视频技术基础01:图像基础和前处理
目录
1 基本概念
1.1 图像基本概念
1.1.1 像素(Pixel)
1.1.2 位深
1.1.3 分辨率
1.1.4 跨距(Stride)
1.2 视频基本概念
1.2.1 帧率
1.2.2 码率
2 颜色空间
2.1 RGB颜色空间
2.2 YUV颜色空间
2.2.1 概述
2.2.2 YUV颜色空间类型
2.2.3 YUV颜色空间存储方式
2.3 RGB和YUV之间的转换
2.3.1 概述
2.3.2 转换标准
2.4 为什么视频领域广泛使用YUV颜色空间?
3 图像缩放算法
3.1 图像缩放场景示例
3.2 缩放算法基本原理
3.2.1 基本过程
3.2.2 放大过程示例
3.2.3 缩小过程示例
3.3 插值算法
3.3.1 概述
3.3.2 线性插值原理
3.3.3 最临近插值(Nearest)
3.3.4 双线性插值(Bilinear)
3.3.5 双三次插值(BiCubic)
1 基本概念
1.1 图像基本概念
1.1.1 像素(Pixel)
1. 像素是图像的基本单元,一个个像素就组成了图像
2. 在直观感受上,像素就是一个带有颜色的小块。下图中的一个个方块,就是像素

1.1.2 位深
1. 在彩色图像中,有R、G、B三个通道,分别表示红、蓝、绿,彩色图像中的像素就是由R、G、B三个值组成
2. 位深是指一个像素中某一个通道(e.g. R通道、G通道、B通道)的像素值的二进制位数
① 常见的RGB位深为8位,也就是R、G、B各占8位。8位能表示256种颜色值,3个通道就是256 ^ 3个颜色值,也就是1677万种颜色
② 目前也有位深为10位和12位的图像,位深越大,能够表示的颜色值就越多
3. 通过位深就可以计算出存储一个像素所需的二进制位数
① 对于位深为8位的图像,存储每个像素需要占用(3 * 8 = 24)位,即3B
② 图像的位深越大,虽然能够表示的颜色值越多,但是需要的存储空间也越大,传输图像所需的流量也越多。因此,目前大多数情况下看到的图像以及视频的位深还是8位
说明1:除了RGB值,有时候还会有Alpha值,该值代表透明度
说明2:上文以RGB颜色空间为例说明位深的概念,在其他颜色空间中也同样有位深
① 例如在YUV颜色空间中,一个像素就有Y通道、U通道和V通道,其中每个通道像素值的二进制位数也是位深
② YUV颜色空间常见的位深为8bit / 10bit / 12bit
1.1.3 分辨率
1. 分辨率是指图像的大小或尺寸
2. 一般使用像素的个数来表示图像的尺寸
例如一张1920 * 1080的图像,就是表示该图像在宽度方向上有1920个像素,在高度方向上有1080个像素

说明1:常见分辨率
① QCIF:176 * 144
② CIF:352 * 288
③ D1:704 * 576或720 *576
④ 360P:640 * 360
⑤ 720P:1280 * 720
⑥ 1080P:1920 * 1080
⑦ 4K:3840 * 2160
⑧ 8K:7680 * 4320
说明2:分辨率与图像清晰度的关系
① 原始图像分辨率越高,图像就越清晰

② 对于经过后期处理的图像(e.g. 放大缩小,尤其是放大之后的图像),分辨率高并不一定更清晰。这是因为放大的图像是经过插值处理得到的,而插值的像素是使用临近像素经过插值算法计算得到的,和实际相机拍摄的像素是不一样的
1.1.4 跨距(Stride)
1. 首先需要说明的是,跨距不是图像本身的属性,而是与图像存储有关的特性,是指图像存储时内存中每行像素所占用的空间
2. 在存储图像时,是按行逐行存储在内存中。为了能够快速读取一行像素,我们一般会对内存中的图像按行进行内存对齐,比如按16B对齐

以位深为8位,分辨率为1278 * 720的RGB图像为例。将该图像存储在内存时,一行像素需要(1278 * 3 = 3834)B,该值无法被16整除。此时可以在每行的3834B之后填充6B,也就是3840B,从而实现16B对齐。也就是说,存储该图像的跨距为3840B
3. 由于存在这种为了字节对齐进行的填充,在读取和处理一行像素时需要越过用于填充的字节。如果没有越过的话,就会将填充的字节作为下一行开始的像素处理,那么得到的图像就会出现"花屏"的现象,屏幕上会出现一条斜线
说明1:由于不同的视频编解码器内部实现的不同,有时候即便是每行像素值是规则值的图像(e.g. 1920或者1280等能被16整除的宽度),图像存储在内存中仍然有可能出现跨距填充的情况
说明2:跨距对齐的目的是使得CPU内存读取效率最大化,因此对齐的标准随CPU而异,除了16B,也可能是32B或64B
1.2 视频基本概念
1.2.1 帧率
1. 视频由一帧帧的图像组成
2. 帧率是指视频1秒内图像的数量
一般帧率达到10 ~ 12帧,人眼就会认为是流畅的。电影帧率一般是24fps,监控行业常用25fps
说明:选择帧率时需要考虑设备的处理性能和网络传输能力
① 帧率越高,每秒要处理的图像越多,从而对设备的处理性能要求就越高
② 如果要对图像进行传输,帧率越高,流量也会越大,对带宽的要求就越高
1.2.2 码率
1. 码率概念的提出与视频压缩处理有关,通常在存储和传输视频时需要对图像进行压缩,码率的概念就是用于描述压缩之后的视频大小
2. 码率是指视频在单位时间内的数据量大小,一般是1秒内的数据量,单位一般是Kb/s或Mb/s
这里的数据量,是指压缩后的数据量。因此虽然每秒视频中图像的分辨率相同,但是经过压缩算法之后得到的每秒数据量却可以是不同的,也就是码率可以是不同的
说明1:码率与清晰度的关系
① 使用压缩工具压缩同一个原始视频的时候,码率越高,图像的失真就会越小,视频画面就会越清晰。但同时码率越高,存储时占用的内存空间就会越大,传输时使用的流量就会越多
② 但是并不是说码率越高,清晰度就会越高,这需要结合压缩算法和压缩速度综合考虑,一般情况下,
- 压缩算法越先进,压缩率就会越高,码率就会越小
- 压缩速度越慢,压缩时的算法就会越精细,最后压缩率也会有提高,相同清晰度的码率也会更小
说明2:码率是固定的还是变化的?
① 码率可以是固定的,也可以是变化的
② 对于固定码率,如果编码后的码率小于固定码率,则填充数据;如果编码后的码率大于固定码率,则丢弃数据降低码率
③ 一般来说,除非要求绝对固定,不然不会填充数据,以免浪费带宽
2 颜色空间
在现实世界中,人眼看到的颜色是千变万化的。为了能够更加方便地表示和处理这些颜色,不同应用领域建立了多种不同的颜色空间,主要有RGB、YUV、CMYK、HSI等
在视频技术中,常用的颜色空间有2种:RGB和YUV
2.1 RGB颜色空间
1. RGB颜色空间是平常遇到最多的一种颜色空间,摄像头采集的原始(raw)图像就是RGB图像,显示器显示的图像也是RGB图像
2. RGB颜色空间中的每个像素都有R、G、B三个值,且三个值依次排列存储
以8bit位深的RGB图像为例,每个值占用1B
3. 虽然颜色空间叫RGB,但是在存储RGB图像像素中的R、G、B值时并不一定是按R、G、B的顺序排列的,也有可能是按B、G、R的顺序排列(e.g. OpenCV就经常使用BGR的排列方式存储图像)

2.2 YUV颜色空间
2.2.1 概述
1. 虽然RGB颜色空间比较简单,但是在视频领域更多是使用YUV颜色空间来表示图像
YUV最早主要是用于电视系统与模拟视频领域,现在视频领域基本都是使用YUV颜色空间
2. YUV图像将亮度信息Y与色彩信息U、V分离开来,其中,
① Y表示亮度,是图像的总体轮廓,称之Y分量
② U、V表示色度,主要描绘图像的色彩等信息,分别称为U分量和V分量
说明:在知道了YUV图像的构成方式后,就很容易理解他为什么最早用于电视系统。因为在早期,只有黑白电视,每一帧电视图像都是黑白的,没有色彩信息。此时只需要使用YUV图像中的Y分量即可,Y分量依旧是一张图像,而且包括了图像的总体轮廓信息,只不过是一张黑白图像
2.2.2 YUV颜色空间类型
根据U、V分量像素点的个数,YUV颜色空间分为如下常用类型
2.2.2.1 YUV 444
每个Y分量对应一组UV分量

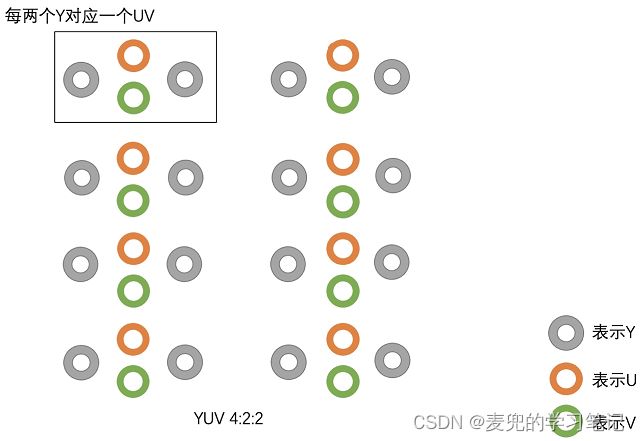
2.2.2.2 YUV 422
每左右两个Y分量共用一组UV分量
2.2.2.3 YUV 420
每上下左右四个Y分量共用一组UV分量
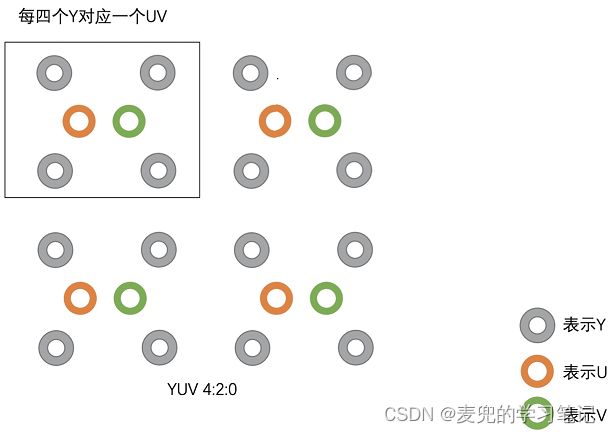
说明1:使用YUV422和YUV420存储图像时,由于减少了色度信息其实是会有失真的,只是人眼对于色度信息相对不敏感,失真在可接受范围内。但是减少色度信息可以减少数据量,所以收益还是明显的
说明2:对于YUV422和YUV420,如果Y分量的分辨率不能被整除(YUV422不能被2整除,YUV420不能被4整除),则余下的Y分量也要有一组UV分量描述色彩信息
例如对于5 * 2像素的YUV420图像,共有10个Y分量,前8个Y分量对应2组UV分量,余下的Y分量虽然只有只有2个(不足4个),也要有1组UV分量描述色彩信息
2.2.3 YUV颜色空间存储方式
2.2.3.1 概述
YUV存储方式主要分为两大类,
1. Planar格式
① Planer格式是先连续存储所有像素点的Y分量,然后连续存储UV分量
② 在连续存储UV分量时,可以先存储U分量,也可以先存储V分量
3. Packed格式
① Packed格式是先连续存储所有像素点的Y分量,然后交替存储UV分量
② 在交替存储UV分量时,可以先存储U分量,也可以先存储V分量
说明:通过格式与UV分量顺序的组合,就有4种YUV存储方式
① Planer格式U分量在前
② Planer格式V分量在前
③ Packed格式U分量在前
④ Packed格式V分量在前
2.2.3.2 YUV444的存储
YUV444常用Planar格式存储,根据UV分量的先后顺序,分为I444和YV24。以4 * 2像素的YUV444图像为例,存储方式如下
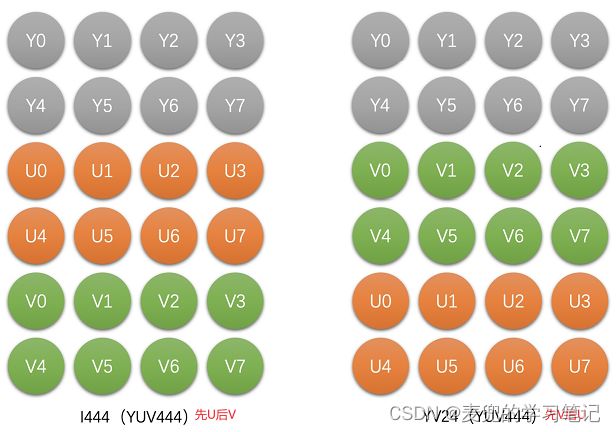
说明:在位深相同的情况下,YUV444和RGB图像存储后的大小是一样的。如果都是8bit位深,就是存储每个像素需要3B
2.2.3.3 YUV422的存储
以4 * 2像素的YUV422图像为例,不同格式和不同UV顺序的存储方式如下
1. Planar格式
根据UV分量的先后顺序,分为YU16和YV16(但是都属于YUV422P,这里的P用于标识Planar格式)

2. Packed格式
根据UV分量的先后顺序,分为NV16和NV61(但是都属于YUV422SP,这里的SP用于标识Packe格式)

说明:假设位深为8bit,存储4 * 2像素的图像
① RGB图像需要(8 * 3 = 24)B
② YUV422图像只需要(8 + 4 + 4 = 16)B
2.2.3.4 YUV420的存储
以4 * 4像素的YUV420图像为例,不同格式和不同UV顺序的存储方式如下
1 Planar格式
根据UV分量的先后顺序,分为YU12和YV12(但是都属于YUV420P,这里的P用于标识Planar格式)
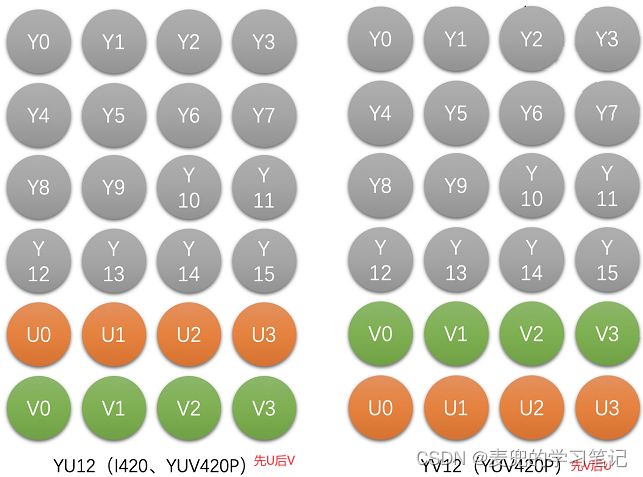
2. Packed格式
根据UV分量的先后顺序,分为NV12和NV21(但是都属于YUV420SP,这里的SP用于标识Packe格式)
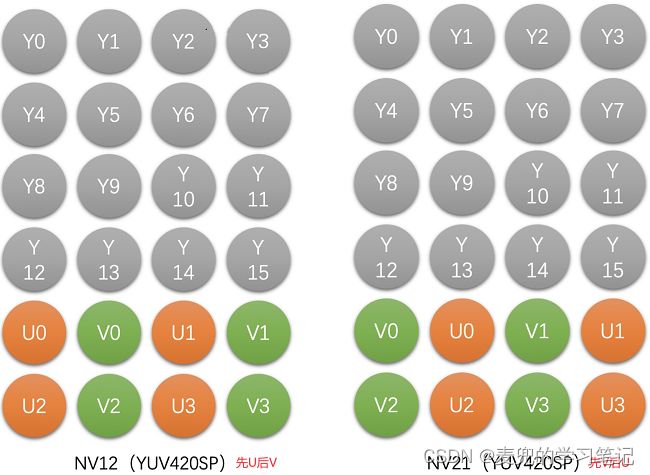
说明1:假设位深为8bit,存储4 * 4像素的图像
① RGB图像需要(16 * 3 = 48)B
② YUV422图像只需要(16 +4 + 4 = 24)B
说明2:因为YUV420所需的存储空间最小,所以他是最常见也是最常用的YUV类型,通常视频压缩时使用的图像格式都是YUV420
说明3:在处理YUV图像的存储和读取时也需要注意跨距(Stride)的问题
假设有一张1283 * 720的YUV图像,其中Y分量存储按16B对齐的话应该是每行占用1296B,所以每读取一行像素的Y分量应该是1296B

2.3 RGB和YUV之间的转换
2.3.1 概述
1. 一般来说,采集到的原始图像和给显示器渲染的最终图像是RGB图像,而视频编码一般使用的是YUV图像,因此就需要在二者之间进行相互转换
2. 由于转换公式与Color Range有关,因此在说明转换标准之前,先说明一下Color Range的概念
对于位深为8bit的RGB图像,Color Range用于规范他的每个R、G、B分量的取值范围,
① Full Range:R、G、B分量的取值范围为0 ~ 255
② Limited Range:R、G、B分量的取值范围为16 ~ 235
2.3.2 转换标准
目前常用的RGB和YUV互相转换的标准是BT601和BT709,其中BT601是标清的标准,BT709是高清的标准。具体的转换公式,如下图所示

说明:关于转换的对应关系
① 在将YUV转换为RGB时,是将每个像素的YUV值转换为RGB值,根据YUV类型不同,像素的UV分量可能是共用的
② 在将RGB转换为YUV时,如果目标YUV类型需要UV分量共用,则需要通过多个像素的RGB值计算UV分量
以RGB转换为YUV420为例,是将每个像素的RGB值转换成一个Y分量;然后每上下左右4个像素的RGB转换成一个U分量和一个V分量,并由相应的4个Y值共用
2.4 为什么视频领域广泛使用YUV颜色空间?
通过上文对RGB和YUV颜色空间的分析,YUV颜色空间有如下优势
1. 减少数据量
由于减少了色度信息,YUV422和YUV420存储每个像素所需的数据量减少
2. 便于压缩编码
① 在RGB颜色空间中,R、G、B三个颜色有相关性,所以不便于做图像压缩编码
如果将R、G、B三个通道分离开当作图像看待的话,三张图像的内容几乎是一样的,只是颜色不同,因此具有相关性。如果进行编码,三张图像同等重要,因此不便于编码
② 而YUV中只有Y是图像的总体轮廓,没有颜色信息;而U、V是颜色信息,三张图像相互独立,可以独立编码
说明:有些图像处理算法只需要灰度图,也就是只需要Y分量就可以。如果原图为RGB图像,还需要额外的转换,这也是YUV目前广泛使用的原因之一
3 图像缩放算法
3.1 图像缩放场景示例
1. 播放窗口与原始图像分辨率不匹配时需要缩放(e.g. 图像全屏播放)
2. 在线观看视频时会有多种分辨率可供选择,即需要在一个图像分辨率的基础上缩放出多种不同尺寸的图像
3. 在RTC场景中,有时需要根据网络状况实时调节视频通话的分辨率,这也需要缩放算法来完成
3.2 缩放算法基本原理
3.2.1 基本过程
图像缩放就是将原图像的已有像素经过加权运算得到目标图像的目标像素,主要包括两个基本过程,
1. 像素位置映射过程
将目标图像的像素位置映射到原图像的对应位置上
2. 映射位置像素的插值过程
将通过插值计算得到的原图像对应位置的像素值作为目标图像对应位置的像素值
说明:图像缩放和插值计算在RGB和YUV颜色空间中都可以进行,因此下文不会对颜色空间做区分
3.2.2 放大过程示例
假设将720P(1280 * 720)的原图放大到1080P(1920 * 1080)
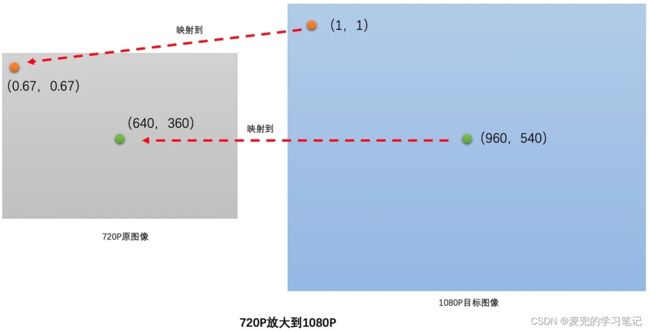
1. 像素位置映射过程
以目标图像中位置为(1,1)和(960,540)的像素为例,在从720P放大到1080P时,目标图像在宽度方向上是原图的(1920 / 1280 = 1.5)倍,在高度方向上是原图的(1080 / 720 = 1.5倍),因此,
① 目标图像中的(1,1)映射到原图的(0.67,0.67)
② 目标图像中的(960, 540)映射到原图的(640, 360)
2. 映射位置像素的插值过程
在原图中根据插值算法计算位置为(0.67,0.67)和(640,360)的像素值,并将他们作为目标图像中位置为(1,1)和(960,540)的像素值
3.2.3 缩小过程示例
假设将720P(1280 * 720)的原图缩小到360P(640 * 360)
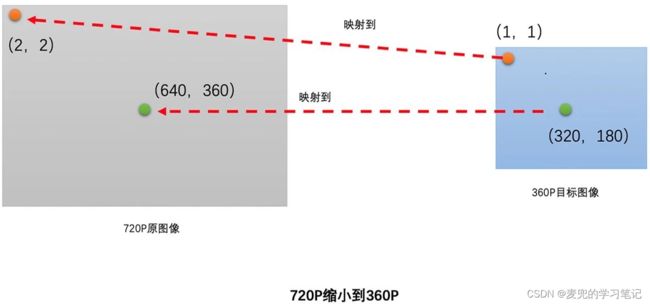
1. 像素位置映射过程
以目标图像中位置为(1, 1)和(320, 180)的像素为例,在从720P缩小到360P时,目标图像在宽度方向上是原图的(640 / 1280 = 0.5)倍,在高度方向上是原图的(360 / 720 = 0.5倍),因此,
① 目标图像中的(1,1)映射到原图的(2,2)
② 目标图像中的(320, 180)映射到原图的(640, 360)
2. 映射位置像素的插值过程
在原图中根据插值算法计算位置为(2,2)和(320,180)的像素值,并将他们作为目标图像中位置为(1,1)和(320,180)的像素值
说明1:图像缩放算法通用表达式
① 假设原图像的分辨率为w0 * h0,缩放目标图像的分辨率为w1 * h1,那么目标图像中像素位置(x,y)就映射到原图像的(x * w0 / w1,y * h0 / h1)位置
② 在原图像中通过插值算法得到(x * w0 / w1,y * h0 / h1)位置的像素值,并将该值作为目标图像(x,y)位置的像素值
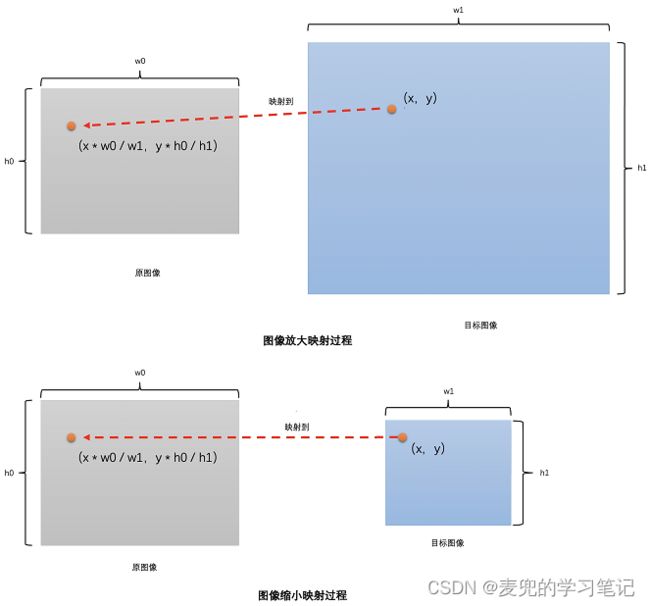
说明2:通过(x * w0 / w1,y * h0 / h1)计算出的位置绝大多数情况下是小数
说明3:图像的缩放也称作图像的重采样,放大图像称为上采样,缩小图像称为下采样
3.3 插值算法
3.3.1 概述
1. 目前图像的缩放算法非常多,其中主要包括最常用的插值算法和目前热门的AI超分算法。由于目前绝大多数图像的缩放还是通过插值算法实现的,因此本文主要说明插值算法
2. 各种插值算法的基本原理都是使用周围已有的像素值,通过一定的加权运算得到插值像素值
3.3.2 线性插值原理
1. 下面要说明的3种插值方法均基于线性插值原理实现
2. 线性插值是一种以距离作为权重的插值方法,距离越近权重越大,距离越远权重越小
线性插值是在两个点中间的某一个位置插值得到一个新的值,线性插值认为这个需要插值得到的点和这两个已知点都有一定关系,并且待插值点与离他近的那个点更相似
3. 假设在下图中已知(x1,y2)和(x2,y2)两个点,需要求得x对应的y值

通过线性插值方法,y值的计算公式如下,

3.3.3 最临近插值(Nearest)
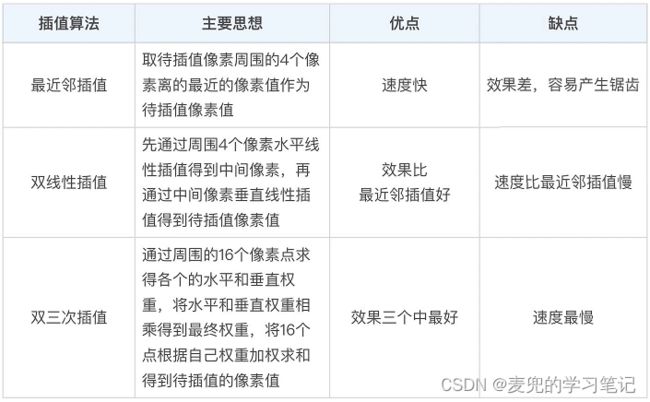
1. 最临近插值算法在原图像中找到映射位置周围的4个像素,然后取离映射位置最近的像素点的像素值作为目标像素值
2. 假设待插值点位置为(0.67,0),使用最临近插值算法就会使用临近4个像素中离他最近的(1,0)像素点的像素值作为目标像素值
可见临近插值法可以理解为线性插值的一种特例,就是最临界像素的权重为1,其余3个像素的权重为0

3. 最临界插值算法计算速度快,但是有一个明显的缺点,就是会导致相邻两个插值像素有很大概率是相同的。这样得到的放大图像会出现块状效应,缩小图像会出现锯齿
3.3.4 双线性插值(Bilinear)
1. 双线性插值算法也是在原图像中找到映射位置周围的4个像素,并将这4个像素值通过一定的运算得到最后的插值像素
2. 双线性插值算法本质上就是三次线性插值的过程
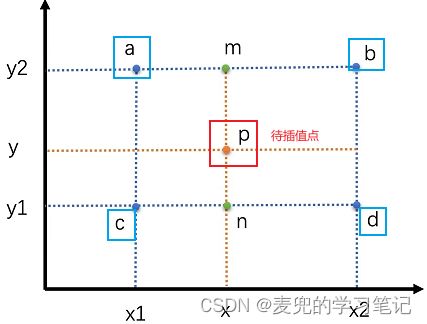
假设p为待插值点,而a / b / c / d是4个已知点,
① 首先通过a和b水平线性插值求得m点的像素
② 再通过c和d水平线性插值求得n点的像素
③ 最后通过m和n垂直线性插值求得p点的像素
3. 相较于最临界插值算法,双线性插值算法运算更多,因此运行时间更长,但是图像缩放效果更好
3.3.5 双三次插值(BiCubic)
1. 双三次插值在原图像中找到映射位置周围的16个像素,并且使用一个特殊的BiCubic基函数计算每个周围像素的权重,然后将16个像素加权平均作为最终的待插值像素值
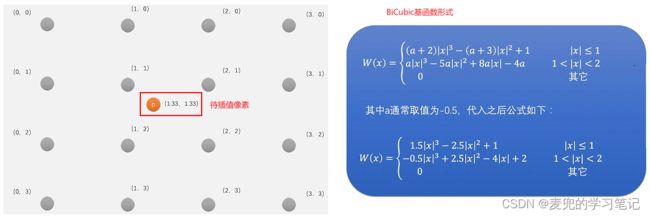
2. 双三次插值需要计算周围16个像素点的权重再加权平均求和,因此计算量更大,但是插值后的图像效果更好
说明1:双三次插值计算时需要周围的16个像素点,但是对于有些位置(e.g. 图像左上角的点(0.5, 0.5)),周围不足16个像素点。此时一般用第一行和第一列的像素进行补充
说明2:上述3种插值算法比较如下
说明3:在实际实现中,图像缩放算法中的大量计算可以使用汇编进行优化。这种优化需要针对不同体系结构进行,例如ARM体系结构中的neon扩展指令