Attention is all you need:关于transformer中的self-attention
本来我是打算直接上swim transformer的,但是预备知识得有VIT,去学VIT,一个self-attention又给我整懵了。所以,现在回到2017年google团队发表的《Attention is all you need》
https://www.bilibili.com/video/BV1Xp4y1b7ih?from=search&seid=14536050607345172525&spm_id_from=333.337.0.0https://www.bilibili.com/video/BV1Xp4y1b7ih?from=search&seid=14536050607345172525&spm_id_from=333.337.0.0 https://www.bilibili.com/video/BV1Xp4y1b7ih?from=search&seid=14536050607345172525&spm_id_from=333.337.0.0之前我不知道该怎么称呼transformer,李老师说self-attention和CNN一样都是一种network,一种网络结构
https://www.bilibili.com/video/BV1Xp4y1b7ih?from=search&seid=14536050607345172525&spm_id_from=333.337.0.0之前我不知道该怎么称呼transformer,李老师说self-attention和CNN一样都是一种network,一种网络结构

在一般的分类任务中,输入就是一个固定长度的向量。之前为了实现加了卷积网络的分类网络可以实现多尺度融合训练,还使用了GAP技术。当然,前提是设计网络的时候必须保证多尺度输入最终的输出的通道数必须保持一致
 假如现在输入网络的是一组向量,并且向量的维度并不固定,网络应该怎么处理
假如现在输入网络的是一组向量,并且向量的维度并不固定,网络应该怎么处理

比如说,对于文本信息而言,每个句子的长短是不一定的,如果将一个句子中的每一个词汇都表示一个向量, 每次单词的长度也可能是不一样的,因此这样就会导致向量组的长度、每个向量的维度是变化的
如何将单词向量化呢?
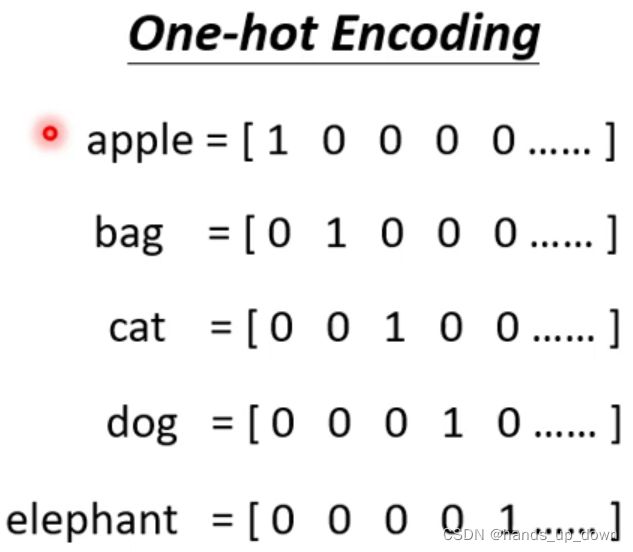
首先建立一个包含所有英文单词的语料库,那么一个单词在这个语料库里面就有一个唯一的序列号,这个序列号使用独热编码来表示。很明显,这个独热编码的维度是很高的,完全没有必要,浪费资源。另外,这种编码没有结构化,反映不出除序列之外的任何信息
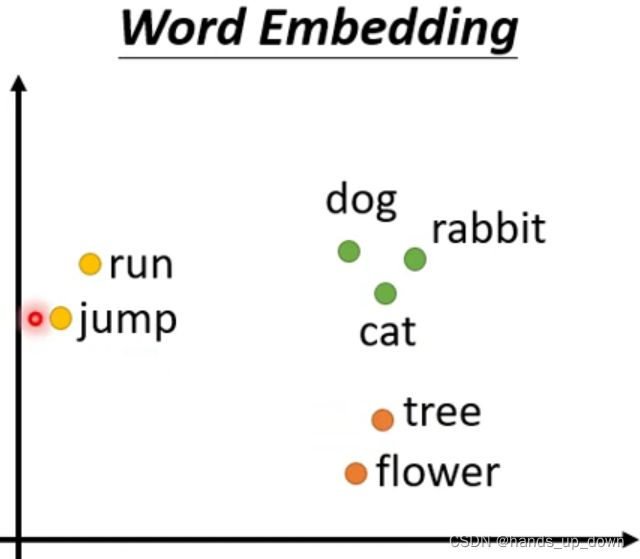
这个embedding是真的抽象,单词嵌入??另外,yolo2似乎坐过类似的将数据进行结构化的尝试
音频和文本信息类似

图网络中每一个节点包含的信息

每一个元素使用独热编码来表示
网络输出的类型:
(1)
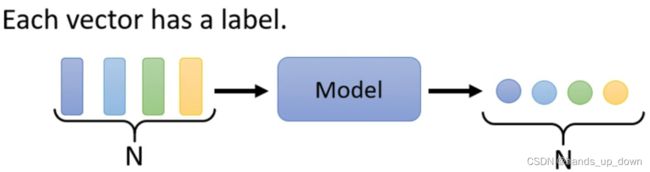
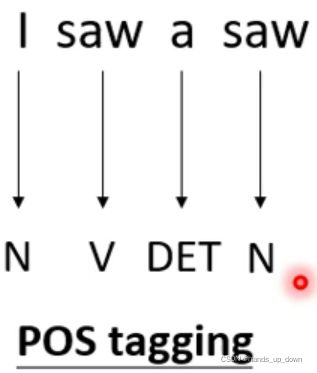
这在CV里面从来没有遇到过。比如说NLP里面的词性标注任务。输入几个词,就必须输出几个词性
(2)
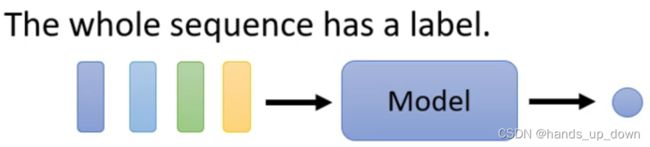

NLP里面的情感分析,对一整个句子做一个一维的评价
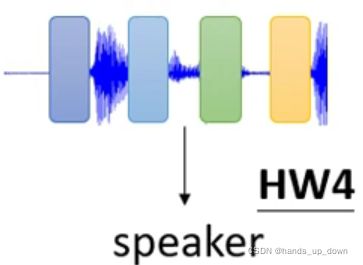
发言人辨认以及分子式输出都是类似的,像CV任务的输出似乎也是这种
(3)
 想具体的机器翻译任务就是典型的模型自行决定输出的label的数量
想具体的机器翻译任务就是典型的模型自行决定输出的label的数量
现在以第一类输出为例,
比如说词性标注,本质上标注每个单词的词性就是一个分类任务,那就一个一个处理
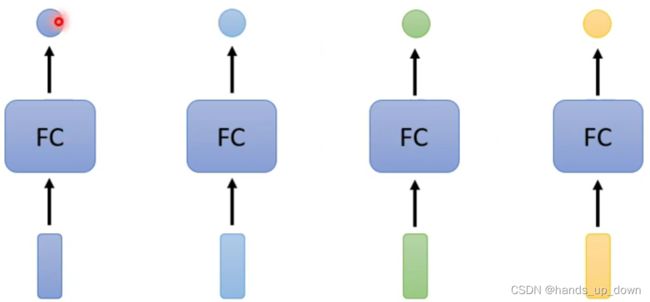
但是,FC依赖于输入的特征,如果输入的特征一样,那么输出是一定不变的。这就意味着他无法处理一词多义的问题。比如,i saw a saw,我看见一把锯子。两个相同的saw输入FC,输出肯定是一样的
改进:
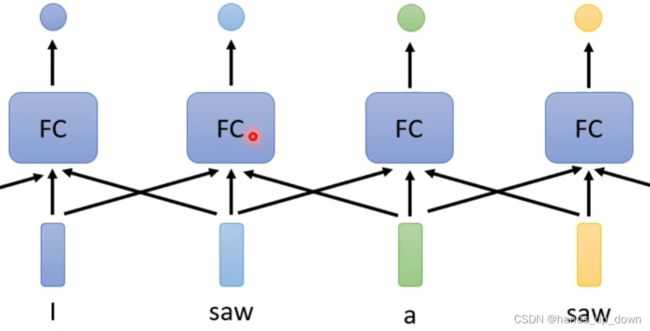 这种方法有效吗??FC我认为是统一的分类器啊,这样的话就把FC当成了单独的部件,跟SVM一样了
这种方法有效吗??FC我认为是统一的分类器啊,这样的话就把FC当成了单独的部件,跟SVM一样了
还有一个问题,这个任务究竟要用多少个FC,我倾向于就一个。就一个的话是无法处理上面提到的一词多义的问题的
我基于前面提到的独热编码,有这样一个判断,在这个判断下,网络确实只需要一个FC:
首先,每个单词都是用独热编码表示,每个表示都是唯一的。因为FC是强依赖于输入的特征,所以只要输入的特征一样,那么经过同一个FC的输出必然是相同的。前文提到,向网络中以上下文为单位输入特征。按照上图的方式,每次输入目标单词以及它的前一个和后一个单词,相当于每次向FC输入三个独热编码长度的特征,这也符合FC要求输入层维度不变的要求
但这种方式只是对独热编码的简单叠加,其实计算效率非常低,可以说叠加一次,网络的速度就会慢很多,计算量呈数量级增长
这样一来,按照上图的设计,相当于每个单词的词性,是由三个单词来确定。虽然一个词有多种意思,但不同意思的上下文是不同的,这样就能区分开来

紧随而来的另一个问题就是,我的上下文应该设置多长呢??假如有一个单词的词性必须通过整个句子才能判断,难道说其他的单词也要跟着如此吗??这样网络的效率会不会太差...
总结:对于词性标注任务,
stage 1: 只通过目标单词本身的信息来判断词性。无法处理一词多义
stage 2: 通过目标单词的前后两个单词以及它本身来判断词性。上下文究竟该设置多长
到这里,本篇文章的主角self-attention终于现身
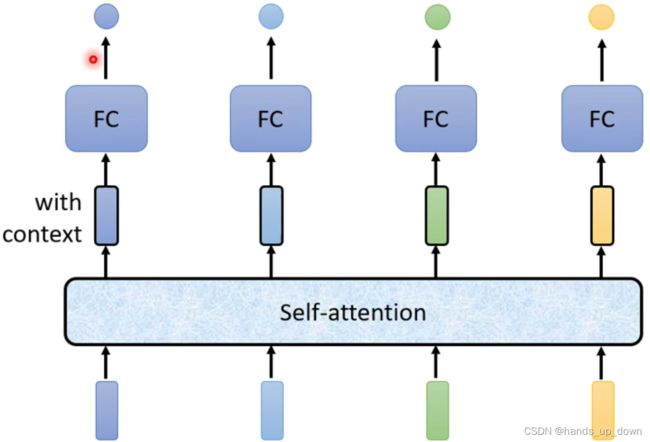
首先,self-attention部件吃进整个句子的信息,然后输出和输入的向量个数相等的特征向量,每一个特征向量都包含有self-attention部件处理过后的上下文信息,然后将特征向量送进FC进行分类。
问题就来了,这个包含上下文信息的特征向量的维度是多少呢??
self-attention部件是可以叠加的:
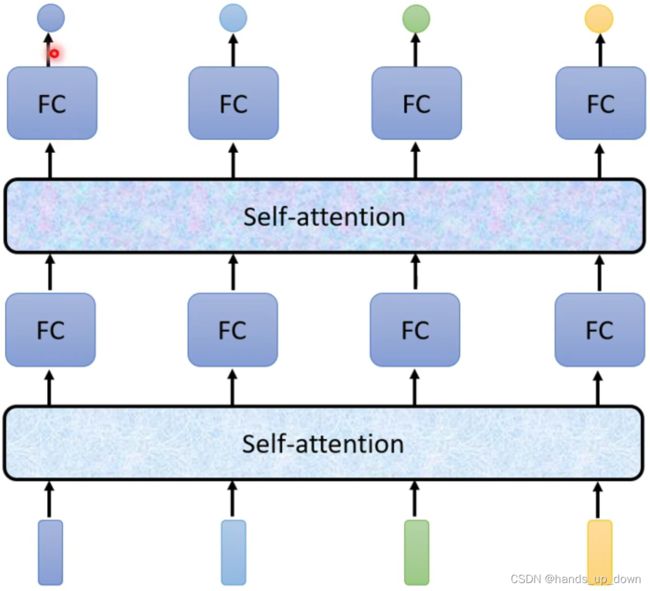
这个部件的使用其实很像激活函数的使用,输入一个值,输出一个值;self-attention部件属于是输入一组向量,输出一组向量,个数都是相同的。如果是接在输入层后面,处理过后就相当于网络有了新的输入;如果是连接在hidden layer后面,就相当于网络的下一层有了新的输入
基于现在掌握的情况,我做以下猜想:
在前文中,我简单地将独热编码在维度方向上进行叠加,这种方法会呈指数级增加运算量。我们的目的是对FC的输入进行区分,因此可以采用向量相加的方式,独热编码本身是惟一的,相加之后仍然是惟一的。这样一来,无论上下文的长度去多少,FC的输入的维度始终是一定的。
另外,简单的attention机制。实际上,就是为全文信息生成一组权重,这组权重仍然是可以通过神经网络来学习的,权值与相应的独热编码相乘,得到的新向量仍然是惟一的。甚至说还可以做归一化
如何加上卷积网络?如果是直接在输入层后面加入卷积网络,那就使用1*1卷积;也可以对独热编码进行重排,重拍之后的结果一定也是唯一的,然后再进行卷积处理。这样一来,其实自由度就很高了。而卷积网络内部,又可以设置通道注意力和空间注意力部件
self-attention部件的内部结构:
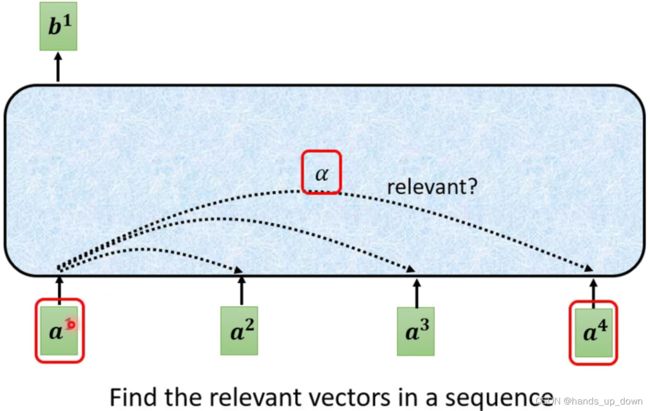
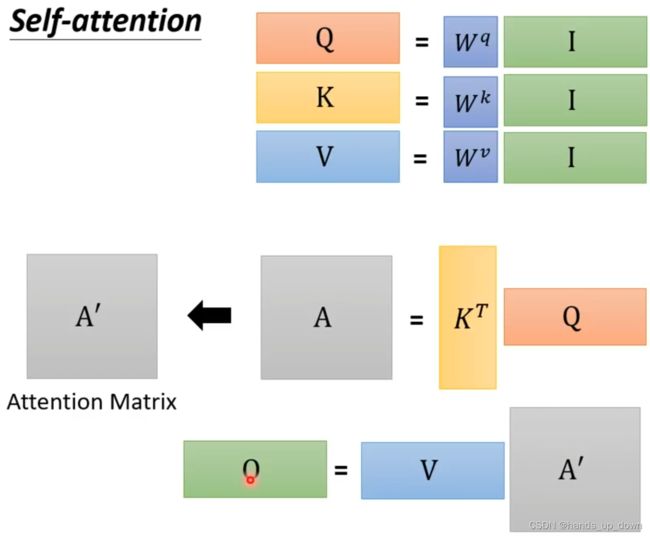
前文提到,self-attention部件吃进全部的信息。首先,他要确定其他输入向量和当前向量的关联程度,这个程度使用α来表示,实际上这就是权重。可以这样讲,两个向量的关联程度....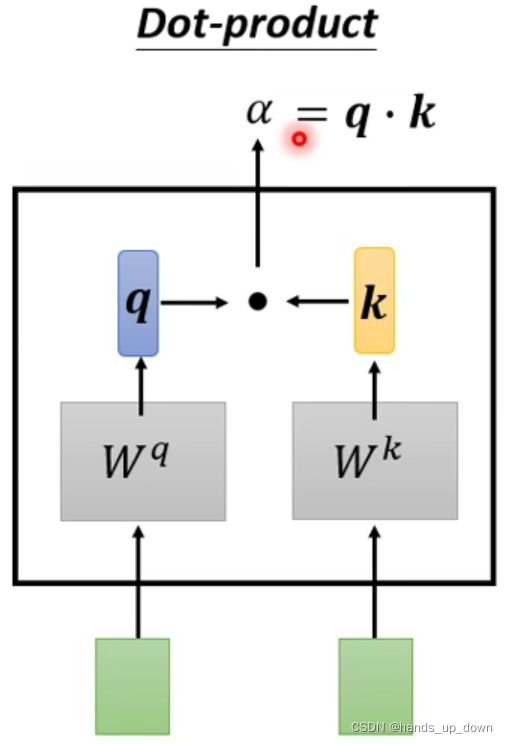
方法一:点积法。那么这两个矩阵是可以进行迭代,可以进行学习的吗??向量的点积与它们夹角的余弦成正比,如果是单位向量,可以反映两个向量的相似性。内积为0,两向量垂直。从更高维度出发,内积可以引出希尔伯特空间和傅里叶变换
假设q为给定权重向量,k为特征向量,则q*k其实为一种线性组合,函数F(q*k)则可以构建一个基于q*k+c = 0 (c为偏移)的某一超平面的线性分类器
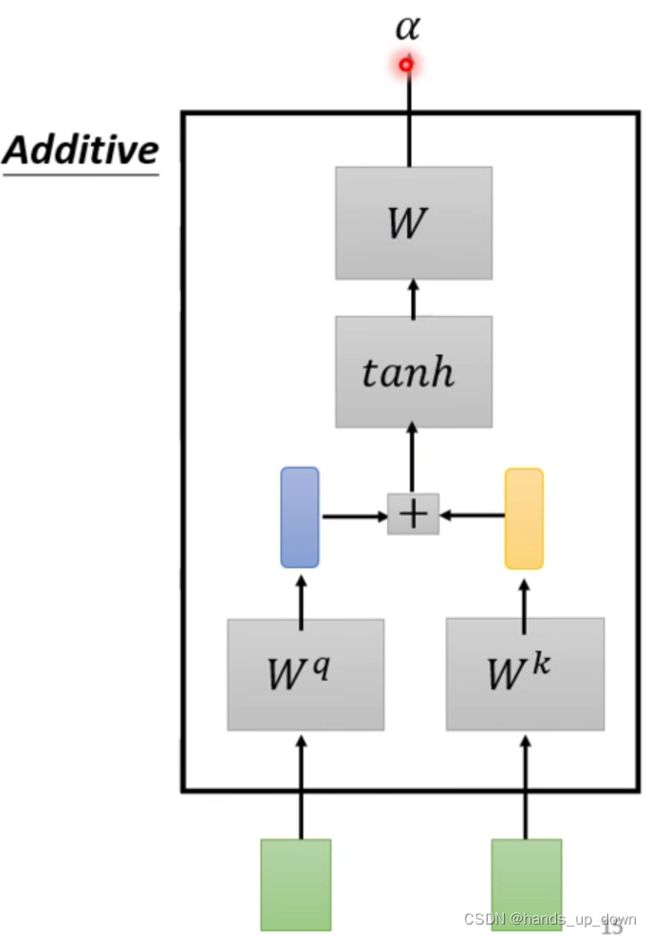
方法二:使用了激活,还是那个问题,这是可学习的吗??
常用的方法是法一,dot-product点积法
矩阵q是一个可以重复使用的值,给他一个名称query, 好像是之前李沐讲的什么随意线索。用来搜索一系列的relevant content,α。
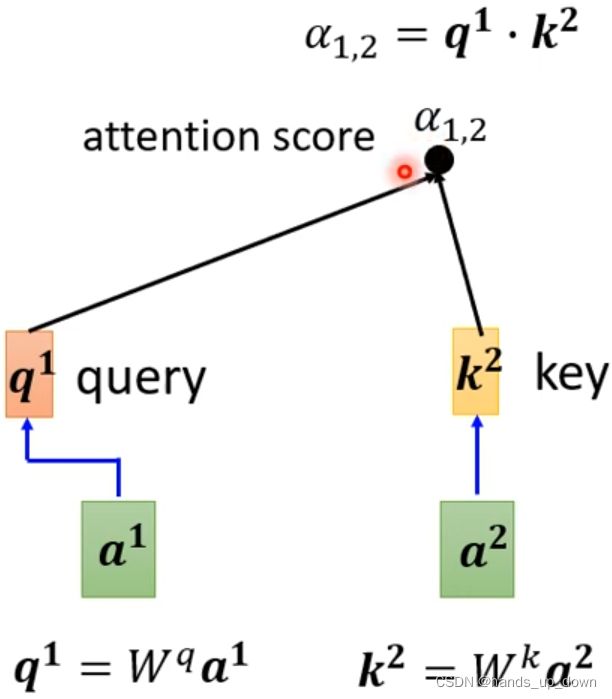
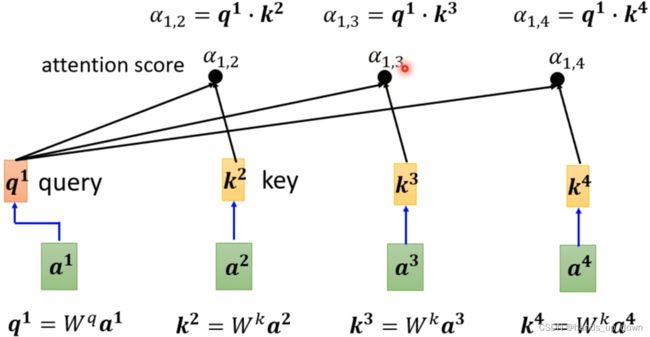
这张图就说明了self-attention部件里面这个dot-product是如何进行的。α反映的是两个向量之间相关的程度,在注意力机制之下,又叫做注意力得分,attention score
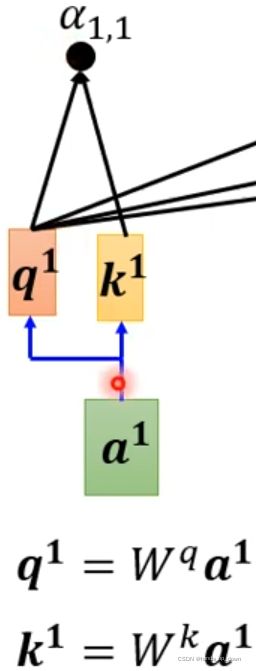
在实际的运算中,还需要计算自己跟自己的关联性,在这里的计算中并不只是单纯的进行点积计算,在点积之前,两个向量分别要做矩阵运算
矩阵运算的含义可以从很多角度来解释,如果是从坐标变换的角度出发,矩阵可以看做是对运动的描述,那么矩阵乘法有三个维度上的作用,缩放、旋转、平移,因此,当你对同一个向量变换了坐标系之后,他们之间的相关性肯定会发生变化
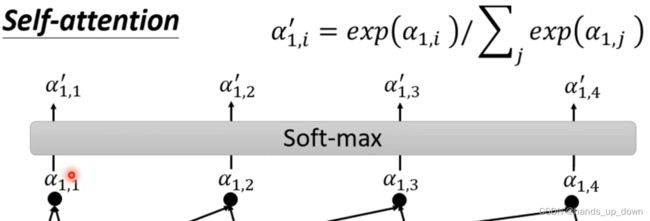
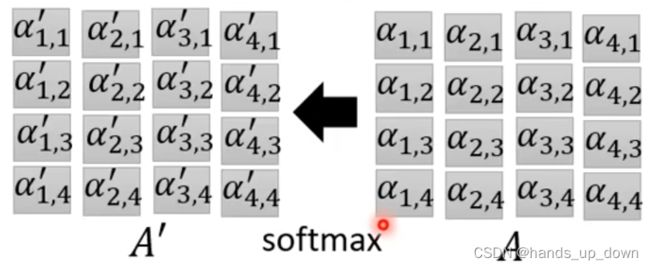
在做softmax之前需要对α1,1进行缩放,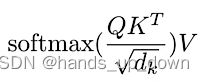 ,其中dk表示向量q,k,v的维度
,其中dk表示向量q,k,v的维度
之后对输出的attention score做softmax处理,仍然是那种输入多少个,就输出多少个的计算
这里的选择其实是开放的,其实仅仅做一个归一化也是可以的,做relu都行,主要目的是加入一些非线性因素
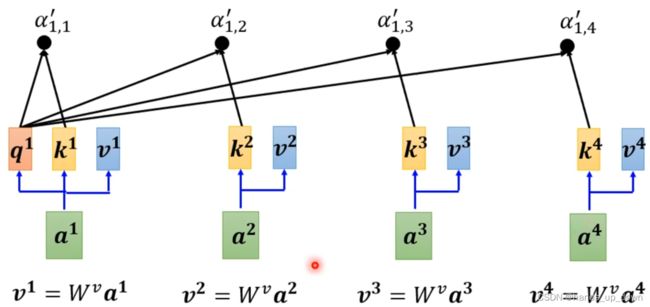
可以看到,计算完attention score之后,再一次对输入的向量做了矩阵运算,得到了v。我严重怀疑,q,k,v全部都是向量。这种设计思路就很明显,必须对向量做变换,就是不使用原向量作为FC的输入。这从某种意义上,是不是也在提取特征呢??
很有可能V的维度和原向量是一致的
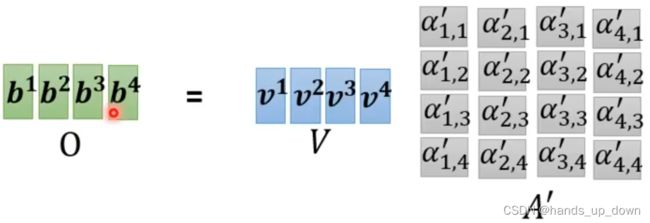
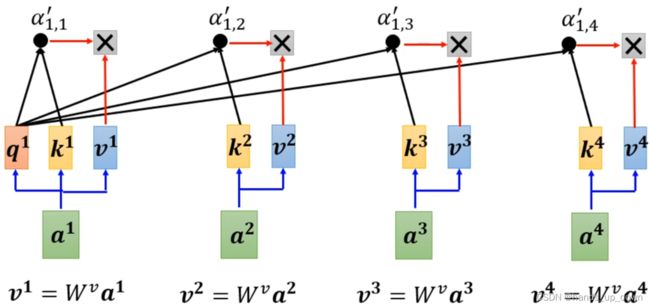 将权重,也就是attention score乘到V向量上去
将权重,也就是attention score乘到V向量上去
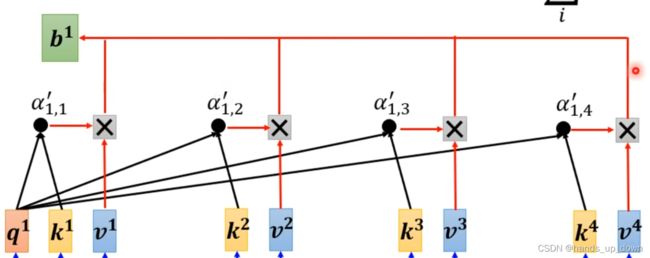 bingo,我的猜想没有错,最后果然是加起来
bingo,我的猜想没有错,最后果然是加起来
在具体实现中,每个输入向量经过self-attention模块处理后的向量是一次性计算的,不是通过循环依次计算,因为某些值在计算中是共享的,或者说是重复使用的
 首先,对于每一个输入的特征向量,共享w_q,w_k,w_v,进而可以计算出各自对应的q_i,k_i,v_i. 就是说在self-attention部件中做计算时,每个特征向量计算出的q,k,v都是固定的
首先,对于每一个输入的特征向量,共享w_q,w_k,w_v,进而可以计算出各自对应的q_i,k_i,v_i. 就是说在self-attention部件中做计算时,每个特征向量计算出的q,k,v都是固定的
如何进行统一计算??
(1)得到每个特征向量对应的q_i,k_i,v_i
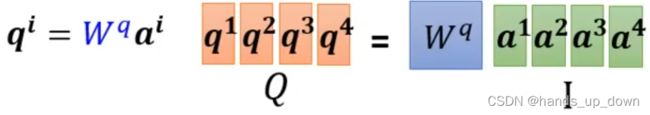
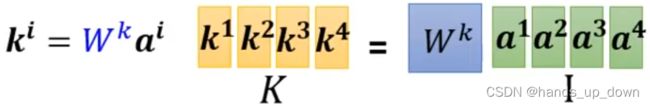
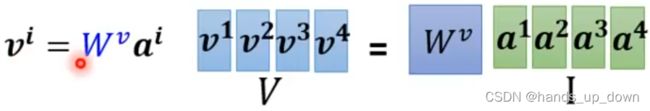
(2)计算属于每个特征向量的多个attention score

到这里,我已经十分确信q_i,k_i,v_i就是向量,两个向量做点积运算。所谓横*竖才能得到一个数,把k_i叠起来
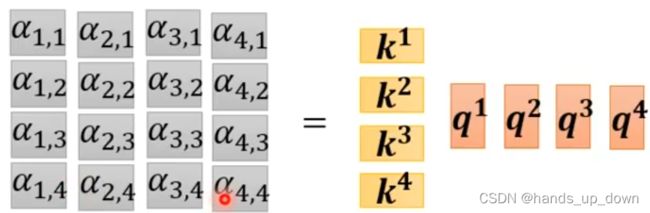 妙啊!!!!!!
妙啊!!!!!!
 最后再做一下softmax,加一些非线性因素进去
最后再做一下softmax,加一些非线性因素进去
 最终的输出就是从b1--b4.总结下来就是
最终的输出就是从b1--b4.总结下来就是
救赎之道,就在其中啊!!
前面讲到点积法的时候,我就有疑问,并且猜想w_q,w_k,w_v是可以进行学习的,w矩阵的每个元素都要参与到运算中,反向传播当然也适用于它
进阶版的self-attention模块:multi-head self-attention
这个地方的head怎么理解,我猜是和之前在yolo中提到的分类头,定位头差不多的,估计和级联cascade也是有类似意思的
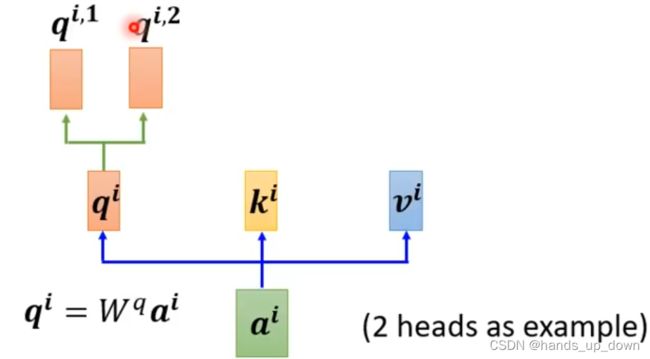
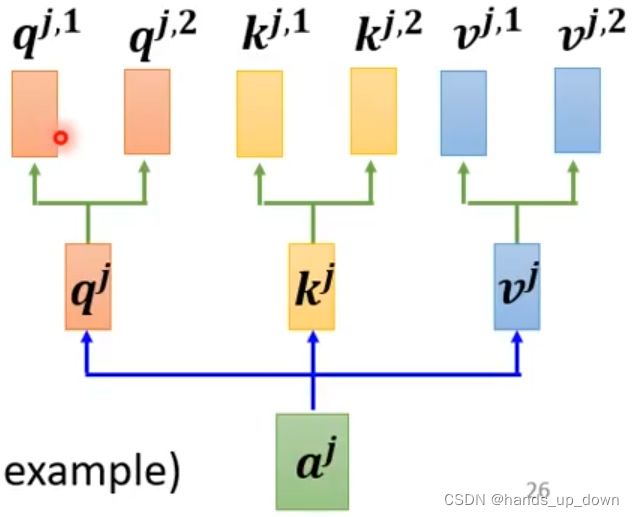
上图就是一种2-heads self-attention
多头self-attention实际上就是配备了多组矩阵Wq,Wk,Wv,从而计算出多组向量q,k,v
但还有一种操作,将向量q,k,v都分成head个等长的新向量。这种多头机制肯定比上一种节省计算资源

将这两个向量叠起来再做一次坐标系变化,缩放、旋转、平移。这是将多头的结果concat到一起,再做一次映射,融合成最终的结果
可以这样理解,相关性有很多种,因此我们在计算attention score的时候,根据情况,看需要计算多少种相关性。每一个query都要和k去做计算
在翻译或者说语音这样的任务中,multi-head就是非常有必要的
另外,self-attention部件并不能感知到输入的特征向量的顺序,但是对于带有时序的信息来说,位置信息又是十分重要的

如何让self-attention部件可以感知到位置信息呢??


我猜这个位置信息是不是也是用的one hot coding,独热编码
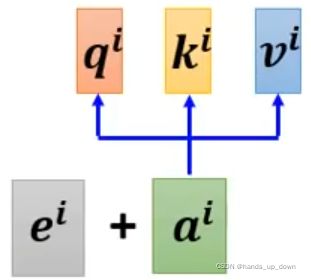
位置信息需要提前加到相应的特征向量上面去。在位置信息e_i的具体取值上,有许多种方法。这里没有办法直接使用独热编码,因为在默认情况下,位置编码的维度应该和输入向量的个数一样,这显然和特征向量的维度不一样。当然,可以直接对位置编码进行升维,这没有什么影响
我看人家用了很多复杂的方法来生成这个位置编码,同时位置编码也是可学习的
self-attention机制也可以用在语音领域

语音的切分通常是10ms一个划分,1s的内容就是100个向量,这个输入的规模是非常庞大的
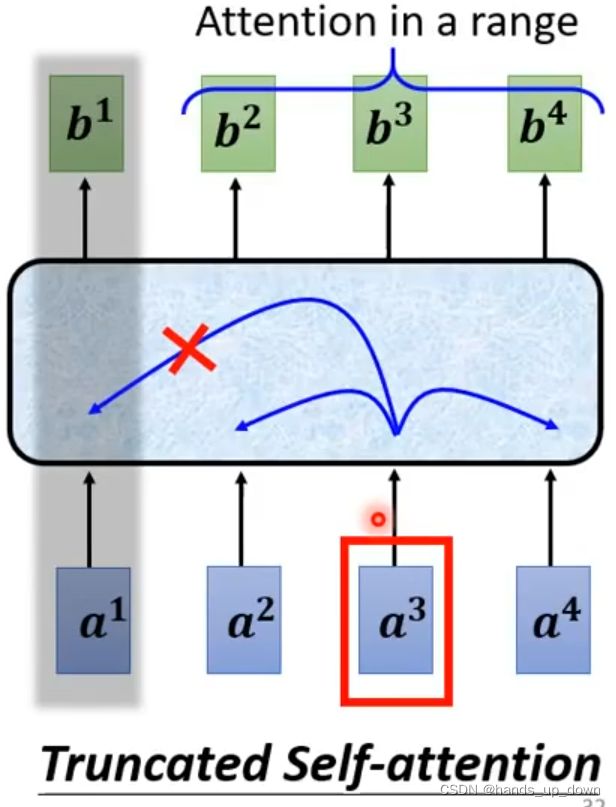 缩减的,删节的self-attention
缩减的,删节的self-attention
self-attention这个部件在处理词性标注问题中的一词多义时,就是要考虑整句话的信息;但是到了语音任务上,因为输入的特征向量的数量过于巨大,有不得不主动选择忽略某些信息


这个地方去三个通道的一个像素值组成一个维度为3的向量,这种方式跟以往很不同。通常一个通道上的特征是有空间信息的,以像素为单位分割通道特征,会不会丢失空间信息呢??
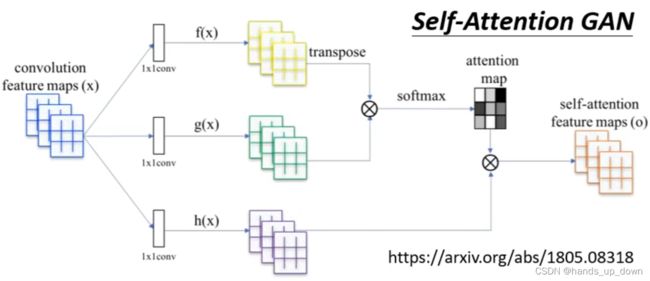
看起来不太像通道注意力机制
我前面还在批判以像素为单位进行信息提取,这后面就在说CNN可能是一种简化版的self-attention机制。比如说,以一个通道的特征为例,虽然说卷积最终也是提取一个通道上的所有信息,filter的感受野也会有那么大的范围,但是一次卷积操作,或者说feature map上的一个值始终是由filter大小的信息计算出来的,虽然我们设置了stride机制,会让滤波器对整个通道的特征信息进行提取
另外一方面,之前在计算感受野的时候我们就已经说过了,为了简化网络的参数量,始终有一个减少filter维度的倾向,就是用多个小的滤波器替代大的滤波器,通过前面的描述,小的滤波器意味着什么,我想就不需要过多赘述了
通过前文对self-attention部件计算过程的描述,我们已经知道self-attention部件会吃进全部的信息,并且每一个输入的特征向量都会综合全部的信息从而得到一个新的对应的向量


 这篇论文从数学的角度论证self-attention和CNN之间的关系,CNN就是前者的一个特例
这篇论文从数学的角度论证self-attention和CNN之间的关系,CNN就是前者的一个特例

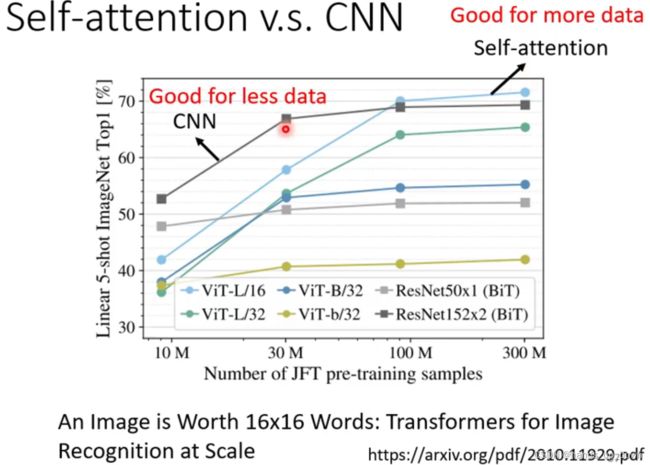
从这篇论文统计的结果来看,self-attention模块的参数量比较大,至少是大于CNN的,两者相比较有这样一种现象:随着数据量的增大,原本优于self-attention的CNN逐渐被self-attention超过
如果以后要做模型性能的消融实验,跑多个模型就成了必要的措施。这确实挺费时间的。
说道imagenet任务,alexnet好像是降到了15,之后resnet降到了5,最后是加入了attention mechanism的SENet将错误率降到了3以下
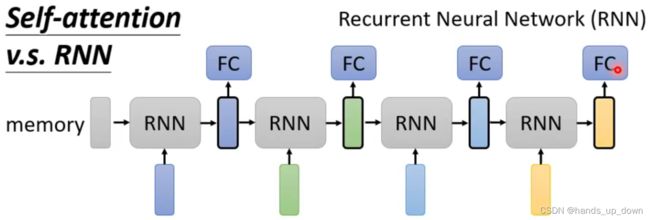
之前看RNN一直没太看懂,这里就简述了RNN的原理。首先RNN网络是用于处理带有时序的数据,。和上面说过的词性标注任务类似,它的输入是一串特征向量,然后有一个Memory模块,这个模块也会产生向量。之后将memory产生的向量和输入的第一个特征向量全部喂进RNN网络,最后输出一个向量
输出的这个向量有两个用处,一是送进FC进行处理,二是和第二个输入的特征向量一起送进RNN网络进行处理去生成下一个输出向量。以此类推,其实这种结构看起来就是简化版的self-attention
RNN的缺陷:memory模块的核心其实和self-attention是一样的,就是尽可能将上下文的信息都融合进相关的输入特征向量中,对每一个输入都做全局信息处理。但是,RNN的组织方式就导致两个问题:(1)memory模块需要单独存储处理过后的数据,非常耗费内存(2)memory模块的输出是有时序的,这就导致无法进行并行计算
如果有一种网络的组织方式可以达到同样的效果同时又可以进行并行计算,而且还不耗费额外的内存,那么self-attention就是一种升级版本
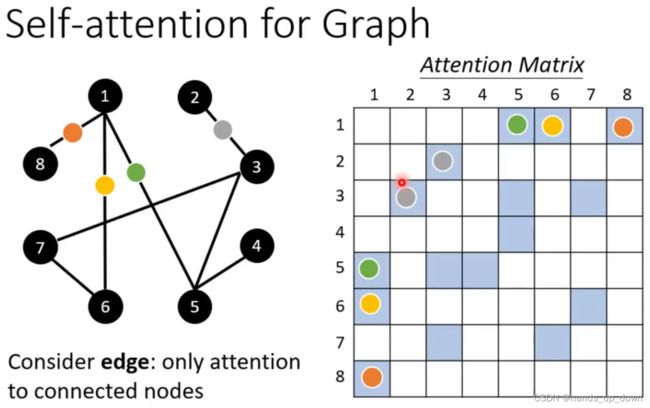
self-attention在图结构上的应用。右边这个attention matrix是对称的。在self-attention模块中很重要的一环是计算attention score,这个分数反映的是两个向量的相关程度。那么在图里边就需要计算两个点的相关程度,既然图里边两个结点之间有边,那就可以直接计算有边相连的两个点
但说实话self-attention模块用在图上有什么作用呢??
GNN-graph neural network

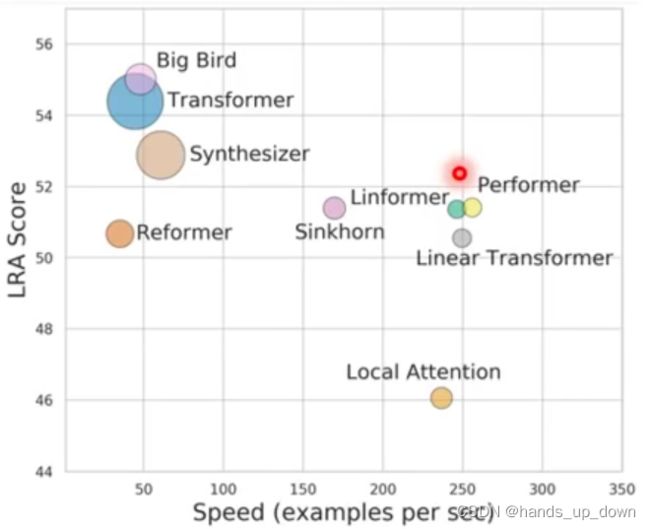
前面在讲解self-attention计算过程的时候已经说了,光是attention matrix的计算,它的时间复杂度就已经是O((输入的特征向量的数量*输入的特征向量的维度)^2),这个计算量是非常巨大的。因此,之后的很多工作都是在保证原有精度下,尽可能提升self-attention的运算速度

transformer:一般讲到transformer就是在将self-attention这个模块
transformer就是一个seqtoseq的model

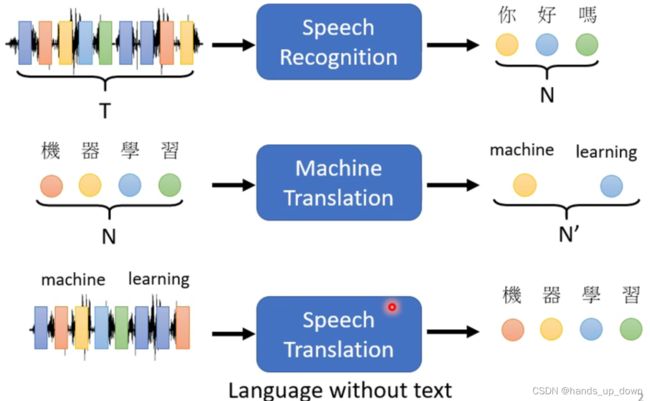 按照定义,speech translation = speech recognition + machine translation
按照定义,speech translation = speech recognition + machine translation
但是为什么需要单独去发展speech translation的model呢??上述叠加的这种方式的前提是等式右边的两个model都能得到成功的训练。可现实情况是,很多语言是没有文字的


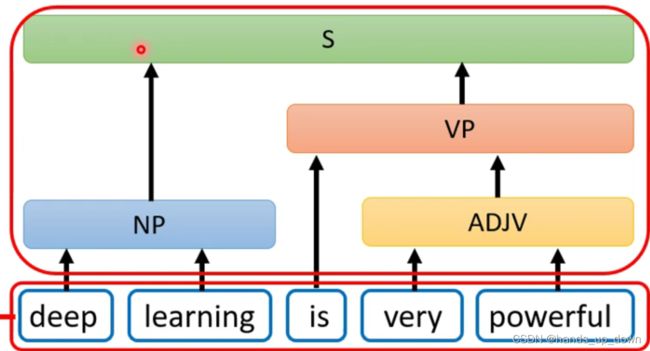
这个是将seqtoseq应用于文法分析的领域,之前搞过一个抓取错误输入的程序,我们采用的就是一种纯粹硬编码的方式,但这种方式是非常低效的。更为全面且逻辑的方式,应该是建立一颗语法树,语法树就包含了我们对输入做出的所有规定。然后将新的输入送进语法树中进行处理,其实就是遍历语法树,看在哪个节点发生错误,输出相关的错误信息。但是生成语法树的方式我没太看懂

这是2014年由谷歌提出的一个想法,将文法当做另外一种语言,然后直接套用当时最好的机器翻译模型,原作者说甚至连adam优化都没有做,就直接跑出了the state of art的结果。那这个东西的标注该怎么做呢??文法的标注

多类别标签分类任务。这个用CNN怎么做,可以思考以下。类似于top5那种,显然不是啊。这需要做多类别标注
它的输入输出模型是一对多,根据前面的描述,这种形式就是可以使用seqtoseq

在视觉任务中,你会发现很多都是一对多的形式,这就意味着全部都潜在地可以使用seqtoseq来硬解。比如说目标检测,样本中具体有多少个目标我们是不清楚的,但我们对输出的设计决定了我们的模型最多可以预测多少个目标。比如说yolo1,最多可以预测49个目标,我们规定了上限,在上限范围内,模型根据设计好的参数自行判断需要输出多少个检测框
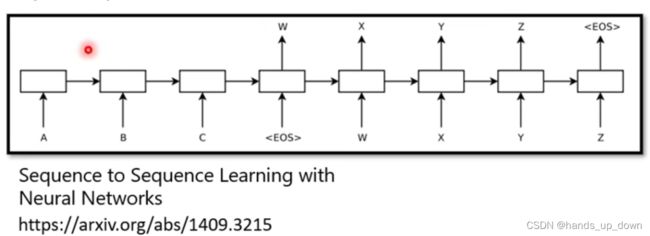
这是seqtoseq最早的模型架构
what is Encoder??
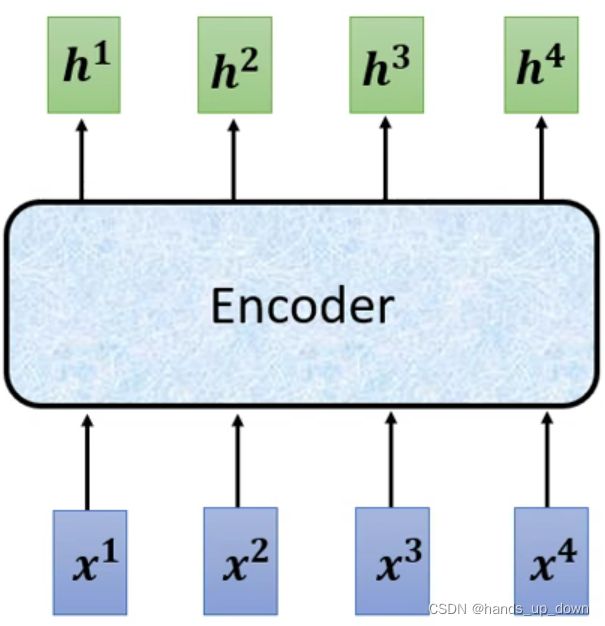
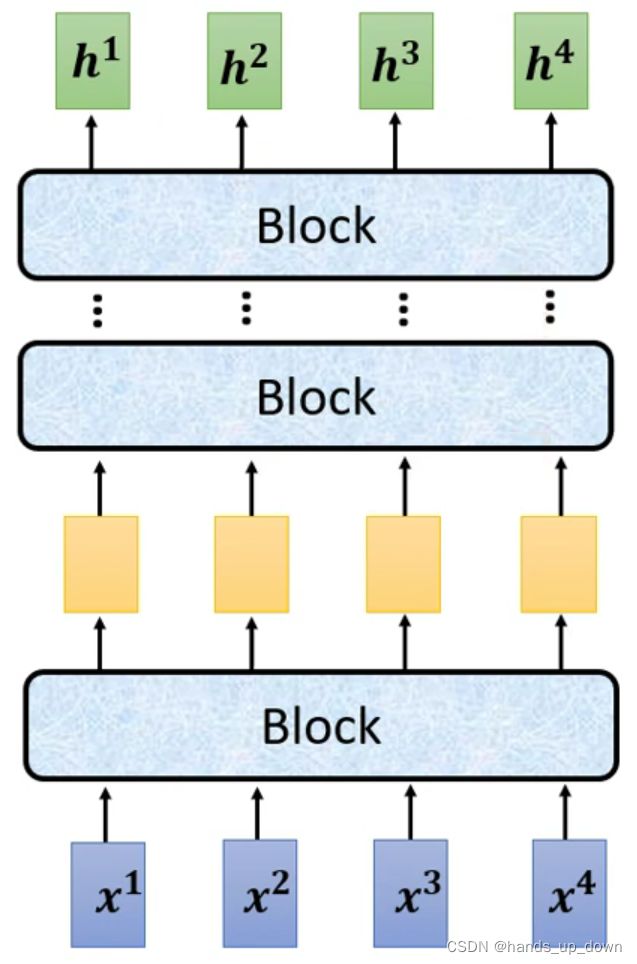
输入一串向量,输出一串向量.
每一个block的内部结构如下:
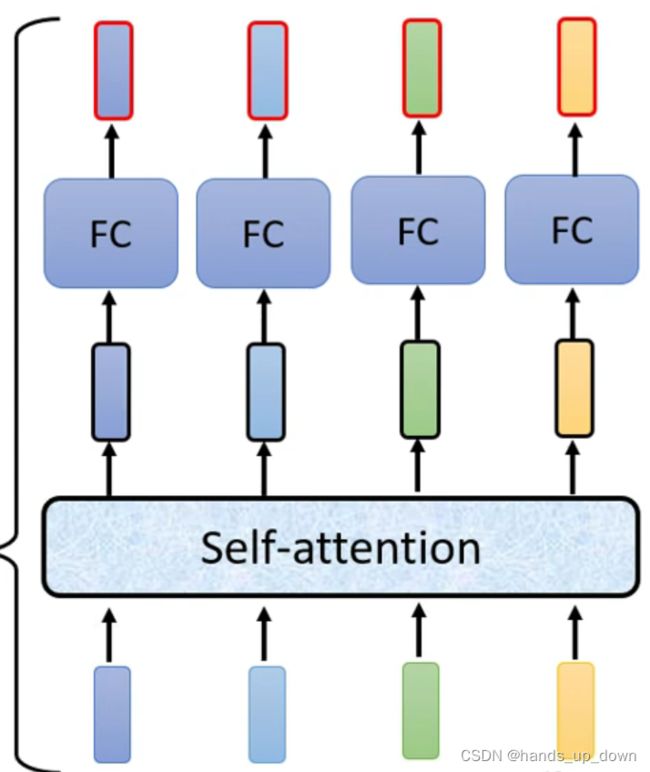
先进行self-attention处理,再对每一个向量做FC。那这种操作可以并行吗??似乎是不可以的
上述结构还可以进行残差化:
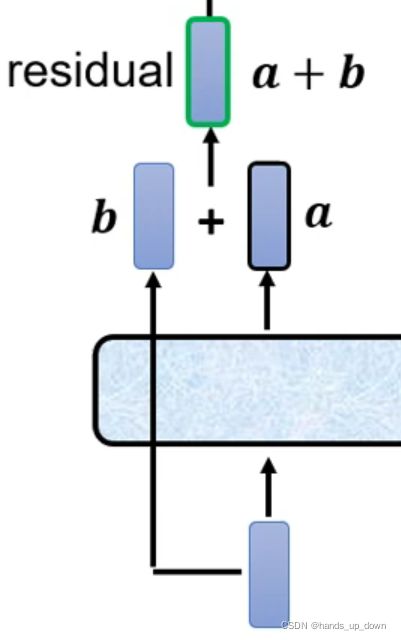 self-attention的结果再加上原向量
self-attention的结果再加上原向量
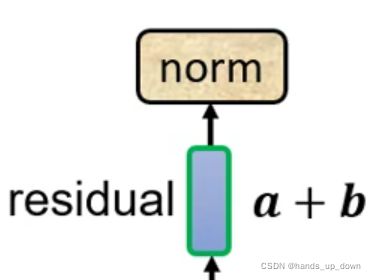
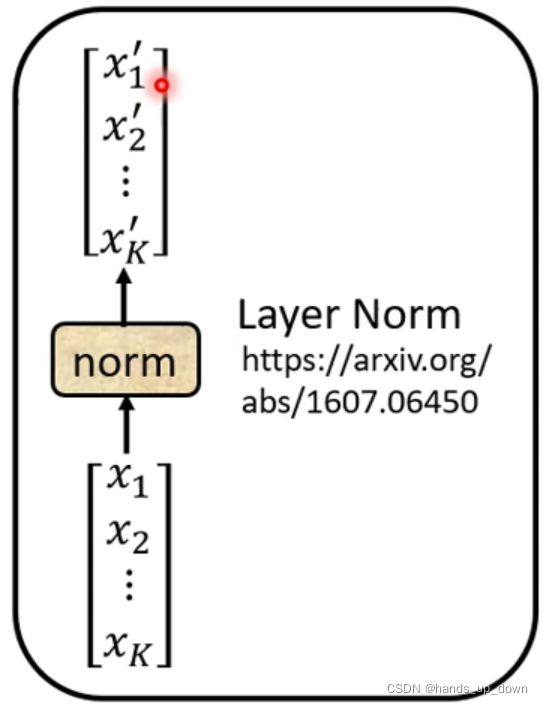
对a+b做layer normalization
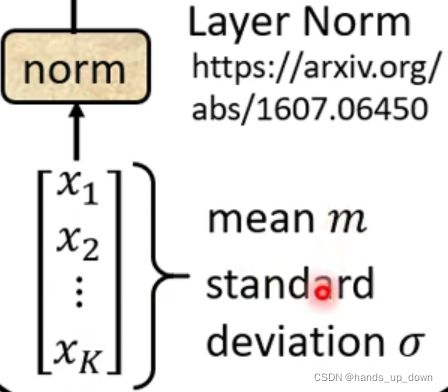
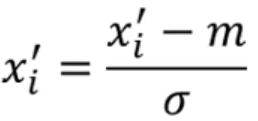
区别于batch normalization, 这里是对向量求均值和标准差。无论是哪一种,normalization都是差不多的,只是用于计算的数据不同。像BN层,他是在FC里面使用,是对同一个神经元的batch个输出做BN操作
同样的操作在FC结构上再做一次:
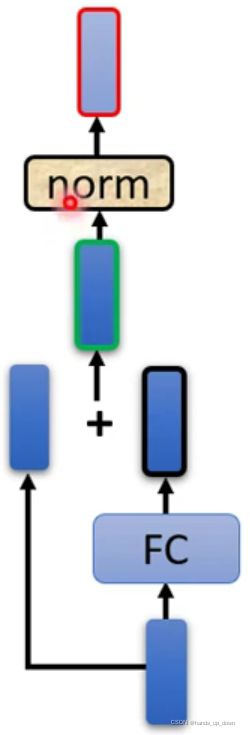 对FC的输出残差化,残差化之后的结果再做一次layer normalization
对FC的输出残差化,残差化之后的结果再做一次layer normalization
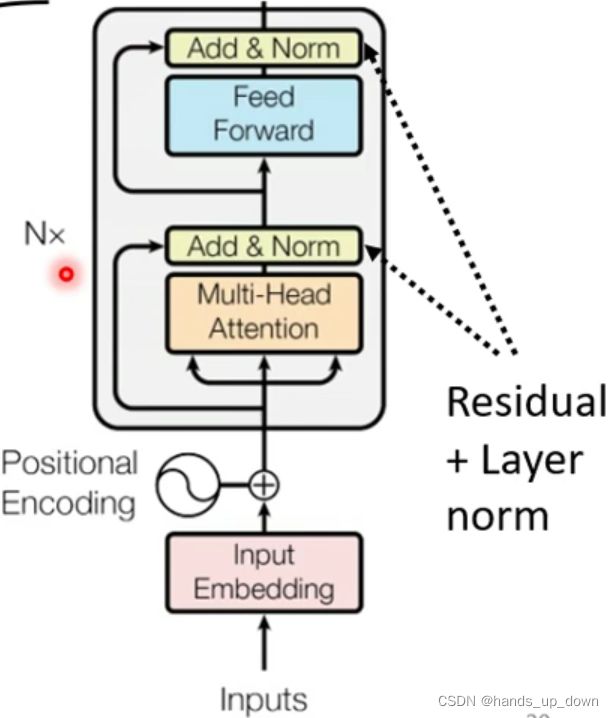
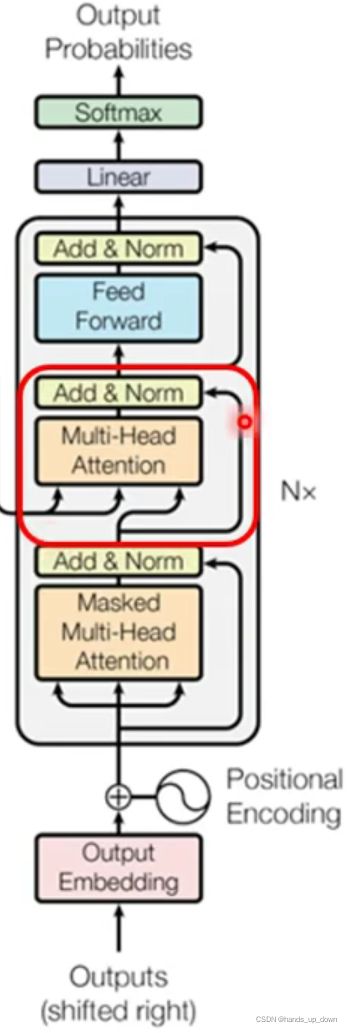
这张图就是encoder部件的精细结构。positional encoding就是前文讲过的除了要从整体上考量各个输入的特征向量之间的相关性之外,还需要考虑各向量位置对相关性的影响。PE处理就是先对输入的特征向量加入距离因素。另外self-attention部件全部使用的是多头结构,这个计算量很大
总结一下:Encoder内部是多个结构一样的block结构。输入是多个特征向量,特征向量要先经过PE(position embedding,就是对输入的每一个序列向量加上对应的位置信息,位置信息也是等维的向量,本质上就是向量相加)处理,然后再送入多个block进行处理。block的结构就是两个残差化和layer normalization化的self-attention部件和FC部件。之前就有个定义,transformer就是一个seqtoseq的网络
从我的角度来讲,在encoder部件后面再加上一个FC,设计好输出层的结构,这就是一个完整的网络结构了。参考yolo1的结构,这个网络可以用于分类和目标检测。那么,encoder就是用于提取transformer特征的网络,可以作为backbone
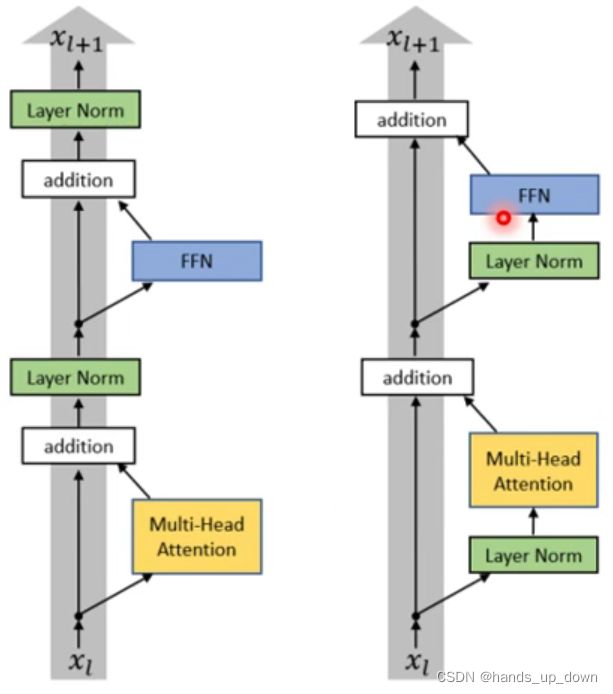
QUESTIONMARK:
(1)残差和layer normalization的位置可以换吗??
上右图就是做了更换的结构图。测试的结果是右图的结构效果更好
(2)可以使用batch normalization吗??
效果会更差
what is decoder??
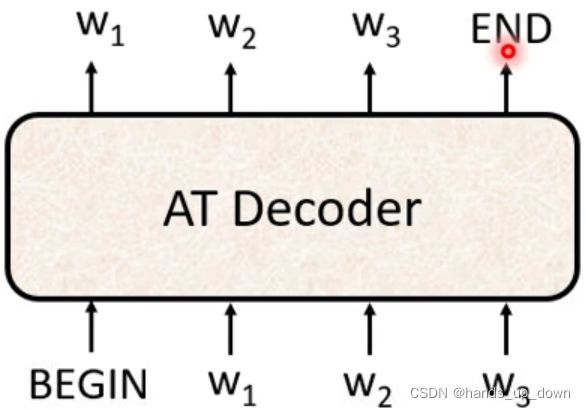
autoregressive??自回归模型。是统计上一种处理时间序列的方法,用同一变数例如x的之前各期,亦即x1至xt-1来预测本期xt的表现,并假设它们为一线性关系。因为这是从回归分析中的线性回归发展而来,只是不用x预测y,而是用x预测 x(自己);所以叫做自回归。
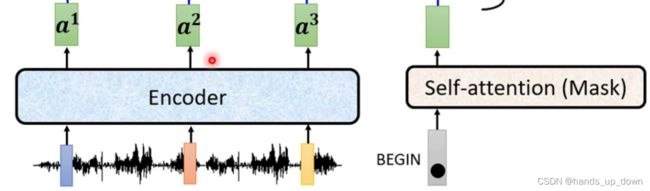
这里以语音识别任务为例:
 根据前文,我知道是将语音以10ms为单位进行切分,每10ms的语音数据作为一个特征向量,但是,不清楚这种特征向量的维度是多少
根据前文,我知道是将语音以10ms为单位进行切分,每10ms的语音数据作为一个特征向量,但是,不清楚这种特征向量的维度是多少
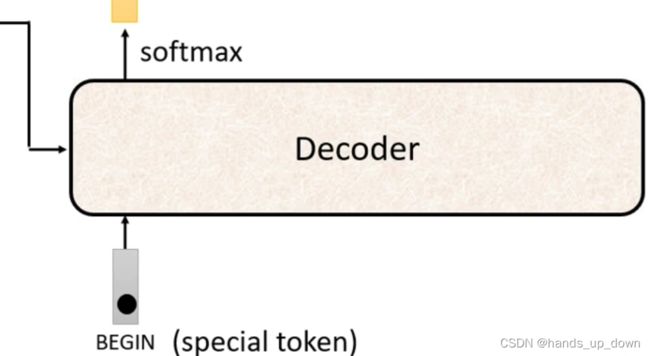 decoder的启动需要一个special token。我猜可能就是一个变量。等到encoder完成之后,就将这个变量置为1.decoder读取这个变量
decoder的启动需要一个special token。我猜可能就是一个变量。等到encoder完成之后,就将这个变量置为1.decoder读取这个变量
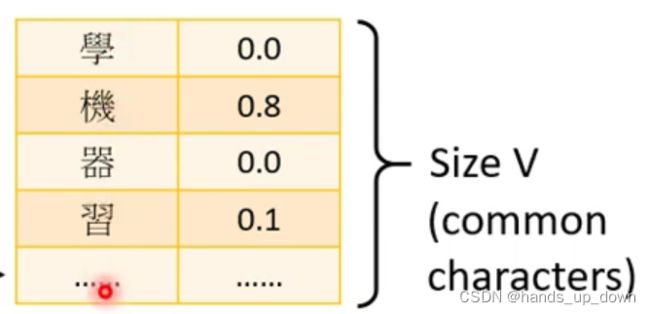 输出的是解码出的每个字的独热编码,这个和之前词性标注任务的输入特征的表示方法一样。词性标注任务的输入就是每个单词的独热编码,其维度由语料库的大小决定
输出的是解码出的每个字的独热编码,这个和之前词性标注任务的输入特征的表示方法一样。词性标注任务的输入就是每个单词的独热编码,其维度由语料库的大小决定
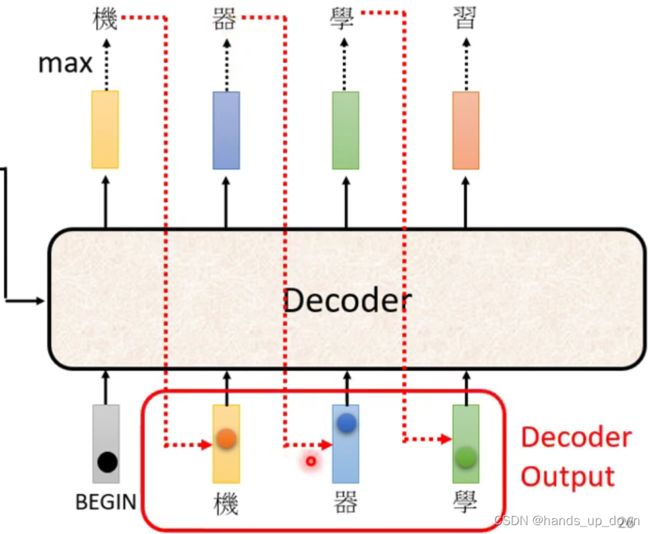
decoder的处理流程:
(1)由encoder的输出和special token作为decoder的第一个输入,从而得到输出的第一个向量
(2)再将encoder的输出、special token和decoder输出的第一个向量作为decoder的第二个输入,从而得到输出的第二个向量
(3)重复以上过程。按照我现在的理解decoder的输入会越来越多,这样怎么组织程序呢?
decoder的这种设计跟RNN有点像,但还是有很大差别。RNN用于处理带有时序的样本,所以在向网络输入特征向量的时候是按次序输入的.decoder有些不同,他有几部分输入,encoder的输出是一次性喂进decoder,但是decoder一次只输出一个向量,输出的向量是带有时序的,每输出一个向量,都会将其当做decoder的输入之一
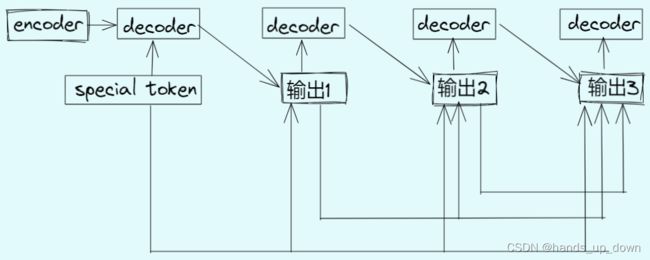
这种将最终的部分输出当做输入的做法带来的一个问题是,如果输出有误,那之后所有的输出都是基于这个错误得出的,可能就是错上加错
另外,我们设计网络的时候没有限制输出的长度,也就是说上述的结构理论上可以一直写下去。我们的期待是他可以自己学会where to stop.这种感觉有点像词语接龙
decoder的精细结构:
这里使用了改版的self-attention模块,masked self-attention

mask在DL中很常见,可以翻译为掩膜,就是说模型中会有遮住某些信息的这种机制
其实masked这种改动,是基于时序这个现实要求。如果设计的网络要求的输入特征是按照顺序依次输入,而self-attention模块是要求一次性输入全部特征向量,显然两者之间无法匹配
因此masked self-attention修改了原版的计算公式,就是说masked self-attention的输出的向量是基于当前的全局信息。重点变成了当前

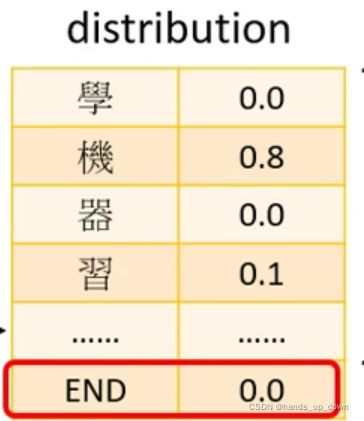
前文不是说了吗,我们希望model自己学会where to stop,所以我们增加了输出向量的独热编码的维度 ,用来表示stop token,当stop token的概率最高的时候,那么decoder的工作就结束了
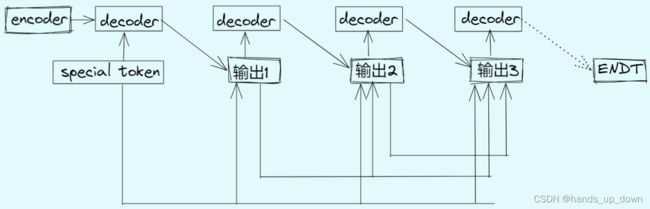
改造之后的网络结构:
 总结:我之前有个误解,认为为了程序的统一性decoder每计算一个输出向量都只需要两个输入,一个是encoder的输出,一个是上一轮decoder的输出。这是我猜的,现在大概弄明白了。decoder的输入是基于当前的全局信息,这个信息经过预处理之后,要送进masked self-attention部件进行第一次处理
总结:我之前有个误解,认为为了程序的统一性decoder每计算一个输出向量都只需要两个输入,一个是encoder的输出,一个是上一轮decoder的输出。这是我猜的,现在大概弄明白了。decoder的输入是基于当前的全局信息,这个信息经过预处理之后,要送进masked self-attention部件进行第一次处理

前文介绍的就是autoregressive模型
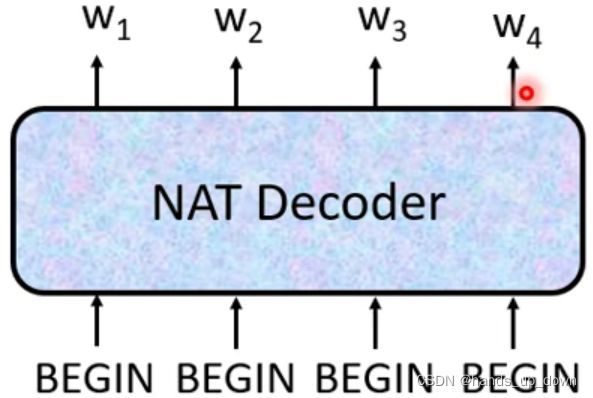
NAT,non autoregressive策略,吃进一串begin以及encoder的输出,直接输出结果。一个begin对应一个输出向量。但很明显的问题,NAT Decoder怎么确定输出的长度呢??
法一:用专门的分类器预测输出的长度。这个分类器以encoder的输出为输入
法二:人为设定一个输出长度,并且采用AT的一个做法,增加输出向量的一个维度表示end token。对于输出结果,忽略end token以及之后的向量
NAT Decoder的优势:快。从计算上来讲,他从一开始就用一系列的begin来充当全局信息,这样就可以一次性计算出结果。而AT Decoder的结构决定了他要按顺序进行运算
另外,可以更为容易地确定输出向量的数量
不过这样一来NAT Decoder是否就不需要使用masked self-attention了???
我们看到前文中提到了RNN,包括LSTM在内,他们为了体现数据中的时序关系,均采用了按顺序计算的模式,这种模式的缺陷之一就是慢。AT Decoder采用了这种模式,虽然在encoder中有self-attention部件,但他的这种改造做的并不彻底。因此,到了NAT Decoder,对模型进行了更为彻底的self-attention化增强
![]()
快的没他准??准的没他快??
这里提到原因可能是多模态造成的,multi-modality
什么是多模态机器学习?_计算机视觉life-CSDN博客_多模态
这篇文章做了一些简要的介绍
每一种信息的来源或者形式,都可以称为一种模态。例如,人有触觉,听觉,视觉,嗅觉;信息的媒介,有语音、视频、文字等;多种多样的传感器,如雷达、红外、加速度计等。以上的每一种都可以称为一种模态。形式可以被称作模态是比较符合直觉,语音是模态,视频是模态,图像是模态。但是还能说触觉、红外、雷达也是模态吗??
那根据这一点,看图说话这种项目就算是一个multi-modality的项目
同时,模态也可以有非常广泛的定义,比如我们可以把两种不同的语言当做是两种模态,甚至在两种不同情况下采集到的数据集,亦可认为是两种模态。那么机器翻译就是一个多模态任务
因此,多模态机器学习,英文全称 MultiModal Machine Learning (MMML),旨在通过机器学习的方法实现处理和理解多源模态信息的能力。目前比较热门的研究方向是图像、视频、音频、语义之间的多模态学习
这里提到全称,多源模态信息,这种说法感觉冗余太多,前面的定义里面,模态应该就包含了信息,这里后面有加了一个信息
encoder 和 decoder之间是如何传递信息的???
这张结构图里面用的还是AT结构,仍然在使用masked self-attention部件
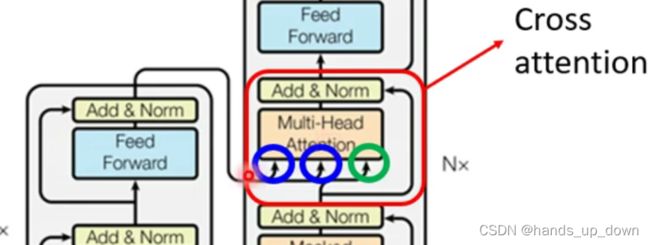
这个结构跟上面的不同,按照上面的结构图,encoder 的输入应该是在decoder处理的最开始充当其中一个输入
所以说,如果遵循这张结构图,那么encoder的输出应该参与到decoder的每一次运算。其实我觉得这也是更符合直觉。那么我前面画的粗粒度结构图,就差了encoder部件的输出充当输入这一环。encoder部件可以类比于提取卷积特征的卷积网络,提取出来的卷积特征应当被充分使用才对,不应该只用一次。右边这种跨层的箭头是残差化处理,除此之外,还要做layer normalization
decoder中间位置的这个self-attention部件有三个输入,encoder提供其中两个,masked self-attention提供一个
并不是说encoder提供两个输入,前文已经说过,encoder会输出一定数量的向量,是将输出的这所有的向量都用来充当self-attention的部分输入,而decoder的masked self-attention部件会提供另一部分的输入,最开始mask self-attention只能提供一个输出,之后逐一递增。
这样一来,我就再总结一次数据的流转情况:masked self-attention部件的输入只有begin, 以及每一次decoder部件输出的那些向量,encoder部件的输出是不经过madked sle-attentionbujian 的。encoder 部件的输出知识输入到decoder部件中间的self-attention 部件。
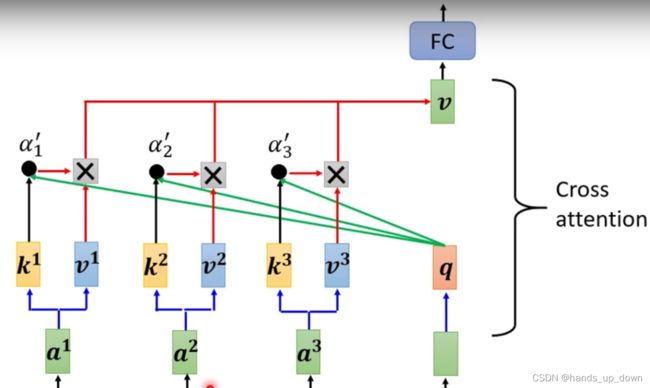
这个计算的形式可以说已经是非常的熟悉了,就是之前self-attentionbujia的计算公式。只是说这个self-attention部件的输入的来源分成了两个部分,如下图
 就因为self-attention部件的输入的来源来自不同的地方,因此这种类型的self-attention就叫做cross attention
就因为self-attention部件的输入的来源来自不同的地方,因此这种类型的self-attention就叫做cross attention
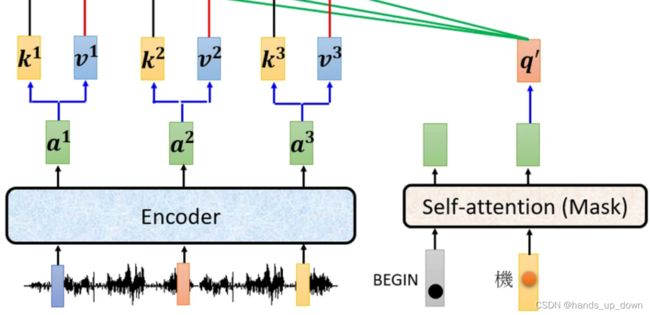 这里有令人迷惑了,为什么这个begin不参与运算了??? 难道说对于masked self-attention部件的输出的使用只是用对应轮次的向量???前面我们已经知道,self-attention部件是有多少输入就有多少输出,并且所有的输出是一次性计算完成。这里有点反直觉的原因在于,可能潜意识里面认为计算出多少向量,就必须使用多少
这里有令人迷惑了,为什么这个begin不参与运算了??? 难道说对于masked self-attention部件的输出的使用只是用对应轮次的向量???前面我们已经知道,self-attention部件是有多少输入就有多少输出,并且所有的输出是一次性计算完成。这里有点反直觉的原因在于,可能潜意识里面认为计算出多少向量,就必须使用多少
另外,masked self-attention部件的输出的特点在于,当一个向量已经被计算,后续计算中同一位置的向量是不变的。这从计算方法上可以看出,这可能就意味着masked self-attention部件在实际的程序安排中可能会有优化,将重复性的计算去除
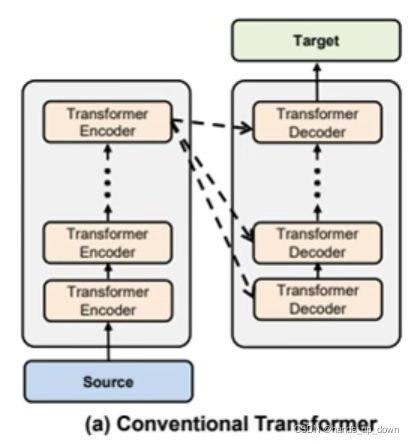
这是一张在更大尺度上的transformer结构图。可以看到transformer的输入要经过多次encoder,然后将最后一个encoder的输出充当每一个decoder的部分输入,也就是decoder中的self-attention部件需要encoder的输出。decoder也有很多个
从这个更大尺度的结构图,我们可以一直向下做细分结构的拆分。编码部分加上解码部分,其实主干全部都是使用的self-attention,而self-attention在数学上和卷积运算是等价的。是不是从某种意义上,transformer是一种全卷积网络呢??
前面又对此做过说明,卷积其实是一种简化版的transformer,transformer相对卷积会考虑全局信息,而后者只是在各自的感受野范围内去提取高维度、抽象的信息。是否可以这么讲,transformer的数学结构其实更美
卷积运算的规模之前测算过,前面也提到了self-attention部件的时间复杂度。不管是encoder还是decoder,里面的核心部件就是self-attention,因此在预估运算规模上,我认为也是基于self-attention部件。它的时间复杂度是O((输入的特征向量的数量*输入的特征向量的维度)^2)
对于以何种方式来利用各层encoder的输出,这还是一个值得研究的处女地。可以参考FC,可以参考线性回归,可以用多层赋权重结构
how to train transformer??
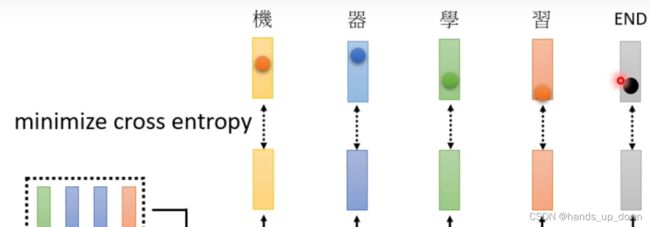
每个输出向量其实就是某个字的one hot coding,独热编码。把这样一个向量放到FC网络里面不就是一个分类问题吗。怎么计算其中的误差,标注对于每个字也是独热编码,这种形式其实我们也见得很多了,这种形式很适合使用交叉熵,cross entropy
AT方案下的decoder是没有直接限制decoder的输出向量的个数,很明显,在训练早期,很可能会遇到decoder输出向量的个数是会多于标注中向量的个数。我的想法是,计算误差的时候,直截取decoder中的前面部分,长度于标注中向量的个数一致
 这里有个问题我没有注意到。他提到,在训练transformer的时候,decoder的输入应该是使用标注
这里有个问题我没有注意到。他提到,在训练transformer的时候,decoder的输入应该是使用标注
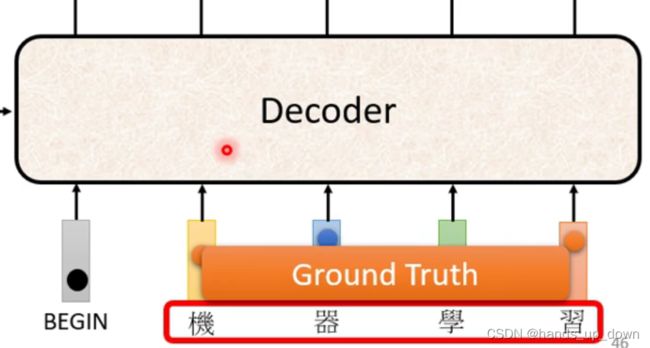
我现在的判断是这种做法可以加速模型的训练。我可以先假设,训练阶段和预测阶段一样,decoder的输入应该是自己输出的向量
前面我们提过预测阶段decoder将自己的输出作为输入的方式会造成严重的错误累积。这个问题在前文中没有得到解答,不知道这种so called teacher foring是不是在训练阶段就可以改善这种情况
并且采用teacher foring这种方法还解决了AT方案下decoder不限制输出向量个数的问题,因为标注中向量的个数是一定的,那么训练阶段decoder输出的向量个数就定下来了
QUESTIONMARK:这里存在一个mismatch,训练和推理阶段decoder采取了两种类型的输入,这种方案会导致什么问题??
Training Tips:
(一)copy mechanism
对于一些专有名词,比如说术语,名字等

比如说在聊天机器人当中,就是如此。我们希望机器人可以学到当碰到名字,他不要去做什么翻译了,直接copy就好
摘要机器人。数据的是在百万级别

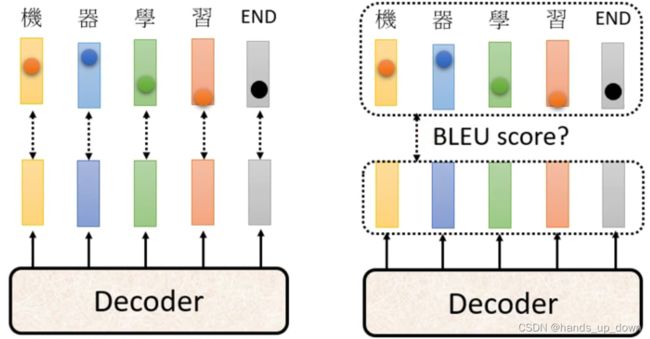 左右图是两种求误差的方式,右图这种方式没有见过。他说是计算两个句子相似程度的分数,BLEU score.但是,又提到使用这种方式来收敛的话,loss function是没有办法做微分的???
左右图是两种求误差的方式,右图这种方式没有见过。他说是计算两个句子相似程度的分数,BLEU score.但是,又提到使用这种方式来收敛的话,loss function是没有办法做微分的???
都不提loss function的形式的吗??


现在来处理前文中提到的mismatch的问题,exposure bias, 曝光偏差
有一种很直觉但被证明有效的方法,既然担心训练的时候decoder的输入全是正确的结果,而到了推理阶段,一旦模型遇到错误的输入就可能产生很离谱的结果,所以说在训练阶段就给decoder输入错误的向量
这种方法叫做scheduled sampling,轮训采样或者是定时采样

这种方法会破坏transformer计算平行性