阅读论文——A cnn-rnn framework for crop yield prediction
Khaki S, Wang L, Archontoulis S V. A cnn-rnn framework for crop yield prediction[J]. Frontiers in Plant Science, 2020, 10: 1750. https://doi.org/10.3389/fpls.2019.01750
CNN-RNN 模型:一个使用卷积神经网络 (CNN) 和循环神经网络 (RNN) 的深度学习框架,用于基于环境数据和管理实践的作物产量预测。
其他流行的方法:回归树、随机森林 (RF)、多元回归、关联规则挖掘、人工神经网络、深度全连接神经网络 (DFNN) 和 LASSO和来预测作物产量。
新模型实现了各自平均收益率的 9% 和 8% 的均方根误差 (RMSE),大大优于所有其他经过测试的方法。
CNN-RNN 具有三个显着特征:
(1) 捕捉环境因素的时间依赖性和种子随时间的遗传改良,而无需其基因型信息。
(2) 展示了将产量预测推广到未经测试的环境的能力,而预测精度不会显着下降。
(3) 与反向传播方法相结合,该模型可以揭示天气条件、天气预报的准确性、土壤条件和管理实践能够在多大程度上解释作物产量的变化。
下一段为其他人的成就:
机器学习模型将输出(作物产量)视为输入变量(如天气成分和土壤条件)的隐式函数,随机森林能够很好地预测作物产量并且优于多元线性回归。随机森林预测芒果果实产量以响应不同灌溉制度下的供水,并发现随机森林适用于芒果产量预测,特别关注水管理。人工神经网络来近似非线性函数,以将玉米产量与天气、土壤和管理实践等输入变量联系起来。使用土壤和天气信息评估了玉米氮推荐工具的机器学习方法。逐步多元线性回归、投影追踪回归和人工神经网络,以根据土壤特性预测粮食产量。使用随机森林和多元线性回归等机器学习算法预测玉米产量和硝酸盐损失。使用数学优化模型计算的生物量来预测马铃薯产量。应用人工神经网络和多元线性回归基于遥感和气候数据估计冬小麦产量,发现人工神经网络模型优于多元线性回归。使用分段线性回归方法,基于遥感数据和其他地表参数预测玉米和大豆的产量。应用决策树和关联规则挖掘等多种机器学习方法对硬粒小麦的产量成分进行分类,结果表明关联规则挖掘方法在所有位置都获得了最佳性能。
深度神经网络模型来预测 2008 年至 2016 年间 2,247 个地点的玉米产量,优于套索、浅层神经网络和回归树。应用 CNN 和 RNN 根据一系列遥感图像预测大豆产量。金等人。(2019 年)利用 2006 年至 2015 年间卫星产品和气象数据集的优化输入变量开发了一种用于作物产量预测的深度神经网络模型。Wang等人。(2018)设计了一个深度学习框架来预测阿根廷的大豆作物产量,他们还通过迁移学习方法以较少的数据量预测巴西大豆的收成,取得了令人满意的结果。杨等人。(2019)研究了 CNN 使用遥感图像估计水稻产量的能力,发现 CNN 模型在整个成熟阶段提供了可靠的产量预测。Khaki 和 Khalilzadeh(2019 年)使用深度 CNN 预测美国和加拿大 1,560 个地点的玉米产量损失。
更深层次的模型更难训练,需要更先进的硬件和优化技术。例如,深度神经网络的损失函数具有极高的维度和非凸性,由于具有许多局部最优和鞍点,这使得该函数的优化更加困难。更深的网络也可能存在梯度消失问题,这可以通过使用残差快捷连接或网络的多个辅助头(损失函数)来缓解。
其他提高深度学习模型性能的技术:批量归一化 、dropout 和随机梯度下降 (SGD)。
混合 CNN-RNN 模型:由卷积神经网络 (CNN) 和递归神经网络 (RNN) 组成。
CNN 处理具有多种数组格式的数据,例如一维数据(信号和序列)、二维数据(图像)和三维数据(视频)。CNN 模型通常由多个卷积层和池化层以及几个全连接 (FC) 层组成。CNN 有一些设计参数,包括过滤器的数量、过滤器大小、填充类型和步幅。过滤器是我们对输入数据进行卷积的权重矩阵。填充是向输入添加零以保持输入空间维度的过程。步幅是过滤器移动的量。
RNN 用于涉及顺序数据的任务,以捕获它们的时间依赖性。RNN 将序列的所有过去元素的历史记录在称为状态向量的隐藏单元中,并在一次处理一个元素的输入序列时使用此信息。RNN 是非常强大的序列建模模型。
为了缓解梯度消失和爆炸问题,RNN 通过长短期记忆 (LSTM) 细胞(循环神经元)进行了改进。LSTM 单元使用称为记忆单元的特殊单元来长时间记住输入并防止梯度消失问题。
本文的其余部分安排如下。数据部分介绍了本文使用的数据。方法论部分描述了我们提出的作物产量预测模型。实验设计部分提供了本研究中使用的模型的实现细节。结果部分介绍了结果。分析部分提供了基于建议模型执行的分析。最后,结论部分总结了本文。
数据
四组数据:产量表现、管理、天气和土壤;
● 单产表现数据集包含 1980 年至 2018 年间玉米和大豆的平均单产,玉米带 13 个州的 1,176 个玉米县和 1,115 个大豆县:
● 管理数据包括各州每周累计种植面积百分比,从每年四月开始。产量表现和管理数据来自美国国家农业统计局(USDA-NASS,2019)。
● 天气数据包括降水量、太阳辐射量、雪水当量、最高气温、最低气温和水汽压6 个天气变量的日记录。天气数据来自 Daymet ( Thornton et al., 2018 )。气象数据的空间分辨率为1 km 2。
● 土壤数据包括湿土容重、干容重、粘土百分比、植物有效含水量上限、植物有效含水量下限、导水率、有机质百分比、pH、沙子百分比和饱和体积含水量在 0-5、5-10、10-15、15-30、30-45、45-60、60-80、80-100 和 100-120 cm 深度测量的变量。仅在土壤表面记录了四个土壤变量,包括以百分比表示的田间坡度、玉米的全国商品作物生产力指数、所有作物的全国商品作物平均生产力指数和作物根区深度。土壤数据来自美国网格化土壤调查地理数据库 ( gSSURGO, 2019 )。土壤数据的空间分辨率为1 km 2。
根据网格地图方法从每个县选择了多个天气和土壤样本,并对这些样本取平均值以获得天气和土壤的代表性样本。某些地点的土壤数据有 6.7% 的缺失值,我们使用其他县的相同土壤变量的平均值估算。部分地点的管理数据有 6.3% 的缺失值,我们使用同年其他县的相同管理变量的平均值估算。我们尝试了其他插补技术,例如中值和最频繁,发现均值方法产生最准确的结果。
天气数据没有任何缺失值,但每日数据比揭示基本信息所需的粒度更细。结果取每周的平均值,实现了 365:52 的降维比。这种天气数据的预处理大大减少了神经网络模型第一层的可训练参数的数量。
方法
混合模型:结合了 CNN、全连接层和 RNN
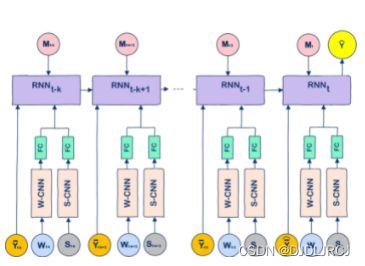
W-CNN 和 S-CNN
W-CNN 和 S-CNN 模型旨在分别捕捉天气和土壤数据的线性和非线性效应。W-CNN 模型使用一维卷积来捕捉天气数据的时间依赖性,而 S-CNN 模型使用一维卷积来捕捉在地下不同深度测量的土壤数据的空间依赖性。类似的卷积模型已广泛用于各种应用领域,并被发现可有效提高预测准确性(Ince 等人,2016 年;Borovykh 等人,2017 年;Kiranyaz 等人,2019 年)。
足球俱乐部
使用全连接层(FC)将W-CNN和S-CNN提取的天气成分和土壤条件的高级特征结合起来,这也降低了CNN模型的输出维度。
循环神经网络
RNN 模型旨在捕捉作物产量多年来的时间依赖性。RNN 模型的使用受到两个对比观察的推动。一方面,玉米单产和大豆单产在过去 40 年均呈现增长趋势。另一方面,基因型数据并未公开用于该预测研究。因此,基因型的影响必须使用可用数据间接反映在模型中。RNN 是一种人工神经网络,其中节点的时间依赖性通过有向图来反映。因此,我们设计了一个特殊的 RNN 模型来捕捉由于遗传改良而导致的作物产量的时间动态行为。这些 RNN 使用 LSTM 单元进行了增强,LSTM 单元是精心设计的循环神经元,用于捕获输入随时间的依赖性。与其他时间序列模型相比,Hochreiter 和 Schmidhuber,1997 年;Pham 等人,2014 年;舍斯廷斯基,2018 年)。
RNN 模型由k个 LSTM 单元组成,它使用从t - k年到t年的信息预测一个县在 t 年的作物产量。单元的输入包括平均产量(同一年所有县)数据、管理数据和 FC 层的输出,该层利用天气和土壤数据提取了 W-CNN 和 S-CNN 模型处理的重要特征。唯一的例外是 S-CNN 和 FC 模型专门设计用于将在土壤表面测量的土壤数据直接传递到 LSTM 单元。虽然土壤数据一般是静态的,但图2中土壤数据的下标允许随着时间的推移改变土壤条件。使用历史平均产量数据作为输入的一部分允许 RNN 模型使用作物产量的历史趋势预测作物产量,即使没有天气或土壤数据。假设t年是产量预测的目标年,那么在测试阶段,W t中未观测到的部分天气数据可以用预测的天气数据代替。然而,在训练阶段,这种替换是不必要的,因为所有输入数据都是可用的。
实验设计
使用超参数来训练 CNN-RNN 模型。
W-CNN 和 S-CNN 模型都有四个卷积层,其详细结构在补充材料的表 S2中提供。在 CNN 模型中,通过平均池化进行下采样,步幅为 2。W-CNN 的输出后面是一个全连接层,其中有 60 个神经元用于玉米产量预测,40 个神经元用于大豆产量预测。S-CNN 模型的输出之后是一个具有 40 个神经元的全连接层。RNN 层的时间长度为 5 年,因为我们考虑了 5 年的收益率依赖关系。RNN 层具有具有 64 个隐藏单元的 LSTM 单元。在尝试了不同的网络设计之后,我们发现这种架构可以提供最佳的整体性能。
所有权重均使用 Xavier 方法初始化(Glorot 和 Bengio,2010 年)。我们使用小批量大小为 25 的随机梯度下降 (SGD)。使用 Adam 优化器 ( Kingma and Ba, 2014 ),学习率为 0.03%,每 60,000 次迭代除以 2。该模型经过最多 350,000 次迭代的训练。我们对 CNN 和 FC 层使用了整流线性单元 (ReLU) 激活函数。输出层具有线性激活函数。所提出的模型是在 Python 中使用 Tensorflow 库 ( Abadi et al., 2016 ) 实现的,在 CPU (i7-4790, 3.6 GHz) 上训练时间大约需要一个小时。
补充材料中的图 S2显示了玉米和大豆产量预测的训练损失和验证损失图。
其他三种流行的预测模型:随机森林 (RF) ( Breiman, 2001 )、深度全连接神经网络 (DFNN) ( Khaki 和 Wang, 2019 ) 以及最小绝对收缩和选择算子 (LASSO) (蒂布希拉尼,1996 年):
● 随机森林是一种强大的非参数模型,它使用集成学习来避免过拟合。我们尝试了不同数量的树,发现 50 棵树的预测最准确。增加 RF 模型中的树数会增加训练时间,但不会提高结果的准确性。我们还尝试了不同数量的树的最大深度。我们发现树的最大深度等于 10 会导致最准确的预测。增加树的最大深度会导致过度拟合,而减小树的最大深度会导致预测精度低。
● 具有多个堆叠非线性层的DFNN 模型是一种强大的非线性模型。DFNN 模型有 9 层,每层有 50 个神经元,如Khaki 和 Wang (2019)。DFNN 模型使用最先进的深度学习技术,例如批量归一化(Ioffe 和 Szegedy,2015 年)和残差学习(He 等人,2016 年)来提高预测精度。我们尝试了不同数量的隐藏层,发现九个隐藏层导致了最准确的预测。
● LASSO 作为基准模型,比较土壤和天气数据在产量预测中的线性和非线性效应。尝试了 LASSO 模型中L 1项 ( Ng, 2004 )系数的不同值,我们发现 0.3 和 0.5 之间的值导致最准确的预测。
结果
将 2016 年、2017 年和 2018 年三年作为验证年,并预测了这些年玉米和大豆的产量。对于每个验证年,训练数据包括从 1980 年到相应验证年前一年的数据。表 1和表2比较了四种模型在训练和验证数据集上的表现,分别是玉米和大豆产量预测的 RMSE 和相关系数。表 3显示了验证年份的汇总统计数据。
混合 CNN-RNN 模型在不同程度上明显优于其他三个模型:
LASSO 的弱性能主要是由于其线性特性,无法捕捉土壤条件和天气成分的非线性效应。
DFNN 的表现优于 LASSO,因为 DFNN 能够捕捉环境成分的非线性效应。除了 2016 年玉米产量预测的验证 RMSE 之外,DFNN 与 RF 模型相比,在所有性能指标上都有更好的性能。除了用于玉米产量预测的 2017 年验证 RMSE 之外,RF 与 LASSO 相比,在所有性能指标方面表现出更好的性能。
除了 2016 年大豆产量预测的相关系数外,LASSO 与 RF 相比,在所有性能指标上都取得了更好的性能。CNN-RNN 模型在所有三个验证年的所有测量中都优于所有其他三个模型。CNN-RNN 可以有效地预测玉米和大豆的产量,其 RMSE 验证数据约为各自平均值的 9% 和 8%。
CNN-RNN 模型表现突出的原因如下:
(1)CNN-RNN 模型的 RNN 部分通过捕获产量的年度时间依赖性来考虑种子的遗传改良,
(2)W -CNN-RNN模型的CNN部分捕获了天气数据的内部时间依赖性,
(3)CNN-RNN模型的S-CNN部分考虑了在地下不同深度测量的土壤数据的空间依赖性,
(4) CNN-RNN 模型考虑了环境成分的非线性效应。
结果还表明,CNN-RNN 模型在所有验证年份的玉米和大豆产量预测中都具有一致的性能。为了检查各个县的产量预测误差,我们获得了 2018 年玉米和大豆产量预测的绝对预测误差。图 3分别显示了玉米和大豆的预测误差图。如图 3所示,大多数县的预测误差一直很低。
补充材料中的图 S3分别显示了玉米和大豆产量预测的 2018 年验证年的预测产量与实际产量的关系图。为了了解 CNN-RNN 模型是否可以保留地面实况收益率的一些分布特性,我们绘制了地面实况收益率的概率密度函数和 CNN-RNN 模型的预测收益率。如补充材料中的图 S4所示,CNN-RNN 模型可以近似地保留地面实况收益率的一些分布特性。
分析
特征选择
我们根据天气成分、土壤条件和管理实践等输入变量预测了作物产量。为了找到每个因素的相对重要性,我们基于训练好的 CNN-RNN 模型进行了特征选择。我们进行了两种特征选择,一种用于玉米,另一种用于大豆产量预测。我们使用引导反向传播方法反向传播正梯度以找到输入变量,从而最大限度地激活我们的目标神经元(Springenberg 等人,2014 年;Khaki 和 Wang,2019 年)。首先,我们将所有验证样本馈送到 CNN-RNN 模型,并计算在时间步t时 RNN 单元输出中所有神经元的平均激活. 我们设置激活神经元的梯度为 1,其他神经元的梯度为 0。然后,我们将激活神经元的梯度反向传播到输入空间,根据梯度的大小(越大,更重要)。
图4-8说明了天气成分的估计影响、在土壤表面和不同深度测量的土壤条件以及管理实践。对每一组的影响进行标准化,即天气成分、土壤条件和管理实践,以使影响具有可比性。
我们重要性分析的创新方面是时间分辨率,它允许识别关键时期,以更深入地了解复杂的农艺系统是如何工作的(图 4和5)。在这里检查的六个天气变量中,太阳辐射是玉米产量因素中最敏感的因素,而雪是最不敏感的因素。从农学角度来看这是合理的,因为辐射是光合作用以及随后的生物量生产和谷物产量的关键驱动因素(Sinclair 和 Horie,1989 年)。另一方面,雪水对土壤水分平衡有影响,降水和水汽亏缺也有影响(Ritchie,1998),这是比雪更重要的变量,因为它们对作物产量的影响持续时间更长,尤其是在夏季。雪在生长季节之前和之后有些重要,目前的分析很好地描述了这一点(图 4和图5)。辐射显示了两个采摘期(产量预测非常敏感的时期),一个在第 15 周左右,即作物种植之前,另一个在第 30 周左右,与最关键的玉米阶段(出丝期)相吻合。在吐丝期,每株植物的籽粒数是确定的,文献表明籽粒数(谷物产量的主要决定因素)与植物生长速率之间存在很强的关系,主要由光合作用驱动(Andrade 等,1999); 因此,当前的分析捕捉到了这一现象。最高温度在第 20 周左右的产量预测中最为敏感,这一时期通常与玉米种植(5 月 13 日)同时发生。从农艺学的角度来看,那个时期的温度非常重要,因为它会影响种子的发芽和出苗,通常高温会导致出苗快速且均匀,而低温会导致出苗缓慢且不均匀,从而影响植物生长产量。最低温度在第 22 周(5 月 30 日)和第 35 周(8 月 26 日)左右最为敏感。第 22 周的重要性与种子出苗的最高温度相同。有趣的是,该模型选择了灌浆期最低温度的重要性,众所周知,最低温度会影响玉米产量(Hatfield 和 Prueger,2015; Schauberger 等人,2017 年)。大豆也是如此,模型捕捉到了这一点。该分析的另一个有趣结果是在灌浆期(第 30 至 40 周)降水的重要性日益增加,这也与实验研究一致(Hatfield 等人,2011 年;Hatfield 等人,2018 年)。
在土壤变量方面(参见图 6和图7),我们的分析表明有几个因素对两种产量预测都很敏感。解释所有这些因素在农艺学上超出了本文的范围,但众所周知,所有这些因素都会影响作物的土壤水和氮供应,从而影响作物产量(Archontoulis 等人,2016 年)。
在播种日期方面,玉米产量预测在 4 月 20 日至 5 月 15 日前后最不敏感,这一时期被认为是玉米带地区玉米的最佳播种日期(Baum 等,2018)。从农艺学的角度来看,玉米产量在这个最佳范围之外下降,模型能够通过增加对种植日期的敏感性来捕捉这一事实。大豆得到了相反的结果,而模型在 5 月 15 日至 5 月底期间最为敏感,这被认为是大豆的最佳种植时间(Egli 和 Bruening,1992 年)。
为了评估特征选择方法的性能,我们获得了基于特征子集的预测结果。我们在 1980 年到 2016 年的数据上训练了 CNN-RNN 模型,并使用 2017 年的数据进行特征选择。最后,我们评估了特征选择方法在 2018 年产量预测中的性能。我们根据它们的估计效果对所有特征进行排序,并选择了 50% 和 75% 最重要的特征。表 4显示了使用这些选定特征的 CNN-RNN 模型的产量预测性能。与使用所有特征的 CNN-RNN 模型(100%)相比,CNN-RNN 模型的预测准确率没有显着下降,这表明特征选择方法可以成功找到重要特征。
环境与管理实践的重要性比较
为了比较天气成分、土壤条件和管理实践的个体重要性,我们使用以下模型进行了产量预测:
CNN-RNN(W):该模型使用 CNN-RNN 模型根据天气数据预测产量,而不使用土壤和管理数据。该模型仅捕获天气数据的线性和非线性效应。
CNN-RNN(S):该模型使用 CNN-RNN 模型根据土壤数据预测产量,而不使用天气和管理数据。该模型仅捕获土壤数据的线性和非线性效应。
CNN-RNN(M):该模型使用 CNN-RNN 模型根据管理数据预测产量,而不使用天气和土壤数据。该模型仅捕获管理数据的线性和非线性效应。
平均:该模型提供了一个仅使用平均产量进行预测的基准。
表 5比较了上述四种模型在玉米和大豆产量预测中的表现 CNN-RNN(W) 在玉米和大豆产量预测中表现出与 CNN-RNN(S) 相当的性能,并且它们的预测准确度显着高于CNN-RNN(M)。结果表明,天气和土壤是产量预测中同样重要的因素,并且比管理措施(种植日期)更多地解释了作物产量的变化。结果还表明,与玉米相比,种植日期对大豆的影响更大。
CNN-RNN 模型的泛化能力
为了检查模型将预测推广到从未测试过的位置的能力,我们从训练数据(1980-2017)中随机排除位置,并在剩余位置上训练 CNN-RNN 模型。然后,我们针对 2018 年产量预测的排除位置测试了该模型。我们使用 k 折交叉验证来估计所提出模型的泛化能力。2018 年可用地面实况产量的地点数量分别为 807 个和 684 个(玉米和大豆)。我们对具有 2018 年可用地面实况产量的位置进行了 5 折交叉验证,这导致玉米和大豆的每个折中分别有 163 和 140 个位置。
表 6显示了 CNN-RNN 模型对玉米和大豆产量预测的 5 倍交叉验证性能。如表 6所示,与表 1和表2中的相应结果相比,CNN-RNN 模型的预测精度没有显着下降,这表明 CNN-RNN 模型可以成功地将产量预测推广到未经测试的位置。补充材料中的图 S5显示了 CNN-RNN 模型在单个 100 个未测试位置上的性能。如补充材料中的图 S5所示,大多数未测试位置的预测误差始终较低。
使用预测天气数据进行产量预测
天气是预测作物产量的重要因素之一,但它是先验未知的. 因此,天气预报是作物产量预测中不可避免的一部分。为了评估天气预报对 CNN-RNN 模型性能的影响,我们使用预测的天气数据获得了 2018 年爱荷华州的产量预测结果。我们将 2017 年 6 月至 9 月的天气数据作为 2018 年相应时间段的预测天气数据。我们将使用完美天气数据的 CNN-RNN 模型的 RMSE 和预测状态平均产量与 RMSE 和预测的使用预测天气数据的 CNN-RNN 模型的状态平均产量。为了更好地了解天气预报对产量预测的影响,我们从 6 月到 9 月每周更新预测的天气数据及其对应的 2018 年地面实况天气数据,并获得每周的预测结果。如图所示如图 9 所示,我们每周用地面真实天气数据更新预测的天气数据越多,预测误差就越小,这表明产量预测对天气预测的敏感程度。结果还表明,完善的天气预报模型可以显着提高产量预测结果。
结论
在本文中,我们提出了一种基于深度学习的作物产量预测方法,该方法根据环境数据和管理实践准确预测了美国整个玉米带的玉米和大豆产量。最重要的是,我们的方法超越了预测,因为它提供了解释产量预测(按时间段变化的重要性)的关键结果。
所提出的方法明显优于其他流行的方法,如 LASSO、随机森林和 DFNN。所提出的模型是一种结合了 CNN 和 RNN 的混合模型。该模型的 CNN 部分旨在捕捉天气数据的内部时间依赖性以及在地下不同深度测量的土壤数据的空间依赖性。由于植物育种和管理实践的不断改进,模型的 RNN 部分旨在捕捉作物产量多年来的增长趋势。该模型的性能对许多变量相对敏感,包括天气、土壤和管理。所提出的模型成功地预测了未经测试的环境中的产量;因此,它可以用于未来的产量预测任务。
深度学习模型的主要限制之一是它们的黑盒属性。为了使所提出的模型更少黑盒并且更易于解释,使用反向传播方法在训练好的 CNN-RNN 模型的基础上进行特征选择。特征选择方法成功地估计了天气成分、土壤条件和管理变量的个体效应以及这些变量变得重要的时间段,这是本研究的一项创新。这种方法可以扩展到解决其他研究问题。例如,类似的方法可用于根据杂交品种与同一地点的其他杂交品种的相对表现,将其分类为低产或高产。