bp神经网络模型的优缺点,bp神经网络缺点及克服
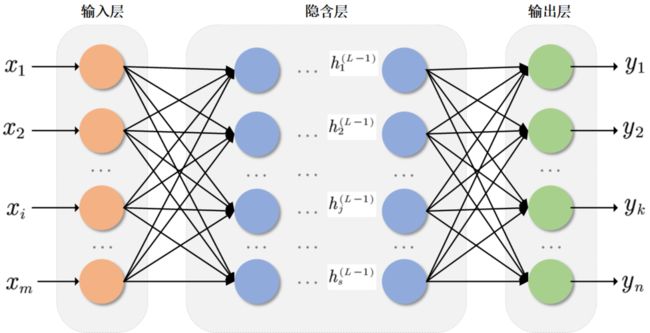
BP神经网络的核心问题是什么?其优缺点有哪些?
。
人工神经网络,是一种旨在模仿人脑结构及其功能的信息处理系统,就是使用人工神经网络方法实现模式识别.可处理一些环境信息十分复杂,背景知识不清楚,推理规则不明确的问题,神经网络方法允许样品有较大的缺损和畸变.神经网络的类型很多,建立神经网络模型时,根据研究对象的特点,可以考虑不同的神经网络模型.前馈型BP网络,即误差逆传播神经网络是最常用,最流行的神经网络.BP网络的输入和输出关系可以看成是一种映射关系,即每一组输入对应一组输出.BP算法是最著名的多层前向网络训练算法,尽管存在收敛速度慢,局部极值等缺点,但可通过各种改进措施来提高它的收敛速度,克服局部极值现象,而且具有简单,易行,计算量小,并行性强等特点,目前仍是多层前向网络的首选算法.多层前向BP网络的优点:网络实质上实现了一个从输入到输出的映射功能,而数学理论已证明它具有实现任何复杂非线性映射的功能。
这使得它特别适合于求解内部机制复杂的问题;网络能通过学习带正确答案的实例集自动提取“合理的”求解规则,即具有自学习能力;网络具有一定的推广、概括能力。
多层前向BP网络的问题:从数学角度看,BP算法为一种局部搜索的优化方法,但它要解决的问题为求解复杂非线性函数的全局极值,因此,算法很有可能陷入局部极值,使训练失败;网络的逼近、推广能力同学习样本的典型性密切相关,而从问题中选取典型样本实例组成训练集是一个很困难的问题。
难以解决应用问题的实例规模和网络规模间的矛盾。这涉及到网络容量的可能性与可行性的关系问题,即学习复杂性问题;网络结构的选择尚无一种统一而完整的理论指导,一般只能由经验选定。
为此,有人称神经网络的结构选择为一种艺术。而网络的结构直接影响网络的逼近能力及推广性质。
因此,应用中如何选择合适的网络结构是一个重要的问题;新加入的样本要影响已学习成功的网络,而且刻画每个输入样本的特征的数目也必须相同;网络的预测能力(也称泛化能力、推广能力)与训练能力(也称逼近能力、学习能力)的矛盾。
一般情况下,训练能力差时,预测能力也差,并且一定程度上,随训练能力地提高,预测能力也提高。但这种趋势有一个极限,当达到此极限时,随训练能力的提高,预测能力反而下降,即出现所谓“过拟合”现象。
此时,网络学习了过多的样本细节,而不能反映样本内含的规律由于BP算法本质上为梯度下降法,而它所要优化的目标函数又非常复杂,因此,必然会出现“锯齿形现象”,这使得BP算法低效;存在麻痹现象,由于优化的目标函数很复杂,它必然会在神经元输出接近0或1的情况下,出现一些平坦区,在这些区域内,权值误差改变很小,使训练过程几乎停顿;为了使网络执行BP算法,不能用传统的一维搜索法求每次迭代的步长,而必须把步长的更新规则预先赋予网络,这种方法将引起算法低效。
BP神经网络的应用不足
神经网络可以用作分类、聚类、预测等AI爱发猫 www.aifamao.com。神经网络需要有一定量的历史数据,通过历史数据的训练,网络可以学习到数据中隐含的知识。
在你的问题中,首先要找到某些问题的一些特征,以及对应的评价数据,用这些数据来训练神经网络。虽然BP网络得到了广泛的应用,但自身也存在一些缺陷和不足,主要包括以下几个方面的问题。
首先,由于学习速率是固定的,因此网络的收敛速度慢,需要较长的训练时间。
对于一些复杂问题,BP算法需要的训练时间可能非常长,这主要是由于学习速率太小造成的,可采用变化的学习速率或自适应的学习速率加以改进。
其次,BP算法可以使权值收敛到某个值,但并不保证其为误差平面的全局最小值,这是因为采用梯度下降法可能产生一个局部最小值。对于这个问题,可以采用附加动量法来解决。
再次,网络隐含层的层数和单元数的选择尚无理论上的指导,一般是根据经验或者通过反复实验确定。因此,网络往往存在很大的冗余性,在一定程度上也增加了网络学习的负担。最后,网络的学习和记忆具有不稳定性。
也就是说,如果增加了学习样本,训练好的网络就需要从头开始训练,对于以前的权值和阈值是没有记忆的。但是可以将预测、分类或聚类做的比较好的权值保存。
bp算法在深度神经网络上为什么行不通
BP算法作为传统训练多层网络的典型算法,实际上对仅含几层网络,该训练方法就已经很不理想,不再往下进行计算了,所以不适合深度神经网络。
BP算法存在的问题:(1)梯度越来越稀疏:从顶层越往下,误差校正信号越来越小。(2)收敛到局部最小值:尤其是从远离最优区域开始的时候(随机值初始化会导致这种情况的发生)。
(3)一般,我们只能用有标签的数据来训练:但大部分的数据是没标签的,而大脑可以从没有标签的的数据中学习。深度神经网络的特点:多层的好处是可以用较少的参数表示复杂的函数。
在监督学习中,以前的多层神经网络的问题是容易陷入局部极值点。如果训练样本足够充分覆盖未来的样本,那么学到的多层权重可以很好的用来预测新的测试样本。非监督学习中,以往没有有效的方法构造多层网络。
多层神经网络的顶层是底层特征的高级表示,比如底层是像素点,上一层的结点可能表示横线,三角;而顶层可能有一个结点表示人脸。一个成功的算法应该能让生成的顶层特征最大化的代表底层的样例。
如果对所有层同时训练,时间复杂度会太高;如果每次训练一层,偏差就会逐层传递。这会面临跟上面监督学习中相反的问题,会严重欠拟合。
RBF神经网络的缺点!
1.RBF的泛化能力在多个方面都优于BP网络,但是在解决具有相同精度要求的问题时,BP网络的结构要比RBF网络简单。
2.RBF网络的逼近精度要明显高于BP网络,它几乎能实现完全逼近,而且设计起来极其方便,网络可以自动增加神经元直到满足精度要求为止。
但是在训练样本增多时,RBF网络的隐层神经元数远远高于前者,使得RBF网络的复杂度大增加,结构过于庞大,从而运算量也有所增加。
3.RBF神经网络是一种性能优良的前馈型神经网络,RBF网络可以任意精度逼近任意的非线性函数,且具有全局逼近能力,从根本上解决了BP网络的局部最优问题,而且拓扑结构紧凑,结构参数可实现分离学习,收敛速度快。
4.他们的结构是完全不一样的。BP是通过不断的调整神经元的权值来逼近最小误差的。其方法一般是梯度下降。
RBF是一种前馈型的神经网络,也就是说他不是通过不停的调整权值来逼近最小误差的,的激励函数是一般是高斯函数和BP的S型函数不一样,高斯函数是通过对输入与函数中心点的距离来算权重的。
5.bp神经网络学习速率是固定的,因此网络的收敛速度慢,需要较长的训练时间。对于一些复杂问题,BP算法需要的训练时间可能非常长,这主要是由于学习速率太小造成的。
而rbf神经网络是种高效的前馈式网络,它具有其他前向网络所不具有的最佳逼近性能和全局最优特性,并且结构简单,训练速度快。
极端气温、降雨-洪水模型(BP神经网络)的建立
极端气温、降雨与洪水之间有一定的联系。
根据1958~2007年广西西江流域极端气温、极端降雨和梧州水文站洪水数据,以第5章相关分析所确定的显著影响梧州水文站年最大流量的测站的相应极端气候因素(表4.22)为输入,建立人工神经网络模型。
4.5.1.1BP神经网络概述(1)基于BP算法的多层前馈网络模型采用BP算法的多层前馈网络是至今为止应用最广泛的神经网络,在多层的前馈网的应用中,如图4.20所示的三层前馈网的应用最为普遍,其包括了输入层、隐层和输出层。
图4.20典型的三层BP神经网络结构在正向传播中,输入信息从输入层经隐含层逐层处理,并传向输出层。
如果输出层不能得到期望的输出结果,则转入反向传播,将误差信号沿原来的连同通路返回,通过修改各层神经元的权值,使得误差最小。BP算法流程如图4.21所示。
图4.21BP算法流程图容易看出,BP学习算法中,各层权值调整均由3个因素决定,即学习率、本层输出的误差信号以及本层输入信号y(或x)。
其中,输出层误差信号同网络的期望输出与实际输出之差有关,直接反映了输出误差,而各隐层的误差信号与前面各层的误差信号都有关,是从输出层开始逐层反传过来的。
1988年,Cybenko指出两个隐含层就可表示输入图形的任意输出函数。
如果BP网络只有两个隐层,且输入层、第一隐含层、第二隐层和输出层的单元个数分别为n,p,q,m,则该网络可表示为BP(n,p,q,m)。
(2)研究区极端气温、极端降雨影响年最大流量过程概化极端气温、极端降雨影响年最大流量的过程极其复杂,从极端降雨到年最大流量,中间要经过蒸散发、分流、下渗等环节,受到地形、地貌、下垫面、土壤地质以及人类活动等多种因素的影响。
可将一个极端气候-年最大流量间复杂的水过程概化为小尺度的水系统,该水系统的主要影响因子可通过对年最大流量影响显著的站点的极端气温和极端降雨体现出来,而其中影响不明显的站点可忽略,从而使问题得以简化。
BP神经网络是一个非线形系统,可用于逼近非线形映射关系,也可用于逼近一个极为复杂的函数关系。极端气候-年最大流量水系统是一个非常复杂的映射关系,可将之概化为一个系统。
BP神经网络与研究流域的极端气候-年最大流量水系统的结构是相似的,利用BP神经网络,对之进行模拟逼近。
(3)隐含层单元数的确定隐含层单元数q与所研究的具体问题有关,目前尚无统一的确定方法,通常根据网络训练情况采用试错法确定。
在训练中网络的收敛采用输出值Ykp与实测值tp的误差平方和进行控制变环境条件下的水资源保护与可持续利用研究作者认为,虽然现今的BP神经网络还是一个黑箱模型,其参数没有水文物理意义,在本节的研究过程中,将尝试着利用极端气候空间分析的结果来指导隐含层神经元个数的选取。
(4)传递函数的选择BP神经网络模型算法存在需要较长的训练时间、完全不能训练、易陷入局部极小值等缺点,可通过对模型附加动量项或设置自适应学习速率来改良。
本节采用MATLAB工具箱中带有自适应学习速率进行反向传播训练的traingdm( )函数来实现。
(5)模型数据的归一化处理由于BP网络的输入层物理量及数值相差甚远,为了加快网络收敛的速度,使网络在训练过程中易于收敛,对输入数据进行归一化处理,即将输入的原始数据都化为0~1之间的数。
本节将年极端最高气温的数据乘以0.01;将极端最低气温的数据乘以0.1;年最大1d、3d、7d降雨量的数据乘以0.001;梧州水文站年最大流量的数据乘以0.00001,其他输入数据也按类似的方法进行归一化处理。
(6)年最大流量的修正梧州水文站以上的流域集水面积为32.70万km2,广西境内流域集水面积为20.24万km2,广西境内流域集水面积占梧州水文站以上的流域集水面积的61.91%。
因此,选取2003~2007年梧州水文站年最大流量和红水河的天峨水文站年最大流量,分别按式4.10计算每年的贡献率(表4.25),取其平均值作为广西西江流域极端降雨对梧州水文站年最大流量的平均贡献率,最后确定平均贡献率为76.88%。
变环境条件下的水资源保护与可持续利用研究表4.252003~2007年极端降雨对梧州水文站年最大流量的贡献率建立“年极端气温、降雨与梧州年最大流量模型”时,应把平均贡献率与梧州水文站年最大流量的乘积作为模型输入的修正年最大流量,而预测的年最大流量应该为输出的年最大流量除以平均贡献率76.88%,以克服极端气温和降雨研究范围与梧州水文站集水面积不一致的问题。
4.5.1.2年极端气温、年最大1d降雨与梧州年最大流量的BP神经网络模型(1)模型的建立以1958~1997年年极端最高气温、年极端最低气温、年最大1d降雨量与梧州水文站年最大流量作为学习样本拟合、建立“年极端气温、年最大1d降雨-梧州年最大流量BP神经网络模型”。
以梧州气象站的年极端最高气温,桂林、钦州气象站的年极端最低气温,榜圩、马陇、三门、黄冕、沙街、勾滩、天河、百寿、河池、贵港、金田、平南、大化、桂林、修仁、五将雨量站的年最大1d降雨量为输入,梧州水文站年最大流量为输出,隐含层层数取2,建立(19,p,q,1)BP神经网络模型,其中神经元数目p,q经试算分别取16和3,第一隐层、第二隐层的神经元采用tansig传递函数,输出层的神经元采用线性传递函数,训练函数选用traingdm,学习率取0.1,动量项取0.9,目标取0.0001,最大训练次数取200000。
BP网络模型参数见表4.26,结构如图4.22所示。
图4.22年极端气温、年最大1d降雨-梧州年最大流量BP模型结构图表4.26BP网络模型参数一览表从结构上分析,梧州水文站年最大流量产生过程中,年最高气温、年最低气温和各支流相应的流量都有其阈值,而极端气温和极端降雨是其输入,年最大流量是其输出,这类似于人工神经元模型中的阈值、激活值、输出等器件。
输入年最大1d降雨时选用的雨量站分布在14条支流上(表4.27),极端降雨发生后,流经14条支流汇入梧州,在这一过程中极端气温的变化影响极端降雨的蒸散发,选用的雨量站分布在年最大1d降雨四个自然分区的Ⅱ、Ⅲ、Ⅳ3个区。
该过程可与BP神经网络结构进行类比(表4.28),其中,14条支流相当于第一隐含层中的14个神经元,年最高气温和年最低气温相当于第一隐含层中的2个神经元,年最大1d降雨所在的3个分区相当于第二隐含层的3个神经元,年最高气温、年最低气温的影响值和各支流流量的奉献值相当于隐含层中人工神经元的阈值,从整体上来说,BP神经网络的结构已经灰箱化。
表4.27选用雨量站所在支流一览表表4.28BP神经网络构件物理意义一览表(2)训练效果分析训练样本为40个,经过113617次训练,达到精度要求。
在命令窗口执行运行命令,网络开始学习和训练,其训练过程如图4.23所示,训练结果见表4.29和图4.24。
表4.29年最大流量训练结果图4.23神经网络训练过程图图4.24年最大流量神经网络模型训练结果从图4.26可知,训练后的BP网络能较好地逼近给定的目标函数。
从训练样本检验结果(表4.5)可得:1958~1997年40年中年最大流量模拟值与实测值的相对误差小于10%和20%的分别为39年,40年,合格率为100%。
说明“年极端气温、年最大1d降雨-梧州年最大流量预测模型”的实际输出与实测结果误差很小,该模型的泛化能力较好,模拟结果较可靠。
(3)模型预测检验把1998~2007年梧州气象站的年极端最高气温,桂林、钦州气象站的年极端最低气温,榜圩、马陇、三门、黄冕、沙街、勾滩、天河、百寿、河池、贵港、金田、平南、大化、桂林、修仁、五将雨量站的年最大1d降雨量输入到“年极端气温、年最大1d降雨梧州年最大流量BP神经网络模型”。
程序运行后网络输出预测值与已知的实际值进行比较,其预测检验结果见图4.25,表4.30。
图4.25年最大流量神经网络模型预测检验结果表4.30神经网络模型预测结果与实际结果比较从预测检验结果可知:1998~2007年10年中年最大流量模拟值与实测值的相对误差小于20%的为9年,合格率为90%,效果较好。
4.5.1.3年极端气温、年最大7d降雨与梧州年最大流量的BP神经网络模型(1)模型的建立以1958~1997年年极端最高气温、年极端最低气温、年最大7d降雨量和梧州水文站年最大流量作为学习样本来拟合、建立“年极端气温、年最大7d降雨-梧州年最大流量BP神经网络模型”。
以梧州气象站的年极端最高气温,桂林、钦州气象站的年极端最低气温,凤山、都安、马陇、沙街、大湟江口、大安、大化、阳朔、五将雨量站的年最大7d降雨量为输入,梧州水文站年最大流量为输出,隐含层层数取2,建立(12,p,q,1)BP神经网络模型,其中,神经元数目p,q经试算分别取10和4,第一隐层、第二隐层的神经元采用tansig传递函数,输出层的神经元采用线性传递函数,训练函数选用traingdm,学习率取0.1,动量项取0.9,目标取0.0001,最大训练次数取200000。
BP网络模型参数见表4.31,结构如图4.26所示。
表4.31BP网络模型参数一览表图4.26年极端气温、年最大7d降雨-梧州年最大流量BP模型结构图本节输入年最大7d降雨时选用的雨量站分布在8条支流上(表4.32),在发生极端降雨后,流经8条支流汇入梧州,在这一过程中极端气温的变化影响极端降雨的蒸散发,且选用的雨量站分布在年最大7d降雨四个自然分区的Ⅰ、Ⅱ、Ⅲ、Ⅳ4个区中。
该过程可与BP神经网络结构进行类比(表4.33),其中,8条支流相当于第一隐含层中的8个神经元,年最高气温和年最低气温相当于第一隐含层中的2个神经元,年最大7d降雨所在的4个分区相当于第二隐含层的4个神经元,整体上来说,BP神经网络的结构已经灰箱化。
表4.32选用雨量站所在支流一览表表4.33BP神经网络构件物理意义一览表(2)训练效果分析训练样本为40个,经过160876次的训练,达到精度要求,在命令窗口执行运行命令,网络开始学习和训练,其训练过程如图4.27所示,训练结果见表4.34,图4.28。
图4.27神经网络训练过程图表4.34年最大流量训练结果图4.28年最大流量神经网络模型训练结果从图4.28可知,训练后的BP网络能较好地逼近给定的目标函数。
由训练样本检验结果(表4.34)可得:1958~1997年40年中年最大流量模拟值与实测值的相对误差小于10%和20%的,分别为38年、40年,合格率为100%。
说明“年极端气温、年最大7d降雨-梧州年最大流量BP神经网络模型”的泛化能力较好,模拟的结果较可靠。
(3)模型预测检验把1998~2007年梧州气象站的年极端最高气温,桂林、钦州气象站的年极端最低气温,凤山、都安、马陇、沙街、大湟江口、大安、大化、阳朔、五将雨量站的年最大7d降雨量输入到“年极端气温、年最大7d降雨-梧州年最大流量BP神经网络模型”。
程序运行后网络输出预测值与已知的实际值进行比较,其预测结果见图4.29和表4.35。
图4.29年最大流量神经网络模型预测检验结果表4.35神经网络模型预测结果与实际结果比较由预测检验结果可知:1998~2007年10年中年最大流量模拟值与实测值的相对误差小于20%的为7年,合格率为70%,效果较好。
4.5.1.4梧州年最大流量-年最高水位的BP神经网络模型(1)模型的建立以1941~1997年梧州水文站的年最大流量与年最高水位作为学习样本来拟合、建立梧州水文站的“年最大流量-年最高水位BP神经网络模型”。
以年最大流量为输入,年最高水位为输出,隐含层层数取1,建立(1,q,1)BP神经网络模型,其中,神经元数目q经试算取7,隐含层、输出层的神经元采用线性传递函数,训练函数选用traingdm,学习率取0.1,动量项取0.9,目标取0.00001,最大训练次数取200000。
BP网络模型参数见表4.36,结构如图4.30所示。
表4.36BP网络模型参数一览表图4.30梧州年最大流量—年最高水位BP模型结构图广西西江流域主要河流有南盘江、红水河、黔浔江、郁江、柳江、桂江、贺江。
7条主要河流相当于隐含层中的7个神经元(表4.37),整体上来说,BP神经网络的结构已经灰箱化。
表4.37BP神经网络构件物理意义一览表(2)训练效果分析训练样本为57个,经过3327次训练,误差下降梯度已达到最小值,但误差为3.00605×10-5,未达到精度要求。
在命令窗口执行运行命令,网络开始学习和训练,其训练过程如图4.31所示,训练结果见图4.32和表4.38。
表4.38年最高水位训练结果从图4.32和表4.19可看出,训练后的BP网络能较好地逼近给定的目标函数。
对于训练样本,从检验结果可知:1941~1997年57年中年最高水位模拟值与实测值的相对误差小于10%和20%的分别为56a,57a,合格率为100%。
说明“年最大流量-年最高水位BP神经网络模型”的实际输出与实测结果误差很小,该模型的泛化能力较好,模拟的结果比较可靠。
图4.31神经网络训练过程图图4.32年最高水位神经网络模型训练结果(3)模型预测检验把1998~2007年梧州水文站年最大流量输入到“年最大流量-年最高水位BP神经网络模型”。
程序运行后网络输出预测值与已知的实际值进行比较,其预测结果见图4.33,表4.39。
表4.39神经网络模型预测结果与实际结果比较从预测检验结果可知:1998~2007年10年中,年最高水位模拟值与实测值的相对误差小于20%的为10年,合格率为100%,效果较好。
图4.33年最高水位量神经网络模型预测检验结果。
蚁群算法优化BP神经网络 遇到的问题。
bp神经网络选择激活sigmoid函数,还有tansig函数的优缺点?求告知?
(1)对于深度神经网络,中间的隐层的输出必须有一个激活函数。否则多个隐层的作用和没有隐层相同。这个激活函数不一定是sigmoid,常见的有sigmoid、tanh、relu等。
(2)对于二分类问题,输出层是sigmoid函数。这是因为sigmoid函数可以把实数域光滑的映射到[0,1]空间。函数值恰好可以解释为属于正类的概率(概率的取值范围是0~1)。
另外,sigmoid函数单调递增,连续可导,导数形式非常简单,是一个比较合适的函数(3)对于多分类问题,输出层就必须是softmax函数了。softmax函数是sigmoid函数的推广。
bp神经网络与量子行为粒子群算法有什么不一样
这四个都属于人工智能算法的范畴。其中BP算法、BP神经网络和神经网络属于神经网络这个大类。遗传算法为进化算法这个大类。
神经网络模拟人类大脑神经计算过程,可以实现高度非线性的预测和计算,主要用于非线性拟合,识别,特点是需要“训练”,给一些输入,告诉他正确的输出。若干次后,再给新的输入,神经网络就能正确的预测对于的输出。
神经网络广泛的运用在模式识别,故障诊断中。BP算法和BP神经网络是神经网络的改进版,修正了一些神经网络的缺点。遗传算法属于进化算法,模拟大自然生物进化的过程:优胜略汰。
个体不断进化,只有高质量的个体(目标函数最小(大))才能进入下一代的繁殖。如此往复,最终找到全局最优值。遗传算法能够很好的解决常规优化算法无法解决的高度非线性优化问题,广泛应用在各行各业中。
差分进化,蚁群算法,粒子群算法等都属于进化算法,只是模拟的生物群体对象不一样而已。
BP网的功能及导高预测适用性
采用BP算法的前馈神经网是神经网络在各个领域中应用最广泛的一种,已经成功解决了大量实际问题。BP网的广泛应用,归因于其主要能力:具有非线性映射能力、泛化能力与容错能力。
多层前馈网能学习和存储大量输入-输出模式映射关系,即使不了解描述这种映射关系的数学方程,只要能提供足够多的样本模式对以供BP网络进行学习训练,它便可以完成由n维输入空间到m维输出空间的非线性映射,即非线性映射能力。
在工程上及许多技术领域中,对某一输入输出系统常常积累了大量相关的输入输出数据,但仍未掌握其内部蕴涵的规律,无法用数学方法来描述该规律。
对难以得到解析解、缺乏专家经验,但能够表示和转化为模式识别或非线性映射的这类问题,多层前馈网络具有无可比拟的优势。
通过训练的多层前馈网络,将所提取的样本对中的非线性映射关系存储在权值矩阵中,当向网络输入训练时未曾见的非样本数据时,网络也能完成由输入空间向输出空间的正确映射,即泛化能力,是衡量多层前馈网性能优劣的一个重要方面。
由于权矩阵的调整是从大量的样本中提取统计特性的过程,反映正确规律的知识来自全体样本,个别样本中的误差不能左右对矩阵的调整。所以多层前馈网允许输入样本中带有较大的误差甚至个别错误,即容错能力。
标准算法在应用中具有训练次数多,学习效率低,收敛速度慢,隐节点的选取缺乏理论指导,训练时学习新样本有遗忘旧样本的趋势,容易形成局部极小而得到局部全优等缺点,通过要权值调整公式中增加动量项α、自适应调节学习率η、在转移函数中引入陡度因子λ等方法,有效改进了BP算法,进一步提高其适用性。
因此,采用BP人工神经网络建立导水裂隙带高度与其影响因子之间的非线性映射关系,并发挥BP网的泛化能力,输入影响因子,对导水裂隙带高度进行预测,具有无可比拟的优越性。
RBF神经网络和BP神经网络有什么区别
1.RBF的泛化能力在多个方面都优于BP网络,但是在解决具有相同精度要求的问题时,BP网络的结构要比RBF网络简单。
2.RBF网络的逼近精度要明显高于BP网络,它几乎能实现完全逼近,而且设计起来极其方便,网络可以自动增加神经元直到满足精度要求为止。
但是在训练样本增多时,RBF网络的隐层神经元数远远高于前者,使得RBF网络的复杂度大增加,结构过于庞大,从而运算量也有所增加。
3.RBF神经网络是一种性能优良的前馈型神经网络,RBF网络可以任意精度逼近任意的非线性函数,且具有全局逼近能力,从根本上解决了BP网络的局部最优问题,而且拓扑结构紧凑,结构参数可实现分离学习,收敛速度快。
4.他们的结构是完全不一样的。BP是通过不断的调整神经元的权值来逼近最小误差的。其方法一般是梯度下降。
RBF是一种前馈型的神经网络,也就是说他不是通过不停的调整权值来逼近最小误差的,的激励函数是一般是高斯函数和BP的S型函数不一样,高斯函数是通过对输入与函数中心点的距离来算权重的。
5.bp神经网络学习速率是固定的,因此网络的收敛速度慢,需要较长的训练时间。对于一些复杂问题,BP算法需要的训练时间可能非常长,这主要是由于学习速率太小造成的。
而rbf神经网络是种高效的前馈式网络,它具有其他前向网络所不具有的最佳逼近性能和全局最优特性,并且结构简单,训练速度快。