TIP2021/UDA/语义分割:Affinity Space Adaptation for Semantic Segmentation Across Domains跨域语义分割的关联空间适应
TRANSACTIONS ON IMAGE PROCESSING2021: Affinity Space Adaptation for Semantic Segmentation Across Domains跨域语义分割的关联性空间适应
- 0.摘要
- 1.概述
- 2.相关工作
-
- 2.1.语义分割
- 2.2.成对的关联性
- 2.3.领域自适应
- 2.4.和相关工作的比较
- 3.方法
-
- 3.1.概述
- 3.2.关联空间清理
- 3.3.关联空间对齐
- 3.4.网络架构
- 4.实验
-
- 4.1.数据集和精度评定指标
- 4.2.应用细节
- 4.3.Synthetic-to-Real适应的结果
-
- 4.3.1.与相关的基于分布对齐的方法的比较
- 4.3.2.与IT和ST互补
- 4.4.消融实验
-
- 4.4.1.超参数的消融实验
- 4.4.2.不同连通性的消融实验
- 4.5.模型复杂度分析
-
- 4.5.Real-to-Real适应结果
- 4.6.缺点
- 5.总结
- 参考文献
论文地址
代码地址
0.摘要
基于深度学习的密集像素标注语义分割算法取得了良好的性能。然而,语义分割在野外的推广仍然具有挑战性。本文研究了语义分割中的无监督域自适应问题。由于源领域和目标领域具有不变的语义结构,我们建议利用这种跨领域的不变性,利用结构化语义分割输出中成对像素之间的并发模式。这与大多数现有的方法不同,后者试图根据图像、特征或输出级别中的单个像素级信息来适应域。具体地说,我们对相邻像素之间的关联关系(称为源域和目标域的关联空间)进行域适应。为此,我们制定了两种关联空间适应策略:关联空间清理策略和对抗性关联空间对齐策略。大量的实验表明,所提出的方法在跨域语义分割的几个具有挑战性的基准上比一些最先进的方法具有更好的性能。
1.概述
在一个特定的领域不能很好地概括在一个新的领域。这是因为源训练图像和目标测试图像之间存在域转移。为了克服这个问题,人们通常求助于大量像素级标记的目标数据,这既昂贵又乏味。因此,语义分割在实际应用中仍然具有挑战性。
为了解决上述问题,近年来研究了非监督域适应(UDA)方法,该方法只提供源域的标注,而不提供目标域的标注。这种UDA问题已被广泛用于图像分类,其中大多数之前的工作试图匹配源和目标分布,通过对抗学习[9]学习领域不变特征。同样,在语义分割领域,最近的方法试图通过最小化图像样式[10]、中间特征[11]-[13]或网络输出空间[14]的分布之间的差异来弥合域间隙。现有的方法表明,图像、特征和输出级别的对齐在跨域语义分割中起着重要作用。
考虑到语义分割是一个结构化的预测问题,具有跨领域的鲁棒性,可以假设结构化知识有利于跨领域的语义切分。相邻像素输出之间的关联关系包含了丰富的空间结构和局部上下文信息,揭示了结构知识。因此,我们引入了关联性空间的概念,该空间建立在每个像素的预测输出与其所有相邻像素之间的关联性关系之上。我们的目标是在这个概念的基础上,对语义分割进行域适应。具体来说,我们探索了这一概念在两个方案中不同视角下的两种实施,以实现这种关联力空间适应。首先,我们设计了一种关联力损失,在源图像和目标图像的关联力空间中都强制高关联力,并在源区域上分割损失。因为一幅图像(包括源域和目标域)是由一些连续的语义区域组成的先验。属于同一语义的相邻像素在两个不同语义区域的相邻像素中占主导地位。因此,这种设计的关联力损失就相当于关联力空间的清洗,将关联力空间规整,使得目标域几乎处处都接近于源域的高值关联力空间。事实上,如图1(a)所示,如果没有适应性,目标域的关联力空间就不是很干净,因为存在许多低关联力。提出的关联空间清理(见图1(b))将为源和目标域产生干净且相似的关联映射。其次,我们还研究了对抗性训练,以直接对齐目标域和源域的关联空间分布。如图1©所示,对抗性关联空间适应也能有效地对齐关联空间。
综上所述,本文的主要贡献包括三个方面:1)我们引入了关联力空间的概念,通过利用相邻像素之间的共现输出模式来强调结构,从而在语义分割中进行域适应;2)提出了关联空间适应性的两种有效方案:关联空间损失清洗和关联空间对抗性对齐;3)在多个具有挑战性的跨域语义分割基准上,提出的关联性空间适应方法比一些最新的方法取得了更好的性能。
本文的其余部分组织如下。我们在第二节简要回顾了一些相关的工作,然后在第三节提出了方法。第四节给出了广泛的实验结果。最后,第五部分对全文进行了总结并提出了一些看法。
2.相关工作

图1所示。提出了由跨域输出结构相似驱动的亲和空间适应性。我们建议匹配亲和空间,揭示源和目标域之间的输出结构。(a)为源领域和目标领域不需要自适应的分割结果。(b)和©分别为提出的亲和性空间适应的亲和性空间清理(ASC)和亲和性空间对齐(ASA)策略的分割结果。对于亲和可视化,我们展示了每个像素的预测与其所有相邻像素之间的平均余弦相似度。
我们首先回顾了第II-A节中一些关于语义切分的代表性著作,然后是第II-B节中一些利用成对关联的相关著作。然后,我们简要回顾了一些最近的领域适应方法跨领域的语义分割在第II-C节。第II-D节给出了所提方法与一些相关工作的比较。
2.1.语义分割
语义分割是计算机视觉的一项基本任务。目标是为图像的每个像素分配一个类别标签。自FCN[1]和U-Net[15]以来,在深度神经网络的驱动下,语义分割取得了很大的进展。.
许多方法被提出,以提高分割性能。例如,Deeplab[4],[16]表明通过扩大卷积扩大感受野可以显著提高性能。通过atrous空间金字塔池(ASPP)[4]、[16]、金字塔空间池(PSP)[3]或上下文编码[5]利用上下文信息也可以提高分割精度。其他一些方法[2]、[7]、[17]试图结合成对关系来提供结构化推理,有助于缓解语义分割中的不一致性问题。最近,DANet[18]和OCNet[19]提出利用自我注意机制来捕获远程依赖,从而获得优异的性能。
这些完全监督的方法依赖于大量像素级注释数据。然而,[20]声称,专家在每幅图像的像素级注释上花费了90分钟。提出了一些弱监督方法来利用容易获得的注释,如图像级标签[21]、[22]、绑定框[23]、[24]或涂鸦[25],以规避像素级注释的昂贵成本。解决注释问题的另一个方向是利用合成数据集,例如GTA5[20]和SYNTHIA[26]。虽然带注释的合成数据很容易收集,但在实际场景中应用时,由于合成数据和真实数据之间的域转移,在合成数据上训练的模型性能急剧下降。
2.2.成对的关联性
成对像素关联在计算机视觉任务中有着悠久的应用历史。在早期的视觉[27]中,局部关联力被用来表征内在的几何结构。在[28]和[29]中,两两关联作为聚类线索参与了分割。近年来,成对像素关联与卷积神经网络(CNN)相结合,为语义或实例分割提供结构推理。示例为[2],[4],[7],[17],[30]。在[2]和[4]中,作者通过条件随机场(CRF)利用了成对关联性。为了提高分割精度,在[7]中提出了一种基于关联度的自适应丢失算法。在[17]中,作者提出了学习关联力的空间传播网络,以提高语义切分。在[30]中,作者显式地回归了成对的关联,用于分离具有相同语义的实例,以便进行实例分割
2.3.领域自适应
域适应旨在解决源域和目标域之间的域转移问题。为了跨域图像分类,开发了多种方法[31]-[38]。其主要思想是通过对抗性学习来最小化域间分布的差异。
与分类上的适应相似,大多数现代的语义分割适应模型也依赖对抗性学习来适应中间特征级别[11]、[39]-[41]或输出级别[14]、[42]、[43]的域。首先在[11]中通过对抗网络对源和目标域的全局特征进行比对,解决UDA语义分割问题。最近,在[41]中引入了一个意义感知的信息瓶颈来对潜在特征空间中的域进行对齐。[14]、[42]-[44]表明,在输出级比对域可能比在特征级比对域更好地进行跨域语义分割。在[14]中,作者首先提出在结构化输出上显式对齐域,然后通过引入新的损失函数[42]、[43]或额外的补丁级输出空间对齐[44]来改进或扩展结构化输出域。
除了平等对待每个语义类别的分布(即特征级或输出级)对齐策略外,一些[44]-[46]方法倾向于提高某些特定类别或区域的性能。在[45]中,Luo等人提出了一个类别级对抗网络,它自适应地为类别级适应的对抗损失加权。SSF-DAN[46]利用伪标签获取每个类的语义特征,进行分离适配,从而在不太频繁的类上提高性能。在[44]中,Tsai等人考虑了多模式的逐patch输出分布,并在[14]上附加了一个patch对齐模块,进一步提高了适应性能。这些最新的方法表明,类或区域条件适应有利于基于分布对齐的跨域语义分割。
在[10],[44],[47]-[50]中,像图像平移和自训练这样的技术已经被证明是有用的,或者是对基于分布对齐的领域适应方法的补充。在[10]中,作者利用CycleGAN[51]生成额外的目标数据,并在特征层上进行对抗性适应。DCAN[47]同时进行图像级和特征级适配。DISE[49]将图像分解为领域不变结构和领域特定纹理,以便更好地进行图像平移和标签转移。在CBST[48]中,作者提出了一个新的类平衡自训练框架,该框架考虑了类分布的不平衡和空间先验。最近,BDL[50]提出了一种双向学习框架,使图像翻译模型、分割适应模型和自训练模型交替学习,进一步提高了性能。
还有一些方法通过有效利用源数据[52],设计损失函数[43],[53],课程模型适应[54],[55],或自集成策略[56],[57]来寻求减少域间隙
2.4.和相关工作的比较
现有的无监督域自适应方法主要是基于图像中单个像素级信息、中间特征或输出水平进行域对齐。尽管这些方法在跨领域中取得了显著的性能,但结构和上下文表示并没有得到明确的利用。我们建议在结构化语义分割的输出级别中,通过利用成对像素之间的共发生模式来突出结构。该方法对输出预测中相邻像素间的关联关系给出的关联空间进行域自适应。我们采用两种关联空间适应策略:关联空间清理策略和对抗性关联空间对齐策略。虽然我们提出的方法是受一些完全监督分割方法中涉及的成对关联性的重要性的驱动,但我们以不同的方式利用成对关联性,通过构建一个关联性空间并对其进行域适应。这首次证明了关联关系有利于UDA在语义分割中的应用。
3.方法
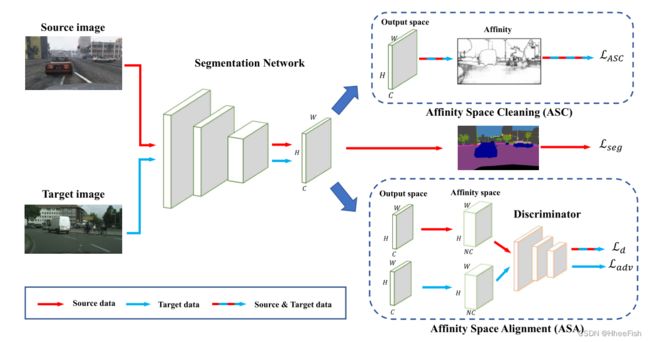
图2所示。所提方法的概述。对于具有亲和空间清洗的亲和空间适应,在源域和目标域都施加了基于亲和的损失LASC。在对抗性亲和空间对齐策略中,我们利用对抗性训练使跨域的亲和空间看起来相似。红色箭头用于源域,蓝色箭头用于目标域,混合箭头表示两个域。对于这两种亲和空间适应方案,分割损失Lseg也计算在分割预测之间,并提供源图像的注释。
3.1.概述
给定源数据XS⊂RH×W×3带有密集像素级注释的YS⊂(1,…, C)H×W和目标数据XT⊂RH×W×3没有注释。语义分割中的无监督域适应(UDA)旨在训练一个对目标数据XT性能良好的模型,其中h和w分别是图像的高度和宽度,C是类的数量。考虑到语义分割是一个结构化的预测问题,我们利用成对的共现模式,揭示了输出结构在不同域之间是不变的。具体来说,我们引入了关联力空间的概念,它建立在输出空间中相邻像素之间的关联力基础上。我们使用UDA对关联空间进行语义分割,而不是对单个像素的信息(来自图像、特征或输出水平)进行语义分割。为此,我们提出了两种基于关联空间概念的适应方案,关联空间描述相邻像素之间的相似性,并根据提出的方案有不同的实现。第一种策略通过关联性空间清理损失隐性规格化关联性空间(见3.2节)。第二个是一个对抗性框架,它显式地对齐跨域的关联分布(见3.3节)。关联空间适应框架的流程如图2所示。用于跨域进行语义分割的网络体系结构见第3.4节。
3.2.关联空间清理
语义分割可以看作是一个结构化的预测问题。即使目标图像没有地面真实值,我们仍然可以对输出结构施加一些限制。事实上,根据对输出空间中相邻像素之间关联力的观察(见图1),我们注意到关联力是不干净的,即在没有自适应的大部分目标图像上关联性都很低。对于期望的语义分割,仅在相邻语义区域的边缘关联性较低,从而得到清晰的关联性图。因此,我们提出在源图像和目标图像上都存在关联力空间的清理损失,以迫使网络产生干净的输出空间的关联力映射。对于图像X,建议的关联空间清理(ASC)损失公式如下:
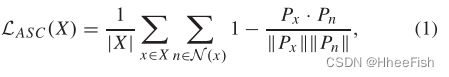
其中N(x)是像素x的4个或8个空间相邻邻居的集合,|·|表示基数(即集合中包含的元素的“个数”),P表示Softmax输出预测,||·||是向量的大小。最大限度地减少这种关联空间清理损失鼓励高关联性无处不在。虽然在边界像素上的ASC并不完全有意义,但在大多数情况下,在期望的分割中,位于同一语义区域的成对相邻像素优于来自两个不同语义区域的相邻像素。采用这种方法进行结构推理是合理的,使目标域的关联空间规整到接近源域的关联空间。对于目标图像Xt,最小化这种关联清理损失。对于带有ground truth注释y的源图像Xs,我们可以优化以下交叉熵损失用于分割:
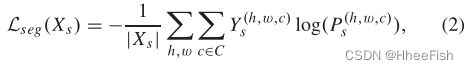
其中Ys是ground-truth注解的独热表示。该关联空间适应方案最终要最小化的目标函数为:
![]()
其中λASC是一个权重因子(设置为一个较小的值,如0.001),表示损失LASC的重要性。Eq.(1)中的ASC损失在某种程度上起到平滑目标图像中没有监督的区域的作用,并且在[0,1]的范围内。在训练开始时,当目标预测不准确时,源图像上Lseg分割的交叉熵损失远大于LASC:λASC = 0.001。因此,训练的开始主要以源图像的分割损失为指导。当源图像的分割损失下降到一个比较小的值时,分割模型已经对目标图像具有一定的分割能力,ASC开始影响网络训练。因此,本文提出的ASC策略一般不会损害模型训练。
提出的ASC的另一种解释可能是,通过以完全监督的方式优化源图像,分割模型已经具有一定的预测目标图像语义标签的能力。通过进一步最小化LASC,我们强制相邻像素具有相同的标签预测,以某种方式将当前像素的准确分类分数传播到相邻属于同一语义区域的像素。
3.3.关联空间对齐
我们还提出了一个对抗框架,以明确对齐目标领域与源领域的关联空间分布。通过这种方式,我们可以将共存模式的知识从源域转移到目标域,例如,天空类总是在建筑类的顶部,骑手类总是在自行车或摩托车类的顶部。对于这种对抗性关联空间对齐(ASA),我们首先从输出预测P∈RH×W×C构建关联空间A∈RH×W×NC,其中N(4或8对于4-连通性或8-连通性而言)是每个像素上涉及的相邻像素个数。精确地说,对于一个像素x和它的一个相邻像素n,我们将Px = (p1x,···,pCx)和Pn = (p1n,···,pCn)作为相应的c类Softmax输出向量。然后,我们基于关联相关向量An = (a1n,···,aCn)构建关联空间A,对每个类使用KL类散度测度,其中
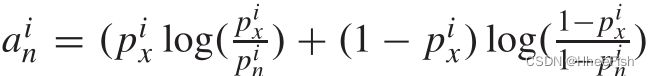
对于底层像素x的N对相邻像素,我们有N个这样的关联向量,通过将它们串联在一起,得到一个NC通道向量A = (A1,···,AN)。它产生关联空间A,其每个图象的大小为H×W×NC,与将所有通道压缩为相邻像素之间的标量相似性的K路KL散度和余弦相似性相比,这种类KL散度度量更好地保留了不同类之间的共现信息。例如,不同K-way分类概率的相邻像素可能会导致这些标量测量值相同。在每一类上使用所提出的KL类散度测度,可以生成不同的向量。
给定来自源域或目标域的图像X,分割网络生成关联空间A。我们使用源域和目标域的二进制交叉熵损失Ld将关联空间A转发给完全卷积鉴别器D。损耗Ld公式如下:
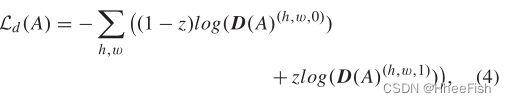
其中,对于来自目标域的样本,z等于0,对于来自源域的样本,z是1。对于来自目标域的图像Xt,训练分割网络的对抗目标如下所示:
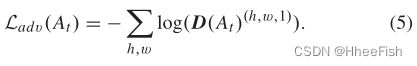
目标是通过最大化目标域的关联空间At被视为源域的关联空间的概率来训练分割网络并欺骗鉴别器。与等式(2)中源图像的分割损失协作,用于训练分割网络的总体损失函数可以写为:
![]()
其中λASA是Ladv的权重因子。在训练期间,我们交替地分别使用等式(4)和等式(6)中的损失函数优化鉴别器网络D和分割网络。
3.4.网络架构
对于语义分割网络,我们采用与[14]相同的网络架构。更具体地说,我们采用Deeplab-V2模型[4]作为基础架构,同时摒弃了多尺度融合策略。我们使用两个CNN主干(VGG-16[58]和ResNet-101[59])来评估所提出的方法,这两个主干都是用在ImageNet上预先训练的模型初始化的。根据文献[4],我们修改了CNN主干最后两个卷积层的步幅和扩张率。两个主干模型的最后一层也应用了膨胀率为{6、12、18、24}的Atrus空间金字塔池(ASPP)。对于鉴别器,我们选择了[14]中使用的类似网络体系结构,用于提议的对抗性亲和空间对齐。更准确地说,鉴别器由五个4×4卷积层组成,分别具有步长2和通道编号{64、128、256、512、1}。除最后一层外,每个卷积层后面都有一个LeakyReLU层,其固定负斜率为0.2。
4.实验
为了验证所提出的跨领域语义分割方法的有效性,我们在两个流行的领域适应基准上进行了实验:GTA5[20]到Cityscapes[61]和SYNTHIA[26]到Cityscapes。实验结果,包括跨城市案例和跨领域医学图像分割,也给出了真实到真实适应场景的验证。在下面,我们将阐明实现细节,并将所提出的方法与使用类似主干的其他最新方法进行比较。
4.1.数据集和精度评定指标
1)合成-真实适应
首先以cityscape[61]为目标数据集,GTA5[20]和SYNTHIA[26]分别为源数据集进行合成-真实适应实验。关于这些数据集的详细信息简短描述如下。
Cityscapes[61]是一个应用广泛的语义分割数据集,包含了来自50个城市的5000幅图像的高质量密集注释。数据集分为2975、500和1525幅图像,分别用于训练、验证和测试。它提供了30个常见类,其中19个类用于评估。
GTA5[20]是一个合成数据集,包含24966张使用游戏引擎GTA5构建的图像。提供了33个类的像素级语义注释。按照其他方法,我们只使用常见的19个类与Cityscapes[61]数据集进行配对。
SYNTHIA[26]是另一个由Unity游戏引擎渲染的大型合成数据集。它的子集名为SYNTHIA-RANDCITYSCAPES,提供了9400张与Cityscapes[61]类兼容的标签图像。与GTA5不同的是,这个数据集包含各种视角的合成图像,使其具有领域适应性的挑战性
在前人的工作[14]、[42]、[48]基础上,我们利用已标记的cityscape合成图像和未标记的训练图像进行适应,并在cityscape的val分割上评估所提出的适应模型。
2)真实-真实适应
我们还对真实-真实适应情景进行评估,以进一步验证所提方法的有效性。为此,我们在跨城市数据集[62]和两个视网膜眼底图像数据集REFUGE[63]和RIM-ONE-r3[64]上进行实验。这些数据集的细节将在下面给出。
Cross-city[62]是一个高质量的道路场景数据集,收集自四个不同的城市:罗马、里约热内卢、东京和台北。每个城市由3200张未标注的图片和100张与城市景观兼容的标注图片组成。与[62]相似,我们采用cityscape训练集作为源域,利用3200幅未标注的图像将分割模型应用于每个目标城市。每个数据集的其他100幅带注释的图像用于评估
REFUGE[63]和RIM-ONE-r3[64]是两个视网膜眼底图像数据集,用于视网膜视盘和视杯的分割。REFUGE[63]有400幅高分辨率的训练图像。RIM-ONE-R3[64]数据集包含99个训练样本和60个测试样本。两个数据集都有精确的像素级分割注释光盘和杯子。我们使用REFUGE[63]中的400幅高分辨率训练图像作为源域,并将分割模型应用于RIM-ONE-R3[64]数据集的99个样本。我们报告了在RIM-ONE-R3[64]数据集中的60幅测试图像的分割结果。
3)精度评定指标
在所有的实验中,我们都采用了广泛使用的交叉口-过联合(IoU)对道路场景进行合成-真实和真实-真实的分割适应,并采用Dice系数(DSC)对医学图像进行分割适应。具体而言,两个评价指标分别为:
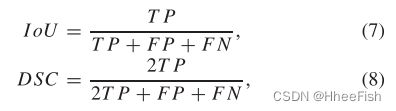
其中TP, FP, and Fn分别表示真阳性、假阳性、假阴性像素的个数。
4.2.应用细节
该实现基于公共工具箱PyTorch[65]。所有实验都是在配备12GB内存的NVIDIA TITAN Xp GPU卡的工作站上进行的。为了进行公平的比较,我们使用与AdaptSegNet[14]相同的超参数设置。更具体地说,对于分割模型,我们使用SGD作为具有“poly”学习速率策略的优化器。我们将初始学习率base_lr设为2.5 × 10−4,功率设为0.9。动量设置为0.9,权重衰减设置为0.0005。对于鉴别器,我们采用初始学习率为1 × 10−4的Adam优化器。动量设定为0.9和0.99。本文所有实验中,Eq.(3)中的λASC和Eq.(6)中的λAS A均设为0.001。除明确声明外,我们使用8连通性相邻像素来定义关联空间。由于GPU内存有限,在训练期间,GTA5(对应。SYNTHIA)源图像的大小调整为720 × 1280(对应。760 × 1280),所有实验均将目标cityscape图像的大小调整为512×1024。在测试阶段,使用与Cityscapes培训阶段相同的512 × 1024大小。然后分割结果在评估时调整到原始输入大小。在real-to-real自适应实验中,我们将图像大小调整为512 × 1024作为跨城市自适应的训练输入,并在REFUGE和RIM-ONE-r3数据集上将图像大小调整为512 × 512用于医学图像的分割自适应。请注意,我们没有使用地面真实值来选择最佳适应模型。相反,正如我们在第III-B节中所假设的那样,一个预期的语义分割网络会产生清晰的输出空间亲和性。因此,我们通过计算训练集上的平均像素亲和度(ground-truth-free)来选择自适应模型。具体来说,我们选择在目标域的序列集上具有最大平均像素关联性值的模型。
4.3.Synthetic-to-Real适应的结果
该方法旨在通过对输出预测的关联空间进行对齐来实现自适应,属于基于分布对齐的方法。因此,我们首先将所提出的方法与一些试图利用对抗性训练来对齐特征或输出分布的最先进的方法进行比较。然后,我们探索了所提出的方法与使用伪标签的图像翻译(IT)和自我训练(ST)的互补,并与一些同样使用这些技术的相关方法进行了比较。注意:本文不对使用不同骨干网而不是VGG16或ResNet101的相关方法进行比较。
4.3.1.与相关的基于分布对齐的方法的比较
我们首先将提出的方法与一些相关的基于分布对齐的方法进行比较。依靠类或区域条件适应来提高某些特定类别或区域的性能的方法不包括在比较中。
GTA5→Cityscapes
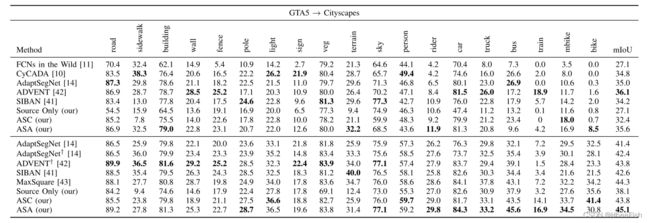
表1:与一些最先进的方法进行定量比较,以使GTA5适应城市景观。在第一组和第二组中,分别采用VGG-16和RESNET-101骨干网络。使用多级自适应训练的方法标有†
图3:GTA5的定性结果→ 城市景观适应。(a) 目标图像和相应的GTs。(b-d):在(b)中使用建议的关联空间清理,在(d)中使用建议的对抗关联空间对齐,在(b)中使用适应之前的关联映射和语义分割结果。
我们首先对GTA5中所提出的方法进行了基准测试。选项卡。我将介绍几种最先进的方法的性能比较。提出的亲和力空间适应实现了竞争或优越的性能。具体地说,与使用VGG16和ResNet101主干网的其他方法相比,本文提出的亲和空间清理具有竞争性。使用ResNet101骨干网,提出的ASC产生43.8%的mIoU, mIoU比多级设置的[14]高出1.4%,比类似的单级设置的[14]高出2.4%。值得注意的是,设计亲和损失的ASC不依赖额外的对抗性鉴别器,从而导致更有效的训练。提出的对抗亲和空间对齐进一步提高了VGG16和ResNet101主干网的性能。更准确地说,使用ResNet101骨干提出的ASA比最近的工作,直接校准Softmax输出[14]或输出熵[42]之间的源域和目标域(在多级适应下)分别2.7%和1.3% mIoU。与SIBAN[41]和MaxSquare[43]相比,提出的ASA分别提高了2.5% mIoU和0.8% mIoU。图3给出了所提出的亲和空间适应性的一些定性结果。该方法有效地对齐了亲和空间,实现了跨域的自适应语义分割。
SYNTHIA→Cityscapes
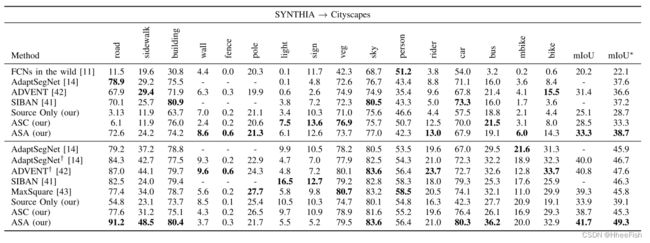
表2:在使SYNTHIA适应城市景观方面,与一些最先进的方法进行定量比较。在第一组和第二组中,分别采用VGG-16和RESNET-101骨干网络。使用多级自适应训练的方法标有†
然后,我们将提出的方法从SYNTHIA数据集应用于城市景观。在之前的工作[14],[42]之后,我们在Tab中报告了16和13类(用*标记)的结果。2《侠盗猎车手5》对城市景观的适应也是如此。所提出的ASC达到了与几种最先进的方法相同的结果。与GTA5对城市景观的适应性结果一致,提出的与ASA策略的亲和力空间适应性与最先进的方法具有竞争力。准确地说,使用ResNet101骨干提出的ASA对[14]和[42]的多级设置分别提高了2.6%和1.7% mIoU,对[14]的类似单级设置提高了3.4% mIoU。与[41]和[43]的方法相比,本文提出的ASA分别提高了3.0% mIoU和3.5% mIoU。对于VGG16骨干网,所提出的ASA比[14]提高了1.1% mIoU。与ResNet101骨干网相比,VGG16骨干网对亲和性空间适应性的改进不明显。这可能是因为在源域上使用VGG16的语义分割不如使用ResNet101的语义分割准确,导致亲和空间对齐距离ground-truth亲和空间较远。这使得适应更具挑战性。
值得注意的是,大多数方法在Tab中显示的未被充分表示的类(例如fence, pole和light)上表现不佳。我和选项卡。2这是无监督域适应中常见的类不平衡问题。在适应过程中,网络更倾向于关注主导阶级而不是其他阶级。因此,本文提出的方法对高频类(如road、building和sky)的性能提升一致,而对高频类(如fence、pole和light)的性能提升不一致。尽管如此,如Tab所示。我和选项卡。二、总体业绩仍很令人鼓舞。结合类平衡技术可能会获得更好的性能,这是未来很有前途的探索方向。
4.3.2.与IT和ST互补
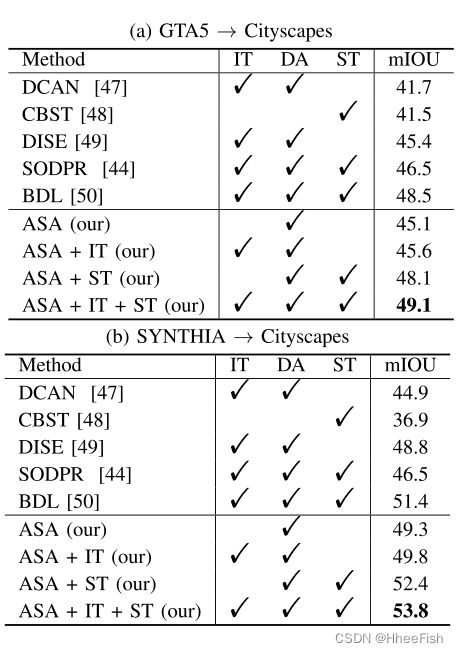
表3:基于分布对齐(DA)、图像转换(IT)和自我训练(ST)的拟议ASA的补充
最近的工作旨在通过利用以下三种策略来解决UDA的语义分割问题:1)连接图像风格差异的图像翻译(IT);2)分布对齐(DA),其目的是对中间特征或输出预测的分布进行对齐;3)有效使用伪标签的自我训练。如[49],[50]所示,这三种策略是相辅相成的。虽然所提出的方法主要关注输出预测的分布对齐(DA),但我们也讨论了所提出的分布对齐与IT和ST技术的互补。
图像翻译(Image Translation, IT)
在无监督域自适应中,图像平移是一种直观的减小图像级域间隙的方法。我们首先探索与IT的互补,利用CyCADA[10]从源域图像生成类似目标的图像。然后,我们利用ASA对新生成的图像进行自适应,使其与目标图像相适应。由于图像平移以某种方式减小了domian gap,本实验将式(6)中的ASA适应权重λAS A设为0.0001。如Tab所示。第三,图像转换技术在GTA5→Cityscapes和SYNTHIA→Cityscapes两种适应中都带来了性能提升,表明图像转换与ASA适应是互补的。
自训练(Selg-Training, ST)
自我训练是无监督领域适应的另一种常见策略。自我训练的核心是如何获得“正确”的伪标签。我们采用与提议的ASA相适应的模型以一种直接的方式生成伪标签。具体来说,对于图像中的每个像素x,我们验证该像素上的Softmax输出。如果最高置信度大于0.9,我们认为预测的类是x上的伪标签。否则,我们将其设置为忽略标签,在梯度反向传播中将忽略该标签。我们在目标域上用伪标签对分割网络进行再训练。如Tab所示。第三,提出的方法也是对自我培训战略的补充。更具体地说,在GTA5→Cityscapes适应方面,提出的ASA结合自我训练策略产生48.1% mIoU,与依赖额外图像转换策略的BDL[50]表现相似。在SYNTHIA→城市景观适应方面,提出的ASA结合自我训练策略,mIoU达到52.4%,BDL[50]提高1.0% mIoU。
图像平移和自训练
图像平移和自训练可以进一步补充基于分布对齐的方法[44],[50]。为了与BDL[50]和SODPR[44]进行公平的比较,我们还在提出的ASA中加入了图像平移和自训练策略,以进一步提高性能。如Tab所示。第三,我们在GTA5→Cityscapes和SYNTHIA→Cityscapes基准测试中都达到了最先进的性能,这进一步证明了ASA在图像翻译和自我训练方面的互补性。具体来说,我们在GTA5→城市景观适应上得到49.1%的mIoU,分别比BDL[50]和SODPR[44]高出0.6% mIoU和2.6% mIoU。在SYNTHIA→cityscape适应性实验中,获得了53.8%的mIoU, BDL[50]提高了2.4% mIoU, SODPR[44]提高了7.3% mIoU。
4.4.消融实验
我们对所提出方法的两个主要组成部分进行了消融研究:1)公式(3)中的Loss超参数λASC和公式(6)中的λASA;2)关联空间定义的连通性不同。
4.4.1.超参数的消融实验
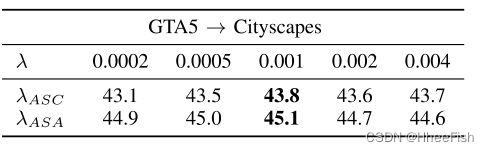
表4:ASC和ASA损失λ的敏感性分析
ASC的加权因子λASC和ASA的加权因子λASA是两个重要的超参数。我们对这两个超参数进行了敏感性分析。以不同的权重因子评价不同的ASC和ASA对GTA5→城市景观适应的表现。如Tab所示。第四,ASC和ASA都能承受较大范围的权重因子。在所有实验中,λASC和λASA均为0.001。
4.4.2.不同连通性的消融实验
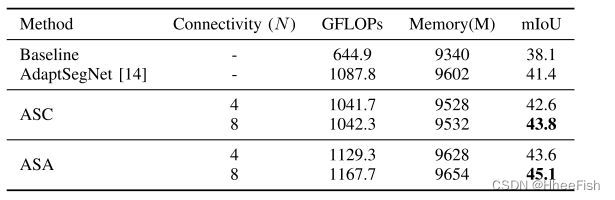
表5:基于关联空间概念及模型复杂度分析中相邻像素数N的探讨 GTA5→ Cityscapes适应

图4:GTA5上具有不同连接设置的ASA对角线关联可视化→ (a)中一些目标图像上的城市景观调整。(b) 和(c)分别显示在4连接性(C4)和8连接性(C8)设置下,ASA的每个像素及其所有对角线相邻像素的预测之间的平均余弦相似性所给出的对角线关联性
我们还研究了不同的连接设置对定义亲和空间的影响。为此,我们在GTA5→Cityscapes适应过程中进行了4连通性和8连通性实验。如表5所示。ASC和ASA两种亲和空间适应策略在8连通性方面都取得了更好的性能,这表明揭示输出结构的共发生模式在语义分割中是非监督域适应的重要作用。为了进一步理解不同连通性的影响,我们还可视化了一些目标图像上具有不同连通性设置的ASA的对角关联图。如图4所示,对于每个像素,我们计算的平均余弦相似性与4对角线邻国(见红色箭头在图目标图像的左下角。4)。它可以观察到,与8-connectivity ASA (C8)设置下实现对角关联比ASA 4-connectivity (C4)设置,从而获得更好的分割性能。
4.5.模型复杂度分析
我们还分析了训练期间的计算量和内存占用。ASC和ASA的额外计算复杂度均为O(N×H ×W),其中×W表示输出预测的空间分辨率,N表示所涉及的相邻像元个数。如Tab所示。V,与AdaptSegNet[14]相比,本文提出的ASC和ASA都取得了更好的性能,但在训练过程中略微增加了计算成本和内存使用量。
4.5.Real-to-Real适应结果
基于虚拟-真实适应评价,提出的ASA策略总体上比ASC策略更有效地适应关联空间。我们在两个真实到真实的分割适应上评估所提出的ASA,以进一步证明所提出的方法的有效性。
Cross-City → Cityscapes
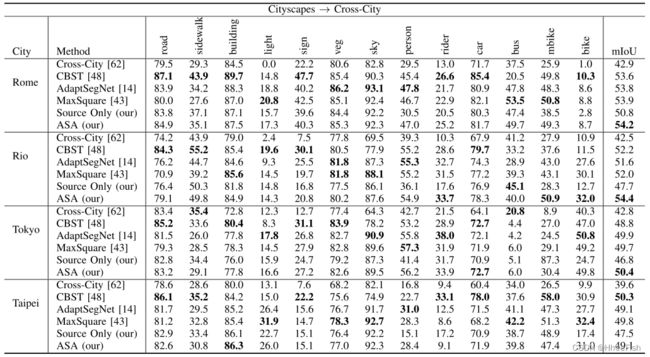
表6:在Cityscapes →Cross-City ,与一些最先进的方法进行定量比较

图5:Cityscapes →Cross-City 一些定性结果→ 跨城市适应。从左到右:(a)目标图像;(b) 地面真值分割;(c) 无适应性的分割;(d) 具有相似空间对齐(ASA)自适应的分段
目前针对UDA语义分割的研究主要集中在从合成到真实情景,特别是从合成到城市景观的任务上。在实践中,跨不同城市的领域转移是一个更加现实和具有挑战性的场景。为了验证该方法在真实到真实的适应上的有效性,我们进行了cityscape数据集与Cross-city数据集的语义分割实验。我们在Tab中列出基线和ASA结果。VI,并与其他一些最先进的方法进行比较。如Tab所示。VI,针对真实场景下域差距小的问题,提出的方法也实现了不同城市的一致性改进。一些定性分割结果如图5所示。该算法在不需要任何自适应的情况下,有效地改善了分割结果
REFUGE → RIM-ONE-r3
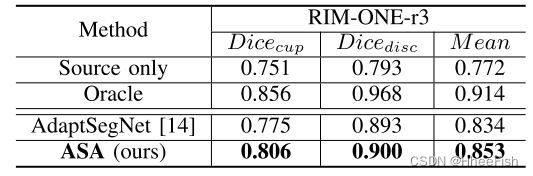
表7:RIM-ONE-R3“测试”拆分时,将REFUGE 调整到RIM-ONE-R3的DICE系数量化结果
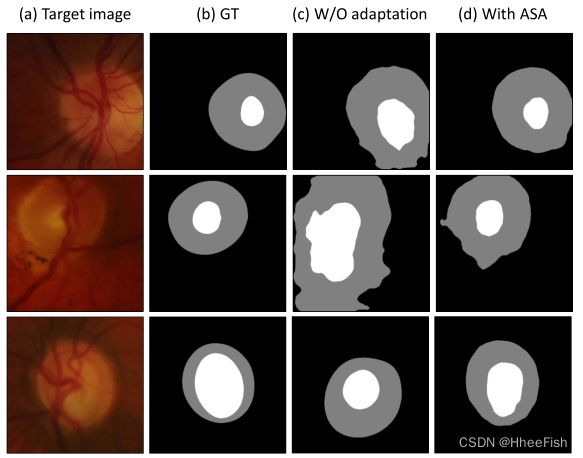
图6:关于REFUGE→RIM-ONE-r3适应性的一些定性结果。
在医学图像分析中,除了对城市场景进行适应外,域间隙也是一个重要问题。为了验证所提方法的通用性,我们进行了视网膜视盘和视网膜杯分割的无监督域适应实验。具体来说,我们采用Deeplabv3-plus[16]作为基线,并使用相同的实验设置评估最相关的AdaptSegNet[14]和提议的ASA。如Tab所示。7推荐的ASA始终优于基线和AdaptSegNet[14]。一些定性结果如图6所示。该算法有效地弥合了源域和目标域之间的域差距。
4.6.缺点
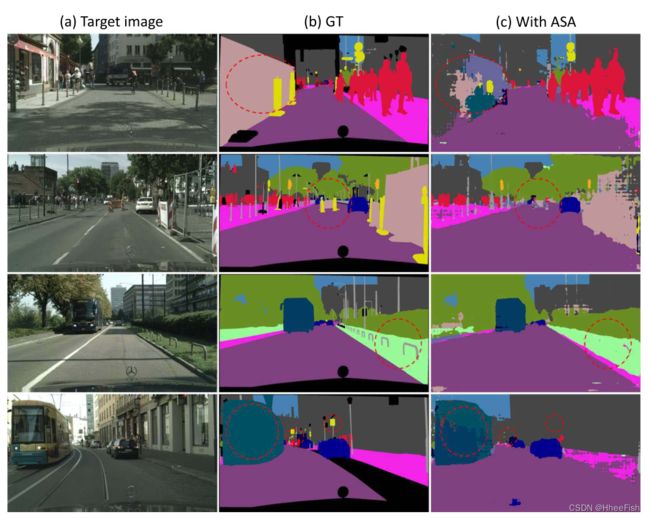
图7:GTA5→Cityscapes中的一些失败例子(游戏邦注:如红色圆圈所示)适应。
实验结果表明,该方法在大多数情况下都能取得较好的效果。然而,它仍然不能解决一些棘手的问题,如精细的结构,区域不一致。所提出的方法对于低频率类(例如,light和pole)也不太有效。一些失效案例如图7所示。请注意,这些困难的问题对于其他最先进的方法也具有挑战性
5.总结
本文研究了无监督域自适应语义分割问题。考虑到语义分割的输出通常是结构化的,并且具有跨域的不变结构,我们建议利用这种不变性,通过利用输出级相邻像素之间的亲和关系,而不是在大多数最先进的方法中对单个逐像素信息适应域。为此,我们引入了对关联关系进行编码的亲和空间的概念。我们采用两种关联空间适应策略:关联空间清理策略和对抗性关联空间对齐策略。两种关联空间适应方案都能有效地将揭示源领域和目标领域语义分割输出结构的共现模式对齐,从而获得优于某些最新方法的性能。这首次证明了亲和关系有利于语义分割中的无监督域自适应。未来,我们计划研究提出的两种关联空间适应策略的结合,并将提出的输出级适应与其他图像和/或特征级的适应相结合。我们还想探索所提出的方法与最近的类或区域条件适应的补充,以进一步提高性能。
参考文献
[1] J. Long, E. Shelhamer, and T. Darrell, “Fully convolutional networks for semantic segmentation,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2015, pp. 3431–3440.
[2] S. Zheng et al., “Conditional random fields as recurrent neural networks,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), Dec. 2015, pp. 1529–1537.
[3] H. Zhao, J. Shi, X. Qi, X. Wang, and J. Jia, “Pyramid scene parsing network,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jul. 2017, pp. 2881–2890
[4] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Y uille, “DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 40, no. 4, pp. 834–848, Apr. 2018.
[5] H. Zhang et al., “Context encoding for semantic segmentation,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Jun. 2018, pp. 7151–7160.
[6] H. Zhao et al., “Psanet: Point-wise spatial attention network for scene parsing,” in Proc. Eur. Conf. Comput. Vis., Sep. 2018, pp. 267–283.
[7] T.-W. Ke, J.-J. Hwang, Z. Liu, and S. X. Y u, “Adaptive affinity fields for semantic segmentation,” in Proc. Eur. Conf. Comput. Vis., Sep. 2018, pp. 587–602.
[8] M. Zhen, J. Wang, L. Zhou, T. Fang, and L. Quan, “Learning fully dense neural networks for image semantic segmentation,” in Proc. AAAI Conf. Artif. Intelligence., 2019, pp. 9283–9290.
[9] I. Goodfellow et al., “Generative adversarial nets,” in Proc. Adv. Neural Inf. Process. Syst., 2014, pp. 2672–2680.
[10] J. Hoffman et al., “Cycada: Cycle-consistent adversarial domain adaptation,” in Proc. Int. Conf. Mach. Learn., 2018, pp. 1994–2003.
[11] J. Hoffman, D. Wang, F. Y u, and T. Darrell, “FCNs in the wild: Pixel-level adversarial and constraint-based adaptation,” 2016, arXiv:1612.02649.
[Online]. Available: http://arxiv.org/abs/1612.02649
[12] S. Sankaranarayanan, Y . Balaji, A. Jain, S. N. Lim, and R. Chellappa, “Learning from synthetic data: Addressing domain shift for semantic segmentation,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Jun. 2018, pp. 3752–3761.
[13] Y . Zhang, Z. Qiu, T. Y ao, D. Liu, and T. Mei, “Fully convolutional adaptation networks for semantic segmentation,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Jun. 2018, pp. 6810–6818.
[14] Y .-H. Tsai, W.-C. Hung, S. Schulter, K. Sohn, M.-H. Y ang, and M. Chandraker, “Learning to adapt structured output space for semantic segmentation,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Jun. 2018, pp. 7472–7481.
[15] O. Ronneberger, P. Fischer, and T. Brox, “U-Net: Convolutional networks for biomedical image segmentation,” in Proc. 18th Int. Conf. Med. Image Comput. Comput.-Assist. Intervent., vol. 9351, 2015, pp. 234–241.
[16] L.-C. Chen, Y . Zhu, G. Papandreou, F. Schroff, and H. Adam, “Encoderdecoder with atrous separable convolution for semantic image segmentation,” in Proc. Eur. Conf. Comput. Vis., Sep. 2018, pp. 801–818.
[17] S. Liu, S. De Mello, J. Gu, G. Zhong, M.-H. Y ang, and J. Kautz, “Learning affinity via spatial propagation networks,” in Proc. Adv. Neural Inf. Process. Syst., 2017, pp. 1520–1530.
[18] J. Fu et al., “Dual attention network for scene segmentation,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2019, pp. 3146–3154.
[19] Y . Yuan and J. Wang, “OCNet: Object context network for scene parsing,” 2018, arXiv:1809.00916.
[Online]. Available: http://arxiv. org/abs/1809.00916
[20] S. R. Richter, V . Vineet, S. Roth, and V . Koltun, “Playing for data: Ground truth from computer games,” in Proc. Eur. Conf. Comput. Vis., vol. 9906, 2016, pp. 102–118.
[21] Z. Huang, X. Wang, J. Wang, W. Liu, and J. Wang, “Weakly-supervised semantic segmentation network with deep seeded region growing,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Jun. 2018, pp. 7014–7023.
[22] X. Li, H. Ma, and X. Luo, “Weaklier supervised semantic segmentation with only one image level annotation per category,” IEEE Trans. Image Process., vol. 29, pp. 128–141, 2020.
[23] J. Dai, K. He, and J. Sun, “BoxSup: Exploiting bounding boxes to supervise convolutional networks for semantic segmentation,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), Dec. 2015, pp. 1635–1643.
[24] A. Khoreva, R. Benenson, J. Hosang, M. Hein, and B. Schiele, “Simple does it: Weakly supervised instance and semantic segmentation,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jul. 2017, pp. 876–885.
[25] D. Lin, J. Dai, J. Jia, K. He, and J. Sun, “ScribbleSup: Scribblesupervised convolutional networks for semantic segmentation,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2016, pp. 3159–3167.
[26] G. Ros, L. Sellart, J. Materzynska, D. Vazquez, and A. M. Lopez, “The SYNTHIA dataset: A large collection of synthetic images for semantic segmentation of urban scenes,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2016, pp. 3234–3243.
[27] T. Poggio, “Early vision: From computational structure to algorithms and parallel hardware,” in Human and Machine Vision II. A m s t e r d a m , The Netherlands: Elsevier, 1986, pp. 190–206.
[28] J. Shi and J. Malik, “Normalized cuts and image segmentation,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 22, no. 8, pp. 888–905, Aug. 2000.
[29] X. Wang, Y . Tang, S. Masnou, and L. Chen, “A global/local affinity graph for image segmentation,” IEEE Trans. Image Process., vol. 24, no. 4, pp. 1399–1411, Apr. 2015.
[30] Y . Liu et al., “Affinity derivation and graph merge for instance segmentation,” in Proc. Eur. Conf. Comput. Vis., Sep. 2018, pp. 686–703.
[31] E. Tzeng, J. Hoffman, K. Saenko, and T. Darrell, “Adversarial discriminative domain adaptation,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jul. 2017, pp. 7167–7176.
[32] W. Zhang, W. Ouyang, W. Li, and D. Xu, “Collaborative and adversarial network for unsupervised domain adaptation,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Jun. 2018, pp. 3801–3809.
[33] K. Saito, K. Watanabe, Y . Ushiku, and T. Harada, “Maximum classifier discrepancy for unsupervised domain adaptation,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Jun. 2018, pp. 3723–3732.
[34] S. Xie, Z. Zheng, L. Chen, and C. Chen, “Learning semantic representations for unsupervised domain adaptation,” in Proc. Int. Conf. Mach. Learn., 2018, pp. 5419–5428.
[35] M. Long, H. Zhu, J. Wang, and M. I. Jordan, “Unsupervised domain adaptation with residual transfer networks,” in Proc. Adv. Neural Inf. Process. Syst., 2016, pp. 136–144.
[36] K. Saito, Y . Ushiku, T. Harada, and K. Saenko, “Adversarial dropout regularization,” in Proc. Int. Conf. Learn. Represent., 2017, pp. 1–15.
[37] S. Li, S. Song, G. Huang, Z. Ding, and C. Wu, “Domain invariant and class discriminative feature learning for visual domain adaptation,” IEEE Trans. Image Process., vol. 27, no. 9, pp. 4260–4273, Sep. 2018.
[38] J. Li, M. Jing, K. Lu, L. Zhu, and H. T. Shen, “Locality preserving joint transfer for domain adaptation,” IEEE Trans. Image Process., vol. 28, no. 12, pp. 6103–6115, Dec. 2019.
[39] W. Hong, Z. Wang, M. Y ang, and J. Y uan, “Conditional generative adversarial network for structured domain adaptation,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Jun. 2018, pp. 1335–1344.
[40] Q. Wang, J. Gao, and X. Li, “Weakly supervised adversarial domain adaptation for semantic segmentation in urban scenes,” IEEE Trans. Image Process., vol. 28, no. 9, pp. 4376–4386, Sep. 2019.
[41] Y . Luo, P . Liu, T. Guan, J. Y u, and Y . Y ang, “Significance-aware information bottleneck for domain adaptive semantic segmentation,” in Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), Oct. 2019, pp. 6777–6786.
[42] T.-H. Vu, H. Jain, M. Bucher, M. Cord, and P . Perez, “ADVENT: Adversarial entropy minimization for domain adaptation in semantic segmentation,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2019, pp. 2517–2526.
[43] M. Chen, H. Xue, and D. Cai, “Domain adaptation for semantic segmentation with maximum squares loss,” in Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), Oct. 2019, pp. 2090–2099.
[44] Y .-H. Tsai, K. Sohn, S. Schulter, and M. Chandraker, “Domain adaptation for structured output via discriminative patch representations,” in Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), Oct. 2019, pp. 1456–1465.
[45] Y . Luo, L. Zheng, T. Guan, J. Y u, and Y . Y ang, “Taking a closer look at domain shift: Category-level adversaries for semantics consistent domain adaptation,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2019, pp. 2507–2516.
[46] L. Du et al., “SSF-DAN: Separated semantic feature based domain adaptation network for semantic segmentation,” in Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), Oct. 2019, pp. 982–991.
[47] Z. Wu et al., “DCAN: Dual channel-wise alignment networks for unsupervised scene adaptation,” in Proc. Eur. Conf. Comput. Vis., Sep. 2018, pp. 518–534.
[48] Y . Zou, Z. Y u, B. V . Kumar, and J. Wang, “Unsupervised domain adaptation for semantic segmentation via class-balanced self-training,” in Proc. Eur. Conf. Comput. Vis., Sep. 2018, pp. 289–305.
[49] W.-L. Chang, H.-P . Wang, W.-H. Peng, and W.-C. Chiu, “All about structure: Adapting structural information across domains for boosting semantic segmentation,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2019, pp. 1900–1909.
[50] Y . Li, L. Yuan, and N. Vasconcelos, “Bidirectional learning for domain adaptation of semantic segmentation,” in Proc. IEEE/CVF Conf. . Comput. Vis. Pattern Recognit. (CVPR), Jun. 2019, pp. 6936–6945.
[51] J.-Y . Zhu, T. Park, P . Isola, and A. A. Efros, “Unpaired image-to-image translation using cycle-consistent adversarial networks,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), Oct. 2017, pp. 2223–2232.
[52] F. S. Saleh, M. S. Aliakbarian, M. Salzmann, L. Petersson, and J. M. Alvarez, “Effective use of synthetic data for urban scene semantic segmentation,” in Proc. Eur. Conf. Comput. Vis., Sep. 2018, pp. 84–100.
[53] X. Zhu, H. Zhou, C. Y ang, J. Shi, and D. Lin, “Penalizing top performers: Conservative loss for semantic segmentation adaptation,” in Proc. Eur. Conf. Comput. Vis., Sep. 2018, pp. 568–583.
[54] C. Sakaridis, D. Dai, S. Hecker, and L. V an Gool, “Model adaptation with synthetic and real data for semantic dense foggy scene understanding,” in Proc. Eur. Conf. Comput. Vis., Sep. 2018, pp. 687–704.
[55] C. Sakaridis, D. Dai, and L. V an Gool, “Semantic foggy scene understanding with synthetic data,” Int. J. Comput. Vis., vol. 126, no. 9, pp. 973–992, Sep. 2018.
[56] Y . Xu, B. Du, L. Zhang, Q. Zhang, G. Wang, and L. Zhang, “Selfensembling attention networks: Addressing domain shift for semantic segmentation,” in Proc. AAAI Conf. Artif. Intell., vol. 33, 2019, pp. 5581–5588.
[57] J. Choi, T. Kim, and C. Kim, “Self-ensembling with GAN-based data augmentation for domain adaptation in semantic segmentation,” in Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), Oct. 2019, pp. 6830–6840.
[58] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” in Proc. Int. Conf. Learn. Represent., 2015, pp. 1–14.
[59] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2016, pp. 770–778.
[60] O. Russakovsky et al., “ImageNet large scale visual recognition challenge,” Int. J. Comput. Vis., vol. 115, no. 3, pp. 211–252, Dec. 2015.
[61] M. Cordts et al., “The cityscapes dataset for semantic urban scene understanding,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2016, pp. 3213–3223.
[62] Y .-H. Chen, W.-Y . Chen, Y .-T. Chen, B.-C. Tsai, Y .-C.-F. Wang, and M. Sun, “No more discrimination: Cross city adaptation of road scene segmenters,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), Oct. 2017, pp. 1992–2001.
[63] J. I. Orlando et al., “REFUGE challenge: A unified framework for evaluating automated methods for glaucoma assessment from fundus photographs,” Med. Image Anal., vol. 59, Jan. 2020, Art. no. 101570.
[64] F. Fumero, S. Alayon, J. L. Sanchez, J. Sigut, and M. Gonzalez-Hernandez, “RIM-ONE: An open retinal image database for optic nerve evaluation,” in Proc. 24th Int. Symp. Comput.-Based Med. Syst. (CBMS), Jun. 2011, pp. 1–6.
[65] A. Paszke et al., “Automatic differentiation in PyTorch,” in Proc. NIPS Workshop, 2017, pp. 1–4.