吴恩达机器学习(十三)—— ex5:Regularized Linear Regression and Bias v.s. Variance(MATLAB+Python)
吴恩达机器学习系列内容的学习目录 → \rightarrow →吴恩达机器学习系列内容汇总。
- 一、线性回归的正则化
-
- 1.1 可视化数据集
- 1.2 正则化线性回归的代价函数
- 1.3 线性回归梯度的正则化
- 1.4 拟合线性回归
- 二、偏差和方差
-
- 2.1 学习曲线
- 三、多项式回归
-
- 3.1 学习多项式回归
- 3.2 可选练习:调整正则化参数
- 3.3 使用交叉验证集选择 λ λ λ
- 3.4 可选练习:计算测试集误差
- 3.5 可选练习:使用随机选择的样本绘制学习曲线
- 四、MATLAB实现
-
- 4.1 ex5.m
- 五、Python实现
-
- 5.1 ex5.py
本次练习对应的基础知识总结 → \rightarrow →线性回归、正则化、应用机器学习的建议和机器学习系统的设计。
本次练习对应的文档说明和提供的MATLAB代码 → \rightarrow → 提取码:dcfm。
本次练习对应的完整代码实现(MATLAB + Python版本) → \rightarrow →Github链接。
一、线性回归的正则化
在前半部分的练习中,我们将通过实现正则化线性回归来利用水库水位变化预测大坝的出水量。在后半部分,我们将通过调试学习算法进行一些诊断,并检查偏差与方差的影响。
提供的脚本ex5.m将帮助我们逐步完成此练习。
1.1 可视化数据集
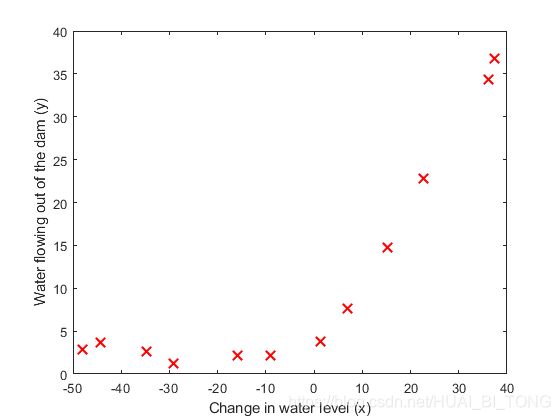
我们将通过可视化数据集开始此次练习,该数据集包含有关水位变化 x x x以及大坝的出水量 y y y的历史记录。数据集分为三个部分:
- 我们的模型将学习的训练集: X X X、 y y y
- 用于确定正则化参数的交叉验证集: X v a l X_{val} Xval、 y v a l y_{val} yval
- 用于评估性能的测试集(这些是我们的模型在训练期间看不到的样本数据): X t e s t X_{test} Xtest、 y t e s t y_{test} ytest
我们运行ex5.m绘制训练数据,如图1所示。在接下来的部分中,我们将实现线性回归并使数据拟合成一条直线,然后绘制出学习曲线。之后,我们将实现多项式回归来找到对数据更为合适的拟合。
1.2 正则化线性回归的代价函数
回想一下,正则化线性回归的代价函数为 J ( θ ) = 1 2 m ( ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 ) + λ 2 m ∑ j = 1 n θ j 2 J(\theta)=\frac{1}{2m} \left ( \sum_{i=1}^{m} (h _{\theta}(x^{(i)})-y^{(i)})^{2} \right )+\frac{ \lambda}{2m} \sum_{j=1}^{n} \theta _{j}^{2} J(θ)=2m1(i=1∑m(hθ(x(i))−y(i))2)+2mλj=1∑nθj2
其中 λ λ λ是控制正则化程度的正则化参数,因此有助于防止过度拟合。正则化项对总代价 J J J进行惩罚,随着模型参数 θ j θ_{j} θj的大小增加,惩罚也在增加。需要注意的是,我们不应正则化 θ 0 θ_{0} θ0项。
我们现在应该在文件linearRegCostFunction.m中完成代码,任务是编写一个函数来计算正则化线性回归的代价函数。编写程序时最好对代码进行向量化处理,避免编写循环。
完成linearRegCostFunction.m中的代价函数部分需要填写以下代码:
temp=[0;theta(2:end)]; % 先把theta(1)拿掉,不参与正则化
h = X * theta;
J = 1/(2*m) * (X*theta - y)'* (X*theta - y) + lambda /(2*m) * temp' * temp ;
完成后,ex5.m使用初始化为[1; 1]的theta调用linearRegCostFunction,我们可以得到输出为303.993。
Cost at theta = [1 ; 1]: 303.993192
(this value should be about 303.993192)
1.3 线性回归梯度的正则化
相应地,正则化线性回归代价对 θ j θ_{j} θj的偏导数定义为
∂ J ( θ ) ∂ θ 0 = 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) f o r j = 0 ∂ J ( θ ) ∂ θ j = ( 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) ) + λ m θ j f o r j ⩾ 1 \begin{matrix} \frac{\partial J(\theta )}{\partial \theta _{0}}=\frac{1}{m}\sum_{i=1}^{m} (h _{\theta}(x^{(i)})-y^{(i)})x_{j}^{(i)}\ _{}\ _{}\ _{}\ _{}for\ _{}\ _{}j=0\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\\ \\ \frac{\partial J(\theta )}{\partial \theta _{j}}=\left (\frac{1}{m}\sum_{i=1}^{m} (h _{\theta}(x^{(i)})-y^{(i)})x_{j}^{(i)} \right )+\frac{\lambda }{m}\theta _{j}\ _{}\ _{}\ _{}\ _{}for\ _{}\ _{}j\geqslant 1 \end{matrix} ∂θ0∂J(θ)=m1∑i=1m(hθ(x(i))−y(i))xj(i) for j=0 ∂θj∂J(θ)=(m1∑i=1m(hθ(x(i))−y(i))xj(i))+mλθj for j⩾1
在linearRegCostFunction.m中,添加代码以计算梯度,并将其返回到变量grad中。
完成linearRegCostFunction.m中的梯度部分需要填写以下代码:
grad = 1/m .* X' * (h - y) + lambda/m * temp;
完成后,ex5.m使用初始化为[1; 1]的theta调用linearRegCostFunction,我们可以得到输出为[-15.30; 598.250]。
Gradient at theta = [1 ; 1]: [-15.303016; 598.250744]
(this value should be about [-15.303016; 598.250744])
1.4 拟合线性回归
一旦我们的代价函数和梯度能够正常运行,接下来ex5.m将运行trainLinearReg.m中的代码以计算 θ θ θ的最优值,我们通过使用fmincg优化代价函数来寻找 θ θ θ的最优值。
在这部分中,我们将正则化参数 λ λ λ设为零。因为我们当前线性回归的实现是在试图拟合二维 θ θ θ,而正则化对于低维的 θ θ θ不会产生太大的帮助。在后面的练习部分中,我们将使用带正则化的多项式回归。
ex5.m使用 λ = 0 λ=0 λ=0调用trainLinearReg,我们可以得到如下结果:
Iteration 1 | Cost: 1.052435e+02
Iteration 2 | Cost: 2.237391e+01
Iteration 3 | Cost: 2.237391e+01
Iteration 4 | Cost: 2.237391e+01
Iteration 5 | Cost: 2.237391e+01
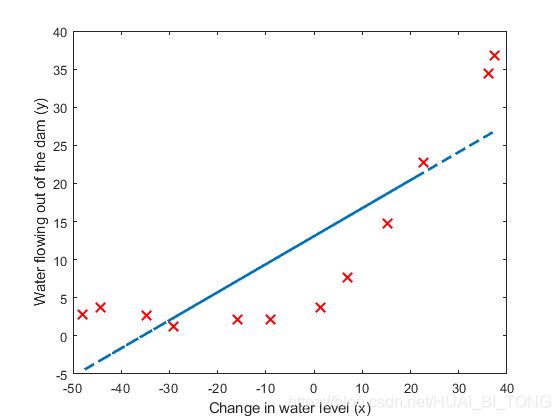
最后,ex5.m脚本还应该绘制最佳拟合线,如图2所示。最佳拟合线告诉我们,该模型对于我们的数据而言不是一个好的拟合,因为数据具有非线性模式。可视化最佳拟合是调试学习算法中的一种可能的方法,但可视化数据和模型并不总是那么容易。在下一部分中,我们将实现一个生成学习曲线的函数,该函数可以帮助我们调试学习算法,即使是不那么容易可视化的数据。
二、偏差和方差
机器学习中一个重要的概念是偏差和方差的权衡。高偏差模型对数据的拟合不够复杂,往往存在欠拟合现象,而高方差模型对训练数据的拟合程度过高。
在本部分的练习中,我们将在学习曲线上绘制训练和测试误差,以诊断偏差和方差的问题。
2.1 学习曲线
现在,我们将实现代码以生成学习曲线,这将有助于调试学习算法。回想一下,学习曲线将训练和交叉验证误差绘制为训练集大小的函数。我们的任务是完成learningCurve.m函数,以便它为训练集和交叉验证集返回误差向量。
为了绘制学习曲线,我们需要不同尺寸训练集时的训练和交叉验证集误差。要获得不同大小的训练集,我们应使用原始训练集 X X X的不同子集。
我们可以使用trainLinearReg函数寻找 θ θ θ参数。要注意的是,lambda作为参数传递给learningCurve函数。在学习 θ θ θ参数之后,我们应该在训练和交叉验证集上计算误差。回想一下,数据集的训练误差定义为 J t r a i n ( θ ) = 1 2 m [ ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 ] J_{train}(\theta)=\frac{1}{2m}\left [ \sum_{i=1}^{m} (h _{\theta}(x^{(i)})-y^{(i)})^{2} \right ] Jtrain(θ)=2m1[i=1∑m(hθ(x(i))−y(i))2]
特别要注意的是,训练集误差不包括正则项。一种计算训练集误差的方法是使用现有代价函数,仅当使用 λ λ λ计算训练误差和交叉验证误差时将 λ λ λ设为0。在计算训练集误差时,请确保在训练子集上计算误差,而不是在整个训练集上进行计算。但是对于交叉验证误差的计算,我们应该在整个交叉验证集上对其进行计算。我们还应该将计算出的误差存储在向量error_train和error_val中。
完成learningCurve.m时需要填写以下代码:
for i=1:m
% 将训练集数目逐个增加,进行训练得出参数,这样就能画出随着训练数据集个数增加,训练集与验证集误差的大小变化
%利用X(1:i,:),y(1:i),trainLinearReg(),来训练参数theta
theta = trainLinearReg(X(1:i,:), y(1:i), lambda);
%用得出来的参数分别放到训练集和验证集中计算代价函数
%训练误差计算只用X(1:i,:), y(1:i)
error_train(i) = linearRegCostFunction(X(1:i,:), y(1:i), theta, 0);
%交叉验证用上所有的验证集,即Xval, yval
error_val(i) = linearRegCostFunction(Xval, yval, theta, 0);
end
完成后,ex5.m打印的学习曲线如图3所示,得到的训练误差和交叉验证误差的结果如下所示。
# Training Examples Train Error Cross Validation Error
1 0.000000 205.121096
2 0.000000 110.300366
3 3.286595 45.010231
4 2.842678 48.368911
5 13.154049 35.865165
6 19.443963 33.829962
7 20.098522 31.970986
8 18.172859 30.862446
9 22.609405 31.135998
10 23.261462 28.936207
11 24.317250 29.551432
12 22.373906 29.433818

在图3中,我们可以观察到,随着训练样本数量的增加,训练误差和交叉验证误差都很高。这反映了模型中的高偏差问题,线性回归模型太简单,无法很好地拟合我们的数据集。在下一部分中,我们将实现多项式回归来对该数据集拟合更好的模型。
三、多项式回归
我们的线性模型的问题在于,它对于数据而言过于简单,并导致欠拟合(高偏差)。在本部分的练习中,我们将通过增加更多的特征来解决此问题。
对于使用多项式回归,我们的假设具有以下形式: h θ ( x ) = θ 0 + θ 1 ∗ ( w a t e r L e v e l ) + θ 2 ∗ ( w a t e r L e v e l ) 2 + . . . + θ p ∗ ( w a t e r L e v e l ) p = θ 0 + θ 1 x 1 + θ 2 x 2 + . . . + θ p x p \begin{matrix}h_{\theta}(x)=\theta_{0}+\theta_{1}*(waterLevel)+\theta_{2}*(waterLevel)^{2}+...+\theta_{p}*(waterLevel)^{p}\\ =\theta_{0}+\theta_{1}x_{1}+\theta_{2}x_{2}+...+\theta_{p}x_{p}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\ _{}\end{matrix} hθ(x)=θ0+θ1∗(waterLevel)+θ2∗(waterLevel)2+...+θp∗(waterLevel)p=θ0+θ1x1+θ2x2+...+θpxp
上式通过定义 x 1 = ( w a t e r L e v e l ) x_{1}=(waterLevel) x1=(waterLevel), x 2 = ( w a t e r L e v e l ) 2 x_{2}=(waterLevel)^{2} x2=(waterLevel)2,…, x p = ( w a t e r L e v e l ) p x_{p}=(waterLevel)^{p} xp=(waterLevel)p,我们获得了线性回归模型,其中特征是原始值 ( w a t e r L e v e l ) (waterLevel) (waterLevel)的各种次幂。
现在,我们将使用数据集中现有特征 x x x的更高次幂添加更多特征。我们在本部分中的任务是完成polyFeatures.m中的代码,以便该函数将大小为 m × 1 m×1 m×1的原始训练集 X X X映射为其更高的次幂。具体来说,当将大小为 m × 1 m×1 m×1的训练集 X X X传递给该函数时,该函数应返回一个 m × p m×p m×p的矩阵X_poly,其中第1列储存 X X X的原始值,第2列储存 X 2 X^{2} X2的值,第3列储存 X 3 X^{3} X3的值,依此类推。
现在,我们有了一个可以将特征映射到更高维度的函数,并且ex5.m会将其应用于训练集、测试集和交叉验证集。
完成polyFeatures.m时需要填写以下代码:
% 增加多项式特征向量 x^p
for i=1:p
X_poly(:,i)=X .^ i;
end
3.1 学习多项式回归
在完成polyFeatures.m之后,ex5.m脚本将继续使用线性回归代价函数来训练多项式回归。
请记住,即使我们的特征向量中包含多项式项,但我们仍在解决线性回归的优化问题,多项式项已简单地转变为可用于线性回归的特征。我们仍将继续使用本练习前面部分中编写的代价函数和梯度函数。
在这部分中,我们将使用8维的多项式。事实证明,如果我们直接在预测数据上运行训练将无法很好地工作,因为特征严重缩放(例如,有样本 x = 40 x= 40 x=40,增加高次幂项后将会有特征 x 8 = 4 0 8 = 6.5 × 1 0 12 x_{8} = 40^{8} = 6.5×10^{12} x8=408=6.5×1012)。因此,我们需要归一化特征。
在学习用于多项式回归的参数 θ θ θ之前,ex5.m将首先调用featureNormalize归一化训练集的特征,并分别存储mu和sigma参数。此次练习已经为我们实现了此函数,并且与第一次练习中的函数相同。
ex5.m调用featureNormalize函数后,我们可以得到如下结果。
Normalized Training Example 1:
1.000000
-0.362141
-0.755087
0.182226
-0.706190
0.306618
-0.590878
0.344516
-0.508481
学习了参数θ之后,我们可以看到 λ = 0 λ= 0 λ=0的多项式回归得到的两个图如图4和5所示,得到的训练误差和交叉验证误差的结果如下所示。
Polynomial Regression (lambda = 0.000000)
#Training Examples Train Error Cross Validation Error
1 0.000000 160.721900
2 0.000000 160.121510
3 0.000000 61.754825
4 0.000000 61.928895
5 0.000000 6.609627
6 0.000001 10.629136
7 0.019388 12.558919
8 0.069170 7.537410
9 0.172022 7.157028
10 0.158695 9.556273
11 0.115700 7.354208
12 0.141381 16.746791


从图4中,我们可以看到多项式拟合能够很好地跟随数据点,因此可以获得一个低训练误差。但是,多项式拟合非常复杂,甚至在极端情况下也会下降,这表明多项式回归模型会过度拟合训练数据并且不能很好地泛化。
为了更好地理解非正则化(λ= 0)模型的问题,我们可以看到学习曲线(图5)有着相同的效果:训练误差低但交叉验证误差高。训练和交叉验证错误之间有差距,表明存在高方差问题。
解决过拟合(高方差)问题的一种方法是在模型中添加正则化。在下一节中,我们将尝试使用不同的 λ λ λ参数以观察正则化如何导致更好的模型。
3.2 可选练习:调整正则化参数
在本小节中,我们将观察正则化参数如何影响正则化多项式回归的偏差和方差。现在,我们应该在ex5.m中修改lambda参数,并尝试 λ = 1 、 100 λ= 1、100 λ=1、100。对于每一个值,脚本应该生成对数据的多项式拟合以及学习曲线。
- λ = 1 λ= 1 λ=1


对于 λ = 1 λ= 1 λ=1,我们可以看到很好地跟随数据趋势的多项式拟合(图6)和显示交叉验证和训练误差都收敛到相对较低的值的学习曲线(图7)。这表明 λ = 1 λ= 1 λ=1的正则多项式回归模型不存在高偏差或高方差问题。实际上,它在偏差和方差之间实现了良好的权衡。
- λ = 100 λ= 100 λ=100


对于 λ = 100 λ= 100 λ=100,我们可以看到不能很好地跟随数据的多项式拟合(图8)和显示交叉验证和训练误差都很大的学习曲线(图9)。在这种情况下,正则化太多,模型无法拟合训练数据。
3.3 使用交叉验证集选择 λ λ λ
在练习的前面部分中,我们观察到 λ λ λ的值会严重影响训练集和交叉验证集的正则化多项式回归结果。特别是,没有正则化( λ = 0 λ= 0 λ=0)的模型很适合训练集,但不能泛化。相反,具有过多正则化( λ = 100 λ= 100 λ=100)的模型不适合训练集和测试集。适当选择 λ λ λ(例如 λ = 1 λ= 1 λ=1)可以很好地拟合数据。
在本节中,我们将实现一种自动方法来选择 λ λ λ参数。具体来说,我们将使用交叉验证集来评估每个 λ λ λ值的好坏。在使用交叉验证集选择最佳 λ λ λ值后,我们可以在测试集上评估模型,以估计模型在实际看不见的数据上的表现。
我们的任务是完成validationCurve.m中的代码。具体来说,我们应该使用trainLinearReg函数去训练不同 λ λ λ值的模型,并计算训练误差和交叉验证误差。我们应该在以下范围内尝试 λ λ λ:{0, 0.001, 0.003, 0.01, 0.03, 0.1, 0.3, 1, 3, 10}。
完成validationCurve.m时需要填写以下代码:
for i=1:length(lambda_vec)
% 改变训练集数目中正则化参数,进行训练得出参数
% 这样就能画出随着正则化参数增加,训练集与测试集在线性回归代价函数的大小变化
lambda=lambda_vec(i);
theta = trainLinearReg(X, y, lambda);
% 用得出来的参数分别放到训练集和验证集中计算代价函数
error_train(i) = linearRegCostFunction(X, y, theta, 0);
error_val(i) = linearRegCostFunction(Xval, yval, theta, 0);
end
完成代码后,ex5.m的下一部分将运行我们的函数,该函数可以绘制交叉验证误差与 λ λ λ的曲线,如图10所示, λ λ λ为允许我们选择的参数,得到的训练误差和交叉验证误差的结果如下所示。
lambda Train Error Validation Error
0.000000 0.141381 16.746791
0.001000 0.148588 16.874732
0.003000 0.192817 19.855017
0.010000 0.222925 17.144918
0.030000 0.281851 12.829058
0.100000 0.459318 7.587014
0.300000 0.921760 4.636833
1.000000 2.076188 4.260626
3.000000 4.901351 3.822907
10.000000 16.092213 9.945509

在图10中,我们可以看到 λ λ λ的最佳值约为3。由于数据集的训练集和验证集拆分具有随机性,因此交叉验证误差有时可能会比训练误差低。
3.4 可选练习:计算测试集误差
在上一部分练习中,我们计算了正则化参数 λ λ λ各个值的交叉验证误差。但是,为了更好地反映模型在实际应用中的性能,在没有用于任何训练的测试集上评估“最终”模型是很重要的(即此测试集既没有用于选择 λ λ λ参数,也没有用于选择学习模型参数 θ θ θ)。
对于此可选的练习,我们应该使用找到的最佳 λ λ λ值去计算测试误差。在我们的交叉验证中,对于 λ = 3 λ= 3 λ=3,我们获得了3.8599的测试误差。
Compute Test Error (error_test = 3.859888)
3.5 可选练习:使用随机选择的样本绘制学习曲线
在实践中,尤其是对于小型训练集,当我们绘制学习曲线以调试算法时,在随机选择的多个样本集合中求平均值通常有助于确定训练误差和交叉验证误差。
具体而言,要确定 i i i个样本的训练误差和交叉验证误差,首先我们应该从训练集中随机选择 i i i个样本,并从交叉验证集中随机选择 i i i个样本。然后,我们将使用随机选择的训练集学习参数 θ θ θ,并在随机选择的训练集和交叉验证集上评估参数 θ θ θ。最后,我们应将上述步骤重复多次(例如50次),并且使用平均误差来确定 i i i个样本的训练误差和交叉验证误差。
对于此可选的练习,我们应该通过实现上述策略来计算学习曲线。完成此部分练习的代码如下:
%% =========== Part 9: Plotting learningcurves with randomly selected examples =============
lambda = 0.01;
error_train = zeros(m, 1);
error_val = zeros(m, 1);
num = 50;
for i = 1:num
for j = 1:m
ind = randperm(m,j);%randperm(m,j) 返回一行从1到m的整数中的j个,而且这j个数也是不相同的
X_poly_rand = X_poly(ind,:);%随机选择训练集样本
y_rand = y(ind,:);
ind_val = randperm(m,j);
X_poly_val_rand = X_poly_val(ind_val,:);%随机选择交叉验证集样本
yval_val_rand = yval(ind_val,:);
[theta] = trainLinearReg(X_poly_rand, y_rand, lambda);
[J, grad] = linearRegCostFunction(X_poly_rand, y_rand, theta, 0);
[Jval, gradval] = linearRegCostFunction(X_poly_val_rand, yval_val_rand, theta, 0);
error_train(j) = error_train(j) + J;
error_val(j) = error_val(j) + Jval;
end
end
error_train = error_train/num;
error_val = error_val/num;
plot(1:m, error_train, 1:m, error_val);
title(sprintf('Polynomial Regression Learning Curve (lambda = %f)', lambda));
xlabel('Number of training examples')
ylabel('Error')
axis([0 13 0 100])
legend('Train', 'Cross Validation')
作为参考,图11显示了 λ = 0.01 λ= 0.01 λ=0.01的多项式回归所获得的学习曲线。由于样本的随机选择,每个人的图可能会略有不同。

四、MATLAB实现
4.1 ex5.m
%% Machine Learning Online Class
% Exercise 5 | Regularized Linear Regression and Bias-Variance
%
% Instructions
% ------------
%
% This file contains code that helps you get started on the
% exercise. You will need to complete the following functions:
%
% linearRegCostFunction.m
% learningCurve.m
% validationCurve.m
%
% For this exercise, you will not need to change any code in this file,
% or any other files other than those mentioned above.
%
%% Initialization
clear ; close all; clc
%% =========== Part 1: Loading and Visualizing Data =============
% We start the exercise by first loading and visualizing the dataset.
% The following code will load the dataset into your environment and plot
% the data.
%
% Load Training Data
fprintf('Loading and Visualizing Data ...\n')
% Load from ex5data1:
% You will have X, y, Xval, yval, Xtest, ytest in your environment
load ('ex5data1.mat');
% m = Number of examples
m = size(X, 1);
% Plot training data
plot(X, y, 'rx', 'MarkerSize', 10, 'LineWidth', 1.5);
xlabel('Change in water level (x)');
ylabel('Water flowing out of the dam (y)');
fprintf('Program paused. Press enter to continue.\n');
pause;
%% =========== Part 2: Regularized Linear Regression Cost =============
% You should now implement the cost function for regularized linear
% regression.
%
theta = [1 ; 1];
J = linearRegCostFunction([ones(m, 1) X], y, theta, 1);
fprintf(['Cost at theta = [1 ; 1]: %f '...
'\n(this value should be about 303.993192)\n'], J);
fprintf('Program paused. Press enter to continue.\n');
pause;
%% =========== Part 3: Regularized Linear Regression Gradient =============
% You should now implement the gradient for regularized linear
% regression.
%
theta = [1 ; 1];
[J, grad] = linearRegCostFunction([ones(m, 1) X], y, theta, 1);
fprintf(['Gradient at theta = [1 ; 1]: [%f; %f] '...
'\n(this value should be about [-15.303016; 598.250744])\n'], ...
grad(1), grad(2));
fprintf('Program paused. Press enter to continue.\n');
pause;
%% =========== Part 4: Train Linear Regression =============
% Once you have implemented the cost and gradient correctly, the
% trainLinearReg function will use your cost function to train
% regularized linear regression.
%
% Write Up Note: The data is non-linear, so this will not give a great
% fit.
%
% Train linear regression with lambda = 0
lambda = 0;
[theta] = trainLinearReg([ones(m, 1) X], y, lambda);
% Plot fit over the data
plot(X, y, 'rx', 'MarkerSize', 10, 'LineWidth', 1.5);
xlabel('Change in water level (x)');
ylabel('Water flowing out of the dam (y)');
hold on;
plot(X, [ones(m, 1) X]*theta, '--', 'LineWidth', 2) %[ones(m, 1) X]为12x2
hold off;
fprintf('Program paused. Press enter to continue.\n');
pause;
%% =========== Part 5: Learning Curve for Linear Regression =============
% Next, you should implement the learningCurve function.
%
% Write Up Note: Since the model is underfitting the data, we expect to
% see a graph with "high bias" -- Figure 3 in ex5.pdf
%
lambda = 0;
[error_train, error_val] = learningCurve([ones(m, 1) X], y, [ones(size(Xval, 1), 1) Xval], yval, lambda);
plot(1:m, error_train, 1:m, error_val);
title('Learning curve for linear regression')
legend('Train', 'Cross Validation')
xlabel('Number of training examples')
ylabel('Error')
axis([0 13 0 150])
fprintf('# Training Examples\tTrain Error\tCross Validation Error\n');
for i = 1:m
fprintf(' \t%d\t\t%f\t%f\n', i, error_train(i), error_val(i));
end
fprintf('Program paused. Press enter to continue.\n');
pause;
%% =========== Part 6: Feature Mapping for Polynomial Regression =============
% One solution to this is to use polynomial regression. You should now
% complete polyFeatures to map each example into its powers
%
p = 8;
% Map X onto Polynomial Features and Normalize
% 对训练集的特征向量 进行扩展为8个特征向量 并进行特征向量归一化
X_poly = polyFeatures(X, p);
[X_poly, mu, sigma] = featureNormalize(X_poly); % Normalize
X_poly = [ones(m, 1), X_poly]; % Add Ones
% Map X_poly_test and normalize (using mu and sigma)
% 对测试集的特征向量 进行扩展为8个特征向量 并进行特征向量归一化
X_poly_test = polyFeatures(Xtest, p);
X_poly_test = bsxfun(@minus, X_poly_test, mu);
X_poly_test = bsxfun(@rdivide, X_poly_test, sigma);
X_poly_test = [ones(size(X_poly_test, 1), 1), X_poly_test]; % Add Ones
% Map X_poly_val and normalize (using mu and sigma)
% 对验证测试集的特征向量 进行扩展为8个特征向量 并进行特征向量归一化
X_poly_val = polyFeatures(Xval, p);
X_poly_val = bsxfun(@minus, X_poly_val, mu);
X_poly_val = bsxfun(@rdivide, X_poly_val, sigma);
X_poly_val = [ones(size(X_poly_val, 1), 1), X_poly_val]; % Add Ones
fprintf('Normalized Training Example 1:\n');
fprintf(' %f \n', X_poly(1, :));
fprintf('\nProgram paused. Press enter to continue.\n');
pause;
%% =========== Part 7: Learning Curve for Polynomial Regression =============
% Now, you will get to experiment with polynomial regression with multiple
% values of lambda. The code below runs polynomial regression with
% lambda = 0. You should try running the code with different values of
% lambda to see how the fit and learning curve change.
%
lambda = 0;
[theta] = trainLinearReg(X_poly, y, lambda);
% Plot training data and fit
figure(1);
plot(X, y, 'rx', 'MarkerSize', 10, 'LineWidth', 1.5);
plotFit(min(X), max(X), mu, sigma, theta, p);
xlabel('Change in water level (x)');
ylabel('Water flowing out of the dam (y)');
title (sprintf('Polynomial Regression Fit (lambda = %f)', lambda));
figure(2);
[error_train, error_val] = learningCurve(X_poly, y, X_poly_val, yval, lambda);
plot(1:m, error_train, 1:m, error_val);
title(sprintf('Polynomial Regression Learning Curve (lambda = %f)', lambda));
xlabel('Number of training examples')
ylabel('Error')
axis([0 13 0 100])
legend('Train', 'Cross Validation')
fprintf('Polynomial Regression (lambda = %f)\n\n', lambda);
fprintf('# Training Examples\tTrain Error\tCross Validation Error\n');
for i = 1:m
fprintf(' \t%d\t\t%f\t%f\n', i, error_train(i), error_val(i));
end
fprintf('Program paused. Press enter to continue.\n');
pause;
%% =========== Part 8: Validation for Selecting Lambda =============
% You will now implement validationCurve to test various values of
% lambda on a validation set. You will then use this to select the
% "best" lambda value.
%
[lambda_vec, error_train, error_val] = validationCurve(X_poly, y, X_poly_val, yval);
close all;
plot(lambda_vec, error_train, lambda_vec, error_val);
legend('Train', 'Cross Validation');
xlabel('lambda');
ylabel('Error');
fprintf('lambda\t\tTrain Error\tValidation Error\n');
for i = 1:length(lambda_vec)
fprintf(' %f\t%f\t%f\n', ...
lambda_vec(i), error_train(i), error_val(i));
end
fprintf('Program paused. Press enter to continue.\n');
pause;
%Computing test set error
theta = trainLinearReg(X_poly, y, 3);
[error_test, grad] = linearRegCostFunction(X_poly_test, ytest, theta, 0);
fprintf('Compute Test Error (error_test = %f)\n\n', error_test);
五、Python实现
5.1 ex5.py
import numpy as np
import scipy.io as sio
import matplotlib.pylab as plt
import scipy.optimize as op
from numpy import linalg as la
# =========== Part 1: Loading and Visualizing Data =============
print('Loading and Visualizing Data ...')
datainfo = sio.loadmat('ex5data1.mat')
X = datainfo['X'][:, 0]
Y = datainfo['y'][:, 0]
Xtest = datainfo['Xtest'][:, 0]
Ytest = datainfo['ytest'][:, 0]
Xval = datainfo['Xval'][:, 0]
Yval = datainfo['yval'][:, 0]
m = np.size(X, 0)
plt.plot(X, Y, 'rx', ms=10, mew=1.5)
plt.xlabel('Change in water level (x)')
plt.ylabel('Water flowing out of the dam (y)')
plt.show()
_ = input('Press [Enter] to continue.')
# =========== Part 2 & 3: Regularized Linear Regression Cost and Gradient=============
# 线性回归损失函数
def linRegCostFunc(theta, x, y, lamb):
m = np.size(y, 0)
j = 1/(2*m)*(x.dot(theta)-y).T.dot(x.dot(theta)-y)+lamb/(2*m)*(theta[1:].dot(theta[1:]))#不需要正则化第一项theta0(即偏置单元)
return j
# 线性回归梯度函数
def linRegGradFunc(theta, x, y, lamb):
m = np.size(y, 0)
grad = np.zeros(np.shape(theta))
grad[0] = 1/m*(x.dot(theta)-y).dot(x[:, 0])
grad[1:] = 1/m*(x[:, 1:]).T.dot(x.dot(theta)-y)+lamb/m*theta[1:]
return grad
theta = np.array([1.0, 1.0])
j = linRegCostFunc(theta, np.vstack((np.ones((m,)), X)).T, Y, 1)#np.vstack:按垂直方向(行顺序)堆叠数组构成一个新的数组
grad = linRegGradFunc(theta, np.vstack((np.ones((m,)), X)).T, Y, 1)
print('Cost at theta = [1 ; 1]: %f \
\n(this value should be about 303.993192)' % j)
print('Gradient at theta = [1 ; 1]: [%f; %f] \
\n(this value should be about [-15.303016; 598.250744])' % (grad[0], grad[1]))
# =========== Part 4: Train Linear Regression =============
# 训练线性回归
def trainLinReg(x, y, lamb):
init_theta = np.zeros((np.size(x, 1),))
theta = op.fmin_cg(linRegCostFunc, init_theta, fprime=linRegGradFunc, maxiter=200, args=(x, y, lamb))
return theta
lamb = 0
theta = trainLinReg(np.vstack((np.ones((m,)), X)).T, Y, lamb)
# 绘制图像
plt.plot(X, Y, 'rx', ms=10, mew=1.5)
plt.plot(X, np.vstack((np.ones((m,)), X)).T.dot(theta), '--', lw=2)
plt.xlabel('Change in water level (x)')
plt.ylabel('Water flowing out of the dam (y)')
plt.show()
_ = input('Press [Enter] to continue.')
# =========== Part 5: Learning Curve for Linear Regression =============
# 学习曲线
def learningCurve(x, y, xval, yval, lamb):#绘制学习曲线,即交叉验证误差与训练误差随着样本数量的变化而变化
m = np.size(x, 0)
err_train = np.zeros((m,))
err_val = np.zeros((m,))
for i in range(m): #i取0-11之间的值
theta = trainLinReg(x[0:i+1, :], y[0:i+1], lamb) #x[0:i+1, :]取x的0-i行
err_train[i] = linRegCostFunc(theta, x[0:i+1, :], y[0:i+1], 0)
err_val[i] = linRegCostFunc(theta, xval, yval, 0)
return err_train, err_val
mval = np.size(Xval, 0)
err_train, err_val = learningCurve(np.vstack((np.ones((m,)), X)).T, Y \
,np.vstack((np.ones((mval,)), Xval)).T, Yval, lamb)
# 绘制图像
plt.plot(np.arange(m)+1, err_train, 'b-', label='Train')
plt.plot(np.arange(m)+1, err_val, 'r-', label='Cross Validation')
plt.axis([0, 13, 0, 150])
plt.legend(loc='upper right')
plt.title('Learning curve for linear regression')
plt.xlabel('Number of training examples')
plt.ylabel('Error')
plt.show()
print('Training Examples Train Error Cross Validation Error')
for i in range(m):
print('\t%d\t\t\t\t%f\t\t\t%f' % (i+1, err_train[i], err_val[i]))
_ = input('Press [Enter] to continue.')
# =========== Part 6: Feature Mapping for Polynomial Regression =============
# 多项式映射
def polyFeature(x, p):
m = np.size(x, 0)
x_poly = np.zeros((m, p))
for i in range(p):
x_poly[:, i] = np.power(x, i+1)
return x_poly
# 归一化处理
def featureNormalize(x):
mu = np.mean(x, 0)
sigma = np.std(x, 0, ddof=1)
x_norm = (x-mu)/sigma
return x_norm, mu, sigma
p = 8
X_p = polyFeature(X, p)
X_p, mu, sigma = featureNormalize(X_p)
X_poly = np.concatenate((np.ones((m, 1)), X_p), axis=1)
ltest= np.size(Xtest, 0)
X_p_test = polyFeature(Xtest, p)
X_p_test = (X_p_test-mu)/sigma
X_poly_test = np.concatenate((np.ones((ltest, 1)), X_p_test), axis=1)
lval = np.size(Xval, 0)
X_v_test = polyFeature(Xval, p)
X_v_test = (X_v_test-mu)/sigma
X_poly_val = np.concatenate((np.ones((lval, 1)), X_v_test), axis=1)
print('Normalized Training Example 1: \n', X_poly[0, :])
_ = input('Press [Enter] to continue.')
# =========== Part 7: Learning Curve for Polynomial Regression =============
# 曲线拟合
def plotFit(min_x, max_x, mu, sigma, p):
x = np.arange(min_x-15, max_x+25, 0.05)
x_p = polyFeature(x, p)
x_p = (x_p-mu)/sigma
l = np.size(x_p, 0)
x_poly = np.concatenate((np.ones((l, 1)), x_p), axis=1)
return x, x_poly.dot(theta)
lamb = 0
theta = trainLinReg(X_poly, Y, lamb)
x_simu, y_simu = plotFit(np.min(X), np.max(X), mu, sigma, p)
fig1 = plt.figure(1)
ax = fig1.add_subplot(111)
ax.plot(X, Y, 'rx', ms=10, mew=1.5)
ax.plot(x_simu, y_simu, '--', lw=2)
ax.set_xlabel('Change in water level (x)')
ax.set_ylabel('Water flowing out of the dam (y)')
fig1.suptitle('Polynomial Regression Fit (lambda = 0)')
err_train, err_val = learningCurve(X_poly, Y, X_poly_val, Yval, lamb)
fig2 = plt.figure(2)
ax2 = fig2.add_subplot(111)
ax2.plot(np.arange(m)+1, err_train, 'b', label='Train')
ax2.plot(np.arange(m)+1, err_val, 'r', label='Cross Validation')
ax2.set_xlabel('Number of training examples')
ax2.set_ylabel('Error')
handles2, labels2 = ax2.get_legend_handles_labels()
ax2.legend(handles2, labels2)
ax2.set_xlim([0, 13])
ax2.set_ylim([0, 100])
fig2.suptitle('PPolynomial Regression Learning Curve (lambda = 0)')
plt.show()
print('Polynomial Regression (lambda = 0)')
print('Training Examples\tTrain Error\tCross Validation Error')
for i in range(m):
print(' \t%d\t\t%f\t%f' % (i+1, err_train[i], err_val[i]))
_ = input('Press [Enter] to continue.')
# =========== Part 8: Validation for Selecting Lambda =============
def validationCurve(x, y, xval, yval):
lamb_vec = [0, 0.001, 0.003, 0.01, 0.03, 0.1, 0.3, 1, 3, 10]
err_train = np.zeros((len(lamb_vec,)))
err_val = np.zeros((len(lamb_vec,)))
for i in range(len(lamb_vec)):
lamb = lamb_vec[i]
theta = trainLinReg(x, y, lamb)
err_train[i] = linRegCostFunc(theta, x, y, 0)
err_val[i] = linRegCostFunc(theta, xval, yval, 0)
return lamb_vec, err_train, err_val
lambda_vec, err_train, err_val = validationCurve(X_poly, Y, X_poly_val, Yval)
plt.plot(lambda_vec, err_train, 'b', label='Train')
plt.plot(lambda_vec, err_val, 'r', label='Cross Validation')
plt.xlabel('lambda')
plt.ylabel('Error')
plt.legend(loc='upper right')
plt.show()
print('lambda\t\tTrain Error\tValidation Error')
for i in range(len(lambda_vec)):
print(' %f\t%f\t%f' % (lambda_vec[i], err_train[i], err_val[i]))
_ = input('Press [Enter] to continue.')
#计算测试集误差
theta = trainLinReg(X_poly, Y, 3);
error_test = linRegCostFunc(theta, X_poly_test, Ytest, 0);
print('Compute Test Error (error_test = %f)\n\n' %error_test);