YOLOv1——YOLOX系列及FCOS目标检测算法详解
文章目录
-
- 一、 开山之作:YOLOv1
-
- 1.1. YOLOv1简介
- 1.2 YOLOv1 检测原理
- 1.3 YOLOv1网络结构
- 1.4 YOLOv1 损失函数
- 1.5 YOLOv1优缺点
- 二、 YOLOv2
-
- 2.1 Darknet-19
- 2.2 优化方法
- 三、 YOLOv3
-
- 3.1 YOLOv3简介
- 3.2 darknet-53及YOLOv3网络结构
- 3.3 真实框匹配&多尺度预测
- 3.4 目标边界框的预测
- 3.5 正负样本匹配&真实框监督信息
- 3.6 损失函数和多标签分类
-
- 3.6.1 置信度损失
- 3.6.2 类别损失和多标签分类
- 3.6.4 定位损失
- 3.7最终预测
- 四、 YOLOv3 SPP
-
- 4.1 Mosaic图像增强
- 4.2 SPP(Spatial Pyramid Pooling)结构
- 4.3 CIoU Loss
-
- 4.3.1 IoU Loss
- 4.3.2 GIoU Loss(Generalized IoU)
- 4.3.3 DIoU Loss(收敛快、定位准)
- 4.3.4 CIOU Loss
- 4.4 Focal loss
-
- 4.4.1 Focal loss效果
- 4.4.2 Focal loss理论
- 4.5 YOLOv3 SPP源码分析
- 五、YOLOv4
-
- 5.1 简介
- 5.2 YOLOv4 网络结构
-
- 5.2.1 Backbone: CSPDarknet53
- 5.2.2 Neck: SPP,PAN
- 5.3 优化策略
-
- 5.3.1 Eliminate grid sensitivity :消除grid网格敏感程度
- 5.3.2 Mosaic 数据增强
- 5.3.3 IoU threshold正负样本匹配
- 5.3.4 Optimizer Anchors
- 5.3.5 CIoU(定位损失)
- 六、YOLOV5
-
- 6.1 YOLOV5简介
- 6.2 YOLOv5网络结构
-
- 6.2.1 主要结构
- 6.2.2 SPPF
- 6.2.3 New CSP-PAN
- 6.3 数据增强
- 6.4 训练策略
- 6.5 损失计算
-
- 6.5.1 平衡不同尺度的损失
- 6.5.2 消除Grid敏感度
- 6.6 正样本匹配(Build Targets)
- 6.7 YOLOv5应用demo
- 七、 FCOS
-
- 7.1 基于Anchor的目标检测模型缺点
- 7.2 FCOS简介
- 7.3 FCOS网络结构
- 7.4 正负样本匹配
-
- 7.4.1 center sampling匹配准则
- 7.4.2 Ambiguity问题
- 7.5 损失计算
- 7.6 Assigning objects to FPN
- 八、YOLOX
-
- 8.1 前言
- 8.2 YOLOX网络结构
- 8.3 Anchor-Free
- 8.4 正负样本匹配策略SimOTA
-
- 8.4.1 cost含义和计算
- 8.4.2 利用cost进行正负样本的匹配
- 8.5 损失计算
参考:太阳花的小绿豆系列博文《object detection目标检测系列》、github项目《深度学习在图像处理中的应用教程》、bilibili讲解视频《深度学习-目标检测篇》
参考:《目标检测7日打卡营》
作者君说学习某个模型代码步骤是:网络搜索模型讲解,理解大概原理、结构→读论文(很重要,很多细节是根据原论文实现的)→找github上源码(选喜欢的框架、fork多、经常维护的项目)→fork、然后根据readme跑通。→参考原论文,分析代码(网络搭建、数据预处理、损失计算)
一、 开山之作:YOLOv1
参考《YOLO系列算法精讲:从yolov1至yolov5的进阶之路(2万字超全整理)》
1.1. YOLOv1简介
在YOLOv1提出之前,R-CNN系列算法在目标检测领域独占鳌头。R-CNN系列检测精度高,但是由于其网络结构是双阶段(two-stage)的特点,使得它的检测速度不能满足实时性,饱受诟病。为了打破这一僵局,设计一种速度更快的目标检测器是大势所趋。
2016年,Joseph Redmon、Santosh Divvala、Ross Girshick等人提出了一种单阶段(one-stage)的目标检测网络。它的检测速度非常快,每秒可以处理45帧图片,能够轻松地实时运行。由于其速度之快和其使用的特殊方法,作者将其取名为:You Only Look Once(也就是我们常说的YOLO的全称),并将该成果发表在了CVPR 2016上,从而引起了广泛地关注。
YOLO 核心思想:把目标检测转变成一个单一的回归问题。利用整张图作为网络的输入,仅仅经过一个神经网络,得到bounding box(边界框) 的位置及其所属的类别。
1.2 YOLOv1 检测原理
YOLO 检测策略:将图像划分为S*S个网格,物体真实框的中心落在挪个网格上,就由该网格对应的锚框负责检测该物体。 这49个网格就相当于是目标的感兴趣区域,而不需要像Faster R-CNN那样,通过一个RPN来获得目标的感兴趣区域,不需要再额外设计一个RPN网络,这正是YOLOv1作为单阶段网络的简单快捷之处!

- x、y是bounding box中心相对于网格的坐标。比狗的真实框中心在网格A,那么bounding box的中心肯定限制在网格A之内,且bounding box中心相对于网格的坐标就是x、y。所以 x , y ∈ [ 0 , 1 ] x,y\in [0,1] x,y∈[0,1]。
- w、h是bounding box相对于整张图像的w和h,所以 w , h ∈ [ 0 , 1 ] w,h\in [0,1] w,h∈[0,1]
- confidence是预测框bounding box和真实框的IoU*Pr(Object)。(当网格中确实有被检测物体时Pr(Object)=1,否则为0)
- YOLOv1中是没有Anchor这个概念的,x,y,w,h是直接预测bounding box的位置。Faster-RCNN或者SSD中,x,y,w,h是Anchor的位置信息。
- 预测时,输出结果是某个类别的概率乘以预测框与真实框的IoU值。
YOLOv1实现过程可简单理解为:
- 将一幅图像分成 S×S个网格(grid cell),如果某个 object 的中心落在这个网格中,则这个网格就负责预测这个object;
- 每个网格要预测 B 个bounding box和C个类别的分数,每个 bounding box 要预测 (x, y, w, h) 和 confidence 共5个值。(confidence在之前Faster-RCNN或者SSD中是没有的)
- YOLOv1采用的是PASCAL VOC数据集,把一张图片划分为了7×7个网格,并且每个网格预测2个Box(Box1和Box2)。PASCAL VOC有20个类别。所以实际上,S=7,B=2,C=20。那么网络输出的shape为S × S × (5×B+C)也就是7×7×30。具体的输出结构如下图所示(在通道维度(C)上来预测偏移量(x, y, w, h) 、 confidence、类别等信息):

1.3 YOLOv1网络结构
网络结构

- 网络输入:448×448×3的彩色图片。
- 卷积池化层:由若干卷积层和最大池化层组成,用于提取图片的抽象特征。s-2表示卷积步幅为2,没有写就是默认步幅为1。}×4表示这两个层重复4次。最终卷积池化层输出7×7×1024的特征图。
- 全连接层:由两个全连接层组成,用来预测目标的位置和类别概率值。第一层将7×7×1024的卷积池化层输出拉平,输入fc(4096)的全连接网络;第二层输入fc(1470)的全连接层后reshape成7×7×30的向量。
- 网络输出:7×7×30的预测结果。
网格划分
之前我们说YOLO核心思想是先将一幅图像分成 S×S个网格(grid cell)。这里划分不是在原图上直接物理划分,而是根据backbone输出的特征图大小来划分:

1.4 YOLOv1 损失函数

- 损失由三部分组成,分别是:坐标预测损失、置信度预测损失、类别预测损失。
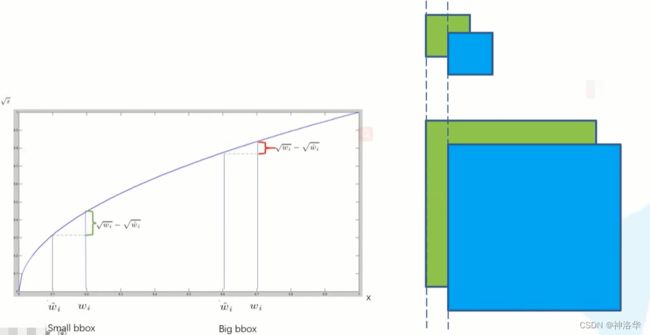
- 使用的是sum squared error误差平方和作为损失函数(类似mse)。需要注意的是,w和h在进行误差计算的时候取的是它们的平方根。如果直接相减,那么即使是一样的偏移量,但是对不同大小的物体,bounding box和真实框的误差是不一样的。而 ( x i − x i ^ ) 2 (\sqrt{x_{i}}-\sqrt{x_{i}^{\hat{}}})^{2} (xi−xi^)2的方式求误差,可以保证不同尺度的物体偏移同样的距离,所得到的误差是不一样的。如下图:
- 含object的box为正样本,其 C i ^ = 1 C_{i}^{\hat{}}=1 Ci^=1,不含object的box为负样本,为 C i ^ = 0 C_{i}^{\hat{}}=0 Ci^=0。
- 定位误差比分类误差更大,所以增加对定位误差的惩罚,使 λ c o o r d = 5 λ_{coord }= 5 λcoord=5
- 在每个图像中,许多网格单元不包含任何目标。训练时就会把这些网格里的框的“置信度”分数推到零,这往往超过了包含目标的框的梯度。从而可能导致模型不稳定,训练早期发散。因此要减少了不包含目标的框的置信度预测的损失,使 λ n o o b j = 0.5 λ_{noobj }=0.5 λnoobj=0.5
1.5 YOLOv1优缺点
(1)优点:
- YOLOv1检测速度非常快。
- 通用性强,能运用到其他的新的领域(比如艺术品目标检测)。
(2)局限:
- YOLOv1对相互靠近的物体,以及很小的群体检测效果不好,这是因为一个网格只预测了2个bounding box,并且都只属于同一类(一个网格只预测一组类别参数)。
- 每个网格只对应两个bounding box,当物体的长宽比不常见(也就是训练数据集覆盖不到时),效果较差
- 每个网格只对应一个类别,容易出现漏检(物体没有被识别到)
- 定位效果差。影响检测效果的主要原因是定位误差,尤其是太小的物体。因为YOLOv1直接预测目标的坐标信息,而不是Faster-RCNN那样,预测Anchor的微参数。YOLOv1对于小的bounding boxes,small error影响更大。 所以从YOLOv2开始,就是基于Anchor进行回归预测。
二、 YOLOv2
论文《YOLO9000:Better, Faster, Stronger》
YOLOv2使用PASCAL VOC数据集和ImageNet数据集联合训练,可以检测目标种类超过9000个,所以叫YOLO9000
参考《YOLO v2详细解读》
YOLOv2重点解决YOLOv1召回率和定位精度方面的不足。
相比于YOLOv1是利用全连接层直接预测Bounding Box的坐标,YOLOv2借鉴了Faster R-CNN的思想,引入Anchor机制。利用K-means聚类的方法在训练集中聚类计算出更好的Anchor模板,大大提高了算法的召回率。同时结合图像细粒度特征,将浅层特征与深层特征相连,有助于对小尺寸目标的检测。
为什么要引入锚框,而不是直接对目标真实框进行回归预测?
模型训练可以看做是一个猜答案的过程,loss告诉模型是猜大了还是猜小了。如果没有预先的模板只是盲目猜,收敛太慢。而在训练集上K-means聚类得到Anchor模板,生成的预测框只需要在锚框的基础上微调就行,相当于引入了先验知识,收敛更快、效果更好。 PaddleDetection提供tools/anchor_cluster.py脚本进行锚框聚类,得到合适的锚框大小。
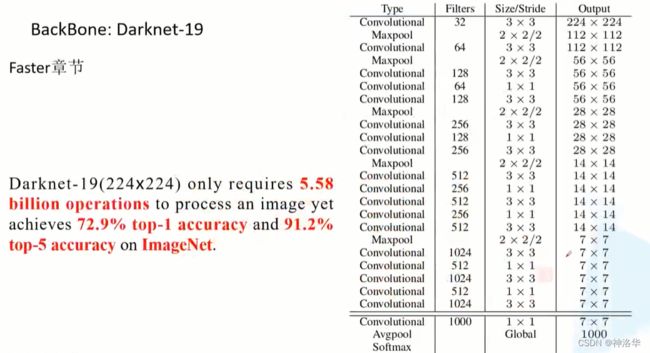
2.1 Darknet-19
关于DarkNet19和Kmeans聚类anchor等等细节可以参考《YOLO系列算法精讲:从yolov1至yolov5的进阶之路(2万字超全整理)》
YOLO v2采用Darknet-19作为骨干网络(19个卷积层):
2.2 优化方法
在原论文Bettrt章节中,提出了以下7种优化方法 :
-
Batch Normalization:YOLO v2中在每个卷积层后加BN层,能提升模型收敛速度。起到一定的正则化效果,所以可以去掉dropout层。检测效果上,mAP提升了2%。
-
高分辨率分类器 :图像输入尺寸从224*224变为448*448,mAP提升了4%
-
Convolutional With Anchor Boxes: 使用Anchor进行目标边界框预测。YOLO v1利用全连接层直接对边界框进行预测,导致丢失较多空间信息,定位效果比较差。YOLO v2去掉了 YOLO v1中的全连接层,使用Anchor Boxes预测边界框,网络更容易学习,每张图可以检测更多的类别。效果上召回率提高了7%。

YOLOv1 有一个致命的缺陷就是:一张图片被分成7×7的网格,一个网格只能预测一个类,当一个网格中同时出现多个类时,就无法检测出所有类。针对这个问题,YOLOv2做出了相应的改进:- 将YOLOv1网络的FC层和最后一个Pooling层去掉,使得最后的卷积层的输出可以有更高的分辨率特征。
- 网络输入大小416×416→448×448,使得网络输出的特征图有奇数大小的宽和高(13×13),进而使得每个特征图在划分单元格的时候只有一个中心单元格(图片中的物体都倾向于出现在图片的中心位置)。
- 借鉴Faster R-CNN,YOLOv2通过引入Anchor Boxes,预测Anchor Box的偏移值与置信度,而不是直接预测坐标值。
- 每个Cell选择5个Anchor Box,可以预测13 × 13 × 5 = 845 个边界框,比YOLOv1预测的98个bounding box 要多很多,因此在定位精度方面有较好的改善。
-
Anchor Box的宽高由聚类产生 : YOLO v2采用k-means聚类算法对训练集中的边界框做分析来选择Anchor Box 的大小。最终每个网格采用5种 Anchor,比 Faster R-CNN 采用9种 Anchor 得到的平均 IOU 还略高,模型更容易学习。(Faster R-CNN 中 Anchor Box 的大小和比例是按经验设定的。)
-
绝对位置预测:

这个公式是无约束的,预测的边界框很容易向任何方向偏移。因此,每个位置预测的边界框可以落在图片任何位置,这会导致模型的不稳定性,加长训练时间。
下图σ就是sigmoid函数。最终模型的mAP值提升了约5%。

-
Fine-Grained Features:细粒度特征融合。YOLOv2通过添加一个Passthrough Layer,把前层的26×26的特征图,将其同最后输出的13×13的特征图进行连接,而后输入检测器进行检测,以此来提高对小目标的检测能力。最终模型性能提升了1%。

Passthrough Layer可以使宽高减半,channel增加为4倍。最终输出13×13×1028的特征图。
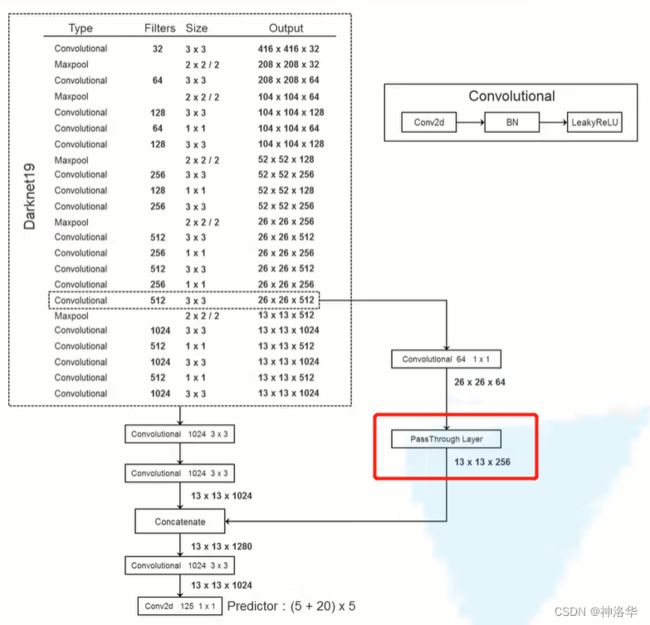
-
Multi-Scale Training:多尺度训练 。作者认为网络输入尺寸固定的话,模型鲁棒性受限,所以考虑多尺度训练。具体的,在训练过程中每隔10个batches,重新随机选择输入图片的尺寸[320,352,416…608](Darknet-19最终将图片缩放32倍,所以一般选择32的倍数)。
因为是多尺度训练,所以最终预测时,图片入网尺寸选择320到608都可以,尺寸大检测效果好,但是推理变慢。
检测效果
- 横坐标是每秒检测图片的帧数,纵坐标是2007PASCAL VOC测试集上的mAP。
- YOLOv2最高精度是输入544×544,即下图最高的蓝色点。但是常用是416×416的输入网络。

待改进点
- 小目标上召回率不高
- 靠近的群体目标检测效果不好
- 检测精度还有优化空间
三、 YOLOv3
参考《YOLO v3网络结构分析》、论文名称:《YOLOv3: An Incremental Improvement》
3.1 YOLOv3简介
2018年,作者 Redmon 又在 YOLOv2 的基础上做了一些改进。特征提取部分采用darknet-53网络结构代替原来的darknet-19(也提供了轻量级的tiny-darknet,可以灵活选择),利用特征金字塔网络结构实现了多尺度检测,分类方法使用逻辑回归代替了softmax,在兼顾实时性的同时保证了目标检测的准确性。
下图右侧是darknet-53结构,借鉴了残差网络的思想。

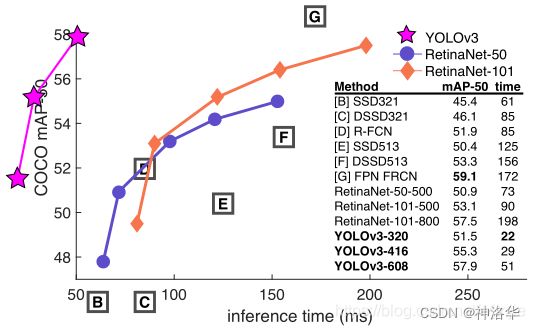
YOLOv3性能表现
如下图所示,是各种先进的目标检测算法在COCO数据集上测试结果。很明显,在满足检测精度差不都的情况下,YOLOv3具有更快的推理速度!
下面对YOLOv3改进之处进行逐一的介绍。
3.2 darknet-53及YOLOv3网络结构
相比于YOLOv2,YOLOv3骨干网络由darknet-19改进为darknet-53:

上图右侧表格是不同采用backbone后模型在ImageNet数据集上top-1、top-5精度和推理速度FTPs等。综合考虑最终YOLOv3采用darknet-53为backbone。(推测darknet-53用卷积层替换最大池化来进行下采样,所以精度提高。其卷积核数明显少于resnet网络,所以推理速度更快)
convolutional和Residual结构以及整个网络多尺度预测结构如下图1所示:

-
Convolutional=Conv2d+BN+LeakyReLU,卷积层Conv2d没有偏置参数。128 3×3/2表示channel=128,卷积核3×3,步幅为2。没有写步幅就是默认为1。
-
res unit: 上图有五个方框,每个方框是一整个残差单元。Residual表示输入通过两个Convolutional后,再与原输入进行add。
-
特征图1:是darknet-53去掉平均池化层和全连接层之后输出13×13的特征图,再经过Convolutional Set和一个3×3卷积得到第一个特征图。经过卷积核大小1×1的预测器进行预测。COCO数据集类别数为80,所以每个特征图需要预测的参数个数为N×N×3×(4+1+80)个。
-
特征图2:是特征图1经过上采样,和上一层的特征图在通道维度拼接concat,然后经过Convolutional Set等几个层提取特征得到的,y3同理。(FPN中两个特征层进行融合的方式是对应维度进行相加)
-
Conv 2d 1×1表示YOLOv3最终预测还是将特征图经过1×1普通卷积之后变换通道数,在通道维度上进行预测位置、置信度、类别等信息。具体的,网络在三个特征图中分别通过 ( 4 + 1 + c ) × k (4+1+c) \times k (4+1+c)×k个大小为 1 × 1 1 \times 1 1×1的卷积核进行预测,其中k为预设边界框(bounding box prior)的个数,c为预测目标的类别数。在每个预测特征层中k默认取3,则一共9个Anchor。每个Anchor都会预测4个位置参数(偏移量),一个置信度参数,以及对应每个类别的概率分数。

darknet-53相对于darknet-19做了如下改进: -
没有采用最大池化层,转而采用步长为2的卷积层进行下采样。(即尺寸压缩不是用池化层而是卷积层实现)
-
为了防止过拟合,在每个卷积层之后加入了一个BN层和一个Leaky ReLU。
-
引入了残差网络的思想,目的是为了让网络可以提取到更深层的特征,同时避免出现梯度消失或爆炸。
-
将网络的中间层和后面某一层的上采样进行张量拼接,达到多尺度特征融合的目的。

3.3 真实框匹配&多尺度预测
从上一节可以看出,YOLOv3是从三个不同尺度的特征图上进行预测,每个特征图生成三种不同的尺度的Anchor,一共9种不同大小的Anchors(这些预设边界框尺寸都是作者根据COCO数据集聚类得到的)。这样就可以预测多尺度的目标。具体的,特征图1尺寸最小,我们会在上面预测大尺度的目标,在特征图2上预测中尺度的目标,而在特征图3上预测小尺度的目标。

如果两个真实框落在同一个网格上,还匹配了同一个锚框怎么办?在yolo里面,后一个真实框覆盖掉前一个真实框。这就是为什么yolo在检测群体性小目标,或靠的很近有遮挡的物体时,精度不高的原因。


3.4 目标边界框的预测
锚框只给出了框的高度和宽度,怎么去表征真实的边界框?有多少真实框,在图片的哪个位置?
我们通过在特征图上划分网格,真实框在哪个网格就用哪个网格的锚框来预测,这样粗定位真实框。然后通过边界框回归参数,调整锚框中心点位置和锚框的宽高,来匹配真实框。
上面说过,YOLOv3网络从三个不同尺度的特征图上进行预测,每个特征图又生成三种不同的尺度的Anchor。每个Anchor都会预测4个位置参数,一个置信度参数,以及对应每个类别的概率分数。
下图展示了目标边界框的回归过程,以及从( t x , t y , t w , t h t_x, t_y, t_w, t_h tx,ty,tw,th)转换到 ( b x , b y , b w , b h b_x, b_y, b_w, b_h bx,by,bw,bh)的公式:

- 图中虚线矩形框为Anchor模板,蓝色实线矩形框为最终预测的边界框。
- ( c x , c y ) (c_x, c_y) (cx,cy)为当前网格Grid Cell左上角的x、y坐标;( p w , p h p_w, p_h pw,ph)为Anchor模板映射在特征层上的宽和高,Anchor模板只用看 ( p w , p h p_w, p_h pw,ph)信息
- 网络预测的四个回归参数是( t x , t y , t w , t h t_x, t_y, t_w, t_h tx,ty,tw,th)。 ( t x , t y t_x, t_y tx,ty)是网络预测边界框中心相对于当前网格左上角的偏移量, ( t w , t h t_w, t_h tw,th)是预测边界框的宽高缩放因子。
- ( b x , b y , b w , b h b_x, b_y, b_w, b_h bx,by,bw,bh)为最终预测的目标边界框参数。 ( b x , b y b_x, b_y bx,by)是最终预测边界框中心点的x、y坐标,( b w , b h b_w, b_h bw,bh)是预测框的宽和高。
- σ ( x ) \sigma(x) σ(x)函数是sigmoid函数,其目的是将预测偏移量 ( t x , t y t_x, t_y tx,ty)缩放到0到1之间(这样能够将每个Grid Cell中预测的边界框的中心坐标限制在当前cell当中,加快网络收敛)。同样的取exp函数是为了将宽高限制为正数。
- 从上图可以看出,YOLOv3预测的边界框中心点的回归参数是相对于当前网格左上角这个点的,而之前的Faster-RCNN和SSD中,预测的回归参数是相对于Anchor的。
3.5 正负样本匹配&真实框监督信息
针对每个真实框GT(ground truth object)都会分配一个正样本。分配原则是
- 将每个GT Boxes与每个Anchor模板进行匹配(这里直接将GT和Anchor模板左上角对齐,然后计算IoU)
- 将GT投影到对应预测特征层上,根据GT的中心点定位到对应cell(图中黑色×表示cell的左上角)
- 该cell中与GT的IoU值最大,即重合度最高的Anchor作为正样本
- 与GT的IoU值超过某个阈值(比如0.5)但又不是最大IoU的样本会被丢弃
- 与GT的IoU值低于阈值的样本为负样本
- 正样本三种损失都需要计算
- 定位损失:回归参数向能形变成真实框的值回归
- objectness损失:将预测框的objectness向1回归
- 分类损失:分类概率向真实框类别one-hot编码回归
- 负样本只有objectness,即置信度分数。
- objectness损失:将预测框的objectness向0回归。没有匹配到真实框,所以不存在类别标签,也没有回归参数。
按论文中这种方式进行正样本匹配会发现正样本数会非常少,网络很难训练。在u版YOLOv3中正样本匹配准则:所有和GT的IoU大于阈值(比如0.7)的bounding box都是正样本。将GT映射到特征层上,如果GT中心所在的Grid Cell有多个Anchor和GT的IoU值都大于阈值,那么这些Anchor都是正样本。这样就可以扩充正样本数量,实践中发现这样做效果也更好。

上图橙色为GT,蓝色为Anchor模板。两者左上角 重合之后计算IoU。

3.6 损失函数和多标签分类

其中 λ 1 , λ 2 , λ 3 \lambda _{1},\lambda _{2},\lambda _{3} λ1,λ2,λ3是平衡系数。
3.6.1 置信度损失
置信度损失即confidence score,可以理解为预测目标矩形框内存在目标的概率,目标置信度损失 L c o n f ( o , c ) L_{conf}(o,c) Lconf(o,c)使用的是二值交叉熵损失函数(pytorch中的BCELoss)。
- 下图蓝色框表示Anchor,绿色为真实边界框,黄色为最终预测框,经过Anchor与GT的偏移量微调得到。
- 这里写的是 o i o_i oi为预测框和真实边界框IoU值(值域[0,1],在YOLOv1、YOLOv2和YOLOapp源码中是这样的。)但是在YOLOv3中写的 o i o_i oi取值为0或1(是否是正样本)
- c i ^ \hat{c_{i}} ci^表示预测目标矩形框i内是否存在目标的Sigmoid概率(将预测值 c i c_{i} ci通过sigmoid函数得到)。

3.6.2 类别损失和多标签分类

结合下图可以看到, YOLOv3由于使用sigmoid激活函数来预测类别,而不是softmax,所以每个类别的预测概率是不不相关的,各分类概率和不等于1。这是为了实现多标签分类。
- 在YOLOv2中,使用用softmax进行分类,算法认定一个目标只从属于一个类别,根据网络输出类别的得分最大值,将其归为某一类,即单标签分类。然而在一些复杂的场景中,单一目标可能从属于多个类别。比如在一个交通场景中,某目标的种类既属于汽车也属于卡车,即多标签分类。
- 为实现多标签分类,需要用逻辑分类器来对每个类别都进行二分类。逻辑分类器主要用到了sigmoid函数,它可以把输出约束在0到1,如果某一特征图的输出经过该函数处理后的值大于设定阈值,那么就认定该目标框所对应的目标属于该类。
3.6.4 定位损失
类似mse,其实就是预测框的回归参数( t x , t y , t w , t h t_x, t_y, t_w, t_h tx,ty,tw,th)和真实框的回归参数( g x ^ , g y ^ , g w ^ , g h ^ g_x^{\hat{}}, g_y^{\hat{}}, g_w^{\hat{}}, g_h^{\hat{}} gx^,gy^,gw^,gh^)差值的平方和。真实框的回归参数是真实框位置信息( g x , g y , g w , g h g_x, g_y, g_w, g_h gx,gy,gw,gh)计算得到。

PaddleDetection里面,计算定位损失时,x、y上由于用了sigmoid激活,使用的是二值交叉熵损失(感觉还是不对啊,算的是数值又不是类别),wh方向使用L1损失。
3.7最终预测
计算预测框;

生成的预测框(class,objectness,xywh)经过NMS处理得到最终的预测框。
- 预测框按class分开计算
- 某个类别预测框按objectness 分数倒序排列,选择分数最大的预测框A
- 删除所有和预测框A的IoU大于阈值的锚框(其被认为和预测框A是相似的)
- 重复以上过程,直到所有锚框要么被选中,要么被删除
四、 YOLOv3 SPP
ultralytics/yolov3仓库、太阳花小绿豆的仓库、小绿豆bilibili视频
下图是ultralytics版YOLOv3 SPP项目中截取的一部分参数。当输入都是512×512大小,原始YOLOv3 的COCO mAP=32.7(在IOU从0.5到0.95取均值)。加入SPP之后提升到35.6,u版YOLOv3 SPP提升到42.6(加了很多trick)

4.1 Mosaic图像增强
一般的数据增强是图片随机裁剪、翻转、调整明暗度饱和度等等。Mosaic图像增强是将多张图像进行拼接后输入网络进行训练。项目中默认使用4张图像进行拼接增强。
- 增加数据的多样性。随机四张图像组合拼接,得到的图像数比原图像数更多。
- 增加目标个数
- BN能一次性统计多张图片的参数(BN 主要是求每个特征层均值和方差,batch_size越大求得的结果越接近整个数据集的结果,训练效果更好。受限设备batch_size不能太大,而多张图片拼接,变相增大了输入网络的batch_size)

4.2 SPP(Spatial Pyramid Pooling)结构
如下图是YOLOv3 SPP中加入的SPP结构,简单讲就是输入特征图经过四个分支之后进行拼接得到。这四个分支是:
- 输入直接接到输出的分支,size为[16,16,512]
- 三个不同池化大小的最大池化层分支。k5表示卷积核大小为5,s1表示步幅为1,p2表示padding=2。所以这三个池化层是输入特征图进行padding之后再最大池化,池化后特征图尺寸大小、通道数都不变,都为[16,16,512]
- 四个分支进行concatenate拼接,size为[16,16,2048]。拼接后实现不同尺度特征融合。这个简单的结构对最终结果提升很大。

SPP结构能一定程度上解决多尺度检测问题。下面是YOLOv3 SPP结构图:(来自《deep-learning-for-image-processing》项目)
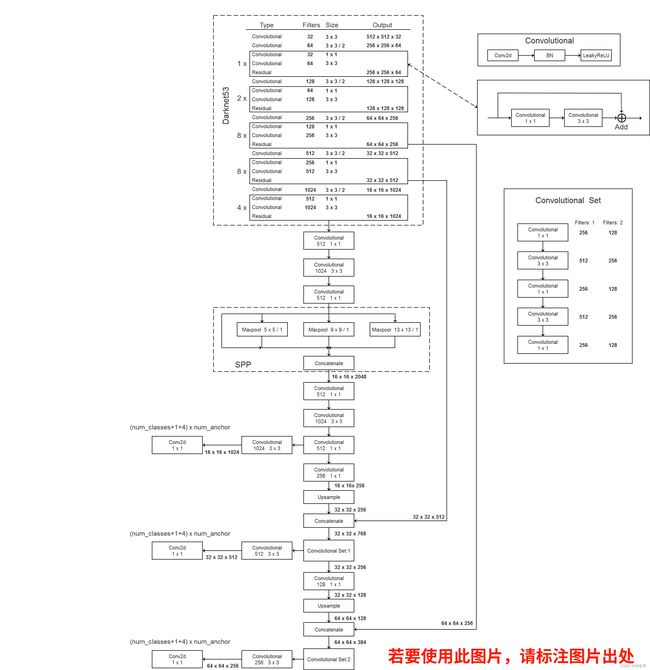
对比可以发现:原来YOLOv3中的特征图1,是darknet-53去掉平均池化层和全连接层之后输出13×13的特征图,再经过Convolutional Set和一个3×3卷积得到第一个预测特征图。而在YOLOv3 SPP中,是在这个过程中加入了SPP结构,其它不变。
为何不在生成第二个或者第三个预测特征图的时候也加入SPP结构呢?下图是YOLOv3 SPP论文中的实验对比。YOLOv3 SPP1和YOLOv3 SPP3分别是加入1个SPP结构和每个预测特征图之前都加入SPP结构的网络模型。橙色和绿色折线表示了二者的mAP效果。小尺寸输入图像上YOLOv3 SPP1效果更好,大尺寸输入图像上YOLOv3 SPP3效果更好(推理速度有所下降)。

4.3 CIoU Loss
YOLOv3中定位损失就是一个L2损失(差值平方和)。
4.3.1 IoU Loss
- IoU是两个区域的交并比。如下图,绿色表示真实框,黑色表示最终预测边界框。计算可以发现三组边界框的L2损失是一样的,但是其IOU值不一样。这说明L2损失不能很好的反映两个边界框的重合程度,由此引出IOU Loss。IOU Loss=-ln IOU(常见计算方式还有1-IOU,计算更简单)
- 优点:IOU Loss能更好的反映边界框的重合程度,且有尺度不变性(IOU LOSS大小和两个边界框大小、尺度无关)
- 缺点:两个边界框不重合时Loss=0,无法传递梯度。

4.3.2 GIoU Loss(Generalized IoU)
如下图,绿色是真实框,红色是预测边界框,蓝色框二者最小外界矩形。公式中 A c A^c Ac就是蓝色框面积,u就是真实框和预测框并集的面积。
- 两个边界框完全重合时,IOU=1, A c A^c Ac=u,GIoU=1
- 两个边界框无限远离时,IOU=0, A c A^c Ac=∞,GIoU→-1。这样两个边界框完全不重合时,也能计算损失传播梯度。
- 两个边界框尺寸一样,水平或这垂直重合时,GIoU退化成IOU。

计算mAP时,需要先判断预测框是否正确匹配上了目标。当预测框和真实框的IOU大于某个阈值时,可以认为预测框匹配到了目标。
- 下图右侧表格第一列计算得到的mAP(IOU从0.5到0.95取均值),定位损失为L2损失、IOU Loss、GIOU Loss时,mAP分别为0.461,0.466,0.477。
- 第三列表示IOU=0.75时,使用IOU loss和GIOU Loss对AP提升更大。

4.3.3 DIoU Loss(收敛快、定位准)
IOU loss和GIOU Loss缺点是收敛慢,定位(回归)不够准确。
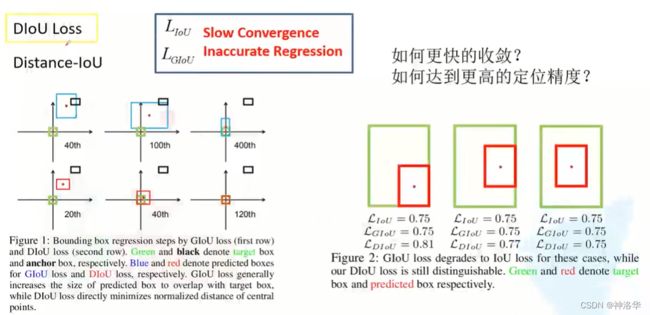
- Figure1上面一排三张图,表示使用GIOU Loss训练,分别迭代40步、100步、400步时预测边界框不断回归到真实框的过程。黑色框表示Anchor,绿色是真实框,期望训练后将蓝色预测框向真实框不断靠拢直至重合。
- Figure1下面三张图表示使用DIOU Loss训练的过程,训练120步时预测框和真实框已经完全重合了,可见 使用DIOU Loss训练收敛更快,定位更准*。
- Figure2表示两个边界框重合程度一样时,IOU Loss和GIOU Loss是一样的,说明二者不能很好的表示两个边界框的重合的位置关系。而三组边界框的DIOU Loss是不一样的。
DIOU Loss计算公式如下:
- b和 b g t b^{gt} bgt分别表示预测框和真实框中心点的坐标。 ρ 2 \rho ^{2} ρ2表示二者的欧氏距离。c表示两个边界框最小外界矩形对角线的长度。
- 两个边界框重合时,d=0,DIOU=IOU=1
- 两个边界框无限远时,c和d都趋近于∞,IOU=0,DIOU→-1。

4.3.4 CIOU Loss
CIOU Loss在DIOU Loss基础上加上了 α ν \alpha \nu αν项,即考虑边界框的长宽比。下图可以看出使用CIOU Loss训练效果更好。 L C I O U ( D ) L_{CIOU}(D) LCIOU(D)表示将验证评价模型mAP时的IOU换成DIOU,模型效果还有进一步提升。文中说,虽然提升少,但是更合理,因为某些时候,IOU没办法准确判断两个边界框的重合关系的,而DIOU好很多。现在很多算法就是将IOU替换成DIOU。

下图是论文中给出的样例,使用CIOU Loss定位效果更好。

4.4 Focal loss
也可参《从 loss 的硬截断、软化到 Focal Loss》及讲解视频
4.4.1 Focal loss效果
下图右侧是YOLOv3使用Focal loss精度反而下降2个点(所以有些人使用Focal loss发现没什么用)。左侧是Focal loss论文中使用Focal loss,采用不同的参数得到的精度。

Focal loss主要是解决正负样本不平衡问题。下图是 Focal loss论文表示 Focal loss主要是针对单阶段检测模型,比如SSD和YOLO。其实两阶段检测模型也有正负样本不平衡的问题,但是两阶段模型会先经过RPN网络再输出RoI(候选框),数量一般是2000个,再输入第二个阶段进行预测,所以正负样本不平衡问题比单阶段模型好很多。
在之前经过,YOLOv3正负样本选择时,不会使用所有的负样本,而是选择与真实框的IoU值低于阈值的样本为负样本(即损失很大的负样本),即hard negative mining方法。下图右下表格OHEM表示使用hard negative mining方法的模型效果,比FL(Focal loss)效果差很多。

4.4.2 Focal loss理论
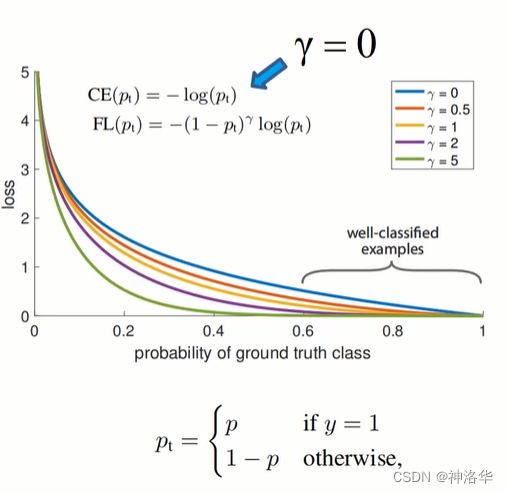
Focal loss的设计主要是针对单阶段检测模型中正负样本极度不平衡的情况(背景框数量远远大于正样本)。二分类交叉熵公式如下: C E ( p , y ) = − l o g ( p t ) CE(p,y)=-log(p_{t}) CE(p,y)=−log(pt)。

- 加入正负样本平衡系数α之后, C E ( p , y ) = − α t l o g ( p t ) CE(p,y)=-\alpha _{t}log(p_{t}) CE(p,y)=−αtlog(pt),其中正样本的 α t = α \alpha _{t}=\alpha αt=α,负样本的 α t = 1 − α \alpha _{t}=1-\alpha αt=1−α。但是α无法区分哪些是容易训练的样本,哪些是难以训练的样本。
- 引入系数 ( 1 − p t ) γ (1-p_{t})^{\gamma } (1−pt)γ之后,可以减少容易样本的损失,使训练聚焦于困难样本上。
4.5 YOLOv3 SPP源码分析
参考github项目YOLOv3 SPP
这一节具体内容请参考我的另一篇帖子《YOLOv3 SPP源码分析》
五、YOLOv4
参考帖子《YOLOv4网络详解》、对应bilibili视频
论文名称:《YOLOv4: Optimal Speed and Accuracy of Object Detection》、开源仓库
5.1 简介
YOLOv4是2020年Alexey Bochkovskiy等人发表在CVPR上的一篇文章,并不是Darknet的原始作者Joseph Redmon发表的,但这个工作已经被Joseph Redmon大佬认可了。如果将YOLOv4和原始的YOLOv3相比效果确实有很大的提升,但和Ultralytics版的YOLOv3 SPP相比提升确实不大,但毕竟Ultralytics的YOLOv3 SPP以及YOLOv5都没有发表过正式的文章,所以不太好讲。所以今天还是先简单聊聊Alexey Bochkovskiy的YOLOv4。
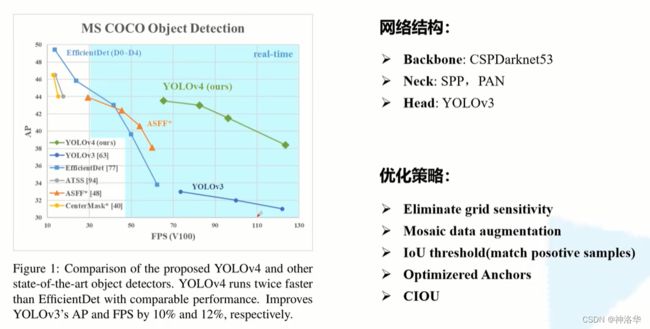
上图可以看到,YOLOv4相比YOLOv3在AP和FPs上都提升了10%-12%。
5.2 YOLOv4 网络结构
论文中,作者就是把当年所有的常用技术罗列了一遍,然后做了一堆消融实验,实验过程及结果写的还是很详细的。在论文3.4章节中介绍了YOLOv4网络的具体结构:
- Backbone:
CSPDarknet53 - Neck:
SPP,PAN - Head:
YOLOv3
相比之前的YOLOv3,改进了下Backbone,在Darknet53中引入了CSP模块(来自CSPNet)。在Neck部分,采用了SPP模块(Ultralytics版的YOLOv3 SPP就使用到了)以及PAN模块(来自PANet)。Head部分没变还是原来的检测头。
5.2.1 Backbone: CSPDarknet53
原论文有介绍CSP的作用:
- 增强CNN学习能力
- 移除计算瓶颈
- 降低对显存的占用
即CSP可以加快网络推理速度,减少显存使用,提升网络学习能力。
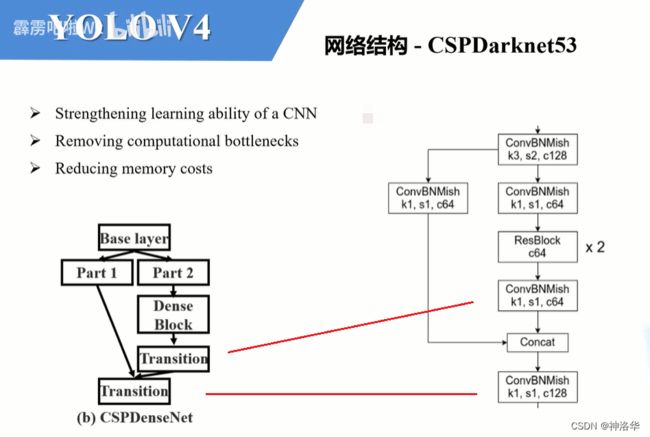
- 上图左侧是CSP原论文中绘制的CSPDenseNet:
- 进入每个stage(一般在下采样后)先将数据划分成俩部分Part1和Part2。(在CSPNet源码中是直接按照通道均分)
- 在Part2后跟一堆Blocks(CSP原论文以DenseNet为例,所以Part2后接的是 Dense Blocks。)然后再通过1x1的卷积层(图中的Transition),接着将两个分支的信息在通道方向进行Concat拼接,最后再通过1x1的卷积层进一步融合(图中的Transition)。
- 上图右侧是YOLOv4的CSP部分:
- 一般CSP模块前有一个下采样。然后通过两个1x1的卷积层将输入数据的划分为两部分。如原数据channel=128,通过两个64个1×1卷积核的卷积层将数据分为两部分。
- part2输出经过一系列ResBlock,再经过1×1卷积层(对应CSPDenseNet的第一个Transition)后和part1的输出进行cancat拼接。拼接后通过1×1卷积层(对应CSPDenseNet的第二个Transition)得到CSP模块的输出。
接下来详细分析下CSPDarknet53网络的结构,下图是帖子《YOLOv4网络详解》作者根据pytorch-YOLOv4开源仓库中代码绘制的CSPDarknet53详细结构(以输入图片大小为416 × 416 × 3为例),图中:
- k代表卷积核的大小
- s 代表步距
- c 代表通过该模块输出的特征层channels
- CSPDarknet53 Backbone中所有的激活函数都是
Mish激活函数

- 上图DownSample1中,CSP模块数据划分时通道数没有减半。ResBlock中,将通道数减半后又还原,和右边画的ResBlock模块也不一样(右边ResBlock中channel不变)
- DownSample2开始,后面的CSP模块都和刚才讲的是一样的了。
5.2.2 Neck: SPP,PAN
关于SPP,在前面YOLOv3-SPP中4.2章节有讲,不再赘述。
PAN(Path Aggregation Network)来自PANNet论文,其结构其实就是在FPN(从顶到底信息融合)的基础上加上了从底到顶的信息融合,结构如下图所示:

- 上图a模块就是FPN结构,左侧是Backbone提取特征,右侧是特征金字塔,顶层信息从上往下融合。
- b模块是底层信息往高层融合。a和b合在一起就是PAN模块。
- 关于特征层的融合,PAN原论文是直接相加
Add的方式,但在YOLOv4中是通过在通道方向Concat拼接的方式进行融合的。
下面给出整个YOLOv4的网络结构:(来自《YOLOv4网络详解》)

- 预测特征特征层1.2.3:
- Darknet53输出通过
ConvSet1、SPP、ConvSet2得到13×13×512的特征层1 - ConvSet2另一个分支接1×1卷积层、UpSample1后输出size翻倍。将这个输出和DownSample4的输出(经过1×1卷积核调整通道后)进行拼接。拼接结果通过
ConvSet3得到特征层2。同样的方法可以得到特征层3。
- Darknet53输出通过
- 三个预测特征层最终输出:
最终输出3:特征层3通过3×3卷积层、1×1卷积层(Conv2d层,没有bn和激活函数),就能得到这个预测特征层的输出。Conv2d层通道数c=(5+classes)×3。(每个预测特征层生成3个anchor模板,每个模板预测4个位置参数和obj参数以及类别参数)最终输出2:特征层3另一个分支经过下采样层和特征层2拼接,再经过ConvSet5、3×3卷积层、1×1卷积层(Conv2d层)得到预测特征层2的最终输出。同样方法得到最终输出1
5.3 优化策略
5.3.1 Eliminate grid sensitivity :消除grid网格敏感程度
预测特征层通过1×1卷积来预测最终结果。1×1卷积层每滑动到一个grid 网格,就预测这个网格对应的三个anchors的一系列信息。本文3.4章节有讲过:


但在YOLOv4的论文中作者认为这样做不太合理,比如当真实目标中心点非常靠近网格边界时时,网络的预测值需要负无穷或者正无穷时才能取到,而这种很极端的值网络一般无法达到。(比如中心点为左上角点或者右下角点时, σ ( t x ) \sigma(t_x) σ(tx)和 σ ( t y ) \sigma(t_y) σ(ty)应该趋近于0或者1)为了解决这个问题,作者引入了一个大于1的缩放系数 s c a l e x y {\rm scale}_{xy} scalexy:
b x = ( σ ( t x ) ⋅ s c a l e x y − s c a l e x y − 1 2 ) + c x b y = ( σ ( t y ) ⋅ s c a l e x y − s c a l e x y − 1 2 ) + c y b_x = (\sigma(t_x) \cdot {\rm scale}_{xy} - \frac{{\rm scale}_{xy}-1}{2}) + c_x \\ b_y = (\sigma(t_y) \cdot {\rm scale}_{xy} - \frac{{\rm scale}_{xy}-1}{2})+ c_y bx=(σ(tx)⋅scalexy−2scalexy−1)+cxby=(σ(ty)⋅scalexy−2scalexy−1)+cy
通过引入这个系数,网络的预测值能够很容易达到0或者1,现在比较新的实现方法包括YOLOv5都将s c a l e x y s c a l e x y {\rm scale}_{xy} scalexy设置为2,即:
b x = ( 2 ⋅ σ ( t x ) − 0.5 ) + c x b y = ( 2 ⋅ σ ( t y ) − 0.5 ) + c y b_x = (2 \cdot \sigma(t_x) - 0.5) + c_x \\ b_y = (2 \cdot \sigma(t_y) - 0.5) + c_y bx=(2⋅σ(tx)−0.5)+cxby=(2⋅σ(ty)−0.5)+cy
下面是 y = σ ( x ) y = \sigma(x) y=σ(x)对应sigma曲线和 y = 2 ⋅ σ ( x ) − 0.5 y = 2 \cdot \sigma(x) - 0.5 y=2⋅σ(x)−0.5对应scale曲线,很明显通过引入缩放系数scale以后,x 在同样的区间内,y 的取值范围更大,或者说y 对x 更敏感了。并且偏移的范围由原来的( 0 ,1 )调整到了( − 0.5 ,1.5 ),解决了刚才那个问题。

5.3.2 Mosaic 数据增强
Mosaic data augmentation在数据预处理时将四张图片拼接成一张图片,增加学习样本的多样性, 在4.1 章节Mosaic图像增强讲过,这里不在赘述。
5.3.3 IoU threshold正负样本匹配
在YOLOv3中针对每一个GT都只分配了一个Anchor。但在YOLOv4包括之前讲过的YOLOv3 SPP以及YOLOv5中一个GT可以同时分配给多个Anchor,它们是直接使用Anchor模板与GT Boxes进行粗略匹配,然后在定位到对应cell的对应Anchor。
首先回顾下之前在讲ultralytics版本YOLOv3 SPP源码解析时提到的正样本匹配过程。流程大致如下图所示:比如说针对某个预测特征层采用如下三种Anchor模板AT1、AT2、AT3。

- 将每个GT Boxes与每个Anchor模板进行匹配(这里直接将GT和Anchor模板左上角对齐,然后计算IoU)
- 如果GT与某个Anchor模板的IoU大于给定的阈值,则将GT分配给该Anchor模板,如图中的AT2
- 将GT投影到对应预测特征层上,根据GT的中心点定位到对应cell(图中黑色×表示cell的左上角)
- 则该cell对应的AT2为正样本。
- 如果GT中心点所在的Grid Cell有多个Anchor和GT的IoU值都大于阈值,那么这些Anchor都是正样本。也就是GT可以匹配多个Anchor模板。(原始YOLOv3每个GT只能匹配一个Anchor,详见本文3.5)
但在YOLOv4以及YOLOv5中关于匹配正样本的方法又有些许不同。主要原因在于5.3.1 Eliminate grid sensitivity中提到的缩放因子 s c a l e x y scale_{xy} scalexy,通过缩放后网络预测中心点的偏移范围已经从原来的(0,1)调整到了(−0.5,1.5)。所以对于同一个GT Boxes可以分配给更多的Anchor,即正样本的数量更多了。如下图所示:
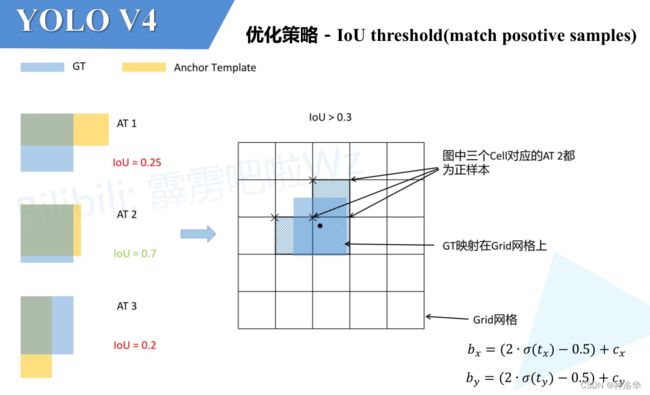
- 将每个GT Boxes与每个Anchor模板进行匹配(这里直接将GT和Anchor模板左上角对齐,然后计算IoU,在YOLOv4中IoU的阈值设置的是0.213)
- 如果GT与某个Anchor模板的IoU大于给定的阈值,则将GT分配给该Anchor模板,如图中的AT 2
- 将GT投影到对应预测特征层上,根据GT的中心点定位到对应cell(注意图中有三个对应的cell,后面会解释)
- 这三个cell对应的AT2都为正样本
为什么图中的GT会定位到3个cell?刚刚说了网络预测中心点的偏移范围已经调整到了(-0.5, 1.5),所以按理说只要Grid Cell左上角点距离GT中心点在 (-0.5, 1.5)范围内,它们对应的Anchor都能回归到GT的位置处。
上图为例,假设GT中心点为图中黑色圆点,除了当前网格外,上方网格的左上角坐标和GT中心点坐标相比,x坐标之差明显在0.5之内,y坐标之差在1.5之内。(这个中心点在当前网格是偏向左上的)所以GT也可以匹配到上方的网格。左侧网格同理。
YOLOv4和YOLOv5等改进版本都是采用类似的方法匹配正样本。 这样的方式会让正样本的数量得到大量的扩充。但需要注意的是,YOLOv5源码中扩展Cell时只会往上、下、左、右四个方向扩展,不会往左上、右上、左下、右下方向扩展。下面又给出了一些根据 G T x c e n t e r , G T y c e n t e r GT^{center}_x, GT^{center}_y GTxcenter,GTycenter的位置扩展的一些Cell,其中%1表示取余并保留小数部分。

5.3.4 Optimizer Anchors
YOLOv3中使用anchor模板是聚类得到的,YOLOv4中作者针对512 × 512 尺度采用的anchor模板进行了优化。但是YOLOv5使用的模板还是;YOLOv3原来的模板,也不知道这样做效果好不好。

5.3.5 CIoU(定位损失)
在YOLOv3中定位损失采用的是MSE损失,但在YOLOv4中作者采用的是CIoU损失。在本文4.3 CIoU Loss很详细的讲解过IoU Loss,DIoU Loss以及CIoU Loss,这里不在赘述。

六、YOLOV5
参考帖子《YOLOv5网络详解》、对应bilibili视频
论文名称:作者没有发表呢
6.1 YOLOV5简介
YOLOv5项目的作者是Glenn Jocher,也不是原Darknet项目的作者Joseph Redmon。并且这个项目至今都没有发表过正式的论文。YOLOv5仓库是在2020-05-18创建的,到今天已经迭代了很多个大版本了,2022-2-22已经迭代到v6.1了。所以本篇博文讲的内容是针对v6.1的。
下图是YOLOv5不同版本的效果。横坐标是推理速度,越小越好;纵坐标是COCO mAP。下图右上(n,s,m,l,x)模型输入分辨率为640*640,下图左下(n6,s6,m6,l6,x6)是针对输入图片分辨率更大的场景(1280*1280),效果也更好一点。除此之外,二者在模型结构上也有一点区别。本文讲的是左上角的模型。

YOLOv5(n,s,m,l,x)最大下采样倍率也是32,预测特征层也是三个(P3,P4,P5)。YOLOv5(n6,s6,m6,l6,x6)模型最大下采样倍率是64,预测特征层是四个(P3,P4,P5,P6)。
下表是当前(v6.1)官网贴出的关于不同大小模型以及输入尺度对应的mAP、CPU/GPU推理速度、参数数量以及理论计算量FLOPs。

6.2 YOLOv5网络结构
6.2.1 主要结构
YOLOv5的网络结构主要由以下几部分组成:
- Backbone: New CSP-Darknet53
- Neck: SPPF, New CSP-PAN(CSP结构也添加PAN)
- Head: YOLOv3 Head
下图是小绿豆根据yolov5l.yaml绘制的网络整体结构,YOLOv5针对不同大小(n, s, m, l, x)的网络整体架构都是一样的,只不过会在每个子模块中采用不同的深度和宽度,分别应对yaml文件中的depth_multiple和width_multiple参数。

ConvBNSINU对应的是下面yaml文件中的Conv。其余还有C3、SPPF等模块。C3类似本文5.2.1 Backbone: CSPDarknet53中讲的CSP结构。
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
YOLOv5在v6.0版本有一个很小的改动,把网络的第一层(原来是Focus模块)换成了一个6x6大小的卷积层。两者在理论上其实等价的,但是对于现有的一些GPU设备(以及相应的优化算法)使用6x6大小的卷积层比使用Focus模块更加高效。详情可以参考issue #4825。
下图是原来的Focus模块(和之前Swin Transformer中的Patch Merging类似),将每个2x2的相邻像素划分为一个patch,然后将每个patch中相同位置(同一颜色)像素给拼在一起就得到了4个feature map(高宽减半,通道数为原来四倍),然后在接上一个3x3大小的卷积层。Focus模块和直接使用一个6x6大小的卷积层等效。

6.2.2 SPPF
在Neck部分,首先是将SPP换成成了SPPF,两者的作用是一样的,但后者效率更高。SPP结构如下图所示,是将输入并行通过多个不同大小的MaxPool,然后做进一步融合,能在一定程度上解决目标多尺度问题。
SPPF结构是将输入串行通过多个5x5大小的MaxPool层,这里需要注意的是串行两个5x5大小的MaxPool层是和一个9x9大小的MaxPool层计算结果是一样的,串行三个5x5大小的MaxPool层是和一个13x13大小的MaxPool层计算结果是一样的,但是参数更少,计算量更小。(这不就是VGG和inception2改进的使用小卷积核吗)

小绿豆试验了SPP和SPPF的计算结果以及速度,发现计算结果是一模一样的,但SPPF比SPP计算速度快了不止两倍。(注意这里将SPPF中最开始和结尾处的1x1卷积层给去掉了,只对比含有MaxPool的部分):
import time
import torch
import torch.nn as nn
class SPP(nn.Module):
def __init__(self):
super().__init__()
self.maxpool1 = nn.MaxPool2d(5, 1, padding=2)
self.maxpool2 = nn.MaxPool2d(9, 1, padding=4)
self.maxpool3 = nn.MaxPool2d(13, 1, padding=6)
def forward(self, x):
o1 = self.maxpool1(x)
o2 = self.maxpool2(x)
o3 = self.maxpool3(x)
return torch.cat([x, o1, o2, o3], dim=1)
class SPPF(nn.Module):
def __init__(self):
super().__init__()
self.maxpool = nn.MaxPool2d(5, 1, padding=2)
def forward(self, x):
o1 = self.maxpool(x)
o2 = self.maxpool(o1)
o3 = self.maxpool(o2)
return torch.cat([x, o1, o2, o3], dim=1)
def main():
input_tensor = torch.rand(8, 32, 16, 16)
spp = SPP()
sppf = SPPF()
output1 = spp(input_tensor)
output2 = sppf(input_tensor)
print(torch.equal(output1, output2))
t_start = time.time()
for _ in range(100):
spp(input_tensor)
print(f"spp time: {time.time() - t_start}")
t_start = time.time()
for _ in range(100):
sppf(input_tensor)
print(f"sppf time: {time.time() - t_start}")
if __name__ == '__main__':
main()
终端输出:
True
spp time: 0.5373051166534424
sppf time: 0.20780706405639648
6.2.3 New CSP-PAN
在Neck部分另外一个不同点就是New CSP-PAN了,在YOLOv4中,Neck的PAN结构是没有引入CSP结构的,但在YOLOv5中作者在PAN结构中加入了CSP。详情见上面的网络结构图,每个C3模块里都含有CSP结构。在Head部分,YOLOv3, v4, v5都是一样的。
6.3 数据增强
在YOLOv5代码里,hyp.scratch-high.yaml列出了关于数据增强的策略,还是挺多的,这里简单罗列部分方法:
# Hyperparameters for high-augmentation COCO training from scratch
...
...
degrees: 0.0 # image rotation (+/- deg)
translate: 0.1 # image translation (+/- fraction)
scale: 0.9 # image scale (+/- gain)
shear: 0.0 # image shear (+/- deg)
perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
flipud: 0.0 # image flip up-down (probability)
fliplr: 0.5 # image flip left-right (probability)
mosaic: 1.0 # image mosaic (probability)
mixup: 0.1 # image mixup (probability)
copy_paste: 0.1 # segment copy-paste (probability
Random horizontal flip,随机水平翻转Augment HSV(Hue, Saturation, Value),随机调整色度,饱和度以及明度。Random affine(Rotation, Scale, Translation and Shear),随机进行仿射变换,但根据配置文件里的超参数发现只使用了Scale和Translation(缩放和平移)。Mosaic,将四张图片拼成一张图片,讲过很多次了Copy paste,将部分目标随机的粘贴到图片中,简单有效。前提是数据要有segments数据才行,即每个目标的实例分割信息。下面是Copy paste原论文中的示意图。

MixUp,就是将两张图片按照一定的透明度融合在一起,具体有没有用不太清楚,毕竟没有论文,也没有消融实验。代码中只有较大的模型才使用到了MixUp,而且每次只有10%的概率会使用到。
Albumentations,主要是做些滤波、直方图均衡化以及改变图片质量等等,代码里写的只有安装了albumentations包才会启用,但在项目的requirements.txt文件中albumentations包是被注释掉了的,所以默认不启用。
6.4 训练策略
在YOLOv5源码中使用到了很多训练的策略,这里简单总结几个注意到的点,可能还有些没注意到可以自己看下源码:
Multi-scale training(0.5~1.5x),多尺度训练。假设设置输入图片的大小为640×640 ,训练时采用尺寸是在0.5×640∼1.5×640之间随机取值。注意取值时取得都是32的整数倍(因为网络会最大下采样32倍)。AutoAnchor(For training custom data),训练自己数据集时可以根据自己数据集里的目标进行重新聚类生成Anchors模板。(如果自己数据集的目标和常见目标的长宽比例差异很大时可以启用)Warmup and Cosine LR scheduler,训练前先进行Warmup热身,然后在采用Cosine学习率下降策略。EMA(Exponential Moving Average),可以理解为给训练的参数加了一个动量,让参数更新过程更加平滑。Mixed precision,混合精度训练,能够减少显存的占用并且加快训练速度,前提是GPU硬件支持。理论上显存减半,速度加倍。Evolve hyper-parameters,超参数优化,没有炼丹经验的人勿碰,保持默认就好。
6.5 损失计算
YOLOv5的损失主要由三个部分组成:
Classes loss,分类损失,采用的是BCE loss,注意只计算正样本的分类损失。Objectness loss,obj损失,采用的依然是BCE loss,注意这里的obj指的是网络预测的目标边界框与GT Box的CIoU。这里计算的是所有样本的objectness损失。(YOLOv3中obj损失是根据当前anchor里面是否有目标将其设为0和1)Location loss,定位损失,采用的是CIoU loss,注意只计算正样本的定位损失。
L o s s = λ 1 L c l s + λ 2 L o b j + λ 3 L l o c Loss=\lambda_1 L_{cls} + \lambda_2 L_{obj} + \lambda_3 L_{loc} Loss=λ1Lcls+λ2Lobj+λ3Lloc
其中 λ 1 , λ 2 , λ 3 λ \lambda_1, \lambda_2, \lambda_3λ λ1,λ2,λ3λ为平衡系数。
6.5.1 平衡不同尺度的损失
针对三个预测特征层(P3, P4, P5)上的obj损失采用不同的权重,作者说这是针对COCO数据集设置的超参数。(一般来说,小目标更难检测,所以设置更大的权重)
L o b j = 4.0 ⋅ L o b j s m a l l + 1.0 ⋅ L o b j m e d i u m + 0.4 ⋅ L o b j l a r g e L_{obj} = 4.0 \cdot L_{obj}^{small} + 1.0 \cdot L_{obj}^{medium} + 0.4 \cdot L_{obj}^{large} Lobj=4.0⋅Lobjsmall+1.0⋅Lobjmedium+0.4⋅Lobjlarge
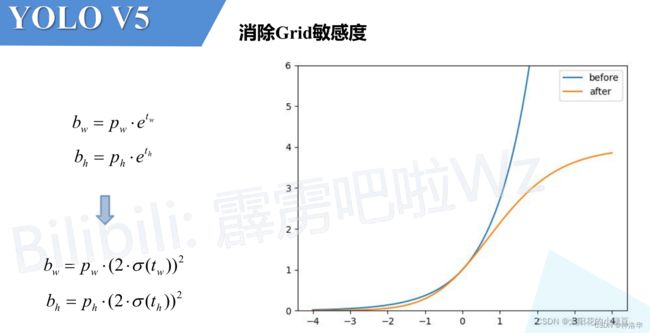
6.5.2 消除Grid敏感度
在本文5.3.1 Eliminate grid sensitivity :消除grid网格敏感程度中有提到过,为了避免真实目标中心点非常靠近网格边界时时,网络的预测值需要负无穷或者正无穷时才能取到的问题(sigmoid函数特点),YOLOv4调整了预测目标中心点x、y坐标计算公式:

在YOLOv5中除此之外还调整了预测目标高宽的计算公式:
作者Glenn Jocher的原话如下,也可以参考issue #471:
The original yolo/darknet box equations have a serious flaw. Width and Height are completely unbounded as they are simply out=exp(in), which is dangerous, as it can lead to runaway gradients, instabilities, NaN losses and ultimately a complete loss of training.
大致意思是,原来的计算公式并没有对预测目标宽高做限制,所以 t x t_x tx或者 t y t_y ty很大的时候,可能出现指数爆炸的情况。这样可能造成梯度爆炸,损失为NaN,训练不稳定等问题。上图是修改前 y = e x y = e^x y=ex和修改后 y = ( 2 ⋅ σ ( x ) ) 2 y = (2 \cdot \sigma(x))^2 y=(2⋅σ(x))2(相对Anchor宽高的倍率因子)的变化曲线, 很明显调整后倍率因子被限制在(0,4)之间。
6.6 正样本匹配(Build Targets)
YOLOv5和YOLOv4正样本匹配方式差不多,主要的区别在于GT Box与Anchor Templates模板的匹配方式。
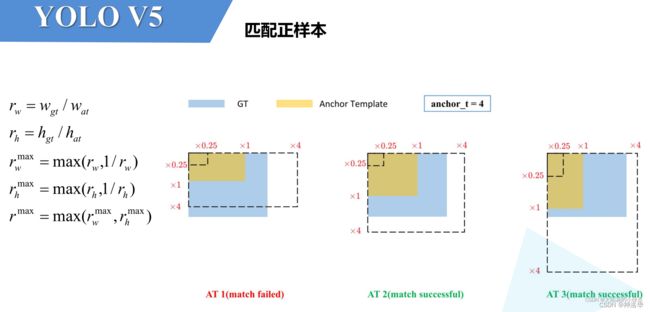
在YOLOv4中是直接将每个GT Box与对应的Anchor Templates模板计算IoU,只要IoU大于设定的阈值就算匹配成功。但在YOLOv5中,计算方式如下:
- 计算每个GT Box与对应的Anchor Templates模板的高宽比例,即:
r w = w g t / w a t r h = h g t / h a t r_w = w_{gt} / w_{at} \\ r_h = h_{gt} / h_{at} rw=wgt/watrh=hgt/hat - 然后统计这些比例和它们倒数之间的最大值,这里可以理解成计算GT Box和Anchor Templates分别在宽度以及高度方向的最大差异(当相等的时候比例为1,差异最小):
r w m a x = m a x ( r w , 1 / r w ) r h m a x = m a x ( r h , 1 / r h ) r_w^{max} = max(r_w, 1 / r_w) \\ r_h^{max} = max(r_h, 1 / r_h) rwmax=max(rw,1/rw)rhmax=max(rh,1/rh) - 接着统计 r w m a x r_w^{max} rwmax和 r h m a x r_h^{max} rhmax之间的最大值,即宽度和高度方向差异最大的值:
r m a x = m a x ( r w m a x , r h m a x ) r^{max} = max(r_w^{max}, r_h^{max}) rmax=max(rwmax,rhmax)
如果GT Box和对应的Anchor Template的 r m a x r^{max} rmax小于阈值anchor_t(在源码中默认设置为4.0,因为调整后,YOLOv5的Anchor宽高缩放比例最大是4倍),即GT Box和对应的Anchor Template的高、宽比例相差不算太大,则将GT Box分配给该Anchor Template模板。
为了方便大家理解,可以看下图。假设对某个GT Box而言,其实只要GT Box满足在某个Anchor Template宽和高的 × 0.25 \times 0.25 ×0.25倍和 × 4.0 \times 4.0 ×4.0倍之间就算匹配成功。
剩下的步骤和YOLOv4中一致:
- 将GT投影到对应预测特征层上,根据GT的中心点定位到对应Cell,注意图中有三个对应的Cell。这样会让正样本的数量得到大量的扩充。(5.3.3 IoU threshold正负样本匹配中有讲为什么是匹配到三个cell)
- 这三个Cell对应的AT2和AT3都为正样本。

YOLOv5源码中扩展Cell时只会往上、下、左、右四个方向扩展,不会往左上、右上、左下、右下方向扩展。下面又给出了一些根据 G T x c e n t e r , G T y c e n t e r GT^{center}_x, GT^{center}_y GTxcenter,GTycenter的位置扩展的一些Cell,其中%1表示取余并保留小数部分。
6.7 YOLOv5应用demo
参考我的另一篇帖子《yolov5s V6.1版本训练PASCAL VOC2012数据集&yolov5官网教程Train Custom Data》
七、 FCOS
FCOS论文名称:FCOS: Fully Convolutional One-Stage Object Detection
参考博文:《FCOS网络解析》、bilibili视频讲解
7.1 基于Anchor的目标检测模型缺点
在之前讲的一些目标检测网络中,比如Faster RCNN系列、SSD、YOLOv2~v5(注意YOLOv1不包括在内)都是基于Anchor进行预测的。先在原图上生成一堆密密麻麻的Anchor Boxes,然后网络基于这些Anchor去预测它们的类别、中心点偏移量以及宽高缩放因子得到网络预测输出的目标,最后通过NMS即可得到最终预测目标。
那基于Anchor的网络存在哪些问题呢,在FCOS论文的Introduction中,作者总结了四点:
- 检测器的性能和Anchor模板的设计相关(size和高宽比)。 比如在RetinaNet中改变
Anchor size能够产生约4%的AP变化。换句话说,Anchor设计的好坏,对最终结果影响还是很大的。 - 有限的Anchor很难适配所有场景。 一般Anchor的size和aspect ratio都是固定的,所以很难处理那些形状变化很大的目标。而且迁移到其他任务中时,如果新的数据集目标和预训练数据集中的目标形状差异很大,一般需要重新设计Anchor。(比如一本书横着放w远大于h,竖着放h远大于w,斜着放w可能等于h,很难设计出合适的Anchor)
- 为了达到更高的召回率,每张图片都要生成大量的Anchor,大部分是负样本,这样就造成 正负样本极度不平衡。 (比如说在FPN(Feature Pyramid Network)中会生成超过18万个Anchor Boxes(以输入图片最小边长800为例))
- Anchor的引入使得网络在训练过程中更加的繁琐。因为匹配正负样本时需要计算每个Anchor Boxes和每个GT BBoxes之间的IoU,来进行正负样本匹配。
下图是随手画的样例,红色的矩形框都是负样本,黄色的矩形框是正样本。

7.2 FCOS简介
现今有关Anchor-Free的网络也很多,比如DenseBox、YOLO v1、CornerNet、FCOS以及CenterNet等等,而我们今天要聊的网络是FCOS(它不仅是Anchor-Free还是One-Stage,FCN-base detector)。
FCOS是一篇发表在2019年CVPR上的文章,这篇文章的想法不仅简单而且很有效,它的思想是跳出Anchor的限制,在预测特征图的每个位置上直接去预测该点分别距离目标左侧(l: left),上侧(t:top),右侧(r: right)以及下侧(b:bottom)的距离,有了这四个距离参数,就可以直接得到预测边界框了,如下图所示:

下图是FCOS相比当年主流检测模型的效果对比图:

7.3 FCOS网络结构
FCOS论文有2019和2020两个版本。区别在于
Center-ness分支的位置,在2019年论文的图中是将Center-ness分支和Classification分支放在一起的,但在2020年论文的图中是将Center-ness分支和Regression分支放在一起。论文中也有解释,将Center-ness分支和Regression分支放在一起能够得到更好的结果。
下面这幅图是2020年FCOS论文中给出的网络结构:
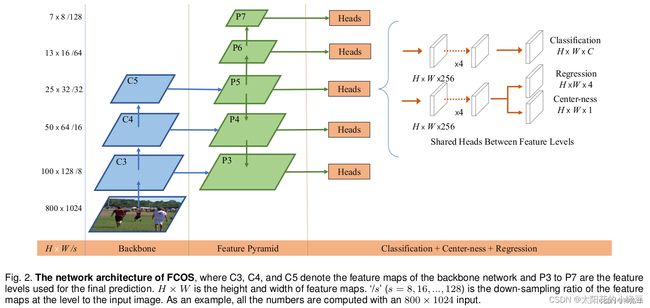
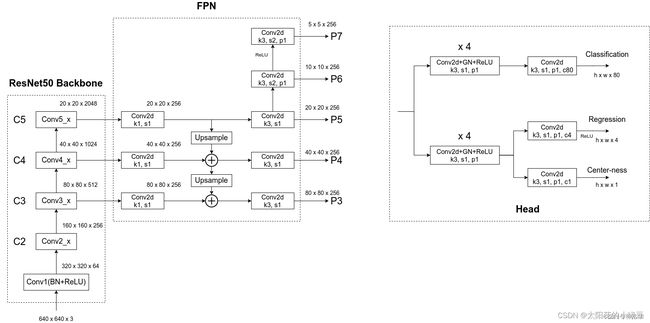
下面这张图是小绿豆结合Pytorch官方实现FCOS的源码,绘制的更加详细的网络结构:
- Backbone:
ResNet50 - Nack:
FPN - Head:共享检测头
详细来说:
FPN是在Backbone输出的C3、C4和C5上先生成P3、P4和P5,接着 P 5 → C o n v 2 d ( k 3 , s 2 , p 1 ) P 6 → C o n v 2 d ( k 3 , s 2 , p 1 ) P 7 P5\overset{Conv2d(k3,s2,p1)}{\rightarrow}P6\overset{Conv2d(k3,s2,p1)}{\rightarrow}P7 P5→Conv2d(k3,s2,p1)P6→Conv2d(k3,s2,p1)P7,所以FCOS一共有五个预测特征层。- P3到P7共享一个Head检测头,这个Head有三个分支:
Classification、Regression和Center-ness,Regression和Center-ness是同一个分支上的两个不同小分支。 - 每个分支都会先通过4个
Conv2d+GN+ReLU的组合模块,然后再通过一个Conv2d(k3,s1,p1)卷积层和1×1卷积层得到最终的预测结果。Classification分支,在预测特征图的每个位置上都会预测80个score参数(COCO数据集的类别数)Regression分支,在预测特征层的每个位置上都会预测4个距离参数。-
由于是Anchor Free的模型,所以一个网格只预测4个位置参数就行。而之前的基于Anchor Base的模型,比如YOLOV2到YOLOV5,一个网格预测三Anchor模板,就是12个位置参数。
-
这四个参数是上面提到的ltrb参数,是相对于特征层尺度上的。假设对于预测特征图上某个点映射回原图的坐标是 ( c x , c y ) (c_x, c_y) (cx,cy),特征图相对原图的步距是s,那么该点映射回原图的目标边界框左上角、右下角坐标分别为:
x m i n = c x − l ⋅ s , y m i n = c y − t ⋅ s x m a x = c x + r ⋅ s , y m a x = c y + b ⋅ s x_{min}=c_x - l \cdot s \ , \ \ y_{min}=c_y - t \cdot s \\ x_{max}=c_x + r \cdot s \ , \ \ y_{max}=c_y + b \cdot s xmin=cx−l⋅s , ymin=cy−t⋅sxmax=cx+r⋅s , ymax=cy+b⋅s Center-ness:反映的是预测特征层上每个点距离目标中心的远近程度该点。center-ness真实标签的计算公式如下:(这个公式是求比值,无量纲。在特征图或者原图上算都一样)
c e n t e r n e s s ∗ = m i n ( l ∗ , r ∗ ) m a x ( l ∗ , r ∗ ) × m i n ( t ∗ , b ∗ ) m a x ( t ∗ , b ∗ ) centerness^*=\sqrt{\frac{min(l^*,r^*)}{max(l^*,r^*)} \times \frac{min(t^*,b^*)}{max(t^*,b^*)}} centerness∗=max(l∗,r∗)min(l∗,r∗)×max(t∗,b∗)min(t∗,b∗)
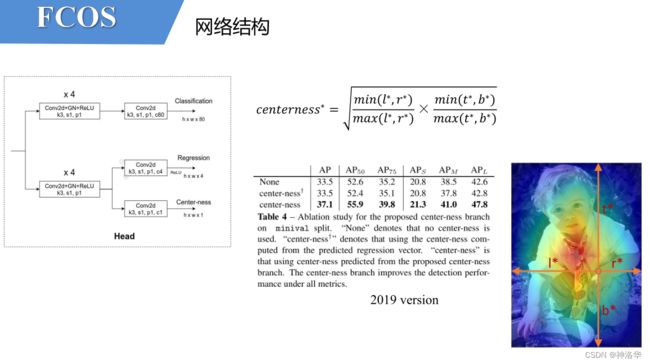
Center-ness计算损失时只考虑正样本,即预测点在目标内的情况。上图*代表真实标签,没有*就是网络预测值。 l ∗ , t ∗ l^{*},t^{*} l∗,t∗等表示这个预测点距离GT Box真实框的距离。可以看到它的值域在0~1之间,距离目标中心越近center-ness越接近于1。- 上图表格是给出的消融试验结果,加了
Center-ness之后,mAP从33.5提升到37.1,还是很有用的。
7.4 正负样本匹配
7.4.1 center sampling匹配准则
在基于Anchor的目标检测网络中,一般会通过计算每个Anchor Box与每个GT的IoU配合事先设定的IoU阈值去匹配。比如某个Anchor Box与某个GT的IoU大于0.7,那么我们就将该Anchor Box设置为正样本。但对于Anchor-Free的网络根本没有Anchor,那该如何匹配正负样本呢?

- 2019版FCOS论文是说,对于特征图上的某一点( x , y ) ,只要落入GT box内的点都是正样本(左上图
√的区域)。上图黑点对应的是特征图√处映射回原图的位置。后来作者发现,只将落入GT box中间某个区域的点视为正样本,效果会更好,这个区域就叫sub-box(右上图√的区域)。 - 2020版论文中就增加了这个规则,并给出了
sub-box计算公式: ( c x − r s , c y − r s , c x + r s , c y + r s ) (c_x - rs, c_y - rs, c_x + rs, c_y + rs) (cx−rs,cy−rs,cx+rs,cy+rs)
其中 ( c x , c y ) (c_x, c_y) (cx,cy)是GT的中心点坐标;s是特征图相对原图的步距;r是一个超参数,用来控制距离GT中心的远近。换句话说预测点不仅要在GT的范围内,还要离GT的中心点足够近才能被视为正样本。 (关于r的消融实验可以看上图右下角表格,在COCO数据集中r设置为1.5效果最好。)
7.4.2 Ambiguity问题
如果feature map上的某个点同时落入两个GT Box内,那该点到底分配给哪个GT Box,这就是论文中提到的Ambiguity问题。如下图所示,橙色圆圈对应的点同时落入人和球拍两个GT Box中,此时 默认将该点分配给面积Area最小的GT Box ,即图中的球拍。这并不是一个很好的解决办法,不过在引入FPN后,能够减少这种情况。

- 上图是作者在COCO2017的val数据上进行的分析。
- 在FPN中会采用多个预测特征图,不同尺度的特征图负责预测不同尺度的目标。这样在匹配正负样本时能够将部分重叠在一起的目标(这里主要指不同尺度的目标)给分开,即解决了大部分ambiguous samples问题。
比如上图,feature map1是更底层的预测特征层,适合预测大目标——人。feature map2是更顶层的预测特征层,适合预测小目标——球拍。此时进行正负样本匹配,ambiguous samples问题就得到解决了。
- 再采用center sampling匹配准则(落入GT box以及sub-box范围内的才算正样本),能够进一步降低ambiguous samples的比例。
7.5 损失计算

- 回归分支和Center-ness分支前有 1 { c x , y ∗ > 0 } 1_{\{c^*_{x,y}>0\}} 1{cx,y∗>0}这一项,所以这两个分支只会计算正样本的损失。
- s x , y ∗ s^*_{x,y} sx,y∗是特征图(x,y)处的真实
Center-ness,计算公式就是上面提到的 c e n t e r n e s s ∗ centerness^* centerness∗计算公式。公式右边 l ∗ , t ∗ l^{*},t^{*} l∗,t∗等表示这个预测点距离GT Box的真实距离。
7.6 Assigning objects to FPN
这部分内容只在2020版的论文中2.2章节有进行讨论,讲的是按照怎样的准则将目标划分到对应尺度的特征图上。在FPN中是采用如下计算公式分配的:
k = ⌊ k 0 + l o g 2 ( w h / 224 ) ⌋ k = \left \lfloor {k_0 + log_2(\sqrt{wh} / 224)} \right \rfloor k=⌊k0+log2(wh/224)⌋
但在FCOS中,作者发现直接套用FPN中的公式效果并不是很好。作者猜测是因为按照FPN中的分配准则,不能确保目标在对应感受野范围内。比如对于某个特征层,每个cell的感受野为28x28,但分配到该特征层上的目标为52x52(举的这个例子可能不太恰当,因为head中采用的都是3x3大小的卷积层)。下面是作者自己尝试的一些其他的匹配策略:

最终采用的是 m a x ( l ∗ , t ∗ , r ∗ , b ∗ ) max(l^*,t^*,r^*,b^*) max(l∗,t∗,r∗,b∗)策略,即对于不同的预测特征层只要满足以下公式即可:
m i − 1 < m a x ( l ∗ , t ∗ , r ∗ , b ∗ ) < m i m_{i-1} < max(l^*,t^*,r^*,b^*) < m_i mi−1<max(l∗,t∗,r∗,b∗)<mi
其中 l ∗ , t ∗ , r ∗ , b ∗ l^*,t^*,r^*,b^* l∗,t∗,r∗,b∗分别代表某点(特征图映射在原图上)相对GT Box左边界、上边界、右边界以及下边界的距离。 m i m_i mi的值如上图红色方框所示。比如说对于P4特征图只要 m a x ( l ∗ , t ∗ , r ∗ , b ∗ ) max(l^*,t^*,r^*,b^*) max(l∗,t∗,r∗,b∗)在( 64 , 128 ) 之间即为正样本。
八、YOLOX
论文名称:《YOLOX: Exceeding YOLO Series in 2021》、论文源码地址
参考:太阳花的小绿豆《YOLOX网络结构详解》、bilibili视频讲解
8.1 前言
YOLOX是旷视科技在2021年发表的一篇文章,对标的网络就是当时很火的YOLO v5。YOLOX主要改进有三点:decoupled head、anchor-free以及advanced label assigning strategy(SimOTA)。下图是原论文中YOLOX性能对比图,比当年的YOLO v5略好一点。论文中说他们利用YOLOX获得了当年的Streaming Perception Challenge的第一名。
在自己的项目中YOLO v5和YOLOX到底应该选择哪个。如果你的数据集图像分辨率不是很高,比如640x640,那么两者都可以试试。如果你的图像分辨率很高,比如1280x1280,那么我建议使用YOLO v5。因为YOLO v5官方仓库有提供更大尺度的预训练权重,而YOLOX当前只有640x640的预训练权重。

8.2 YOLOX网络结构
下图是小绿豆绘制的YOLOX-L网络结构。YOLOX-L网络是基于YOLOv5 tag:v5.0版本改进的,所以其Backbone以及PAN部分和YOLO v5是一模一样的,只是检测头不一样。
YOLOv5 tag:v5.0版本和上一章讲的v6.1版本有些细微的差别。
- 一是v6.1版本取消了网络的第一层(原来是Focus模块),换成了一个6x6大小的卷积层。两者在理论上其实等价的,但是对于现有的一些GPU设备(以及相应的优化算法)使用6x6大小的卷积层比使用Focus模块更加高效。(详情参考本文6.2 YOLO v5网络结构部分)
- 二是v6.1版本将Nack部分
SPP结构换成SPPF,将输入串行通过多个5x5大小的MaxPool层,达到和SPP一样的效果。但后者参数更少,计算量更少,效率更高。另外SPPF摆放位置也有点不一样。 - BottleNeck堆叠次数稍有不同

YOLOX和YOLO v5在网络结构主要的差别就在检测头head部分。
之前的检测头就是通过一个Conv2d(kernel_size=1,stride=1,padding=0)的卷积层实现的,即这个卷积层要同时预测类别分数、边界框回归参数以及object ness,这种方式在文章中称之为coupled detection head(耦合的检测头),作者说这样是对网络有害的。
如果将coupled detection head换成decoupled detection head(解耦的检测头)能够大幅提升网络的收敛速度。在论文的图3中展示了YOLO v3分别使用coupled detection head和decoupled detection head的训练收敛情况,明显采用decoupled detection head后收敛速度会更快(在论文的表2中显示采用decoupled detection head能够提升AP约1.1个点)。

- 上图蓝色线和橙色线分别是在
YOLOv3上使用解耦检测头和耦合的检测头的效果,可以看出解耦检测头收敛明显更快。 - 在
decoupled detection head中对于预测Cls.(类别)、Reg.(回归参数)以及IoU(objcetness)参数分别使用三个不同的分支,这样就将三者进行了解耦。 - 另外需要注意两点,一是在YOLOX中对于不同的预测特征图采用不同的head,即参数不共享(在FCOS中Head参数是共享的);二是预测Reg回归参数时,和FCOS类似,二者都是Anchor Free网络,所以针对预测特征图的每个grid cell,只会预测四个回归参数,而不是像之前基于Anchor 模型那样,回归参数×3。
8.3 Anchor-Free
YOLOX也是一个Anchor-Free的网络,并且借鉴了FCOS中的思想。上面说过YOLOX的decoupled detection head,对预测特征层(feature map/Grid 网格)上的每一个位置都预测了 n u m c l s + 4 + 1 num_{cls}+4+1 numcls+4+1个参数,即类别数、位置回归参数和objcetness参数(图中标的是IoU.)。
YOLOX是Anchor-Free的网络,所以head在每个位置处直接预测4个目标边界框参数 [ t x , t y , t w , t h ] [t_x, t_y, t_w, t_h] [tx,ty,tw,th]如下如所示,这4个参数分别对应预测目标中心点相对Grid Cell左上角 ( c x , c y ) (c_x, c_y) (cx,cy)的偏移量,以及目标的宽度、高度因子,注意这些值都是相对预测特征层尺度上的,如果要映射回原图需要乘上当前特征层相对原图的步距stride。

关于如何将预测目标边界框信息转换回原图尺度可参考源码中decode_outputs函数(在源码项目中的yolox -> models -> yolo_head.py文件中):
def decode_outputs(self, outputs, dtype):
grids = []
strides = []
for (hsize, wsize), stride in zip(self.hw, self.strides):
yv, xv = meshgrid([torch.arange(hsize), torch.arange(wsize)])
grid = torch.stack((xv, yv), 2).view(1, -1, 2)
grids.append(grid)
shape = grid.shape[:2]
strides.append(torch.full((*shape, 1), stride))
grids = torch.cat(grids, dim=1).type(dtype)
strides = torch.cat(strides, dim=1).type(dtype)
outputs[..., :2] = (outputs[..., :2] + grids) * strides # 预测目标边界框中心坐标
outputs[..., 2:4] = torch.exp(outputs[..., 2:4]) * strides # 预测目标边界框宽度和高度
return outputs
8.4 正负样本匹配策略SimOTA
8.4.1 cost含义和计算
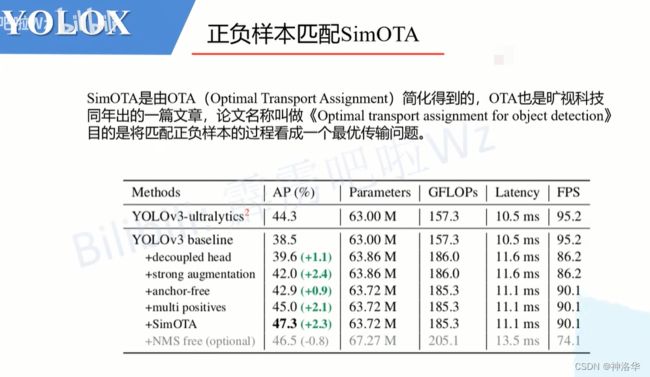
OTA是旷视科技同年出的一篇文章,论文名称叫做《Optimal transport assignment for object detection》
训练网络时就是通过SimOTA来进行正负样本的匹配。而SimOTA是由OTA(Optimal Transport Assignment)简化得到的。根据原论文中的表二,可以看到,在YOLO v3的基准上使用SimOTA后能够给AP带来2.3个点的提升。
OTA简单来说就是 将匹配正负样本的过程看成一个最优传输问题。
举个简单的例子。如下图所示,假设有1到6共6个城市(图中的五角星),有2个牛奶生产基地A和B。现在要求这两个牛奶生产基地为这6个城市送牛奶,究竟怎样安排才能最小化运输成本。假设运输成本(cost)仅由距离决定,那么很明显城市1、2、3由牛奶生产基地A负责,城市4、5、6由牛奶生产基地B负责,运输成本最低。

那么在SimOTA正负样本匹配过程中,城市对应的是每个样本(对应论文中的anchor point,其实就是grid网格中的每个cell),牛奶生产基地对应的是标注好的GT Bbox,那现在的目标是怎样以最低的成本(cost)将GT分配给对应的样本。根据论文中的公式1,cost的计算公式如下,其中 λ \lambda λ为平衡系数,代码中设置的是3.0:
c i j = L i j c l s + λ L i j r e g c_{ij}=L_{ij}^{cls}+\lambda L_{ij}^{reg} cij=Lijcls+λLijreg
通过公式可以得知,成本cost由分类损失和回归损失两部分组成。所以网络预测的类别越准确cost越小,网络预测的目标边界框越准确cost越小。那么最小化cost可以理解为让网络以最小的学习成本学习到有用的知识。
那是不是所有的样本都要参与cost的计算呢,当然不是。这里先回忆一下之前讲过的FCOS网络,它将那些落入GT中心sub-box范围内的anchor point视为正样本,其他的都视为负样本。

SimOTA也类似。它首先会进行一个预筛选,即将落入特征图上的目标GT Bbox内或落入固定中心区域fixed center area内的样本给筛选出来。fixed center area就类似上面FCOS的sub-box。
在源码中作者将center_ratius设置为2.5,即fixed center area是一个5x5大小的box。如下图所示,feature map(或者称grid网格)中所有打勾的位置都是通过预筛选得到的样本(anchor point)。进一步的,将落入GT Bbox与fixed center area相交区域内的样本用橙色的勾表示。

接着计算这些预筛选样本和每个GT之间的cost。在源代码中,计算代码如下:
cost = (
pair_wise_cls_loss
+ 3.0 * pair_wise_ious_loss
+ 100000.0 * (~is_in_boxes_and_center) #论文中没写,源码中有
)
其中:
pair_wise_cls_loss:每个样本与每个GT之间的分类损失 L i j c l s L_{ij}^{cls} Lijcls;pair_wise_ious_loss:每个样本与每个GT之间的回归损失 L i j r e g L_{ij}^{reg} Lijreg;(回归损失是IoULoss,每个anchor point预测的边界框和每个GT的IOU)~is_in_boxes_and_center:不在GT Bbox与fixed center area交集内的样本,即上图中黑色色勾对应的样本。(~表示取反)。接着乘以100000.0,也就是说对于GT Bbox与fixed center area交集外的样本cost加上了一个非常大的系数,这样在最小化cost过程中会优先选择GT Bbox与fixed center area交集内的样本。
8.4.2 利用cost进行正负样本的匹配
以下内容全部是按照源码中的计算流程进行讲解,可能没那么容易理解,如果想看懂源码的话建议多看几遍。
- 第二次筛选样本:如下图,构建之前筛选出的Anchor Point与每个GT之间的cost矩阵以及IoU矩阵,然后根据IOU,第二次筛选出前
n_candidate_k个Anchor Point。
下图公式可以看到,
n_candidate_k是取10和预筛选的Anchor Point数量之间的最小值。下面给的这个示例中由于Anchor Point数量为6,所以n_candidate_k=6,这次筛选依旧保留了所有的Anchor Point。

- 动态计算每个GT分配的正样本数量: 对每个GT,其分配到的正样本数量为
dynamic_ks。下图计算代码top_ious.sum(1).int()表示,dynamic_ks是每个GT和第二次筛选剩下的Anchor Point的IOU之和,并向下取整得到的。
这个计算过程对应论文中的
Dynamic k Estimation Strategy),每个GT分配到的正样本个数是不一样的。
对于下面的示例,GT1的所有Anchor Point的IoU之和为3.0,向下取整还是3。所以对于GT1有3个正样本,同理GT2也有3个正样本。
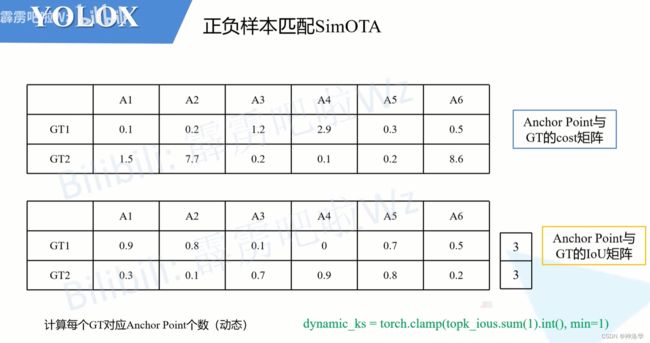
- 找出每个GT对应的正样本,并构建正样本分配矩阵:每个GT选取前
dynamic_ks个cost值最小的Anchor Point作为其正样本。再构建一个Anchor Point分配矩阵,记录每个GT对应哪些正样本。对应正样本的位置标1,其他位置标0。
比如刚刚示例中的GT1、GT2,都是有
dynamic_ks=3个正样本。cost按照从小到大的顺序,那么GT1对应的正样本是A1、A2和A5;GT2对应的正样本是A3、A4和A5。根据以上结果,我们构建一个Anchor Point分配矩阵如下图所示。
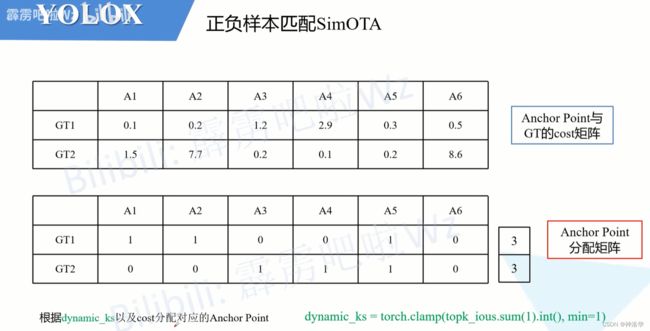
4. 冲突判断 :按照上面示例我们会发现一个问题,即GT1和GT2同时分配给了A5。作者为了解决这个带有歧义的问题,又加了一个判断。如果多个GT同时分配给一个Anchor Point,那么只选cost最小的GT。在示例中,由于A5与GT2的cost小于与GT1的cost,故只将GT2分配给A5。

根据以上流程就能找到所有的正样本以及正样本对应的GT了,那么剩下的Anchor Point全部归为负样本。接下来就可以进行损失计算和正向传播了。
8.5 损失计算
