使用深度学习的PointNet直接从无人机载激光雷达数据中分割单个树冠
Abstract
从扫描点云中准确分割单个树冠是森林生物量监测和森林生态管理的一项基本任务。激光雷达作为森林调查的主流工具,正在推进森林数据获取的模式。在这项研究中,我们执行了一个新的深度学习框架,直接处理属于四种森林类型(即苗圃基地、修道院花园、混交林和落叶林)的森林点云,以实现ITC分割。该方法的具体步骤如下:首先,采用体素化策略将采集到的不同森林类型的不同树种的点云细分为多个体素。这些包含点云的体素被用作PointNet深度学习框架的训练样本,以在体素尺度上识别树冠。其次,在初始分割结果的基础上,利用与高度相关的梯度信息精确地刻画出每个树冠的边界。同时,将反演的单木树冠宽度与实测值进行比较,验证了方法的有效性。在四种森林类型中,我们的结果显示苗圃基地的表现最好(树冠检出率 r = 0.90 r=0.90 r=0.90;树冠宽度估计 R 2 > 0.94 R^2>0.94 R2>0.94,均方根误差 ( ( ( RMSE) < 0.2 m ) <0.2 \mathrm{~m}) <0.2 m))。寺院花园和混交林也取得了良好的表现,它们具有复杂的森林结构、复杂的树枝交叉和不同的建筑类型,寺院花园的 r = 0.85 , R 2 > 0.88 r=0.85, R^2>0.88 r=0.85,R2>0.88和RMSE < 0.6 <0.6 <0.6米,混交林的 r = 0.80 , R 2 > 0.85 r=0.80, R^2>0.85 r=0.80,R2>0.85和RMSE < 0.8 m <0.8 \mathrm{~m} <0.8 m米。对于树冠落叶分布在整个林地的第四种森林地块类型,我们实现了 r = 0.82 , R 2 > 0.79 r=0.82, R^2>0.79 r=0.82,R2>0.79和RMSE < 0.7 m <0.7 \mathrm{~m} <0.7 m米的性能。我们的方法提出了一个受深度学习技术和计算机图形学理论启发的鲁棒框架,该框架解决了ITC分割问题,并检索了各种森林条件下的森林参数。
关键词: 深度学习;单个树冠分割;机载激光雷达数据;计算机图形学
1. Introduction
单个树的准确分离在树参数反演中起着至关重要的作用。森林参数[1],例如树木位置、树高、树冠密度、树冠宽度、树种和胸径(DBH),对于森林资源管理、实地清查和造林活动执行至关重要[2] .传统的树木结构参数获取通常是通过现场测量,但这个过程非常耗时、劳动密集且具有破坏性[3]。光探测和测距(LiDAR)是一种主动遥感技术,由于其高精度和高效率使其成为获取详细和准确目标表型数据的最有效的测量技术之一[4]。在承载平台方面,激光扫描系统可分为四类:机载激光扫描(ALS)[5]、星基激光扫描(SLS)[6]、车载激光扫描(VLS)[7]和地面激光扫描 (TLS) [8]。与ALS类似,无人机(UAV)为激光雷达数据采集提供了替代平台,在低速和低空飞行时可以降低成本并提供更密集的激光雷达点[9]。
如上所述,单个树冠的检测和分割是准确估计单个树结构属性的基本步骤[10]。我们将现有的单棵树冠(ITC)分割方法分为两大类,它们广泛用于林业领域:(1)基于树冠高度模型(CHM)的方法[11],它使用图像处理来分割单个树冠,然后使用局部最大值来定义树顶的位置。还采用了标记控制的分水岭算法[12]、基于图的分割算法[13]和基于拓扑关系的局部轮廓扩展[14]等算法,根据检测到的树顶位置完成树冠分割。然而,这些算法相对较低的准确度总是由不均匀、互锁和阻塞的檐篷造成的[15]。(2)基于点的方法是一种需要大量计算3D点的方法。该方法可以有效减少树级别的信息损失[16],避免在生成CHM过程中点云插值造成的错误,如K-means聚类[17]、mean-shift算法[18] 、体素空间投影[19]、自适应多尺度滤波器[3]和区域增长方法[20]。然而,对于树冠可能极其不规则且经常严重相交的天然林,这些方法对单个树冠的准确分割结果仍有待提高。
深度学习作为机器学习的一个新领域,已广泛应用于图像分类、目标检测和定位等方面[21]。使用卷积神经网络(CNN)的深度学习算法在二维(2D)图像[22]的自动分类方面显示出令人鼓舞的结果,例如面部识别[23]、自动驾驶[24]、医学成像[25]和水果和蔬菜检测[26,27]。然而,更多的3D目标的表型结构[28]直接反映在点云中,如果使用2D网络,则会丢失原始信息和空间特征。因此,许多研究团体提出了3D目标检测。
目前,随着激光扫描技术的发展,3D深度学习受到了极大的关注。基于深度学习的3D点云识别方法可分为四类:(1)基于特征的方法[29],从点云中提取特征描述符,然后使用全连接网络对形状进行分类。然而,这种方法受到提取特征的表示能力的限制;(2)多视图方法[30]应用2D卷积网络对2D图像进行分类,使用投影策略从不同角度转换3D点云或形状。基于多视图的方法在分类任务中取得了很好的性能[31],但在转化为2D图像的过程中丢失了原始的3D空间位置信息;(3)基于体素化的方法,将无序的点云转化为连续排列的体素网格,并通过3D卷积神经网络对体素网格进行分类[30,32]。基于体素化的方法可以有效地保留每个体素中点云的原始空间信息,有利于后续细化处理,以准确描绘目标。比较上述三种方法的性能,基于体素的方法使用分治策略[33]从所研究的复杂场景的全部收集数据中识别小目标,然后将识别结果拼接在一起以实现从整个收集的数据中提取小目标。许多研究人员提出了一些相关的深度学习框架,例如PointNet[34]、Kd-Network[35]和 PointCNN[36]。 PointNet是一项开创性的工作,将每个体素中的原始点云作为深度学习的输入。模型PointNet为从目标分类、部分分割到场景语义解析的应用提供了统一的架构。
在本文中,提出了一种结合PointNet方法的新颖的个体树分割方法。本文的研究目标主要包括(1)利用无人机载激光LiDAR进行数据采集;(2)对训练和测试地点进行体素化;(3)将训练和测试站点的数据从体素化转换为PointNet训练和测试所需的格式;(4)基于PointNet对分割后的体素进行识别,利用梯度信息在每个体素中构造和描述树的边界,实现树冠(Individual Tree Crown,ITC)分割。我们方法的工作流程如图1所示。

图 1. 基于深度学习方法的个体树分割的主要步骤。
2. Materials and Methods
2.1. Study Area
研究区位于中国安徽省西南部池州市岐山风景区( 3 0 ∘ 3 8 ′ 15.8 9 ′ ′ N 30^{\circ} 38^{\prime} 15.89^{\prime \prime} \mathrm{N} 30∘38′15.89′′N, 11 7 ∘ 3 0 ′ 11.3 3 ′ ′ E 117^{\circ} 30^{\prime} 11.33^{\prime \prime} \mathrm{E} 117∘30′11.33′′E)(图2)。池州市作为国家森林城市,气候温暖,四季分明,雨量充沛,属暖湿亚热带季风气候。这里年平均降水量1400~2200毫米,年平均气温16.7℃,最冷月(1月)和最热月(7月)平均气温分别约为3.1℃和28.7℃。岐山总面积36平方公里,最高海拔868米。本区树种主要有水杉(Metasequoia glyptostroboides Hu & W. C. Cheng)、杉木(Cunninghamia lanceolata (Lamb.) Hook)、雪松(Cedrus deodara (Roxb.) G. Don)、杉木(Cedrus deodara (Roxb.) G. Don)、银杏 (Ginkgo biloba L.)、无患子 (Sapindus mukorossi Gaertn.)、苹果树 (Malus pumila Mill.)、杨树 (Populus L.)、樟脑 (Cinnamomum camphora (L.) Presl)、木棉 (Bombax malabaricum) 和蝗虫树(国槐)。如图2所示,4种试验场地类型,包括苗圃基地(试验场地1)、寺院花园(试验场地2)、混交林(试验场地3)和落叶林景观(试验场地4)。我们选择岐山风景区进行实验。此外,1号、2号、4号试验点位于山脚下,3号试验点位于山腰,地势崎岖不平。四个实验地点由建筑物、灌木和树木组成。
图 2. 研究区概况(a):中国安徽省池州市岐山风景区内的研究区和四个实验点的位置。 (b):从谷歌地球获取的遥感图像,其中不同颜色的矩形标记了不同实验地点的边缘。 (c ):照片显示四个实验地点的树木生长情况。
从4个实验点中提取的4个子集分别为1947.16、44596.64、60601.78和14780.11平方米,作为后续实验的研究区域。提取每个子集50%面积内的植被成分和建筑物作为训练样本。其余四个子集用作测试样本(与用作训练样本的子集不相交)。
2.2. Laser Data Acquisition
LiDAR数据是使用DJI FC6310无人机(UAV)[37]上的Velodyne HDL-32E传感器测量的。系统中的激光组可实现-30.67°到+10.67°的角度调节,提供360°的水平视野。该传感器每秒可输出约700,000个扫描点云,测量精度为±2cm。此外,该传感器具有穿透烟雾和雾气的优点,工作环境可以从-10°C到+60°C,大大提高了工作环境的冗余度。Velodyne LiDAR系统将激光扫描与SLAM(同时定位和建图)技术[38]相结合,快速完成每次扫描的配准,并为每个目标树生成高密度点云。在数据采集过程中,飞行速度、飞行高度和激光扫描重叠分别设置为18 m/s、60m(高于起飞位置水平)和40%。最终提取的点云存储在LAS 1.2格式。苗圃基地、寺院花园、混交林和落叶林栖息地采集的LiDAR数据的平均点密度分别为1511.30 pts m − 2 \mathrm{m}^{-2} m−2、1002.17 pts m − 2 \mathrm{m}^{-2} m−2、722.31 pts m − 2 \mathrm{m}^{-2} m−2和 502.34 pts m − 2 \mathrm{m}^{-2} m−2。
2.3. Data Pre-Processing
从激光扫描仪扫描的实验点获取点云数据后,我们使用高斯滤波的方法[21]从扫描数据中去除噪声点。使用布模拟滤波(CSF)[39]方法将去噪后的点云分为地上点和地面点。然后,根据不同的体素大小对地上点进行体素化,并将一个体素内的点随机采样到1024个点。我们根据PointNet的要求将构成训练和测试集的每个体素中的点云转换为HDF5[40]格式。在本实验中,HDF5文件的标准包括两部分:数据和标签。在数据部分,将扫描点作为训练和测试点转换的数据是一个 n × 1024 × 3 n \times 1024 \times 3 n×1024×3的数组,其中n表示分割的输入体素的总数;1024表示一个体素中随机采样点云的数量,3表示维度,即空间位置(x,y,z)。标签用于识别某些属性或特征,或分类或包含的目标。
2.3.1. Training Data
在本研究中,我们手动生成了三种类型的训练数据,其中包括:(1)属于多种树种并处于两种植物生理状态(有叶和无叶)下的单棵树,(2)不同的中国建筑风格,如宫殿、城墙、寺庙和房屋,以及(3)其他对象,包括裸地、林下植被和关于单棵树(通常< 20%)或相邻树交叉部分的小部分点云。苗圃基地、寺院花园、混交林地和落叶森林景观的训练样本(树木和建筑物)数分别为501(树木)、168(树木)/334(建筑物)、426(树木)和166(树木)。图3显示了部分训练数据,其中手动提取的单棵树或部分建筑物的点云被限制在一个体素中。
大量的样本是高精度训练的基础,因此尽可能多的训练数据来训练神经网络以避免过拟合是值得的。在我们的研究中,数据扩充[41]被用来解决这个问题。数据扩充方法是一种增加可用于训练模型的数据的多样性而不实际收集新数据的策略,从而提高模型的准确性。我们基于每个体素中的整个点云沿着垂直轴以随机角度旋转来生成新的训练数据集。同时,沿着随机向量以小偏移移动每个体素中的每个点的策略,即通过具有零均值和小标准差(范围为0.02–0.06)的高斯噪声来抖动每个训练样本的每个点的位置。结果,训练样本的数量被广泛地扩展到10240个。
2.3.2. Testing Data
上述四个实验地点,即苗圃基地、寺院花园、混交林和落叶林,用于测试该方法的准确性和鲁棒性。试验地点1、2、3和4中试验地点的树木数量分别为522、160、456和167株(表1)。去除噪声点后,通过体素化将相应实验点的四个扫描点集 V 1 , V 2 , V 3 , V 4 V_1, V_2, V_3, V_4 V1,V2,V3,V4细分成许多体素。然后,根据HDF5标准通过每次体素化(即 v j , v j ∈ V v_j, v_j \in V vj,vj∈V)获得每个体素中的点云。

图 3.为PointNet网络收集的部分点云训练集示意图。第1到10行是针对不同树种提取相应扫描点的单棵树,即(a)水杉,(b)杉木,(c)雪松,(d)银杏,(e)无患子,(f)苹果树,(g)杨树、(h)樟树、(i)木棉和(j)槐树。最后五行(k-o)是建筑物的一部分,包括宫殿、城墙、寺庙和不同中国建筑风格的房屋,以及其他物体,包括裸露的地面、下层植被和关于一棵树的一小部分点云(通常<20%) 或相邻树木的交叉部分。
表 1. 我们的深度学习方法的数据集的详细描述。
NT:树的数量。NP:扫描点数。NPPT:每棵树的平均扫描点数。

2.4. Training by PointNet
PointNet 是第一个直接处理无序点云数据的深度神经网络。 PointNet具有三个核心构建块,即转换网络 (T-Net)、作为对称函数的最大池化层以聚合来自所有体素的信息和多层感知器 (MLP) 网络。点云 p i j ( x i , y i , z i ) p_i^j\left(x_i, y_i, z_i\right) pij(xi,yi,zi)表示为属于扫描点集 P ⊂ R 3 P \subset R^3 P⊂R3的第j个体素中的3D扫描点,其中每个点 p p p是其 ( x , y , z ) (x, y, z) (x,y,z)坐标的向量,作为点的通道。点云有三个核心属性,包括(1)是无序的,它表示一个消耗N个3D点集的网络,需要对N个保持不变!输入集在数据馈送顺序中的排列,(2)点之间的相互作用,这意味着点不是孤立的,相邻点形成一个有意义的子集,以及(3)变换下的不变性[42],这表示学习到的点集的表示应该对某些变换是不变的。因此,有必要在代数组合学中设计一个对称函数,该函数的取值与体素中扫描点的阶数无关。 PointNet网络由对称方程(1)表示。
f ( p 1 j , p 2 j , … , p i j , … , p 1024 j ) = γ ( max i = 1 , … , 1024 { h ( p i j ) } ) (1) f\left(p_1^j, p_2^j, \ldots, p_i^j, \ldots, p_{1024}^j\right)=\gamma\left(\max _{i=1, \ldots, 1024}\left\{h\left(p_i^j\right)\right\}\right) \tag{1} f(p1j,p2j,…,pij,…,p1024j)=γ(i=1,…,1024max{h(pij)})(1)
式中, p 1 j , p 2 j , … , p i j , … , p 1024 j p_1^j, p_2^j, \ldots, p_i^j, \ldots, p_{1024}^j p1j,p2j,…,pij,…,p1024j是第j个体素中的输入无序点云; p i j ∈ P p_i^j \in P pij∈P; 1024是每个体素的输入点云的数量; f f f是连续集函数,将一组点映射到一个向量; γ \gamma γ表示多层感知器网络, h h h表示单个变量函数和最大池化函数的组合。无论点云的输入顺序如何,等式(1)中的连续集函数 f f f的值都是不变的。
图4显示了PointNet的网络架构。网络的输入是包含n个体素和一个体素内的1024个点的三维点云的三维坐标(n×1024×3)。 T-Net是一个可以预测仿射变换矩阵的迷你网络。网络中的第一个T-Net生成仿射变换矩阵,对点云的旋转、平移等变化进行归一化处理。此时,第一个T-Net的输入是原始点云数据,第一个T-Net的输出(对齐数据)是一个3×3的旋转矩阵。然后,将原始3D点数据乘以第一个T-Net学习到的变换矩阵(3×3),实现数据对齐,保证模型对特定空间变换的不变性。每个体素中点云(1024×3)的对齐数据通过多层感知器(MLP(64, 64)),括号中显示给定的层大小数量,以获得矩阵(1024×64)。 MLP的全连接层由图4上部的三个虚线框表示。之后,为每个体素提取64维特征,然后通过第二次特征空间变换预测64×64的变换矩阵T-Net预测网络的矩阵,应用于特征以实现特征对齐。同理,将矩阵(1024×64)乘以变换矩阵(64×64),实现特征的对齐。然后,使用第二个MLP(64,128,1024)基于每个体素进行特征提取,直到特征的维度改为1024,然后通过最大池化层提取每个体素的全局特征向量。最后,1×1024维度的全局特征通过第三个MLP(512,256,3),得到3个分类,其中3代表分类的类别(即标签定义的类别个数,0代表树,1代表建筑物,2代表其他物体)。每个类别对应于点云的分类分数。然后,通过基于SoftMax函数的激活层,可以得到每个体素中点云的预测概率。

图 4. PointNet的架构。该架构主要由两个变换矩阵预测网络(T-Net)、三个多层感知器(MLP)和一个最大池化层组成。该网络将一个体素中的1024个点作为输入,应用输入和特征变换,然后通过最大池化聚合点特征。输出是类分类的预测可能性。
2.5. The loss Function of the Training Process
SoftMax交叉熵函数(公式(2))作为深度学习网络的损失函数。在训练过程中,损失函数定义如下:
Loss = − 1 k + 1 ∑ l = 0 k L l + weight regre L reg = − 1 k + 1 ∑ ζ ∑ l = 0 k ( indic ζ , l ∙ log ( y ^ l j ) ) + weight regre L r e g (2) \text { Loss }=-\frac{1}{k+1} \sum_{l=0}^k L_l+\text { weight }_{\text {regre }} L_{\text {reg }}=-\frac{1}{k+1} \sum_\zeta \sum_{l=0}^k\left(\text { indic }_{\zeta, l} \bullet \log \left(\hat{y}_l^j\right)\right)+\text { weight }_{\text {regre }} L_{r e g} \tag{2} Loss =−k+11l=0∑kLl+ weight regre Lreg =−k+11ζ∑l=0∑k( indic ζ,l∙log(y^lj))+ weight regre Lreg(2)
indic ζ , l = { [ 0 , 0 , 1 ] The first category ζ = 0 [ 0 , 1 , 0 ] The sec ond category ζ = 1 [ 1 , 0 , 0 ] The third category ζ = 2 (3) \text { indic }_{\zeta, l}= \begin{cases}{[0,0,1]} & \text { The first category } \zeta=0 \\ {[0,1,0]} & \text { The sec ond category } \zeta=1 \\ {[1,0,0]} & \text { The third category } \zeta=2\end{cases} \tag{3} indic ζ,l=⎩ ⎨ ⎧[0,0,1][0,1,0][1,0,0] The first category ζ=0 The sec ond category ζ=1 The third category ζ=2(3)
y ^ l j = softmax ( Z l j ) = e Z l j ∑ l = 0 2 e Z l j (4) \hat{y}_l^j=\operatorname{softmax}\left(Z_l^j\right)=\frac{e^{Z_l^j}}{\sum_{l=0}^2 e^{Z_l^j}} \tag{4} y^lj=softmax(Zlj)=∑l=02eZljeZlj(4)
Z l j = ω ∗ p j (5) Z_l^j=\omega * p^j \tag{5} Zlj=ω∗pj(5)
L reg = l 2 l o s s ( I − A A T ) (6) L_{\text {reg }}={l2loss} \left(I-A A^T\right) \tag{6} Lreg =l2loss(I−AAT)(6)
公式(2)中, i n d i c ζ , l { }_{i n d i c_{\zeta, l}} indicζ,l表示与分类数有关的指标。如果计算出的类别ζ与体素j的当前类别l相同,则该指标为1,否则为0。我们的工作,类别总数为3。因此, k = 2 k=2 k=2和 l = { 0 , 1 , 2 } l=\{0,1,2\} l={0,1,2}。•表示两个矩阵的点积。 L r e g L_{r e g} Lreg用于约束特征变换矩阵,其中 A A A是特征对齐矩阵(即从第二个T-Net得到的64×64的变换矩阵), I I I是单位矩阵.函数 l 2 l o s s l2_loss l2loss表示矩阵中每个元素的平方和然后除以2。这里,weight regre _{\text {regre }} regre 的值设置为0.001。 y ^ l j ∈ [ 0 , 1 ] \hat{y}_l^j \in[0,1] y^lj∈[0,1]是使用SoftMax函数的第j个体素的网络输出概率,表示输入体素属于第l个类别的概率, Z l j Z_l^j Zlj是经过神经网络分析后计算出的属于第l个类别的第j个体素中的点云的概率值。 ω ω ω是网络模型的线性权重, p j p^j pj是分段输入体素的第j个体素的点云。
深度卷积神经网络每层的weight(ω)通过随机梯度下降(SGD)算法进行更新[43]。层是一个容器,通常接收加权输入,用一组非线性函数对其进行转换,然后将这些值作为输出传递给下一层。当训练损失函数小于某个损失阈值(即收敛)时,则停止训练,不再改变固定网络各层的权重,从而得到训练好的深度卷积神经网络。
2.6. Individual Tree Segmentation
测试过程包括以下步骤。通过体素化将每个测试站点的点云分配给连续分布的体素。然后,利用PointNet框架通过训练阶段学习到的参数对每个体素中的细分点云进行分析,得到每个体素的分类结果。对于识别为树木的体素中的点云,我们根据与高度相关的梯度信息细化了树冠边界描绘,并准确描绘了超出定义体素边界限制的树冠边界。
首先,被分类为树木类别的体素中的点云被映射到数字表面模型(DSM)的均匀分布的平面光栅C中[44]。栅格单元的高程值 c k ∈ C , k = 1 , 2 , … m 2 c_k \in C, k=1,2, \ldots m^2 ck∈C,k=1,2,…m2等于单元内点的最大高度值,其中 m 2 m^2 m2表示从体素内点云导出的栅格中包含的单元数量。
然后,采用局部最大值搜索算法[45]在每个体素中找到树顶的位置。在下文中用 ∇ \nabla ∇表示的哈密尔顿算子代表由x、y(水平)和z(垂直)轴定义的三维空间中单元的梯度。相应的等式如下:
∇ c r , p , q = ∂ C ∂ x u ⃗ + ∂ C ∂ y v ⃗ + ∂ C ∂ z w ⃗ (7) \nabla c_{r, p, q}=\frac{\partial C}{\partial x} \vec{u}+\frac{\partial C}{\partial y} \vec{v}+\frac{\partial C}{\partial z} \vec{w} \tag{7} ∇cr,p,q=∂x∂Cu+∂y∂Cv+∂z∂Cw(7)
在等式(7)中, u ⃗ , v ⃗ \vec{u}, \vec{v} u,v和 w ⃗ \vec{w} w分别是x、y和z方向上的单位向量。梯度是哈密顿算子直接作用于每个体素的DSM C的结果。在我们的研究中,每个体素在栅格单元分辨率下的DSM为11 × 11。 ∂ C ∂ x , ∂ C ∂ y \frac{\partial C}{\partial x}, \frac{\partial C}{\partial y} ∂x∂C,∂y∂C和 ∂ C ∂ z \frac{\partial C}{\partial z} ∂z∂C是沿x、y的每个栅格单元中的最高扫描点的导数和z方向,分别。树冠外围的表型特征呈现向下的层次结构,即树冠表面像素的高度值从峰顶向周围逐渐减小。因此,相邻两棵树之间必然存在鞍点(最低点,该点的梯度接近于0)。辅助计算每个单元格的梯度信息,通过等高线提取方法[46]定位相邻树冠之间的谷线,该方法类似于基于节点深度的图切割方法。最后,如果两个相邻体素内的部分点云的高度值呈连续下降趋势,即沿相似方向连续梯度下降,则表明属于同一树冠的点云被细分为两部分体素化。因此,应合并一棵树冠的两个部分(图5)。
图 5. 示意图显示了基于高度相关梯度信息的21个相邻体素中点云的单个树冠分割。黑色长方体表示被PointNet分类为树的分割体素。(b,c)分别是图(a)中所示的黄色长方体的缩放区域的侧视图和俯视图。
与人工测量结果相比,评估了具有不同林分结构特征的选定测试点的分割结果。 TP(真阳性)表示正确分割的树的数量。 FN(假阴性)表示未检测到的分割树的数量(遗漏错误)。 FP表示(误报)现实中不存在但被我们的模型错误添加(委托错误)的分割树的数量。此外,三个测试点的r(召回率)、P(精度)和F(F-score)使用以下公式[47]计算:
r = T P T P + F N (8) r=\frac{T P}{T P+F N} \tag{8} r=TP+FNTP(8)
P = T P T P + F P (9) P=\frac{T P}{T P+F P} \tag{9} P=TP+FPTP(9)
F = 2 ∗ r ∗ P r + P (10) F=2 * \frac{r * P}{r+P} \tag{10} F=2∗r+Pr∗P(10)
其中r表示树的检测率,P表示检测树的正确性,F表示检测树的整体准确率。从公式中可以看出,高TP、低FN和低FP值代表树检测的高精度。
3. Results
3.1. Results of Training and Testing of the PointNet Model
除了在配备Intel® Core ™ i7-7700 CPU @2.80 GHz处理器(Intel Inc., Santa Clara, CA, USA)的windows 10 64位PC上执行的关于深度学习的部分之外的实验,和16GB内存。由于深度学习涉及自动化计算机系统以研究大量训练数据并且需要高计算能力,因此我们使用NVIDIA RTX 2080Ti GPU(NVIDIA Inc.,Santa Clara,CA,USA)代替CPU来减少我们的训练时间。在PointNet的模型中,学习率为0.0001,batch size为16,epoch数为200。训练损失和训练准确率如图6所示。总训练和测试时间约为100小时。

图 6.(a,b)是PointNet从输入体素进行树识别的训练精度值和训练损失值曲线。浅色区域的波动是由于在一批复杂样本中反复学习有效特征以识别体素是否为树而引起的,但整体上升趋势和曲线下降趋势表明训练的收敛效果更好。
随着学习过程的不断epoch,训练样本(每个体素中的点云)呈现出训练精度增加的趋势和训练损失减小的趋势,表明我们的PointNet是一个全局优化过程。在前25个epoch中,训练准确率和训练损失分别显着增加和减少。原因很可能是在处理3D目标分类中压倒性的样本时,模型PointNet表现出不兼容,因为它的梯度主要由这些容易分类的样本决定。在训练过程中,神经元网络批量遇到一些复杂的样本,例如一个体素包含多棵树的部分、单个树数据的一小部分或一些矮灌木,这损害了模型的学习效果,导致回归损失函数值的剧烈波动。在75个epoch后,训练样本的准确率和损失分别收敛到0.96和0.009,表明PointNet的拟合能力很强。图7是PointNet的模型得到的四个测试图的识别结果侧视图。


图 7. 使用PointNet模型对我们研究站点中属于四种林地类型的部分LiDAR数据的识别结果:(a)苗圃基地,(b)修道院花园,(c)混交林和(d)落叶林。用上面不同颜色的矩形简化表示,表示每个对应体素内下面点云的分类结果,其中(a1,b1,c1,d1)中的绿色、蓝色和红色矩形表示矩形下面的点云体素内分别被识别为树木、建筑物和其他物体。 (a2–a4,b2–b4,c2–c4,d2–d4) 显示了一些体素中点云的缩放分类结果。
表2列出了对四个测试点的个体素的定量评估。在实验中,体素大小的设置至关重要,会影响PointNet模型的精度。因此,我们尽可能根据四个测试点的树木特征(即树冠),设置不同的合适的体素规格(即每个测试点的东西和南北方向的平均树冠宽度作为体素的长度和宽度)。苗圃基地(试验点1)有相似树冠大小、树种和年龄的同质森林。因此,设置体素化的大小相对容易。对于不同类型的建筑,不同树种的修道院花园(试验点2),由于各种树种错综复杂的生长和不同的大小,设置体素的大小会很繁琐。对于具有各种大小的树冠的混交林(试验点3)、树枝的复杂交叉以及包含大约15%的亚树冠树、具有裸露树枝的落叶林(试验点4)、以及一些下部被周围灌木覆盖的树,很难确保一个体素包含一棵完整的树。
表 2. 用于识别树木的四个测试地点的单个体素的总体准确度评估。

T:识别为树的体素数。 B:识别为建筑物的体素数。 O:识别为其他目标的体素数。
通过初步森林调查获得的平均树冠大小用于定义体素的大小。在这里,我们定义了苗圃基地的长度、宽度和高度分别为1.35m、1.36m、4.92m,寺院花园为6.46 m、5.81m、26.96m,混交林为7.08m、6.59m、48.06m,落叶林分别为5.23m、5.2m、20.96m。
对于苗圃基地、寺院花园、混交林和落叶林四个试验点,树木的识别体素分别为470、136、365和137。对于苗圃基地,如图7(a2)所示,主要错误出现在包含扫描点的体素被认为是树冠未成熟和拓扑结构不明确的树苗的一小部分(例如,不是典型的塔形和伞形)。模型PointNet提取每个独立点的特征和全局点云的特征,很难从两个不同的目标中学习联合特征,这很可能导致从一个点云特征中提取点云特征后识别不正确,冠层形状不完整。通过分割获得的体素。当一个体素包含具有双峰分布的多棵树数据的一部分(即完整的树冠和相邻树冠的一小部分(<20%))时,模型将普遍学习完整的信息并始终识别整个点云在像树一样的体素中。
对于寺院花园来说,空间树形是一种几何原始形态,其表型特征如主干支撑着椭圆形或圆锥形的树冠,有别于具有规则表型特征的建筑物等刚性物体。当一个体素包含树木和建筑物的两个部分时,当包含树木和寺庙墙壁的体素时,由于表型特征不明确而容易误判时产生的假设错误。树木和建筑物混合中的点云总是被识别为非树,一个合理的解释是,高数据复杂度使深度学习网络从树中提取的有用信息恶化,使得点云的分类结果在体素不确定。体素中混合点云的分类精度可能受点云在体素中树的比例和机器学习的特征提取手段的影响。相比之下,在体素化后的建筑物截面的情况下取得了良好的性能。我们预计这个结果的主要原因是寺庙具有不同于树的规则表面特征,并且网络中的第一个T-Net生成了一个仿射变换矩阵来归一化点云的旋转、平移和其他变化。从多视角提供有效的空间和距离度量,并捕获与训练样本对应的语义特征匹配的地球和局部特征。
混交林地块具有多种树冠形状和丛生交织的枝叶丛,导致林干分布密度不均,树冠间有重叠遮蔽(图7(c2))。丰富的生物质森林创造了复杂且难以区分的激光雷达点模式,降低了深度学习网络的识别能力。因此,一些体素中包含的关于重叠树的点云被错误地识别为树。此外,部分树干歪斜、树体倾斜的树冠点云识别不准确,这与树冠向上结构大致对称分散的分枝结构不同,容易出现误分类。
对于含有无叶树木的落叶林,分类结果如图7d所示。在休眠期,树枝光秃的树木缺乏叶子元素。从树模型的全局结构判断,成功识别出许多树骨架。然而,有些情况仍然无法被网络识别,例如,少数树木下部被周围灌木覆盖,许多树木的树干或树枝不完整,被相邻的体素切除。此外,缺乏足够的落叶树训练样本也降低了深度学习网络的识别强度。
在基于PointNet模型的体素分类之后,使用2.6节中提到的方法进行树冠描绘。提取的单个树冠采用相同的颜色编码,如图8所示。
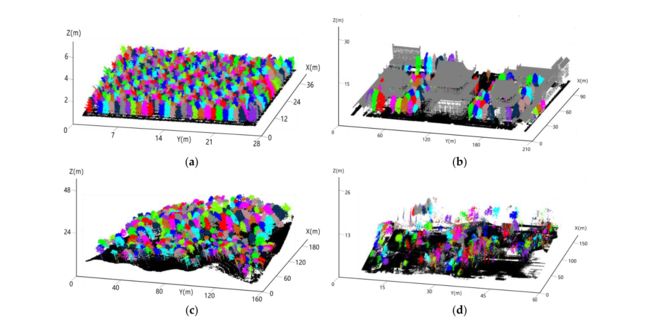
图 8. 显示我们对单个树冠分割结果的程序图,其中不同的颜色表示每棵树的分割结果。 (a-d) 分别显示苗圃基地、寺院花园、混交林和落叶林的部分分段激光雷达数据。
使用PointNet方法在四种不同类型的森林站点的树分割结果中实现了良好的性能(图8)。发现苗圃基地和寺院花园的整体分割精度(分别为r = 0.90和r = 0.85)(表3)高于混交林和落叶林(分别r=0.80和r=0.82)。对这种差异的一种解释是,苗圃基地的树龄相近,种植排列均匀,交叉生长的树枝较少,几乎没有林下植被,这使得体素包含较为完整的具有一定形态特征的树点云。寺院花园中有许多树冠近乎空间孤立,并通过人工修剪修改了形状。因此,有些树的树冠包裹紧密,便于利用与高度相关的梯度信息来实现单棵树的分割。与苗圃基地不同的是,混交落叶天然林由多种树种和灌木组成,枝条交错突出。深度学习模型和基于梯度的分割方法难以在因遮挡导致数据不足的森林冠层和处于休眠期的其他树木光秃秃、最外层外观不平滑的情况下分割树木,导致个体树木相对较差分割结果(分别为混交林 r = 0.80 和落叶林 r = 0.82)。4类林地因同树冠的多叶丛、强侧枝产生局部凸点、庙宇顶角上翘的屋檐被误识别为树梢等原因,产生了一定的委托误差。
表 3. 四个测试站点上单个树分割的准确性评估。

NT:地块中树木的数量。 NS:分割树的数量。 TP:正确分割的树的数量。 FN:未检测到的分割树的数量。 FP:现实中不存在但被我们的模型错误添加的分割树的数量。 r(召回):树检测率。 P(precision):检测到的树的正确性。 F(F-score):检测到的树的整体准确率。
3.2. Accuracy of Tree Crown Width Estimation
对于通过我们的方法分割的单棵树,从每个测试站点选择100棵树,计算南北方向( C b n C b_n Cbn)和东西方向( C b e C b_e Cbe)的树冠宽度,并与手动分割结果进行比较。还计算了系数 ( R 2 R^2 R2)、均方根误差 (RMSE) 和相对均方根误差(rRMSE)的相关性,以评估我们结果的定性方面。
对于四个测试点,苗圃基地的树冠宽度估计精度最高( R 2 = 94.4 ± 0.28 % R^2=94.4 \pm 0.28 \% R2=94.4±0.28%, RMSE = 0.13 ± 0.01 m =0.13 \pm 0.01 \mathrm{~m} =0.13±0.01 m和rRMSE = 9.59 ± 0.70 % =9.59 \pm 0.70 \% =9.59±0.70%)(图9),这可能归因于树冠的规则和均匀的几何形状,树枝交叉较少。混交林 ( R 2 = 85.105 ± 0.015 % R^2=85.105 \pm 0.015 \% R2=85.105±0.015%, RMSE = 0.74 ± 0.01 m =0.74 \pm 0.01 \mathrm{~m} =0.74±0.01 m和 r R M S E = 10.835 ± 0.245 % \mathrm{rRMSE}=10.835 \pm 0.245 \% rRMSE=10.835±0.245%) 和寺院花园 ( R 2 = 88.665 ± 0.285 % R^2=88.665 \pm 0.285 \% R2=88.665±0.285%, RMSE = 0.57 ± 0.01 m =0.57 \pm 0.01 \mathrm{~m} =0.57±0.01 m和 r R M S E = 9.31 ± 0.33 % \mathrm{rRMSE}=9.31 \pm 0.33 \% rRMSE=9.31±0.33%),合理的解释是部分树冠被周围高大的树木或建筑物挡住,导致林中部分被抑制的树木或部分树木的树冠宽度估计出现偏差就在建筑物旁边。对于落叶林地,我们的方法和手动测量之间的冠幅估计的一致性进一步降低。由于地块中有很多树光秃秃,没有叶子,很多树冠没有连续的滴水线和平滑的树冠表面,这导致生成的DSM有空的单元格或缺少高程数据的间隙。这些不利因素不利地影响梯度计算和冠宽测量。因此,对于最后一个图,获得了冠宽估计的相对较低的统计指数( R 2 = 79.94 ± 0.13 % R^2=79.94 \pm 0.13 \% R2=79.94±0.13%, RMSE = 0.61 ± 0.02 m =0.61 \pm 0.02 \mathrm{~m} =0.61±0.02 m和 r R M S E = 11.7 ± 0.35 % \mathrm{rRMSE}=11.7 \pm 0.35 \% rRMSE=11.7±0.35%)。

图 9. 散点图说明通过实地测量获得的树冠宽度与我们的方法对四种不同森林类型的比较结果,即(a)苗圃基地、(b)修道院花园、(c)混交林和(d)落叶林。
4. Discussion
4.1. The Advantages of Our Approach
从机载激光扫描数据中自动提取(分割)单个树木是树木表型和生物物理参数估计的重要先决条件[48]。目前,机器视觉算法和图像处理技术已广泛应用于个体树的分割。然而,当仅结合有限的几何空间信息时,很难处理具有相似高度和不同密度分布的聚类树。例如,高度相似且分布紧密的丛生树冠可能会被错误地检测为单个树梢并导致分割不足。此外,非树梢局部最大值可能被错误地检测为树梢并导致过度分割。对于基于树冠中心和点密度分布 [49] 的单个树木的分割,当树木延伸一侧的树冠或倾斜的树体遭受与邻近树木竞争性生长或环境影响时,预计会出现偏差,例如,飓风破坏或太阳辐照度分布不均匀。高密度扫描点簇通常出现在重叠的树冠、开放的枝叶密集的树枝或暴露在激光扫描传感器下的不必要和无遮挡的植物元素的结合区域内。因此,这些问题将导致单独的树分割减少,仅依赖于点云的有限特征。
深度学习尝试使用分层方式对数据中的高级抽象进行建模,通过从大量样本中提取有效特征并反复提高神经网络性能 [21],为机器提供了更强的识别目标的能力。此外,随着深度学习的快速发展,大量研究致力于以二维图像为原始输入数据的各种深度学习分类或分割任务,以实现个体树的分割[50]。虽然这些方法在树冠分割方面取得了很好的效果,但在转化为2D图像的过程中,仍然会丢失所研究目标的原始3D几何信息。森林点云的无序、不均匀、不规则和噪声等问题给点云分割带来了很大挑战,现有的图像分类和分割框架不能直接应用于点云。因此,我们提出了一种新颖的PointNet深度学习方法,该方法直接处理无序点云数据以实现对单个树的分割。据我们所知,本文是一个大胆的尝试,将PointNet直接作用于扫描数据上进行个体树冠分割,最大程度地保留了点云的空间特征,并在最终测试中取得了良好的表现。模型的T-Net用于对扫描数据在输入体素中的旋转、平移等变化进行归一化处理,模型的MLP用于从各种神经网络中提取众多特征并聚合这些特征,从而有效地学习实体关于树和其他对象的特征。 PointNet模型与大量采集的训练样本相结合,在训练过程中通过迭代前向和反向传播获得最优权重,这使得模型能够鲁棒地识别构成树结构的点云。
4.2. Comparison with Existing Methods
我们的研究采用了体素化策略、点网模型和原始点云上与高度相关的梯度信息的协同使用,这不同于现有的一些ITC分割方法,如分水岭算法和基于点云的聚类分割算法。
分水岭算法是基于DSM或CHM上渐进水膨胀的物理原理,最终停止在树冠边界的低洼区域。然而,分水岭算法仅限于具有规则形状的树种,其在树冠的相似表型特征上具有良好的性能,即树木排列整齐,具有常见的塔或伞形状。对于树冠形状不规则、内部结构复杂的林区,森林的高郁闭度和树冠之间的重叠遮挡可能导致林冠出现多个局部顶点。此外,分水岭算法的性能易于不适当地处理弱边缘(即森林外观表面的细微灰度变化)和DSM上的噪声,这将产生过分割和欠分割。对于分水岭算法,当遇到由树冠和亚树冠树木组成的茂盛森林栖息地时,这些情况会加剧,树冠和亚树冠树木构成了具有互锁树冠和混合物种的多层森林组件。
基于点云的聚类分割算法是一种采用自上而下的区域生长方法从最高到最短依次分割单个树的算法。通常假设通过分析扫描点的几何空间特征来寻找树冠顶点,结合各种距离度量来实现单木分割。然而,该方法的关键参数对于不同的森林样地类型是不确定的。如果分配了不适当的参数值,则具有伸长分支和严重弯曲分支的树可能被过度分割,或者树冠重叠的相邻树可能被错误地分割。因此,合适的参数对于该方法的最终性能至关重要。此外,该算法利用了激光雷达点云中固有的3D结构,因此,由于相互遮挡的植物元素和仪器的不同扫描角度,在树冠被激光脉冲不均匀采样的情况下,可能会发生误分割。
这里,将分水岭算法、基于点云的聚类分割算法和我们的基于深度学习的方法的比较结果应用于相同的四个实验森林地点(即苗圃基地、修道院花园、混交林和落叶林)收集的点云上,三种方法的精度在表4中列出。该表表明,对于树冠形状相似、种植密度较低、排列整齐的苗圃地,三种方法表现出相似的分割精度。由于复杂的森林包含更广泛的树种混合和不同的树木结构,因此实现了树木分割准确性的小幅增加,这说明当处理高度复杂的森林场景时,我们的深度学习框架在提取树体的空间显式特征方面表现得更好。
表 4. 使用分水岭算法、基于点云的聚类分割算法和我们的方法对相同四个实验森林站点的原始点云进行ITC分割的准确性比较。

NT:树的数量。NS:分段树的数量。r(召回率):树检测率。P (precision):检测到的树的正确性。F (F-score):检测到的树的整体精度。TP:被正确分割的树的数量。FN:未检测到的分段树的数量。FP:现实中不存在的,但被我们的模型错误添加的分段树的数量。
4.3. Potential Improvements
如3.1节所述,在本实验中,设置合适的体素尺寸至关重要。过大的体素尺寸会产生包含在一个体素中的多个对象的更多点云,并削弱机器理解单个树的语义特征的能力。相反,过小的体素尺寸将使单棵树的完整点云集合变得支离破碎,并对开发树冠的几何知识产生不利影响。这里,我们将每个实验地点的体素大小设置为从初步森林调查中获得的平均树冠宽度。树冠或大或小的树木将是我们方法的主要挑战。这个问题类似于使用标记控制分水岭方法[51]在水膨胀之前选择CHM平滑的过滤器尺寸。一些研究采用半变异函数统计[51]来确定个别树冠分割前CHM树冠大小的局部范围。同样,可以进一步设计应用于深度学习框架的自动自适应体素尺寸分配策略,以优化参数设置。此外,如2.3节所述,通过随机采样方法将体素中的点云数量采样为1024,这小于扫描点的原始数量。在实验中,可以设计不同的采样策略,从原始采集的同一棵树的扫描点生成更多的训练样本。同时,每个点的位置在预期公差内的细微抖动也是实现训练样本数据扩充的一种可选方式。
PointNet的深度学习网络只学习每个点的局部特征,而忽略了点之间的连接关系,即它无法捕获点所在的度量空间所诱导的局部结构,因此不太可能学习细粒度的模式或理解复杂的场景。因此,与革命性的神经网络相比,如采用类金字塔特征聚合方案的PointNet++等[52],PointNet探索特征间相互关系的能力略弱。进一步,我们将结合先进的神经网络来优化深度学习模型的效率,并实现树冠识别的高精度。
5. Conclusions
设计了一种基于无人机机载激光雷达采集的扫描点云的深度学习方法,在体素尺度上识别树木,并结合高度相关的梯度信息完成单个树冠的描绘。提出的分割算法由两个阶段组成。第一阶段,人工提取各种形态的树木和建筑物的点云作为训练样本,带入点网模型中训练网络,获得最优网络参数。然后,基于体素化对每个森林点云进行细分。将每个体素中的点云作为测试样本,用训练好的点网网络进行分析,得到分类结果。在第二阶段,基于深度学习在体素尺度上的分割结果,采用与高度相关的梯度信息来精确描述每个树冠的边界。同时,将深度学习方法估计的树冠宽度与人工测量的结果进行比较,以验证我们方法的有效性。对于所研究的四种森林样地类型,即苗圃基地、寺庙园林、混交林和落叶林,结果显示苗圃基地的表现最好(树冠检出率 r = 0.90 r=0.90 r=0.90,树冠宽度估计 R 2 > 0.94 R^2>0.94 R2>0.94)。对于具有复杂森林结构、复杂树枝交叉和不同类型建筑的寺院花园和混交林,也实现了良好的性能,寺院花园的 r = 0.85 r=0.85 r=0.85和 R 2 > 0.88 R^2>0.88 R2>0.88,混交林的 r = 0.80 r=0.80 r=0.80, 和 R 2 > 0.85 R^2>0.85 R2>0.85。对于树冠落叶跨林地分布的第四种森林样地类型,我们实现了落叶森林的 r = 0.82 r=0.82 r=0.82 和 R 2 > 0.79 R^2>0.79 R2>0.79的性能。与分水岭算法和基于点云的聚类分割算法相比,该方法的树木检测准确率提高了1%–6%。总体而言,本工作表明,应用深度学习框架直接对各种森林类型的扫描点进行处理,解决单木分割问题是可行的。
原文链接:https://www.mdpi.com/1999-4907/12/2/131
References


-
Sylvain, J.-D.; Drolet, G.; Brown, N. Mapping dead forest cover using a deep convolutional neural network and digital aerial photography . ISPRS J. Photogramm. Remote. Sens. 2019, 156, 14–26. [CrossRef]
-
Hu, B.; Li, J.; Jing, L.; Judah, A. Improving the efficiency and accuracy of individual tree crown delineation from high-density LiDAR data. Int. J. Appl. Earth Obs. Geoinf. 2014, 26, 145–155. [CrossRef]
-
Qi, C.; Yi, L.; Su, H.; Guibas, L. PointNet++: Deep Hierarchical Feature Learning on point sets in a metric space. In Proceedings of the NIPS’17, 31st Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 5105–5114.