python学习1.1--将数据集写入csv文档中,从csv文档读取数据集,数据值缺失处理,转换为张量格式
本文仅仅是个人学习笔记,以及记录学习过程中出现的一些问题。
学习参考书网站
deep learning在线学习文档
文章目录
-
- 将数据集写入csv文档中
- 读取数据集
- 处理缺失值
- 转换为张量格式
将数据集写入csv文档中
首先我们需要手动写一些数据到csv文件中,文档中使用以下代码。
- os库是对文件或者文件夹进行操作的一个工具
- os.makedirs()函数,递归目录创建函数,和os.mkdir()很像,但是os.mkdir()只创建最后一层的目录。而对于os.makedirs()来说,如果路径中哪一层不存在,则自动创建。
- os.makedirs:的exist_ok参数设置为True时,可以自动判断当文件夹已经存在就不创建(我感觉这个超方便)
import os
os.makedirs(os.path.join('..', 'data'), exist_ok=True)
data_file = os.path.join('..', 'data', 'house_tiny.csv')
with open(data_file, 'w') as f:
f.write('NumRooms,Alley,Price\n') # 列名
f.write('NA,Pave,127500\n') # 每行表示一个数据样本
f.write('2,NA,106000\n')
f.write('4,NA,178100\n')
f.write('NA,NA,140000\n')
但是运行之后在我的电脑上会报以下错误

解决办法是将以下2句修改一下,参考文章:报错: [WinError 5] 拒绝访问。: ‘…\data‘
os.makedirs(os.path.join('\\', 'data'), exist_ok=True)
data_file = os.path.join('\\', 'data', 'house_tiny.csv')
此时,创建成功后,在电脑C盘的data文件夹中会出现一个house_tiny.csv的文件夹。

读取数据集
导入pandas包并调用read_csv函数,由上一问可知,这个数据集有4行3列,
如果没有安装pandas,可以使用下行来安装pandas
!pip install pandas
import pandas as pd
data = pd.read_csv(data_file)
print(data)
运行可以得到以下结果

处理缺失值
上图中的NAN即为缺失值,我们需要将缺失值补起来。对于NumRooms列,缺失值就可以用该列的平均值来代替。
- 通过位置索引 iloc,我们将data分成inputs和outputs, 其中前者为data的前两列,而后者为data的最后一列。
- data.iloc[ A:B ,C:D ]
用法:逗号前面表示的是取哪些行,逗号后面表示取哪些列
-inputs.fillna()函数是用来补全缺失数据的,
inputs.fillna(0)就是用0填充缺失数据
inputs.fillna(data.mean()))就是用每列特征的均值填充缺失数据
参考博客:详解pandas.DataFrame.fillna( )函数
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2]
inputs = inputs.fillna(inputs.mean())
print(inputs)
运行结果如下:

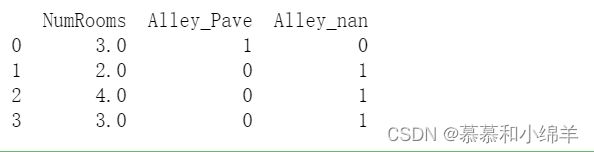
对于Alley列,我们将NAN看作是一个类别,这样可以将Alley分为2列
pandas可以自动将此列转换为两列“Alley_Pave”和“Alley_nan”。 巷子类型为“Pave”的行会将“Alley_Pave”的值设置为1,“Alley_nan”的值设置为0。 缺少巷子类型的行会将“Alley_Pave”和“Alley_nan”分别设置为0和1。
- get_dummies是pandas中的一个功能,它可以在现有的数据集上添加虚拟变量,让数据集变成可以用的格式。
- dummy_na : bool, default False
增加一列表示空缺值,如果False就忽略空缺值
inputs = pd.get_dummies(inputs, dummy_na=True)
print(inputs)
运行结果是:
转换为张量格式
文档中提供了三个主流深度学习框架,分别是MXNET,PYTORCH,TENSORFLOW
我们这里使用PYTORCH框架
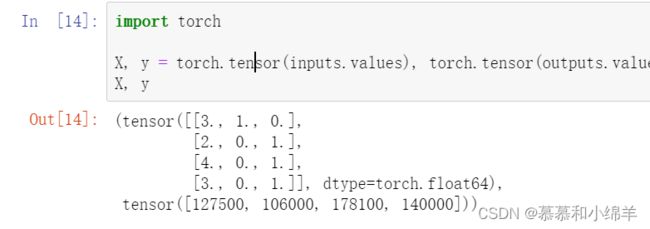
import torch
X, y = torch.tensor(inputs.values), torch.tensor(outputs.values)
X, y
但是我这里又报错了
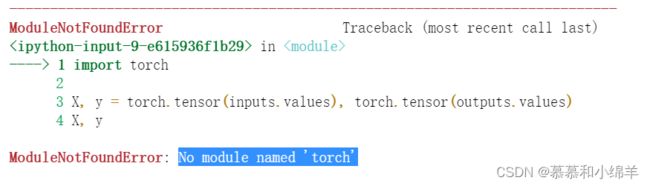
原因是未安装torth,安装语句是
pip install torch
安装之后要稍微等一段时间,再运行上述代码
运行结果如下: