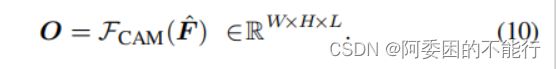【论文阅读】Regional Semantic Contrast and Aggregation for Weakly Supervised Semantic Segmentation
论文标题:
Regional Semantic Contrast and Aggregation for Weakly Supervised Semantic Segmentation
作者信息:

代码地址:
https://github.com/maeve07/RCA.git
Abstract
弱监督分割是一个非常具有挑战的任务。很多方法从单个图像或者图像对获得相对有限的语义标注信息。作者提出来使用弱标签的训练集数据进行丰富的语义信息的学习。提出了regional semantic contrast and aggregation (RCA) 模块,主要包括两个方面:
1.semantic contrast:让网络对大量不同类别的区域的信息进行学习,以使有一个整体的pattern的理解(数据集级别的learning方法)
2.semantic aggregation: 捕获不同的上下文献信息去扩充语义表示(如何使用semantic contrast学到的信息)
Introduction
(图一简述了该论文主要的motivation)
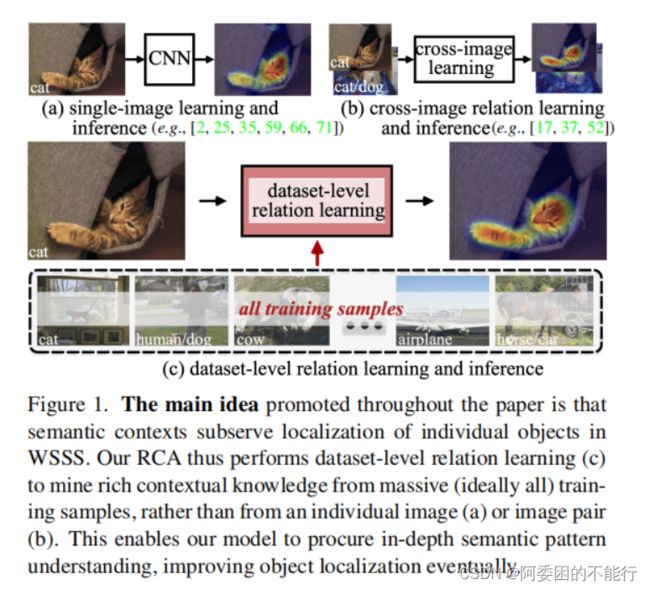
在WSSS发展中,:
- 首先是 class activation mapping (CAM) ,但是它们对物体的区域的估计不够完整也很稀疏,另外仅使用单个图片的信息用于物体定位,忽略图像间的信息。(单个图像不行)
- 另外一些方法尝试利用图像对(pairwise or quadruplet) 中的有限图片,但也无法保证对整体语义模式的理解(cannot guarantee a sufficient understanding of holistic semantic patterns in the entire dataset)。(图像对也不行)
上述两种均缺乏有效的监督信号,并且比较占用计算代价。
作者提出了RCA,从整体的数据集的角度进行更全面的语义模式的学习与推理。(此处作者又列举了一些优点和做法,如下:
- RCA prefers region-aware representations that are more efficient and robust to noises.
- For each pseudo region, RCA establishes its relations to regions in all other images to facilitate dataset-level semantic context learning.
- We associate RCA with a continuously-updated memory bank.)
RCA主要从Semantic contrast 和Semantic aggregation两个方面展开的,其中:
- Semantic contrast:lets the model learn to discriminate all possible object regions in the dataset。
- Semantic aggregation :allows the model to gather dataset-level contextual knowledge to yield more meaningful object representations.
二者的作用:
- Semantic contrast helps the network to learn more structured object embedding space from a holistic view。
- Semantic aggregation focuses on improving feature representations of each image by collecting diverse semantic contexts.
Method
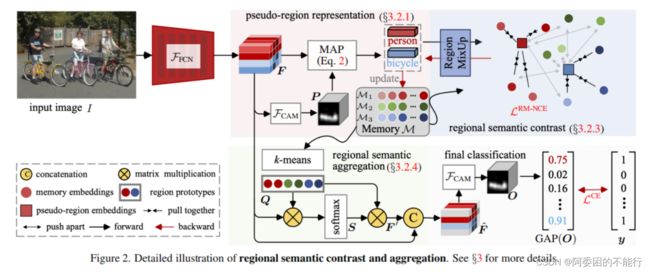
(图2为论文的总体结构图)
3.1. Problem Statement
Task Setup: Training a classification network first for identifying object regions corresponding to each category, which are then re-
fined to produce pseudo segmentation labels as the supervision of a semantic segmentation network。
Previous Solutions to WSSS 最近的一些方法从与训练的全卷积网络中抽出 class-ware attention maps,一些论文证明了产生定位的效果和CAM一致(该论文基于此展开)。对于mini-batch的图像 I I I,它产生class-ware attention maps的方式如下:
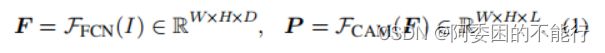
其中 F F C N F_{FCN} FFCN指骨架网络(VGG,Resnet)等, F C A M F_{CAM} FCAM 是常见的CAM的提取方法,可以理解成一个1x1卷积。
对于得到的map P l P_l Pl,一般经由全局池化获得多标签的分类score。
3.2. Regional Semantic Contrast and Aggregation
3.2.1 Pseudo-Region Representation
根据公式(1)中的 P P P对 F F F加入masked average pooling (MAP),生成嵌入向量:
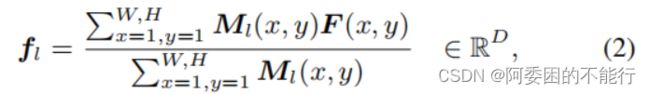
主要是根据 P l P_l Pl的均值设定阈值 u u u用于mask 池化,将特征图F中的关于类别l的强activate 像素生成Representation。
3.2.2 Pseudo-Region Memory Bank
作者为RCA建立了一个非参数和动态存储库来存储数据集级的区域语义信息,称为mermory bank,M。M中包含L个字典,每个字典对应一类标签类别,即:
![]()
其中的每一个 M l M_l Ml代表图像 I I I中的第l个类别的区域性的representation,记为 m l m_l ml。内存库会在反向传播过程中不断更新 m l m_l ml,即:

仅当 I I I中第l个类别出现,且对应的 p l p_l pl大于阈值时,才会更新 m l m_l ml,否则不更新。
Memory Mechanism Discussion (该方法的优势):
- Memory bank 比较容易进行划分,能够分别压缩每个训练样本中的每个潜在语义假设(即伪区域嵌入),并能够在弱标记的视觉数据中很好地编码每个类别的不同语义模式。
- 更新方案,能够使semantic contrast获得较为一致的memory feature,并提供较为精准全面的语义表示。
总体来公式(3)积累了由图像分类器在不同的训练时期产生的每个对象区域的所有中间状态。训练到最后, m l m_l ml的表征能力将逐渐提升,后面用于semantic aggregation。
3.2.3 Regional Semantic Contrast (RSC)
采用对比学习的思想,对于公式2中给定的 f l f_l fl,训练使其同类别 { m l + ∈ M l } \{m_l^+\in{M_l}\} {ml+∈Ml}的相似性越高高越好,不同类别 { m l − ∈ M l } \{m_l^-\in{M_l}\} {ml−∈Ml}的相似性越低越好。
利用NCE损失函数:
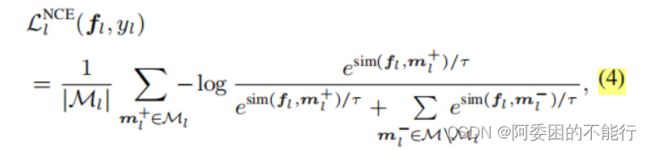
由于弱监督的标签比较弱且存在噪声,使用了region mixup去增强学习的representations 的鲁棒性。即对于I中的每个区域l,通过将其与另一个小批量图像中的区域ll线性组合来创建一个混合区域。
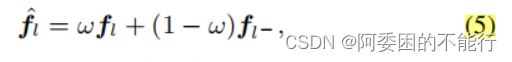
这里 l l l和 l − l- l−表示不同的类别。 w w w为服从 β \beta β分布的系数。应用mixup后的对比学习的损失函数为:

公式(6)鼓励网络从mix region中学习相似性,并从不完美的label中学习鲁棒性。
3.2.4 Regional Semantic Aggregation (RSA)
(对获得representations进行利用)
memory bank中的信息比较的富足和冗余,直接利用也计算量比较大。作者对bank中的每个类别 l l l对应的 M l M_l Ml使用k-means均值聚类获得K个原型reprentation,记为 Q l Q_l Ql。多个 Q l Q_l Ql用于解释类内特征的不同。将bank中所有的一类的 Q l Q_l Ql连接在一起,得到 Q = [ Q 1 , . . . , Q L ] Q=[Q_1,...,Q_L] Q=[Q1,...,QL]。将公式(1)中的 F F F和获得的reprentation Q Q Qconcat并做softmax处理获得affinity matrix S:

每个S都反应了F的每一行和Q中的每一列的标准化相似性(S的作用)。基于affinity matrix S,计算扩充feature reprentation F ′ F^{'} F′:

将获得的enrich reprentation F ′ F^{'} F′和原本的 F F F concat:
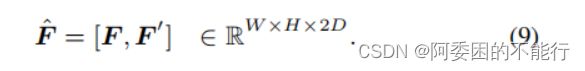
其中 F F F能够表示intra-image local contexts , F ′ F^{'} F′能够表示 inter-image global contexts,那么所获得总F的大概就有能表示这个意思。
3.2.5 Class Activation Map Prediction
把公式(9)获得的总的F输入到公式(1)的 F C A M F_{CAM} FCAM(本质是一个1×1的卷积)中去: