CVPR2018/语义分割/UDA:Learning from Synthetic Data: Addressing Domain Shift for Semantic Segmentation
Learning from Synthetic Data: Addressing Domain Shift for Semantic Segmentation 从合成数据中学习:面向语义分割的域转移
- 0.摘要
- 1.概述
- 2.相关工作
- 3.方法
-
- 3.1.网络块描述
- 3.2.处理源数据和目标数据
- 3.3.迭代优化
- 3.4.D的设计
- 4.实验和结果
-
- 4.1.SYNTHIA -> CITYSCAPES
- 4.2.GTA5 -> CITYSCAPES
- 5.讨论
-
- 5.1.图像大小的影响
- 5.2.与直接的风格转移的比较
- 5.3.特定组件的消融
- 5.4.跨域检索
- 5.5.对不可见域的泛化
- 6.结论和未来工作
- 7.附录:架构细节和超参数
-
- 7.1.架构细节和超参数
- 7.2.损失函数的具体实现
-
- 7.2.1.Loss For Discriminator Updating
- 7.2.2.Loss For Generator Updating
- 7.2.3.Loss For F,C Network Updating
- 参考文献
论文地址
代码地址
0.摘要
视觉域适应是计算机视觉中的一个重要问题。以前的方法表明,即使是深度神经网络也无法跨域转移学习信息表示。在获取手工标记数据极其困难和乏味的任务中,这个问题更加严重。在这项工作中,我们专注于适应通过分割网络在合成和真实领域学习的表示。与以前使用简单的对抗目标或超像素信息来辅助处理的方法相反,我们提出了一种基于生成对抗网络(GANs)的方法,使嵌入更接近学习到的特征空间。为了展示我们方法的普遍性和可扩展性,我们展示了我们可以在两个具有挑战性的场景中实现最先进的结果,即从合成到真实领域的适应。额外的探索性实验表明,我们的方法:(1)推广到不可见域和(2)结果改善对齐源和目标分布。
1.概述
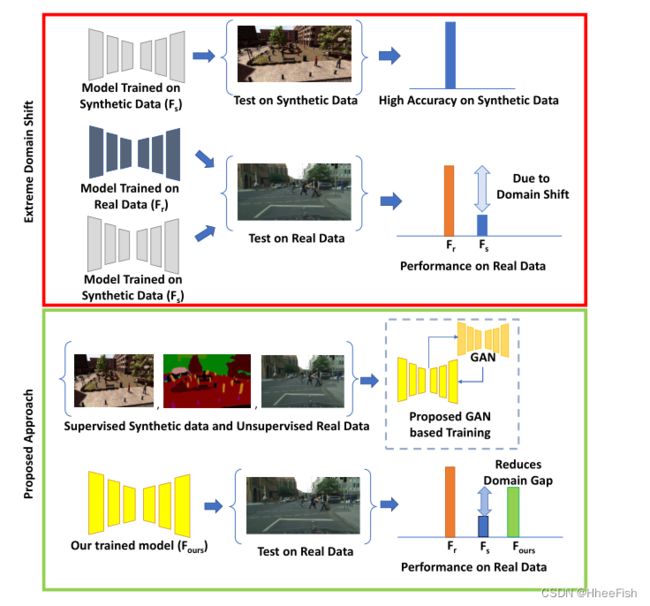
图1:域转移的特征和所提议的方法在减少域转移方面的效果
深度卷积神经网络(DCNNs)彻底改变了计算机视觉领域,在图像分类[12]、语义分割[20]、视觉问题回答[23]等多种任务中取得了最佳性能。这种强劲的表现可以归因于大量标记训练数据的可用性。虽然对图像分类等特定任务来说,对数据进行注释相对容易一些,但对其他任务来说,注释数据可能非常费力和耗时。语义分割就是这样一项需要大量人力的任务,因为它涉及到获取密集的像素级标签。从CITYSCAPES数据集获取单个图像的像素级标签的注释时间大约为1小时。,突出难度等级([4],[26])。另一个挑战在于收集数据:虽然自然图像更容易获得,但在某些领域,比如医学图像,收集数据和找专家精确地标记它们也可能非常昂贵
解决上述问题的一种有希望的方法是利用综合生成的数据进行训练。然而,基于合成数据训练的模型在真实数据集上表现不佳,因为数据集之间存在领域差距。领域适应包括处理领域转移问题的技术类。因此,研究领域自适应语义分割算法是本文研究的重点。具体来说,我们关注的是难以解决的问题,即目标域没有可用的标签。这类技术通常被称为无监督域适应
传统的域适应方法涉及最小化源和目标分布之间的距离的一些度量。两种常用的测量方法是最大均值差异(MMD)([9],[21],[22]),以及使用DCNNs学习距离度量方法([7],[30])。这两种方法在分类问题上都取得了很好的成功;然而,正如[32]中指出的那样,它们的性能改进并不能很好地转化为语义分割问题。这激发了开发新的领域适应技术的需求,以适应语义分割。
我们在这项工作中提出的方法属于使用对抗性框架对齐域的范畴。在最近解决这个问题的技术中,野生[14]中的FCN是唯一使用对抗性框架的方法。然而,与[14]中鉴别器直接作用于特征空间不同,我们使用生成器将特征投影到图像空间,而鉴别器作用于这个投影图像空间。然后从鉴别器中得到对抗性损失。我们观察到,与直接在特征空间中应用这种损失相比,在这个投影图像空间中应用对抗性损失取得了显著的性能改进(参见表4)。
这项工作的主要贡献在于我们提出了一种利用生成模型来对齐特征空间中的源和目标分布的技术。
- 我们首先将DCNN获得的中间特征表示投影到图像空间,通过使用L1和对抗性损失的组合训练重建模块。
- 然后,我们通过强制网络学习特征来施加域对齐约束,使源特征在传递给重构模块时产生类似目标的图像,反之亦然。这是通过一系列对抗性的损失来实现的。随着训练的进行,生成的质量逐渐提高,同时特征的域不变性增强。
2.相关工作
Shelhamer等[20]的完全卷积网络(FCN)标志着如何充分利用CNNs的表征能力进行语义像素标记任务的范式转变。虽然PASCAL VOC[6]和MS-COCO[18]等流行基准的性能一直在稳步提高,但它们并没有解决语义分割背景下领域转移的挑战。
领域自适应在计算机视觉中得到了广泛的研究,主要用于分类任务。早期的一些方法涉及到使用特性加权技术[5],或者使用流形构造中间表示([11],[10])。由于深度神经网络的出现,重点已经转移到学习领域不变的特征,以端到端方式。深度域适应的标准框架包括在解决任务的同时最小化域差异的度量。一些方法使用最大均值差异及其内核变体([21],[22])来执行此任务,而其他方法使用对抗性方法([7],[2],[28])。
我们关注对抗性方法,因为它们与我们的工作更相关。Revgrad[7]在特征空间应用对抗性损失进行域自适应,PixelDA[2]和CoGAN[19]在像素空间进行操作。虽然这些技术对分类任务进行了调整,但很少有方法针对语义分割。据我们所知,[14]和[32]是解决这个问题的唯一两种方法。[14]中的FCN提出了两种对齐策略——(1)全局对齐,这是[7]对分割问题提出的域对抗训练的扩展,(2)局部对齐,通过将其制定为一个多实例学习问题来对齐类特定统计数据。课程域适应[32]则提出了课程式学习方法,首先学习图像上的全局标签分布和地标超像素上的局部分布。然后训练分割网络,使目标标签分布遵循这些推断的标签属性。
解决域适应问题的一个可能方向是采用样式转移或跨域映射网络将源域图像风格化为目标,并在这个风格化空间中训练分割模型。因此,我们讨论了一些最近的工作有关的风格转移和不配对的图像翻译任务。Gatys等人[8]的热门工作引入了一种涉及反向传播的优化方案来执行内容保持风格转移,而Johnson等人[15]提出了一种前馈方法。CycleGAN[33]通过使用对抗损失和循环一致性损失来执行图像到图像的非配对转换。在我们的实验中,我们将我们的方法与一些基于样式转移的数据增强方案进行了比较。
3.方法
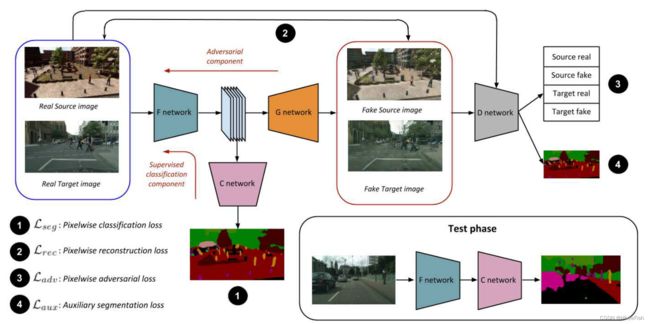
图3:在训练期间,F和C网络与对抗框架(G-D对)联合训练。F使用监督损失和对抗性组件的组合进行更新。在右下角,我们显示了测试时间的使用情况。仅使用F和C网络块。与基本模型相比,评估期间没有额外的开销。
在本节中,我们将对所提出的方法进行形式化的处理,并详细解释我们的迭代优化过程。设X∈RM×N×C为任意输入图像(有C个通道),Y∈RM×N为对应的标签图。给定一个输入X,我们表示一个CNN的输出为Yˆ∈RM×N×Nc,其中Nc为类的数量。Yˆ (i, j)∈RNc是一个向量,表示CNN输出的像素位置(i, j)处的类概率分布。源(s)或目标(t)域由上标表示,如Xs或Xt。
首先,我们提供通道中不同网络块的输入-输出描述。接下来,我们分别描述源数据和目标数据的处理,然后描述不同的损失函数和相应的更新步骤。最后,我们展示鉴别器(D)架构中涉及的设计选择。
3.1.网络块描述
我们的训练程序涉及到以下网络块的交替优化:
(a)基础网络的体系结构是类似于pre-trained VGG-16等模型,分为两个部分:将输入映射到嵌入空间的F和pixel-wise分类器C, C是一个标签的输出地图,上采样至与输入 F的相同大小。
(b)生成器网络(G)以学习到的嵌入为输入,重建RGB图像。
©对于给定的输入,鉴别器网络(D)执行两个不同的任务:(a)它以域一致的方式将输入区分为真实或虚假(b)它执行类似于c网络的像素标注任务。注意(b)仅对源数据有效,因为目标数据在训练期间没有任何标签。
3.2.处理源数据和目标数据
给定一个源图像和标签对{Xs, Y s}作为输入,我们首先使用F网络提取特征表示。分类器C以嵌入F(Xs)为输入,生成一个图像大小的标签映射Yˆs,生成器G根据嵌入情况重构源输入Xs。随着最近在图像生成方面的成功工作,我们没有显式地将生成器输入与随机噪声向量连接起来,而是在整个G网络中使用dropout层。如图3所示,D执行两个任务:(1)区分真实的源输入和生成的源图像为源-真实/源-伪。(2)给出生成器产生的源图像的像素级标签映射。
给定目标输入Xt,生成网络G以F的目标嵌入为输入,重建目标图像。与上例类似,训练D区分真实目标数据(target-real)和G生成的目标图像(target-fake)。然而,与前一种情况不同的是,D只执行单一任务,即它将目标输入分类为target-real/target-fake。由于目标数据在训练时没有任何标签,所以当系统有目标输入时,分类器网络C是不活跃的。
3.3.迭代优化

表1:训练期间用于更新我们网络的域内和跨域对抗性损失。G和D网络仅使用域内损耗进行更新,而F网络仅使用跨域损耗进行更新。所有这些对抗性损失都源于D网络。Ladv,X表示损失函数L的梯度仅用于更新X,而其他网络保持不变
图3显示了我们方法中使用的各种损失。我们从描述这些损失开始,然后描述我们的迭代优化方法。
用于训练我们模型的不同对抗性损失如表1所示。除了这些对抗损失,我们使用以下损失:
- Lseg和Laux像素级交叉熵损失用于标准分割网络,如FCN
- 输入图像和重建图像之间的Lrec - L1损失。

图2:在我们的迭代更新过程中,前进过程中数据流实心箭头的方向和后退过程中梯度流虚线箭头的方向。实心块表示该块在更新步骤期间冻结,而虚线块表示该块正在更新。红色表示源信息,蓝色表示目标信息。
图2列出了跨不同网络块的信息流方向。在每次迭代中,向系统提供一个随机抽样的三元组(Xs, Ys, Xt)。然后,按照以下顺序迭代更新网络块:
- D-update:对于源输入,使用域内对抗性损失Lsadv,D和辅助分类损失Lsaux的组合来更新D。对于目标输入,只使用对抗性损失Ltadv,D对D进行更新。总损失LD由LD = Lsadv,D + Ltadv,D + Lsaux给出。
- G-update:在这一步中,使用对抗性损失Lsadv,G + Ltadv意图欺骗D的G,以及重建损失Lrec的组合更新生成器。对抗性损失鼓励生成器产生现实的输出。像素级L1损耗是保证生成器输出和相应输入图像之间图像保真度的关键。生成器总损耗为:LG = Lsadv,G + Ltadv,G + Lsrec + Ltrec。
- F-update:对F网络的更新是我们框架的关键方面,在这个框架中,域转移的概念被捕获。F的参数使用几个损失项的组合进行更新:LF=Lseg+αLsaux+β(Lsadv,F+Ltadv,F)。如表1所示,用于更新F的对抗性损失术语说明了域适配。更具体地说,这里描述的迭代更新可以被视为F和G-D网络之间的最小-最大博弈。在前面讨论的D更新步骤中,D的对抗损失分支学习以域一致的方式将输入图像分类为真图像或假图像。为了更新F,我们使用D的梯度,这会导致域分类的反转,即对于源嵌入,我们使用D的梯度,将这些嵌入分类为目标域(Lsadv,F),对于目标嵌入,我们使用D的梯度,将这些嵌入分类为源域(Ltadv,F)。请注意,这类似于G-D对之间的最小-最大博弈,但在这种情况下,竞争是将生成的图像分类为源域/目标域,而不是真域/假域。
3.4.D的设计
- 在从DCGAN[25]实现派生的传统GANs中,鉴别器的输出是单个标量,表示输入是假的或来自底层数据分布的概率。最近关于图像生成的工作利用了Patch鉴别器的思想,其中输出是一个二维特征图,其中每个像素都有一个真实/虚假的概率。这导致在他们的生成器重建的视觉质量的显著改善。我们通过使用Patch鉴别器的变体将这一思想扩展到我们的设置中,其中输出映射中的每个像素表示源和目标域的真实/虚假概率,因此每个像素有四个类:src-real、src-fake、tgt-real、tgt-fake。
- 一般来说,GANs很难在涉及更大规模真实图像的任务上接受训练。使用GAN框架训练稳定生成模型的一种很有希望的方法是Odena等人的辅助分类器GAN(ACGAN)方法。他们表明,通过在训练期间调节G并向D添加辅助分类损失,他们可以实现更稳定的GAN训练,甚至生成大规模图像。受他们对图像分类结果的启发,我们将他们的想法扩展到分割问题,通过对D网络使用辅助的像素级标记损失。
事实证明,这两个组件对我们的性能都至关重要。第5.3节中进行的消融研究显示了上述设计选择对最终性能的影响。有关这些网络块的体系结构的详细信息,请参阅补充材料。
4.实验和结果
在本节中,我们通过在基准数据集上进行实验,对我们的方法进行定量评估。我们考虑了两个具有挑战性的用于语义分割的合成数据集:SYNTHIA和GTA5。SYNTHIA[27]是一个大型数据集,它包含了从虚拟城市渲染而来的真实感帧,并带有精确的像素级语义注释。在之前的作品([14],[32])之后,我们使用了SYNTHIA-RAND-CITYSCAPES子集,其中包含了9400张与城市景观兼容的注释图像。GTA-5是另一个包含24966幅标记图像的大型数据集。数据集由Richter et al.[26]整理,通过从电脑游戏GTA5中提取帧生成
我们使用CITYSCAPES[4]作为我们的真实数据集。这个数据集包含了一辆行驶中的汽车在德国及其邻国的50个城市拍摄的城市街道图像。该数据集包含5000张带注释的图像,分为三组——2975张在train集,500张在val集,1595张在test集。在我们所有的实验中,为了训练我们的模型,我们使用标记过的SYNTHIA或GTA-5数据集作为我们的源域,而未标记过的CITYSCAPES列车集作为我们的目标域。我们将所提出的方法与当代仅有的两种解决这一问题的方法进行了比较:野生[14]中的FCN和课程域适应[32]。按照这些方法,我们将CITYSCAPES val中的500张图像指定为我们的测试集。
架构
在我们所有的实验中,我们都使用FCN-8s作为我们的基本网络。该网络的权值用Imagenet[17]训练的vgg - 16[29]模型的权值进行初始化。
应用细节
在我们所有的实验中,图像都被调整为1024 × 512。我们使用批量大小为1的Adam求解器[16]来训练我们的模型为100,000次迭代。F和C网络的学习率为10−5,G和D网络的学习率为2 × 10−4。在CITYSCAPES数据集(其图像和地面真实注释大小为2048 × 1024)上进行评估时,我们首先在1024 × 512大小的图像上产生我们的预测,然后对我们的预测进行2倍采样,以获得最终的标签地图,用于评估。我们的训练代码和其他结果是公开的。
4.1.SYNTHIA -> CITYSCAPES
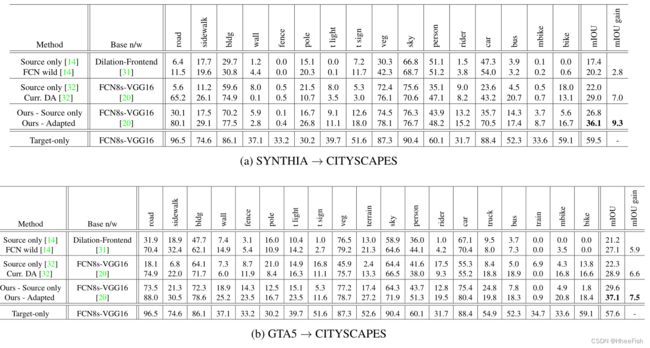
表2:从(a)SYTNHIA到CITYSCAPES和(b)GTA-5到CITYSCAPES的语义分割结果。我们比较了使用两种不同基础网络的两种方法。为了公平地了解我们的性能增益,我们将其与使用与我们相同的基础网络的课程DA方法进行比较。由于在这两种情况下,目标域都是CITYSCAPES,因此这两种设置的纯目标培训过程是相同的。然而,(a)中的结果是在16个常见类别中报告的,而(b)中的结果是在所有19个类别中报告的。
在这个实验中,我们使用SYNTHIA数据集作为源域,CITYSCAPES作为目标域。我们从SYNTHIA数据集的9400张带标签的图像中随机选取100张图像,并将其用于验证目的,其余的图像用于训练。我们使用CITYSCAPES列车集对应的未标记图像来训练我们的模型。为了保证实验结果的公正性,我们遵循了之前作品([14],[32])中指定的准确的评估协议:选择SYNTHIA和CITYSCAPES之间的16个常见类作为我们的标签。与其他类对应的预测被视为属于void类,在训练期间不反向传播。16个等级分别是:天空、建筑、道路、人行道、围栏、植被、电线杆、汽车、交通标志、人、自行车、摩托车、交通灯、公共汽车、墙壁、骑手。
表2a报告了我们的方法与[14]和[32]相比的性能。对应于不适应情况即仅使用源域数据进行训练的纯源模型平均IOU为26.8。纯目标值表示使用CITYSCAPES训练集(监督训练)训练的模型获得的性能,它们是域适应性能的粗略上界。包含这些值是为了更好地反映所提出的方法所获得的性能收益。我们观察到,我们的方法获得了平均36.1的IOU,从而将基线提高了9.3分,因此与其他报告的方法相比,性能提高更高。
4.2.GTA5 -> CITYSCAPES
在这个实验中,我们从GTA-5数据集调整到CITYSAPES数据集。我们从GTA-5数据集的24966张带标签的图像中随机选取1000张图像,并将其用于验证目的,其余的图像用于训练。我们使用CITYSCAPES列车集对应的未标记图像来训练我们的模型。为了确保实验结果的公正性,我们遵循了之前作品([14],[32])所指定的准确评估协议:我们使用GTA-5和CITYSCAPES之间的19个常见类作为我们的标签。实验结果见表2b。与之前的实验类似,由于网络架构和实验设置的差异,我们的基线性能(29.6)高于[14]报告的性能。此外,该方法提高了7.5分,mIOU为37.1。这种性能增益比其他比较方法获得的性能增益要高。
关于不同基线的注意事项:由于实验设置不同,我们报告的基线数据与[32]和[14]中报告的基线数据不匹配([32]中也报告了这种不匹配)。然而,我们想指出的是,与我们的两个适应实验中的其他两种方法相比,我们在更强的基线上有所改善。此外,[32]使用来自PASCAL-CONTEXT[24]数据集的附加数据来获得超像素分割。相比之下,我们的方法是一个单阶段的端到端学习框架,不使用任何额外的数据,但获得了更好的性能改进。
5.讨论
5.1.图像大小的影响

表3:SYNTHIA→CITYSCAPES设置上不同图像大小的平均借据值和计算时间。粗体显示的数字表示与仅source基线相比性能的绝对改进。报告的培训和评估时间是针对所提议的方法的,并且是训练和评估运行的平均时间。
本文中考虑的数据集由大分辨率的图像组成,至少比最常用的cnn分割基准(即PASCAL VOC (500×300)和MSCOCO (640×480))的两倍大。在这种情况下,从定量和计算的角度理解图像大小对算法性能的影响是有指导意义的。表3展示了我们的方法在三种不同大小的图像上应用的结果,以及训练和评估时间。应该注意的是,Curriculum DA方法[32]使用了640×320的分辨率。通过与表2a中的主要结果进行比较,我们可以看到我们的方法在类似的基线上提供了更高的相对性能改进。
5.2.与直接的风格转移的比较
在最近的一段时间里,风格转换的生成方法取得了很大的成功。进行域适应的一种简单方法是使用数据增强方法:将图像从源域转移到目标域,并使用提供的源地面真实值在源数据和目标数据的组合上训练分类器。为了将该方法与直接数据增强过程进行比较,我们使用了最先进的生成方法(CycleGAN[33])将图像从源域转移到目标域。从我们的实验来看,仅将生成式方法作为一种数据增强方法,只比仅基于源的基线提供了相对较小的改进,而且与所提出的方法相比明显不是最优的。然而,正如Hoffman等人[13]最近的一种方法所示,这种跨域转移可以通过仔细的训练程序来完成。该方法得到的结果与[13]方法相当或更好。结合这两种方法产生一个更强的领域适应技术的分割正在进展中。
5.3.特定组件的消融

表4:消融研究显示了我们的方法在SYNTHIA→CITYSCAPES设置中每个组件对最终性能的影响
在这个实验中,我们展示了我们的损失函数中的每个部分是如何影响最终性能的。我们考虑以下情况:(a)我们的(完整):我们方法的完整实现(b)我们的无辅助像素级损失:这里,D网络的输出是一个单独的分支,将输入分类为真实/虚假。这对应于F -update步骤中的α = 0。注意,将α和β都设为零对应于我们实验中只设置源。仅设置β = 0并不比仅源基线提高,因为没有跨域对抗损失。©我们的w/o Patch鉴别器:我们不使用D网络作为Patch鉴别器,而是使用常规的gan样鉴别器,其中输出是一个4-D的概率向量,输入图像属于srcreal、src-fake、tgt-real和tgt-fake这四个类中的一个。(d)基于特征空间的d:在这种设置下,我们去除G-D网络,并直接在嵌入上应用对抗性损失。这类似于fcn-wild方法[14]中的全局对齐设置。
5.4.跨域检索

图4:用所提出的方法实现的领域适应的说明。该图比较了第5.4节中描述的跨域检索任务在纯源模型和采用所提方法的模型之间的平均采样检索数。目标→源意味着使用的查询集属于目标域(QT),从集合X查询的项属于源域,对于源→目标则相反。通常,y轴上绘制的值对应于从集合X中检索到的属于与查询集相反域的样本数量。
领域适应的一个关键方面是找到领域差异的良好度量,从而很好地说明了领域偏移。虽然在图像分类中存在a -距离[1]和M - M - D[9]等经典度量,但这些度量对于像素级问题(如语义分割)的扩展是不容小视的。在本节中,我们设计了一个简单的实验,以说明所提出的方法如何使源和目标分布在学习的嵌入空间更接近。我们从F网络的最后一层开始,我们称之为嵌入层,它的输出是一个空间特征图。我们对每个输入图像执行平均池化,将空间映射减少到4096维的特征描述符。
我们通过从源和目标训练集中选择N = Nsrc +Ntgt的图像池来开始跨域检索任务。让X表示这组图片和FX表示组的特征描述符计算X,我们选择两个查询集,组成的一个源图像和目标图像的其他组成(T),每个分离X让相应的特性集表示QS和QT。我们从组合特征集FX中检索查询集中每个条目的k-NN列表。对于QS中的每个查询点,我们统计在对应的k-NN列表中检索到的目标样本的数量。|Ak|表示在整个源查询集QS上检索到的目标样本的平均数量。对于QT中的每个查询点,我们统计在对应的k-NN列表中检索到的源样本的数量。|Bk|表示在整个目标查询集QT上检索的源样本的平均数量。我们使用余弦相似度作为度量来计算k-NN列表。如果对一个源查询点检索到更多的目标样本(反之亦然),这表明源和目标分布在特征空间中对齐良好
本实验中查询集和特征集FX的大小如下:Nsrc = Ntgt = 1000, |QS| = 1000, |QT | = 1000。为各个跨域任务计算整个查询集的平均精度(mAP)。图4显示了k值范围内的数量| Ak |(图4b)和| Bk |(图4a)的曲线图。它可以观察到从情节的任务对于任何给定的秩k,跨域样本的数量适应模型比sourceonly检索模型。随着k的增加,这种效应变得更加明显。如图4所示,改进后的模型的更好的mAP值支持了这一观察结果。虽然这本身不是更好的分割性能的充分条件,但这与表2的结果表明,提出的方法以一种有意义的方式进行域适应。由于很难将分割任务学习到的映射可视化,跨域检索实验可以被视为如何在特征空间中缩小域差距的合理措施。
5.5.对不可见域的泛化

表5:对应于SYNTHIA→CITYSCAPES设置的模型,在第三个不可见域(CamVid数据集)上测量的平均IoU分割性能
任何域自适应算法的一个理想特征是域泛化,即提高在训练过程中看不到的域的性能。为了测试该方法的泛化能力,我们测试了为SYNTHIA训练的模型→ CamVid数据集上的城市景观设置。我们选择在三个数据集中的10个常见类上评估我们的模型。表5显示了仅源基线和适应模型计算的平均IoU值。所提出的方法在性能上获得了8.3点的原始改进,这是一个显著的改进,考虑到在训练期间自适应模型无法看到CamVid图像。这个实验展示了该方法以一种通用的方式学习领域不变表示的能力。
6.结论和未来工作
在本文中,我们讨论了跨不同领域执行语义分割的问题。特别是,我们考虑了一个非常困难的情况,即合成数据(源)有丰富的监控信息,但实际数据(目标)没有此类信息。我们提出了一种联合对抗的方法,该方法使用生成器-鉴别器对将目标分布的信息传递给学习的嵌入。通过在两个大型数据集上的实验,我们证明了我们的方法比现有方法的优越性,从而证明了我们的训练过程的通用性和可扩展性。此外,我们的方法在评估期间没有额外的计算开销,这是在实践中部署此类方法时的一个关键方面。作为未来的工作,我们希望扩展这种方法,以明确纳入考虑透视变化的几何约束,并适应不同领域的视频等时间输入。
7.附录:架构细节和超参数
7.1.架构细节和超参数

我们实验中使用的网络架构的详细信息。Conv-卷积层,ConvT-转置卷积层,S-步幅,P-填充。对于每个Conv /ConvT层,括号中的数字表示过滤器的数量。
我们实验中使用的架构的详细信息如图所示。如本文第3节所述,我们的方法的整个管道由4个网络组成——F、C、G和D网络。我们对F− C对的两种体系结构进行了实验:FCN-8s和Deeplab-Resnet-101。对于FCN-8s,我们将直到fc7层的网络表示为f网络,最后的分类层处理为C网络。对于Deeplab-Resnet-101,res5c层之前的网络表示为F网络,其余层表示为C网络。
图描述了G和D网络的体系结构。G网络是一个多级网络,它接受F网络中间层的输入以生成重建图像。我们观察到,与仅使用最后一层的响应相比,融合来自F网络早期层的信息可以产生高质量的生成结果。对于G和D网络,我们都使用了受最近几个生成模型成功启发的残差块[32]
在我们的方法中有两个超参数:α-:辅助分类损失的权重;β-:对抗性成分的权重(参见本文第3节)。我们观察到网络对这些参数不是很敏感。我们发现参数设置α=0.1和β=0.1在所有设置中都很有效,并将其用于我们的所有实验。
7.2.损失函数的具体实现

7.2.1.Loss For Discriminator Updating
- Lsadv,D
1)将真实的源域影像输入D得到对影像标签的预测(真实标签为Source-Real),通过计算预测标签和Source-Real-Label的交叉熵损失
lossD_src_real_s = cross_entropy2d(outD_src_real_s, domain_labels_src_real, size_average=self.size_average)
2)将生成的假源域影像输入D得到对影像标签的预测(真实标签为Source-Fake),通过计算预测标签和Source-Fake-Label的交叉熵损失
lossD_src_fake_s = cross_entropy2d(outD_src_fake_s, domain_labels_src_fake, size_average=self.size_average)
3)将真实的源域影像输入D得到对影像分割的预测图,通过预测的分割图和源域真实的分割掩模之间的交叉熵损失
lossD_src_real_c = cross_entropy2d(outD_src_real_c, label_forD, size_average=self.size_average)
- Ltadv,D
1)将真实的目标域影像输入D得到对影像分割的预测图,通过预测的分割图和源域真实的
lossD_tgt_real = cross_entropy2d(outD_tgt_real_s, domain_labels_tgt_real, size_average=self.size_average)
2)将生成的假目标域影像输入D得到对影像标签的预测(真实标签为Target-Fake),通过计算预测标签和Target-Fake-Label的交叉熵损失
lossD_tgt_fake = cross_entropy2d(outD_tgt_fake_s, domain_labels_tgt_fake, size_average=self.size_average)
7.2.2.Loss For Generator Updating
- Lsadv,G
1)将生成的假源域影像输入D得到对影像标签的预测(真实标签为Source-Fake),通过计算预测标签和Source-Real-Label的交叉熵损失
lossG_src_adv_s = cross_entropy2d(outD_src_fake_s, domain_labels_src_real,size_average=self.size_average)
2)将生成的假源域影像输入D得到对影像分割的预测图,通过预测的分割图和源域真实的分割掩模之间的交叉熵损失
lossG_src_adv_c = cross_entropy2d(outD_src_fake_c, label_forD,size_average=self.size_average)
- Ltadv,G:将生成的假目标域影像输入D得到对影像标签的预测(真实标签为Target-Fake),通过计算预测标签和Target-Real-Label的交叉熵损失
- L~recon,G:通过计算源域和目标域的原图与对应生成的假图像之间的MSE损失:
lossG_src_mse = F.l1_loss(outG_src,data_source_forD)
lossG_tgt_mse = F.l1_loss(outG_tgt,data_target_forD)
最终损失
lossG = lossG_src_adv_c
+ 0.1*(lossG_src_adv_s+ lossG_tgt_adv_s)
+ self.l1_weight * (lossG_src_mse + lossG_tgt_mse)
lossG /= len(data_source)
7.2.3.Loss For F,C Network Updating
- Lsseg,FC:将真实的源域影像输入F再经过C直接得到预测的分割图,计算预测的分割图和真实分割图治安的交叉熵损失
lossC = cross_entropy2d(score, labels_source,size_average=self.size_average)
- Lsadv,F
1)将生成的假源域影像输入D得到对影像标签的预测(真实标签为Source-Fake),通过计算预测标签和Target-Real-Label的交叉熵损失
lossF_src_adv_s = cross_entropy2d(outD_src_fake_s, domain_labels_tgt_real,size_average=self.size_average)
2)将生成的假源域影像输入D得到对影像分割的预测图,通过预测的分割图和源域真实的分割掩模之间的交叉熵损失
lossG_src_adv_c = cross_entropy2d(outD_src_fake_c, label_forD,size_average=self.size_average)
- Ltadv,F:将生成的目标源域影像输入D得到对影像标签的预测(真实标签为Target-Fake),通过计算预测标签和Source-Real-Label的交叉熵损失
lossF_tgt_adv_s = cross_entropy2d(outD_tgt_fake_s, domain_labels_src_real,size_average=self.size_average)
最终损失
lossF = lossC
+ self.adv_weight*(lossF_src_adv_s + lossF_tgt_adv_s)
+ self.c_weight*lossF_src_adv_c
lossF /= len(data_source)
参考文献
[1] S. Ben-David, J. Blitzer, K. Crammer, and F. Pereira. Analysis of representations for domain adaptation. In Advances in neural information processing systems, pages 137–144, 2007. 7
[2] K. Bousmalis, N. Silberman, D. Dohan, D. Erhan, and D. Krishnan. Unsupervised pixel-level domain adaptation with generative adversarial networks. arXiv preprint arXiv:1612.05424, 2016. 2
[3] G. J. Brostow, J. Fauqueur, and R. Cipolla. Semantic object classes in video: A high-definition ground truth database. Pattern Recognition Letters, 30(2):88–97, 2009. 8
[4] M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele. The cityscapes dataset for semantic urban scene understanding. In Proc. of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016. 1, 5
[5] H. Daume III. Frustratingly easy domain adaptation. In Proceedings of the 45th Annual Meeting of the Association of Computational Linguistics, June 2007. 2
[6] M. Everingham, L. Gool, C. K. Williams, J. Winn, and A. Zisserman. The pascal visual object classes (voc) challenge. Int. J. Comput. Vision, 2010. 2
[7] Y . Ganin and V . Lempitsky. Unsupervised domain adaptation by backpropagation. arXiv preprint arXiv:1409.7495, 2014. 2
[8] L. A. Gatys, A. S. Ecker, and M. Bethge. A neural algorithm of artistic style. CoRR, abs/1508.06576, 2015. 2
[9] B. Geng, D. Tao, and C. Xu. Daml: Domain adaptation metric learning. IEEE Transactions on Image Processing, 20(10):2980–2989, 2011. 2, 7
[10] B. Gong, Y . Shi, F. Sha, and K. Grauman. Geodesic flow kernel for unsupervised domain adaptation. In 2012 IEEE Conference on Computer Vision and Pattern Recognition, pages 2066–2073, 2012. 2
[11] R. Gopalan, R. Li, and R. Chellappa. Domain adaptation for object recognition: An unsupervised approach. In Proceedings of the 2011 International Conference on Computer Vision, ICCV ’11, 2011. 2
[12] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016. 1
[13] J. Hoffman, E. Tzeng, T. Park, J.-Y . Zhu, P . Isola, K. Saenko, A. A. Efros, and T. Darrell. Cycada: Cycle-consistent adversarial domain adaptation. arXiv preprint arXiv:1711.03213, 2017. 7
[14] J. Hoffman, D. Wang, F. Y u, and T. Darrell. Fcns in the wild: Pixel-level adversarial and constraint-based adaptation. CoRR, abs/1612.02649, 2016. 2, 5, 6, 7
[15] J. Johnson, A. Alahi, and L. Fei-Fei. Perceptual losses for real-time style transfer and super-resolution. In Computer Vision - ECCV 2016 - 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part II, pages 694–711, 2016. 2
[16] D. P . Kingma and J. Ba. Adam: A method for stochastic optimization. CoRR, abs/1412.6980, 2014. 5
[17] A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems, 2012. 5
[18] T.-Y . Lin et al. Microsoft coco: Common objects in context. In ECCV, 2014. 2
[19] M.-Y . Liu and O. Tuzel. Coupled generative adversarial networks. In D. D. Lee, M. Sugiyama, U. V . Luxburg, I. Guyon, and R. Garnett, editors, Advances in Neural Information Processing Systems 29, pages 469–477. 2016. 2
[20] J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3431–3440, 2015. 1, 2, 6
[21] M. Long, Y . Cao, J. Wang, and M. I. Jordan. Learning transferable features with deep adaptation networks. In Proceedings of the 32nd International Conference on Machine Learning, pages 97–105, 2015. 2
[22] M. Long, J. Wang, and M. I. Jordan. Unsupervised domain adaptation with residual transfer networks. CoRR, abs/1602.04433, 2016. 2
[23] J. Lu, J. Yang, D. Batra, and D. Parikh. Hierarchical question-image co-attention for visual question answering. In Advances in Neural Information Processing Systems 29: Annual Conference on Neural Information Processing Systems 2016, December 5-10, 2016, Barcelona, Spain, 2016. 1
[24] R. Mottaghi, X. Chen, X. Liu, N.-G. Cho, S.-W. Lee, S. Fidler, R. Urtasun, and A. Y uille. The role of context for object detection and semantic segmentation in the wild. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2014. 6
[25] A. Radford, L. Metz, and S. Chintala. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv preprint arXiv:1511.06434, 2015. 4
[26] S. R. Richter, V . Vineet, S. Roth, and V . Koltun. Playing for data: Ground truth from computer games. In B. Leibe, J. Matas, N. Sebe, and M. Welling, editors, European Conference on Computer Vision (ECCV), volume 9906 of LNCS, pages 102–118. Springer International Publishing, 2016. 1, 5
[27] G. Ros, L. Sellart, J. Materzynska, D. V azquez, and A. M. Lopez. The synthia dataset: A large collection of synthetic images for semantic segmentation of urban scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3234–3243, 2016. 5
[28] S. Sankaranarayanan, Y . Balaji, C. D. Castillo, and R. Chellappa. Generate to adapt: Aligning domains using generative adversarial networks. arXiv preprint arXiv:1704.01705, 2017. 2
[29] K. Simonyan and A. Zisserman. V ery deep convolutional networks for large-scale image recognition. CoRR, abs/1409.1556, 2014. 5
[30] E. Tzeng, J. Hoffman, K. Saenko, and T. Darrell. Adversarial discriminative domain adaptation. CoRR, abs/1702.05464, 2017. 2
[31] F. Y u and V . Koltun. Multi-scale context aggregation by dilated convolutions. In ICLR, 2016. 6
[32] Y . Zhang, P . David, and B. Gong. Curriculum domain adaptation for semantic segmentation of urban scenes. In The IEEE International Conference on Computer Vision (ICCV), Oct 2017. 2, 5, 6
[33] J.-Y . Zhu, T. Park, P . Isola, and A. A. Efros. Unpaired image-to-image translation using cycle-consistent adversarial networks. In The IEEE International Conference on Computer Vision (ICCV), Oct 2017. 2, 7