1.CephFS文件存储核心概念
1.1.CephFS文件存储简介
官方文档:docs.ceph.com/en/pacific/…
传统的文件存储通常使用的是NAS存储,通过NFS协议来实现,NFS类型的文件存储可以同时共享给多个客户端使用,传输协议简单,只要有网络就可以实现。
对于存储而言,高可用性是必须具备的,一旦存储宕机,就会影响应用程序的使用,而NAS存储最典型的缺点就是单点故障。
在Ceph分布式存储系统中有关于文件存储的存储类型,称之为CephFS,CephFS是一个符合POSIX的文件系统,构建在Ceph对象存储Rados之上,CephFS可以为各种应用程序提供最先进的、多用途、高可用性和高性能的文件存储。
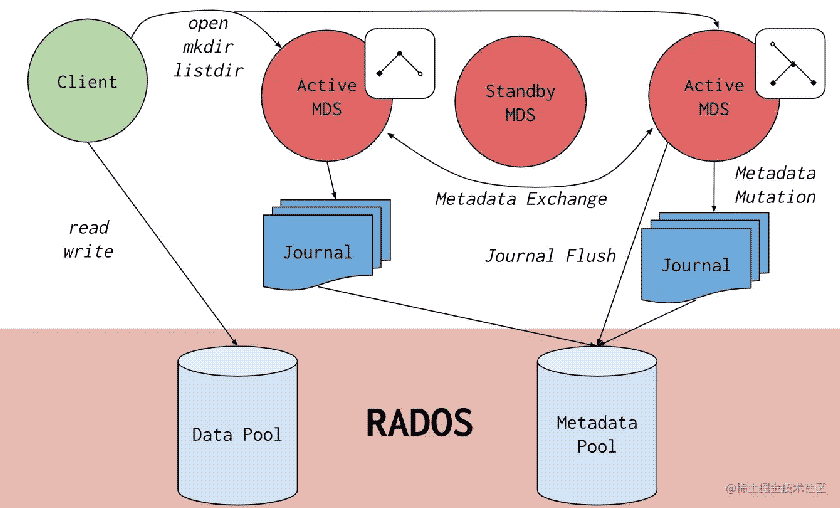
CephFS文件系统至少需要一个MDS(Metadata Server组件)来存储文件系统的元数据信息,因此在使用CephFS文件存储之前,首先要在集群中部署MDS组件,我们希望CephFS文件存储具备高可用性,所以MDS组件一般都会在集群中部署多个,大多数情况下都是三个MDS组件。
CephFS支持用户级别和内核级别的挂载使用,可扩展性极高,并且可以同时让多个Client客户端进行读写。
简而言之:CephFS文件存储就是提供类似NFS服务的共享存储系统,相当于基于NFS的分布式文件存储系统,多个客户端可以同时去挂载这个文件存储系统,并且还可以提供高可靠服务。
1.2.CephFS文件存储架构
CephFS文件系统的核心组件有:
MDS:MDS组件主要用于保存文件的元数据信息,会单独存放在一个Pool资源池中。
MDS支持高可用性,默认采用主备模式,也可以配置成多主模式。
Client:客户端。
RADOS:CephFS也是基于RADOS来实现文件存储的,CephFS文件存储中的文件数据与文件的元数据都是单独在不同的Pool资源池中存储的。
Ceph集群如果想要实现CephFS文件存储,首先需要在集群中准备MDS组件,MDS组件主要是来保存文件存储中文件的元数据信息,一般会部署三个MDS组件,形成高可用模式,其中一个MDS的Active状态提供服务,另外两个都是Standby的状态,当Active状态的MDS挂掉后,Standby状态的MDS之间会就进行选举,选举成功的MDS节点就会成为集群中的Active。
MDS组件会将文件的元数据信息写在Journal日志中,最终Journal日志中的文件元数据信息会写入到一个Metadata的Pool资源池中,所有的MDS节点都会连接这个Pool资源池,并且MDS各节点之间会交换元数据信息,当Active状态的MDS组件挂掉了,选举出来的MDS会从Metadata Pool资源池获取整个集群中所有文件的元数据信息。
CephFS会将用户写入的文件数据与文件的元数据分开存放在不同的Pool资源池中,将数据与元数据分开存储。
Client客户端可以直接在存放数据的Pool资源池中写入文件数据,写入的文件依旧会被拆分成多个Object对象文件,这些Object对象文件写入到PG中,最后通过CRUSH算法存储在多个OSD中。
1.3.CephFS文件系统的应用场景与特性
应用场景:
- 为K8S集群Pod资源提供持久化存储。
- 多个服务器同时挂载一个文件系统,同时进行读写。
CephFS文件系统多MDS的优势及特点:
- 当元数据默认的单个MDS成为瓶颈时,配置多个活跃的MDS守护进程,提升集群性能。
- 多个活跃的MDS有利于性能提升。
- 多个活跃的MDS可以实现MDS负载均衡。
- 多个活跃的MDS可以实现多租户资源隔离。
- 它能够将文件系统树分割成子树,每个子树可以交给特定的MDS进行权威管理,从而达到了随着元数据服务器数量的增加,集群性能线性地扩展。
- 每个子树都是基于元数据在给定目录树中的热动态创建的。
- 一旦创建了子树,它的元数据就被迁移到一个未加载的MDS。
- 后续客户端对先前授权的MDS的请求被转发。
2.在Ceph集群中部署MDS组件
1.在集群所有节点都安装mds组件 yum -y install ceph-mds 2.将所有的ceph节点都部署mds组件形成高可用集群 [root@ceph-node-1 ~]# cd /data/ceph-deploy/ [root@ceph-node-1 ceph-deploy]# ceph-deploy mds create ceph-node-1 ceph-node-2 ceph-node-3

3.查看集群状态
[root@ceph-node-1 ceph-deploy]# ceph -s
cluster:
id: a5ec192a-8d13-4624-b253-5b350a616041
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-node-1,ceph-node-2,ceph-node-3 (age 19h)
mgr: ceph-node-1(active, since 19h), standbys: ceph-node-2, ceph-node-3
mds: 3 up:standby
osd: 6 osds: 6 up (since 18h), 6 in (since 18h)
rgw: 1 daemon active (ceph-node-1)
task status:
data:
pools: 7 pools, 320 pgs
objects: 252 objects, 161 KiB
usage: 6.1 GiB used, 54 GiB / 60 GiB avail
pgs: 320 active+clean
可以看到集群中已经有3个MDS组件了,但是状态都处于standby,那是因为集群中还没有创建CephFS文件系统,导致MDS组件无法选举。
3.在Ceph集群中创建一个CephFS文件存储系统
一个Cephfs文件存储系统至少需要两个Rados资源池,一个资源池用于存放文件数据,另一个资源池用于存放文件的元数据信息,如果元数据资源池中的任何数据丢失,都有可能导致整个文件系统无法访问。
对元数据资源池建议使用较低延迟的OSD,例如可以使用SSD硬盘的OSD,元数据资源池的延迟直接会影响在客户端中文件系统操作的延迟。
3.1.为CephFS文件存储系统创建Pool资源池
创建好这两个Pool资源池后,只能为一个cephfs文件存储系统使用,如果集群中需要创建多个cephfs文件系统,则需要创建多个元数据池和数据池,一个元数据资源池和数据资源池只能为一个Cephfs文件系统提供使用。
1.创建元数据资源池 [root@ceph-node-1 ~]# ceph osd pool create cephfs_metadata 16 16 pool 'cephfs_metadata' created 2.创建数据资源池 [root@ceph-node-1 ~]# ceph osd pool create cephfs_data 16 16 pool 'cephfs_data' created 3.查看创建的资源池 [root@ceph-node-1 ~]# ceph osd lspools 1 ceph-rbd-data 2 .rgw.root 3 default.rgw.control 4 default.rgw.meta 5 default.rgw.log 6 default.rgw.buckets.index 7 default.rgw.buckets.data 8 cephfs_metadata 9 cephfs_data
3.2.创建CephFS文件系统
命令格式:ceph fs new {cephfs_name} {metadata_pool} {data_pool}
1.创建cephfs文件存储
[root@ceph-node-1 ~]# ceph fs new cephfs-storage cephfs_metadata cephfs_data
new fs with metadata pool 8 and data pool 9
2.查看创建的cephfs文件存储
[root@ceph-node-1 ~]# ceph fs ls
name: cephfs-storage, metadata pool: cephfs_metadata, data pools: [cephfs_data ]
[root@ceph-node-1 ~]# ceph fs volume ls
[
{
"name": "cephfs-storage"
}
]
3.3.再次观察Ceph集群的状态
[root@ceph-node-1 ~]# ceph -s
cluster:
id: a5ec192a-8d13-4624-b253-5b350a616041
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-node-1,ceph-node-2,ceph-node-3 (age 24h)
mgr: ceph-node-1(active, since 24h), standbys: ceph-node-2, ceph-node-3
mds: cephfs-storage:1 {0=ceph-node-1=up:active} 2 up:standby #当创建完cephfs文件系统后,mds组件自动选举一个mds组件为active状态,其余为standby状态
osd: 6 osds: 6 up (since 23h), 6 in (since 23h)
rgw: 1 daemon active (ceph-node-1)
task status:
data:
pools: 9 pools, 352 pgs
objects: 274 objects, 164 KiB
usage: 6.1 GiB used, 54 GiB / 60 GiB avail
pgs: 352 active+clean
4.内核级别挂载CephFS文件系统
挂载的操作文档:docs.ceph.com/en/pacific/…
4.1.无需认证的方式挂载CephFS文件系统
1)在客户端中创建挂载目录
[root@ceph-node-1 ~]# mkdir /cephfs_data
2)使用内核级别挂载Cephfs文件系统
CephFS系统可以理解为也是一个磁盘,类型是ceph的类型,直接可以通过mount命令进行挂载。
命令格式:mount -t ceph {monitor_addr}:/ /{path} -o name=admin
挂载时最好指定所有monitor组件的地址,否则当有一个monitor组件产生问题,就会影响挂载。
1.首先确认mount是否支持ceph类型的文件系统,如果不支持则去安装ceph-common包 [root@ceph-node-1 ~]# which mount.ceph /usr/sbin/mount.ceph 2.挂载cephfs文件系统 [root@ceph-node-1 ~]# mount -t ceph 192.168.20.20:6789,192.168.20.21:6789,192.168.20.22:6789:/ /cephfs_data/ -o name=admin #这个admin用户是ceph集群默认的用户,不需要指定secret key 3.查看是否挂载成功 [root@ceph-node-1 ~]# df -hT /cephfs_data/ 文件系统 类型 容量 已用 可用 已用% 挂载点 192.168.20.20:6789,192.168.20.21:6789,192.168.20.22:6789:/ ceph 17G 0 17G 0% /cephfs_data 4.此时就可以在挂载目录中写入数据了。
4.2.使用认证方式挂载CephFS文件系统
1.获取admin用户的Key
[root@ceph-node-1 ~]# cat /etc/ceph/ceph.client.admin.keyring
[client.admin]
key = AQBIWUhiEmaFOBAA6Jr6itUeHiLVVOeYFVpRog==
caps mds = "allow *"
caps mgr = "allow *"
caps mon = "allow *"
caps osd = "allow *"
2.通过认证方式挂载CephFS文件系统
[root@ceph-node-1 ~]# mount -t ceph 192.168.20.20:6789,192.168.20.21:6789,192.168.20.22:6789:/ /cephfs_data/ -o name=admin,secret=AQBIWUhiEmaFOBAA6Jr6itUeHiLVVOeYFVpRog==
3.查看是否挂载成功
[root@ceph-node-1 ~]# df -hT /cephfs_data/ 文件系统 类型 容量 已用 可用 已用% 挂载点 192.168.20.20:6789,192.168.20.21:6789,192.168.20.22:6789:/ ceph 17G 0 17G 0% /cephfs_data
4.设置开机自动挂载
[root@ceph-node-1 ~]# vim /etc/fstab 192.168.20.20:6789,192.168.20.21:6789,192.168.20.22:6789:/ /cephfs_data ceph name=admin,secret=AQBIWUhiEmaFOBAA6Jr6itUeHiLVVOeYFVpRog== 0 0
也可以将用户的Key写入到一个文件中,然后引用这个文件,如下所示:
1.将key写入到一个文件中 [root@ceph-node-1 ~]# ceph-authtool -p /etc/ceph/ceph.client.admin.keyring > admin.key [root@ceph-node-1 ~]# chmod 600 admin.key 2.挂载时引用这个Key文件 [root@ceph-node-1 ~]# mount -t ceph 192.168.20.20:6789,192.168.20.21:6789,192.168.20.22:6789:/ /cephfs_data/ -o name=admin,secretfile=/root/admin.key 3.开机自动挂载 192.168.20.20:6789,192.168.20.21:6789,192.168.20.22:6789:/ /cephfs_data ceph name=admin,secretfile=/root/admin.key 0 0
5.用户空间挂载CephFS文件系统
1.安装ceph-fuse客户端 [root@ceph-node-1 ~]# yum -y install ceph-fuse 2.创建挂载点 [root@ceph-node-1 ~]# mkdir /cephfuse-data 3.使用fuse挂载 [root@ceph-node-1 ~]# ceph-fuse -n client.admin -m 192.168.20.20:6789,192.168.20.21:6789,192.168.20.22:6789 /cephfuse-data/ 2022-04-03 23:37:18.794 7f5574ca7f80 -1 init, newargv = 0x5615fadddb50 newargc=9ceph-fuse[31903]: starting ceph client ceph-fuse[31903]: starting fuse 4.查看挂载的文件系统 ceph-fuse[31903]: starting fuse [root@ceph-node-1 ~]# df -HT /cephfuse-data/ 文件系统 类型 容量 已用 可用 已用% 挂载点 ceph-fuse fuse.ceph-fuse 19G 0 19G 0% /cephfuse-data
6.查看CephFS的状态
[root@ceph-node-1 ~]# ceph fs status cephfs-storage
以上就是Ceph集群CephFS文件存储核心概念及部署使用详解的详细内容,更多关于Ceph CephFS文件存储部署的资料请关注脚本之家其它相关文章!