透视表:
# 透视数据
df_p = df.pivot_table(index=['学院','学科'], # 透视的行,分组依据
columns='年份', # 设置列为年份
values='报名人数', # 值
aggfunc='sum' # 聚合函数
)
df_p

添加总计列:
df_p.columns=['2006','2007','2008']
df_p['总计'] = df_p.sum(axis=1)
df_p
结果:
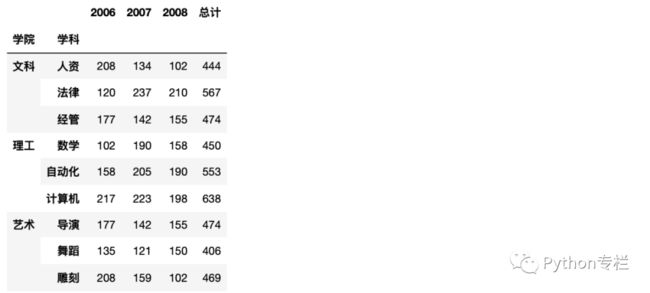
最后追加一行总计数据行
result = df_p.sum(axis=0) # 此时是一个Series对象
result['学院'] = '总计' # 添加数据
result['学科'] =''
# 对result进行转置
df_1 = pd.DataFrame(data=result)
df2 = df_1.T
df2.set_index(['学院','学科'],inplace=True)
# 在df_p上添加一行
df_p = df_p.append(df2)
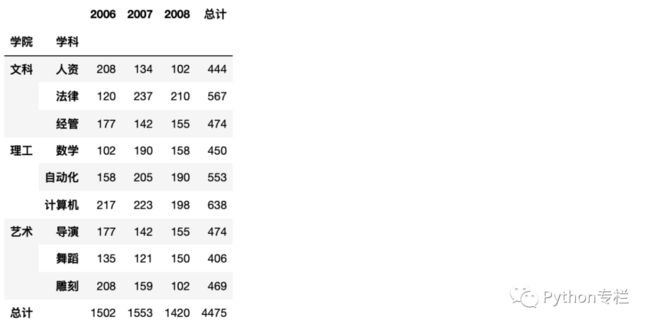
这样我们就得到了同样的效果。
扫码添加请备注:python,进群与宋老师面对面交流:517745409
