分类算法
1. 简介
1.1 定义
- 分类算法通过对已知类别训练集的计算和分析,从中发现类别规则并预测新数据的类别。
1.2 应用场景
-
分类算法是解决分类问题的方法,是数据挖掘、机器学习和模式识别中一个重要的研究领域。
-
分类的主要用途和场景是“预测”,基于已有的样本预测新样本的所属类别,例如信用评级、风险等级、欺诈预测等。 分类算法也可以用于知识抽取,通过模型找到潜在的规律,帮助业务得到可执行的规则。
1.3 地位
- 分类和回归是解决实际运营问题中非常重要的两种分析和挖掘方法。
1.4 分类
- 常用的分类算法包括朴素贝叶斯、逻辑回归、决策树、随机森林、支持向量机等。
2. 应用
2.1 简介
案例 电信客户流失预测
- AT&T数据,用户个人,通话,上网等信息数据
- 充分利用数据预测客户的流失情况
- 帮助挽留用户,保证用户基数和活跃程度
2.2 数据说明
- CustomerID 客户ID
- Gender 性别
- partneratt 配偶是否也为att用户
- dependents_att 家人是否也是att用户
- landline 是否使用att固话服务
- internet_att/internet_other 是否使用att的互联网服务
- Paymentbank/creditcard/electroinc 付款方式
- MonthlyCharges 每月话费
- TotalCharges 累计话费
- Contract_month/1year 用户使用月度/年度合约
- StreamingTv/streamingMovies 是否使用在线视频或者电影app
- Churn 客户转化的flag
2.3 处理流程
- 分析流程:数据概况分析->单变量分析->相关性分析与可视化->回归模型
- 数据概况分析
- 数据行/列数量
- 缺失值分布
- 单变量分析
- 数字型变量的描述指标(平均值,最大最小值,标准差)
- 类别型变量(多少个分类,各自占比)
- 正负样本占比
- 相关性分析与可视化
- 按类别交叉对比
- 变量之间的相关性分析
- 散点图/热力图
- 逻辑回归分析
- 模型建立
- 模型评估与优化
2.4 实现
步骤
1 加载数据,查看churn.info()
2 对churn列和gender列进行onehot编码
3 churn的onehot编码中churn_yes作为标签列,churn_no丢弃
gender_yes gender_no都保留
**4 churn.flag.value_counts() churn.flag.value_counts(1)查看正负样本分布** 正负样本是人为定义的,关注哪个类别则定义该类别为正样本
5 按照flag分组,计算平均值,查看相关特征
6 围绕flag变量,分析其他变量与flag的相关关系
7 选择相关性比较高的作为特征
8 构建模型,训练评估
9 如果评估结果不理想,则重新选择特征重新训练
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
churn=pd.read_csv('churn.csv')
churn.info()
RangeIndex: 7043 entries, 0 to 7042
Data columns (total 16 columns):
Churn 7043 non-null object
gender 7043 non-null object
Partner_att 7043 non-null int64
Dependents_att 7043 non-null int64
landline 7043 non-null int64
internet_att 7043 non-null int64
internet_other 7043 non-null int64
StreamingTV 7043 non-null int64
StreamingMovies 7043 non-null int64
Contract_Month 7043 non-null int64
Contract_1YR 7043 non-null int64
PaymentBank 7043 non-null int64
PaymentCreditcard 7043 non-null int64
PaymentElectronic 7043 non-null int64
MonthlyCharges 7043 non-null float64
TotalCharges 7043 non-null float64
dtypes: float64(2), int64(12), object(2)
memory usage: 880.5+ KB
#预测目标是churn,是类别型变量 gender也是类别型变量 需要对类别型变量进行处理
churn.head()
Churn gender Partner_att Dependents_att landline internet_att
0 No Female 1 0 0 1
1 No Male 0 0 1 1
2 Yes Male 0 0 1 1
3 No Male 0 0 0 1
4 Yes Female 0 0 1 0
internet_other StreamingTV StreamingMovies Contract_Month Contract_1YR
0 0 0 0 1 0
1 0 0 0 0 1
2 0 0 0 1 0
3 0 0 0 0 1
4 1 0 0 1 0
PaymentBank PaymentCreditcard PaymentElectronic MonthlyCharges
0 0 0 1 29.85
1 0 0 0 56.95
2 0 0 0 53.85
3 1 0 0 42.30
4 0 0 1 70.70
TotalCharges
0 29.85
1 1889.50
2 108.15
3 1840.75
4 151.65
#需要把churn和gender转变为数字型变量,使用get_dummies
churn=pd.get_dummies(churn)
churn.head()
Churn_No Churn_Yes gender_Female gender_Male
0 1 0 1 0
1 1 0 0 1
2 0 1 0 1
3 1 0 0 1
4 0 1 1 0
#数据整理,将churn_yes保留,将female保留,drop不需要的数据
churn.drop(['Churn_No','gender_Male'],axis=1,inplace=True)
#变量大小写不规则,统一变成小写
churn.columns=churn.columns.str.lower()
churn.head()
churn_yes gender_female
0 0 1
1 0 0
2 1 0
3 0 0
4 1 1
#将churn_yes重命名,方便后续的变量编写
churn=churn.rename(columns={'churn_yes':'flag'})
#二分类模型,分析flag 1和0的占比
churn.flag.value_counts()
0 5174
1 1869
Name: flag, dtype: int64
churn.flag.value_counts(1)
0 0.73463
1 0.26537
Name: flag, dtype: float64
summary=churn.groupby('flag')
summary.mean()
partner_att dependents_att landline internet_att internet_other
flag
0 0.528218 0.344801 0.901044 0.379204 0.347700
1 0.357945 0.174425 0.909042 0.245586 0.693954
streamingtv streamingmovies contract_month contract_1yr paymentbank
flag
0 0.365868 0.369927 0.429068 0.252609 0.248550
1 0.435527 0.437667 0.885500 0.088818 0.138042
paymentcreditcard paymentelectronic monthlycharges totalcharges
flag
0 0.249324 0.250097 61.265124 2545.918081
1 0.124131 0.573034 74.441332 1528.514714
gender_female
flag
0 0.492656
1 0.502408
- 观察flag在0和1的情况下,所有自变量的差别 internet_other变量,在0的分组中,均值是0.35,在1的分组中,均值是0.69。数据显示如果使用别的公司的互联网,用户流失的概率就越高
sns.countplot(y='contract_month',hue='flag',data=churn)
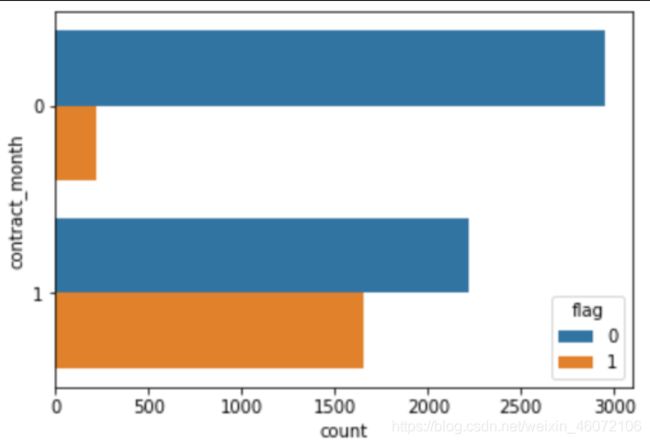
- 结论:contract_month为1的客户流失的概率更高,即与非按月付费客户相比,按月付费客户流失比例高
- 相关性分析
#围绕flag变量,分析其他变量与flag的相关关系
churn.corr()[['flag']].sort_values('flag',ascending=False)
flag
flag 1.000000
contract_month 0.405103
internet_other 0.308020
paymentelectronic 0.301919
monthlycharges 0.193356
streamingtv 0.063228
streamingmovies 0.061382
landline 0.011942
gender_female 0.008612
paymentbank -0.117937
internet_att -0.124214
paymentcreditcard -0.134302
partner_att -0.150448
dependents_att -0.164221
contract_1yr -0.177820
totalcharges -0.198175
# contract_month与internet_other与flag相关性高
- 逻辑回归模型
#设定因变量与自变量, y 是 flag, x 根据刚才的相关分析挑选contract_month,internet_other与streamingtv
#自变量可以分为几类,partner/dependents,internet,streaming,contract,payment,charges,后续大家可以自己挑选进行建模
y=churn['flag']
x=churn[['contract_month','internet_other','streamingtv']]
#模型优化,streamingtv调整为paymentelectronic
y=churn['flag']
x=churn[['contract_month','internet_other','paymentelectronic']]
#调用sklearn模块,随机抽取训练集与测试集
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3,random_state=100)
#模型优化,测试集与训练集对半分,第三次也跑这里
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.5,random_state=100)
#使用sklearn
from sklearn import linear_model
lr=linear_model.LogisticRegression()
lr.fit(x_train,y_train)
"""
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
penalty='l2', random_state=None, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False)
"""
- 模型的截距与系数
#第一次
lr.intercept_
lr.coef_
#array([-3.21761938])
#array([[2.19790192, 1.14360005, 0.23641705]])
#第二次,测试集与训练集对半分
lr.intercept_
array([-3.26144359])
array([[2.23886897, 1.09248895, 0.32579547]])
#第三次,变量调整
array([-3.18770265])
array([[2.0019671 , 1.02830763, 0.62165925]])
- 模型的评估
y_pred_train=lr.predict(x_train)
y_pred_test=lr.predict(x_test)
import sklearn.metrics as metrics
metrics.accuracy_score(y_train,y_pred_train)
from sklearn.metrics import roc_curve,auc
fpr,tpr,threshold=roc_curve(y_train,y_pred_train)
roc_auc=auc(fpr,tpr)
-
用分类分析来提炼规则、提取变量、处理缺失值
-
分类分析用于提炼应用规则 预测是分类分析的主要应用方向,但将分类用于提炼应用规则,为数据化运营提供规则支持也是其重点应用之一,这种应用相对于其他算法更加具有落地价值。常见的应用场景如下:
- 要针对沉默会员做会员重新激活,应该挑选具有什么特征的会员?
- 商品A库存积压严重,现在要通过促销活动清仓,选择哪些类型的促销活动更容易实现该目标?
- 网站需要大流量广告位来满足VIP商家的精准广告投放,具有哪些特征的广告位更符合VIP商家的客户需求?
-
-
从分类算法中提炼特征规则,利用的是在构建算法过程中的分类规则
- 以决策树为例,决策树的分裂节点是表示局部最优值的显著特征值,每个节点下的特征变量以及对应的值的组合构成了规则。
-
分类分析用于提取变量特征
- 具体实现思路是:获取原始数据集并对数据做预处理,将预处理的数据集放到分类算法中进行训练,然后从算法模型中提取特征权重信息。
- 分类分析用于处理缺失值
3. 聚类和分类算法的区别
- 学习方式不同聚类是一种非监督式学习算法,而分类是监督式学习算法。
- 对源数据集要求不同,有无目标值
- 应用场景不同
- 聚类一般应用于数据探索性分析、数据降维、数据压缩等探索性、过程性分析和处理
- 分类更多地用于预测性分析和使用。
- 解读结果不同。聚类算法的结果是将不同的数据集按照各自的典型特征分成不同类别,不同人对聚类的结果解读可能不同;而分类的结果却是一个固定值(例如高、中、低、是、否等),不存在不同解读的情况。
- 模型评估指标不同
- 聚类分析没有所谓的“准确”与否,以及多么准确的相关度量,更多的是基于距离的度量。如果是对带有标签的数据集做聚类则可以做相似度、完整度等方面的评估
- 而分类模型的指标例如准确率、混淆矩阵、提升率等都有明显的好与坏、提升程度等评估指标。例如准确率、混淆矩阵、提升率等都有明显的好与坏、提升程度等评估指标。
- 假如原始数据集带有类别标签,那么选择分类或聚类算法都可以(标签列数据并不是一定要使用)。假如原始数据集不带有类别标签,那么只能选择使用聚类算法。
- 有关分类和聚类的应用示例
- 假如现在公司要对某新会员做促销活动,例如推荐商品、提供个性化信息、推荐最感兴趣的热榜等,并尽量提供该用户感兴趣的内容。
- 分类:基于现有的会员及其特定类别标签(可选择有代表性或与实际运营场景最相关的类别标签)做分类模型训练,将该新用户的数据作为新的样本输入模型,预测得到该用户所属的目标类别。接着计算该类别下用户最经常购买的商品、经常浏览的信息等,并给出推荐内容。
- 聚类:将新的会员和现有的会员作为一个整体做聚类分析,然后获得该会员所属的聚类类别,进而提取其所在类别下其他会员的经常购买商品、经常浏览信息等,并给出推荐内容。
4. 分类分析算法选择
- 文本分类:朴素贝叶斯,例如电子邮件中垃圾邮件的识别。
- 训练集较小,选择高偏差且低方差的分类算法:朴素贝叶斯、支持向量机(不容易过拟合)
- 算法模型的计算时间短和模型易用性,不要选支持向量机、人工神经网络
- 重视算法的准确率:支持向量机或GBDT、XGBoost等基于Boosting的集成方法
- 注重效果的稳定性或模型鲁棒性,那么应选择随机森林、组合投票模型等基于Bagging的集成方法。
- 想得到有关预测结果的概率信息,基于预测概率做进一步的应用:逻辑回归
- 担心离群点或数据不可分并且需要清晰的决策规则:决策树
5. 分类评估
- 准确率:(对不对)
- (TP+TN)/(TP+TN+FN+FP)
- 精确率 – 查的准不准
- TP/(TP+FP)
- 召回率 – 查的全不全
- TP/(TP+FN)
- F1-score
- 反映模型的稳健性
- 不同的场景关注的指标不一样
5…1 混淆矩阵
在分类任务下,预测结果(Predicted Condition)与正确标记(True Condition)之间存在四种不同的组合,构成混淆矩阵(适用于多分类)
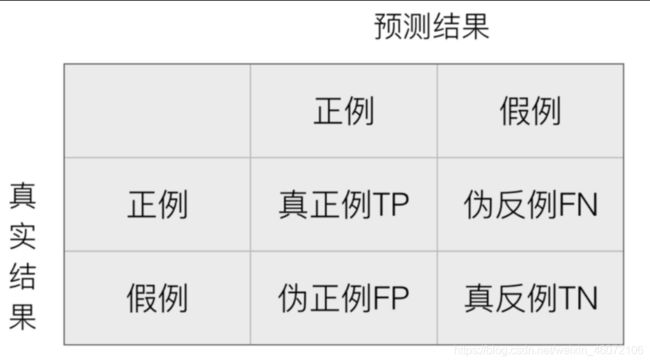
TP True positive
FN False nagative
FP False positive
TN True negative
5.2. 精确率/查准率
- 精确率(Precision):预测结果为正例样本中真实为正例的比例
- TP/(TP+FP)

5.3. 召回率/查全率
- 召回率(Recall):真实为正例的样本中预测结果为正例的比例(查得全,对正样本的区分能力)
- TP/(TP+FN)

5.4. F1-score
反映了模型的稳健性
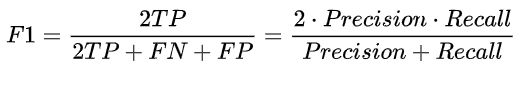
5.5 ROC曲线与AUC指标
1. TPR与FPR
- 真阳性率
- 所有真实类别为1的样本中,预测类别为1的比例
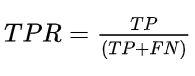
- 假阳性率
- 所有真实类别为0的样本中,预测类别为1的比例

2. ROC曲线
多次调整阈值得到若干组TPR FPR的值,把这些值在同一个坐标系中表示出来,就得到了ROC曲线
最极端,FPR=0,TPR=1,
FPR=0时,即FP=0;TPR=1时,即FN=0,就是所有预测错了的样本都为0,也就是所有的样本预测结果都是正确的
此时对应的曲线下面积是1,如果roc曲线和对角线重合,则面积是0.5,此时模型的预测结果和瞎猜是一样的
AUC指标,area under curve
AUC=1,完美分类器
0.5 from sklearn.metrics import roc_auc_score 样本不均衡下的评估问题: 假设这样一个情况,如果99个样本癌症,1个样本非癌症,不管怎样全都预测正例(默认癌症为正例),准确率就为99%但是这样效果并不好
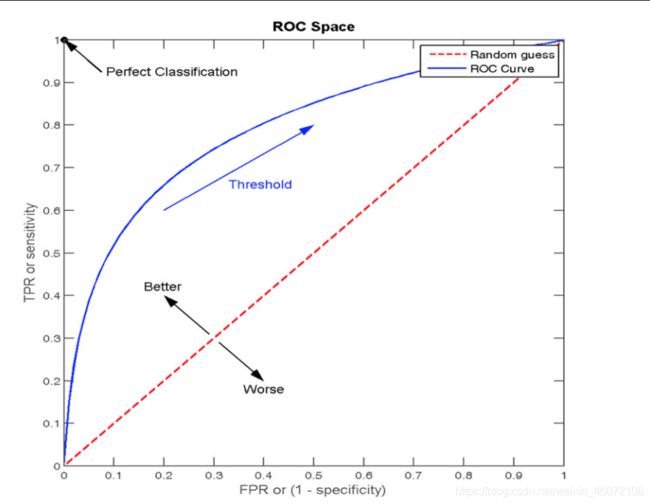
3. AUC指标
4. API
from sklearn.metrics import roc_auc_score
sklearn.metrics.roc_auc_score(y_true, y_score)
# 0.5~1之间,越接近于1约好
y_test = np.where(y_test > 2.5, 1, 0)
print("AUC指标:", roc_auc_score(y_test, y_predict)
6. 分类评估报告api
# y_true:真实目标值
# y_pred:估计器预测目标值
# labels:指定类别对应的数字
# target_names:目标类别名称
# return:每个类别精确率与召回率
sklearn.metrics.classification_report(y_true, y_pred, labels=[], target_names=None )
ret = classification_report(y_test, y_predict, labels=(2,4), target_names=("良性", "恶性"))
print(ret)