(转)【重磅】无监督学习生成式对抗网络突破,OpenAI 5大项目落地
【重磅】无监督学习生成式对抗网络突破,OpenAI 5大项目落地
【新智元导读】“生成对抗网络是切片面包发明以来最令人激动的事情!”LeCun前不久在Quroa答问时毫不加掩饰对生成对抗网络的喜爱,他认为这是深度学习近期最值得期待、也最有可能取得突破的领域。生成对抗学习是无监督学习的一种,该理论由 Ian Goodfellow 提出,此人现在 OpenAI 工作。作为业内公认进行前沿基础理论研究的机构,OpenAI 不久前在博客中总结了他们的5大项目成果,结合丰富实例介绍了生成对抗网络,并对OpenAI 五大落地项目进行梳理,包括完善对抗生成网络(GAN)、完善变分推断(VAE)、提出GAN的扩展 InfoGAN,以及提出生成对抗模仿学习及代码。

OpenAI 旨在开发能够让计算机理解世界的算法和技术。
我们常会忽略自己对周遭世界的理解:你知道世界由三维环境构成,物体可以移动、碰撞、相互作用;人能行走、说话、思考;动物会吃草、飞翔、奔跑或者鸣叫;屏幕会显示经过编码的信息,内容涉及天气、篮球赛的结果或者 1970 年的事情。
这些海量信息就在那里,大都触手可及——其存在形式要么是现实世界中的原子,要么是数字世界里的比特。唯一的问题是如何设计模型和算法,分析和理解这些宝贵的数据。
生成模型是实现这一目标最值得期待的方法。训练生成模型,首先要大量收集某种数据(比如成千上万的图像、句子或声音),然后训练一个模型,让这个模型可以生成这样的数据。
其原理是费曼的名言:“做不出来就没有真正明白。”(What I cannot create, I do not understand.)
用于生成模型的神经网络,很多参数都远远小于用于训练的数据的量,因此模型能够发现并有效内化数据的本质,从而可以生成这些数据。
生成式模型有很多短期应用。但从长远角度看,生成模型有望自动学会数据集的类型、维度等特征。
生成图像
举个例子,假设有某个海量图像数据集,比如含有 120 万幅图像的 ImageNet 数据集。如果将每幅图的宽高设为 256,这个数据集就是 1200000*256*256*3(约 200 GB)的像素块。其中的一些样例如下:

这些图像是人类肉眼所见的样子,我们将它们称为“真实数据分布中的样本”。现在我们搭建生成模型,训练该模型生成类似上图的图像,在这里,这个生成模型就是一个输出为图像的大型神经网络,这些输出的图像称为“模型样本”。
DCGAN
Radford 等人提出的 DCGAN 网络(见下图)就是这样一个例子。DCGAN 网络以 100 个从一个高斯分布中采样的随机数作为输入(即代码,或者叫“隐含变量”,靠左红色部分),输出图像(在这里就是 64*64*3 的图像,靠右绿色部分)。当代码增量式变化时,生成的图像也随之变化——说明模型已经学会了如何描述世界,而不是仅仅是记住了一些样本。
网络(黄色部分)由标准的卷积神经网络(CNN)构成:
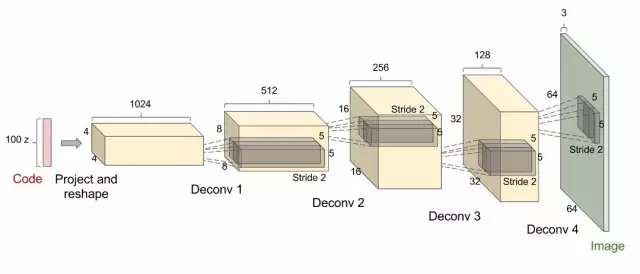
DCGAN 使用随机权重初始化,所以随机代码输入会生成一个完全随机的图像。但是,这个网络有好几百万的参数可以调整,而我们的目的是设置参数,让根据随机代码输入产生的样本与训练数据看上去相似。换句话说,我们想要模型分布与图像空间中真实数据的分布相匹配。
训练生成模型
假设我们使用最新初始化的网络生成 200 幅图,每次都从不同的随机代码开始。问题是:我们该如何调整网络的参数,让每次输出的新图像都更接近理想?需要注意的是,这里并非监督学习场景,我们也没有对 200 幅输出图像设定明确的预期;我们只是希望这些图像看起来跟真实的一样。
一个巧妙的处理方式是依照生成对抗网络(Generative Adversarial Network,GAN)方法。这里,我们引入另一个判别器网络(discriminator network,通常是一个标准的卷积神经网络),判断输入的图像是真实的还是生成的。我们可以将 200 幅生成的图像和 200 幅真实图像用作训练数据,将这个判别器训练成一个标准的分类器,其功能就是区分这两种不同的图像。
此外,我们还可以经由判别器和生成器反向传播(backpropagate),找出应该如何改变生成器的参数,使其生成的 200 幅样本对判别器而言混淆度更大。这两个网络就形成了一种对抗:判别器试着从伪造图像中区分出真实图像,而生成器则努力产生可以骗过判别器的图像。最后,生成器网络输出的结果就是在判别器看来无法区分的图像。
下图展示了两种从生成模型采样的过程。两种情况下,输入都是有噪声和混乱的,经过一段时间收敛,可以得到较为可信的图像统计:

VAE 学会产生图像(log time)

GAN 学会产生图像(linear time)
这令人兴奋——这些神经网络正在逐渐学会世界看起来是什么样子的!这些模型通常只有 10 亿参数,所以一个在 ImageNet 上训练的网络(粗略地)将 200GB 的像素数据压缩到 100MB 的权重。这让模型得以发现数据最主要的特征:例如,模型很可能学会位置邻近的像素更有可能拥有同样的颜色,或者世界是由水平或竖直的边构成。
最终,模型可能会发现很多更复杂的规律:例如,图像中有特定类型的背景、物体、纹理,它们会以某种可能的排列方式出现,或者在视频中随时间按某种方式变化等等。
更泛化的表现形式
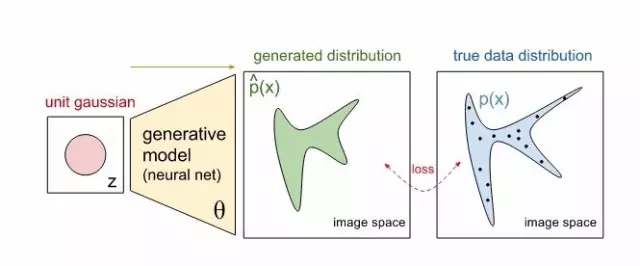
数学上看,我们考虑数据集 x1,…,xn 是从真实数据分布 p(x) 中的一段。下图中,蓝色区域展示了一部分图像空间,这部分空间以高概率(超过某阈值)包含真实图像,而黑色点表示数据点(每个都是数据集中一副图像)。现在,我们的模型同样刻画了一个分布 p^θ(x) (绿色),将从一个单位 Gaussian 分布 (红色) 获得的点,通过一个(判别器)神经网络映射,得到了生成模型 (黄色)。
我们的网络是参数为 θ 的函数,调整这些参数就能改变生成出的图像分布。目标是找到参数 θ 可以产生一个较好匹配真实数据分布的分布。因此,你可以想象绿色分布从随机开始,然后训练过程迭代式改变参数 θ 拉长和压缩自己使得更匹配蓝色分布。
生成模型三种搭建方法
大多数生成模型有一个基础的设置,只是在细节上有所不同。下面是生成模型的三个常用方法:
-
Generative Adversarial Network(GAN)这个我们在上面讨论过了,将训练过程作为两个不同网络的对抗:一个生成器网络和一个判别器网络,判别器网络试图区分样来自于真实分布 p(x) 和模型分布 p^(x) 的样本。每当判别器发现两个分布之间有差异时,生成器网络便微整参数,使判别器不能从中找到差异。
-
Variational Autoencoders(VAE)让我们可以在概率图模型框架下形式化这个问题,我们会最大化数据的对数似然(log likelihood)的下界
-
PixelRNN 等自回归模型。训练一个建模了给定前面像素下每个独立像素条件分布的网络(从左到右,从上到下). 这类似于将图像的像素输入到一个 char-rnn,但是 RNN 水平和垂直遍历图像,而不是 1D 的字符序列
所有这些方法有各自的优缺点。例如,变分自编码器可以执行学习和在复杂的包含隐含变量的概率图模型上进行高效贝叶斯推断(如 DRAW 或者 Attend Infer Repeat 近期相对复杂的模型)。但是,生成的样本会有些模糊不清。GAN 目前生成了清楚的图像,但是因为不稳定的训练动态性很难优化。PixelRNN 有一个非常简单和稳定的训练过程(softmax loss),并且当前给出了最优的对数似然(产生出数据的可信程度)。然而,PixelRNN 在采样时相对低效,而且没有给图像以简单的低维代码。
OpenAI 5 大落地
我们对 OpenAI 做出的生成式模型非常兴奋,刚刚发布了四个对近期工作项目改进工作. 对每个贡献,我们同样发布了技术报告和源代码.
1. 完善对抗生成网络(GAN)
GAN 是非常值得期待的生成模型,不像其他方法,GAN 产生的图像干净、清晰,并且能够学会与纹理有关的代码。然而,GAN 被构建成两个网络之间的对抗,保持平衡十分重要(而且相当考验技巧):两个网络可能在解析度之间震荡,生成器容易崩溃。
Tim Salimans, Ian Goodfellow, Wojciech Zaremba 等人引入了一些新技巧,让 GAN 训练更加稳定。这些技巧让我们能够放大 GAN ,获得清晰的 128*128 ImageNet 样本:

[左]真实图像(ImageNet);[右]生成的图像
我们 CIFAR-10 的样本看起来也是非常清晰的——Amazon 为图像打标签的工人(Amazon Mechanical Turk workers)在区分这些图像和真实图像时,错误率为 21.3% (50% 的错误率代表随机猜测)。

[左]真实图像(CIFAR-10);[右]生成的图像
除了生成更好的图像,我们还引入了一种结合 GAN 和半监督学习的方法。这使我们在不需要大量带标签样本的前提下,在 MNIST、SVHN 和 CIFAR-10 获得当前最佳的结果。在 MNIST,我们对每个类仅有 10 个带标签的样本,使用了一个全连接的神经网络,达到了 99.14% 的准确率——这个结果接近已知最好的监督学习,而后者使用了 6 万个带标签的样本。由于为样本打标签非常麻烦,所以上述方法是很值得期待的。
生成对抗网络是两年多前才提出来的,我们期望在未来出现更多提升其训练稳定性的研究。
2. 完善变分推断(VAE)
在这项工作中,Durk Kingma 和 Tim Salimans 引入了一个灵活、可扩展的计算方法,提升变分推断的准确率。目前,大多数 VAE 训练采用暴力近似后验分布(approximate posterior),每个隐含变量都是独立的。最近的扩展工作虽然解决了这个问题,但由于引入的序列依赖,在计算上仍然称不上高效。
这项工作的主要贡献是“逆自递归流”(Inverse Autoregressive Flow,IAF),这种方法使 rich approximate posterior 能够并行计算,从而高度灵活,可以达到近乎随机的任意性。
我们在下面的图中展示了一些 32*32 的图像样本。前一幅是来自 DRAW 模型的早期样本(初级 VAE 样本看起来更差和模糊)。DRAW 模型一年前才发表的,由此也可以感受到训练生成模型的发展迅速。

[左]用 IAF 训练 VAE 生成的图像;[右]DRAW 模型生成的图像
3. InfoGAN
Peter Chen 等人提出了 InfoGAN ——GAN 的扩展。普通的 GAN 通过在模型里重新生成数据分布,让模型学会图像的disentangled 和 interpretable 表征。但是,其 layout 和 organization 是 underspecified。
InfoGAN 引入了额外的结构,得到了相当出色的结果。在三维人脸图像中,改变代码的一个连续维度,保持其他维度不变,很明显从每张图片给出的 5 行例子中,代码的 resulting dimension 是可解释的,模型在事先不知道摄像头角度、面部变化等特征存在的前提下,可能已经理解这些特征是存在的,并且十分重要:

(a)pose (b)Elevation

(c)Lighting (d)Wide or Narrow
同时,值得一提的是,上述方法是非监督学习的方法。 因此,相比通过监督学习的方法实现了同样结果的思路,这种方法体现出了更高的水平。
3. 生成模型的深度强化学习(两项)
下面是两个强化学习场景下(另一个 OpenAI 聚焦的领域),生成式模型的完善:Curiosity-driven Exploration in Deep Reinforcement Learning via Bayesian Neural Networks。
在高维度连续空间中进行高效的探索是当前强化学习尚未解决的一个难题。没有有效的探索方法,智能体只能到处乱闯直到碰巧遇到奖励。若要对高维行动空间进行探索(比如机器人),这些算法是完全不够的。这篇论文中,Rein Houthooft 等人提出了 VIME,一个使用生成模型对不确定性进行探索的实用方法。
VIME 让智能体本身驱动;它主动地寻求意外的状态-行动。作者展示了 VIME 可以提高一系列策略搜索方法,并在更多稀疏奖励的实际任务(比如智能体需要在无指导的情形下学习原始行动的场景)取得了显著改进。

用 VIME 训练的策略

没有受训的策略
4. 生成对抗模仿学习
Jonathan Ho 等人提出了一个新的模仿学习(imitation learning)方法。Jonathan Ho 在斯坦福大学完成了这项工作的主要内容,他作为暑期实习生加入 OpenAI 后,结合 GAN 以及 RL 等相关工作的启发,最终完成了生成对抗模仿学习及代码。
标准的强化学习场景通常需要设计一个规定智能体预期行为的奖励函数。但实际情况是,有样做有时候会为了实现细节上的正确,而引入代价过高的试错过程。相较而言,模仿学习中,智能体从样本展示中学习,就免去了对奖励函数的依赖。
常用模仿方法包含两个阶段的流程:首先学习奖励函数,然后依照奖励函数执行深度强化学习。这样的过程非常缓慢,也由于这种间接性方法,很难保证结果策略的质量。这项工作展示了如何通过 GAN 直接从数据中抽取策略。这个方法在 OpenAI Gym 环境中可以根据专家表现进行策略学习。
展望未来
生成模型是快速发展的研究领域。在完善这些模型,扩展训练和数据集的同时,我们完全可以认为最终将会产生能够以假乱真的图像或视频样本。这可以用很多应用, 图像降噪(image denoising)、inpainting、高清分辨率(super-resolution)、结构化预测(structured prediction)、强化学习探索(exploration in reinforcement learning),以及神经网络预处理这些为数据打标签的很复杂、造价很高的领域,有很多潜力。
这项工作更深的启示是,在训练生成模型的过程中,我们最终会增进计算机对世界及其构成的理解。