52_LSTM及简介,RNN单元的内部结构,LSTM单元的内部结构,原理,遗忘门,输入门,输出门,LSTM变体GRU,LSTM变体FC-LSTM,Pytorch LSTM API介绍,案例(学习笔记)
1.52.LSTM
1.52.1.LSTM简介
1.52.2.RNN单元的内部结构
1.52.3.LSTM单元的内部结构
1.52.4.原理
1.52.5.遗忘门
1.52.6.输入门
1.52.7.输出门
1.52.8.Intuitive Pipeline
1.52.9.LSTM变体GRU
1.52.10.LSTM变体FC-LSTM
1.52.11.Pytorch LSTM API介绍
1.52.11.1.nn.LSTM
1.52.11.2.nn.LSTMCell
1.52.12.案例1
1.52.13.演示实验代码2
1.52.14.以MNIST分类为例实现LSTM分类
1.52.15.词性标注案例(LSTM,jieba,Word2Vec)
1.52.16.GRU
1.52.17.参考博文
1.52.LSTM
为了解决传统RNN无法长时依赖问题,RNN的两个变体LSTM和GRU被引入。
LSTM是一种特殊的RNN,其引入状态量来保留历史信息,同时引入门的概念来更新状态量。
1.52.1.LSTM简介
Long Short Term Memory,称为长短期记忆网络,意思就是长的短时记忆,其解决的仍然是短时记忆问题,这种短时记忆比较长,能一定程度上解决长时依赖。

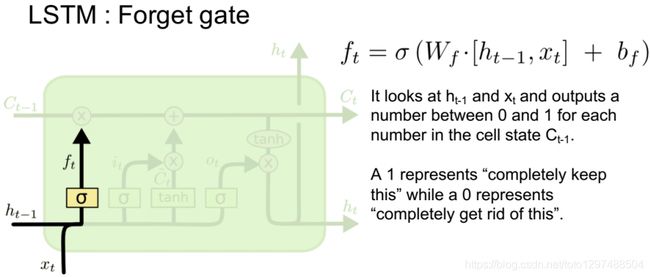
上图为LSTM的抽象结构,LSTM由3个门来控制,分别是输入门、遗忘门和输出门。输入门控制网络的输入,遗忘门控制着记忆单元,输出门控制着网络的输出。最为重要的就是遗忘门,可以决定哪些记忆被保留,由于遗忘门的作用,使得LSTM具有长时记忆的功能。对于给定的任务,遗忘门能够自主学习保留多少之前的记忆,网络能够自主学习。
1.52.2.RNN单元的内部结构
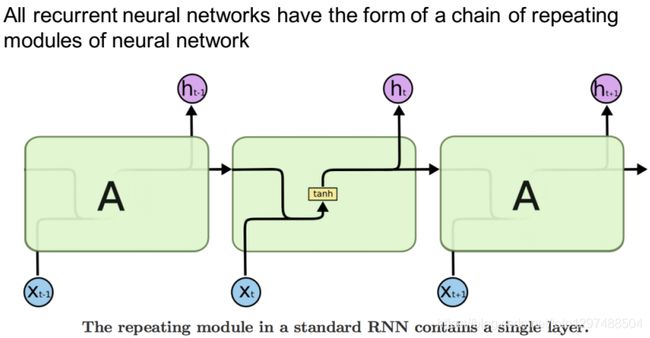
1.52.3.LSTM单元的内部结构
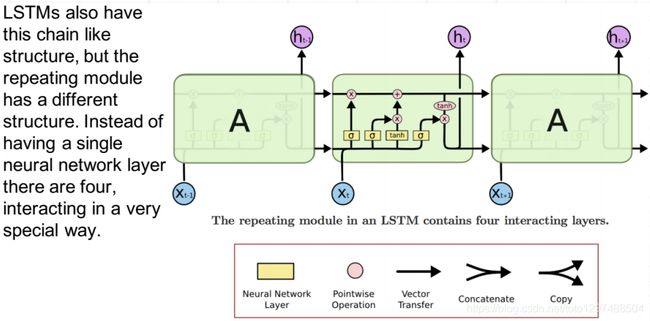




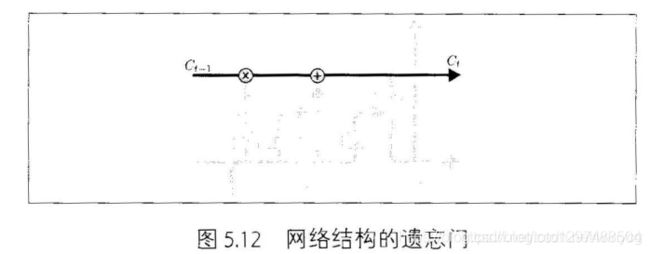
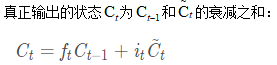


1.52.4.原理
RNN网络中历史信息在每个RNN单元,都经过tanh/ReLu,信息在逐渐流失;而LSTM,采用信息更新的方式,更容易将有用的信息传递下去,传得更远。也就是下图中C随序列传递的过程。

为了实现状态量C的旧状态删除、新状态更新、当前结果有用状态信息的提取,分别引入”遗忘门”、”输出门”三个结构。
门:使用前一个输出,结合当前输入,通过sigmoid函数,得到输出值,在0~1之间,决定信息量各部分被遗忘/选择的程度。
1.52.5.遗忘门
![]()
1.52.6.输入门
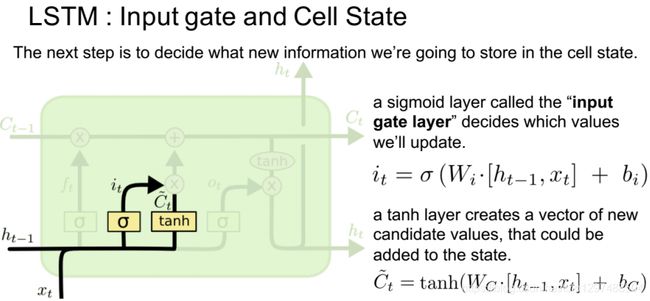
输入门挑选信息来更新状态量C。

1.52.7.输出门
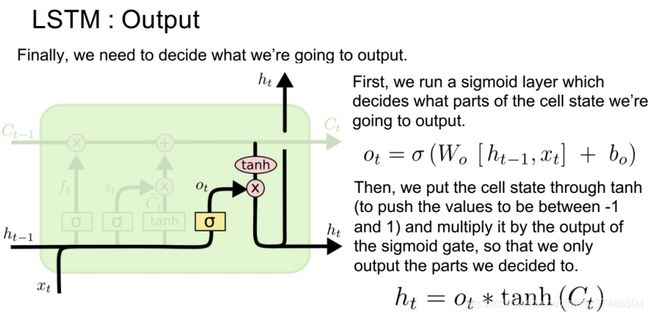
输出门挑选更新后的状态量C。
1.52.8.Intuitive Pipeline
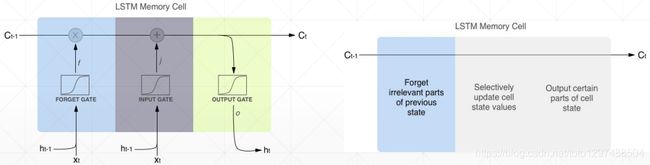 http://harinisuresh.com/2016/10/09/lstms/
http://harinisuresh.com/2016/10/09/lstms/

http://www.cs.toronto.edu/~rgrosse/courses/csc321_2017/readings/L15%20Exploding%20and%20Vanishing%20Gradients.pdf


https://weberna.github.io/blog/2017/11/15/LSTM-Vanishing-Gradients.html
http://www.cs.toronto.edu/~rgrosse/courses/csc321_2017/readings/L15%20Exploding%20and%20Vanishing%20Gradients.pdf
1.52.9.LSTM变体GRU

1.52.10.LSTM变体FC-LSTM

1.52.11.Pytorch LSTM API介绍
1.52.11.1.nn.LSTM
__init__

LSTM.forward()

class torch.nn.LSTM(*args, **kwargs)
参数列表:
input_size: x的特征维度。
hidden_size: 隐藏层的特征维度。
num_layers: lstm隐层的层数,默认为1
bias: False则bih=0和bhh=0,默认为True
batch_first: True则输入输出的数据格式为(batch,seq,feature)
dropout: 除最后一层,每一层的输出都进行dropout,默认为0
bidirectional: True则为双向lstm默认为False。
输入:input,(h_0, c_0)
输出:output,(h_n, c_n)
在Pytorch中使用nn.LSTM()可调用,参数和RNN的参数相同。具体介绍LSTM的输入和输出:
输入: input, (h_0, c_0)
input:输入数据with维度(seq_len,batch,input_size)
h_0:维度为(num_layers*num_directions,batch,hidden_size),在batch中的初始的隐藏状态.
c_0:初始的单元状态,维度与h_0相同
Pytorch里的LSTM单元接受的输入都必须是3维的张量(Tensors).每一维代表的意思不能弄错。
第一维体现的是序列(sequence)结构,也就是序列的个数,用文章来说,就是每个句子的长度,因为是喂给网络模型,一般都设定为确定的长度,也就是我们喂给LSTM神经元的每个句子的长度,当然,如果是其他的带有带有序列形式的数据,则表示一个明确分割单位长度,
例如是如果是股票数据内,这表示特定时间单位内,有多少条数据。这个参数也就是明确这个层中有多少个确定的单元来处理输入的数据。
第二维度体现的是batch_size,也就是一次性喂给网格多少条句子,或者股票数据中的,一次性喂给模型多少个时间单位的数据,具体到每个时刻,也就是一次性喂给特定时刻处理的单元的单词数或者该时刻应该喂给的股票数据的条数。
第三位体现的是输入的元素(elements of input),也就是,每个具体的单词用多少维向量来表示,或者股票数据中 每一个具体的时刻的采集多少具体的值,比如最低价,最高价,均价,5日均价,10均价,等等
输出:output, (h_n, c_n)
output:维度为(seq_len, batch, num_directions * hidden_size)。
h_n:最后时刻的输出隐藏状态,维度为 (num_layers * num_directions, batch, hidden_size)
c_n:最后时刻的输出单元状态,维度与h_n相同。

nn.LSTM案例
# -*- coding: UTF-8 -*-
import torch
import torch.nn as nn
lstm = nn.LSTM(input_size=100, hidden_size=20, num_layers=4)
print(lstm)
x = torch.randn(10, 3, 100)
out, (h, c) = lstm(x)
print(out.shape, h.shape, c.shape)
"""
输出结果:
LSTM(100, 20, num_layers=4)
torch.Size([10, 3, 20]) torch.Size([4, 3, 20]) torch.Size([4, 3, 20])
"""
1.52.11.2.nn.LSTMCell
LSTMCell.forward()

Single layer
# -*- coding: UTF-8 -*-
import torch
import torch.nn as nn
x = torch.randn(10, 3, 100)
print('one layer lstm')
cell = nn.LSTMCell(input_size=100, hidden_size=20)
h = torch.zeros(3, 20)
c = torch.zeros(3, 20)
for xt in x:
h, c = cell(xt, [h, c])
print(h.shape, c.shape)
"""
输出结果:
one layer lstm
torch.Size([3, 20]) torch.Size([3, 20])
"""
Two Layers
# -*- coding: UTF-8 -*-
import torch
import torch.nn as nn
x = torch.randn(10, 3, 100)
print('two layer lstm')
cell1 = nn.LSTMCell(input_size=100, hidden_size=30)
cell2 = nn.LSTMCell(input_size=30, hidden_size=20)
h1 = torch.zeros(3, 30)
c1 = torch.zeros(3, 30)
h2 = torch.zeros(3, 20)
c2 = torch.zeros(3, 20)
for xt in x:
h1, c1 = cell1(xt, [h1, c1])
h2, c2 = cell2(h1, [h2, c2])
print(h2.shape, c2.shape)
"""
输出结果:
two layer lstm
torch.Size([3, 20]) torch.Size([3, 20])
"""
1.52.12.案例1
# -*- coding: utf-8 -*-
"""lstm
Automatically generated by Colaboratory.
Original file is located at
https://colab.research.google.com/drive/1GX0Rqur8T45MSYhLU9MYWAbycfLH4-Fu
"""
!pip install torch
!pip install torchtext
!python -m spacy download en
# K80 gpu for 12 hours
import torch
from torch import nn, optim
from torchtext import data, datasets
print('GPU:', torch.cuda.is_available())
torch.manual_seed(123)
TEXT = data.Field(tokenize='spacy')
LABEL = data.LabelField(dtype=torch.float)
train_data, test_data = datasets.IMDB.splits(TEXT, LABEL)
print('len of train data:', len(train_data))
print('len of test data:', len(test_data))
print(train_data.examples[15].text)
print(train_data.examples[15].label)
# word2vec, glove
TEXT.build_vocab(train_data, max_size=10000, vectors='glove.6B.100d')
LABEL.build_vocab(train_data)
batchsz = 30
device = torch.device('cuda')
train_iterator, test_iterator = data.BucketIterator.splits(
(train_data, test_data),
batch_size = batchsz,
device=device
)
class RNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim):
"""
"""
super(RNN, self).__init__()
# [0-10001] => [100]
self.embedding = nn.Embedding(vocab_size, embedding_dim)
# [100] => [256]
self.rnn = nn.LSTM(embedding_dim, hidden_dim, num_layers=2,
bidirectional=True, dropout=0.5)
# [256*2] => [1]
self.fc = nn.Linear(hidden_dim*2, 1)
self.dropout = nn.Dropout(0.5)
def forward(self, x):
"""
"""
# [seq, b, 1] => [seq, b, 100]
embedding = self.dropout(self.embedding(x))
# output: [seq, b, hid_dim*2]
# hidden/h: [num_layers*2, b, hid_dim]
# cell/c: [num_layers*2, b, hid_di]
output, (hidden, cell) = self.rnn(embedding)
# [num_layers*2, b, hid_dim] => 2 of [b, hid_dim] => [b, hid_dim*2]
hidden = torch.cat([hidden[-2], hidden[-1]], dim=1)
# [b, hid_dim*2] => [b, 1]
hidden = self.dropout(hidden)
out = self.fc(hidden)
return out
rnn = RNN(len(TEXT.vocab), 100, 256)
pretrained_embedding = TEXT.vocab.vectors
print('pretrained_embedding:', pretrained_embedding.shape)
rnn.embedding.weight.data.copy_(pretrained_embedding)
print('embedding layer inited.')
optimizer = optim.Adam(rnn.parameters(), lr=1e-3)
criteon = nn.BCEWithLogitsLoss().to(device)
rnn.to(device)
import numpy as np
def binary_acc(preds, y):
"""
get accuracy
"""
preds = torch.round(torch.sigmoid(preds))
correct = torch.eq(preds, y).float()
acc = correct.sum() / len(correct)
return acc
def train(rnn, iterator, optimizer, criteon):
avg_acc = []
rnn.train()
for i, batch in enumerate(iterator):
# [seq, b] => [b, 1] => [b]
pred = rnn(batch.text).squeeze(1)
#
loss = criteon(pred, batch.label)
acc = binary_acc(pred, batch.label).item()
avg_acc.append(acc)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i%10 == 0:
print(i, acc)
avg_acc = np.array(avg_acc).mean()
print('avg acc:', avg_acc)
def eval(rnn, iterator, criteon):
avg_acc = []
rnn.eval()
with torch.no_grad():
for batch in iterator:
# [b, 1] => [b]
pred = rnn(batch.text).squeeze(1)
loss = criteon(pred, batch.label)
acc = binary_acc(pred, batch.label).item()
avg_acc.append(acc)
avg_acc = np.array(avg_acc).mean()
print('>>test:', avg_acc)
for epoch in range(10):
eval(rnn, test_iterator, criteon)
train(rnn, train_iterator, optimizer, criteon)
1.52.13.演示实验代码2
# -*- coding: UTF-8 -*-
import torch
from torch import nn
import numpy as np
class Rnn(nn.Module):
def __init__(self, INPUT_SIZE):
super(Rnn, self).__init__()
self.rnn = nn.LSTM(
input_size=INPUT_SIZE,
hidden_size=32,
num_layers=2,
bias=True,
batch_first=True,
dropout=0,
bidirectional=False
)
self.out = nn.Linear(32, 1)
def forward(self, x, hc_state):
# input(x): batch, seq_len, input_size = 1, 10, 2
# output(r_out): batch, seq_len, hidden_size * num_directions = 1, 10, 32*1
r_out, hc_state = self.rnn(x, hc_state)
outs = []
for time in range(r_out.size(1)):
outs.append(self.out(r_out[:, time, :]))
return torch.stack(outs, dim=1), hc_state
# 定义一些超参
TIME_STEP = 10
INPUT_SIZE = 2
LR = 0.02
# "看"数据
# plt.plot(steps, y_np, 'r-', label='target(cos)')
# plt.plot(steps, x_np, 'b-', label='input(sin)')
# plt.legend(loc='best')
# plt.show()
# 选择模型
model = Rnn(INPUT_SIZE)
print(model)
# 定义优化器和损失函数
loss_func = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=LR)
h_state = torch.autograd.Variable(
torch.zeros(2, 1, 32)) # h0/c0: num_layers * num_directions, batch, hidden_size = 2*1, 1, 32
c_state = torch.autograd.Variable(torch.zeros(2, 1, 32)) # 第一次的时候,暂存为0
for step in range(300):
start, end = step * np.pi, (step + 1) * np.pi
steps = np.linspace(start, end, TIME_STEP, dtype=np.float32)
x_np = np.sin(steps)
y_np = np.cos(steps)
x = torch.from_numpy(x_np[np.newaxis, :, np.newaxis])
y = torch.from_numpy(y_np[np.newaxis, :, np.newaxis])
# 为了演示,重复x将输入数据特征扩展为两维
prediction, (h_state, c_state) = model(torch.cat((x, x), 2), (h_state, c_state))
h_state = h_state.data
c_state = c_state.data
loss = loss_func(prediction, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print("x:")
print(x)
print("y:")
print(y)
print("predict:")
print(prediction)
输出结果:
Rnn(
(rnn): LSTM(2, 32, num_layers=2, batch_first=True)
(out): Linear(in_features=32, out_features=1, bias=True)
)
x:
tensor([[[ 2.1783e-05],
[-3.4199e-01],
[-6.4281e-01],
[-8.6604e-01],
[-9.8481e-01],
[-9.8481e-01],
[-8.6602e-01],
[-6.4279e-01],
[-3.4203e-01],
[-1.2874e-05]]])
y:
tensor([[[-1.0000],
[-0.9397],
[-0.7660],
[-0.5000],
[-0.1736],
[ 0.1737],
[ 0.5000],
[ 0.7660],
[ 0.9397],
[ 1.0000]]])
predict:
tensor([[[-0.9952],
[-0.9373],
[-0.7687],
[-0.4961],
[-0.1764],
[ 0.1734],
[ 0.5018],
[ 0.7659],
[ 0.9358],
[ 1.0058]]], grad_fn=<StackBackward>)
1.52.14.以MNIST分类为例实现LSTM分类
MNIST图片大小为28 * 28,可以将每张图片看做是长为28的序列,序列中每个元素的特征维度为28。将最后输出的隐藏状态ht作为抽象的隐藏特征输入到全连接层进行分类。最后输出的导入头文件:
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
from torchvision import transforms
class Rnn(nn.Module):
def __init__(self, in_dim, hidden_dim, n_layer, n_classes):
super(Rnn, self).__init__()
self.n_layer = n_layer
self.hidden_dim = hidden_dim
self.lstm = nn.LSTM(in_dim, hidden_dim, n_layer, batch_first=True)
self.classifier = nn.Linear(hidden_dim, n_classes)
def forward(self, x):
out, (h_n, c_n) = self.lstm(x)
# 此时可以从out中获得最终输出的状态h
# x = out[:, -1, :]
x = h_n[-1, :, :]
x = self.classifier(x)
return x
训练和测试代码:
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5]),
])
trainset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True)
testset = torchvision.datasets.MNIST(root='./data', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=100, shuffle=False)
net = Rnn(28, 10, 2, 10)
net = net.to('cpu')
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.1, momentum=0.9)
# Training
def train(epoch):
print('\nEpoch: %d' % epoch)
net.train()
train_loss = 0
correct = 0
total = 0
for batch_idx, (inputs, targets) in enumerate(trainloader):
inputs, targets = inputs.to('cpu'), targets.to('cpu')
optimizer.zero_grad()
outputs = net(torch.squeeze(inputs, 1))
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
train_loss += loss.item()
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
print(batch_idx, len(trainloader), 'Loss: %.3f | Acc: %.3f%% (%d/%d)'
% (train_loss/(batch_idx+1), 100.*correct/total, correct, total))
def test(epoch):
global best_acc
net.eval()
test_loss = 0
correct = 0
total = 0
with torch.no_grad():
for batch_idx, (inputs, targets) in enumerate(testloader):
inputs, targets = inputs.to('cpu'), targets.to('cpu')
outputs = net(torch.squeeze(inputs, 1))
loss = criterion(outputs, targets)
test_loss += loss.item()
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
print(batch_idx, len(testloader), 'Loss: %.3f | Acc: %.3f%% (%d/%d)'
% (test_loss/(batch_idx+1), 100.*correct/total, correct, total))
for epoch in range(200):
train(epoch)
test(epoch)
输出结果:
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz to ./data\MNIST\raw\train-images-idx3-ubyte.gz
99%|█████████▉| 9846784/9912422 [00:20<00:00, 459422.31it/s]Extracting ./data\MNIST\raw\train-images-idx3-ubyte.gz to ./data\MNIST\raw
Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz to ./data\MNIST\raw\train-labels-idx1-ubyte.gz
0it [00:00, ?it/s]
0%| | 0/28881 [00:00<?, ?it/s]Extracting ./data\MNIST\raw\train-labels-idx1-ubyte.gz to ./data\MNIST\raw
Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz to ./data\MNIST\raw\t10k-images-idx3-ubyte.gz
0it [00:00, ?it/s]
0%| | 0/1648877 [00:00<?, ?it/s]
1%| | 16384/1648877 [00:00<00:10, 157293.84it/s]
4%|▍ | 73728/1648877 [00:00<00:08, 190069.53it/s]
9%|▉ | 147456/1648877 [00:00<00:06, 243820.22it/s]
14%|█▍ | 229376/1648877 [00:00<00:04, 308867.34it/s]
18%|█▊ | 303104/1648877 [00:01<00:03, 371035.22it/s]
25%|██▍ | 409600/1648877 [00:01<00:02, 455352.87it/s]
38%|███▊ | 622592/1648877 [00:01<00:01, 595166.32it/s]
53%|█████▎ | 876544/1648877 [00:01<00:01, 771295.72it/s]
81%|████████ | 1335296/1648877 [00:01<00:00, 1026424.47it/s]Extracting ./data\MNIST\raw\t10k-images-idx3-ubyte.gz to ./data\MNIST\raw
Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz to ./data\MNIST\raw\t10k-labels-idx1-ubyte.gz
0it [00:00, ?it/s]
0%| | 0/4542 [00:00<?, ?it/s]Extracting ./data\MNIST\raw\t10k-labels-idx1-ubyte.gz to ./data\MNIST\raw
Processing...
D:\installed\Anaconda3\lib\site-packages\torchvision\datasets\mnist.py:480: UserWarning: The given NumPy array is not writeable, and PyTorch does not support non-writeable tensors. This means you can write to the underlying (supposedly non-writeable) NumPy array using the tensor. You may want to copy the array to protect its data or make it writeable before converting it to a tensor. This type of warning will be suppressed for the rest of this program. (Triggered internally at ..\torch\csrc\utils\tensor_numpy.cpp:141.)
return torch.from_numpy(parsed.astype(m[2], copy=False)).view(*s)
Done!
32768it [00:03, 10112.94it/s]
1654784it [00:02, 615868.70it/s]
8192it [00:01, 8065.27it/s]
Epoch: 0
0 469 Loss: 2.333 | Acc: 4.688% (6/128)
1 469 Loss: 2.313 | Acc: 6.250% (16/256)
2 469 Loss: 2.307 | Acc: 7.292% (28/384)
3 469 Loss: 2.310 | Acc: 9.180% (47/512)
4 469 Loss: 2.310 | Acc: 9.375% (60/640)
5 469 Loss: 2.313 | Acc: 9.896% (76/768)
XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
239 469 Loss: 0.190 | Acc: 94.447% (29014/30720)
240 469 Loss: 0.190 | Acc: 94.447% (29135/30848)
241 469 Loss: 0.189 | Acc: 94.457% (29259/30976)
242 469 Loss: 0.189 | Acc: 94.470% (29384/31104)
243 469 Loss: 0.189 | Acc: 94.474% (29506/31232)
244 469 Loss: 0.189 | Acc: 94.480% (29629/31360)
245 469 Loss: 0.189 | Acc: 94.480% (29750/31488)
246 469 Loss: 0.189 | Acc: 94.471% (29868/31616)
247 469 Loss: 0.189 | Acc: 94.475% (29990/31744)
248 469 Loss: 0.189 | Acc: 94.468% (30109/31872)
249 469 Loss: 0.189 | Acc: 94.475% (30232/32000)
250 469 Loss: 0.189 | Acc: 94.472% (30352/32128)
251 469 Loss: 0.189 | Acc: 94.475% (30474/32256)
252 469 Loss: 0.189 | Acc: 94.479% (30596/32384)
1.52.15.词性标注案例(LSTM,jieba,Word2Vec)
就是训练网络帮我们标注词性,当然实际的自然语言处理我们有很多成功的算法,但是应对新词总会有点麻烦,我们想啊,既然网络可以帮我们做了很多神奇的事,那么我们可不可以训练一个网络模型来帮我们自动的标注词性呢,显然这个思路靠谱,使用神经网络的套路:
准备训练数据,这一步最是头大的,最好的办法就是找各大机构提供的标准的标注库,实在找不到,自己处理,国内外很多的分词标准库和工具可以用,jieba分词标注是一个不错的选择,使用起来也简单。
读取数据文件
分词
把词语和标注分别放在两个数组里面
构建词汇表、构建标注表
把分词结果转换成对应词汇表和标签表中的序号。
构建网络模型,这里使用Word2Vec预处理一下输入文本
训练网络
分析结果
下面按照这个套路上源码:
# -*- coding: UTF-8 -*-
'''
转自:https://zhuanlan.zhihu.com/p/41261640
'''
'''
pip install jieba | pip3 install jieba | easy_install jieba
'''
import jieba.posseg
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# import sys
'''
处理语料
pip install gensim
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple gensim
'''
import gensim
torch.manual_seed(2)
# sys.stdout = open('1.log', 'a')
# sys.stdout = open('1.log', 'a')
sent = '明天是荣耀运营十周年纪念日。' \
'荣耀从两周年纪念日开始,' \
'在每年的纪念日这天凌晨零点会开放一个新区。' \
'第十版账号卡的销售从三个月前就已经开始。' \
'在老区玩的不顺心的老玩家、准备进入荣耀的新手,都已经准备好了新区账号对这个日子翘首以盼。' \
'陈果坐到了叶修旁边的机器,随手登录了她的逐烟霞。' \
'其他九大区的玩家人气并没有因为第十区的新开而降低多少,' \
'越老的区越是如此,实在是因为荣耀的一个账号想经营起来并不容易。' \
'陈果的逐烟霞用了五年时间才在普通玩家中算是翘楚,哪舍得轻易抛弃。' \
'更何况到最后大家都会冲着十大区的共同地图神之领域去。'
words = jieba.posseg.cut(sent, HMM=True) # 分词
processword = []
tagword = []
for w in words:
processword.append(w.word)
tagword.append(w.flag)
# 词语和对应的词性做一一对应
texts = [(processword, tagword)]
# 使用gensim构建本例的词汇表
id2word = gensim.corpora.Dictionary([texts[0][0]])
# 每个词分配一个独特的ID
word2id = id2word.token2id
# 使用gensim构建本例的词性表
id2tag = gensim.corpora.Dictionary([texts[0][1]])
# 为每个词性分配ID
tag2id = id2tag.token2id
def sen2id(inputs):
return [word2id[word] for word in inputs]
def tags2id(inputs):
return [tag2id[word] for word in inputs]
# 根据词汇表把文本输入转换成对应的词汇表的序号张量
def formart_input(inputs):
return torch.tensor(sen2id(inputs), dtype=torch.long)
# 根据词性表把文本标注输入转换成对应的词汇标注的张量
def formart_tag(inputs):
return torch.tensor(tags2id(inputs), dtype=torch.long)
# 定义网络结构
class LSTMTagger(torch.nn.Module):
def __init__(self, embedding_dim, hidden_dim, voacb_size, target_size):
super(LSTMTagger, self).__init__()
self.embedding_dim = embedding_dim
self.hidden_dim = hidden_dim
self.voacb_size = voacb_size
self.target_size = target_size
# 使用Word2Vec预处理一下输入文本
self.embedding = nn.Embedding(self.voacb_size, self.embedding_dim)
# LSTM 以word_embeddings作为输入, 输出维度为 hidden_dim 的隐状态值
self.lstm = nn.LSTM(self.embedding_dim, self.hidden_dim)
# 线性层将隐状态空间映射到标注空间
self.out2tag = nn.Linear(self.hidden_dim, self.target_size)
self.hidden = self.init_hidden()
def init_hidden(self):
# 开始时刻, 没有隐状态
# 关于维度设置的详情,请参考 Pytorch 文档
# 各个维度的含义是 (Seguence, minibatch_size, hidden_dim)
return (torch.zeros(1, 1, self.hidden_dim),
torch.zeros(1, 1, self.hidden_dim))
def forward(self, inputs):
# 预处理文本转成稠密向量
embeds = self.embedding((inputs))
# 根据文本的稠密向量训练网络
out, self.hidden = self.lstm(embeds.view(len(inputs), 1, -1), self.hidden)
# 做出预测
tag_space = self.out2tag(out.view(len(inputs), -1))
tags = F.log_softmax(tag_space, dim=1)
return tags
model = LSTMTagger(10, 10, len(word2id), len(tag2id))
loss_function = nn.NLLLoss()
optimizer = optim.SGD(model.parameters(), lr=0.1)
# 看看随机初始化网络的分析结果
with torch.no_grad():
input_s = formart_input(texts[0][0])
print(input_s)
print(processword)
tag_s = model(input_s)
for i in range(tag_s.shape[0]):
print(tag_s[i])
# print(tag_s)
for epoch in range(300):
# 再说明下, 实际情况下你不会训练300个周期, 此例中我们只是构造了一些假数据
for p, t in texts:
# Step 1. 请记住 Pytorch 会累加梯度
# 每次训练前需要清空梯度值
model.zero_grad()
# 此外还需要清空 LSTM 的隐状态
# 将其从上个实例的历史中分离出来
# 重新初始化隐藏层数据,避免受之前运行代码的干扰,如果不重新初始化,会有报错。
model.hidden = model.init_hidden()
# Step 2. 准备网络输入, 将其变为词索引的Tensor 类型数据
sentence_in = formart_input(p)
tags_in = formart_tag(t)
# Step 3. 前向传播
tag_s = model(sentence_in)
# Step 4. 计算损失和梯度值, 通过调用 optimizer.step() 来更新梯度
loss = loss_function(tag_s, tags_in)
loss.backward()
print('Loss:', loss.item())
optimizer.step()
# 看看训练后的结果
with torch.no_grad():
input_s = formart_input(texts[0][0])
tag_s = model(input_s)
for i in range(tag_s.shape[0]):
print(tag_s[i])
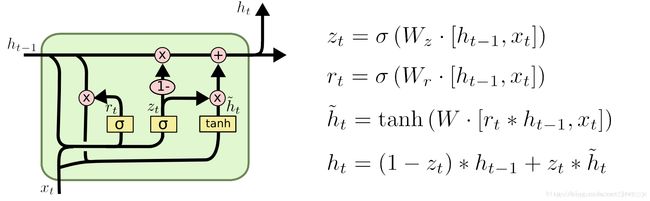
1.52.16.GRU

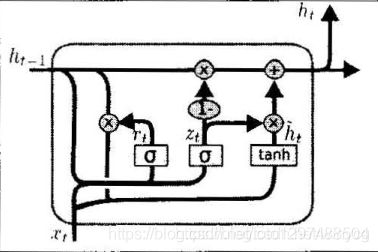
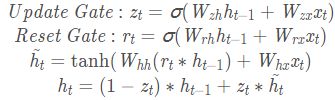
上述的过程的线性变换没有使用偏置。隐藏状态参数不再是标准RNN的4倍,而是3倍,也就是GRU的参数要比LSTM的参数量要少,但是性能差不多。
1.52.17.参考博文
http://blog.ziyouman.cn/?id=85
https://blog.csdn.net/winycg/article/details/88937583
https://zhuanlan.zhihu.com/p/144132609
https://zhuanlan.zhihu.com/p/41261640
https://cloud.tencent.com/developer/article/1072464?from=information.detail.pytorch%E5%AE%9E%E7%8E%B0lstm
https://blog.csdn.net/qq_36652619/article/details/88085828
http://t.zoukankan.com/jiangkejie-p-10600185.html