【目标检测】YOLOX ,YOLO系列的集大成者
文章目录
-
- 一、YOLOX简介
- 二、YOLOX模型结构(Decouple head)
- 三、YOLOX的改进之处
-
- 3.1 数据增强(data augmentation)
- 3.2 Anchor-free(不使用anchor)
- 3.3 Multi positives(多个正样本)
- 3.4 SimOTA
- 四、YOLOX的不同版本
-
- 4.1 YOLOX-S、YOLOX-M、YOLOX-L、YOLOX-X
- 4.2 YOLOX-Tiny、YOLOX-Nano
一、YOLOX简介
提出时间:2021年
作者单位:旷视科技
旷视官方代码:https://github.com/Megvii-BaseDetection/YOLOX
论文下载地址:https://arxiv.org/abs/2107.08430
论文题目:《YOLOX: Exceeding YOLO Series in 2021》
《YOLOX: Exceeding YOLO Series in 2021》的意思是YOLOX在2021年超越了所有YOLO系列,标题很狂妄呀。
从2015年的YOLOv1,2016年YOLOv2,2018年的YOLOv3,再到2020年的YOLOv4和YOLOv5,2021年的YOLOX,YOLO系列在不断的进化发展。
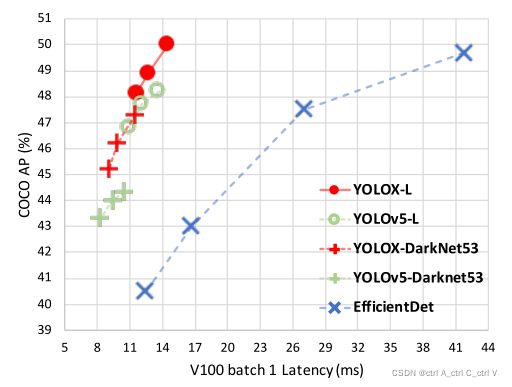
YOLOX的速度和精度图如下,横坐标为推理速度,纵坐标为MAP精度。
YOLOX不同版本的参数量(模型大小)和MAP精度图:
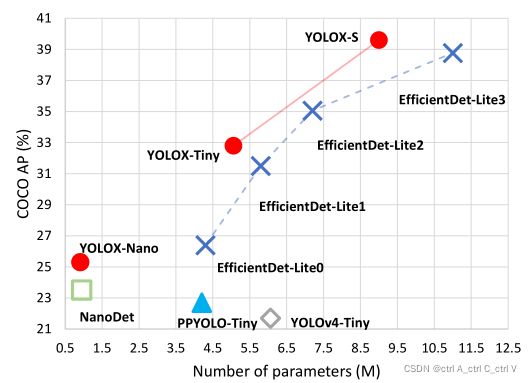
可以发现在YOLOX不同版本中,YOLOX-Nano模型最小,速度最快。
模型大小往往与速度成正比,很难做到小模型实现高精度。
二、YOLOX模型结构(Decouple head)
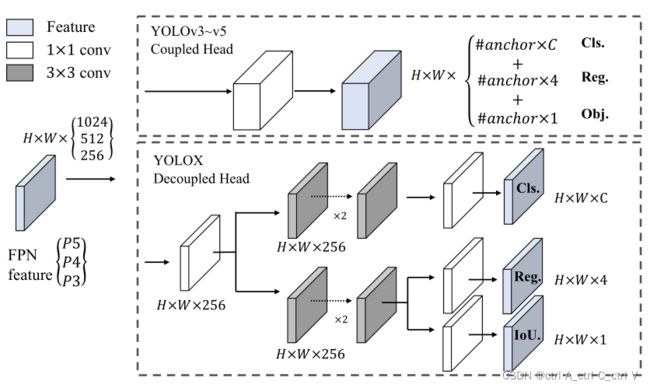
YOLOX以YOLOv3-SPP为基础模型进行改进,其backbone是DarkNet-53。
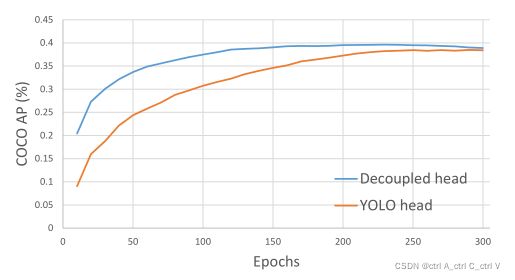
如下图所示,在YOLOv3–YOLOv5中,检测头对候选框的分类和回归是耦合的(在一起进行,Couple),这样会影响模型检测的性能。YOLOX 对分类和回归进行了解耦(Decouple),即将二者分开,变成两个分支,并增加了IOU计算的分支。
下图是训练过程,显然解耦的检测头(Decouple head)的检测精度更高(解耦能带来4.2%AP提升),收敛速度更快。
三、YOLOX的改进之处
3.1 数据增强(data augmentation)
YOLOX采用了 Mosaic 和 MixUp 两种数据增强方式。
Mosaic是在YOLOv4中提出的,对四张图片进行拼接,每一张图片都有其对应的框框,将四张图片拼接之后就获得一张新的图片,同时也获得这张图片对应的框框。具体可以参考 YoloV4当中的Mosaic数据增强方法
MixUp 采用配对的方式进行训练,通过混合两个甚至是多个样本的分布,同时加上对应的标签来训练。两张图以一定的比例对rgb值进行混合,同时需要模型预测出原本两张图中所有的目标。目前MixUp在各大竞赛、各类目标检测中属于稳定提点的策略。具体可以参考 全网最全:盘点那些图像数据增广方式Mosiac,MixUp,CutMix等.
3.2 Anchor-free(不使用anchor)
YOLOv2–YOLOv5都是基于anchor的算法( anchor-based),这种方式有一些问题:
(1)为了达到最优的检测性能,需要在训练前对训练集进行聚类分析,确定一组最优的anchor。这些聚类获得的anchor是对于特点数据集适用的,不具有普遍性。
(2)anchor机制增加了检测头的复杂度,以及对每幅图像的预测数量。在一些边缘AI系统中,在设备之间移动如此大量的预测(例如从NPU到CPU)可能会成为整体延迟的潜在瓶颈。
Anchor-free算法可以减少模型参数,具有代表性的Anchor-free算法是在论文《FCOS:Fullu Convolutional One-Stage Object Detection》,该方法借鉴了语义分割的方法,根据主像素点预测边界框。
YOLOX中,特征图中的一个点只预测一个候选框(而不是多个anchor),直接预测4个值(候选框左上角的xy坐标与w,h)。
3.3 Multi positives(多个正样本)
YOLO系列中关于正负样本的定义可以参考 YOLOv3/v4/v4/x中正负样本的定义
3.4 SimOTA
SimOTA是一种标签分配方法,
四、YOLOX的不同版本
4.1 YOLOX-S、YOLOX-M、YOLOX-L、YOLOX-X
如果不采用DarkNet53作为backbone,而采用YOLOv5的backbone(包括SCPNet、SiLU activation、PAN head),可以得到不同版本YOLO5对应的YOLOX的版本:
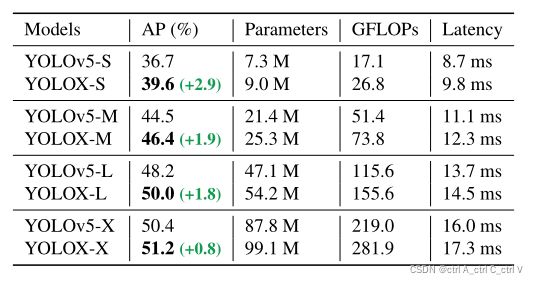
可以发现,YOLOX比YOLOv5的相应版本性能更好。
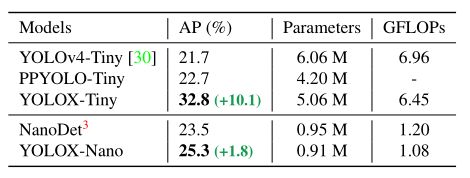
4.2 YOLOX-Tiny、YOLOX-Nano
Nano是纳米,YOLOX-Tiny和YOLOX-Nano是YOLOX的小模型,模型对比如下: