猿创征文|TiDB架构解析和注意事项
TiDB 简介
TiDB是一款开源的分布式HTAP数据库,同时支持TP(Transactional Processing)的在线事务处理,也支持AP(Analytical Processing)的在线分析处理。
实际使用下来的感受:TP场景的高并发确实非常优秀,但是AP场景的分析能力相对专业的AP数据库还是存在一些不足之处。
TiDB的最大亮点:通过 Multi-Raft Learner 协议将TiKV的数据实时复制到TiFlash,确保行存储引擎 TiKV 和列存储引擎 TiFlash 之间的数据强一致。
这个是用于同时支撑AP和TP场景的核心,也是TiDB的最大亮点(个人之见)。
TiDB架构
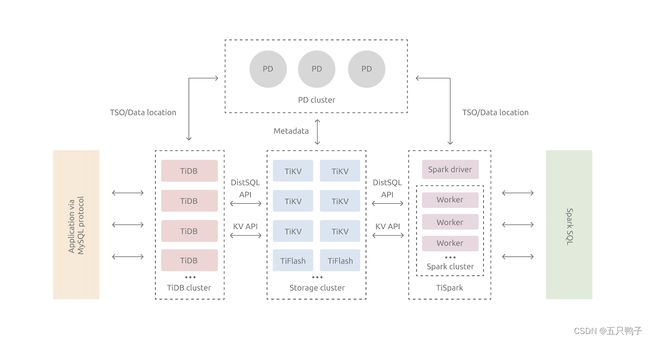
上面是TiDB的整体架构图,组件非常多,功能也比较完善强大,同时也带来了部署运维成本的增加,也增加了整个集群的复杂性。一一介绍下主要组件的作用
PD
PD是整个集群的大脑,主要存储了TIDB的元数据、数据分布情况、集群拓扑和事务号的生成等。集群各组件定期向PD汇报自身状况,PD会根据汇报信息对集群资源进行调度。所以说PD是整个集群的大脑。通过Raft协议让各个PD节点之间的数据保持一致性,推荐PD至少部署三个节点。
TiDB (组件)
此处的TiDB是一个组件名,叫TiDB,而非指整个TiDB数据库,此处很容易造成误解。
TiDB节点本身不存储数据,是用于对外暴露MySQL协议的链接,负责接收客户端连接,执行SQL解析和优化,最终生成分布式执行计划。TIDB是无状态的节点,因此建议至少部署2台及以上TiDB节点,实际生产应用中通常使用负载均衡组件来均衡TiDB的请求,如Haproxy,F5等。实际应用中为了保证TP服务的高可用,不让AP服务对TP服务造成大的影响,还可以通过负责均衡组件将AP和TP场景分开,需要注意的是此方案只能隔离TiDB组件,底层的存储在同一个集群内依然无法隔离。
TIKV
TIKV是数据存储的核心组件,数据通过RocksDB来持久化到磁盘上,以Key-Value的格式存储,以Region为单位进行切分管理,类似于MySQL的Page页,使用Raft协议复制多副本,支持多版本并发控制(MVCC)和分布式ACID事务
Key-Vlue Pairs (键值对)
TIKV中的数据以Key-Value的形式存储,TIKV为每一个表分配了一个TableID,为每一行分配了一个RowID,当表中有主键的时候主键就是RowID,最终的KV数据结构如下:
Key: tablePrefix{TableID}_recordPrefixSep{RowID}
Value: [col1, col2, col3, col4]
索引需要额外的kv来存储
- 唯一索引:
Key: tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue
Value: RowID - 普通索引:
Key: tablePrefix{TableID}_indexPrefixSep{IndexID}indexedColumnsValue{RowID}
Value: null

RocksDB本地存储
TIKV并没有直接向磁盘写数据,而是将数据写进了RocksDB,具体数据落磁盘的动作由RocksDB完成。作为一款数据库引擎,为啥还要引入RocksDB来作为重要的数据存储呢? 官网的解释是:因为开发一个单机存储引擎工作量很大,特别是要做一个高性能的单机引擎,需要做各种细致的优化,而 RocksDB 是由 Facebook 开源的一个非常优秀的单机 KV 存储引擎,可以满足 TiKV 对单机引擎的各种要求。
RocksDB利用LSM Tree的存储结构,进行写操作时,只需要更新内存,内存中的数据以块数据形式刷到磁盘中,是一个顺序的IO操作,另外磁盘文件的定期合并也将带来IO操作。
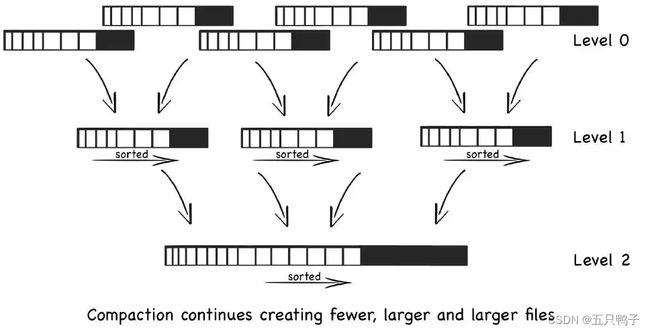
LSM Tree读操作是先从内存数据中读取,如果内存中没有,再顺序从磁盘文件中一个一个查找,由于文件本身是有序的,并且定期的合并减少了磁盘文件的数量,因而使得查询过程加快。
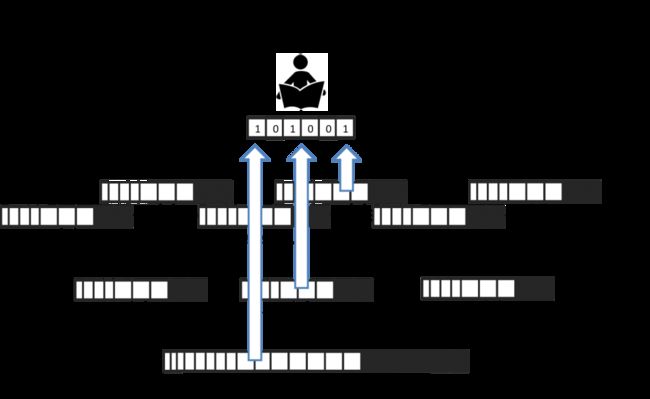
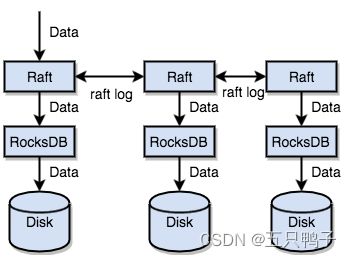
Raft
为了保证数据的一致性,TIKV也是通过Raft协议来将数据复制到其他TIKV节点中,Raft是一个多数派协议,不会出现脑裂的问题,由一个leader,和多个follower组成,客户端的所有请求全部由Leader来处理。
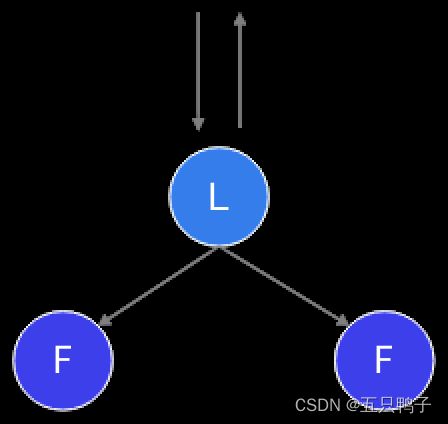
TiKV 利用 Raft 来做数据复制,每个数据变更都会落地为一条 Raft 日志,通过 Raft 的日志复制功能,将数据同步到 Group 的多数节点中
Region
TiKV 将整个Key-Value 分成了很多段,每一段都是一系列连续的key,每一段叫做一个Region,每一个Region的默认大小是96MB,每个Region都可以用[StartKey, EndKey) 这样一个左闭右开区间来描述。
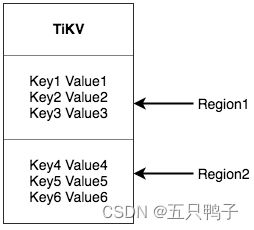
Region是TiDB中数据存储切分的最小单位
以Region为单位,将数据分散在集群中所有的节点上,并且尽量保证Region在集群中分布均匀。
以Region为单位,做Raft的复制和成员管理,也就是说一个Region会有多副本(Replica),Replica之间仍然是通过Raft来保证数据的一致性。
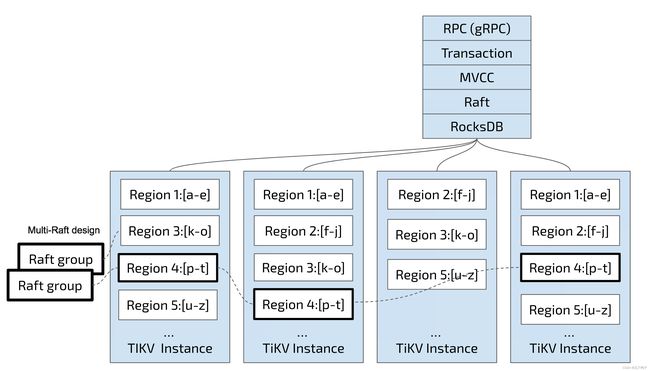
TIKV中,通过Region单位的划分和Raft的复制,能方便的支持水平扩容并能保证数据的高可用。
TiFlash
TiFlash组件是一个列式存储,拥有MPP能力的AP存储引擎,数据来源于TIKV,通过Raft Learner协议实时异步复制。这也是为什么TiDB能同时提供实时的TP和AP场景的原因。
TiFlash的数据只能从TIKV中同步,不支持直接写入,而且需要手动执行SQL来指定表的Tiflash副本数。
ALTER TABLE table_name SET TIFLASH REPLICA count;
count标识副本数,推荐至少2个副本,为0时表示删除TIFlash中的数据。
查看表同步进度
可通过如下 SQL 语句查看特定表(通过 WHERE 语句指定,去掉 WHERE 语句则查看所有表)的 TiFlash 副本的状态
SELECT * FROM information_schema.tiflash_replica WHERE TABLE_SCHEMA = '' and TABLE_NAME = '';
查询结果中:
AVAILABLE 字段表示该表的 TiFlash 副本是否可用。1 代表可用,0 代表不可用。副本状态为可用之后就不再改变,如果通过 DDL 命令修改副本数则会重新计算同步进度。
PROGRESS 字段代表同步进度,在 0.0~1.0 之间,1 代表至少 1 个副本已经完成同步。
TIKV和TiFlash整体存储结构

TIKV和TiFlash都是分布式,多副本存储。
隔离性:TiFlash中的副本是通过Raft Learner进行异步数据复制的,即使当TiFlash节点宕机或者网络高延时等状况发生,都不会影响到TIKV的服务。不过如果TIKV节点有问题,TiFlash是会受到影响的。
一致性:每次收到读取请求,TiFlash 都会向 TiKV Leader 副本发起进度校对,只有当进度确保至少所包含读取请求时间戳所覆盖的数据之后才响应读取。

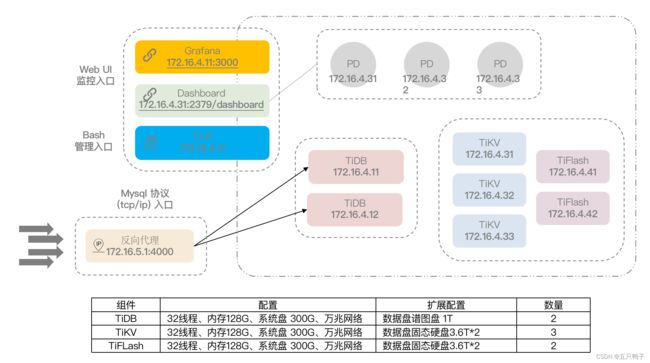
TIBD部署基本拓扑图
TiDB为什么快
-
基于CBO(Cost-Based Optimization)优化器:使用最小代价的物理计划优化算法,率先在Oracle7上使用,现在主流数据库都已经采用了CBO优化器
-
向量化:利用SIMD指令集,充分发挥CPU的处理能力,一些新型的分布式数据库也均已采用全面向量化,如doris,clickhouse等
-
协处理:将计算尽量靠近存储节点,TiFlash 和TIKV同时都拥有协处理的能力,类似于谓词下推,可以将计算下推到TiFlash和TIKV,从而利用分布式计算能力,且减少RPC的调用次数以及传输的数据量,最终提高计算性能
-
行存(TIKV)和列存(TiFlash)同时存在,并且能智能选择最优的执行计划(需要保证表的健康度)
-
站在巨人的肩膀上:RocksDB,Raft
TiDB适用场景
- 高并发的TP场景:例如联机交易,日志埋点等
- 实时数仓存储:大规模数据的写入和读取操作
- 基于宽表的实时AP场景:不能有太多的JOIN,基于宽表的实时报表分析查询
- 大量数据的存储,避免分库分表
使用TiDB的一些注意事项
- 如果不Order by ,每次返回的数据顺序都不一致
在单机数据库中由于数据都存储在一台服务器上,有些数据库(尤其是 MySQL InnoDB 存储引擎)还会按照主键或索引的顺序进行结果集的输出,所以每次查询返回的数据顺序相对稳定。
而TiDB 是分布式数据库,数据被存储在多台服务器上,多份数据返回的时间先后并不固定。另外 TiDB 层不缓存数据页,因此不含 order by 的 SQL 语句查询出来的结果集的数据顺序无法保证一致。
- 自增列不能保证连续
TiDB中自增列只保证自增且唯一,并不保证连续
TiDB目前采用批量分配的方式,所以如果在多台 TiDB 上同时插入数据,分配的自增 ID 会不连续。当多个线程并发往不同的 tidb-server 插入数据的时候,有可能会出现后插入的数据自增 ID 小的情况。
TiDB 实现自增 ID 的原理是每个 tidb-server 实例缓存一段 ID 值用于分配(目前会缓存 30000 个 ID),用完这段值再去取下一段。在集群中有多个 tidb-server 时,人为向自增列写入值之后,可能会导致 TiDB 分配自增值冲突而报 “Duplicate entry” 错误。
- 表的健康度要关注
TIDB采用CBO优化器来生成物理执行计划,当某个表的健康度降低的时候,会导致CBO执行器无法准确判断走哪个索引的代价更小,从而导致选择错误的索引,而导致查询性能较低。
通过 SHOW STATS_HEALTHY 可以查看表的统计信息健康度,并粗略估计表上统计信息的准确度。当 modify_count >= row_count 时,健康度为 0;当 modify_count < row_count 时,健康度为 (1 - modify_count/row_count) * 100。
健康度越高,执行器选择正确的索引的成功率越高。
TiDB会自动收集表信息,可以通过下面语句查询TIDB执行收集信息的时间和阀值
show variables like '%analyze%'

tidb_auto_analyze_ratio 默认为0.5,表示健康度低于50的时候在tidb_auto_analyze_start_time 和 tidb_aotu_analyze_end_time的时间范围内会自动执行analyze table table_name 来收集信息。
(ps +0000表示时区,+0800是东八区)
也可以手动执行 analyze table table_name 来立即收集信息。
- 注意谓词下推,很多函数不支持
具体支持的列表可参考:
TiFlash支持的下推算子和运算符列表
TIKV支持的下推算子和运算符列表
- 事务超时
含 DML 语句的事务,除了受 tikv_gc_life_time 限制之外,还受到另外一个参数 max-txn-time-use 的影响,这个参数位于 tidb-server 的配置文件 tidb.toml 中,用于控制单个事务允许的最大执行时间。该参数的默认值为 590(秒),需要注意必须控制该参数的值小于 tikv_gc_life_time 的值。
如 insert into t2 select * from t1的 SQL 语句,即使执行时间没有达到 tikv_gc_life_time 限制,但超过了 max-txn-time-use 的限制,会由于超时而回滚。
- OOM问题
TIKV由于是KV结构存储的,不具备Join能力,如果查询语句中有关联表没有Tiflash,则必须要将TIKV中的所有数据都拉取到TiDB节点再进行处理,此时极易产生OOM。应当尽量避免此类情况产生,也可以通过设置SQL内存的方式来增大内存使用量。
例如:
配置整条 SQL 的内存使用阈值为 8GB:
SET tidb_mem_quota_query = 8 << 30;
配置整条 SQL 的内存使用阈值为 8MB:
SET tidb_mem_quota_query = 8 << 20;
- Index Merge 只支持 or ,不支持 and
TiDB 4.0之后开始支持Index Merge,但是目前6.2版本也支持or的操作,对于and的查询操作仍然是不支持的。那就意味着我们在创建索引的时候不能向MySQL那样创建多个单独索引,而是需要根据实际使用的场景建立联合索引(这点尤为重要)。
其他注意事项待使用中发现总结后再持续更新…
总结
TiDB是一款相当优秀的国产分布式数据库,适用于实时数仓存储,维表计算,高并发TP场景,以及大量数据存储等场景。但是在使用中有很多注意的小点,特别是在性能上,需要对它有足够的了解,才能驾驭好它。