TensorFlow深度学习!构建神经网络预测股票!

作者:韩信子@ShowMeAI
深度学习实战系列:https://www.showmeai.tech/tutorials/42
TensorFlow 实战系列:https://www.showmeai.tech/tutorials/43
本文地址:https://www.showmeai.tech/article-detail/327
声明:版权所有,转载请联系平台与作者并注明出处
收藏ShowMeAI查看更多精彩内容
股票价格数据是一个时间序列形态的数据,诚然,股市的涨落和各种利好利空消息更相关,更多体现的是人们的信心状况,但是它的形态下,时序前后是有一定的相关性的,我们可以使用一种特殊类型的神经网络『循环神经网络 (RNN)』来对这种时序相关的数据进行建模和学习。

在本篇内容中,ShowMeAI将给大家演示,如何构建训练神经网络并将其应用在股票数据上进行预测。

对于循环神经网络的详细信息讲解,大家可以阅读ShowMeAI整理的系列教程和文章详细了解:
- 深度学习教程:吴恩达专项课程 · 全套笔记解读
- 深度学习教程 | 序列模型与RNN网络
- 自然语言处理教程:斯坦福CS224n课程 · 课程带学与全套笔记解读
- NLP教程(5) - 语言模型、RNN、GRU与LSTM
数据获取
在实际建模与训练之前,我们需要先获取股票数据。下面的代码使用 Ameritrade API 获取并生成数据,也可以使用其他来源。
import matplotlib.pyplot as plt
import mplfinance as mpl
import pandas as pd
td_consumer_key = 'YOUR-KEY-HERE'
# 美国航空股票
ticker = 'AAL'
##periodType - day, month, year, ytd
##period - number of periods to show
##frequencyTYpe - type of frequency for each candle - day, month, year, ytd
##frequency - the number of the frequency type in each candle - minute, daily, weekly
endpoint = 'https://api.tdameritrade.com/v1/marketdata/{stock_ticker}/pricehistory?periodType={periodType}&period={period}&frequencyType={frequencyType}&frequency={frequency}'
# 获取数据
full_url = endpoint.format(stock_ticker=ticker,periodType='year',period=10,frequencyType='daily',frequency=1)
page = requests.get(url=full_url,params={'apikey' : td_consumer_key})
content = json.loads(page.content)
# 转成pandas可处理格式
df = pd.json_normalize(content['candles'])
# 设置时间戳为索引
df['timestamp'] = pd.to_datetime(df.datetime, unit='ms')
df = df.set_index("timestamp")
# 绘制数据
plt.figure(figsize=(15, 6), dpi=80)
plt.plot(df['close'])
plt.legend(['Closing Price'])
plt.show()
# 存储前一天的数据
df["previous_close"] = df["close"].shift(1)
df = df.dropna() # 删除缺失值
# 存储
df.to_csv('../data/stock_'+ticker+'.csv', mode='w', index=True, header=True)
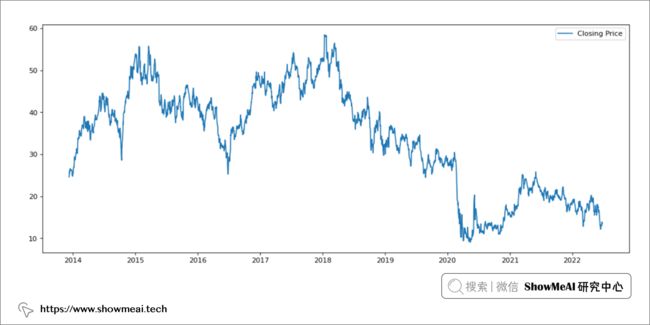
上面的代码查询 Ameritrade API 并返回 10 年的股价数据,例子中的股票为『美国航空公司』。 数据绘图结果如下所示:
数据处理
我们加载刚才下载的数据文件,并开始处理预测。
# 读取数据
ticker = 'AAL'
df = pd.read_csv("../data/stock_"+ticker+".csv")
# 设置索引
df['DateIndex'] = pd.to_datetime(df['timestamp'], format="%Y/%m/%d")
df = df.set_index('DateIndex')
下面我们对数据进幅度缩放,以便更好地送入神经网络和训练。(神经网络是一种对于输入数据幅度敏感的模型,不同字段较大的幅度差异,会影响网络的训练收敛速度和精度。)
# 幅度缩放
df2 = df
cols = ['close', 'volume', 'previous_close']
features = df2[cols]
scaler = MinMaxScaler(feature_range=(0, 1)).fit(features.values)
features = scaler.transform(features.values)
df2[cols] = features
在这里,我们重点处理了收盘价、成交量和前几天收盘价列。
数据切分
接下来我们将数据拆分为训练和测试数据集。
# 收盘价设为目标字段
X = df2.drop(['close','timestamp'], axis =1)
y = df2['close']
import math
# 计算切分点(以80%的训练数据为例)
train_percentage = 0.8
split_point = math.floor(len(X) * train_percentage)
# 时序切分
train_x, train_y = X[:split_point], y[:split_point]
test_x, test_y = X[split_point:], y[split_point:]
接下来,我们对数据进行处理,构建滑窗数据,沿时间序列创建数据样本。(因为我们需要基于历史信息对未来的数值进行预测)
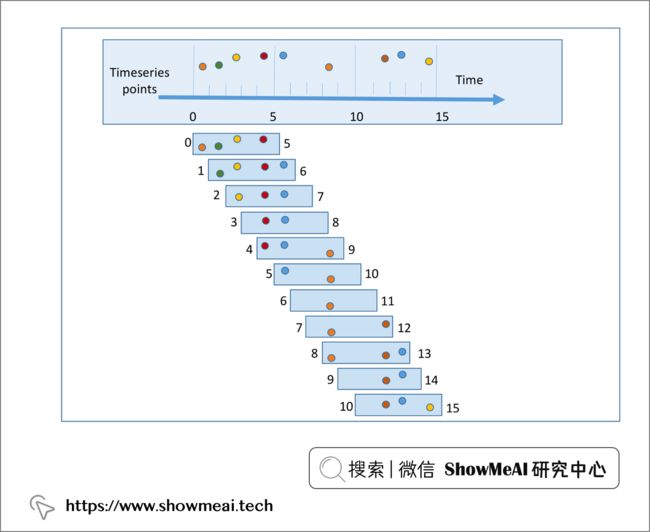
# 构建滑窗数据
import numpy.lib
from numpy.lib.stride_tricks import sliding_window_view
def genWindows(X_in, y_in, window_size):
X_out = []
y_out = []
length = X_in.shape[0]
for i in range(window_size, length):
X_out.append(X_in[i-window_size:i, 0:4])
y_out.append(y_in[i-1])
return np.array(X_out), np.array(y_out)
# 窗口大小为5
window_size = 5
X_train_win, y_train_win = genWindows(np.array(train_x), np.array(train_y), window_size)
X_test_win, y_test_win = genWindows(np.array(test_x), np.array(test_y), window_size)
模型构建&训练
构建完数据之后,我们就要构建 RNN 模型了,具体的代码如下所示。注意到下面使用了1个回调函数,模型会在验证集性能没有改善的情况下提前停止训练,防止模型过拟合影响泛化能力。
from tensorflow.keras import callbacks
# 早停止 回调函数
callback_early_stopping = callbacks.EarlyStopping(
monitor="loss",
patience=10,#look at last 10 epochs
min_delta=0.0001,#loss must improve by this amount
restore_best_weights=True,
)
from tensorflow import keras
from tensorflow.keras import layers
from keras.models import Sequential
# 构建RNN模型,结构为 输入-RNN-RNN-连续值输出
input_shape=(X_train_win.shape[1],X_train_win.shape[2])
print(input_shape)
model = Sequential(
[
layers.Input(shape=input_shape),
layers.SimpleRNN(units=128, return_sequences=True),
layers.SimpleRNN(64, return_sequences=False),
layers.Dense(1, activation="linear"),
]
)
# 优化器
optimizer = keras.optimizers.Nadam(learning_rate=0.0001)
model.compile(optimizer=optimizer, loss="mse")
# 模型结构总结
model.summary()
# 模型训练
batch_size = 20
epochs = 50
history = model.fit(X_train_win, y_train_win,
batch_size=batch_size, epochs=epochs,
callbacks=[
callback_early_stopping
])
模型训练过程的损失函数(训练集上)的变化如下图所示。随着训练过程推进,模型损失不断优化,初期的优化和loss减小速度很快,后逐渐趋于平稳。
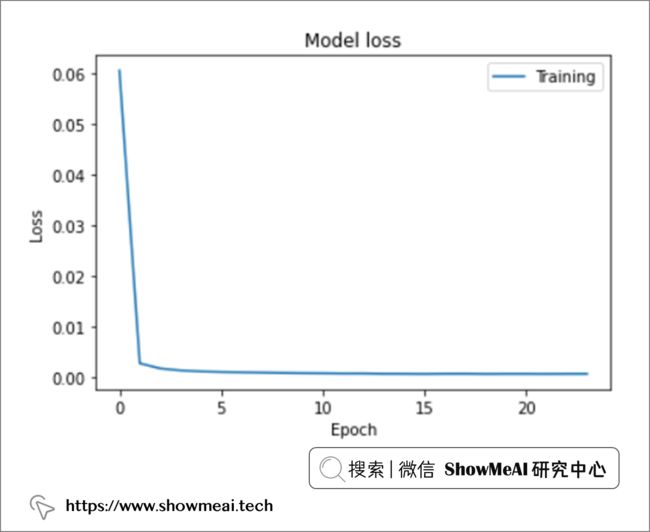
大约 10 个 epoch 后达到了最佳结果,训练好的模型就可以用于后续预测了,我们可以先对训练集进行预测,验证一下在训练集上学习的效果。
# 训练集预测
pred_train_y = model.predict(X_train_win)
# 绘图
plt.figure(figsize=(15, 6), dpi=80)
plt.plot(np.array(train_y))
plt.plot(pred_train_y)
plt.legend(['Actual', 'Predictions'])
plt.show()
模型在训练集上学习的效果还不错,大家可以看到预测结果和真实值对比绘图如下:
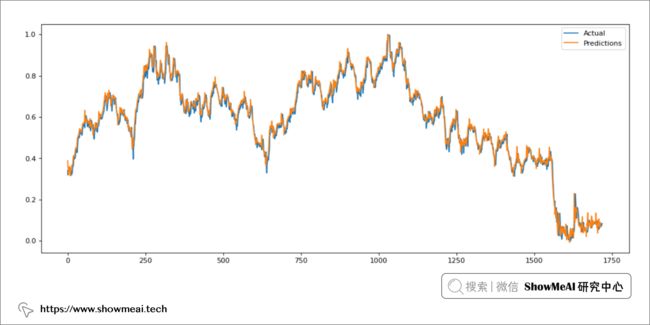
模型预测&应用
我们要评估模型的真实表现,需要在它没有见过的测试数据上评估,大家记得我们在数据切分的时候预留了 20% 的数据,下面我们用模型在这部分数据上预测并评估。
# 测试集预测
pred_test_y = model.predict(X_test_win)
# 预测结果绘制
plt.figure(figsize=(15, 6), dpi=80)
plt.plot(np.array(test_y))
plt.plot(pred_test_y)
plt.legend(['Actual', 'Predictions'])
plt.show()
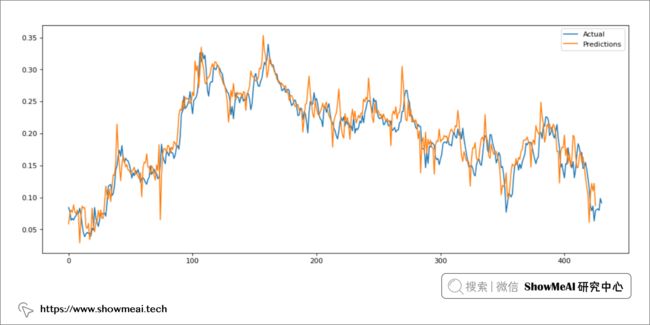
相对训练集来说,大家看到测试集上的效果稍有偏差,但是总体趋势还是预测得不错。
我们要考察这个模型对于时间序列预测的泛化能力,可以进行更严格一点的建模预测,比如将训练得到的模型应用与另一支完全没见过的股票上进行预测。如下为我们训练得到的模型对 Microsoft/微软股票价格的预测:
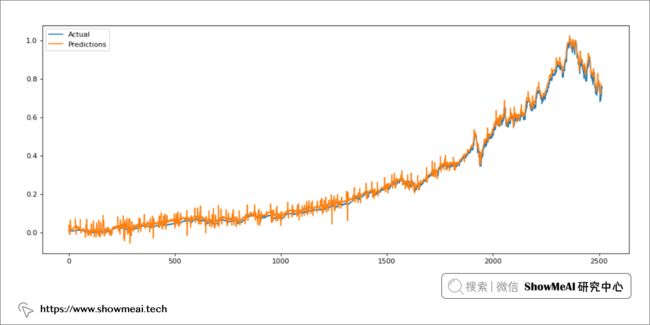
我们从图上可以看到,模型表现良好(预测存在一定程度的噪音,但它对总体趋势的预测比较准确)。
参考资料
- 深度学习教程:吴恩达专项课程 · 全套笔记解读:https://www.showmeai.tech/tutorials/35
- 自然语言处理教程:斯坦福CS224n课程 · 课程带学与全套笔记解读:https://www.showmeai.tech/tutorials/36
- 深度学习教程 | 序列模型与RNN网络:https://www.showmeai.tech/article-detail/225
- NLP教程(5) - 语言模型、RNN、GRU与LSTM:https://www.showmeai.tech/article-detail/239
