spss聚类分析_SPSS聚类分析对比:2种聚类方法哪个更好用?

聚类分析是将物理或者抽象对象的集合分成相似的对象类的过程。本次实验我将对同一批数据做两种不同的类型的聚类;它们分别是系统聚类和K-mean 聚类。其中系统聚类的聚类方法也采用3种不同方法,来考察对比它们之间的优劣。由于没有样本数据,因此不能根据其数据做判别分析。评价标准主要是观察各聚 类方法的所得到的类组间距离和组内聚类的大小。
分析数据依然采用线性回归所使用的标准化后的能源消费数据。
系统聚类
本次实验的系统聚类都是凝聚系统聚类,为了控制变量,都采用平方Euclidean距离。
1.最短距离聚类法
最短距离法聚类步骤如下:
规定样本间的距离,计算样本两两之间的距离,得到对称矩阵。开始每个样品自成一类。
选择对称矩阵中的最小非零元素。将两个样品之间最小距离记为D1,将这两个样品归并成为一类,记为G1。
计算G1与其他样品距离。重复以上过程直到所有样品合并为一类。
我们在SPSS中实现最短距离分析非常简单。
单击![]() 再选择
再选择![]() 最后
最后![]()
将弹出如图1-1所示的对话框,设置相应的参数即可。

图1-1 最短距离法
我们的数据已经做过标准化,在“转化值”-->“标准化”选项上选无。
在统计量的聚类成员中选择“无”,因为这是非监督分类,不需要指定最终分出的类个数。在绘制中选择绘制“树状图”。单击确定,得到以下结果。
表1-2显示了数据的缺失情况:
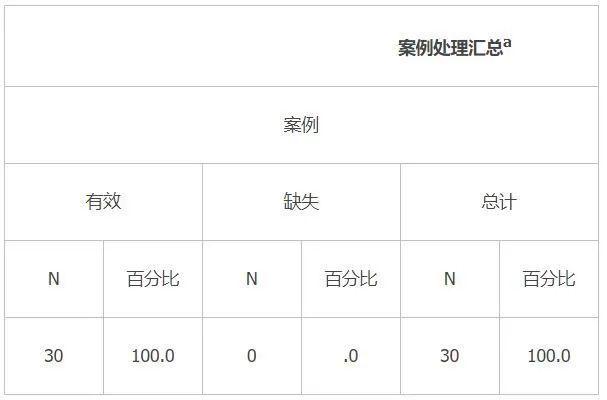
表1-2 数据汇总
我们的数据经过预处理,所以缺失值个数为0。
由于相关矩阵过于庞大,无法在文档中贴出,得到的是一个非相似矩阵。表1-3是样品聚类过程。样品21和28在第一步合并为一类,它们之间的非相关系数最小,为0.211。在下一次合并是第十步。在第五步的时候,样品2、27、14组成一类,出现群集,样品个数为3。如上类推,可以解释表格。
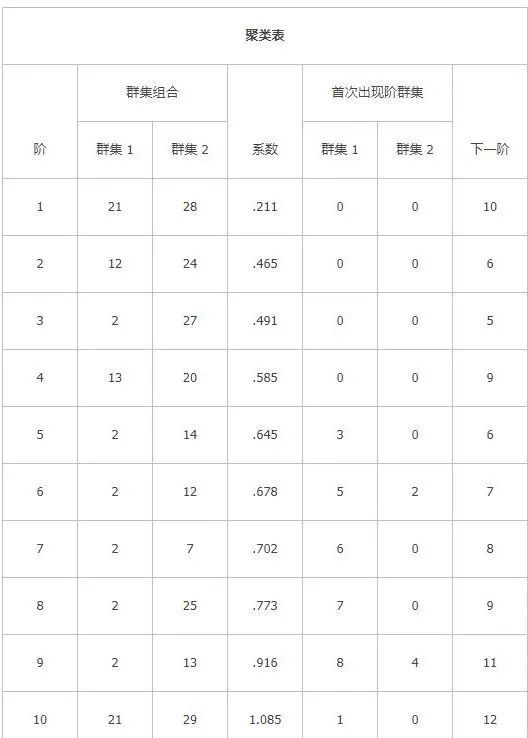


表1-3 聚类过程
我们可以通过更加形象直观的树状图来观察整个聚类过程和聚类效果。如图1-4所示,最短距离法组内距离小,但组间距离也较小。分类特征不够明显,无法凸显各个省份的能源消耗的特点。但是我们可以看到广东省能源消耗组成和其他省份特别不同,在其他方法中也显现出来。

图1-4 最短距离法聚类图
2.组间联接聚类
组间联接聚类法定义为两类之间的平均平方距离,即:

类CK和CL 合并为下一步的CM 则CM与CJ距离的递推公式为:
我们依然贴出组间联接法的聚类表和树状图。
聚类表如表1-5所示,相关解释类似于表1-5所述。


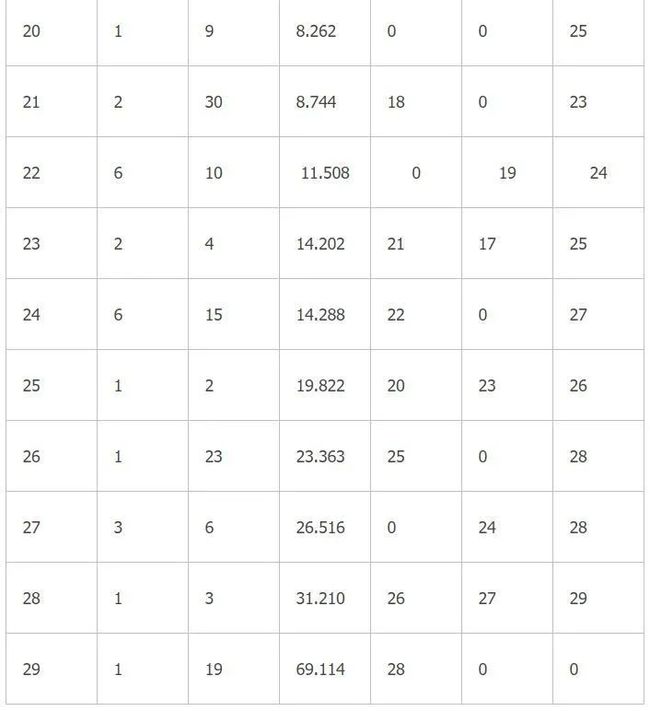 表1-5 组间联接聚类法
表1-5 组间联接聚类法
从树状图可以看到聚类的组间距离较大,组内距离较小。聚类结果较为理想。可以看到海南与青海,宁夏自治区,重庆市的能源消耗特点近似,北京、上海两地能源消耗特点也近似。江浙两地亦然。最后广东和各地能源消耗特点都不同。

3.Ward法聚类
Ward即离差平方和法。它的思想是,同类离差平方和较小,类间偏差平方和较大。Ward方法并类时总是使得并类导致的类内离差平方和增量最小。
公式:
递推公式:
我依然贴出ward法聚类表和树状图。
聚类表如表1-6所示。

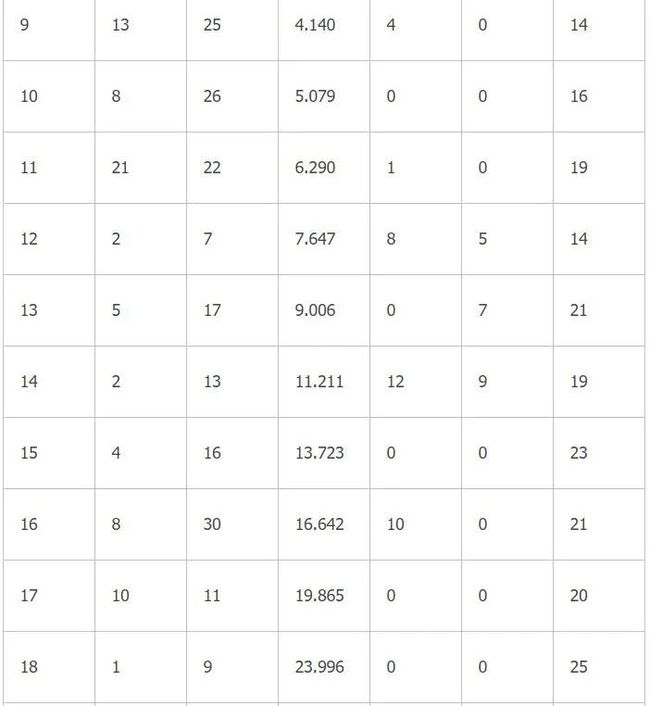


表1-6 Ward法聚类表
树状图如图1-7所示,我们可以看到这个结果较以上两种方法都为理想,组内距离都很小,控制在五次迭代之内。然后组间距离非常大。各分类的样品也基本符合它们的能源消耗特点。最后在接近10次迭代,广东被归入山东、山西这两个分别是能源消耗大省和能源产量大省的一类,说明它们之间的相似度也不大。
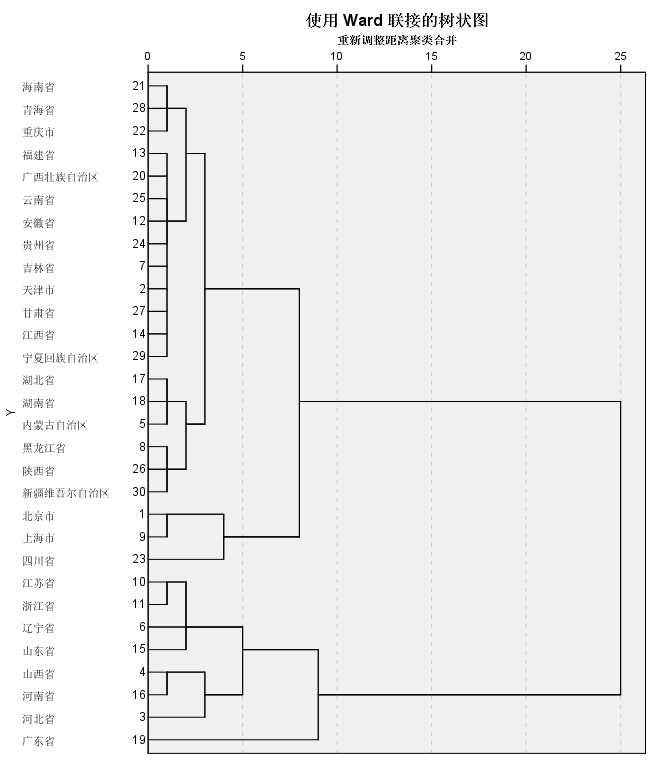
图1-7 Ward法聚类树状图
K-mean聚类
K-mean聚类是用户指定类别数的大样本资料的逐步聚类分析。所谓逐步聚类分析就是先把被聚对象进行初始分类,然后逐步调整,得到最终K个分类。K-mean法对离群点敏感容易扭曲数据分布。
单击![]() 再点击
再点击![]() 最后
最后![]()
将弹出如图1-8所示的对话框,我们根据系统聚类法的经验将K选择为5。迭代次数和系统聚类一样选择25次。

图1-8 K-mean聚类设置
下面输出和解释K-mean聚类结果。
表1-9是K-mean的迭代历史记录,非常明了。
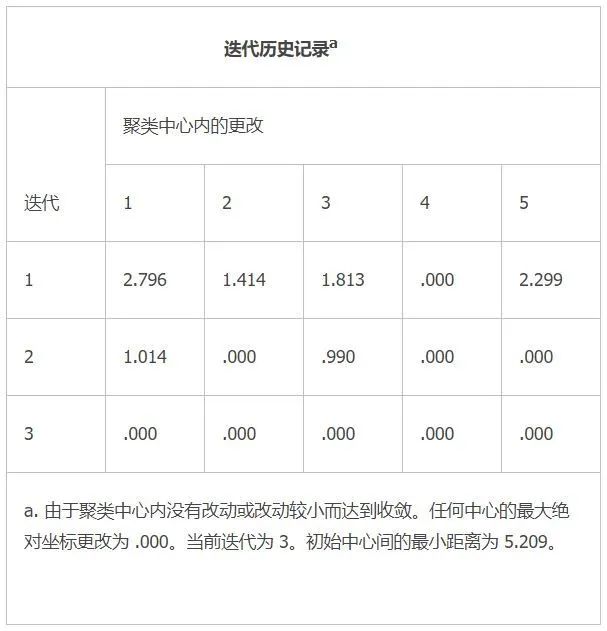
表1-9 迭代历史记录
表1-10是每个聚类样品数表。就是该次K-mean聚类所形成的类它们的样品数量。
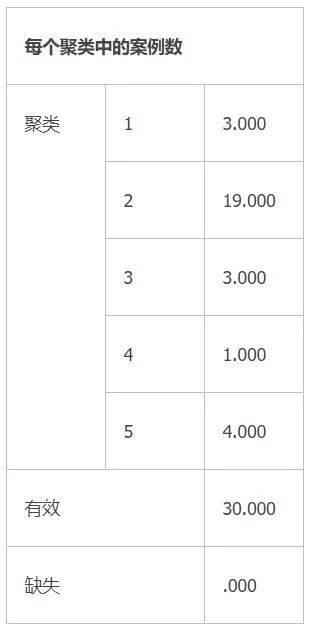
表1-10 聚类样品数
表1-11是K-mean聚类的各个类的具体成员。距离代表的是样品自身和种子点的距离。


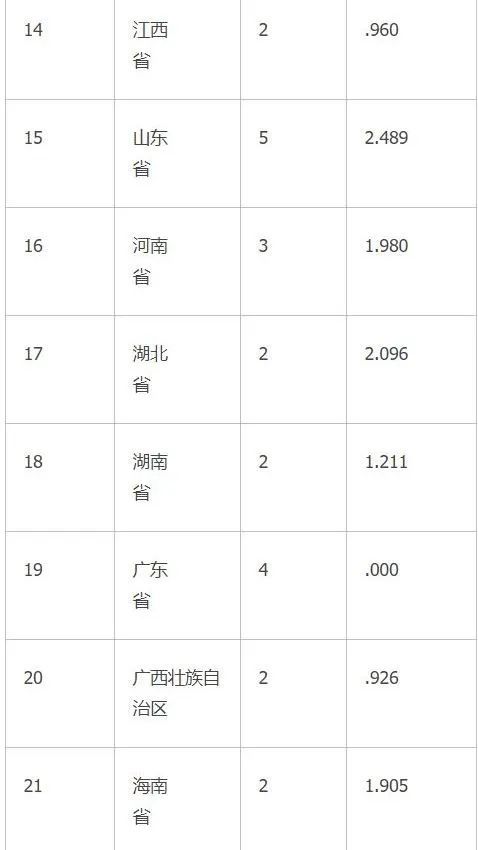

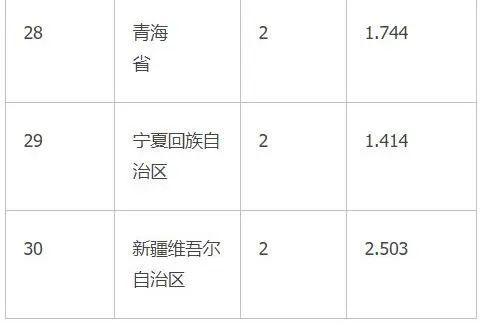
表1-11 聚类成员
最后看到分类结果与ward法有所相似,但是组内距离较大。实际效果不如Ward法。而且该方法需要事先设定分类的个数,并不适合没有先验知识的条件下的数据聚类。
总结
本次实习主要通过一批国内的能源消耗和产量数据,来实现回归分析和聚类分析。回归分析得到一个拟合度良好多元线性回归方程:Y=0.008+1.061x1+0.087x2+0.157x3-0.365x4-0.105x5-0.017x6 。该方程的残差分析也通过了。聚类分析通过比较三种不同的系统聚类方法,同时还比较了K-mean方法与系统聚类法的不同。在处理该批数据的四种聚类方法中,以ward法最为理想。Ward法所做的聚类得到组间距离最大,组内距离最小。
零基础·入职数据分析就业班 就业班学员专享: 趣味月考 测试、 数据库模拟练习 1v1职场生涯规划 班主任监督辅导 专业讲师团队答疑 加入我们你将拥有: 1. 熟练掌握 SQL/Python/Excel/PPT 等数据分析工具的能力 2. 真实数据库 的实战项目经历 3. 数据职场讲师 1v1生涯规划 5月班正在火热报名中!快来扫码咨询吧!End.
作者:lclc
来源:博客园
本文为转载分享,如侵权请联系后台删除

 点击“阅读原文”,入职数据分析
点击“阅读原文”,入职数据分析