TransMix:给视觉Transformer进行数据增强!提升模型性能!
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
转载自:集智书童

基于Mixup的数据增强已经被证明在训练过程中对模型进行泛化是有效的,特别是对于Vision transformer(ViT),因为它们很容易过拟合。
然而,以往基于Mixup的方法有一个潜在的先验知识,即目标的线性插值比率应该与输入插值中提出的比率保持一致。这可能会导致一种奇怪的现象,有时由于增广的随机过程,Mixup图像中没有有效的对象,但标签空间中仍然有响应。
为了弥补输入空间和标签空间之间的差距,本文提出了TransMix,它基于Vision transformer的Attention Map mix labels。Attention Map对相应输入图像的加权越高,标签的置信度越大。TransMix非常简单,只需几行代码就可以实现,无需向基于ViT的模型引入任何额外的参数和flop。
实验结果表明,在ImageNet分类上,该方法能在不同尺度上持续改进各种基于ViT的模型。在ImageNet上使用TransMix进行预处理后,基于ViT-C的模型在语义分割、目标检测和实例分割方面也表现出了较好的可移植性。在评估4个不同的基准时,TransMix也表现得更加健壮。
TransMix: Attend to Mix for Vision Transformers
论文:https://arxiv.org/abs/2111.09833
开源地址:https://github.com/Beckschen/TransMix
1简介
Transformer在自然语言处理的几乎所有任务中占据主导地位。近年来,基于Transformer的架构如Vision Transformer(ViT)被引入到计算机视觉领域,并在图像分类、目标检测和图像分割等任务中显示出巨大的前景。
然而,最近的研究发现,基于ViT的网络很难优化,如果训练数据不足,很容易过拟合。快速解决这一问题的方法是在训练过程中应用数据增强和正则化技术。其中,Mixup和CutMix等基于Mix的方法被证明对基于ViT的网络泛化特别有帮助。
Mixup需要一对输入及其对应的标签,然后以为基础创建一个人工训练实例。这里,是从Beta分布中随机抽样的Mix比例。这就假设了特征向量的线性插值应该与目标的线性插值保持一致。
 图1
图1
然而,本文作者认为上述假设并不完全正确的,因为并非所有像素都是相等的。如图1所示,背景中的像素对标签空间的贡献不像显著区域中的像素那么大。
已有的一些工作也发现了这个问题,并仅在输入层面上Mix最有描述性的部分来解决它。然而,上述方法对输入的操作可能会缩小增强的空间,因为它们往往较少考虑将背景图像放入Mix图像中。同时,上述方法需要更多的参数或训练吞吐量来提取输入显著区域。例如,Puzzle-Mix要求模型在一次迭代中前进和后退两次,而Attentive-Cutmix则引入24M外部CNN来提取显著特征。
本文并没有研究如何在输入层面更好地Mix图像,而是更多地关注如何通过学习标签分配来缓和输入与标签空间之间的差距。作者发现Vision Transformers中自然生成的Attention maps非常适合这项工作。如图1所示,简单地将(的权值)设置为位于A的Attention maps的权值之和,这样标签就可以根据每个像素的重要性重新加权,而不是像Mix输入一样以相同的比例线性插值。由于Attention maps是在基于ViT的模型中自然生成的,所以我该方法无需额外的参数,并且仅仅需要很小的计算开销就可以合并到训练中。
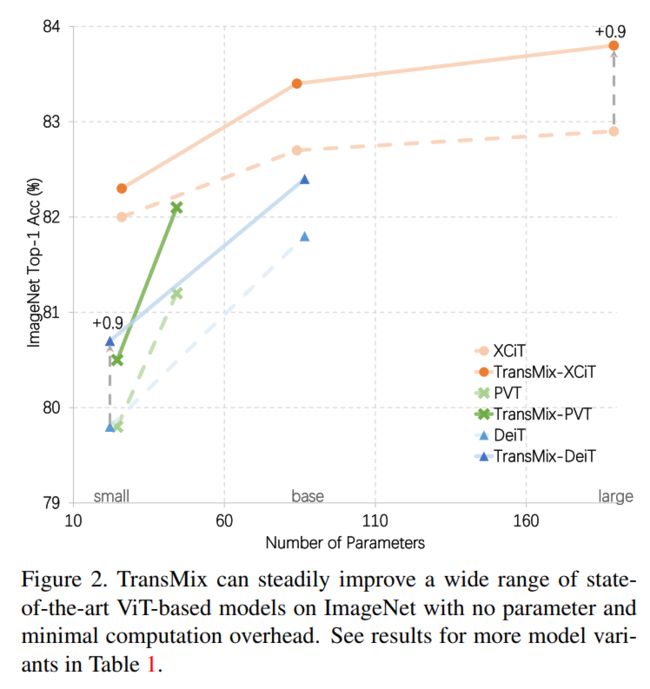 图2
图2
作者证明了该简单想法可以带来广泛的任务和模型的持续和显著的改进。正如图2所展示的那样,TransMix可以稳步提升所有基于Vit的模型。值得注意的是,对于DeiT-S和大型变体XCiT-L, TransMix可以进一步提高ImageNet上top-1的精度0.9%。有趣的是,最大的XCiT-L模型在所有XCiT模型尺度中提升最多。
此外,作者还证明了,如果首先在ImageNet上使用TransMix进行预训练,模型的优势可以进一步转移到下游任务,包括目标检测、实例分割、语义分割和弱监督目标分割/定位。作者还观察到,在4个不同的基准上评估后,TransMix可以帮助模型更加鲁棒。
2相关工作
2.1 Vision Transformers
最近,Vision Transformer(ViT)被提出,通过将图像进行Token和Patch,使其成为一组token序列来适应图像识别。ViT是基于multi-head self attention层和前馈网络组成的Transformer块序列。
DeiT通过引入强大的训练Trick和采用知识蒸馏来加强ViT。在ViT成功的基础上,人们对ViT进行了大量的改进,并将其应用于图像分类、目标定位/检测和图像分割等各种视觉任务中。
2.2 Mixup及其变体
数据增强已经被广泛研究,以防止deepnet对训练数据的过拟合。为了稳定地训练和改善Vision Transformers,Mixup和CutMix是两种最有效的增强方法。
Mixup是一种成功的图像Mix技术,它通过对两幅全局图像进行像素加权组合得到增强图像。下面的Mixup变体可以分为:
全局图像混合,如:ManifoldMixup和Un-Mix;
区域图像混合,如:CutMix、Puzzle-Mix、Attentive-CutMix和Saliency-Mix;
在所有Mixup变体中,基于显著性的方法包括Attentive-CutMix、Puzzle-Mix和Saliency-CutMix是与TransMix最相似的方法。然而,TransMix与它们有2个基本的区别:
以往基于显著性的方法,如强制将图像patch裁剪到输入图像的显著性区域。而TransMix不是在输入空间中操作,而是关注如何更准确地在标签空间中分配标签;
以前的基于显著性的方法,可能会使用额外的参数来提取显著性区域。TransMix自然地利用了Transformer的注意力机制,没有任何额外的参数。
实验结果也表明,与这些方法相比,TransMix在ImageNet上的效果更好。
2.3 数据自适应损失权重分配
TransMix采用注意力引导重新分配ground truth labels,这与数据自适应损失权重分配有关。已有的一些研究发现,类似注意力的信息可以帮助缓解诸如实例分割、图像去马赛克等任务的长尾问题等。
3TransMix方法
3.1 背景
1、CutMix data augmentation
CutMix是一种简单的数据增强技术,结合2个输入标签对和来增强一个新的训练样本。公式如下:

其中为二进制掩码,表示从2幅图像中剔除和填充的位置,1为二进制掩码,为逐元乘法。是在混合标签中的比例。
在增广过程中,在中移除一个随机采样区域,并用从的A中裁剪的patch填充,其中patch的边界坐标均匀采样为。混合目标分配因子等于裁剪面积比。
2、Self-Attention
Self-attention作用于一个输入矩阵,其中N是token的数量,每个维数d。输入x通过使用weight矩阵,和线性预测query,key和value,使, , ,其中。
通过query和key来计算注意力图,Self-Attention操作的输出定义为v中N个token特征的加权和,其权重与注意力图相对应:
通过对query、key和value进行g次不同的线性投影,将Single-head self-attention扩展到Multi-head self-attention。
3.2 TransMix
作者建议TransMix在注意力图的指导下分配Mix标签,其中注意力图被明确定义为Multi-head self-attention A。在分类任务中,class token是一个query q,其对应的key k为所有的输入tokens,class attention是class token到输入token的注意力映射,总结出哪些输入令token对最终分类器最有用。然后建议使用class attention A来mix标签。
1、Multi-head Class Attention
Vision transformer(ViTs)将图像分割嵌入到p个patch token 中,并通过class toekn 聚合全局信息,其中d为嵌入维数。vit在patch embedding 上操作。
给出了一个具有g个注意头的Transformer,输入块嵌入z,用投影矩阵参数化multi-head classattention。每个Head的class attention可以表述为:

其中表示class token,是一个query,其对应的key是所有输入的token,是从class token到图像patch token的注意力映射,总结出哪些patch对最终分类器最有用。当注意力中有多个head时,简单地对所有注意力头进行平均得到。在实现中,可作为最后一个Transformer块的中间输出,无需修改架构。
2、Mixing labels with the attention map A
遵循在CutMix中提出的输入混合过程。
重新计算;
利用注意力图A的指导计算:
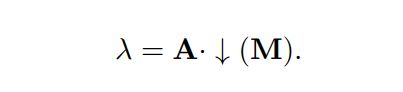
其中为最近邻插值下采样,可以将原始的M从HW转化为p像素。注意,这里省略了unsqueezing。这样,网络就可以学习根据每个数据点在注意力图中的响应动态地重新分配标签的权重。被注意力图更好聚焦的输入将在混合标签中分配更高的值。
3.3 伪标签
算法1以pytorch风格提供了TransMix的伪代码。干净的伪代码表明,只需几行代码就可以以即插即用的方式提高性能。
 算法1
算法1
4实验与分析
4.1 分类实验
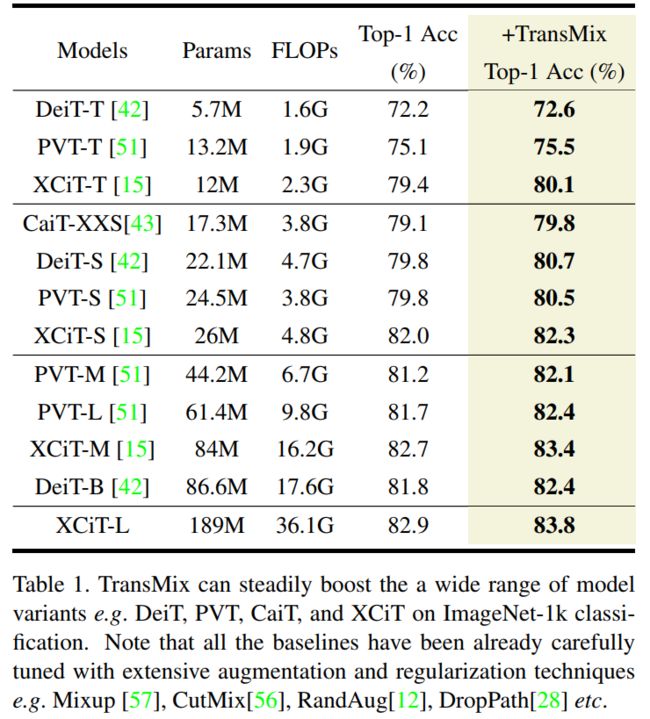 表1
表1
如表1所示,对于所有列出的模型,TransMix可以稳步提高ImageNet上的top-1精度。无论模型有多复杂,TransMix总是可以帮助提高基准性能。
请注意,这些模型具有广泛的模型复杂性,并且Baseline都经过各种数据增强技术(如RandAug, Mixup和CutMix)的仔细调整。
其中,TransMix可以将DeiT-S的top-1准确率提高0.9%。得益于更高的关注质量,TransMix还可以将XCiT-L的top-1精度提高0.9%。
与模型上的结构修改相比,这些仅在数据增强上进行微小调整的系统改进是重要的。例如,CrossViT-B相比DeiT-B只提高了0.4%但是却带来了额外的20.9%的参数开销,而TransMix在无参数的情况下就可以达到。
特别是,TransMix的base/large变体的增幅在0.6%至0.9%之间,这比设计新的架构(如PiT-B、T2T-24、crossvitb)的增幅(分别为0.2%、0.5%和0.4%)更为惊人。
4.2 下游任务的提升
1、语义分割
 表2
表2
根据表2,TransMix预训练DeiT-SLinear和DeiT-S-Segmenter比预训练Baseline分别提高0.6%和0.9%的mIoU。在多尺度测试方面有了持续的改进。
2、目标检测和实例分割
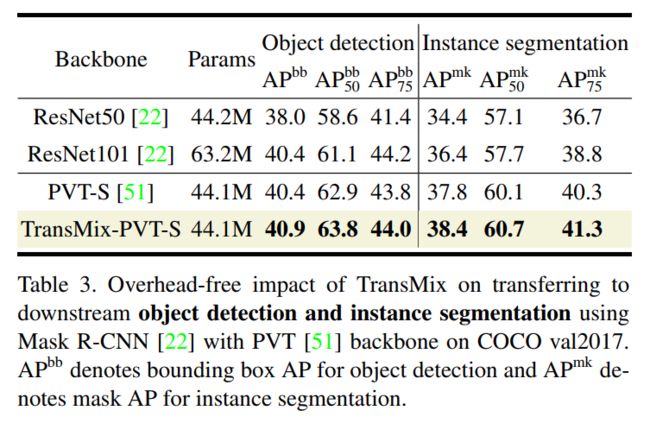 表3
表3
如表3所示,在不引入额外参数的情况下,使用Transmix预训练Backbone初始化的检测器比Cutmix预训练Backbone提高了0.5% Box AP和0.6% Mask AP。
请注意,基于正则化的Backbone预训练对改善下游目标检测的能力有限。例如,最近的Mixup变体Saliency-Mix在更小的检测数据集上仅比Cutmix预先训练的模型提高了0.16%的Box AP。
4.3 鲁棒性分析
1、遮挡鲁棒性
Naseer等人研究了ViT是否在部分或大部分图像内容缺失的闭塞场景下表现强劲。具体来说,vision transformer将一幅图像划分为M=196个patch,这些patch属于一个14×14的空间网格;即一幅大小为224×224×3的图像被分割成196个16×16×3大小的patch。Patch Dropping是指用空白的0值patch替换原来的图像patch。
例如,从输入中删除100个这样的patch相当于丢失51%的图像内容。作者展示了ImageNet-1k验证集上的分类精度,使用3个操作:
Random Patch Dropping:随机选取M个Patch中的一个子集进行dropped;
Salient (foreground) Patch Dropping:研究vit对高度显著区域遮挡的鲁棒性。Naseer等人通过阈值来获取DINO的注意力图中显著patch,显著patch被比率降低;
Non-salient (background) Patch Dropping:用同样的方法对图像中最不显著的区域进行选择和删除。
 图3
图3
如图3所示,使用TransMix的DeiT-S在所有遮挡水平上都优于普通DeiT-S,特别是在极端遮挡(信息丢失率>0.7)。
2、空间结构Shuffle的敏感性
作者通过对输入图像块进行变换来研究模型对空间结构的灵敏度。具体来说,随机打乱不同网格大小的图像patch。注意,Shuffle Grid大小为1表示没有shuffle,Shuffle Grid大小为196表示所有patch token都进行了shuffle。
 图4
图4
图4显示了相对于Baseline的一致改进,TransMix-DeiT-S和DeiT-S在所有打乱网格尺寸上的平均准确率分别为62.8%和58.4%。优越的4.2%增益表明,TransMix使transformer能够更少地依赖位置嵌入来保存信息最丰富的分类上下文。
3、自然对抗的例子

4.4 TransMix和Attention的相互作用
1、TransMix是否有利于Attention?
为了评价注意力矩阵的质量,直接对DeiT-S的分类注意力A进行阈值划分,得到二元注意力掩码,然后进行两项任务:
在基于Pascal VOC 2012上进行弱监督自动分割。
在ImageNet-1k验证集上进行弱监督对象定位(WOSL),其中边界框仅用于求值。
对于任务(1),在PASCAL-VOC12标记集上计算GT和二元注意力掩模之间的Jaccard相似性。
对于task(2),与基于cam的cnn方法不同,作者直接从二元注意力掩模生成一个BBox,并与之进行比较ImageNet-1k上的ground-truth边界框。这两个任务都是弱监督的,因为训练模型只使用类级别的ImageNet标签(即既不使用Box监督目标定位,也不使用逐像素监督分割)。
将由TransMix-DeiT-S或香草DeiT-S生成的注意力Mask与这两个的ground-truth进行比较。评估的分数可以定量的帮助了解TransMix是否对注意力图的质量有积极的影响。
2、更好的Attention能滋养TransMix吗?
以上实验证明,TransMix对注意力图有一定的益处,那不禁要问,更好的注意力图是否也能滋养TransMix?
假设使用的注意力图越好,TransMix对混合目标分配的调整就越准确。例如,Dino证实,通过自监督训练从模型中获得的注意力图保留了更高的质量。
为了验证更好的注意力图是否有助于TransMix,作者设计了一个实验,用从参数冻结的外部模型生成的注意力图代替注意力图。外部参数冻结模型可以是:
Dino自监督预训练DeiT-S
在ImageNet-1k上监督训练的DeiT-S
Deit-S,通过ImageNet-1k上的知识蒸馏设置进行监督训练
然而,表6显示的结果与假设相反。

4.5 泛化性研究
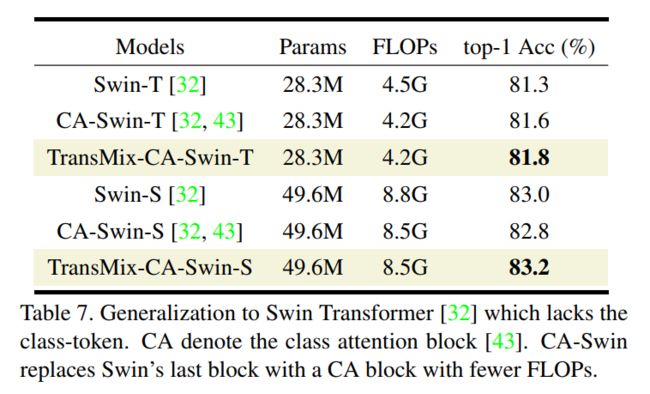
以上的3个模型均为相同的28.3M参数。TransMix-CA-Swin-T和CA-Swin-T的FLOPs比baseline Swin-T低7%。Swin-T、CASwin-T和TransMix-CA-Swin-T的top-1验证精度分别提升到了81.3%、81.6%和81.8%。在Swin-S上的TransMix提高了性能,同时也减少了FLOPs。初步的研究证明了TransMix的可推泛化性。
4.6 Mixup变体的对比
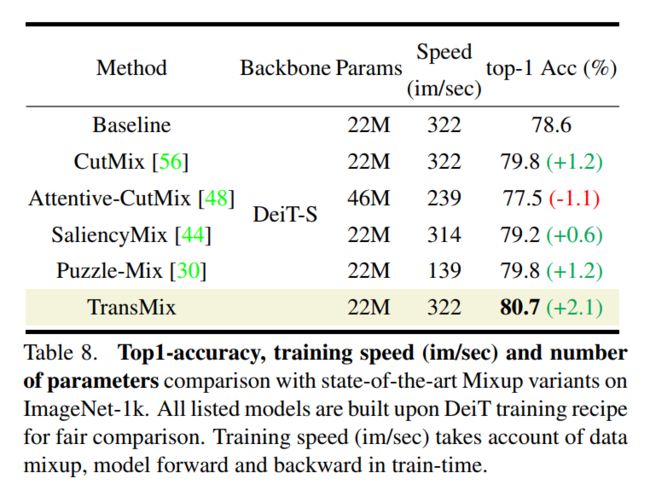 表8
表8
表8显示TransMix显著优于所有其他Mixup变体。与传统的CutMix相比,基于显著性的方法(如Saliency-Mix和Puzzle-Mix)并没有显示出Vision Transformer的优势。作者分析说,这些方法是笨重的调整和面临困难的转移到新的架构。
例如,Attentive-CutMix不仅带来了额外的时间,还带来了参数开销,因为它引入了一个外部模型来提取显著性映射。Puzzle-Mix在一次训练迭代中前进和后退两次的速度是最低的。相比之下,TransMix以最高的训练吞吐量和无参数开销获得了惊人的2.1%的性能提升。
4.7 消融实验研究
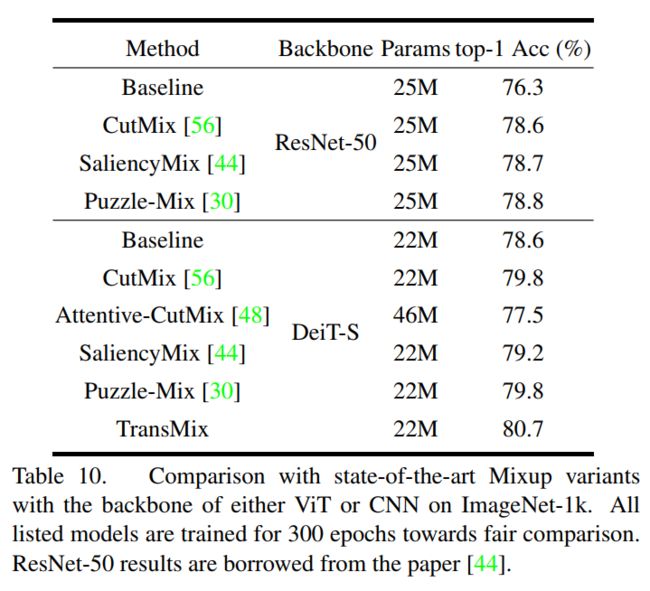 表10
表10
DeiT-S作为Backbone,其参数数量与ResNet-50相似。从表10中可以看出,Saliency-Mix和Puzzle-Mix在ResNet-50上最多只比CutMix提高了0.2%,而在DeiT-S上却没有任何进步。
4.8 可视化

ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
CVer-Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看