深度学习与自然语言处理教程(7) - 问答系统(NLP通关指南·完结)

- 作者:韩信子@ShowMeAI
- 教程地址:https://www.showmeai.tech/tutorials/36
- 本文地址:https://www.showmeai.tech/article-detail/245
- 声明:版权所有,转载请联系平台与作者并注明出处
- 收藏ShowMeAI查看更多精彩内容

本系列为斯坦福CS224n《自然语言处理与深度学习(Natural Language Processing with Deep Learning)》的全套学习笔记,对应的课程视频可以在 这里 查看。

ShowMeAI为CS224n课程的全部课件,做了中文翻译和注释,并制作成了 GIF动图!点击 第10讲-NLP中的问答系统 查看的课件注释与带学解读。更多资料获取方式见文末。
引言
CS224n是顶级院校斯坦福出品的深度学习与自然语言处理方向专业课程,核心内容覆盖RNN、LSTM、CNN、transformer、bert、问答、摘要、文本生成、语言模型、阅读理解等前沿内容。
本篇笔记对应斯坦福CS224n自然语言处理专项课程的知识板块:问答系统。主要针对NLP中的问答系统场景,介绍了一些模型和思路。
内容要点
- question answering
- Dynamic Memory Networks \ 动态记忆网络
- QA
- 问答
- 对话
- MemNN
- DCN
- VQA
1.图文问答系统与动态记忆网络( DMN )
QA 系统的概念是直接从文档、对话、在线搜索等中提取信息(有时是段落,或是单词的范围),以满足用户的信息需求。 QA 系统不需要用户通读整个文档,而是倾向于给出一个简短的答案。
现在, QA 系统可以很容易地与其他 NLP 系统(如聊天机器人)结合起来,有些 QA 系统甚至超越了文本文档的搜索,可以从一组图片中提取信息。
有很多类型的问题,其中最简单的是 Factoid Question Answering 事实类问题回答。它包含的问题看起来像
The symbol for mercuric oxide is?(氧化汞的符号是什么?)Which NFL team represented the AFC at Super Bowl 50?(哪支NFL球队代表AFC参加超级碗50赛?)
当然还有其他类型的问题,如数学问题( 2 + 3 = ? 2+3=? 2+3=?)、逻辑问题,这些问题需要广泛的推理(而且没有背景信息)。然而,我们可以说在人们的日常生活中,寻求信息的事实类问题回答是最常见的问题。
事实上,大多数 NLP 问题都可以看作是一个问答问题,其范式很简单:
- 我们发出一个查询,然后机器提供一个响应。通过阅读文档或一组指令,智能系统应该能够回答各种各样的问题。
- 我们可以要求句子的 POS 标签,我们可以要求系统用不同的语言来响应。
因此,很自然地,我们想设计一个可以用于一般 QA 的模型。
为了实现这一目标,我们面临两大障碍。
- ① 许多NLP任务使用不同的架构,如TreeLSTM (Tai et al., 2015)用于情绪分析,Memory Network (Weston et al., 2015) 用于回答问题,以及双向LSTM-CRF (Huang et al., 2015) 用于词性标注。
- ② 全面的多任务学习往往非常困难,迁移学习仍然是当前人工智能领域(计算机视觉、强化学习等)神经网络架构的主要障碍。
我们可以使用NLP的共享体系结构来解决第一个问题:动态内存网络( DMN ),这是一种为一般 QA 任务设计的体系结构。 QA 很难,部分原因是阅读一段很长的文字很难。即使对于人类,我们也不能在你的工作记忆中存储一个很长的文档。
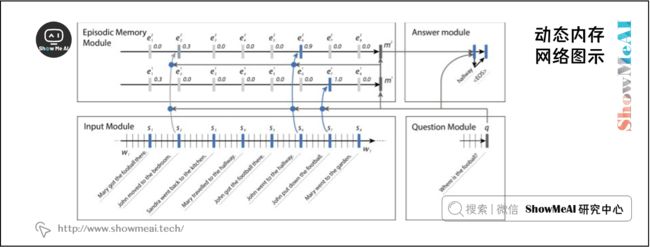
1.1 输入模块
将 DMN 分为多个模块。首先我们来看输入模块。输入模块以单词序列 T I T_I TI 作为输入,输出事实表示序列 T C T_C TC。如果输出是一个单词列表,我们有 T C = T I T_C = T_I TC=TI。如果输出是一个句子列表,我们有 T C T_C TC 作为句子的数量, T I T_I TI 作为句子中的单词数量。我们使用一个简单的 GRU 来读取其中的句子,即隐藏状态 h t = GRU ( x t , h t − 1 ) h_{t}=\operatorname{GRU}\left(x_{t}, h_{t-1}\right) ht=GRU(xt,ht−1),其中 x t = L [ w t ] x_{t}=L\left[w_{t}\right] xt=L[wt], L L L 为嵌入矩阵, w t w_t wt 为 t t t 时刻的单词,我们使用 Bi- GRU 进一步改进,如下图所示。
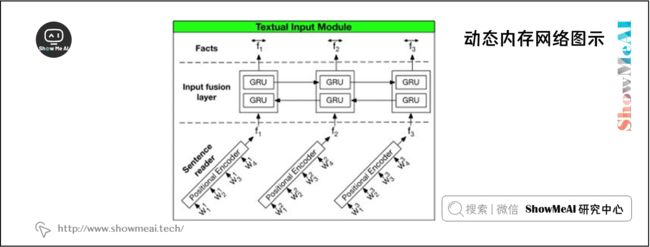
(本部分DMN网络频繁使用到GRU结构,具体的GRU细节讲解可以查看ShowMeAI的对吴恩达老师课程的总结文章深度学习教程 | 序列模型与RNN网络,也可以查看本系列的前序文章NLP教程(5) - 语言模型、RNN、GRU与LSTM)
1.2 问题读取模块
我们也使用标准的 GRU 来读取问题(使用嵌入矩阵 L : q t = GRU ( L [ w t Q ] , q t − 1 ) L : q_{t}=\operatorname{GRU}\left(L\left[w_{t}^{Q}\right], q_{t-1}\right) L:qt=GRU(L[wtQ],qt−1)),但是问题模块的输出是问题的编码表示。
1.3 情景记忆模块
动态记忆网络的一个显著特征是情景记忆模块,它在输入序列上运行多次,每次关注输入的不同事实子集。它使用 Bi- GRU 实现这一点, Bi- GRU 接收输入模块传入的句子级别表示的输入,并生成情景记忆表示。
我们将情景记忆表征表示为 m i m^i mi,情景表征(由注意机制输出)表示为 e i e^i ei。情景记忆表示使用 m 0 = q m^0 = q m0=q 初始化,然后继续使用 G R U : m i = G R U ( e i , m i − 1 ) \mathrm{GRU} : m^{i}=\mathrm{GRU}\left(e^{i}, m^{i-1}\right) GRU:mi=GRU(ei,mi−1)。使用来自输入模块的隐藏状态输出更新情景表征,如下所示,其中 g g g 是注意机制。
h t i = g t i GRU ( c t , h t − 1 i ) + ( 1 − g t i ) h t − 1 i e i = h T C i \begin{aligned} h_{t}^{i} &=g_{t}^{i} \operatorname{GRU}\left(c_{t}, h_{t-1}^{i}\right)+\left(1-g_{t}^{i}\right) h_{t-1}^{i} \\ e_{i} &=h_{T_{\mathrm{C}}}^{i} \end{aligned} htiei=gtiGRU(ct,ht−1i)+(1−gti)ht−1i=hTCi
注意向量 g g g 的计算方法有很多,但是在原始的 DMN 论文(Kumar et al. 2016)中,我们发现以下公式是最有效的
g t i = G ( c t , m i − 1 , q ) g_{t}^{i} =G\left(c_{t}, m^{i-1}, q\right) gti=G(ct,mi−1,q)
G ( c , m , q ) = σ ( W ( 2 ) t a n h ( W ( 1 ) z ( c , m , q ) + b ( 1 ) ) + b ( 2 ) ) G(c, m, q) =\sigma \left(W^{(2)} tanh \left(W^{(1)} z(c, m, q)+b^{(1)}\right)+b^{(2)}\right) G(c,m,q)=σ(W(2)tanh(W(1)z(c,m,q)+b(1))+b(2))
z ( c , m , q ) = [ c , m , q , c ∘ q , c ∘ m , ∣ c − q ∣ , ∣ c − m ∣ , c T W ( b ) q , c T W ( b ) m ] z(c, m, q) =\left[c, m, q, c \circ q, c \circ m,|c-q|,|c-m|, c^{T} W^{(b)} q_{,} c^{T} W^{(b)} m\right] z(c,m,q)=[c,m,q,c∘q,c∘m,∣c−q∣,∣c−m∣,cTW(b)q,cTW(b)m]
这样,如果句子与问题或记忆有关,这个模块中的门就会被激活。在第 i i i 遍中,如果总结不足以回答问题,我们可以在第 i + 1 i +1 i+1 遍中重复输入序列。
例如,考虑这样一个问题 Where is the football? 以及输入序列 John kicked the football 和 John was in the field。在这个例子中,John和football可以在一个pass中连接,然后John和field可以在第二个pass中连接,这样网络就可以根据这两个信息进行传递推断。
1.4 回答模块
回答模块是一个简单的 GRU 解码器,它接收问题模块、情景记忆模块的输出,并输出一个单词(或者通常是一个计算结果)。其工作原理如下:
y t = softmax ( W ( a ) a t ) a t = GRU ( [ y t − 1 , q ] , a t − 1 ) \begin{aligned} y_{t} &=\operatorname{softmax}\left(W^{(a)} a_{t}\right) \\ a_{t} &=\operatorname{GRU}\left(\left[y_{t-1}, q\right], a_{t-1}\right) \end{aligned} ytat=softmax(W(a)at)=GRU([yt−1,q],at−1)
1.5 实验
通过实验可以看出, DMN 在 babl 问答任务中的表现优于 MemNN,在情绪分析和词性标注方面也优于其他体系结构。情景记忆需要多少个情景?答案是,任务越难,通过的次数就越多。多次传递还可以让网络真正理解句子,只关注最后一项任务的相关部分,而不是只对单词嵌入的信息做出反应。
关键思想是模块化系统,你可以通过更改输入模块来允许不同类型的输入。例如,如果我们用一个基于卷积神经网络的模块替换输入模块,那么这个架构就可以处理一个称为可视化问题回答(VQA)的任务。它也能够在这项任务中胜过其他模型。
1.6 总结
自2015年以来,寻找能够解决所有问题的通用体系结构的热情略有减退,但在一个领域进行训练并推广到其他领域的愿望有所增强。要理解更高级的问答模块,读者可以参考动态注意力网络(DCN)。
2.参考资料
- 《ShowMeAI 深度学习与自然语言处理教程》的PDF在线阅读版本 - note7
- 《斯坦福CS224n深度学习与自然语言处理》课程学习指南
- 《斯坦福CS224n深度学习与自然语言处理》课程大作业解析
- 【双语字幕视频】斯坦福CS224n | 深度学习与自然语言处理(2019·全20讲)
ShowMeAI 深度学习与自然语言处理教程(完整版)
- ShowMeAI 深度学习与自然语言处理教程(1) - 词向量、SVD分解与Word2vec
- ShowMeAI 深度学习与自然语言处理教程(2) - GloVe及词向量的训练与评估
- ShowMeAI 深度学习与自然语言处理教程(3) - 神经网络与反向传播
- ShowMeAI 深度学习与自然语言处理教程(4) - 句法分析与依存解析
- ShowMeAI 深度学习与自然语言处理教程(5) - 语言模型、RNN、GRU与LSTM
- ShowMeAI 深度学习与自然语言处理教程(6) - 神经机器翻译、seq2seq与注意力机制
- ShowMeAI 深度学习与自然语言处理教程(7) - 问答系统
- ShowMeAI 深度学习与自然语言处理教程(8) - NLP中的卷积神经网络
- ShowMeAI 深度学习与自然语言处理教程(9) - 句法分析与树形递归神经网络
ShowMeAI 斯坦福NLP名课 CS224n带学详解(20讲·完整版)
- 斯坦福NLP名课带学详解 | CS224n 第1讲 - NLP介绍与词向量初步
- 斯坦福NLP名课带学详解 | CS224n 第2讲 - 词向量进阶
- 斯坦福NLP名课带学详解 | CS224n 第3讲 - 神经网络知识回顾
- 斯坦福NLP名课带学详解 | CS224n 第4讲 - 神经网络反向传播与计算图
- 斯坦福NLP名课带学详解 | CS224n 第5讲 - 句法分析与依存解析
- 斯坦福NLP名课带学详解 | CS224n 第6讲 - 循环神经网络与语言模型
- 斯坦福NLP名课带学详解 | CS224n 第7讲 - 梯度消失问题与RNN变种
- 斯坦福NLP名课带学详解 | CS224n 第8讲 - 机器翻译、seq2seq与注意力机制
- 斯坦福NLP名课带学详解 | CS224n 第9讲 - cs224n课程大项目实用技巧与经验
- 斯坦福NLP名课带学详解 | CS224n 第10讲 - NLP中的问答系统
- 斯坦福NLP名课带学详解 | CS224n 第11讲 - NLP中的卷积神经网络
- 斯坦福NLP名课带学详解 | CS224n 第12讲 - 子词模型
- 斯坦福NLP名课带学详解 | CS224n 第13讲 - 基于上下文的表征与NLP预训练模型
- 斯坦福NLP名课带学详解 | CS224n 第14讲 - Transformers自注意力与生成模型
- 斯坦福NLP名课带学详解 | CS224n 第15讲 - NLP文本生成任务
- 斯坦福NLP名课带学详解 | CS224n 第16讲 - 指代消解问题与神经网络方法
- 斯坦福NLP名课带学详解 | CS224n 第17讲 - 多任务学习(以问答系统为例)
- 斯坦福NLP名课带学详解 | CS224n 第18讲 - 句法分析与树形递归神经网络
- 斯坦福NLP名课带学详解 | CS224n 第19讲 - AI安全偏见与公平
- 斯坦福NLP名课带学详解 | CS224n 第20讲 - NLP与深度学习的未来
ShowMeAI系列教程精选推荐
- 大厂技术实现:推荐与广告计算解决方案
- 大厂技术实现:计算机视觉解决方案
- 大厂技术实现:自然语言处理行业解决方案
- 图解Python编程:从入门到精通系列教程
- 图解数据分析:从入门到精通系列教程
- 图解AI数学基础:从入门到精通系列教程
- 图解大数据技术:从入门到精通系列教程
- 图解机器学习算法:从入门到精通系列教程
- 机器学习实战:手把手教你玩转机器学习系列
- 深度学习教程:吴恩达专项课程 · 全套笔记解读
- 自然语言处理教程:斯坦福CS224n课程 · 课程带学与全套笔记解读
- 深度学习与计算机视觉教程:斯坦福CS231n · 全套笔记解读
