笔记:3.4 《数据库系统概论》之数据查询---SELECT(单表查询、连接查询、嵌套查询、集合查询、多表查询)
对 3.2 数据查询—SELECT(单表查询、连接查询、嵌套查询、集合查询、多表查询)的转载与学习笔记;
0.前言
- 本篇文章是对《数据库系统概论》王珊老师主编的数据库查询SELECT部分做的笔记,采用的是SQL Sever 数据库。
- 本篇文章中所有的例子,都会有结果的截图进行验证。
- 书上的结果和在机器上的结果可能略有不同,可能是数据库版本或软件显示的问题,或者是教材需要升级改版了。
1.思维导图
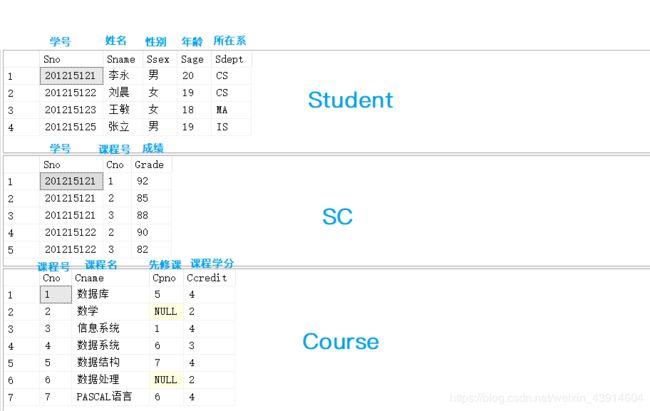
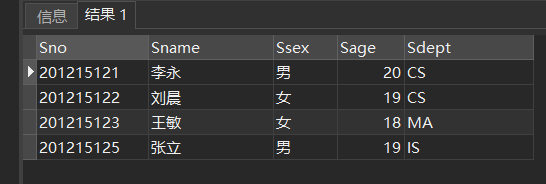
2.Student/SC/Course表数据及结构



- 本篇文章围绕这三个表展开的。
3.SELECT语句的一般格式
先从整体上了解一下SELECT的格式,关键字的位置。
SELECT [ALL|DISTINCT]
<目标列表达式> [别名] [ ,<目标列表达式> [别名]] …
FROM <表名或视图名> [别名] [ ,<表名或视图名> [别名]] …
[WHERE <条件表达式>]
[GROUP BY<列名1>
[HAVING <条件表达式>]]
[ORDER BY <列名2> [ASC|DESC]
4.单表查询
(1)选择表中的若干列
① 查询指定列
查询指定列
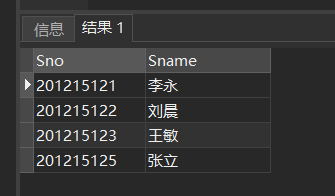
[例1] 查询全体学生的学号与姓名。
SELECT Sno,Sname
FROM Student;
[例2] 查询全体学生的姓名、学号、所在系。
SELECT Sname,Sno,Sdept
FROM Student;
② 查询全部列
- 选出所有属性列:在SELECT关键字后面列出所有列名 ,将<目标列表达式>指定为 *
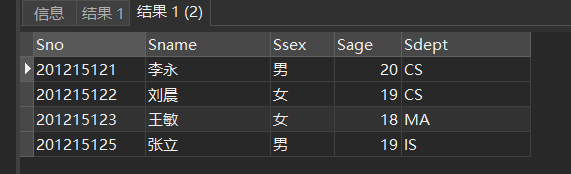
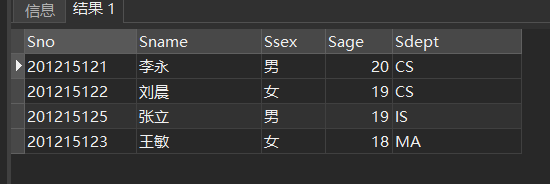
[例3] 查询全体学生的详细记录。
SELECT Sno,Sname,Ssex,Sage,Sdept
FROM Student;
//两种方式
SELECT *FROM Student;
③ 查询经过计算的值
SELECT子句的<目标列表达式>可以为:
算术表达式
字符串常量
函数
列别名
❶ 算术表达式
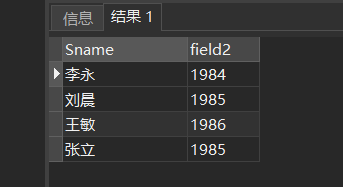
[例4] 查全体学生的姓名及其出生年份。这里假定目前年份是2004年。(2004年之前)
SELECT Sname,2004-Sage
FROM Student;
❷ 字符串常量及函数
[例5] 查询全体学生的姓名、出生年份和所有系,要求用小写字母表示所有系名,这里假定目前年份是2004年。
SELECT Sname,'Year of Birth: ', 2004-Sage, LOWER(Sdept)
FROM Student;
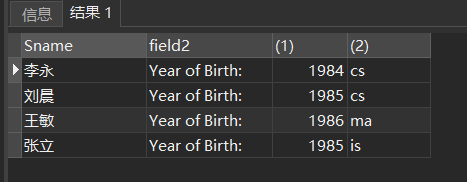
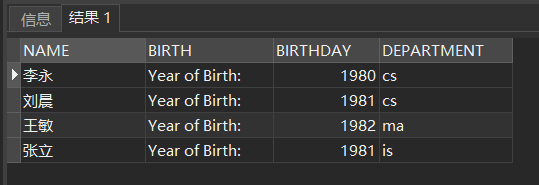
❸ 使用列别名改变查询结果的列标题
SELECT Sname NAME,'Year of Birth: ' BIRTH,
2000-Sage BIRTHDAY,
LOWER(Sdept) DEPARTMENT
FROM Student;
(2)选择表中的若干元组(行)
① 关键词DISTINCT去掉表中重复的行
- 如果没有指定DISTINCT关键词,则缺省为ALL
SELECT Sno FROM SC; /*等价于:*/ SELECT ALL Sno FROM SC;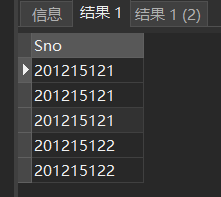
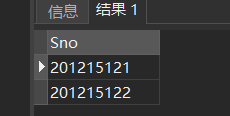
[例6] 查询选修了课程的学生学号。指定DISTINCT关键词,去掉表中重复的行
SELECT DISTINCT Sno
FROM SC;
② 查询满足条件的元组(行)
- 常用的查询条件
| 查询条件 | 谓词 |
| 比较 | =,>,<,>=,<=,!=,<>,!>,!<;NOT+上述比较运算符 |
| 确定范围 | BETWEEN AND,NOT BETWEEN AND |
| 确定集合 | IN,NOT IN |
| 字符匹配 | LIKE,NOT LIKE |
| 空值 | IS NULL,IS NOT NULL |
| 多重条件(逻辑运算) | AND,OR,NOT |
❶ 比较大小
[例7]查询计算机科学系全体学生的名单。
SELECT Sname
FROM Student
WHERE Sdept='CS';
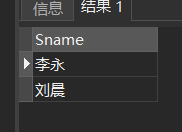
[例8] 查询所有年龄在20岁以下的学生姓名及其年龄。
SELECT Sname,Sage
FROM Student
WHERE Sage < 20;
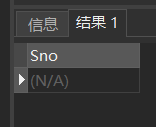
[例9]查询考试成绩有不及格的学生的学号。
SELECT DISTINCT Sno
FROM SC
WHERE Grade<60;
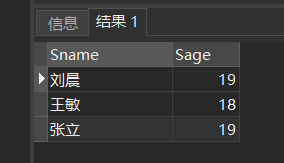
❷ 确定范围
谓词:
BETWEEN … AND …NOT BETWEEN … AND …
[例10] 查询年龄在20~23岁(包括20岁和23岁)之间的学生的
SELECT Sname,Sdept,Sage
FROM Student
WHERE Sage
BETWEEN 20 AND 23;
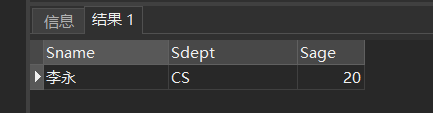
[例11] 查询年龄不在20~23岁之间的学生姓名、系别和年龄
SELECT Sname,Sdept,Sage
FROM Student
WHERE Sage NOT BETWEEN 20 AND 23;
❸ 确定集合
谓词:
IN <值表>,NOT IN <值表>
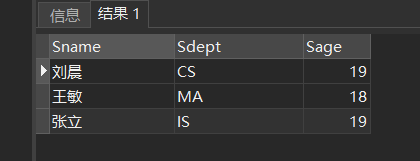
[例12]查询信息系(IS)、数学系(MA)和计算机科学系(CS)学生的姓名和性别。
SELECT Sname,Ssex
FROM Student
WHERE Sdept IN ( 'IS','MA','CS' );
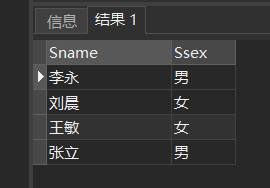
[例13]查询既不是信息系、数学系,也不是计算机科学系的学生的姓名和性别。
SELECT Sname,Ssex
FROM Student
WHERE Sdept NOT IN ( 'IS','MA','CS' );
❹ 字符匹配
谓词:
[NOT] LIKE ‘<匹配串>’ [ESCAPE ‘ <换码字符>’]
匹配串为固定字符串
[例14] 查询学号为201215121的学生的详细情况。
SELECT *
FROM Student
WHERE Sno LIKE '201215121';
/*等价于:*/
SELECT *
FROM Student
WHERE Sno = '201215121';

匹配串为含通配符的字符串
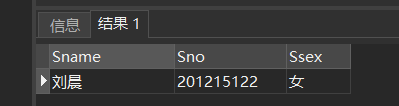
[例15] 查询所有姓刘学生的姓名、学号和性别。(%表示几位都可以, _表示一位)
SELECT Sname,Sno,Ssex
FROM Student
WHERE Sname LIKE '刘%';
[例16] 查询姓"欧阳"且全名为三个汉字的学生的姓名。
SELECT Sname
FROM Student
WHERE Sname LIKE '欧阳_';
[例17] 查询名字中第2个字为"阳"字的学生的姓名和学号。
SELECT Sname,Sno
FROM Student
WHERE Sname LIKE '_阳%';
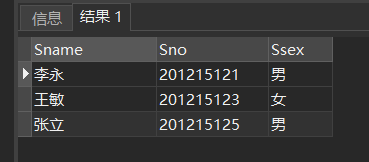
[例18] 查询所有不姓刘的学生姓名。
SELECT Sname,Sno,Ssex
FROM Student
WHERE Sname NOT LIKE '刘%';
❺ 使用换码字符’'将通配符转义为普通字符
ESCAPE '\' 表示“ \” 为换码字符
[例19] 查询DB_Design课程的课程号和学分。
SELECT Cno,Ccredit
FROM Course
WHERE Cname LIKE 'DB\_Design' ESCAPE '\';
[例20] 查询以"DB_"开头,且倒数第3个字符为 i的课程的详细情况。
SELECT *
FROM Course
WHERE Cname LIKE 'DB\_%i_ _' ESCAPE '\';
❻ 涉及空值的查询
谓词:
IS NULLIS NOT NULL“IS” 不能用 “=” 代替
[例21] 某些学生选修课程后没有参加考试,所以有选课记录,但没有考试成绩。查询缺少成绩的学生的学号和相应的课程号。
SELECT Sno,Cno
FROM SC
WHERE Grade IS NULL;
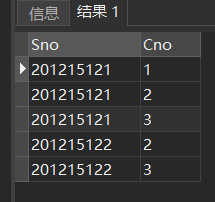
[例22] 查所有有成绩的学生学号和课程号。
SELECT Sno,Cno
FROM SC
WHERE Grade IS NOT NULL;
❼ 多重条件查询
逻辑运算符:
- AND和 OR来联结多个查询条件
- AND的优先级高于OR
- 可以用括号改变优先级
可用来实现多种其他谓词
[NOT] IN[NOT] BETWEEN … AND …
[例23] 查询计算机系年龄在20岁以下的学生姓名
SELECT Sname
FROM Student
WHERE Sdept= 'CS' AND Sage<20;
改写[例12] 查询信息系(IS)、数学系(MA)和计算机科学系(CS)学生的姓名和性别。
SELECT Sname,Ssex
FROM Student
WHERE Sdept IN ( 'IS','MA','CS' );
/*可改写为:*/
SELECT Sname,Ssex
FROM Student
WHERE Sdept= 'IS' OR Sdept= 'MA' OR Sdept= 'CS';
(3)ORDER BY子句
ORDER BY子句
可以按一个或多个属性列排序;升序:ASC;降序:DESC;缺省值为升序;
当排序列含空值时
ASC:排序列为空值的元组最后显示DESC:排序列为空值的元组最先显示
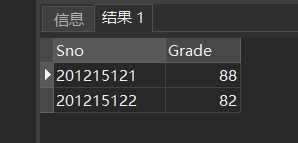
[例24] 查询选修了3号课程的学生的学号及其成绩,查询结果按分数降序排列。
SELECT Sno,Grade
FROM SC
WHERE Cno= '3'
ORDER BY Grade DESC;
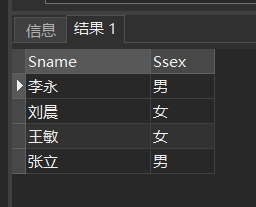
[例25] 查询全体学生情况,查询结果按所在系的系号升序排列,同一系中的学生按年龄降序排列。
SELECT *
FROM Student
ORDER BY Sdept ASC, Sage DESC;
(4)聚集函数 (计数)
聚集函数:
- 计数
COUNT([DISTINCT|ALL] *)COUNT([DISTINCT|ALL] <列名>) - 计算总和
SUM([DISTINCT|ALL] <列名>) - 计算平均值
AVG([DISTINCT|ALL] <列名>) - 最大最小值
MAX([DISTINCT|ALL] <列名>)MIN([DISTINCT|ALL] <列名>)
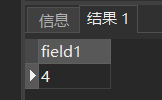
[例26] 查询学生总人数。
SELECT COUNT(*)
FROM Student;
[例27] 查询选修了课程的学生人数。
SELECT COUNT(DISTINCT Sno)
FROM SC;
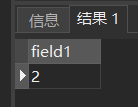
[例28] 计算2号课程的学生平均成绩。
SELECT AVG(Grade)
FROM SC
WHERE Cno= '2';
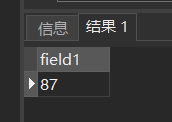
[例29] 查询选修2号课程的学生最高分数。
SELECT MAX(Grade)
FROM SC
WHERE Cno= '2';
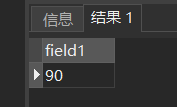
[例30]查询学生201215121选修课程的总学分数。
SELECT SUM(Ccredit)
FROM SC, Course
WHERE Sno='201215121' AND SC.Cno=Course.Cno;
(5)GROUP BY子句 分组 (HAVING短语与WHERE子句)
关于group by的用法 原理
GROUP BY子句分组:
细化聚集函数的作用对象
- 未对查询结果分组,聚集函数将作用于整个查询结果
- 对查询结果分组后,聚集函数将分别作用于每个组
- 作用对象是查询的中间结果表
- 按指定的一列或多列值分组,值相等的为一组
HAVING短语与WHERE子句的区别:
- 作用对象不同
- WHERE子句作用于
基表或视图,从中选择满足条件的元组 - HAVING短语作用于
组,从中选择满足条件的组。
SQL中where与having的区别_yajie_china的博客-CSDN博客_where和having的区别
[例31] 求各个课程号及相应的选课人数。
SELECT Cno,COUNT(Sno)
FROM SC
GROUP BY Cno;
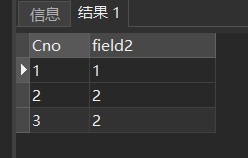
[例32] 查询选修了2门以上课程的学生学号。
SELECT Sno
FROM SC
GROUP BY Sno
HAVING COUNT(*) >2;
分组查询需要巧用group by
例题: SQL19 分组过滤练习题
5.连接查询
连接查询:同时涉及多个表的查询
连接条件或连接谓词:用来连接两个表的条件
一般格式:
[<表名1>.]<列名1> <比较运算符> [<表名2>.]<列名2>[<表名1>.]<列名1> BETWEEN [<表名2>.]<列名2> AND [<表名2>.]<列名3>
连接字段:连接谓词中的列名称
- 连接条件中的各连接字段类型必须是可比的,但名字不必是相同的
(1)连接操作的执行过程
① 嵌套循环法(NESTED-LOOP)
- 首先在表1中找到第一个元组,然后从头开始扫描表2,逐一查找满足连接件的元组,找到后就将表1中的第一个元组与该元组拼接起来,形成结果表中一个元组。
- 表2全部查找完后,再找表1中第二个元组,然后再从头开始扫描表2,逐一查找满足连接条件的元组,找到后就将表1中的第二个元组与该元组拼接起来,形成结果表中一个元组。
- 重复上述操作,直到表1中的全部元组都处理完毕
② 排序合并法(SORT-MERGE)
常用于=连接
- 首先按连接属性对表1和表2排序
- 对表1的第一个元组,从头开始扫描表2,顺序查找满足连接条件的元组,找到后就将表1中的第一个元组与该元组拼接起来,形成结果表中一个元组。当遇到表2中第一条大于表1连接字段值的元组时,对表2的查询不再继续
- 找到表1的第二条元组,然后从刚才的中断点处继续顺序扫描表2,查找满足连接条件的元组,找到后就将表1中的第一个元组与该元组拼接起来,形成结果表中一个元组。直接遇到表2中大于表1连接字段值的元组时,对表2的查询不再继续
- 重复上述操作,直到表1或表2中的全部元组都处理完毕为止
③ 索引连接(INDEX-JOIN)
- 对表2按连接字段建立索引
- 对表1中的每个元组,依次根据其连接字段值查询表2的索引,从中找到满足条件的元组,找到后就将表1中的第一个元组与该元组拼接起来,形成结果表中一个元组
(2)等值与非等值连接查询
等值连接:连接运算符为=
[例33] 查询每个学生及其选修课程的情况
SELECT Student.*,SC.*
FROM Student,SC
WHERE Student.Sno = SC.Sno;
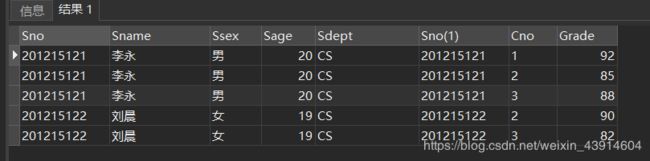
自然连接
[例34] 对[例33]用自然连接完成。
SELECT Student.Sno,Sname,Ssex,Sage,Sdept,Cno,Grade
FROM Student,SC
WHERE Student.Sno = SC.Sno;
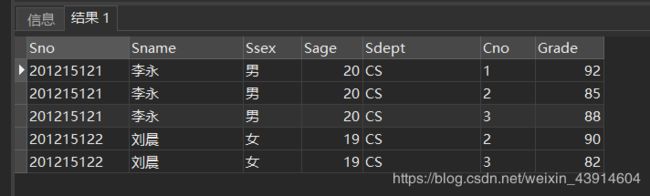
(3)自身连接
- 自身连接:一个表与其自己进行连接
- 需要给表起别名以示区别
- 由于所有属性名都是同名属性,因此必须使用别名前缀
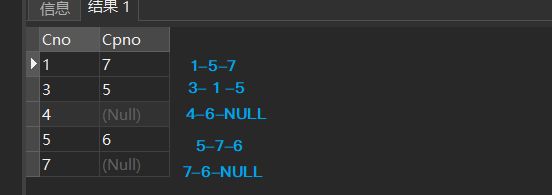
[例35]查询每一门课的间接先修课(即先修课的先修课)
SELECT FIRST.Cno,SECOND.Cpno
FROM Course FIRST,Course SECOND
WHERE FIRST.Cpno = SECOND.Cno;
(4)连接JOIN
- 自身连接:一个表与其自己进行连接
- 需要给表起别名以示区别
- 由于所有属性名都是同名属性,因此必须使用别名前缀
SQL join 用于把来自两个或多个表的行结合起来。
标准格式:
SELECT column_name(s)
FROM table1//左表
table2//右表
ON table1.column_name=table2.column_name;
分为4类:
INNER JOIN (JOIN)LEFT JOIN (LEFT OUTER JOIN)RIGHT JOIN (RIGHT OUTER JOIN)FULL JOIN (FULL OUTER JOIN)
这里就以SC和Course两个表来检验这四类连接 ,把SC和Course两个表连接起来;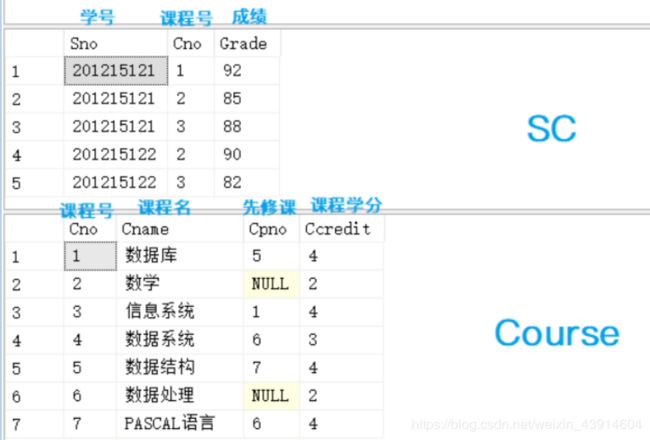 ① INNER JOIN (JOIN)
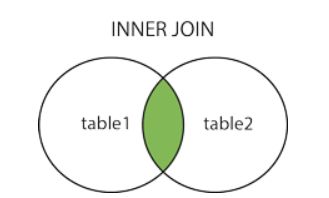
① INNER JOIN (JOIN)
INNER JOIN:关键字在表中存在至少一个匹配时返回行。
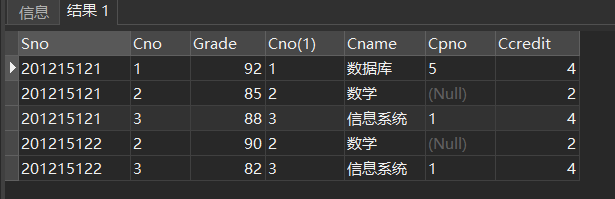
SELECT Sno,SC.Cno,Grade,Course.Cno,Cname,Cpno,Ccredit
FROM SC INNER JOIN Course ON (SC.Cno=Course.Cno);
/*INNER JOIN 与 JOIN结果相同*/
SELECT Sno,SC.Cno,Grade,Course.Cno,Cname,Cpno,Ccredit
FROM SC JOIN Course ON (SC.Cno=Course.Cno);
② LEFT JOIN (LEFT OUTER JOIN)
LEFT JOIN:关键字从左表(table1)返回所有的行,即使右表(table2)中没有匹配。如果右表中没有匹配,则结果为 NULL。
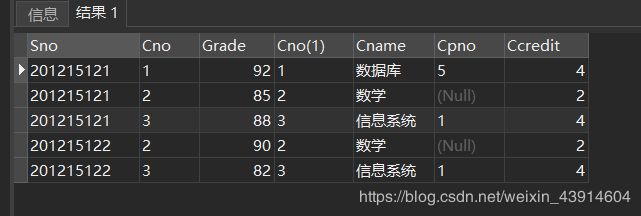
SELECT Sno,SC.Cno,Grade,Course.Cno,Cname,Cpno,Ccredit
FROM SC LEFT JOIN Course ON (SC.Cno=Course.Cno);
/*LEFT JOIN 与 LEFT OUTER JOIN结果相同*/
SELECT Sno,SC.Cno,Grade,Course.Cno,Cname,Cpno,Ccredit
FROM SC LEFT OUTER JOIN Course ON (SC.Cno=Course.Cno);
③ RIGHT JOIN (RIGHT OUTER JOIN)
RIGHT JOIN:关键字从右表(table2)返回所有的行,即使左表(table1)中没有匹配。如果左表中没有匹配,则结果为 NULL。
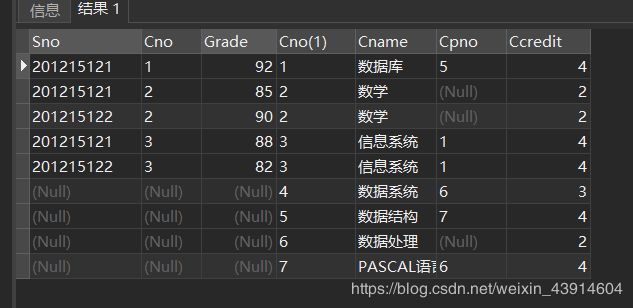
SELECT Sno,SC.Cno,Grade,Course.Cno,Cname,Cpno,Ccredit
FROM SC RIGHT JOIN Course ON (SC.Cno=Course.Cno);
/*RIGHT JOIN 与 RIGHT OUTER JOIN结果相同*/
SELECT Sno,SC.Cno,Grade,Course.Cno,Cname,Cpno,Ccredit
FROM SC RIGHT OUTER JOIN Course ON (SC.Cno=Course.Cno);
④ FULL JOIN (FULL OUTER JOIN)
FULL JOIN:关键字只要左表(table1)和右表(table2)其中一个表中存在匹配,则返回行。结合了 LEFT JOIN 和 RIGHT JOIN 的结果。
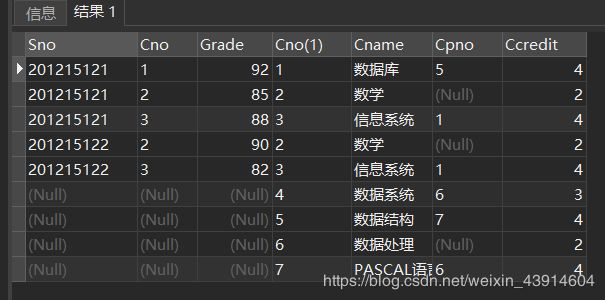
SELECT Sno,SC.Cno,Grade,Course.Cno,Cname,Cpno,Ccredit
FROM SC FULL JOIN Course ON (SC.Cno=Course.Cno);
/*FULL JOIN 与 FULL OUTER JOIN结果相同*/
SELECT Sno,SC.Cno,Grade,Course.Cno,Cname,Cpno,Ccredit
FROM SC FULL OUTER JOIN Course ON (SC.Cno=Course.Cno);
注意:连接查询的对象也可以是select 查询过后的表:如SQL33 找出每个学校GPA最低的同学
题目:现在运营想要找到每个学校gpa最低的同学来做调研,请你取出每个学校的最低gpa。

SELECT a.device_id,a.university,a.gpa FROM user_profile a
JOIN (SELECT university,min(gpa) gpa FROM user_profile
GROUP BY university) b
on a.university=b.university and a.gpa=b.gpa
ORDER BY university;

(5)复合条件连接
复合条件连接:WHERE子句中含多个连接条件
[例37]查询选修2号课程且成绩在88分以上的所有学生
SELECT Student.Sno, Sname
FROM Student,SC
WHERE Student.Sno = SC.Sno AND
/* 连接谓词*/
SC.Cno= '2' AND SC.Grade > 88;
/* 其他限定条件 */
(6)多表连接查询例题
- SQL22 统计每个学校的答过题的用户的平均答题数
- SQL23 统计每个学校各难度的用户平均刷题数
- 三表连接查询:SQL35 浙大不同难度题目的正确率
select qd.difficult_level, count(if(qpd.result='right',1,null))/ count(qpd.result) as correct_rate from user_profile as up join question_practice_detail as qpd on up.device_id=qpd.device_id join question_detail as qd on qpd.question_id=qd.question_id where up.university='浙江大学' group by qd.difficult_level order by correct_rate
6.嵌套查询
(1)嵌套查询概述
- 一个SELECT-FROM-WHERE语句称为一个
查询块 - 将一个
查询块嵌套在另一个查询块的WHERE子句或HAVING短语的条件中的查询称为嵌套查询
一个例子:
SELECT Sname/*外层查询/父查询*/
FROM Student
WHERE Sno IN
(SELECT Sno /*内层查询/子查询*/
FROM SC
WHERE Cno= '2');
- 子查询的
限制:·不能使用ORDER BY子句· - 层层嵌套方式反映了 SQL语言的结构化
- 有些嵌套查询可以用连接运算替代
(2)不相关子查询
子查询的查询条件不依赖于父查询
- 由里向外 逐层处理。即每个子查询在上一级查询处理之前求解,子查询的结果用于建立其父查询的查找条件。
(3)相关子查询
子查询的查询条件依赖于父查询
- 首先取外层查询中表的第一个元组,根据它与内层查询相关的属性值处理内层查询,若WHERE子句返回值为真,则取此元组放入结果表
- 然后再取外层表的下一个元组
- 重复这一过程,直至外层表全部检查完为止
(4)带有IN谓词的子查询
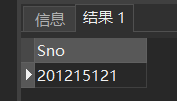
[例39] 查询与“刘晨”在同一个系学习的学生。此查询要求可以分步来完成
SELECT Sno,Sname,Sdept
FROM Student
WHERE Sdept IN
(SELECT Sdept
FROM Student
WHERE Sname= '刘晨');
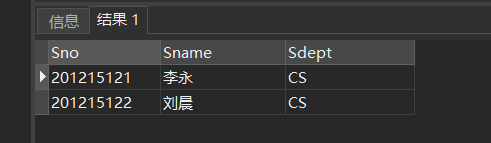
此查询为不相关子查询
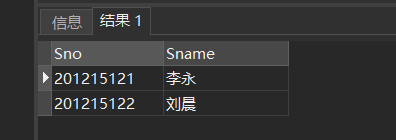
[例40]查询选修了课程名为“信息系统”的学生学号和姓名
SELECT Sno,Sname /*③ 最后在Student关系中取出Sno和Sname*/
FROM Student
WHERE Sno IN
( SELECT Sno /*② 然后在SC关系中找出选修了3号课程的学生学号*/
FROM SC
WHERE Cno IN
( SELECT Cno /*① 首先在Course关系中找出 “信息系统”的课程号,为3号*/
FROM Course
WHERE Cname= '信息系统'
)
);
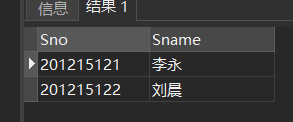
用连接查询实现[例40]
SELECT Student.Sno,Sname
FROM Student,SC,Course
WHERE Student.Sno = SC.Sno
AND SC.Cno = Course.Cno
AND Course.Cname='信息系统';
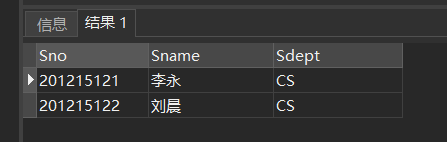
(5)带有比较运算符的子查询
- 带有比较运算符的子查询是指父查询与子查询之间用比较运算符进行连接。当用户能确切知道内层查询返回的是
单个值时,可以用>、<、=、>=、<= 、!=或< >等比较运算符。
- 与ANY或ALL谓词配合使用
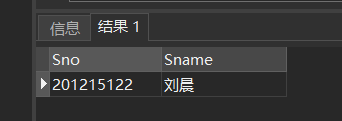
例:假设一个学生只可能在一个系学习,并且必须属于一个系,则在[例39]可以用= 代替IN:
SELECT Sno,Sname,Sdept
FROM Student
WHERE Sdept =
(SELECT Sdept
FROM Student
WHERE Sname= '刘晨');
/*两种方式都可以*/
SELECT Sno,Sname,Sdept
FROM Student
WHERE
(SELECT Sdept
FROM Student
WHERE Sname= '刘晨')
= Sdept ;
[例41]找出每个学生超过他选修课程平均成绩的课程号。
SELECT Sno, Cno
FROM SC x
WHERE Grade >=(SELECT AVG(Grade) /*相关子查询*/
FROM SC y
WHERE y.Sno=x.Sno
);
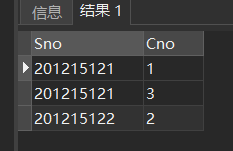
可能的执行过程如下:
1.从外层查询中取出SC的一个元组x,将元组x的Sno值(201215121)传送给内层查询。
SELECT AVG(Grade)
FROM SC y
WHERE y.Sno='201215121';
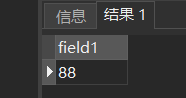
2.执行内层查询,得到值88(近似值),用该值代替内层查询,得到外层查询:
SELECT Sno, Cno
FROM SC x
WHERE Grade >=88;
3.执行这个查询,得到
(200215121,1)
(200215121,3)
4.外层查询取出下一个元组重复做上述1至3步骤,直到外层的SC元组全部处理完毕。结果为:
(6)带有ANY(SOME)或ALL谓词的子查询
谓词语义:
ANY:任意一个值ALL:所有值
需要配合使用比较运算符:
| > ANY | 大于子查询结果中的某个值 |
| > ALL | 大于子查询结果中的所有值 |
| < ANY | 小于子查询结果中的某个值 |
| < ALL | 小于子查询结果中的所有值 |
| >= ANY | 大于等于子查询结果中的某个值 |
| >= ALL | 大于等于子查询结果中的所有值 |
| <= ANY | 小于等于子查询结果中的某个值 |
| <= ALL | 小于等于子查询结果中的所有值 |
| = ANY | 等于子查询结果中的某个值 |
| =ALL | 等于子查询结果中的所有值(通常没有实际意义) |
| !=(或<>)ANY | 不等于子查询结果中的某个值 |
| !=(或<>)ALL | 不等于子查询结果中的任何一个值 |
[例42] 查询其他系中比计算机科学某一学生年龄小的学生姓名和年龄
SELECT Sname,Sage
FROM Student
WHERE Sage < ANY (SELECT Sage
FROM Student
WHERE Sdept= 'CS')
AND Sdept <> 'CS' ; /*父查询块中的条件 */
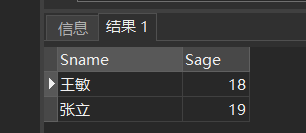
执行过程:
1.RDBMS执行此查询时,首先处理子查询,找出 CS系中所有学生的年龄,构成一个集合(20,19)
2. 处理父查询,找所有不是CS系且年龄小于 20 或 19的学生
用聚集函数实现[例42]
SELECT Sname,Sage
FROM Student
WHERE Sage < (SELECT MAX(Sage)
FROM Student
WHERE Sdept= 'CS')
AND Sdept <> 'CS';
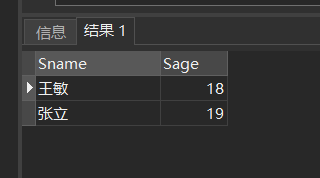
[例43] 查询其他系中比计算机科学系所有学生年龄都小的学生姓名及年龄。
- 方法一:用ALL谓词
SELECT Sname,Sage FROM Student WHERE Sage < ALL (SELECT Sage FROM Student WHERE Sdept= 'CS') AND Sdept <> 'CS';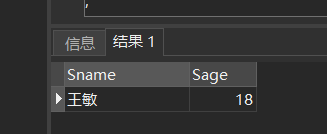
- 方法二:用聚集函数
SELECT Sname,Sage FROM Student WHERE Sage < (SELECT MIN(Sage) FROM Student WHERE Sdept= 'CS') AND Sdept <> 'CS';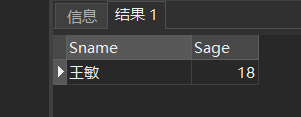
ANY(或SOME),ALL谓词与聚集函数、IN谓词的等价转换关系
| = | != 或者<> | < | <= | > | >= | |
|---|---|---|---|---|---|---|
| ANY | IN | – | | <=MAX |
>MIN |
>=MIN |
|
| ALL | – | NOT IN | | <=MIN |
>MAX |
>=MAX |
|
(7)带有EXISTS谓词的子查询
EXISTS谓词
- 存在量词 ∃
- 带有EXISTS谓词的子查询不返回任何数据,只产生逻辑真值“true”或逻辑假值“false”。
- 若内层查询结果非空,则外层的WHERE子句返回真值
- 若内层查询结果为空,则外层的WHERE子句返回假值
- 由EXISTS引出的子查询,其目标列表达式通常都用* ,因为带EXISTS的子查询只返回真值或假值,给出列名无实际意义
NOT EXISTS谓词
- 若内层查询结果非空,则外层的WHERE子句返回假值
- 若内层查询结果为空,则外层的WHERE子句返回真
[例44]查询所有选修了1号课程的学生姓名。
思路分析:
- 本查询涉及Student和SC关系
- 在Student中依次取每个元组的Sno值,用此值去检查SC关系
- 若SC中存在这样的元组,其Sno值等于此Student.Sno值,并且其Cno=‘1’,则取此Student.Sname送入结果关系
SELECT Sname FROM Student WHERE EXISTS(SELECT * FROM SC WHERE Sno=Student.Sno AND Cno= '1');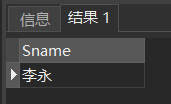
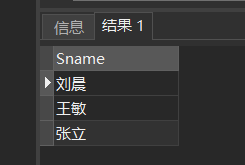
[例45] 查询没有选修1号课程的学生姓名。
SELECT Sname
FROM Student
WHERE NOT EXISTS(SELECT *
FROM SC
WHERE Sno=Student.Sno
AND Cno= '1');
不同形式的查询间的替换
- 一些带EXISTS或NOT EXISTS谓词的子查询不能被其他形式的子查询等价替换
- 所有带IN谓词、比较运算符、ANY和ALL谓词的子查询都能用带EXISTS谓词的子查询等价替换
用EXISTS/NOT EXISTS实现全称量词(难点)
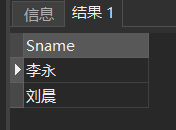
例:[例39]查询与“刘晨”在同一个系学习的学生。
可以用带EXISTS谓词的子查询替换:
SELECT Sno,Sname,Sdept
FROM Student S1
WHERE EXISTS(SELECT *
FROM Student S2
WHERE S2.Sdept = S1.Sdept
AND S2.Sname = '刘晨');
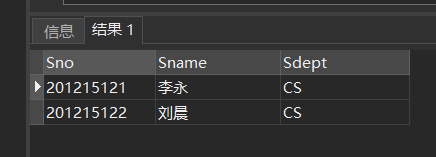
[例46] 查询选修了全部课程的学生姓名。
SELECT Sname
FROM Student
WHERE NOT EXISTS(SELECT *
FROM Course
WHERE NOT EXISTS(SELECT *
FROM SC
WHERE Sno= Student.Sno
AND Cno= Course.Cno)
);
用EXISTS/NOT EXISTS实现逻辑蕴函(难点)
- SQL语言中没有蕴函(Implication)逻辑运算
- 可以利用谓词演算将逻辑蕴函谓词等价转换为:
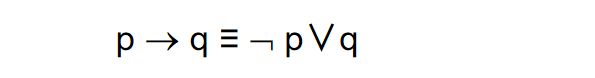
[例47]查询至少选修了学生201215122选修的全部课程的学生号码。
解题思路:
- 用逻辑蕴函表达:查询学号为x的学生,对所有的课程y,只要201215122学生选修了课程y,则x也选修了y。
- 形式化表示:
用P表示谓词 “学生201215122选修了课程y”
用q表示谓词 “学生x选修了课程y”
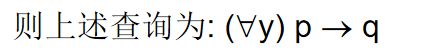
 用NOT EXISTS谓词表示:
用NOT EXISTS谓词表示:
SELECT DISTINCT Sno
FROM SC SCX
WHERE NOT EXISTS(SELECT *
FROM SC SCY
WHERE SCY.Sno = '201215122'
AND NOT EXISTS(SELECT *
FROM SC SCZ
WHERE SCZ.Sno=SCX.Sno
AND SCZ.Cno=SCY.Cno
)
);
(8)嵌套查询例题
6.2 使用select 查询过后的表来替代嵌套查询
对from的表进行改写和编辑
- SQL2 平均播放进度大于60%的视频类别
SELECT tag,concat(avg_1,'%') as avg_play_progress
from (
SELECT tag,
round(avg(
if(timestampdiff(SECOND, start_time,end_time)/duration >1,1,timestampdiff(SECOND, start_time,end_time)/duration))*100,2) as avg_1
FROM tb_user_video_log as a JOIN tb_video_info as b on (a.video_id=b.video_id)
group by tag
having avg_1>60) t1
order by avg_play_progress DESC
7.集合查询
(1) 集合操作的种类
并操作UNION交操作INTERSECT差操作EXCEPT
参加集合操作的各查询结果的列数必须相同;对应项的数据类型也必须相同
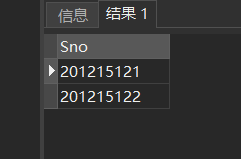
[例48] 查询计算机科学系的学生及年龄不大于19岁的学生。
SELECT *
FROM Student
WHERE Sdept= 'CS'
UNION SELECT *
FROM Student
WHERE Sage<=19;
UNION:将多个查询结果合并起来时,系统自动去掉重复元组。UNION ALL:将多个查询结果合并起来时,保留重复元组
方法二:
SELECT DISTINCT *
FROM Student
WHERE Sdept= 'CS'
OR Sage<=19;
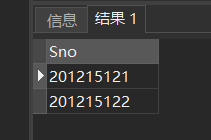
[例49] 查询选修了课程1或者选修了课程2的学生。
SELECT Sno
FROM SC
WHERE Cno='1'
UNION
SELECT Sno
FROM SC
WHERE Cno= '2';
[例50] 查询计算机科学系的学生与年龄不大于19岁的学生的交集
SELECT *
FROM Student
WHERE Sdept='CS'
INTERSECT
SELECT *
FROM Student
WHERE Sage<=19;

[例50] 实际上就是查询计算机科学系中年龄不大于19岁的学生
SELECT *
FROM Student
WHERE Sdept= 'CS'
AND Sage<=19;
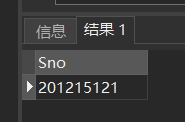
[例51] 查询选修课程1的学生集合与选修课程2的学生集合的交集
SELECT Sno
FROM SC
WHERE Cno='1'
INTERSECT
SELECT Sno
FROM SC
WHERE Cno='2';
[例51]实际上是查询既选修了课程1又选修了课程2 的学生
SELECT Sno
FROM SC
WHERE Cno='1' AND Sno IN
(SELECT Sno
FROM SC
WHERE Cno='2');
[例52] 查询计算机科学系的学生与年龄不大于19岁的学生的差集。
SELECT *
FROM Student
WHERE Sdept='CS'
EXCEPT
SELECT *
FROM Student
WHERE Sage <=19;

[例52]实际上是查询计算机科学系中年龄大于19岁的学生
SELECT *
FROM Student
WHERE Sdept= 'CS'
AND Sage>19;
集合查询例题
- SQL25 查找山东大学或者性别为男生的信息
8 函数查询
(1)条件函数(If和Case)
- If 函数
SQL中IF函数的使用
if(a,b,c)
if判断,如果a满足条件,返回b,否则返回c
举个例子 查询SC表中及格的学生
创建表SC
SC(SId,CId,score)
–SId 学生编号,CId 课程编号,score 分数
create table SC(sid varchar(10),cid varchar(10),score decimal(18,1));
insert into SC values('01' , '01' , 80);
insert into SC values('01' , '02' , 90);
insert into SC values('01' , '03' , 99);
insert into SC values('02' , '01' , 70);
insert into SC values('02' , '02' , 60);
insert into SC values('02' , '03' , 40);
select
sid,
count(if(score>=60,sid,null))
from SC
group by sid;
运行代码满足及格条件的返回学号sid,不满足条件的返回null
- Case 函数
是一种多分支的函数,可以根据条件列表的值返回多个可能的结果表达式中的一个。
可用在任何允许使用表达式的地方,但不能单独作为一个语句执行。
例48. 查询班级表中的学生的班号、班名、系号和班主任号,并对系号作如下处理:
当系号为1时,显示 “计算机系”;
当系号为2时,显示 “软件工程系”;
当系号为3时,显示 “物联网系”。
SELECT 班号 ,班名,
CASE
WHEN 系号=1 THEN '软件工程系'
WHEN 系号=2 THEN '计算机系'
WHEN 系号=3 THEN '物联网系'
END AS 系号,班主任号
FROM 班级表题目:现在运营想要将用户划分为25岁以下和25岁及以上两个年龄段,分别查看这两个年龄段用户数量 SQL26 计算25岁以上和以下的用户数量
SELECT CASE WHEN age < 25 OR age IS NULL THEN '25岁以下'
WHEN age >= 25 THEN '25岁及以上'
END age_cut,COUNT(*)number
FROM user_profile
GROUP BY age_cut

(2)取日期函数 和时间函数
- 类型为Date
day(date) 表示day
month(date) 表示月份
year (date) 表示年份
例题如下:
SQL28 计算用户8月每天的练题数量
select
day(date) as day,
count(question_id) as question_cnt
from question_practice_detail
where month(date)=8 and year(date)=2021
group by date-
对mysql中日期范围搜索的大致有三种方式:MYSQL中 datediff、timestampdiff函数的使用
1、between and语句;
2、datediff函数;
3、timestampdiff函数;
- 第一种: between and语句
select * from dat_document where commit_date between '2018-07-01' and '2018-07-04' 结果是1号到3号的数据,这是因为时间范围显示的实际上只是‘2018-07-01 00:00:00’到'2018-07-04 00:00:00'之间的数据,而'2018-07-04'的数据就无法显示出来,between and对边界还需要进行额外的处理.
- 第二种: datediff函数
datediff函数返回两个日期之间的天数
语法:DATEDIFF(date1,date2)
SELECT DATEDIFF('2018-07-01','2018-07-04');运行结果:-3
所以,datediff函数对时间差值的计算方式为date1-date2的差值。
- 第三种: timestampdiff函数
timestampdiff函数日期或日期时间表达式之间的整数差。
语法:TIMESTAMPDIFF(interval,datetime1,datetime2),比较的单位interval可以为以下数值
- FRAC_SECOND。表示间隔是毫秒
- SECOND。秒
- MINUTE。分钟
- HOUR。小时
- DAY。天
- WEEK。星期
- MONTH。月
- QUARTER。季度
- YEAR。年
select TIMESTAMPDIFF(DAY,'2018-07-01 09:00:00','2018-07-04 12:00:00');运行结果:3
所以,timestampdiff函数对日期差值的计算方式为datetime2-datetime1的差值。
请注意:DATEDIFF,TIMESTAMPDIFF对日期差值的计算方式刚好是相反的。
例题 SQL2 平均播放进度大于60%的视频类别
SELECT tag,concat(avg_1,'%') as avg_play_progress
from (
SELECT tag,
round(avg(
if(timestampdiff(SECOND, start_time,end_time)/duration >1,1,timestampdiff(SECOND, start_time,end_time)/duration))*100,2) as avg_1
FROM tb_user_video_log as a JOIN tb_video_info as b on (a.video_id=b.video_id)
group by tag
having avg_1>60) t1
order by avg_play_progress DESC(3)文本函数
substring_index(str,delim,count)
str:要处理的字符串
delim:分隔符
count:计数
例子:str=www.wikidm.cn
- substring_index(str,'.',1)
结果是:www
- substring_index(str,'.',2)
结果是:www.wikidm
也就是说,如果count是正数,那么就是从左往右数,第N个分隔符的左边的全部内容
相反,如果是负数,那么就是从右边开始数,第N个分隔符右边的所有内容,如:
- substring_index(str,'.',-2)
结果为:wikidm.cn
有人会问,如果我要中间的的wikidm怎么办?
很简单的,两个方向:
从右数第二个分隔符的右边全部,再从左数的第一个分隔符的左边:
- substring_index(substring_index(str,'.',-2),'.',1);
例题如下
- SQL30 统计每种性别的人数
(4) 窗口函数
通俗易懂的学会:SQL窗口函数
简单来说,窗口函数有以下功能:
1)同时具有分组和排序的功能
2)不减少原表的行数
3)语法如下:
select *,
rank() over (order by 成绩 desc) as ranking,
dense_rank() over (order by 成绩 desc) as dese_rank,
row_number() over (order by 成绩 desc) as row_num
from 班级表(5)保留几位小数的函数
round(a/b,3) 表示结果保留三位小数
(6) concat函数将多个字符串连接成一个字符串。
MySQL中concat函数
一. concat()函数
1. 含义:
将多个字符串连接成一个字符串。
2. 语法:
concat(str1, str2,...) 返回结果为连接参数产生的字符串,如果有任何一个参数为null,则返回值为null。
3. 演示:
select concat (id, name) as info from t1;
例2:在例1的结果中三个字段id,name,score的组合没有分隔符,我们可以加一个逗号作为分隔符:
select concat (id,‘,’ ,name) as info from t1;
但是输入sql语句麻烦了许多,三个字段需要输入两次逗号,如果10个字段,要输入九次逗号...麻烦死了啦,有没有什么简便方法呢?——于是可以指定参数之间的分隔符的concat_ws()来了!!!
二、concat_ws()函数
1. 含义:
和concat()一样,将多个字符串连接成一个字符串,但是可以一次性指定分隔符~(concat_ws就是concat with separator)
2. 语法:
concat_ws(separator, str1, str2, ...)
说明:第一个参数指定分隔符。需要注意的是分隔符不能为null,如果为null,则返回结果为null。
3、举例:
例3:我们使用concat_ws()将 分隔符指定为逗号,达到与例2相同的效果:
select concat_ws(',',id ,name) as info from t1;
例4:把分隔符指定为null,结果全部变成了null:
函数查询例题
- SQL34 统计复旦用户8月练题情况
题目: 现在运营想要了解复旦大学的每个用户在8月份练习的总题目数和回答正确的题目数情况,请取出相应明细数据,对于在8月份没有练习过的用户,答题数结果返回0.
示例:用户信息表user_profile


select up.device_id, up.university ,
count(qpd.question_id),
count(if(qpd.result='right',1,null))
from user_profile as up left join question_practice_detail as qpd
on( up.device_id=qpd.device_id
and substring_index(substring_index(qpd.date,'-',2),'-',-1)='08')
where up.university='复旦大学'
group by up.device_id