【集成学习系列教程3】GBDT分类算法原理及sklearn应用
文章目录
-
- 5 GBDT二分类算法
-
- 5.1 概述
- 5.2 算法详解
-
- 5.2.1 逻辑回归预测函数
- 5.2.2 最大似然估计
- 5.2.3 逻辑回归损失函数
- 5.2.4 算法的具体步骤
- 5.3 sklearn中的GradientBoosting分类算法
-
- 5.3.1 原型
- 5.3.2 常用参数
- 5.3.3 常用属性
- 5.3.4 常用方法
- 5.4 实例4:GBDT二分类问题的调参与优化
-
- 5.4.1 数据集的创建与可视化
- 5.4.2 训练集和测试集的分割
- 5.4.3 调参的思路
- 5.4.4 不同参数取值下模型在测试集上的逻辑回归损失曲线的绘制
- 5.4.5 网格搜索
- 5.4.6 绘制最佳分类器的训练准确率和验证准确率曲线
- 5.6.7 损失函数的选择对模型预测结果的影响
5 GBDT二分类算法
5.1 概述
前面我们介绍了AdaBoost的基本原理,并举了几个实例对AdaBoost的使用做了一些演示。简单来说,AdaBoost的大体思想就是:根据每个弱学习器的预测误差为每个弱学习器赋予不同的权重,并以上一个弱学习器的权重为依据更新数据集样本分布的权重(尤其是不断加大上一轮弱学习器预测错误的样本的权重),通过不断循环这一过程,最终得到一个在所有样本上均有较高预测准确率的强学习器,实现了串行提升整体拟合效果的目的。而Boosting系列算法中还有另一个非常具有代表性的算法,叫做GBDT(Gradient Boosting Decision Tree,梯度提升树)。下面就让我们来看一下GBDT算法的基本原理。先从二分类开始。
5.2 算法详解
在介绍GBDT二分类算法之前,首先要先对下面的几个数学知识做了解,才能够更好地理解整个算法的流程。
5.2.1 逻辑回归预测函数
在逻辑回归预测函数,先提出如下问题:这个函数有什么作用呢?我们为什么要用到这个函数?带着问题,我们开始下面的介绍。
先假设经过一定迭代次数的训练之后得到的GBDT分类器的表达式为 F ( x ) F(\boldsymbol x) F(x)。
逻辑回归预测函数的表达式为:
h θ ( x ) = 1 1 + e − θ T x h_\theta(\boldsymbol x)=\frac{1}{1+e^{-\theta^\mathsf T\boldsymbol x}} hθ(x)=1+e−θTx1
其中, θ \theta θ为 F ( x ) F(x) F(x)学习到的参数, θ T x \theta^\mathtt T\boldsymbol x θTx为 F ( x ) F(x) F(x)对样本 x \boldsymbol x x的预测结果。通过上式就可以将 F ( x ) F(\boldsymbol x) F(x)对样本 x \boldsymbol x x的预测结果转化成逻辑回归值的形式。为什么要转化成这种形式呢?这是因为 h θ ( x ) h_\theta(x) hθ(x)实际上就是 F ( x ) F(\boldsymbol x) F(x)预测出样本 x \boldsymbol x x属于类别1的概率,通过这个值的大小就可以衡量 F ( x ) F(\boldsymbol x) F(x)对类别为1的样本分类效果的好坏。这样就可以得到如下的公式:
P ( Y = 1 ∣ x ; θ ) = h θ ( x ) P(Y=1|\boldsymbol x;\theta)=h_\theta(\boldsymbol x) P(Y=1∣x;θ)=hθ(x)
其中 P ( Y = 1 ∣ x ; θ ) P(Y=1|\boldsymbol x;\theta) P(Y=1∣x;θ)表示在给定当前分类器 F ( x ) F(x) F(x)的参数$\theta 的前提下样本 的前提下样本 的前提下样本\boldsymbol x 属于类别 1 的概率,也就是数据集中类别为 1 的样本所占的比例。由此可以得到样本 属于类别1的概率,也就是数据集中类别为1的样本所占的比例。由此可以得到样本 属于类别1的概率,也就是数据集中类别为1的样本所占的比例。由此可以得到样本\boldsymbol x$属于类别0的概率为:
P ( Y = 0 ∣ x ; θ ) = 1 − h θ ( x ) P(Y=0|\boldsymbol x;\theta)=1-h_\theta(\boldsymbol x) P(Y=0∣x;θ)=1−hθ(x)
将上面两个的式子结合起来,可得到如下公式:
P ( Y = y ∣ x ; θ ) = ( h θ ( x ) ) y ( 1 − h θ ( x ) ) 1 − y P(Y=y|\boldsymbol x;\theta)=\bold(h_\theta(\boldsymbol x) \bold)^y\bold(1-h_\theta(\boldsymbol x) \bold)^{1-y} P(Y=y∣x;θ)=(hθ(x))y(1−hθ(x))1−y
其中, y ∈ { 0 , 1 } y\in\{0,1\} y∈{0,1} , P ( Y = y ∣ x ; θ ) ,P(Y=y|\boldsymbol x;\theta) ,P(Y=y∣x;θ)表示 F ( x ) F(\boldsymbol x) F(x)将样本 x \boldsymbol x x预测正确的概率。我们可以用上面这个公式表示将样本的类别为0和样本的类别为1这两种情况给结合起来。也就是说,若样本 x \boldsymbol x x的类别标签为0,则上式就表示预测出 x \boldsymbol x x属于类别0的概率;若样本 x \boldsymbol x x的类别为1,则上式就表示预测出 x \boldsymbol x x属于类别1的概率。
5.2.2 最大似然估计
判断分类器 F ( x ) F(\boldsymbol x) F(x)够不够好的指标之一,就是看它能不能尽可能将所有的样本都分对,也就是说,它能够尽量将所有真实标签为1的样本预测为1,尽量将所有真实标签为0的样本预测为0。从概率的角度来说,就是使得所有真实标签为1的样本被预测为1的概率的乘积尽可能大,同时也使得所有真实标签为0的样本被预测为0的概率的乘积也尽可能大。结合上面的公式,我们可以推断出 F ( x ) F(\boldsymbol x) F(x)的优化目标就是找到合适的参数 θ \theta θ,使得下面的函数最大化:
l ( θ ) = ∏ i = 1 N P ( Y = y i ∣ x i ; θ ) = ∏ i = 1 N ( h θ ( x ) ) i y ( 1 − h θ ( x ) ) 1 − y i l(\theta)=\prod_{i=1}^NP(Y=y_i|\boldsymbol x_i;\theta)=\prod_{i=1}^N\bold(h_\theta(\boldsymbol x) \bold)^y_i\bold(1-h_\theta(\boldsymbol x) \bold)^{1-y_i} l(θ)=i=1∏NP(Y=yi∣xi;θ)=i=1∏N(hθ(x))iy(1−hθ(x))1−yi
其中 N N N表示数据集中总的样本数。我们把这个函数的求解过程称为最大似然估计,这个值越大,就表示 F ( x ) F(\boldsymbol x) F(x)对数据集总体的分类效果越好。由于这个函数的表达式为指数形式,不好求解,所以将其转化为对数的形式:
l ( θ ) = ∑ i = 1 N [ y i l o g h θ ( x i ) + ( 1 − y i ) l o g ( 1 − h θ ( x i ) ) ] l(\theta)=\sum_{i=1}^N\bold[y_ilog\,h_\theta(\boldsymbol x_i) +(1-y_i)log\,\bold(1-h_\theta(\boldsymbol x_i) \bold)^{}\bold] l(θ)=i=1∑N[yiloghθ(xi)+(1−yi)log(1−hθ(xi))]
分类器 F ( x ) F(\boldsymbol x) F(x)的任务就是找到一组合适的参数 θ \theta θ,使得 l ( θ ) l(\theta) l(θ)能最大化。
5.2.3 逻辑回归损失函数
求解 l ( θ ) l(\theta) l(θ)函数的过程用的是梯度下降法。利用梯度下降法可求得上式的损失函数为:
J ( θ ) = − 1 N ∑ i = 1 N [ y i l o g h θ ( x i ) + ( 1 − y i ) l o g ( 1 − h θ ( x i ) ) ] J(\theta)=-\frac{1}{N}\sum_{i=1}^N[y_ilog\,h_\theta(\boldsymbol x_i) +(1-y_i)log\,\bold(1-h_\theta(\boldsymbol x_i) \bold)^{}\bold] J(θ)=−N1i=1∑N[yiloghθ(xi)+(1−yi)log(1−hθ(xi))]
由此可得到对于数据集中的单个样本 x i \boldsymbol x_i xi的损失函数为:
L ( θ ) = − y i l o g h θ ( x i ) − ( 1 − y i ) l o g ( 1 − h θ ( x i ) ) L(\theta)=-y_ilog\,h_\theta(\boldsymbol x_i) -(1-y_i)log\,\bold(1-h_\theta(\boldsymbol x_i) \bold) L(θ)=−yiloghθ(xi)−(1−yi)log(1−hθ(xi))
其中 h θ ( x i ) h_\theta(\boldsymbol x_i) hθ(xi)表示分类器 F ( x ) F(\boldsymbol x) F(x)对样本 x i \boldsymbol x_i xi的逻辑回归预测结果,表达式为:
h θ ( x i ) = 1 1 + e − θ T x i h_\theta(\boldsymbol x_i)=\frac{1}{1+e^{-\theta^\mathsf T\boldsymbol x_i}} hθ(xi)=1+e−θTxi1
令 F ( x i ) = θ T x i F(\boldsymbol x_i)=\theta^ T\boldsymbol x_i F(xi)=θTxi,表示分类器 F ( x ) F(\boldsymbol x) F(x)对样本 x i \boldsymbol x_i xi的预测结果,则可以得到:
L ( y i , F ( x i ) ) = y i l o g ( 1 + e − F ( x i ) ) + ( 1 − y i ) [ l o g ( 1 + e − F ( x i ) ) + F ( x i ) ] L(y_i, F(\boldsymbol x_i))=y_ilog\bold({1+e^{-F(\boldsymbol x_i)}\bold)}+(1-y_i)\bold [log\,\bold({1+e^{-F(\boldsymbol x_i)}\bold)}+F(\boldsymbol x_i) \bold] L(yi,F(xi))=yilog(1+e−F(xi))+(1−yi)[log(1+e−F(xi))+F(xi)]
假设在 F ( x ) F(\boldsymbol x) F(x)之前经过了 m m m轮( m m m棵树)的提升,则可以求出第 m m m棵树对第 i i i个样本的损失函数的负梯度为:
r m , i = − ∣ ∂ L ( y i , F m − 1 ( x i ) ) ∂ F m − 1 ( x i ) ∣ = y i − 1 1 + e − F ( x i ) r_{m,i}=-|\frac{\partial L(y_i, F_{m-1}(\boldsymbol x_i))}{\partial F_{m-1}(\boldsymbol x_i)}|=y_i-\frac{1}{1+e^{-F(\boldsymbol x_i)}} rm,i=−∣∂Fm−1(xi)∂L(yi,Fm−1(xi))∣=yi−1+e−F(xi)1
求解出来的结果称为伪残差,表示样本 x i \boldsymbol x_i xi的真实标签与第 m m m个分类器 F m ( x ) F_m(\boldsymbol x) Fm(x)对其逻辑回归预测结果的差值,通过这个值我们就可以较好地衡量 F m ( x ) F_m(\boldsymbol x) Fm(x)的分类误差,进而对 F m ( x ) F_m(\boldsymbol x) Fm(x)的分类准确率有一个理性的认识。
在了解了上面的几点数学知识后,下面就开始正式介绍GBDT二分类算法的具体步骤。
5.2.4 算法的具体步骤
在介绍算法的具体步骤之前,我们先看一下下面这个示意图,使得对GBDT算法的目标和过程有一个更加直观的认识:

可以看到,GBDT算法的过程实际上就是:在初始化分类器 F 0 ( x ) F_0(\boldsymbol x) F0(x)的基础上,训练出 M M M棵树,并不断地、串行地进行叠加,最后得到一个强学习器 F M ( x ) F_M(\boldsymbol x) FM(x),这个 F M ( x ) F_M(\boldsymbol x) FM(x)经过 M M M棵树的提升之后,会取得比之前的所有分类器都更好的效果。这个示意图对于下一节要讲到的GBDT回归算法也同样适用。接下来我们就来看看这个示意图里的算法具体是怎么实现的。
GBDT二分类算法的具体步骤如下:
-
初始化第一个弱分类器 F 0 ( x ) F_0(\boldsymbol x) F0(x),在这里, F 0 ( x ) F_0(\boldsymbol x) F0(x)是一棵分类回归树,
F 0 ( x ) = l o g P ( Y = 1 ∣ x ) 1 − P ( Y = 1 ∣ x ) F_0(\boldsymbol x)=log\,\frac{P(Y=1 | \boldsymbol x)}{1-P(Y=1 | \boldsymbol x)} F0(x)=log1−P(Y=1∣x)P(Y=1∣x)
由之前的推导可以知道, F 0 ( x ) F_0(\boldsymbol x) F0(x)的初始化值为数据集中类别1的样本出现的概率与类别0的样本出现的概率的比值的对数值。 -
初始化完成后,下面要建立起 M M M棵分类回归树,设每一棵树的编号为 m m m ( m = 1 , 2 , . . . , M ) (m=1,2,...,M) (m=1,2,...,M),求出各棵树对各个样本 x i \boldsymbol x_i xi的伪残差。前面我们已经推导出了第 m m m棵树对第 i i i个样本的伪残差 r m , i r_{m,i} rm,i,这里我们将其实例化,求出第1棵树对第 i i i个样本的伪残差为:
r 1 , i = y 1 − 1 1 + e − F 0 ( x i ) r_{1,i}=y_1-\frac{1}{1+e^{-F_0(\boldsymbol x_i)}} r1,i=y1−1+e−F0(xi)1
这个伪残差实际上就是第 i i i个样本的标签与分类器 F 0 ( x ) F_0(\boldsymbol x) F0(x)对样本 x i \boldsymbol x_i xi的逻辑回归预测值的差值,通过这个差值可以较好地衡量当前分类器的分类误差。 -
根据上面求得的伪残差 r 1 , i r_{1,i} r1,i,就可以用下面的公式计算出第1棵树对其第 j j j个叶子节点的最佳拟合值为:
c 1 , j = ∑ x i ∈ R 1 , j r 1 , i ∑ x i ∈ R 1 , j ( y i − r 1 , i ) ( 1 − y i + r 1 , i ) c_{1,j}=\frac{\sum_{\boldsymbol x_i\in{R_{1,j}}}r_{1,i}}{\sum_{\boldsymbol x_i\in{R_{1,j}}}(y_i-r_{1,i})(1-y_i+r_{1,i})} c1,j=∑xi∈R1,j(yi−r1,i)(1−yi+r1,i)∑xi∈R1,jr1,i
其中 R 1 , j R_{1,j} R1,j表示第1棵树的第 j j j个叶子节点区域。 -
在上面求得的最佳拟合值 c 1 , j c_{1,j} c1,j的基础上,就可以用下面的公式求出初始分类器 F 0 ( x ) F_0(\boldsymbol x) F0(x)经过第1棵树提升后的新的分类器 F 1 ( x ) F_1(\boldsymbol x) F1(x)的表达式:
F 1 ( x ) = F 0 ( x ) + ∑ j = 1 J 1 c 1 , j I ( x ∈ R 1 , j ) F_1(\boldsymbol x)=F_0(\boldsymbol x)+\sum_{j=1}^{J_1}c_{1,j}I(x\in R_{1,j}) F1(x)=F0(x)+j=1∑J1c1,jI(x∈R1,j)
其中:
I ( x ∈ R 1 , j ) = { 1 , 如果样本 x 在第 1 棵树的第 j 个叶子节点里 0 , 如果样本 x 不在第 1 棵树的第 j 个叶子节点里 I(x\in R_{1,j})=\left\{ \begin{aligned}1,\quad 如果样本\boldsymbol x在第1棵树的第j个叶子节点里 \\ 0,\quad 如果样本\boldsymbol x不在第1棵树的第j个叶子节点里 \end{aligned} \right. I(x∈R1,j)={1,如果样本x在第1棵树的第j个叶子节点里0,如果样本x不在第1棵树的第j个叶子节点里
2,3,4步骤的求解过程有点抽象,下面将通过一个简单示意图的形式加深读者对上述步骤的理解。假设第1棵回归决策树要对数据集 X = { x 1 , x 2 , x 3 , x 4 , x 5 } X=\{\boldsymbol x_1,\boldsymbol x_2,\boldsymbol x_3,\boldsymbol x_4,\boldsymbol x_5\} X={x1,x2,x3,x4,x5}进行分类,且这5个样本的标签分别为 y 1 , y 2 , y 3 , y 4 , y 5 = 0 , 0 , 1 , 1 , 1 y_1,y_2,y_3, y_4,y_5=0,0,1,1,1 y1,y2,y3,y4,y5=0,0,1,1,1,分类的效果如下: 图1.5.2: 伪残差的求解
图1.5.2: 伪残差的求解首先,我们分别用步骤3中的公式计算出上图6个叶子节点所对应的伪残差 c 1 , 1 , c 1 , 2 , c 1 , 3 , 1 , 4 , c 1 , 5 , c 1 , 6 c_{1,1},c_{1,2},c_{1,3},_{1,4},c_{1,5},c_{1,6} c1,1,c1,2,c1,3,1,4,c1,5,c1,6,然后用这个6个数对 F 0 ( x ) F_0(\boldsymbol x) F0(x)进行提升,求得经过提升之后的分类器为:
F 1 ( x ) = F 0 ( x ) + c 1 , 1 + c 1 , 2 + c 1 , 3 + c 1 , 4 + c 1 , 5 + c 1 , 6 F_1(\boldsymbol x)=F_0(\boldsymbol x)+c_{1,1}+c_{1,2}+c_{1,3}+c_{1,4}+c_{1,5}+c_{1,6} F1(x)=F0(x)+c1,1+c1,2+c1,3+c1,4+c1,5+c1,6可以看到,从初始化分类器 F 0 ( x ) F_0(\boldsymbol x) F0(x)经过第1棵树提升到 F 1 ( x ) F_1(\boldsymbol x) F1(x)的过程,实际上就是一个先求出第1棵树在其各个叶子节点的最佳拟合值,再将这些最佳拟合值叠加到 F 0 ( x ) F_0(\boldsymbol x) F0(x)上的过程。
F 2 ( x ) , F 3 ( x ) , . . . , F M ( x ) F_2(\boldsymbol x),F_3(\boldsymbol x),...,F_{M}(\boldsymbol x) F2(x),F3(x),...,FM(x)的求解方法也类似。
-
用上面的方法经过 M M M次提升后,得到最终强学习器的表达式如下:
F M ( x ) = F 0 ( x ) + ∑ m = 1 M ∑ j = 1 J m c m , j I ( x ∈ R m , j ) F_{M}(\boldsymbol x)=F_{0}(\boldsymbol x)+\sum_{m=1}^M\sum_{j=1}^{J_m}c_{m,j}I(x\in R_{m,j}) FM(x)=F0(x)+m=1∑Mj=1∑Jmcm,jI(x∈Rm,j)
其中 ∑ m = 1 M \sum_{m=1}^M ∑m=1M表示对所有 M M M棵提升树求累加, ∑ j = 1 J m c m , j \sum_{j=1}^{J_m}c_{m,j} ∑j=1Jmcm,j表示对每棵提升树的所有叶子节点的最佳拟合值求累加。意思就是说,以初始分类器 F 0 ( x ) F_{0}(\boldsymbol x) F0(x)为起点,不断将所有 M M M棵树的所有叶子节点的最佳拟合值加起来,最终就得到了强学习器 F M ( x ) F_{M}(\boldsymbol x) FM(x)。这里需要注意:为了控制每一棵提升树的对分类器的提升程度,会引入一个叫做学习率 η \eta η的参数:
F M ( x ) = F 0 ( x ) + ∑ m = 1 M ∑ j = 1 J m η c m , j I ( x ∈ R m , j ) F_{M}(\boldsymbol x)=F_{0}(\boldsymbol x)+\sum_{m=1}^M\sum_{j=1}^{J_m}\eta\, c_{m,j}I(x\in R_{m,j}) FM(x)=F0(x)+m=1∑Mj=1∑Jmηcm,jI(x∈Rm,j)
学习率 η \eta η对GBDT分类效果的影响至关重要,是实际使用中的重点调参对象。
- 最后再将 F M ( x ) F_{M}(\boldsymbol x) FM(x)的输出结果转换为逻辑回归预测值的形式,也就是 F M ( x ) F_{M}(\boldsymbol x) FM(x)将样本 x \boldsymbol x x预测为类别0的概率:
P ( Y = 1 ∣ x ) = 1 1 + e − F M ( x ) P(Y=1|\boldsymbol x)=\frac{1}{1+e^{-F_{M}(\boldsymbol x)}} P(Y=1∣x)=1+e−FM(x)1
经过上面的六个步骤,就完成了GBDT二分类算法的流程。
5.3 sklearn中的GradientBoosting分类算法
sklearn中的GradientBoostingClassifier类对GradientBoosting分类算法进行了实现。
5.3.1 原型
class sklearn.ensemble.GradientBoostingClassifier(*, loss='deviance', learning_rate=0.1, n_estimators=100, subsample=1.0, criterion='friedman_mse', min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_depth=3, min_impurity_decrease=0.0, min_impurity_split=None, init=None, random_state=None, max_features=None, verbose=0, max_leaf_nodes=None, warm_start=False, presort='deprecated', validation_fraction=0.1, n_iter_no_change=None, tol=0.0001, ccp_alpha=0.0)
GradientBoostingClassifier类的参数多达22个,比AdaBoost多了很多。下面我们挑出其中一些常用的参数做介绍。
5.3.2 常用参数
-
loss: 默认为’deviance’
表示训练过程中所使用的损失函数,可用选项为{‘deviance’, ‘exponential’}:- deviance表示逻辑回归损失函数
- exponential表示指数损失函数
-
learning_rate: 浮点型,默认为0.1表示学习率,对GBDT分类效果的影响较大,是调参的重点对象。
-
n_estimators: 整型,默认值为100
基学习器的最大迭代次数(即最大的基学习器个数)n_estimator太小,基学习器数量太少,容易造成欠拟合;n_estimators太大,基学习器数量太多,容易造成过拟合。在实际使用中,n_estimators的值不宜过大,也不能太小,需要通过调参找到一个合适的取值,所以这个参数也是调参的重点对象。 -
subsample: 浮点型,默认为1.0表示子采样的比例,取值为(0, 1]。注意这里是不放回抽样。默认取值为1.0表示全部样本都用来拟合GBDT的基学习器,等于没有使用子采样方法。如果取值小于1,则表示只有一部分样本会用来拟合GBDT的基学习器。subsample设置为小于1的合适的值可以减少方差,缓解过拟合,但是会增加样本拟合的偏差,因此在实际使用中该参数也是重点调参对象。
实际上,GBDT的参数可分为两类:一类是过程影响类参数,一类是子模型(也就是我们前面一直说的基学习器)影响类参数。上面的四个参数都属于过程影响类参数,我们可以通过改变这些参数,对整个训练过程产生较大的改变,从而在较大幅度上对模型的整体性能产生影响,属于“宏观”上的提升,因此,过程影响类参数是重点的调参对象。而子模型影响类参数就是我们下面要介绍到的参数,它们的作用范围是在单个基学习器上,通过改变这些参数,同样也能对模型的性能产生影响,属于“微观”上的提升。GBDT中比较常用的子模型影响类参数有如下几个:
-
max_depth:整型,默认值为3表示基学习器的最大深度,通过设置该值可以控制基学习器的节点数量,从而对GBDT学习器总体的分类效果产生影响。
-
max_features:整型或浮点型,默认值为None表示基学习器划分时考虑的最大特征数,使用默认值None时,max_features=n_features,即最大特征数等于总特征数。当特征数较多时,可以通过设置该参数来控制划分时考虑的最大特征数,进而控制决策树的生成时间。指定为整数时表示绝对数量,指定为0到1之间的浮点数时表示占总特征数的比例。其他可用的选项有:
- “auto”:max_features=n_features;
- “sqrt”:max_features=sqrt(n_features)
- “log2”:max_features=log2(n_features)
-
min_samples_split:整型或浮点型,默认值为2表示内部节点再划分所需要的最小样本数,通过设置该参数可以限制子树继续划分的条件,如果某节点的样本数少于min_samples_split,则不会继续再尝试选择最优特征来进行划分。指定为整数时表示绝对数量,指定为0到1之间的浮点数时表示占总样本数的比例。
-
min_samples_leaf:整型或浮点型,默认值为None表示基学习器每个叶子节点所需要的最少样本数,如果某叶子节点的样本数小于总样本数,则该节点会和其兄弟节点一起被剪枝。指定为整数时表示绝对数量,指定为0到1之间的浮点数时表示占总样本数的比例。
-
min_weight_fraction_leaf:浮点数,默认值为0.0表示叶子节点最小的样本权重和,这个值限制了叶子节点所有样本权重之和的最小值,如果小于这个值,则该节点会和其兄弟节点一起被剪枝。
-
min_impurity_decrease:浮点数,默认值为None表示节点纯度的阈值,默认值None表示不设置阈值。如果节点的纯度下降幅度大于该阈值,则对该节点进行分裂。
这些参数的使用将会在下一章《决策树》中通过实例进行详细介绍和补充。
5.3.3 常用属性
base_estimator_:返回基学习器(包括种类、详细参数等信息)。feature_importances_:返回数据集中每个特征的权重的组成的列表。train_score_:返回所有迭代的损失函数值,可用train_score_[i]提取第 i i i轮中的损失函数值。loss_:返回损失函数值。这个属性的用法比较特殊,在用的时候还需要传入两个参数:所有样本的实际标签和模型对所有样本的预测标签,然后计算损失值。计算的方法由参数loss所传入的损失函数类型决定。init_:返回整个GBDT分类算法中用于的初始化基学习器。n_features_:数据集的特征数。classes_:所有类别的标签。n_classes_:数据集的类别数。max_features:最大特征的推断值。
5.3.4 常用方法
下面的介绍中多次提到一个“阶梯…”的概念,这个概念听起来很拗口,但在前面1.3.5.3小节中已做过详细解释,读者可以回顾一下。
-
decision_function(X):得到分类器对数据集 X X X中各个样本的计算结果,分为如下两种情况:- 若数据集只有两个类别,则返回的计算结果的尺寸为 s h a p e = ( 样本数 , 1 ) shape=(样本数,1) shape=(样本数,1);
- 若数据集有 k ( k > 2 ) k(k > 2) k(k>2)个类别,则返回的计算结果的尺寸为 s h a p e = ( 样本数 , k ) shape=(样本数,k) shape=(样本数,k)。
假设GBDT分类器abt对样本 x x x的计算结果gbt.decision_functiuon(x)=[-2.222] ,就表示分类器计算样本 x x x的损失值为-2.222。
-
fit(X,y,[,sample_weight]:拟合数据集。 -
get_params([deep]): d e e p deep deep参数指定为 T r u e True True 时,返回集成分类器的各项参数值。 -
predict(X):对数据集 X X X中各样本进行预测。 -
predict_proba(X):计算出样本 X X X属于各个类别的概率。 -
predict_log_proba(X):返回对数据集 X X X中各样本预测结果的自然对数值。 -
staged_decision_function(X):计算每一轮迭代之后得到的阶梯损失值。 -
staged_predict(X):返回对数据集 X X X中各样本的阶梯类别标签预测结果。 -
staged_predict_probe(X):返回对数据集 X X X中各样本的阶梯概率预测结果。
5.4 实例4:GBDT二分类问题的调参与优化
上个实例中我们从简单直观的角度探索了基学习器(回归决策树)的深度对GBDT拟合效果的影响,并在对比了GDBT算法和AdaBoost算法在同一个数据集上的表现。而这个实例将做如下的探究:在不同学习率和子采样比例下,模型在测试集上的逻辑回归损失随迭代次数增加会的变化曲线,进而了解学习率和bagging采样比率这两个重要的超参数对模型性能的影响,并总结出一些调参的规律和经验。
5.4.1 数据集的创建与可视化
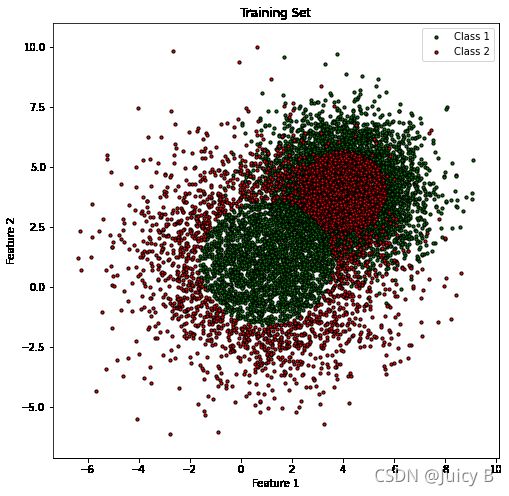
与AdaBoost部分里的实例类似,这里仍然选择采用make_gaussian_quantiles函数创建满足高斯分布的二分类数据集,因为这种分布的数据集非常适合用来测试Boosting模型的性能。创建数据集的代码如下:
# 第一组样本
X1, y1 = make_gaussian_quantiles(mean=(1, 1), cov=5,
n_samples=4000, n_features=2,
n_classes=2, random_state=1)
# 第二组样本
X2, y2 = make_gaussian_quantiles(mean=(4, 4), cov=2,
n_samples=6000, n_features=2,
n_classes=2, random_state=1)
# 将两组样本混在一起,组合成一个数据集
X = np.concatenate((X1, X2))
y = np.concatenate((y1, 1-y2))
可视化训练集的代码如下:
# 取出数据集X中第一个第一个特征,获取最大值和最小值确定第一个特征数值的范围
x1_min= X[:, 0].min() - 1
x1_max = X[:, 0].max() + 1
# 取出数据集X中第一个第二个特征,获取最大值和最小值确定第一个特征数值的范围
x2_min = X[:, 1].min() - 1
x2_max = X[:, 1].max() + 1
plt.figure(figsize=(8, 8))
# 获取标签为0的样本点的索引
index0 = np.where(y == 0)
# X[index, 0]表示数据集中的所有样本的第一个特征的值
# X[index, 1]表示数据集中的所有样本的第二个特征的值
# 以第一个特征为横轴,第二个特征为纵轴,就可以在二维空间中画出数据集
plt.scatter(X[index0, 0], X[index0, 1], c='g', s=30, edgecolor='k', label="Class 1")
plt.xlim(x1_min, x1_max)
plt.ylim(x2_min, x2_max)
plt.legend(loc='upper right')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
# 获取标签为1的样本点的索引
index1 = np.where(y == 1)
# X[index, 0]表示数据集中的所有样本的第一个特征的值
# X[index, 1]表示数据集中的所有样本的第二个特征的值
# 以第一个特征为横轴,第二个特征为纵轴,就可以在二维空间中画出数据集
plt.scatter(X[index1, 0], X[index1, 1], c='r', s=30,edgecolor='k', label="Class 2")
plt.xlim(x1_min, x1_max)
plt.ylim(x2_min, x2_max)
plt.legend(loc='upper right')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Training Set')
输出结果如下:
5.4.2 训练集和测试集的分割
这里选择以8:2的比例划分出训练集与测试集。代码如下:
X_train, X_test = X[:8000], X[8000:]
y_train, y_test = y[:8000], y[8000:]
下面我们来看一下训练集和测试集样本不同类别下的分布情况:
print("Number of class 0 samples in training set: ", y_train[y_train==0].shape)
print("Number of class 1 samples in training set: ", y_train[y_train==1].shape)
输出结果如下:
Number of class 0 samples in training set: (3996,)
Number of class 1 samples in training set: (4004,)
print("Number of class 0 samples in test set: ", y_test[y_test==0].shape)
print("Number of class 1 samples in test set: ",y_test[y_test==1].shape)
输出结果如下:
Number of class 0 samples in test set: (1004,)
Number of class 1 samples in test set: (996,)
可以看到,训练集和测试集中不同类别样本的分布均比较均匀。
5.4.3 调参的思路
想要对一个没有接触过的数据集进行模型调参,若使用盲目搜索方法,简直就跟大海捞针一样困难,特别是对于GBDT这种需要调整的参数非常多的算法。幸运的是,GBDT算法模型有一个非常重要的指标————逻辑回归损失,它可以为调参提供一定的指引。逻辑回归损失的绝对值越大,表示模型的分类误差越大,拟合效果越差;逻辑回归损失的绝对值越小,表示模型的分类误差越小,拟合效果越好。因此,我们可以通过在一个较大的范围内以较大的步长设置一定数量的参数,绘制这些参数下模型拟合的逻辑回归损失曲线,观察总结出一定规律,从而减小调参的范围,减小调参的复杂性。基于以上思路,下面的调参过程将以如下的方式进行:
- 先固定其他参数,调整学习率,绘制不同学习率取值下GBDT模型在测试集上随迭代次数增加的逻辑回归损失函数曲线,对比不同曲线的收敛情况,进而大致确定对学习率的进行小步长精细调参的范围;
- 在上面取得了较好学习率的基础上,使用bagging方法,并对bagging方法中的采样比例subsample进行调整,再次观察逻辑回归损失曲线的收敛情况,找到较好的subsample值;
- 观察曲线随迭代次数增加的收敛和发散情况,使用提前停止方法,用较少的迭代次数实现较好的收敛情况。
这里选择对学习率learning_rate、子采样方法中的采样比例subsample和迭代次数n_estimators这三个参数进行调整,因为这三个参数对GBDT模型拟合效果的影响很大。当然GBDT还有很多其他参数对模型拟合效果的影响也很大,比如迭代过程中单棵回归决策树的最大深度max_depth、最大叶子结点数max_leaf_nodes等,关于这些参数的调参将放在《决策树》部分进行详细介绍。
5.4.4 不同参数取值下模型在测试集上的逻辑回归损失曲线的绘制
若训练好的模型在测试集上的逻辑回归损失曲线收敛到一个较低的水平,则可以判断该模型是一个拟合效果较好的模型。参考上面总结出来的思路,下面将进行如下的参数探索。
学习率的探索
# 由于所有的曲线都要测试500轮迭代的情况,并且为了保证多次运行时的情况相同,所以为每组模型均设置共同的n_estimators和random_state参数
# 其他参数则全部选用默认值
common_params = {'n_estimators': 500, 'random_state': 22}
plt.figure(figsize=(10,6))
# j是迭代次数的索引
j = 1
t1 = time.time()
# 由于要画的曲线过多,逐个定义会使得代码冗余,所以这里选择将各个模型对应的标题、曲线颜色和参数字典封装成元组,并用for循环逐个访问
for label, color, params in [
# 先固定subsample=1.0,表示不使用子采样方法,然后在此基础上调整学习率,观察逻辑回归损失函数曲线的走势
# model_1
('learning_rate=1.0', 'blue',
{'learning_rate': 1.0, 'subsample': 1.0}),
# model_2
('learning_rate=0.8', 'green',
{'learning_rate': 0.8, 'subsample': 1.0}),
# model_3
('learning_rate=0.5', 'orange',
{'learning_rate': 0.5, 'subsample': 1.0}),
# model_4
('learning_rate=0.2', 'red',
{'learning_rate': 0.2, 'subsample': 1.0}),
# model_5
('learning_rate=0.1', 'magenta',
{'learning_rate': 0.1, 'subsample': 1.0})]:
# 所有模型的参数均初始化为共同参数
visualize_params = dict(common_params)
# 使用上面定义的5组参数更新所有模型的参数
visualize_params.update(params)
# 用更新好的参数定义新的GBDT模型
gdt_classifier = GradientBoostingClassifier(**visualize_params)
# 用模型对训练集进行拟合
gdt_classifier.fit(X_train, y_train)
# 定义数组,记录每一组参数所对应的模型在迭代过程中的逻辑回归测试损失
test_logistic_loss = np.zeros((common_params['n_estimators']), dtype=np.float64)
# 使用gdt_classifier.staged_decision_function(X_test)方法获取每轮迭代过程中在测试集上的逻辑回归损失
for i, y_pred in enumerate(gdt_classifier.staged_decision_function(X_test)):
# 记录每一轮的逻辑回归损失
test_logistic_loss[i] = gdt_classifier.loss_(y_test, y_pred)
if (i+1) % 500 == 0:
print("500th iteration test loss of model_%.d: %.4f" % (j, test_logistic_loss[i]))
j = j+1
# 定义步长为2,即每两步绘制一次测试损失曲线
plt.plot((np.arange(test_logistic_loss.shape[0]) + 1)[::2], test_logistic_loss[::2],
'-', color=color, label=label)
# 定义图例、横纵坐标的标签、标题
plt.legend(loc='upper right')
plt.xlabel('GBDT Iterations')
plt.ylabel('Logistic Loss on X_test')
plt.title('Logistic Loss of Different learning_rate when subsample=1.0')
plt.show()
t2=time.time()
total_time = t2 - t1
print("Total Time: %.4fs" % total_time)
输出结果如下:
500th iteration test loss of model_1: 0.7333
500th iteration test loss of model_2: 0.4451
500th iteration test loss of model_3: 0.3976
500th iteration test loss of model_4: 0.2836
500th iteration test loss of model_5: 0.2862

Total Time: 33.1829s
在不使用子采样方法的情况下,在500轮迭代之内,学习率取值为0.1和0.2时曲线的均能收敛到较低的水准,且最终的收敛结果非常接近,这时可以初步确定0.1和0.2是较好的学习率取值,所以下面将分别固定学习率为0.1和0.2,并分别调整子采样比例,观察各自的收敛情况。
learning_rate=0.1,调整子采样比例
1. 不约束纵坐标范围,迭代次数为500:
代码如下:
common_params = {'n_estimators': 500,'random_state':22}
plt.figure(figsize=(10,6))
j = 1
t1 = time.time()
for label, color, params in [
# 固定learning=0.1,然后调整subsample参数(subsample小于1.0时表示使用了子采样方法),观察逻辑回归损失函数曲线的走势
# model_1
('subsample=1.0', 'blue',
{'learning_rate': 0.1, 'subsample': 1.0}),
# model_2
('subsample=0.8', 'green',
{'learning_rate': 0.1, 'subsample': 0.8}),
# model_3
('subsample=0.5', 'orange',
{'learning_rate': 0.1, 'subsample': 0.5}),
# model_4
('subsample=0.3', 'red',
{'learning_rate': 0.1, 'subsample': 0.3}),
# model_5
('subsample=0.2', 'magenta',
{'learning_rate': 0.1, 'subsample': 0.2})
]:
visualize_params = dict(common_params)
visualize_params.update(params)
gdt_classifier = GradientBoostingClassifier(**visualize_params)
gdt_classifier.fit(X_train, y_train)
# 计算每一组参数所对应的模型在测试集上的逻辑回归损失
test_logistic_loss = np.zeros((common_params['n_estimators']), dtype=np.float64)
for i, y_pred in enumerate(gdt_classifier.staged_decision_function(X_test)):
test_logistic_loss[i] = gdt_classifier.loss_(y_test, y_pred)
if (i+1) % 500 == 0:
print("500th iteration test loss of model_%.d: %.4f" % (j, test_logistic_loss[i]))
j = j+1
plt.plot((np.arange(test_logistic_loss.shape[0]) + 1)[::2], test_logistic_loss[::2],
'-', color=color, label=label)
plt.legend(loc='upper right')
plt.xlabel('GBDT Iterations')
plt.ylabel('Logistic Loss on X_test')
plt.title('Logistic Loss of Different subsample when learning_rate=0.1')
plt.show()
t2=time.time()
total_time = t2 - t1
print("Total Time: %.4fs" % total_time)
输出结果如下:
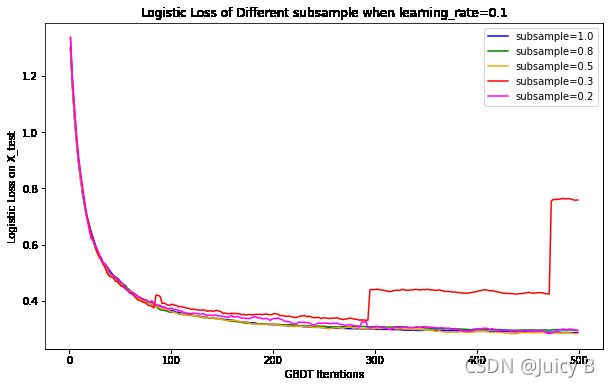
500th iteration test loss of model_1: 0.2862
500th iteration test loss of model_2: 0.2951
500th iteration test loss of model_3: 0.2833
500th iteration test loss of model_4: 0.7589
500th iteration test loss of model_5: 0.2932
Total Time: 21.0707s
可以看到,在500轮迭代之内,不同subsample取值下曲线的收敛情况不同。
其中,当subsample=0.3时,曲线在第300轮迭代开始发散,无法正常收敛;subsample ∈ { 1.0 , 0.8 , 0.5 , 0.2 } \in\{1.0,0.8, 0.5,0.2\} ∈{1.0,0.8,0.5,0.2}时,四条曲线的收敛趋势十分接近,在第500轮迭代时均收敛到了约0.29的水平,并且隐约可以看到,若继续增加迭代次数,曲线还有进一步收敛的趋势。除此之外,使用子采样方法减少了每一次迭代中训练样本的个数,从而减少了模型总体的拟合时间。为了更便于观察对比subsample ∈ { 1.0 , 0.5 , 0.3 , 0.2 } \in\{1.0, 0.5, 0.3, 0.2\} ∈{1.0,0.5,0.3,0.2}时的情况,进一步缩小参数搜索的范围,下面选择将纵坐标范围缩小,同时大幅加大迭代次数,再绘制曲线进行观察。
2. 约束纵坐标范围,迭代次数加大到1500:
这部分的代码只在上一部分的基础上做了如下两点改动,其他均一致:
# 添加下面的语句,将纵坐标的范围缩小到0.25到0.50
plt.ylim(0.25, 0.50)
# 将迭代次数从500增加到1500
common_params = {'n_estimators': 1500,'random_state':22}
输出结果如下:
500th iteration test loss of model_1: 0.2862
1500th iteration test loss of model_1: 0.3062500th iteration test loss of model_2: 0.2951
1500th iteration test loss of model_2: 0.2866500th iteration test loss of model_3: 0.2833
1500th iteration test loss of model_3: 0.2771500th iteration test loss of model_4: 0.7589
1500th iteration test loss of model_4: 7677.4923500th iteration test loss of model_5: 0.2932
1500th iteration test loss of model_5: 6.3716

Total Time: 63.7481s
将迭代次数扩大到1500次时,出现了如下的异常的情况:
500th iteration test loss of model_4: 0.7589
1500th iteration test loss of model_4: 7677.4923500th iteration test loss of model_5: 0.2932
1500th iteration test loss of model_5: 6.3716
当subsample=0.3时,300轮迭代之后曲线开始发散,并且在第1500轮时达到了7677.49的水平,这说明随着迭代次数的增加,曲线的发散程度也越来越严重。而当subsample=0.2时,500轮迭代之内曲线尚能正常收敛,而当迭代次数增加到约第600次时,曲线也出现了发散的情况。这是因为子采样方法采用的是无放回的抽样方法,所以当子采样比例设置得过小时,随着迭代的进行,用于拟合基学习器的样本的数量也会减少得很快,导致在某一轮迭代时训练样本数量过少而突然出现严重的过拟合,进而导致发生损失突然增加的现象。因此,在实际使用中,subsample的值不宜设置得太小,参考本实例的选择并借鉴前人的的丰富经验,一般将subsample的值设置在0.5到0.8之间比较合适。
观察图1.5.5可以发现,learning_rate=0.1时,subsample取值为0.5比较合适,并且在大约第800轮左右曲线收敛到一个较稳定的水平,这时可以使用“提前停止”方法,初步将最大迭代次数设为800,防止迭代次数过多造成计算资源浪费。接下来我们再来看一下learning_rate=0.2时的情况。
learning_rate=0.2,调整子采样比例
1. 不约束纵坐标范围,迭代次数为500:
代码如下:
common_params = {'n_estimators': 500,'random_state':22}
plt.figure(figsize=(10,6))
j = 1
t1 = time.time()
for index, (label, color, params) in enumerate([
# 固定learning=0.1,然后调整subsample参数(subsample小于1.0时表示使用了bagging方法),观察逻辑回归损失函数曲线的走势
('subsample=1.0', 'blue',
{'learning_rate': 0.2, 'subsample': 1.0}),
('subsample=0.8', 'green',
{'learning_rate': 0.2, 'subsample': 0.8}),
('subsample=0.5', 'orange',
{'learning_rate': 0.2, 'subsample': 0.5}),
('subsample=0.3', 'red',
{'learning_rate': 0.2, 'subsample': 0.3}),
('subsample=0.2', 'magenta',
{'learning_rate': 0.2, 'subsample': 0.2})]):
visualize_params = dict(common_params)
visualize_params.update(params)
gdt_classifier = GradientBoostingClassifier(**visualize_params)
gdt_classifier.fit(X_train, y_train)
# 计算每一组参数所对应的模型在测试集上的逻辑回归损失
test_logistic_loss = np.zeros((common_params['n_estimators']), dtype=np.float64)
for i, y_pred in enumerate(gdt_classifier.staged_decision_function(X_test)):
test_logistic_loss[i] = gdt_classifier.loss_(y_test, y_pred)
if (i+1) % 500 == 0:
print("500th iteration test loss of model_%.d: %.4f" % (j, test_logistic_loss[i]))
j = j+1
plt.plot((np.arange(test_logistic_loss.shape[0]) + 1)[::2], test_logistic_loss[::2],
'-', color=color, label=label)
plt.legend(loc='upper right')
plt.ylim(0.2, 1.3)
plt.xlabel('GBDT Iterations')
plt.ylabel('Logistic Loss on X_test')
plt.title('Logistic Loss of Different subsample when learning_rate=0.2')
plt.show()
t2=time.time()
total_time = t2 - t1
print("Total Time: %.4fs" % total_time)
输出结果如下:
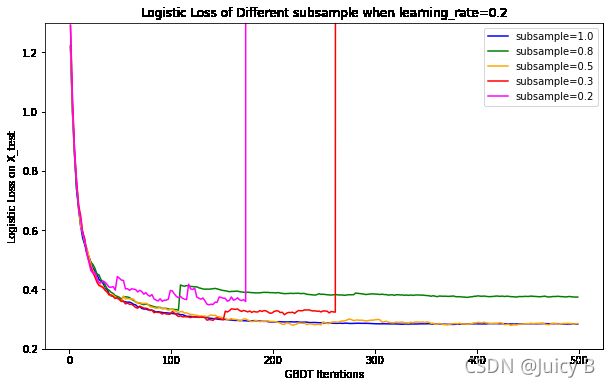
500th iteration test loss of model_1: 0.2836
500th iteration test loss of model_2: 0.3748
500th iteration test loss of model_3: 0.2849
500th iteration test loss of model_4: 21684708241879994243829902443183997462719460904319228536833907553161895218173291003904.0000
500th iteration test loss of model_5: 367821956517265302112681590784.0000
Total Time: 20.8050s
同样可以看到,在500轮迭代之内,当固定learning_rate=0.2时,subsample取值为0.2或0.3时损失曲线同样出现了异常极端的发散现象。同时可以发现,当subsample取值为0.5或1.0时,曲线均收敛到了较低的水平。为了更便于观察对比subsample ∈ { 1.0 , 0.5 } \in\{1.0, 0.5 \} ∈{1.0,0.5}时的情况,下面同样选择将纵坐标范围缩小,同时大幅加大迭代次数,再绘制曲线进行观察。
2. 约束纵坐标范围,迭代次数加大到1500:
这部分的代码只在上一部分的基础上做了如下三点改动,其他均一致:
# 1. 将纵坐标的范围缩小为0.25到0.50
plt.ylim(0.25, 0.50)
# 2. 将迭代次数从500增加到1500
common_params = {'n_estimators': 1500,'random_state':22}
# 3. 在画图代码前面加入约束条件index < 3,排除subsample=0.2和0.3这两个异常极端的现象
if index < 3:
plt.plot((np.arange(test_logistic_loss
输出结果如下:
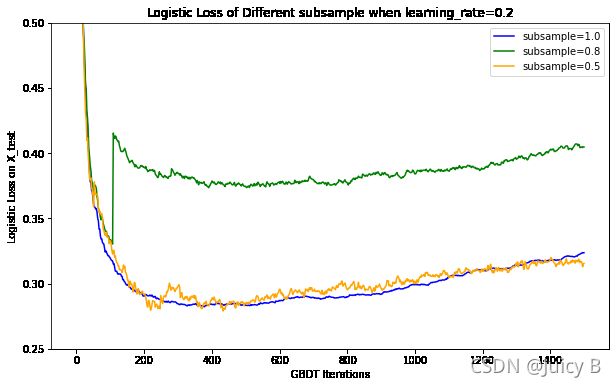
500th iteration test loss of model_1: 0.2836
1500th iteration test loss of model_1: 0.3239500th iteration test loss of model_2: 0.3748
1500th iteration test loss of model_2: 0.4045500th iteration test loss of model_3: 0.2849
1500th iteration test loss of model_3: 0.3177
Total Time: 61.9590s
对比图1.5.5,可以发现,当learning_rate=0.2, subsample=0.5时曲线的收敛效果不如learning_rate=0.1, subsample=0.5时好。
因此,综上考虑:当learning_rate=0.1, subsample=0.5, n_estimators=800时,逻辑回归损失曲线的收敛情况较好。当然这只是粗略的估计,并不能确定在这一组参数下模型的拟合效果就最好,但是可以由此推测最佳参数组合就在这一组参数取值的附近。所以接下来,我们将以learning_rate=0.1, subsample=0.5为搜索区间的中心,并使用提前停止方法,将n_estimators=800设为搜索区间的右顶点,定义步长较小的网格搜索范围,对模型进行进一步的调参优化。
5.4.5 网格搜索
代码如下:
# 创建使用全部默认参数的GBDT分类模型
gdt = GradientBoostingClassifier()
# 定义三个参数的网格搜索范围
n_estimators_range = np.arange(300, 850, 50)
learning_rate_range = np.arange(0.05, 0.15, 0.02)
subsample_range = np.arange(0.4, 0.6, 0.02)
param_grid = dict (learning_rate = learning_rate_range, n_estimators = n_estimators_range, subsample=subsample_range)
# 定义交叉验证方法
cv = StratifiedShuffleSplit(n_splits=5, test_size=0.2, random_state=333)
grid = GridSearchCV(estimator=gdt, param_grid=param_grid, cv = cv, n_jobs=-1)
t1 = time.time()
# 执行网格搜索
grid.fit(X_train, y_train)
t2 = time.time()
t = t2 - t1
# 打印出搜索的总时间
print("Total time: %.4fs" % t )
# 打印出最佳参数
print("Best parameters: ", grid.best_params_)
# 打印出最佳验证准确率
print("Best score:", grid.best_score_)
# 获取最佳模型
gdt_best = grid.best_estimator_
输出结果如下:
Total time: 1994.2339s
Best parameters: {‘learning_rate’: 0.07, ‘n_estimators’: 600, ‘subsample’: 0.58}
Best score: 0.9385
subsample, learning_rate, n_estimators的最佳搜索结果为分别为0.58、0.07和600,这与我们前面的推测比较接近。经过调参,该模型达到了93.85%的平均验证准确率。为了进一步验证模型的性能好坏,接下来将绘制出模型的训练准确率和测试准确率曲线。
5.4.6 绘制最佳分类器的训练准确率和验证准确率曲线
绘制最佳分类器的训练准确率和验证准确率曲线需要先获取最佳分类器的阶梯训练准确率和阶梯测试准确率。这里需要注意,GradientBoostClassifier类不像AdaBoostClassifier类一样有一个staged_score_属性来直接获取GBDT模型的阶梯训练准确率,我们可以借助staged_predict(X)的方法来获取阶梯训练准确率和阶梯测试准确率。代码如下:
# 定义记录阶梯训练准确率的数组
train_staged_accuracy = []
# 获取阶梯训练准确率
gbt_train_score = gdt_best.staged_predict(X_train)
# 将每一轮迭代的阶梯训练准确率放入数组中
for s in gbt_train_score:
train_staged_accuracy.append(accuracy_score(s, y_train))
# 定义记录阶梯测试准确率的数组
test_staged_accuracy = []
# 获取阶梯测试准确率
gbt_test_score = gdt_best.staged_predict(X_test)
# 将每一轮迭代的阶梯测试准确率放入数组中
for s in gbt_test_score:
test_staged_accuracy.append(accuracy_score(s, y_test))
# 画出曲线图
plt.figure(figsize=(10,6))
plt.plot(train_staged_accuracy, color='orange', label="Train Accuracy", alpha=0.8)
plt.plot(test_staged_accuracy, color='green', label="Test Accuracy", alpha=0.8)
plt.legend(loc='lower right')
plt.xlabel('GBDT Iterations')
plt.ylabel('Accuracy')
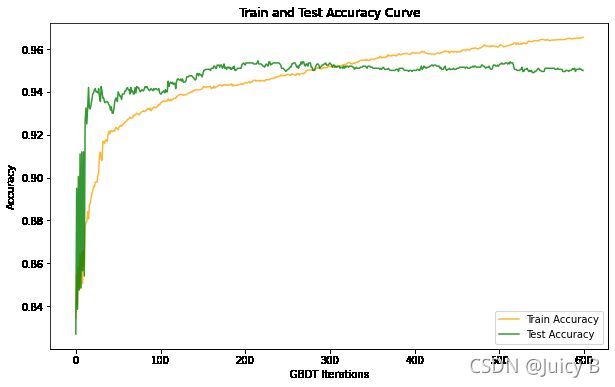
plt.title('Train and Test Accuracy Curve')
plt.show()
# 打印出最后一轮迭代之后的训练准确率和测试准确率
print("Final train accuracy:", train_staged_accuracy[len(train_staged_accuracy)-1])
print("Final test accuracy:", test_staged_accuracy[len(test_staged_accuracy)-1])
输出结果如下:
Final train accuracy: 0.965375
Final test accuracy: 0.95
从上图可以看出,在大约第300轮迭代的时候,模型的测试准确率和训练准确率重叠,并且随着迭代次数的进一步增加,训练准确率在不断上升,最终在第600轮迭代的时候达到了96.54%的训练准确率。而测试准确率在第300轮迭代之后则稳定在了约95%的水平,最终两者之间的差距为1.54%,这个数值说明模型在较高准确率和较低方差之间做出了平衡,结果还是比较理想的。能够达到这样的平衡,以下三点原因功不可没:
-
通过深入探索找到了较合适的learning_rate和subsample取值;
-
在搜索n_estimators时应用了提前停止的方法控制了迭代次数,使得模型在取得较高训练准确率和较高测试准确率的同时又限制住了两者之间的距离,相比使用更多次的迭代,此时模型的泛化性能更好,抗过拟合的能力也更强,训练的时间也比较少;
-
数据集的大小较为合适。笔者在得到本实例的结果之前,在与该例子同分布的1000样本数据集(其中800个训练样本,200个测试样本)上进行了GBDT分类模型的性能测试,最终得到的训练准确率和测试准确率曲线如下:
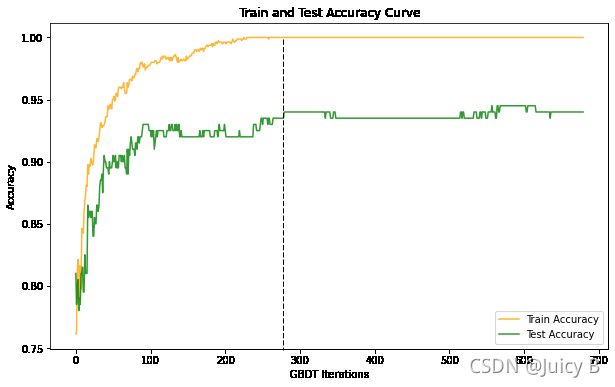 图1.5.9: 数据集样本数为1000时最佳模型的训练准确率和测试准确率曲线
图1.5.9: 数据集样本数为1000时最佳模型的训练准确率和测试准确率曲线观察黑色虚线右边的部分,可以看到,随着迭代次数的增加,训练准确率维持在了100%的最高水平不动,而测试准确率曲线虽然在两个区间内有过小幅度的波动,但是总体上中维持在了大约0.93的水平,两条曲线之间的距离间隔一直无法缩小,此时模型处于一个过拟合的状态,并且随着迭代次数的增加并没有缓和的迹象。这是因为GBDT中采用了无放回抽样的子采样方法,所以随着迭代次数的增加,用于拟合基学习器的训练样本数量会越来越少,甚至会导致后来的基学习器只能分配到1个训练样本,此时训练准确率稳定在100%也就不足为奇了。但正是因为大量的基学习器只能分配到极少数的训练样本,所以无法对整个模型起到明显的推升作用,最终就导致模型无法泛化到未知数据集上。因此,在评估GBDT分类模型的性能的时候,必须尽可能选择较大的数据集,如果无法获取较大型的数据集,就必须及时采用提前停止的方法严格控制迭代的次数,避免跟笔者走一样的弯路。
5.6.7 损失函数的选择对模型预测结果的影响
最后我们来看一下不同损失函数的选择对GBDT模型分类效果的影响。GradientBoostingClassifier类中指定损失函数的参数loss有两个可用选项,一个是默认的"deviance",表示逻辑回归损失;一个是"exponential",表示指数损失。上面的所有步骤全部都使用默认的逻辑回归损失函数。为什么不选指数损失函数呢?下面将绘制出在上面得到的最优参数的情况下选择两种不同损失函数模型在测试集上的损失曲线,直观对比两者的区别。代码如下:
# 选用默认损失函数:逻辑回归损失函数
gdt_logistic = GradientBoostingClassifier(learning_rate= 0.07, n_estimators=600, subsample=0.58)
# 选用指数损失函数
gdt_exp = GradientBoostingClassifier(loss='exponential', learning_rate= 0.07, n_estimators=600, subsample=0.58)
# 分别对上面两个模型进行拟合
gdt_logistic.fit(X_train, y_train)
gdt_exp.fit(X_train, y_train)
# 定义记录逻辑回归损失的数组
test_logistic_loss = []
# 定义记录指数损失的数组
test_exp_loss = []
test_logistic_loss = np.zeros(600, dtype=np.float64)
test_exp_loss = np.zeros(600, dtype=np.float64)
plt.figure(figsize=(10, 6))
# 计算模型在测试集上的逻辑回归损失,并绘制曲线
for i, y_pred in enumerate(gdt_logistic.staged_decision_function(X_test)):
test_logistic_loss[i] = gdt_logistic.loss_(y_test, y_pred)
plt.plot((np.arange(test_logistic_loss.shape[0]) + 1)[::2], test_logistic_loss[::2], '-', color='orange', label='Logistic Loss')
# 计算模型在测试集上的指数损失,并绘制曲线
for i, y_pred in enumerate(gdt_exp.staged_decision_function(X_test)):
test_exp_loss[i] = gdt_exp.loss_(y_test, y_pred)
plt.plot((np.arange(test_exp_loss.shape[0]) + 1)[::2], test_exp_loss[::2], '-', color='green', label='Exponential Loss')
# 画图
plt.legend(loc='upper right')
plt.xlabel('GBDT Iterations')
plt.ylabel('Logistic Loss on X_test')
plt.title('Test Loss Curve of Different Loss Function')
plt.show()
输出结果如下:
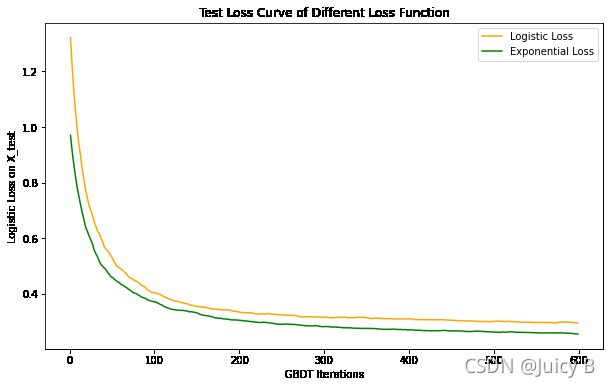
单单从这个图来看,在所有600轮迭代之内,使用指数损失函数时在测试集上的损失都比使用逻辑回归损失函数要低,并且指数损失函数的收敛速度还更快一点点。那是不是说明使用指数损失函数实际上会更好呢?其实不然。出现上图的情况是由这两个函数本身的数学性质决定的,但不能断言说指数损失函数的收敛速度更快、收敛到更低的水平,那它就比逻辑回归损失函数更适用于GBDT模型。我们来看一下当选用指数损失函数、并且使用之前找到的最佳参数(learning_rate= 0.07, n_estimators=600, subsample=0.58)时模型的训练准确率和验证准确率曲线,并打印出最终的准确率数值:
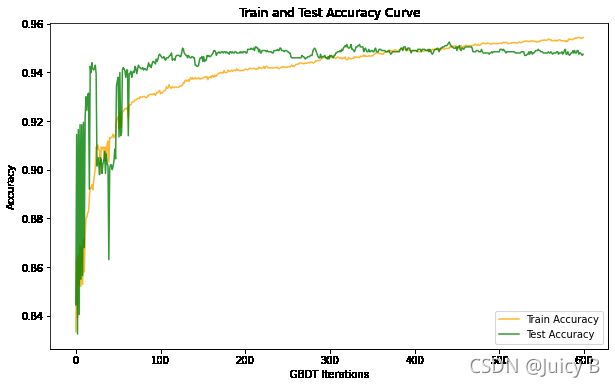
Final train accuracy: 0.954375
Final test accuracy: 0.9475
对比图1.5.8使用逻辑回归损失函数时的曲线,可以发现,若使用指数损失函数,经过600轮迭代之后,无论是训练准确率还是测试准确率都不如使用逻辑回归损失函数时高,并且可以直观看到,在100轮迭代内,使用指数损失函数时的测试准确率曲线的波动范围很大,这是因为,若选用指数损失函数,则模型在迭代过程中会赋予分错样本更大的权重,更加关注分类错误的样本,这会导致当迭代次数较少的时候,模型更趋向于对噪声进行拟合,使得模型抗噪声的能力降低,测试准确率产生大的波动。而使用逻辑回归损失函数时,比如上图迭代次数少于100的部分,测试准确率曲线的走势相比使用指数损失函数时更加平稳,这时因为此时模型不会太过于关注分错的样本,从而使得整个GBDT分类模型在抗噪声的鲁棒性方面更好,进而使得模型能够更好地泛化到未知数据集当中。因此,sklearn选用逻辑回归损失函数作为默认损失函数。