河北工业大学数据挖掘实验二 数据立方体与联机分析处理构建
河北工业大学数据挖掘实验二 数据立方体与联机分析处理构建
- 一、实验目的
- 二、实验原理
-
- 1、关系型数据库
- 2、数据立方体
- 3、OLAP 操作
- 4、数据仓库的设计
- 三、实验内容和步骤
-
- 1、实验内容
- 2、实验步骤
- 3、程序框图
- 4、实验样本
- 6、实验代码
- 四、实验结果
- 五、实验分析
一、实验目的
(1)熟悉基本数据立方体构建、联机分析处理算法。
(2)建立一致的高质量的关系型数据库。
(3)在建立的数据库基础上建立基本数据立方体。
(5)写出实验报告。
二、实验原理
1、关系型数据库
关系数据库,是创建在关系模型基础上的数据库,借助于集合代数等数学概
念和方法来处理数据库中的数据。关系模型由关系数据结构、关系操作集合、关
系完整性约束三部分组成。
2、数据立方体
一种多维数据模型,允许以多维对数据建模和观察。它由维和事实定义。维是一个单位想要的透视或实体。每个维可以有一个与人相关联的表,称为维表,它进一步描述维,如 item 维的维表包含属性 Name、time、type等。事实:多维数据模型围绕诸如销售这样的主题组织,主题用事实表示,事实是数值度量的。
3、OLAP 操作
上卷:沿着一个维的概念分层向上攀升或通过维归约在数据立方体上进行聚集。
下钻:上卷的逆操作,可能过沿维的概念分层向下或引入附加的维来实现。
切片:在给定的数据立方体的一个维上进行选择,导致一个子立方体。就是数据立方体的某一层数据。
切换:在两个或多个维上选择,定义子立方体。就是数据立方体某一层
数据中的某一块。
4、数据仓库的设计
选取待建模的商务处理:都有哪些商务过程,如订单、发票、发货、库 存、记账管理、销售或一般分类账。选取商务处理的粒度:对于商务处理,该粒度是基本的,在事实表中是数据的原子级,如单个事务、一天的快照等。选取用于每个事实表记录的维:典型的维是时间、商品、顾客、供应商、仓库、事务类型和状态。选取将安放在每个事实表记录中的度量:典型的度量是可加的数值量, 如 dollars_sold 和 units_sold。
三、实验内容和步骤
1、实验内容
1)用 VC++编程工具编写程序,建立关系型数据存储结构,建立数据立方体,并在实验报告中写出主要的过程和采用的方法。建立的数据立方体的维度为 3,分别是商品大类、商店编号和时间。具体要求:
- 建立三个存储表格(txt 文件)分别存储 1019、1020、1021的数据;
- 每个 txt 文件横向为商品大类(商品 ID 前五位)10010 油、10020 面制品、10030 米和粉、10088 粮油类赠品;
- 每个 txt 纵向为日期 13-19 这一个星期表中存储的值为总销
售额。
2)进行简单的 OLAP 数据查询
具体要求:
- 能查出 2020 商店 10010 油类商品 13 日总的销售额;
- 能计算出 2020 商店 10030 米和粉总的销售额;
- 能查询出指定商店指定种类商品的销售额;(附加题)
2、实验步骤
1)仔细研究和审查数据,找出应当包含在你分析中的属性或维去掉不需要
的数据。经过数据预处理后的数值已经补充了缺失值,并统一了格式。读取预处理数据的商品 ID、日期、计算出销售额。
2)选择合适的存储结构,实现数据的存储访问,并实现相应的功能。
3、程序框图
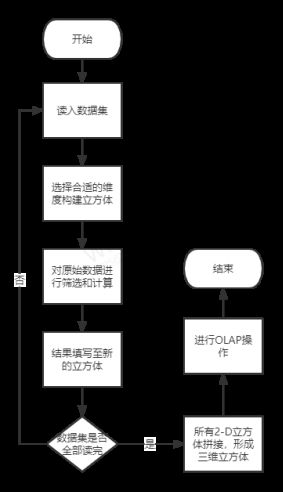
4、实验样本
实验一处理后的data.csv
6、实验代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#
# Copyright (C) 2021 #
# @Time : 2022/5/30 21:27
# @Author : Yang Haoyuan
# @Email : [email protected]
# @File : Exp2.py
# @Software: PyCharm
import pandas as pd
import argparse
parser = argparse.ArgumentParser(description='Exp2')
parser.add_argument('--Shop', type=str, default="1019", choices=["1019", "1020", "1021"])
parser.add_argument('--Good', type=str, default="10010油", choices=["10010油", "10020面制品", "10030米和粉", "10088粮油类赠品"])
parser.set_defaults(augment=True)
args = parser.parse_args()
print(args)
# 读取1019,1020,1021三个商店的数据
def getData():
data = pd.read_csv("data.csv")
data_19 = data[:7693]
data_20 = data[7693:17589]
data_21 = data[17589:]
return data_19, data_20, data_21
# 构建数据立方体,数据结构采用DataFrame
def make_cuboid(data):
arr = [[ 0.0, 0.0, 0.0, 0.0],
[ 0.0, 0.0, 0.0, 0.0],
[0.0, 0.0, 0.0, 0.0],
[0.0, 0.0, 0.0, 0.0],
[ 0.0, 0.0, 0.0, 0.0],
[ 0.0, 0.0, 0.0, 0.0],
[0.0, 0.0, 0.0, 0.0]]
dataFrame = pd.DataFrame(arr, columns=["10010油", "10020面制品", "10030米和粉", "10088粮油类赠品"],
index=["13", "14", "15", "16", "17", "18", "19"])
# 按日期进行筛选,把各日期的数据放入list中
t = [data.loc[data["Date"] == 20030413, ["Date", "GoodID", "Num", "Price"]],
data.loc[data["Date"] == 20030414, ["Date", "GoodID", "Num", "Price"]],
data.loc[data["Date"] == 20030415, ["Date", "GoodID", "Num", "Price"]],
data.loc[data["Date"] == 20030416, ["Date", "GoodID", "Num", "Price"]],
data.loc[data["Date"] == 20030417, ["Date", "GoodID", "Num", "Price"]],
data.loc[data["Date"] == 20030418, ["Date", "GoodID", "Num", "Price"]],
data.loc[data["Date"] == 20030419, ["Date", "GoodID", "Num", "Price"]]
]
idx = 13
for df in t:
# 按照商品类别,将各类商品各日期销售总额计算出来并保存
_df = df[df["GoodID"] >= 1001000]
_df = _df[_df["GoodID"] <= 1001099]
_sum = 0
for index, row in _df.iterrows():
_sum = _sum + row["Num"] * row["Price"]
dataFrame.loc[(str(idx), "10010油")] = _sum
_sum = 0
_df = df[df["GoodID"] >= 1002000]
_df = _df[_df["GoodID"] <= 1002099]
for index, row in _df.iterrows():
_sum = _sum + row["Num"] * row["Price"]
dataFrame.loc[(str(idx), "10020面制品")] = _sum
_sum = 0
_df = df[df["GoodID"] >= 1003000]
_df = _df[_df["GoodID"] <= 1003099]
for index, row in _df.iterrows():
_sum = _sum + row["Num"] * row["Price"]
dataFrame.loc[(str(idx), "10030米和粉")] = _sum
_sum = 0
_df = df[df["GoodID"] >= 1008800]
_df = _df[_df["GoodID"] <= 1008899]
for index, row in _df.iterrows():
_sum = _sum + row["Num"] * row["Price"]
dataFrame.loc[(str(idx), "10088粮油类赠品")] = _sum
_sum = 0
idx = idx + 1
return dataFrame
if __name__ == "__main__":
data_1019, data_1020, data_1021 = getData()
# 各数据立方体按照4为小数保存到txt文件
df_1019 = make_cuboid(data_1019)
df_1019.applymap('{:.4f}'.format).to_csv("1019.txt", index=False)
df_1020 = make_cuboid(data_1020)
df_1020.applymap('{:.4f}'.format).to_csv("1020.txt", index=False)
df_1021 = make_cuboid(data_1021)
df_1021.applymap('{:.4f}'.format).to_csv("1021.txt", index=False)
# 三维数据立方体保存到txt文件中
data = pd.concat([df_1019, df_1020, df_1021], keys=["1019", "1020", "1021"], names=["Shop", "Date"])
data.to_csv("data_cubiod.csv")
# "1020商店10010油类商品13日总的销售额
print("1020商店10010油类商品13日总的销售额", format(data.loc[("1020", "13"), "10010油"], '.2f'))
# 1020商店10030米和粉总的销售额
df = data.loc["1020"]
print("1020商店10030米和粉总的销售额", format(df["10030米和粉"].sum(), '.2f'))
# 指定商店指定货物的销售总额
df = data.loc[args.Shop]
print(args.Shop + "商店" + args.Good + "的销售额", format(df[args.Good].sum(), '.2f'))
四、实验结果
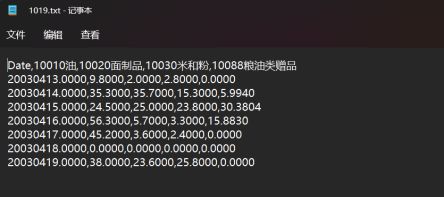
1019数据立方体txt文件
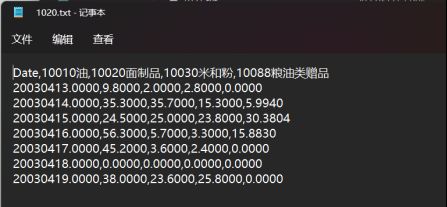
1020数据立方体txt文件
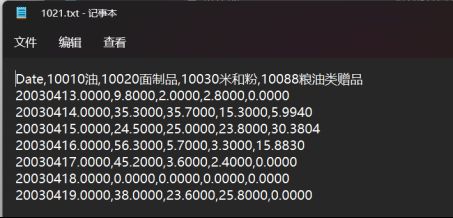
1021数据立方体txt文件
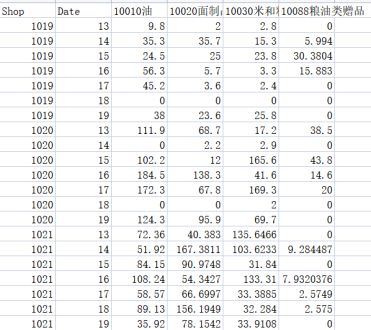
三维数据立方体csv文件,维度为Shop,Date和四类商品

2020商店10010 油类商品13日总的销售额和2020商店10030米和粉总的销售额
![]()
![]()
查询2021商店10088粮油类赠品的销售额
五、实验分析
本次实验主要对预处理后的数据构建数据立方体,并执行相应的OLAP操作。
采用pandas包中的DataFrame数据结构存储二维数据立方体。DataFrame结构有很多适合的操作和方法适用于数据立方体的构建和OLAP操作的实现。
在DataFrame中,每一个数据单元有两个索引,行索引(index)和列索引(columns),可按照任意索引读取1-D立方体,也可以按照两个索引读取基本方体。pandas包中同样有支持三维数据的panel结构,但是这一结构已经逐渐被弃用,所以对于三维立方体的构建,我仍然选择二维的DataFrame进行构建,将原本的三个2-D立方体连接。
OLAP操作则使用DataFrame.loc方法和Series.sum方法实现。