YOLOv5、YOLOv7改进之三十:引入10月4号发表最新的Transformer视觉模型MOAT结构
前 言:作为当前先进的深度学习目标检测算法YOLOv7,已经集合了大量的trick,但是还是有提高和改进的空间,针对具体应用场景下的检测难点,可以不同的改进方法。此后的系列文章,将重点对YOLOv7的如何改进进行详细的介绍,目的是为了给那些搞科研的同学需要创新点或者搞工程项目的朋友需要达到更好的效果提供自己的微薄帮助和参考。由于出到YOLOv7,YOLOv5算法2020年至今已经涌现出大量改进论文,这个不论对于搞科研的同学或者已经工作的朋友来说,研究的价值和新颖度都不太够了,为与时俱进,以后改进算法以YOLOv7为基础,此前YOLOv5改进方法在YOLOv7同样适用,所以继续YOLOv5系列改进的序号。另外改进方法在YOLOv5等其他算法同样可以适用进行改进。希望能够对大家有帮助。
具体改进办法请关注后私信留言!
解决问题:
前面介绍改进YOLO算法,引入Swin transformer模块,本人在某遥感数据集上进行测试,替换主干网络后,确实有精度提升的效果,并且参数量降低了,相对于Botnet中的多头注意力机制来说,加入网络的性价比更高,也证明了Swin transformer模块的有效性和优越性。今年还出了Swin transformer 第二个版本,尝试将其中添加进YOLO系列算法中。同样加入Transformer也是为了拟补YOLO这种卷积网络缺乏长距离建模的能力,没有获取全局信息的能力,为了更好的提取目标特征信息。 Transformer在计算机视觉领域的发展速度真是快,2021年1月出的BoTNet,3月出的Swin transformer 1.0版本,以及后面其他transformer改进不断更新迭代。只能说transformer拟补了卷积网络的不足,确实有不错的提升效果。10月4日新出的MOAT结构,更是效果明显。将其应用于YOLO算法中,将提升检测效果。
基本原理:
MOAT是一个建立在MObile卷积(即倒置残差块)和ATtention之上的神经网络家族。与当前将移动卷积和变换块分开堆叠的工作不同,我们有效地将它们合并到MOAT块中。从一个标准的Transformer块开始,我们用一个移动卷积块替换它的多层感知器,并在自我注意操作之前对其进行重新排序。移动卷积块不仅增强了网络表示能力,还产生了更好的下采样特征。我们概念上简单的MOAT网络非常有效,通过ImageNet-22K预处理,在ImageNet-1K上达到89.1%的前1精度。此外,通过简单地将全球注意力转换为窗口注意力,MOAT可以无缝应用于需要大分辨率输入的下游任务。由于移动卷积可以有效地在像素之间交换本地信息(从而跨窗口),MOAT不需要额外的窗口移动机制。因此,在COCO对象检测中,MOAT使用227M模型参数(单尺度推理和硬NMS)获得59.2%的APbox,在ADE20K语义分割中,MOT使用496M模型参数获得57.6%的mIoU(单尺度推断)。最后,通过简单地减小信道大小而获得的微型MOAT系列也出人意料地优于ImageNet上的几个基于移动特定变压器的模型。我们希望我们简单而有效的MOAT将激发卷积和自我关注的更无缝集成。
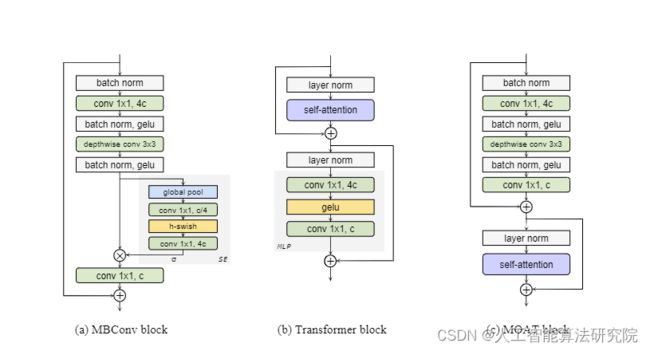
MOAT块 鉴于上述观察结果,我们现在尝试设计一个新块,有效地合并MBConv和Transformer块中的最佳块。我们从功能强大的Transformer块开始,并逐步完善。根据第一次观察,MBConv和Transformer模块都采用了“反向瓶颈”设计。由于深度卷积可以有效地编码像素之间的局部交互,这对于在ConvNets中建模平移等方差至关重要,因此我们开始将深度卷积添加到Transformer的MLP模块。然而,在我们在卷积之间添加额外的规范化和激活之前,我们没有观察到任何性能改进。对于第二个观察结果,我们只是没有将SE模块添加到MBConv块中。保持自我关注操作以捕获全局信息。我们发现第三个观察结果很关键。变压器块中自我注意操作之前的降采样操作(平均池)略微降低了其表示能力。另一方面,MBConv块经过精心设计,可用于跨深度卷积的下采样操作,有效学习每个输入通道的下采样卷积核。因此,我们在自我注意操作之前进一步对“反向瓶颈”(包含深度卷积)重新排序,将下采样操作委托给深度卷积。这样,我们不需要额外的下采样层,如CoAtNet(Dai等人,2021)中的平均池,或SWN(Liu等人,2021)和ConvNeXt(Liu等,2022b)中的面片嵌入层。最后,它产生了我们的MObile卷积与ATtention(MOAT)块 。
项目部分代码如下:
class DeepLab(tf.keras.Model):
"""This class represents the DeepLab meta architecture.
This class supports four architectures of the DeepLab family: DeepLab V3,
DeepLab V3+, Panoptic-DeepLab, and MaX-DeepLab. The exact architecture must be
defined during initialization.
"""
def __init__(self,
config: config_pb2.ExperimentOptions,
dataset_descriptor: dataset.DatasetDescriptor):
"""Initializes a DeepLab architecture.
Args:
config: A config_pb2.ExperimentOptions configuration.
dataset_descriptor: A dataset.DatasetDescriptor.
Raises:
ValueError: If MaX-DeepLab is used with multi-scale inference.
"""
super(DeepLab, self).__init__(name='DeepLab')
if config.trainer_options.solver_options.use_sync_batchnorm:
logging.info('Synchronized Batchnorm is used.')
bn_layer = functools.partial(
tf.keras.layers.experimental.SyncBatchNormalization,
momentum=config.trainer_options.solver_options.batchnorm_momentum,
epsilon=config.trainer_options.solver_options.batchnorm_epsilon)
else:
logging.info('Standard (unsynchronized) Batchnorm is used.')
bn_layer = functools.partial(
tf.keras.layers.BatchNormalization,
momentum=config.trainer_options.solver_options.batchnorm_momentum,
epsilon=config.trainer_options.solver_options.batchnorm_epsilon)
# Divide weight decay by 2 to match the implementation of tf.nn.l2_loss. In
# this way, we allow our users to use a normal weight decay (e.g., 1e-4 for
# ResNet variants) in the config textproto. Then, we pass the adjusted
# weight decay (e.g., 5e-5 for ResNets) to keras in order to exactly match
# the commonly used tf.nn.l2_loss in TF1. References:
# https://github.com/tensorflow/models/blob/68ee72ae785274156b9e943df4145b257cd78b32/official/vision/beta/tasks/image_classification.py#L41
# https://www.tensorflow.org/api_docs/python/tf/keras/regularizers/l2
# https://www.tensorflow.org/api_docs/python/tf/nn/l2_loss
self._encoder = builder.create_encoder(
config.model_options.backbone, bn_layer,
conv_kernel_weight_decay=(
config.trainer_options.solver_options.weight_decay / 2))
self._decoder = builder.create_decoder(
config.model_options, bn_layer, dataset_descriptor.ignore_label)
self._is_max_deeplab = (
config.model_options.WhichOneof('meta_architecture') == 'max_deeplab')
self._post_processor = post_processor_builder.get_post_processor(
config, dataset_descriptor)
# The ASPP pooling size is always set to train crop size, which is found to
# be experimentally better.
pool_size = config.train_dataset_options.crop_size
output_stride = float(config.model_options.backbone.output_stride)
pool_size = tuple(
utils.scale_mutable_sequence(pool_size, 1.0 / output_stride))
logging.info('Setting pooling size to %s', pool_size)
self.set_pool_size(pool_size)
# Variables for multi-scale inference.
self._add_flipped_images = config.evaluator_options.add_flipped_images
if not config.evaluator_options.eval_scales:
self._eval_scales = [1.0]
else:
self._eval_scales = config.evaluator_options.eval_scales
if self._is_max_deeplab and (
self._add_flipped_images or len(self._eval_scales) > 1):
raise ValueError(
'MaX-DeepLab does not support multi-scale inference yet.')
def call(self,
input_tensor: tf.Tensor,
training: bool = False) -> Dict[Text, Any]:
"""Performs a forward pass.
Args:
input_tensor: An input tensor of type tf.Tensor with shape [batch, height,
width, channels]. The input tensor should contain batches of RGB images.
training: A boolean flag indicating whether training behavior should be
used (default: False).
Returns:
A dictionary containing the results of the specified DeepLab architecture.
The results are bilinearly upsampled to input size before returning.
"""
# Normalize the input in the same way as Inception. We normalize it outside
# the encoder so that we can extend encoders to different backbones without
# copying the normalization to each encoder. We normalize it after data
# preprocessing because it is faster on TPUs than on host CPUs. The
# normalization should not increase TPU memory consumption because it does
# not require gradient.
input_tensor = input_tensor / 127.5 - 1.0
# Get the static spatial shape of the input tensor.
_, input_h, input_w, _ = input_tensor.get_shape().as_list()
if training:
result_dict = self._decoder(
self._encoder(input_tensor, training=training), training=training)
result_dict = self._resize_predictions(
result_dict,
target_h=input_h,
target_w=input_w)
else:
result_dict = collections.defaultdict(list)
# Evaluation mode where one could perform multi-scale inference.
scale_1_pool_size = self.get_pool_size()
logging.info('Eval with scales %s', self._eval_scales)
for eval_scale in self._eval_scales:
# Get the scaled images/pool_size for each scale.
scaled_images, scaled_pool_size = (
self._scale_images_and_pool_size(
input_tensor, list(scale_1_pool_size), eval_scale))
# Update the ASPP pool size for different eval scales.
self.set_pool_size(tuple(scaled_pool_size))
logging.info('Eval scale %s; setting pooling size to %s',
eval_scale, scaled_pool_size)
pred_dict = self._decoder(
self._encoder(scaled_images, training=training), training=training)
# MaX-DeepLab skips this resizing and upsamples the mask outputs in
# self._post_processor.
pred_dict = self._resize_predictions(
pred_dict,
target_h=input_h,
target_w=input_w)
# Change the semantic logits to probabilities with softmax. Note
# one should remove semantic logits for faster inference. We still
# keep them since they will be used to compute evaluation loss.
pred_dict[common.PRED_SEMANTIC_PROBS_KEY] = tf.nn.softmax(
pred_dict[common.PRED_SEMANTIC_LOGITS_KEY])
# Store the predictions from each scale.
for output_type, output_value in pred_dict.items():
result_dict[output_type].append(output_value)
if self._add_flipped_images:
pred_dict_reverse = self._decoder(
self._encoder(tf.reverse(scaled_images, [2]), training=training),
training=training)
pred_dict_reverse = self._resize_predictions(
pred_dict_reverse,
target_h=input_h,
target_w=input_w,
reverse=True)
# Change the semantic logits to probabilities with softmax.
pred_dict_reverse[common.PRED_SEMANTIC_PROBS_KEY] = tf.nn.softmax(
pred_dict_reverse[common.PRED_SEMANTIC_LOGITS_KEY])
# Store the predictions from each scale.
for output_type, output_value in pred_dict_reverse.items():
result_dict[output_type].append(output_value)
# Set back the pool_size for scale 1.0, the original setting.
self.set_pool_size(tuple(scale_1_pool_size))
# Average results across scales.
for output_type, output_value in result_dict.items():
result_dict[output_type] = tf.reduce_mean(
tf.stack(output_value, axis=0), axis=0)
# Post-process the results.
result_dict.update(self._post_processor(result_dict))
if common.PRED_CENTER_HEATMAP_KEY in result_dict:
result_dict[common.PRED_CENTER_HEATMAP_KEY] = tf.squeeze(
result_dict[common.PRED_CENTER_HEATMAP_KEY], axis=3)
return 结 果:本人在遥感数据集上进行实验,有涨点效果。需要请关注留言。
预告一下:下一篇内容将继续分享深度学习算法相关改进方法。有兴趣的朋友可以关注一下我,有问题可以留言或者私聊我哦
PS:该方法不仅仅是适用改进YOLOv5,也可以改进其他的YOLO网络以及目标检测网络,比如YOLOv7、v6、v4、v3,Faster rcnn ,ssd等。
最后,希望能互粉一下,做个朋友,一起学习交流。