PyTorch可视化 | 可视化网络结构 | 使用TensorBoard可视化训练过程
文章目录
-
- 一、可视化网络结构
-
- 1.使用print函数打印模型基础信息
- 2.使用torchinfo可视化网络结构
- 二、使用TensorBoard可视化训练过程
-
- 1.TensorBoard简介与安装
-
- 1.1 TensorBoard的运行机制
- 1.2 TensorBoard安装
- 2.TensorBoard的使用
-
- 2.1 SummaryWriter
- 3.TensorBoard模型结构可视化
- 4.TensorBoard图像可视化
PyTorch基础篇:
- PyTorch基础知识 | 安装 | 张量 | 自动求导
- PyTorch主要组成模块 | 数据读入 | 数据预处理 | 模型构建 | 模型初始化 | 损失函数 | 优化器 | 训练与评估
- PyTorch主要组成模块 | hook函数 | 正则化weight decay与Dropout | 标准化
- PyTorch模型定义 | 模型容器 | 模型块 | 修改模型 | 模型读取与保存
- PyTorch进阶技巧 | 自定义损失函数 | 动态调整学习率 | 模型微调 | 半精度训练 | 使用argparse进行调参
- PyTorch可视化 | 可视化网络结构 | 使用TensorBoard可视化训练过程
一、可视化网络结构
随着深度神经网络做的的发展,网络的结构越来越复杂,我们也很难确定每一层的输入结构,输出结构以及参数等信息,这样导致我们很难在短时间内完成debug。因此掌握一个可以用来可视化网络结构的工具是十分有必要的。类似的功能在另一个深度学习库Keras中可以调用一个叫做model.summary()的API来很方便地实现,调用后就会显示我们的模型参数,输入大小,输出大小,模型的整体参数等。在PyTorch中可以使用torchinfo工具包来可视化网络结构。
1.使用print函数打印模型基础信息
import torchvision.models as models
model = models.resnet18()
print(model)
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=1000, bias=True)
)
我们可以发现单纯的print(model),只能得出基础构件的信息,既不能显示出每一层的shape,也不能显示对应参数量的大小。
2.使用torchinfo可视化网络结构
trochinfo的使用也是十分简单,我们只需要使用torchinfo.summary()就行了,必需的参数分别是model,input_size[batch_size,channel,h,w],更多参数可以参考documentation。
import torchvision.models as models
from torchinfo import summary
resnet18 = models.resnet18() # 实例化模型
summary(resnet18, (1, 3, 224, 224)) # 1:batch_size 3:图片的通道数 224: 图片的高宽
torchinfo的结构化输出如下:
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
ResNet -- --
├─Conv2d: 1-1 [1, 64, 112, 112] 9,408
├─BatchNorm2d: 1-2 [1, 64, 112, 112] 128
├─ReLU: 1-3 [1, 64, 112, 112] --
├─MaxPool2d: 1-4 [1, 64, 56, 56] --
├─Sequential: 1-5 [1, 64, 56, 56] --
│ └─BasicBlock: 2-1 [1, 64, 56, 56] --
│ │ └─Conv2d: 3-1 [1, 64, 56, 56] 36,864
│ │ └─BatchNorm2d: 3-2 [1, 64, 56, 56] 128
│ │ └─ReLU: 3-3 [1, 64, 56, 56] --
│ │ └─Conv2d: 3-4 [1, 64, 56, 56] 36,864
│ │ └─BatchNorm2d: 3-5 [1, 64, 56, 56] 128
│ │ └─ReLU: 3-6 [1, 64, 56, 56] --
│ └─BasicBlock: 2-2 [1, 64, 56, 56] --
│ │ └─Conv2d: 3-7 [1, 64, 56, 56] 36,864
│ │ └─BatchNorm2d: 3-8 [1, 64, 56, 56] 128
│ │ └─ReLU: 3-9 [1, 64, 56, 56] --
│ │ └─Conv2d: 3-10 [1, 64, 56, 56] 36,864
│ │ └─BatchNorm2d: 3-11 [1, 64, 56, 56] 128
│ │ └─ReLU: 3-12 [1, 64, 56, 56] --
├─Sequential: 1-6 [1, 128, 28, 28] --
│ └─BasicBlock: 2-3 [1, 128, 28, 28] --
│ │ └─Conv2d: 3-13 [1, 128, 28, 28] 73,728
│ │ └─BatchNorm2d: 3-14 [1, 128, 28, 28] 256
│ │ └─ReLU: 3-15 [1, 128, 28, 28] --
│ │ └─Conv2d: 3-16 [1, 128, 28, 28] 147,456
│ │ └─BatchNorm2d: 3-17 [1, 128, 28, 28] 256
│ │ └─Sequential: 3-18 [1, 128, 28, 28] 8,448
│ │ └─ReLU: 3-19 [1, 128, 28, 28] --
│ └─BasicBlock: 2-4 [1, 128, 28, 28] --
│ │ └─Conv2d: 3-20 [1, 128, 28, 28] 147,456
│ │ └─BatchNorm2d: 3-21 [1, 128, 28, 28] 256
│ │ └─ReLU: 3-22 [1, 128, 28, 28] --
│ │ └─Conv2d: 3-23 [1, 128, 28, 28] 147,456
│ │ └─BatchNorm2d: 3-24 [1, 128, 28, 28] 256
│ │ └─ReLU: 3-25 [1, 128, 28, 28] --
├─Sequential: 1-7 [1, 256, 14, 14] --
│ └─BasicBlock: 2-5 [1, 256, 14, 14] --
│ │ └─Conv2d: 3-26 [1, 256, 14, 14] 294,912
│ │ └─BatchNorm2d: 3-27 [1, 256, 14, 14] 512
│ │ └─ReLU: 3-28 [1, 256, 14, 14] --
│ │ └─Conv2d: 3-29 [1, 256, 14, 14] 589,824
│ │ └─BatchNorm2d: 3-30 [1, 256, 14, 14] 512
│ │ └─Sequential: 3-31 [1, 256, 14, 14] 33,280
│ │ └─ReLU: 3-32 [1, 256, 14, 14] --
│ └─BasicBlock: 2-6 [1, 256, 14, 14] --
│ │ └─Conv2d: 3-33 [1, 256, 14, 14] 589,824
│ │ └─BatchNorm2d: 3-34 [1, 256, 14, 14] 512
│ │ └─ReLU: 3-35 [1, 256, 14, 14] --
│ │ └─Conv2d: 3-36 [1, 256, 14, 14] 589,824
│ │ └─BatchNorm2d: 3-37 [1, 256, 14, 14] 512
│ │ └─ReLU: 3-38 [1, 256, 14, 14] --
├─Sequential: 1-8 [1, 512, 7, 7] --
│ └─BasicBlock: 2-7 [1, 512, 7, 7] --
│ │ └─Conv2d: 3-39 [1, 512, 7, 7] 1,179,648
│ │ └─BatchNorm2d: 3-40 [1, 512, 7, 7] 1,024
│ │ └─ReLU: 3-41 [1, 512, 7, 7] --
│ │ └─Conv2d: 3-42 [1, 512, 7, 7] 2,359,296
│ │ └─BatchNorm2d: 3-43 [1, 512, 7, 7] 1,024
│ │ └─Sequential: 3-44 [1, 512, 7, 7] 132,096
│ │ └─ReLU: 3-45 [1, 512, 7, 7] --
│ └─BasicBlock: 2-8 [1, 512, 7, 7] --
│ │ └─Conv2d: 3-46 [1, 512, 7, 7] 2,359,296
│ │ └─BatchNorm2d: 3-47 [1, 512, 7, 7] 1,024
│ │ └─ReLU: 3-48 [1, 512, 7, 7] --
│ │ └─Conv2d: 3-49 [1, 512, 7, 7] 2,359,296
│ │ └─BatchNorm2d: 3-50 [1, 512, 7, 7] 1,024
│ │ └─ReLU: 3-51 [1, 512, 7, 7] --
├─AdaptiveAvgPool2d: 1-9 [1, 512, 1, 1] --
├─Linear: 1-10 [1, 1000] 513,000
==========================================================================================
Total params: 11,689,512
Trainable params: 11,689,512
Non-trainable params: 0
Total mult-adds (G): 1.81
==========================================================================================
Input size (MB): 0.60
Forward/backward pass size (MB): 39.75
Params size (MB): 46.76
Estimated Total Size (MB): 87.11
==========================================================================================
我们可以看到torchinfo提供了更加详细的信息,包括模块信息(每一层的类型、输出shape和参数量)、模型整体的参数量、模型大小、一次前向或者反向传播需要的内存大小等。
二、使用TensorBoard可视化训练过程
1.TensorBoard简介与安装
TensorBoard是一种可视化工具。在训练过程中,我们要可视化训练过程,用来监控我们当前训练的训练状态。TensorBoard是TensorFlow中强大的可视化工具,但目前PyTorch已支持TensorBoard的使用,支持标量、图像、文本、音频、视频和Eembedding等多种数据可视化。
1.1 TensorBoard的运行机制
python脚本中记录可视化的数据- 将数据存储在硬盘中,以
event file的形式存储
- 在终端使用
TensorBoard工具读取event file的形式数据,TensorBoard工具在Web端进行可视化

网址即为可视化后的网址
1.2 TensorBoard安装
在conda中直接输入pip install tensorboard来进行安装
2.TensorBoard的使用
2.1 SummaryWriter
class SummaryWriter(object):
def __init__(self, log_dir=None, comment='',
purge_step=None, max_queue=10,
flush_secs=120, filename_suffix=''):
...
功能:提供创建event file的高级接口
主要属性:
log_dir:event file输出文件夹comment:不指定log_dir时,文件夹后缀filename_suffix:event file文件名后缀
下面展示这三个参数的使用
import os
import numpy as np
import matplotlib.pyplot as plt
from torch.utils.tensorboard import SummaryWriter
log_dir = "./train_log/test_log_dir"
writer = SummaryWriter(log_dir=log_dir, comment='_scalars', filename_suffix="12345678")
for x in range(100):
writer.add_scalar('y=pow_2_x', 2 ** x, x)
writer.close()

import os
import numpy as np
import matplotlib.pyplot as plt
from torch.utils.tensorboard import SummaryWriter
log_dir = "./train_log/test_log_dir"
writer = SummaryWriter(comment='_scalars', filename_suffix="12345678")
for x in range(100):
writer.add_scalar('y=pow_2_x', 2 ** x, x)
writer.close()

主要方法:
-
add_scalaradd_scalar(tag, scalar_value, global_step=None, walltime=None)功能:记录标量,缺点是只能记录一条曲线
tag:标签名,唯一标识scalar_value:要记录的标量global_step:x轴
-
add_scalars()add_scalars(main_tag, tag_scalar_dict, global_step=None, walltime=None)main_tag:标签tag_scalar_dict:key是变量的tag,value是变量的值global_step:x轴
上述两个方法的使用如下:
import os
import numpy as np
import matplotlib.pyplot as plt
from torch.utils.tensorboard import SummaryWriter
max_epoch = 100
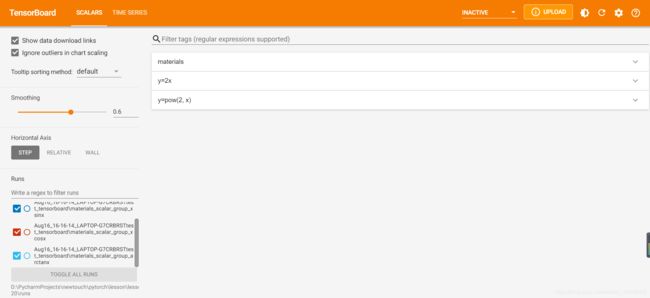
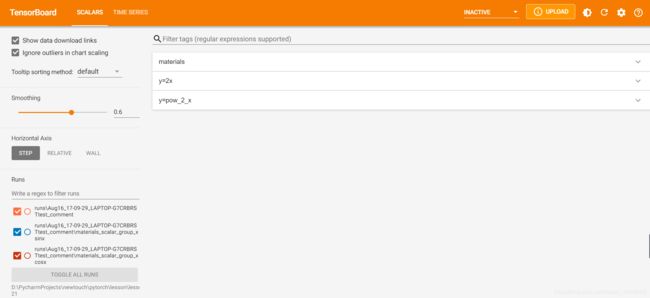
writer = SummaryWriter(comment='test_comment', filename_suffix="test_suffix")
for x in range(max_epoch):
writer.add_scalar('y=2x', x * 2, x)
writer.add_scalar('y=pow_2_x', 2 ** x, x)
writer.add_scalars('materials/scalar_group', {"xsinx": x * np.sin(x),
"xcosx": x * np.cos(x)}, x)
writer.close()
生成的事件文件为:
此时,在终端可视化后可得

点击这个网址,会使用默认浏览器打开可视化界面
-
add_histogram()add_histogram(tag, values, global_step=None, bins='tensorflow', walltime=None)功能:统计直方图与多分位数折线图,用于分析模型参数分布与梯度分布是非常有用的
tag:标签名,唯一标识values:要统计的参数global_step:y轴bins:取直方图的bins
import os
import numpy as np
import matplotlib.pyplot as plt
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter(comment='test_comment', filename_suffix="test_suffix")
for x in range(2):
np.random.seed(x)
# 等差分布
data_union = np.arange(100)
# 正态分布
data_normal = np.random.normal(size=1000)
writer.add_histogram('distribution union', data_union, x)
writer.add_histogram('distribution normal', data_normal, x)
plt.subplot(121).hist(data_union, label="union")
plt.subplot(122).hist(data_normal, label="normal")
plt.legend()
plt.show()
writer.close()

在tensorboard的wed端显示:
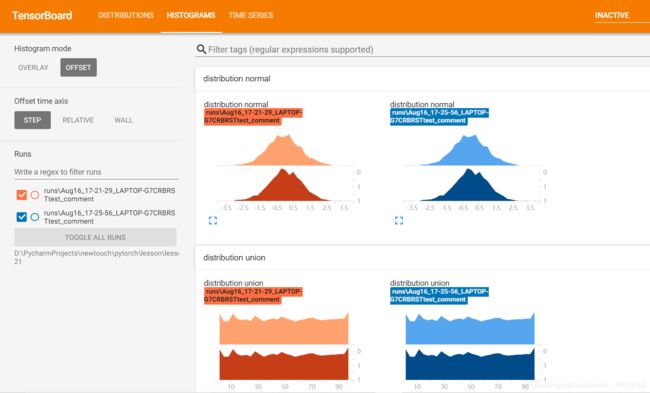
3.TensorBoard模型结构可视化
首先定义模型:
import torch.nn as nn
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3,out_channels=32,kernel_size = 3)
self.pool = nn.MaxPool2d(kernel_size = 2,stride = 2)
self.conv2 = nn.Conv2d(in_channels=32,out_channels=64,kernel_size = 5)
self.adaptive_pool = nn.AdaptiveMaxPool2d((1,1))
self.flatten = nn.Flatten()
self.linear1 = nn.Linear(64,32)
self.relu = nn.ReLU()
self.linear2 = nn.Linear(32,1)
self.sigmoid = nn.Sigmoid()
def forward(self,x):
x = self.conv1(x)
x = self.pool(x)
x = self.conv2(x)
x = self.pool(x)
x = self.adaptive_pool(x)
x = self.flatten(x)
x = self.linear1(x)
x = self.relu(x)
x = self.linear2(x)
y = self.sigmoid(x)
return y
writer = SummaryWriter('./runs')
model = Net()
输出如下:
Net(
(conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1))
(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv2): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1))
(adaptive_pool): AdaptiveMaxPool2d(output_size=(1, 1))
(flatten): Flatten(start_dim=1, end_dim=-1)
(linear1): Linear(in_features=64, out_features=32, bias=True)
(relu): ReLU()
(linear2): Linear(in_features=32, out_features=1, bias=True)
(sigmoid): Sigmoid()
)
可视化模型的思路是给定一个输入数据,前向传播后得到模型的结构,再通过TensorBoard进行可视化,使用add_graph:
writer.add_graph(model, input_to_model = torch.rand(1, 3, 224, 224))
writer.close()
展示结果如下(其中框内部分初始会显示为“Net",需要双击后才会展开):
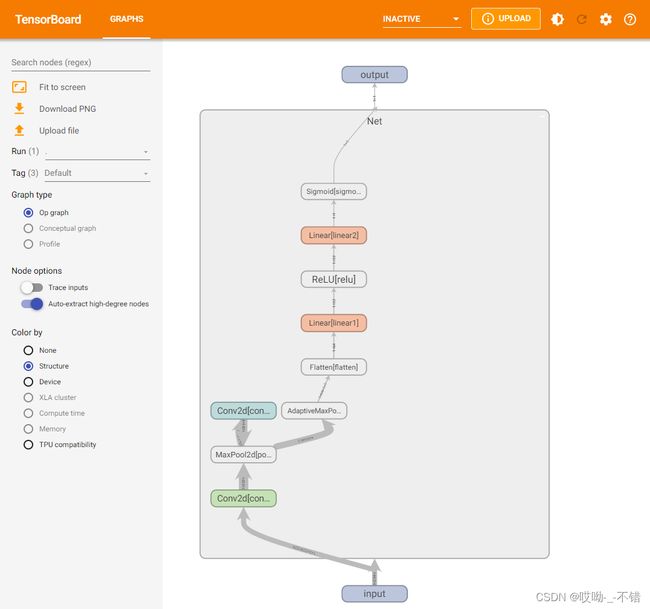
4.TensorBoard图像可视化
当我们做图像相关的任务时,可以方便地将所处理的图片在tensorboard中进行可视化展示。
- 对于单张图片的显示使用
add_image - 对于多张图片的显示使用
add_images - 有时需要使用
torchvision.utils.make_grid将多张图片拼成一张图片后,用writer.add_image显示
这里我们使用torchvision的CIFAR10数据集为例:
import torchvision
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
transform_train = transforms.Compose(
[transforms.ToTensor()])
transform_test = transforms.Compose(
[transforms.ToTensor()])
train_data = datasets.CIFAR10(".", train=True, download=True, transform=transform_train)
test_data = datasets.CIFAR10(".", train=False, download=True, transform=transform_test)
train_loader = DataLoader(train_data, batch_size=64, shuffle=True)
test_loader = DataLoader(test_data, batch_size=64)
images, labels = next(iter(train_loader))
# 仅查看一张图片
writer = SummaryWriter('./pytorch_tb')
writer.add_image('images[0]', images[0])
writer.close()
# 将多张图片拼接成一张图片,中间用黑色网格分割
# create grid of images
writer = SummaryWriter('./pytorch_tb')
img_grid = torchvision.utils.make_grid(images)
writer.add_image('image_grid', img_grid)
writer.close()
# 将多张图片直接写入
writer = SummaryWriter('./pytorch_tb')
writer.add_images("images",images,global_step = 0)
writer.close()
依次运行上面三组可视化(注意不要同时在notebook的一个单元格内运行),得到的可视化结果如下:

参考:
- PyTorch可视化