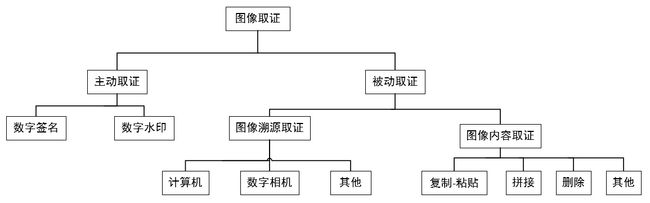
图像取证技术

(1)图像克隆被动取证
这种方法针对的是同一张图像本身的复制粘贴篡改方法。由于图像采集的多样性,同一张图像中的噪声、纹理完全相同的区域几乎不可能出现,而图像克隆篡改方法将导致图像中出现了两个完全相同的区域,因此该类取证方法的关键在于寻找图像中两个完全相同的区域。
(2)图像拼接被动取证
这种方法针对的是不同图像的复制-粘贴篡改方法,该方法产生的篡改图像其统计特性会发生改变,并且边缘特征也会发生变化。通过滤波器对图像进行处理,凸显图像边缘特征,从而发现真实区域与篡改区域之间的边缘差异。
(3)重采样被动取证
一般对图像进行克隆或拼接等篡改操作以后,伪造者会对合成区域进行缩放、旋转,使其尺寸或者形态更符合视觉感受。对图像尺寸的缩放即重采样,通常采用插值算法来增加(上采样)或减少(下采样)图像像素,这就会改变图像原有的统计特性。目前关于重采样的被动取证可分为两类:一类是根据像素相关性进行检测,另一类方法是根据插值区域像素的二阶导数进行检测。
(4)模糊被动取证
模糊是图像篡改中一种常见的润饰方式,能使篡改区域边缘更加自然,在视觉上不引起人注意。当前针对模糊操作的取证方式一般是根据图像模糊操作滤波器的特性来进行判断。不同模糊方法其像素值之间往往有迹可循,根据这些规律,可以判断出图像是否采用了模糊操作以及模糊操作的具体方法。
(5)光照不一致性被动取证
在同一地点的不同时间点,相机拍摄的物体所受光线的角度不同。基于光照不一致性的被动取证依据的是:随机选取的两张图像中物体所受光照不同,在进行合成时,篡改区域和背景区域很难达到光照一致的效果。目前关于光照不一致性被动取证一般分类两类:一类是通过分析图像中的光源位置,判定图像光源是否一致;另一类是寻找图像中的阴影,判断阴影几何形状是否满足图像中的几何特性。
(6)基于模式噪声被动取证
图像内容篡改中的基于模式噪声被动取证和图像来源被动取证中的方法不同,它的目的是检测同一幅图像中模式噪声不一致的区域。人们在篡改图像时,往往只关注图像的RGB域而忽略了图像的噪声域,不同图像的噪声域不同,根据这一点可以判断出图像是否经过篡改操作。
(7)面向JPEG图像篡改的被动取证
JPEG是当前主流的图像压缩标准,现在的数码相机大都支持输出JPEG图像,而网络上的图片多数也是JPEG格式,所以针对JPEG格式图像的取证非常有意义。但是JPEG压缩是有损的,图像的信息会丢失,给取证带来难度。针对篡改手段和检测依据的不同,目前方法大致分为两种:双JPEG压缩检测和块效应不一致性检测。
(8) 基于深度学习的图像被动取证
随着深度学习技术在各种计算机视觉和图像处理任务中的成功应用,最新的一些技术也采用了深度学习方法来进行图像修改识别。深度学习方法可以将图像被动取证看作目标检测问题、异常检测问题。早期的深度学习图像取证方法通过将传统滤波方法与深度学习模型结合,取得了不错的效果。近几年,更多学者希望能够利用深度学习方法的自适应性,使深度学习模型能够自动提取有效的特征,但受限于数据集太小以及篡改方法多样,这仍是深度学习方法在图像被动取证领域中的一大挑战。
当前的图像篡改大多都是对图像内容进行修改,如拼接、复制-粘贴、移除等,如JPEG压缩、模糊、图像增强等篡改方法往往被用来掩盖图像内容刚修改痕迹。
来源:https://zhuanlan.zhihu.com/p/110093560
被动的检测技术:不会对原图造成影响
参考:谁动了我的图片
Image splicing:从一个真实图像复制部分区域然后粘贴它们到其他图片。
Copy-move:复试和粘贴部分区域在相同的图像内。
Remove:从一张图像中删除部分区域,然后修复它。
Copy-move:一幅图像中检测到大块相同的内容
技术手段:基于稀疏特征点(如SIFT)和基于图像块的图像匹配算法
传感器噪声取证:成像传感器的模式噪声(相机噪声)。
由于成像传感器所用的硅阵列的制作瑕疵,阵列中的每个元素都携带有不同幅度的成像噪声。这种噪声会呈现在相机所拍的每张照片中,只是由于其幅度非常小,所以人眼是观察不出来的。而通过特定的信号处理算法,可以把照片的内容过滤掉,只留下潜在的模式噪声。下图就是放大处理过的一台相机的模式噪声。这种噪声看起来就像是随机的二维码,这种随机码可以用来唯一表示一台相机,所以称之为相机指纹。
像素重采样检测:像素插值,(缩放、旋转图片)造出新的像素。
常见的插值算法有(双线性插值、双三次插值)等。无论哪种插值算法都会使插值产生的空挡位置与其四周的原像素产生一种相关性,利用这种特有的相关性就可以判断一副图像是否经过缩放、旋转等操作了。 (缩小可以吗?)
第一幅图放大30%后得到第二幅图,利用最大期望(Expectation Maximization)算法估计图中每个像素点被插值产生的概率得到第三幅图。第三幅图中包含着与放大倍数相关的周期性,这种周期性通过傅里叶分析可以在频域图(第四幅)中观察到,其现象就是箭头所指的4个高频亮点。这种取证方法通过分析邻近像素间的相关性可以检测由于图像缩放而产生的像素插值

反射不一致性检测
基于几何约束的取证方法:物理场景成像所用的小孔相机模型遵从摄影几何的规律,所有违反这些规律的图像都是不可能出现的。
光照一致性检测
估计照片中各个物体所处的光照环境并判别其一致性:通过检测照片中的(人脸),检测(人脸)关键点,拟合三维(人脸)模型,估计光照参数,计算光照参数间的差异性等一系列流程来自动判别图片的真假。
深度学习应用
参考:深度学习在图像取证的进展与趋势
数字图像取证的出发点是通过提取数字图像周期中留下的固有痕迹进行分析和理解数字图像的操作历史。
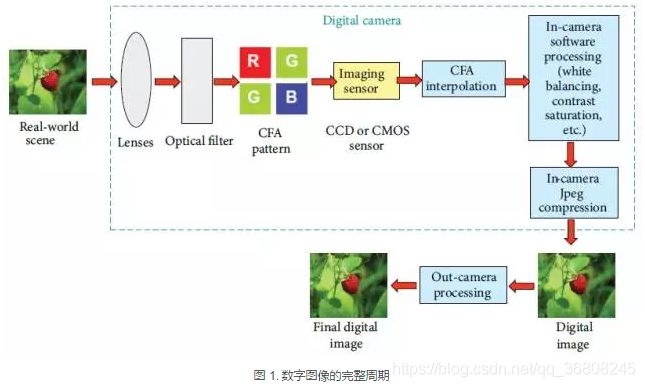
数字图像完整周期的三个部分每一部分都会留下不同的操作痕迹(指纹特性),即获取指纹、编码指纹、编辑指纹。
获取指纹:镜头特性、传感器特性、CFA模式
编码指纹:JPEG压缩以及多重JPEG压缩检测
编辑指纹:基于信号处理和基于物理/几何的技术。
信号处理技术:复制粘贴检测、重采样检测、对比度增强检测、线裁剪检测等;
利用光线/阴影进行拼接检测;
利用几何关系的一致性检测拼接处理
深度学习应用于图像取证领域大致可分为三个层次。
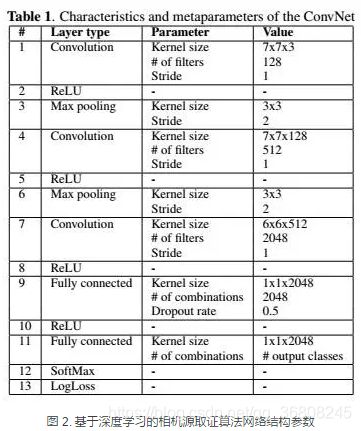
1.简单的迁移,即直接将CV领域常用的CNN网络结构引入到图像取证领域。
取证领域比较常用的网络结构为AlexNet,(AlexNet网络结构相较于其他网络结构复杂度相对较低并且性能较好,对于解决数据集少的取证问题有更好的尝试性条件。)
典型案例:Luca Baroffio, Luca Bond等[3]发表的文章“Camera Identification With Deep Convolutional Networks”, 文章提出用深度学习解决取证中的相机源辨别问题。
2.尝试对网络输入的修改,添加预处理层(或信号增强层)放大类间差别。
原因:由取证问题和CV问题的本质区别所驱使。
取证问题:识别、分类、定位问题
类别之间的形态差异是极其微小的,类间差别以微弱信号的形式存在
比如对于常见的双重JPEG压缩取证,需要解决的问题是区分一副图像是经历过一次JPEG压缩之后的图像,还是经历过两次JPEG压缩之后的图像。在两次压缩使用的压缩因子(压缩因子小于等于90)一致的前提条件下,内容相同的两幅图像的DCT域统计类间差别小于0.4%(数据来源于Detecting Double JPEG Compression With the Same Quantization Matrix[4])。
典型案例:Jiansheng Chen, Xiangui Kang等[5]发表的文章“Median Filtering Forensics Based on Convolutional Neural Networks”,根据论文报告的试验结果,预处理层的添加对检测准确率有了7.22个百分点的提升。
中值滤波图像取证:对图像是否经历过中值滤波操作进行判定。在图像经过篡改之后,为了去除篡改引入图像中的特性,通常会对图像进行中值滤波操作,从而隐藏篡改操作痕迹。图像是否经历过中值滤波操作对于判断图像篡改历史提供了重要线索。传统的图像中值滤波取证算法对于小尺寸图像和做过压缩后处理的图像性能有待提高。
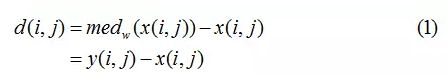 对应下图的滤波层
对应下图的滤波层

3.对网络结构的修改,提出适合于取证问题的网络结构。
典型案例:Belhassen Bayar, Matthew C. Stamm[6]发表的文章“A Deep Learning Approach To Universal Image Manipulation Detection Using A New Convolutional Layer”。
利用新的卷积结构捕获图像操作过程中引入的图像临近像素之间相关关系的变化,同时尽可能压缩图像内容对于图像操作引入的像素相关关系的影响。
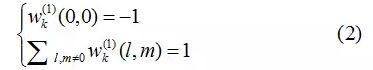 w为新的卷积核,w(0,0)为卷积核中心位置的数值。新的卷积结构只使用在第一层卷积中,从而实现图像预处理卷积核的自动学习。
w为新的卷积核,w(0,0)为卷积核中心位置的数值。新的卷积结构只使用在第一层卷积中,从而实现图像预处理卷积核的自动学习。
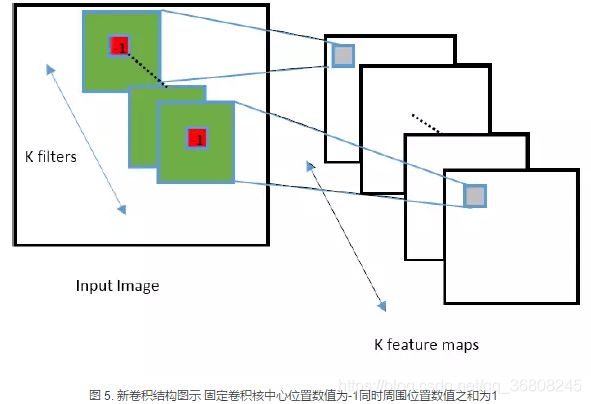
对卷积核的属性进行了限制,使得网络结构可以自动学习预测误差滤波器集合,从而抑制图像内容的影响同时捕获操作特性。
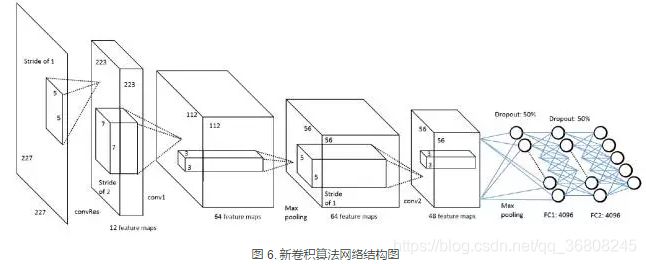
重获取图像取证
Peng P Y, Rong R N, Yao Z.【 Recapture Image Forensics Based On Laplacian Convolutional Neural Networks[C]// International Workshop on Digital-forensics and Watermaking, 2016】提出拉普拉斯卷积神经网络算法检测重获取图像。
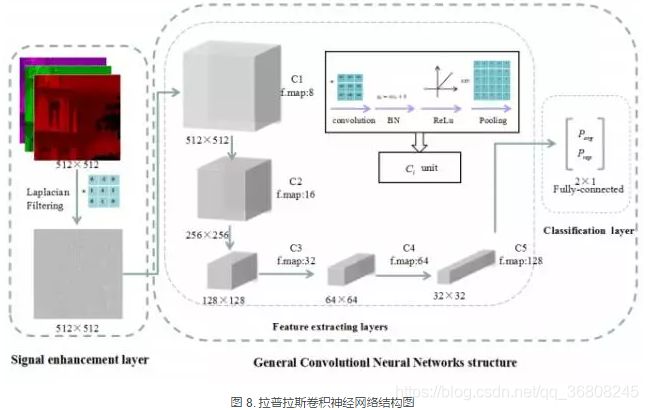
首先利用信号增强层放大重获取噪声信号(预处理),然后利用5个卷积层进行特征提取,最后使用全连接层作为特征分类层。
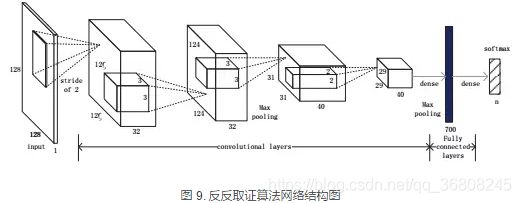
反反取证
Jing J Y, Yi F Z, Jian H Y, et al.【 A Multi-purpose Image Counter-anti-forensic Method Using Convolutional Neural Networks[C] // International Workshop on Digital-forensics and Watermaking, 2016】关注了四类反取证问题:JPEG压缩、中值滤波、重采样、对比度增强,
隐写分析
隐写分析是针对隐写问题发展而来的一种技术手段,目的是检测目标中是否包含隐藏信息。待检测目标中嵌入隐藏信息的比特率越低,意味着隐藏信息量越少,检测难度越大。传统的隐写分析都是基于特征提取加特征分类的两段论方案,为了更全面的刻画待测目标中的“微弱”信号,维度不断增加的高维特征被提出,例如Rich Models特征。特征分类方面为了加速高维隐写特征的分类,Fridrich课题组提出了针对隐写分析的特定分类器,集成分类器[10]。深度学习的发展为隐写分析提供了一种新的思路。Qian Y, Dong J等[11]首次将深度学习算法应用于隐写分析领域,并基于隐写分析的领域知识提出高斯激活函数,取得了和传统方案性能相当的检测效果;Guanshuo Xu, Yun-Qing Shi等[12]设计了一种新的网络结构,在网络结构中添加了绝对值层、BN层和全局pooling层,也取得了较好的检测效果。基于以上工作,两者又相继推出了后续工作。Qian Y, Dong J等[13,14]融合迁移学习的方法进一步提高了算法性能;Guanshuo Xu, Yun-Qing Shi等[15]提出了基于集成学习和集成分类的方案。
[10] Kodovsky J, Fridrich J, Holub V. Ensemble Classifiers for Steganalysis of Digital Media[J]. IEEE Transactions on Information Forensics & Security, 2012
[11] Qian Y, Dong J, Wang W, et al. Deep learning for steganalysis via convolutional neural networks[C]//SPIE/IS&T Electronic Imaging. International Society for Optics and Photonics, 2015
[12] Xu G, Wu H Z, Shi Y Q. Structural Design of Convolutional Neural Networks for Steganalysis[J]. IEEE Signal Processing Letters, 2016
[13] Qian Y, Dong J, Wang W, et al. Learning Representations for Steganalysis from Regularized CNN Model with Auxiliary Tasks[C]//Proceedings of the 2015 International Conference on Communications, Signal Processing, and Systems. Springer Berlin Heidelberg, 2016
[14] Qian Y, Dong J, Wang W, et al. Learning and transferring representations for image steganalysis using convolutional neural network[C]//Image Processing (ICIP), 2016 IEEE International Conference on. IEEE, 2016
[15] Xu G, Wu H Z, Shi Y Q. Ensemble of CNNs for Steganalysis: An Empirical Study[C]//Proceedings of the 4th ACM Workshop on Information Hiding and Multimedia Security. ACM, 2016
作者的问题总结:
1.网络的深度,浅层的网络结构已然可以得到较好的实验结果。当然网络的加深会对实验结果略有提升,但是并不能和增加层数带来的计算复杂度的提升成比例。
2.预处理操作并不是对于所有取证问题都适用,预处理操作在放大噪声信号的同时也相应的丢失了部分原始信息,对于深度学习数据驱动型算法而言,这些丢失的原始信息对于算法性能的影响比重如何暂时还无定论,所以预处理操作添加与否还需具体情况具体分析。
相关数据集
作者:陈振 相关研究:http://fcst.ceaj.org/EN/Y2019/V13/I5/721#
链接:https://www.zhihu.com/question/45555137/answer/441194586
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。1. 中国科学院自动化研究所:CASIA v1.0/v2.0 TIDE:
(1)原作者(链接已失效):CASIA Image Tampering Detection Evaluation Database,只提供原图、篡改图,不包含GroundTruth;
(2)Kaggle(链接可用):casia-dataset-kaggle,提供原图、篡改图;
(3)Github用户@namtpham提供(链接可用):CASIA v1.0-namtpham,CASIA v2.0-namtpham;作者在原图、篡改图的基础上,提供了GroundTruth;另外,@namtpham将原图、篡改图放在了他的谷歌云上,为防止部分朋友无法下载;下面给出百度网盘地址:CASIA v1.0,CASIA v2.0;具体如何使用参照namtpham提供的README;(感谢@青椒提供的信息)
2. Pawel korus
Realistic Tampering Dataset, 高分辨,含原图、篡改图、groundtruth;
(1)作者提供(需Google Drive):Realistic Tampering Dataset
(2)百度网盘(链接可用):链接:https://pan.baidu.com/s/10GWwcC4fzp8YqO2renZv_A 提取码:r1fx
图像篡改检测
参考:https://zhuanlan.zhihu.com/p/56165819
- 大部分深度学习算法离不开传统算法的原理,基本上都源于数字图像的成像过程留下的模式噪声;
- 目前算法基本上可以同时解决检测篡改(Detection )、篡改定位(Localization );
- 深度学习鉴定复制-黏贴(Copy-Move)的算法比较少,关键是如何让算法认识到寻找两个相似物体【原图复制粘贴】,基本上都是研究接片检测(Image splicing);
- 目前的主要算法可以分为:传统手工特征统计学习模型;机器学习半自动化模型;深度学习全自动模型(End-to-End);