C/C++ 指针详解
指针详解
参考视频:https://www.bilibili.com/video/BV1bo4y1Z7xf/,感谢Bilibili@fengmuzi2003的搬运翻译及后续勘误,也感谢已故原作者Harsha Suryanarayana的讲解,RIP。
学习完之后,回看找特定的知识点,善用目录 —>
笔者亲测实验编译器版本:
gcc版本
gcc (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Copyright © 2017 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
指针的基本介绍
数据在内存中的存储与访问
在内存中,每一字节(8位)有一个地址。假设图中最下面的内存地址位0,内存地址向上生长,图中标识出的(下面)第一个字节的地址位201,地址向上生长一直到图中最上面的地址208。

当我们在程序中声明一个变量时,如int a,系统会为这个变量分配一些内存空间,具体分配多少空间则取决于该变量的数据类型和具体的编译器。常见的有int类型4字节,char类型1字节,float类型4字节等。其他的内建数据类型或用户定义的结构体和类的大小,可通过sizeof来查看。
我们声明两个变量:
int a;
char c;
假如他们分别被分配到内存的204-207字节和209字节。则在程序中会有一张查找表(图中右侧),表中记录的各个条目是变量名,变量类型和变量的首地址。
当我们为变量赋值时,如a = 5,程序就会先查到 a 的类型及其首地址,然后到这个地址把其中存放的值写为 5。
指针概念
我们能不能在程序中直接查看或者访问内存地址呢?当然是可以的,这就用到我们今天的主角——指针。
指针是一个变量,它存放的是另一个变量的地址。

- 指针与它指向的变量 假设我们现在有一个整型变量
a=4存放在内存中的204地址处(实际上应该是204-207四个字节中,这里我们用首地址204表示)。在内存中另外的某个地址处,我们有另外一个变量p,它的类型是“指向整型的指针”,它的值为204,即整型变量a的地址,这里的p就是指向整型变量a的指针。 - 指针所占的内存空间 指针作为一种变量也需要占据一定的内存空间。由于指针的值是一个内存地址,所以指针所占据的内存空间的大小与其指向的数据类型无关,而与当前机器类型所能寻址的位数有关。具体来说,在32位的机器上,一个指针(指向任意类型)的大小为4个字节,在64位的机器上则为8个字节。
- 指针的修改 我们可以通过修改指针
p的值,来使它指向其他的内存地址。比如我们将p的值修改为 208,则可以使它指向存放在208地址处的另一个整型变量b。 - 指向用户定义的数据类型 除了内建的数据类型之外,指针也可以指向用户定义的结构体或者类。
指针的声明和引用
-
指针的声明 在C语言中,我们通过
*来声明一个指向某种数据类型的指针:int *p。这个声明的含义即:声明一个指针变量p,它指向一个整型变量。换句话说,p是一个可以存放整型变量的地址的变量。 -
取地址 如果我们想指定
p指向某一个具体的整型变量a,我们可以:p = &a。其中用到了取地址运算符&,它得到的是一个变量的地址,我们把这个地址赋值给p,即使得p指向该地址。这时,如果我们打印
p, &a, &p的值会得到什么呢?不难理解,应该分别是204,204,64。 -
解引用 如果我们想得到一个指针变量所指向的地址存放的值,该怎么办呢?还是用
*放在指针变量p前面,即*p注意这里的*就不再是声明指针的意思了,而称为 解引用,即把p所指向的对象的值读出来。 所以如果我们打印*p,则会得到其所指向的整型变量a的值:5。实际上,我们还可以通过解引用直接改变某个地址的值。比如
*p = 8,我们就将204地址处的整型变量的值赋为8。此时再打印*p或者a,则会得到8。
关于*,&两个运算符的使用,可参考博客:指针(*)、取地址(&)、解引用(*)与引用(&)。
指针代码示例
指针的算术运算
实际上,指针的唯一算术运算就是以整数值大小增加或减少指针值。如p+1、p-2等
示例程序
考虑以下程序:
#include 初学者可能会好奇,指针p 不是一个常规意义上的数字,而是一个内存地址,它能够直接被加1吗?答案是可以的,但是结果可能会和整数的加1结果不太一样。
输出:
358010748
358010752
可以看到p+1比p大了4,而不是我们加的1。
指针的加1
这是因为指针 p 是一个指向整型变量的指针,而一个整型变量在内存中占4个字节, 对 p 执行加1,应该得到的是下一个整型数据的地址,即在地址的数值上面应该加4。
相应地,如果是p+2的话,则打印出的地址的数值应该加8。
危险
可能会造成危险的是,C/C++并不会为我们访问的地址进行检查,也就是说,我们可能通过指针访问一块未分配的内存,但是没有任何报错。这可能会造成我们不知不觉地弄错了一些数值。
比如,接着上面的例子,我们试图打印 p 和 p+1 所指向的地址所存放的值:
#include 输出:
Addresses:
-428690420
-428690416
Values:
10
-428690420
可以看到,对指针进行加法,访问 p+1 所指向的地址的值是没有意义的,但是C/C++并不会禁止我们这么做,这可能会带来一些难以察觉的错误。
指针的类型
明确指针的类型
首先要明确的是,指针是强类型的,即:我们需要特定类型的指针来指向特定类型的变量的存放地址。如int*、char*等或者指向自定义结构体和类的指针。
指针不是只存放一个地址吗?为什么指针必须要明确其指向的数据类型呢?为什么不能有一个通用类型的指针来指向任意数据类型呢?那样不是很方便吗?
原因是我们不仅仅是用指针来存储内存地址,同时也使用它来解引用这些内存地址的内容。而不同的数据类型在所占的内存大小是不一样的,更关键的是,除了大小之外,不同的数据类型在存储信息的方式上也是不同的(如整型和浮点型)。
示例程序
考虑一下程序:
#include 输出:
Size of integer is 4 bytes
p Address = 1241147588, Value=1025
p+1 Address = 1241147592, Value=1241147588
Size of char is 1 bytes
p0 Address = 1241147588, Value=1
p0+1 Address = 1241147589, Value=4
我们可以通过强制类型转换,将指向整型的指针p 转为指向字符型的p0。由于指向了字符型,p0在被解引用时只会找该地址一个字节的内容,而整型1025的第一个字节的内容为0001,第二个字节内容为0100,所以会有上面程序的打印行为。
可以参考笔者画的内存示意图来理解这段测试程序,其中v表示将该段内存解释为%d的值。

需要指出的是这里的指针的强制类型转换,看似只会添乱,毫无用处,但是它实际上是有一些有用使用场景的,会在后面介绍。
void *
我们这里首先对通用指针类型void *的一些基本特性做出说明,后面会介绍一些具体的使用场景。
-
void *时通用指针类型,它不针对某个特定的指针类型。在使用时将其赋值为指向某种特定的数据类型的指针时不需要做强制类型转换。 -
由于不知道它指向的类型,因此不能直接对其进行解引用
*p,也不能对其进行算数运算p+1。
指向指针的指针
我们之所以能够把整型变量 x 的地址存入 p 是因为 p 是一个指向整型变量的指针int*。那如果想要把指针的地址也存储到一个变量中,这个变量就是一个指向指针的指针,即int**。
这个逻辑说起来时挺清楚的,在实际程序中,则有可能会晕掉。我们来看一个示例程序,开始套娃:
#include 在这里我们不按编译器实际输出的地址值来进行分析,因为这个地址值是不固定的且通常较大。笔者在这里画了一小段内存,我们按图中的地址值来分析打印输出的内容。在图中,红色字体是地址值,青色块是该变量占据的地址空间,其中的黑色字体是该变量的值。假设我们在32位机中,即一个指针占4个字节。

在程序中,x是整型变量,p指向x,q指向p,r指向q,这样x, p, q, r的数据类型分别是:int, int*, int**, int***。
*p即对指针p的解引用,应该是x存储的值,即6。*q是对指向指针的指针q的解引用,即其指向的地址p所存储的值235。同时,这个值就是指针p的值,指向整型变量x的地址。**q是对*q的解引用,我们已经知道*q为235,则**q即地址为235的位置的值,是6。**r是对*r的解引用,而*r就是q,所以**r就是*q,235。***r是对**r的解引用,同样是235指向的值,6。
我们编译运行该程序,得到的输出是:
6
-1672706964
6
-1672706964
6
和我们分析的结果一致。
大家可以自己设计一些这种小示例程序,试着分析一下,再来查看程序运行的结果是否与预期一致。
函数传值 vs. 传引用
在执行一个C语言程序时,此程序将拥有唯一的“内存四区”——栈区、堆区、全局区、代码区.
具体过程为:操作系统把硬盘中的数据下载到内存,并将内存划分成四个区域,由操作系统找到main入口开始执行程序。
内存四区
- 堆区(heap):一般由程序员手动分配释放(动态内存申请与释放),若程序员不释放,程序结束时可能由操作系统回收。
- 栈区(stack):由编译器自动分配释放,存放函数的形参、局部变量等。当函数执行完毕时自动释放。
- 全局区(global / stack):用于存放全局变量和静态变量, 里面细分有一个常量区,一些常量存放在此。该区域是在程序结束后由操作系统释放。
- 代码区(code / text):用于存放程序代码,字符串常量也存放于此。

函数调用
-
在程序未执行结束时,
main()函数里分配的空间均可以被其他自定义函数访问。 -
自定义函数若在堆区(malloc动态分配内存等)或全局区(常量等)分配的内存,即便此函数结束,这些内存空间也不会被系统回收,内存中的内容可以被其他自定义函数和
main()函数使用。
函数传值 call by value
假设新手程序员Albert刚刚学习了关于函数的用法,写了这样的程序:
#include 在该程序中,Albert期望通过Increment()函数将a的值加1,然后打印出a = 11,但是,程序的实际运行结果却是a = 10。问题出在哪里呢?
实际上,这种函数调用的方式称为值传递call by value,这样在Increment()函数中,临时变量local variable a,会在该函数结束后立刻释放掉。也就是说Increment()函数中的a ,和main() 函数中的 a 并不是同一个变量。我们可以分别在Increment()和main()两个函数内打印变量a的地址:
printf("Address of a in Increment: %d", &a);
printf("Address of a in main: %d", &a); // 将这两句分别放在Increment函数和main函数中
输出:
Address of a in Increment: 2063177884
Address of a in main: 2063177908
这里两个地址的具体值不重要,重要的是他们是不一样的,也就是说我们在两个函数中操作的a变量并不是同一个,所以程序输出的是没有加1过的a的值。

笔者这里还是根据原视频作者的讲解,通过画出内存的形式来分析值传递。
程序会为每个函数创造属于这个函数的栈帧,我们首先调用main()函数,其中的变量a一直存储在main()函数自己的栈帧中。在我们调用Increment()函数的时候,会单独为其创造一个属于它的栈帧,然后main()函数将实参a=10传给Increment()作为形参,a会在其中加1,但是并没有被返回。在Increment()函数调用结束后,它的栈帧被释放掉,main()函数并不知道它做了什么,main()自己的变量值一直是10,然后调用printf()函数,将该值打印出来。
可以看到,局部变量的值的生命周期随着被调用函数Increment()的结束而结束了,而由于main()中的a和Incremet()中的a并不是同一个变量(刚才已经看到,二者并不在同一地址),因此最终打印出的值还是10。
传引用 call by reference
那怎样才能实现Albert的预期呢?我们刚才已经看到,之所以最终在main()中打印的值没有加1,就是因为加1的变量和最终打印的变量不是同一个变量。那我们只要使得最终打印的变量就是在Increment()中加过1的变量就可以了。这要怎么实现呢?我们刚刚学过,通过指针可以指向某个特定的变量,并可以通过解引用的方式对该变量再进行赋值,而又由于在程序未执行结束时,main()函数里分配的空间均可以被其他自定义函数访问。因此我们可以将main()中的变量地址传给Increment(),在其中对该地址的值进行加一,这样最终打印的变量就会是加过1的了。

实现如下:
#include 这种传地址的方式我们称之为call by reference。
它可以在原地直接修改传入的参数值。另外,由于传的参数是一个指针,无论被指向的对象有多么大,这个指针也只占4个字节(32位机),因此,这种方式也可以大大提高传参的效率。
指针与数组
指针和数组常常一起出现,二者之间有着很强的联系。
数组的声明
当我们声明一个整型数组int A[5]时,就会有五个整型变量:A[0] - A[4],被连续地存储在内存空间中。

数组与指针算术运算
还记得我们在前面介绍过指针的算术运算时,提到过指针的算术运算可能会导致访问到未知的内存,因为我们定义一个指针时,它指向的位置的邻居通常是未知的。而在数组中,我们没有这个问题,因为数组是一整块连续的内存空间,我们确定旁边也存放着一些相同类型的变量。
int A[5];
int* p;
p = A;
printf("%d\n", p); // 200
printf("%d\n", *p); // 2
printf("%d\n", p+1); // 204
printf("%d\n", *(p+1)); // 4
// ...
在数组中,指针的算术运算就很有意义了。因为相邻位置的变量都是已知的,我们可以通过这种偏移量的方式去访问它们。
数组名和指针
数组与指针的另一个联系是:数组名就是指向数组首元素的指针。数组的首元素的地址,也被称为数组的基地址。
(这里还有一个要注意的小点:数组名不能直接自加,即不可A++,但是可以将其赋值给一个指针,指针可以自加:p++)
比如上面例程中我们写的p = A。这样,考虑以下例程的打印输出:
printf("%d\n", A); // 200
printf("%d\n", *A); // 2
printf("%d\n", A+3); // 212
printf("%d\n", *(A+3)); // 8
数组/指针 取值/取地址
对于第 i i i 个元素:
- 取地址:
&A[i]or(A+i) - 取值:
A[i]or*(A+i)
关于C/C++中指针与数组的关系可参考博客:C++中数组和指针的关系(区别)详解,笔者已将全文重要的一些知识点都总结好,放在文章开头。
数组作为函数参数
注意我们可以通过sizeof函数获取到数组的元素个数:sizeof(A) / sizeof(A[0]),即用整个数组的大小除以首元素的大小,由于我们的数组中存储的元素都是相同的数据类型,因此可以通过此法获得数组的元素个数。
例程1
我们现在定义一个SumOfElements()函数,用来计算传入的数组的元素求和,该函数还需要传入参数size作为数组的元素个数。在main()函数中新建一个数组,并通过sizeof来求得该数组的元素个数,调用该函数求和。
#include 打印出的结果如我们所料,为15:
Sum of elements = 15
例程2
有人可能回想,既然我们已经将数组传入函数了,能不能进行进一步的封装,将数组元素个数的计算也放到调用函数内来进行呢?于是有了如下实现:
#include 结果好像除了亿点点问题(笔者注:这里笔者的测试结果与原视频作者不同(原结果1),是由于笔者是在64位机上进行的测试,一个指针大小为8字节,而原作者使用的是32位机,指针占4字节,这在接下来的测试程序中也有体现):
Sum of elements = 3
为了测试问题出在哪里,让我们在main()和SumOfElements()函数中打印如下信息:
printf("Main - Size of A = %d, Size of A[0] = %d\n", sizeof(A), sizeof(A[0]));
printf("SOE - Size of A = %d, Size of A[0] = %d\n", sizeof(A), sizeof(A[0])); // 将这两行分别添加到main和SumOfElements
输出结果:
SOE - Size of A = 8, Size of A[0] = 4
Main - Size of A = 20, Size of A[0] = 4
Sum of elements = 3
果然,在SOE中传入的数组A的大小仅有8字节,即一个指针的大小。
实际上,在编译例程2时,编译器会给我们一定的提示Warning:
pointer.c: In function ‘SumOfElements’:
pointer.c:5:22: warning: ‘sizeof’ on array function parameter ‘A’ will return size of ‘int *’ [-Wsizeof-array-argument]
int size = sizeof(A) / sizeof(A[0]);
可以看到,还是比较准确地指出了可能存在的问题,在被调函数中直接对数组名使用sizeof,会返回指针的大小。
分析
我们还是要画出栈区来进行分析:

我们期望的是向左边那样,在main()函数将数组A作为参数传给SOE()之后,会在SOE()的栈帧上拷贝一份完全相同的20字节的数组。但是在实际上,编译器却并不是这么做的,而是只把数组A的首地址赋值给一个指针,作为SOE()的形参。也就是说,SOE()的函数签名SumOfElements(int A[]) 其实是相当于SumOfElements(int* A)。这也就解释了为什么我们在其内部计算A的大小时,得到的会是一个指针的大小。结合我们之前介绍过的值传递和地址传递的知识。可以这样讲:数组作为函数参数时是传引用(call by reference),而非我们预期的值传递。
需要指出的是,编译器的这种做法其实是合理的。因为通常来讲,数组会是一个很长,占内存空间很大的变量,如果每次传参都按照值传递完整地拷贝一份的话,效率极其低下。而如果采用传引用的方式,需要传递的只有一个指针的大小。
指针与数组辨析
这里视频原作者做了许多解释,笔者认为有一句话可以概括二者关系的本质:数组名称和指针变量的唯一区别是,不能改变数组名称指向的地址,即数组名称可视为一个指向数组首元素地址的指针常量。也就是说数组名指针是定死在数组首元素地址的,其指向不能被改变。比如数组名不允许自加A++,因为这会它是一个不可改变的指针常量,而一般指针允许自加p++;还有常量不能被赋值,即若有数组名 A,指针 p,则A = p是非法的。详见博客:C++中数组和指针的关系(区别)详解。
指针与字符数组
当我们在C语言中谈论字符数组时,通常就是在谈论字符串。
C语言中字符串的存储
在C语言中,我们通常以字符数组的形式来存储字符串。对于一个有 n n n 个字符组成的字符串,我们需要一个长度至少为 n + 1 n+1 n+1 的字符数组。例如要存储字符串JOHN,我们需要一个长度至少为 5 的字符数组。
之所以字符数组的长度要比字符串中字符的个数至少多一个,是因为我们需要符号来标志字符串的结束。在C语言中,我们通过在字符数组的最后添加一个 \0 来标志字符串的结束。如下图。

在这个图中,我们为了存储字符串JOHN,我们使用了字符数组中的5个元素,其中最后一个字符 \0,用来标识字符串的结束。倘若没有这个标识的话,程序就不知道这个字符串到哪里结束,就可能会访问到5,6中一些未知的内容。
示例程序:
#include 这里原作者给出了这样一个示例程序,并且测试得到的输出结果是JOHN+几个乱码,这是合理的,因为如前所述,没有设置 \0 来标识字符串的结束。
但是笔者在自己的机器上亲测(编译器为gcc 7.5.0)的时候打印输出是正常的JOHN字符串,这是由于有些编译器会自动的为你补全\0。笔者也尝试了通过调整gcc的-O参数尝试了各种优化等级,都可以正常打印字符串。
而通过 char C[20] = "JOHN" 这种方式定义的字符串,编译器一定会在其末尾添加一个 \0。 原作者强调这里编译器会强制要求声明的数组长度大于等于5,也就是说char C[4] = "JOHN"是无法通过编译的。但在笔者测试时,这也是可行的,但是 3 就肯定不行了哈。
通过引入头文件string.h,可以使用strlen()函数获取到字符串的长度,无论我们声明的字符数组有多长(比如上面这个20),该函数会找到第一个 \0,并返回之前的元素个数,也就是我们实际的字符串长度。有以下例程:
#include 输出会是 4,我们实际的字符串JOHN的长度。
字符串常量与常量指针
char[] 和 char*
char C[20] = "JOHN"; // 字符串就会储存在分配给这个数组的内存空间中,这种情形下它会被分配在栈上
当向上面一样使用字符数组进行初始化时,字符串就会储存在分配给这个数组的内存空间中,这种情形下它会被分配在栈上。
而当使用 char* 的形式声明一个字符串时(如下),它会是一个字符串常量,通常会被存放在代码区。
char* C = "JOHN"; // 如此声明则为字符串常量,存放在代码区,其值不能被修改
既然叫做常量,那它的值肯定是不能更改的了,即*C[0]='A' 是非法的操作。
常量指针
还记得我们之前提到过,即数组名称可视为一个指向数组首元素地址的指针常量。指针常量的含义是指针的指向不能被修改,如数组名看作指针时不能自加,因为这会修改它的指向。
而本小节提到的常量指针则是指指针指向的值不能被修改。常量指针通常用在引用传参时,如果某个函数要进行一些只读的操作(如打印),为了避免在函数体内部对数据进行了写操作,而又因为是传引用,则会破坏原数据。如以下打印字符串的函数,由于打印字符串不需要改动原来的数据,故可以在函数签名中加上const关键字,来使得 C 是一个常量指针,保证其指向的值不会被误操作修改。注意此处的 C 是常量指针,而非指针常量,即其指向可以改变,因此函数体中的C++是合法的操作。
void printString(const char* C){
while (*C != '\0'){
printf("%c", *C);
C++;
}
printf("\n");
}
指针与多维数组
指针与二维数组
二维数组概念
我们可以声明一个二维数组:int B[2][3],实际上,这相当于声明了一个数组的数组。如此例中,B[0], B[1] 都是包含3个整型数据的一维数组。

如前所述,数组名相当于是指向数组首元素地址的指针常量。在这里,首元素不在是一个整型变量,而是一个包含3个整型变量的一维数组。这时int* p = B就是非法的了,因为数组名B是一个指向一维数组的指针,而非一个指向整型变量的指针。正确的写法应该是:int (*p)[3] = B。
而B[0]就相当于是一个一维数组名(就像前几章的A),也相当于一个指向整型的指针常量。
例程
我们通过一个例程来帮助自己分析理解二维数组和指针,与上面的元素设定一致,也假设地址就按上方蓝色字体,每一组有虚线分隔开来,每一组之内的含义是一样的。大家可以先不看注释中的解释与答案,自己试着分析一下每一组是什么含义。后面会给出笔者的分析。
#include -
第一组 (
B,&B[0]):数组名B是一个指针,其指向的元素是一个一维数组,即二维数组第一个元素(第一个一维数组)的首地址。而B[0]就是二维数组的第一个元素,即二维数组的第一个一维数组,对其进行取地址运算,故&B[0]就是第一个一维数组的地址,也即第一个指向第一个一位数组的指针。所以说第一组是指向一位数组的指针,其值为 400。
-
第二组:(
*B,B[0],&B[0][0]):对数组名B进行解引用,得到的是其第一个元素(第一个一维数组)的值,也就是一个一维数组名B[0](相当于前面几章的一维数组名A),这个一维数组名就相当于是一个指向整型数据的指针常量。而B[0][0]是一个整型数据2,对其进行取地址运算,得到的是一个指向整型变量的指针。所以说第二组是指向整型变量的指针,其值也为400,但与第一组指向的元素不同,注意体会。
-
第三、四组与第一、二组类似,关键区别在于加入了指针运算。这里需要注意的是对什么类型的指针进行运算,是对指向一维数组的指针(+12),还是对指向整型的指针(+4)。在这两组中都是对指向一维数组的指针(如二维数组名
B)进行运算,所以地址要偏移12个字节。 -
第五组中开始有了对不同的指针类型进行指针运算的情况。在这一组中的,+1都是对指向一维数组的指针进行运算,要+(1*12),而+2都是对指向整型变量的指针进行运算,要+(2*4),故最终结果是420。
-
最后一组只有一个值。但需要一步一步仔细分析。首先
*B是对二位数组名进行解引用,得到的是一个一位数组名,也就是一个指向整型的指针常量。对其加1,需要偏移4个字节,即(*B+1)是一个指向地址404处的整型变量的指针,对其进行解引用,直接拿出404地址处的值,得到3。大家可以考虑一下,如果加一个括号
*(*(B+1))的值会是多少呢?
小公式
对于二位数组和指针、指针运算的关系,原作者给出了这样一个公式,笔者同样写在下面供大家参考。希望大家不要死记硬背,而是试着去理解它。
B[i][j] == *(B[i]+j) == *(*(B+i)+j)
指针与高维数组
前面我们已经看到多维数组的本质其实就是数组的数组。如果你已经对上一小节例程中的几组值得含义都已经完全搞清楚了,那么理解高维数组也不难了。
以下我们以三维数组为例进行介绍,开始套娃。
三维数组概念
我们可以这样声明一个三维数组:int C[3][2][2]。三维数组中的每个元素都是二维数组, 具体来说,它是由三个二维数组组成的,每个二维数组是由两个一维数组组成的,每个一维数组含有两个整型变量。图示如下:
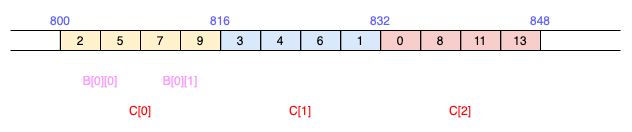
类似地,如果我们想将三维数组名C赋值给一个指针的话,应该这样声明:int (*p)[2][2] = C。
小公式
同样给出三维数组的小公式如下:
C[i][j][k] == *(C[i][j]+k) == *(*(C[i]+j)+k) == *(*(*(C+i)+j)+k)
这里笔者只简单分析一下。首先,要明确,在本例中,一个整型变量占4个字节,一个一维数组占2*4=8个字节,一个二维数组占2*2*4=16个字节,而整个三维数组占3*2*2*4=48个字节。
从右向左、从里向外看:
C是三维数组名,其值是三维数组中的第一个元素(即第一个二维数组)的起始地址,800,相当于指向二维数组的指针常量,C+i是对指向二维数组的指针进行运算,因此应该偏移+i*16个字节,而对其进行解引用*(C+i),得到的就是起始地址为800+i*16处的那个二维数组,其名为C[i](相当于B);
而二维数组名是一个指向一位数组的指针常量,然后C[i]+j是对指向一维数组的指针进行运算,偏移+j*8个字节,而对其进行解引用*(C[i]+j),得到的是起始地址为800+i*16+j*8处的一维数组,其名为C[i][j](相当于A);
而一维数组名是一个指向整型变量的指针常量,C[i][j]+k是对指向整型变量的指针进行运算,应该偏移+k*4个字节,而对其进行解引用*(C[i][j]+k),得到的是起始地址为800+i*16+j*8+k*4处的那个整型变量的值,即C[i][j][k]。
大家可以试着分析一下*(C[1]+1)和*(C[0][1]+1)分别是多少,这时作者给出的两个小测试题,答案是824和9。
多位数组作为函数参数
一维数组作为参数需要注意是传引用,另外在函数体内不修改数据时,注意在函数签名中将数组名指针声明为常量指针。
二维数组做参数:
void func(int (*A)[3]void func(int A[][3])
注意事项
-
注意:多维数组做函数参数时,数组的第一个维度可以省略,但是其他维度必须指定。所以说,对一个需要接收二维数组的参数,将函数签名声明为
void func(int **A)是不可行的,因为这样没有指定任何数组维度。 -
注意:在调用时要正确地传递参数数组的类型。比如下面这样就是不可行的:
void func1(int Arr[][3]){} void func2(int Arr[][2][2]){} int main(){ int A[2][2]; int B[2][3]; int C[3][2][2]; int D[3][2][3]; func1(A); // 错误 func1(B); // 正确 func2(C); // 正确 func2(D); // 错误 }
指针与动态内存
内存四区简介
内存被分为四个区,分别是代码区,静态/全局区,栈区和堆区。
- 代码区:存放指令。
- 静态区 / 全局区:存放静态或全局变量,也就是不再函数中声明的变量,它们的生命周期贯穿整个应用程序。
- 栈区:用来存放函数调用的所有信息,和所有局部变量。
- 堆区:大小不固定,可以由程序员自由地分配和释放(动态内存申请与释放)。

在整个程序运行期间,代码区,静态/全局区,栈区的大小是不会增长的。
有一个小点要说明一下:有堆、栈这两种数据结构,也有堆、栈这两个内存分区,内存中的栈基本是由数据结构中的栈实现的,而内存中的堆和数据结构中的堆毫无关系。堆可以简单理解为一块大的、可供自由分配释放的内存空间。
之前我们已经介绍过在程序运行过程中,代码区、静态/全局区和栈区是怎样运作的了,特别是函数调用时栈区的工作方式,我们特别进行了说明。
C/C++中的动态内存分配
- 在C中,我们需要使用四个函数进行动态内存分配:
malloc(),calloc(),realloc(),free()。 - 在C++中,我们需要使用两个操作符:
new,delete。另外,由于C++是C的超集,兼容C,故也可以用以上4个函数来进行动态内存分配。
malloc 和 free
#include malloc函数从堆上找到一块给定大小的空闲的内存,并将指向起始地址的void *指针返回给程序,程序员应当根据需要做适当的指针数据类型的转换。
向堆上写值的唯一方法就是使用解引用,因为malloc返回的总是一个指针。如果malloc无法在堆区上找到足够大小的空闲内存,则会返回NULL。
程序员用malloc在堆上申请的内存空间不会被程序自动释放,因此程序员在堆上申请内存后,一定要记得自己手动free释放。
free接收一个指向堆区某地址的指针作为参数,并将对应的堆区的内存空间释放。

new 和 delete
在C++中,程序员们通常使用new,delete操作符来进行动态内存的分配和释放。以下是整型变量和整型数组的分配和释放例程。
p = new int;
*p = 10;
delete p;
p = new int[20]
delete[] p;
注意数组delete时要有[]。
在C++中,不需要做指针数据类型的转换,new和delete是类型安全的。它们是带类型的,返回特定类型的指针。
malloc、calloc、realloc、free
malloc
-
函数签名:
void* malloc(size_t size)。函数接收一个参数size,返回的void*指针指向了分配给我们的内存块中的第一个字节的地址。 -
void*类型的指针只能指明地址值,但是无法用于解引用,所以通常我们需要对返回的指针做强制类型转换,转换成我们需要的指针类型。 -
通常我们不显式地给出参数
size的值,而是通过sizeof,再乘上我们需要的元素个数,计算出我们需要的内存空间的大小。 -
典型用法:
int* p = (int*)malloc(3 * sizeof(int)); *p = 10; *(p+1) = 3; p[2] = 2; // 之前学过的数组的形式
calloc
-
函数签名:
void* calloc(size_t num, size_t size)。函数接收两个参数num,size,分别表示特定类型的元素的数量,和类型的大小。同样返回一个void*类型的指针。 -
典型用法:
int *p = (int*)calloc(3, sizeof(int)); -
calloc与malloc的另一个区别是:malloc分配完内存后不会对其进行初始化,calloc分配完内存后会将值初始化位0。
realloc
-
函数签名:
void* realloc(void* ptr, size_t size)。函数接收两个参数,第一个是指向已经分配的内存的起始地址的指针,第二个是要新分配的内存大小。返回void*指针。可能扩展原来的内存块,也可能另找一块大内存拷贝过去,如果是缩小的话,就会是原地缩小。 -
如果缩小,或者拷贝到新的内存地址,总之只要是由原来分配的内存地址不会再被用到,
realloc函数自己会将这些不被用到的地址释放掉。 -
以下这种情况使用
realloc相当于free:int* B = (int*)realloc(A, 0);以下这种情况使用
realloc相当于malloc:int* B = (int*)realloc(NULL, sizeof(int));
free
在堆区动态分配的内存会一直占据着内存空间,如果程序员不将其显式地释放,程序是不会自动将其释放的,直到整个程序结束。 已经没有用的堆区内存如果不进行手动释放会造成内存泄漏,因此,使用上面三个函数在动态分配的堆区内存的使命结束后,程序员有责任记得将它们释放。
在C中,我们使用free函数来进行堆区内存的释放。只需将要释放的内存的其实地址传入即可:free(p)。
使用场景
当我们想要根据用户的输入来分配一个合适大小的数组,如果写成如下这样:
#include 作者将这样在运行时才知道数组的大小是不行的。但是笔者实验过发现是可以的,这应该是C99支持的特性变长数组。
但是这并不妨碍我们试着练习用动态分配内存的方式来新建一个数组,我们可以这样做:
int* A = (int*)malloc(n * sizeof(int));
或者用calloc,会自动将初始值赋为0:
int* A = (int*)calloc(n, sizeof(int));
别忘了手动释放堆区内存。
free(A);
注意
在C程序中,只要我们知道某个内存的地址,我们就能访问它,C语言并不禁止我们的这种行为。但我们应当注意,不要去试图读写未知的内存,因为这将使我们的程序的行为不可预测,可能某个存在非法读写的程序在某个机器上运行正常,但是到了另一个环境、另一个机器上就会崩溃。最好的方法是:只去读写为我们分配的内存,而不要试图访问未知的内存。
内存泄漏
动态分配内存使用结束后不进行释放的行为可能会造成内存泄漏。乍看之下,好像不进行内存释放”只是“多占了一些内存空间而已,为什么会被称为内存泄漏呢?而又为什么只有堆区的动态内存未被释放会造成内存泄漏呢?本小节将介绍相关内容。
#include 我们有在主函数上调用allocate_stack或者allocate_heap,两者的区别是一个在栈上开辟一个数组并直接返回,另一个在堆区开辟一个数组并且不释放返回。在主函数中死循环询问是否继续开辟数组,得到继续开辟数组的命令后开辟100个数组。我们可以通过top命令清晰地看到allocate_stack的内存占用在每次开辟数组后骤增,然后掉下去,而allocate_heap的内存占用每次骤增后也不掉下去,直到内存占用过大被操作系统kill掉。
allocate_stack

对于调用allocate_stack的程序,在allocate_stack函数调用时,每次将数组创建在栈区,然后再函数返回时,程序自动将其栈帧释放,数组也被释放掉,不会占用内存。
allocate_heap

对于调用allocate_heap的程序:每次调用allocate_heap在堆区开辟一个数组Arr,在栈上只创建了一个指针p来指向这个堆区数组,但是堆区数组没有释放,这样在allocate_heap函数返回之后,函数栈帧上的p也被程序释放掉,就再也没有办法去释放堆区的数组Arr。这样随着函数调用次数越来越多,这些堆区的数组都处于已分配但无法引用也无法使用的状态。而堆区大小又是不固定的,可以一直向操作系统申请,终有一天,会超过内存上限,被系统这就是内存泄漏。
函数返回指针
指针本质上也是一种数据类型(就像int、char),其中存储了另外一个数据的地址,因此将一个指针作为返回类型是完全可行的。但是,需要考虑的是,在什么情况下,我们会需要函数返回一个指针类型呢?
示例程序
考虑这样一个程序:
#include 我们定义了一个加和函数Add,它从main函数中接收两个参数,并将二者求和的值返回给main。需要注意的是,就像我们之前提到的那样,这里的x,y,z都是栈区main函数栈帧里的局部变量,而a, b 则都是栈区上Add函数栈帧中的局部变量。
并且这种函数传参的方式我们之前已经讲过,成为值传递。
要将函数的传参方式改为地址传递,只需改为以下程序:
#include 函数返回指针
上面关于传值和传引用的做法我们已经在前面介绍过了,我们这一小节的重点是看看怎样让函数返回一个指针,我们的第一个版本可能会是这样的:
#include 这个版本在作者测试时是正常的,但是如果在打印结果之前再多调用一个函数printHello,则会导致输出错误。这究竟是怎么回事呢?我们还是要借助栈区内存分析。

我们再次划出这个程序运行时的内存,这里没有用到堆区,就暂时先不画出来了。
我们看到,在调用Add是,有Add自己的栈帧,其中存放两个传入的指向整型的指针a,b,指向main函数栈帧中的我们想要加和的两个整型变量x,y,Add的栈帧中还有一个整型变量c,是我们的计算结果,按照上面的程序写法,Add函数返回一个整型指针指向变量c,即main中的ptr。
问题来了,在Add函数返回之后,它在栈区上的栈帧也被程序自动释放了,这个时候,原来存放整型变量c的150这个内存地址中的值就已经是未知的了,我们之前说过,访问未知的内存是极其危险的。
如果在Add函数返回之后,没有调用其他任何函数,直接对150解引用,有可能能够打印出正确的结果,如果编译器没有对释放的栈帧进行其他处理。但是如果调用了其他函数,如printHello,即使该函数中没有任何我们看得到的参数,但也需要保存一些返回地址、寄存器现场等参数,因此也会在栈区占用一块作为自己的栈帧。这时,内存位置150几乎是肯定被重写了,这时无法得到预期的结果。无论如何,访问未知的内存地址是一定要杜绝的,不能寄希望于偶然的正确结果。
另外,需要指出的是,main函数也通过传引用的形式将地址传递给了Add函数,但这是没问题的,因为Add函数调用时,main函数的栈帧还是在原来的内存位置,这是已知的,我们可以进行访问。即栈底向上传参数是可以的,从栈底向上传一个局部变量或者一个局部变量的地址是可以的。但是栈顶向下传参数是不可以的,从栈顶向下传一个局部变量或者一个局部变量的地址是不可以的。可想而知,C/C++中的main函数是可以自由地向被调函数传引用的。
笔者自己在亲测这个程序,编译时会报警告:
pointer.c: In function ‘Add’:
pointer.c:6:12: warning: function returns address of local variable [-Wreturn-local-addr]
return &c;
^~
而运行时则会直接Core Dumped。应该是新版本的编译器直接禁止了这种返回已释放的栈区指针的行为。
使用场景
可以见到,返回被调函数在栈区的局部变量的指针是危险的。通常,我们可以安全地返回堆区或者全局区的内存指针,因为它们不会被程序自动地释放。
我们尝试在堆区分配内存,将上面的程序中的Add函数改为:
int* Add(int* a, int* b){
int* c = (int*)malloc(sizeof(int));
*c = (*a) + (*b);
return c;
}
这样,程序就可以正常地工作了。

这样,Add返回的指针所指向的地址存放在堆区,不像栈区一样在函数返回之后被程序自动释放,可以在main函数中正常地进行访问。堆区内存使用结束之后不要忘记释放。
函数指针
代码段
函数指针,就像名字所描述的那样,是用来存储函数的地址的。之前我们介绍的指针都是指向数据的,本章我们将讨论指向函数的指针。我们可以使用函数指针来解引用和执行函数。

我们已经不止一次提过内存四区或者内存四区的某一部分了。但是有一部分我们在之前的讲述中一直没有提到过,那就是代码区(Code)。我们知道,虽然我们编写程序源代码时使用的大多是C、C++等高级语言,但是机器要真正的运行程序,必须是运行二进制的机器代码。从C到机器代码的这个过程(包括预处理、编译、汇编、链接)是由编译器替我们完成的,得到的二进制代码将被存放在可执行文件中。
应用程序的代码段,就是用来存放从可执行文件拷贝过来(到内存代码段)的机器码或指令的。下面我们来仔细讨论一下代码区。

如上图所示,假设一条指令占4个字节,在内存中,一个函数就是一块连续的内存(其中存放的不是数据,而是指令)。指令通常都是顺序执行的,直到发生跳转(如函数调用,函数返回),会根据指令调到指定的地址执行。假设图中蓝色区域(指令02 - 指令 05,地址208 - 220)是一个函数,指令00是一条跳转指令,调用了蓝色区域的函数,程序就会从200跳转到208执行。函数的起始地址(比如208),被称为函数的入口点,它是函数的第一条指令的地址。
函数指针的定义和使用
下面这个程序定义和使用了一个函数指针:
#include -
声明函数指针的语法是:
int (*p)(int, int),这条语句声明了一个接收两个整型变量作为参数,并且返回一个整型变量的函数指针。注意函数指针可以指向一类函数,即可以说,指针p指向的类型是输入两整型,输出一整型的这一类函数,即所有满足这个签名的函数,都可以赋值给p这个函数指针。另外,要注意指针要加括号。否则
int *p(int, int),是声明一个函数名为p,接收两个整型,并返回一个整型指针的函数。 -
函数指针赋值:
p = &Add,将函数名为Add的函数指针赋值给p。同样注意只要满足p声明时的函数签名的函数名都可以赋值给p。 -
函数指针的使用:
int c = (*p)(2, 3),先对p解引用得到函数Add,然后正常传参和返回即可。 -
还有一点,在为函数指针赋值时,可以不用取地址符号
&,仅用函数名同样会返回正确的函数地址。与之匹配的,在调用函数的时候也不需要再解引用。这种用法更加常见。int (*p)(int, int); p = Add; c = p(2, 3); -
再强调一下:注意函数指针可以指向一类函数,即可以说,指针
p指向的类型是输入两整型,输出一整型的这一类函数,即所有满足这个签名的函数,都可以赋值给p这个函数指针。用不同的函数签名来声明的函数指针不能指向这个函数。如以下这些函数指针的声明都是不能指向
Add函数的:void (*p)(int, int); int (*p)(int); int (*p)(int, char);
函数指针的使用案例(回调函数)
回调函数的概念
这里使用函数指针的案例都围绕着这么一个概念:函数指针可以用作函数参数,而接收函数指针作为参数的这个函数,可以回调函数指针所指向的那个函数。
#include 或者我们可以直接在主函数中B(A),而不需要上面那写两句先复制给p,再调用p。
在上面的例程中,将函数A()的函数指针传给B(),B()在函数体内直接通过传入的函数指针调用函数A(),这个过程成为回调。这里函数指针被传入另一个函数,再被用函数指针进行回调的函数A()成为回调函数。
回调函数的实际使用场景
#include 输出排序结果:
-5 -4 -1 2 3 7 9
对于这个排序函数,我们可能有时需要升序排序有时需要降序排序,即我们可能会根据具体使用场景有不同的排序规则。而由于实现不同的排序函数时,整个算法的逻辑是不变的,只有排序的规则会不同,总不至于为了不同的排序规则都单独写一个函数,这时我们就可以借助函数指针作为参数来实现不同的排序规则的切换。
即实现如下:
#include 我们在排序函数中接收一个函数指针Compare作为参数,用整个参数来指示排序的规则。这样我们就利用回调函数实现了这一想法。我们可以写不同的排序规则作为回调函数,比如笔者这里又写了一个按照绝对值比较大小的回调函数abs_greater,
输出:
-1 2 3 -4 -5 7 9
另外回调函数还有更多有趣的应用,比如事件回调函数等。
Ref:
https://blog.csdn.net/helloyurenjie/article/details/79795059