数据中台开源解决方案(一)
数据中台商业的解决方案有很多,开源框架种类繁多,每一个模块都有很多开源的套件。以查询引擎为例,可以使用的开源工具有MySQL、Redis、Impala、MongoDB、PgSQL等。可以根据实际业务需要,选择合适的开源套件。
可供选择的解决方案太多,重点推荐开源解决方案,框架图如下图所示。企业的数据应用主要有离线计算和实时计算。建议离线计算优先选择Hive和Spark。Spark是基于内存的。实时计算目前主流的选择是Flink框架。
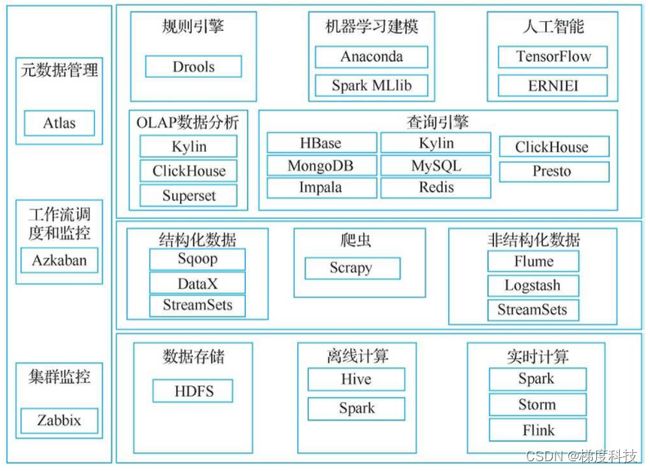
1.数据存储
互联网行业大数据的主流存储框架是基于Hadoop的分布式文件系统HDFS。由于其具有高容错性和适合批处理数据的特点,适合部署在低廉的PC服务器上存储海量的数据,数据存储的性价比较高。
2.离线计算
在HDFS的基础上,Hadoop生态又开发了离线数据仓库计算引擎Hive。Hive 基于MapReduce技术支持分布式批处理计算,同时支持以SQL操作的方式对存储在HDFS上的数据进行「类数据库」的操作、计算和统计分析。Hive 适合海量数据的批处理操作场景,操作简单,容错性和扩展性好,缺点是高延迟、查询和计算都比较慢,因此Hive被广泛应用在离线计算场景中,尤其是对海量数据的批处理操作和分析场景中。
因为基于MapReduce技术涉及磁盘间高频的I/O操作,所以Hive的计算效率较低,时效很长。为了提高计算的效率,Hive社区增加了新的计算引擎,即Spark。与MapReduce相比,Spark的RDD计算引擎基于内存进行计算,计算和查询效率显著提升。
目前,主流的离线计算框架采用Hive和Spark结合的方式。在100 个节点以下时,可以选用Hive作为数据仓库、Spark作为计算引擎。另外,对于海量数据场景(如节点数需要几百个甚至上千个时),Hive的优势是稳定性和容错性好,可以用于处理海量数据的复杂计算。Spark的优势是计算速度快,缺点是容易出现内存泄漏和不足,从而导致计算缓慢或者任务失败。在海量数据场景中,出于稳定的要求,Spark一般用于处理数据仓库上层的查询、计算和分析操作,而底层的操作由Hive完成。重点推荐使用Hive和Spark工具。
3.实时计算
开源的实时计算框架比较多,如Spark、Storm和Flink等。与Storm 相比,Spark的优势是用一个统一的框架和引擎支持批处理、流计算、查询、机器学习等功能。由于Spark的微批处理的设计机制,在处理流数据的时候,效率比Storm要低。整体而言, Spark 体系更加成熟, 易用性较好、社区文档和案例更加丰富,如果对于数据延迟要求是秒级,那么 Spark 更容易上手且能满足性能要求。
4.查询引擎
为了提高数据交互性查询的效率,在大数据时代根据不同的业务要求诞生了很多新的查询引擎,常见的查询引擎有HBase、Redis、MongoDB 等。按照大类划分,查询引擎可以分为SQL交互式查询引擎和NoSQL交互式查询引擎。HBase、Redis、MongoDB都属于NoSQL交互式查询引擎。
1)SQL交互式查询引擎
常用的SQL交互式查询引擎有Impala、Presto、ClickHouse、Kylin 等。Impala和Presto基于MPP架构,通过分布式查询引擎提高查询效率。ClickHouse、Kylin是目前主流的联机分析处理OLAP计算和查询引擎。Kylin 通过预计算机制,提前将客户经常查询的维度和指标设计好并进行预处理操作,以数据立方体模型(Cube)形式缓存,以便加快聚合操作和查询的速度,特别适合对海量数据的OLAP场景。由于需要提前将数据预处理好,Kylin需要消耗额外的空间,且无法高效支持随机的计算和查询。
ClickHouse 适合海量数据的大宽表(维度和指标较多的表)的灵活和随机的查询、过滤和聚合计算,写入和查询性能很好,而多表关联操作性能一般,尤其是多个数据量较大的表(即大表)关联的情况。其劣势是不擅长高频的修改和删除操作,在多用户高并发场景中性能一般。
Presto由Facebook开源,支持基于内存的并行计算,支持多个外部数据源和跨数据源的级联查询,在对单表的简单查询和多表关联方面性能较好,擅长进行实时的数据分析。在处理海量数据时,Presto对内存容量要求高,多个大表关联容易出现内存溢出。
Impala由Cloudera推出,是一个SQLon Hadoop的查询工具,也基于内存进行并行计算,目标是提供HDFS、HBase数据源复杂的高性能交互式查询。
2)NoSQL交互式查询引擎
HBase是基于key-value原理的列式查询引擎,适用于频繁进行插入操作且查询字段较多的场景,如统计每分钟每个商品的点击次数、收藏次数、购买次数等。HBase的列式扩展能力较强,理论上硬盘有多大,HBase 的存储能力就有多大。HBase不适用于大量更改(update)操作的场景。HBase的主要缺点是update操作性能较低。
Redis是内存数据库。Redis的原理是基于内存进行计算和查询。Redis 的存储容量与内存容量有关,支持的数据类型比较丰富,有一定的持久化能力,适用于高频 update 操作的场景,读写的速度都非常快。其缺点是内存容量有限,价格较高,一般用于存储非常有价值且需要高频读写的数据。比如,实时统计全站客户累计点击次数、收藏次数、购买次数等用于数据看板(dashboard)的展示。
MongoDB主要以JSON(JavaScript Object Notation)数据串格式存储数据,适用于表结构变化大的海量数据查询和聚合计算的场景,这是其区别于其他数据库的重要特色。比如,构建客户大宽表,客户的有关字段经常发生改变或增删,在这种场景中很适合用MongoDB存储并高效读取客户的单一维度信息或聚合信息。但是其写入操作和多表关联复杂操作性能一般,很少用于复杂的多表关联的计算场景。在实际应用中,一般会综合部署上述NoSQL引擎,满足不同的应用场景。
5.数据采集工具
开源的数据采集工具很多,如Sqoop、DataX、Scrapy、Flume、Logstash和StreamSets等。Sqoop和DataX主要用于采集结构化数据,Flume和Logstash主要用于采集非结构化数据。StreamSets同时支持结构化和非结构化数据的采集。
在结构化数据采集方面,与DataX相比,Sqoop的综合性能更好,社区更活跃,插件更丰富,使用更广泛。Logstash 更轻量,使用更简单,插件丰富,对技术要求不高,运维比较简单。Flume框架更复杂,偏重于数据传输过程中的安全,不会出现丢包的情况, 整体配置更复杂, 入门难度较高, 运维难度更高。StreamSets 通过可视化界面的拖、拽等操作实现数据的采集和传输,支持多种数据源,组件丰富,功能强大,简单易用,且内置监控组件,可以实时监控数据传输情况。