【AI视野·今日CV 计算机视觉论文速览 第246期】Thu, 21 Apr 2022
AI视野·今日CS.CV 计算机视觉论文速览
Thu, 21 Apr 2022
Totally 71 papers
上期速览✈更多精彩请移步主页

Interesting:
*****户外单图重光照方法, 基于单图深度估计结果作为几何引导,并利用图像空间的光线对齐层将深度图转换为3D表示来缓解遮挡对于光迹追踪的影响。(from adobe)

https://dgriffiths.uk/outcast
序列点云学习综述, 动态的时间变化的点云信息进行表示,学习和下游任务。主要适用于自动驾驶等动态领域的点云表示与学习,可以基于卷积、图网络 RNN以及点云网络等架构进行学习。(from 纽约城市大学)
现有数据集:
各种序列点云表示方法:
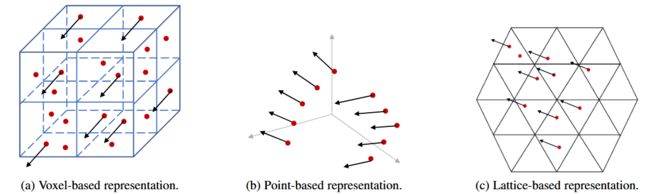
内窥镜3D重建, 基于光度立体视觉与单目深度估计(from Universidad de Zaragoza 萨拉哥萨大学)
PP-Matting, 高分辨率分支+语义分支的高精度抠图(from 百度 )
https://github.com/PaddlePaddle/PaddleSeg
SPG-IM,高精度抠图 (from oppo )
GazeOnce多人视线估计, 单阶段多人视线估计模型。(from 鹏城实验室 )

数据集生成方法,通过已标注的视线结果替换人脸眼部构建数据集:
音乐引导的视频生成, 将按帧切分的音频频谱图直接映射到style干的隐空间,随后利用clip来进一步加强构建音频与视频关系,生成器学习如何从声音获取隐变量,并最终逐帧生成对应视频(from 高丽大学)
Daily Computer Vision Papers
| Sim-2-Sim Transfer for Vision-and-Language Navigation in Continuous Environments Authors Jacob Krantz, Stefan Lee 视觉和语言导航 VLN 的最新工作提出了两种具有不同现实主义的环境范式,标准 VLN 设置建立在导航被抽象化的拓扑环境上,以及代理必须使用低级动作导航连续 3D 环境的 VLN CE 设置。尽管共享高级任务甚至底层指令路径数据,但 VLN CE 的性能明显落后于 VLN。在这项工作中,我们通过将代理从 VLN 的抽象环境转移到 VLN CE 的连续环境来探索这一差距。我们发现这种 sim 2 sim 传输非常有效,比 VLN CE 中的现有技术提高了 12 成功率。虽然这证明了这个方向的潜力,但转移并没有完全保留代理在抽象设置中的原始性能。 |
| One-Class Model for Fabric Defect Detection Authors Hao Zhou, Yixin Chen, David Troendle, Byunghyun Jang 作为纺织行业缓慢、不一致、容易出错和昂贵的人工操作员的替代品,自动化和准确的织物缺陷检测系统的需求量很大。以前的努力集中在某些类型的织物或缺陷上,这不是一个理想的解决方案。在本文中,我们提出了一种新颖的一类模型,该模型能够检测不同织物类型上的各种缺陷。我们的模型利用精心设计的 Gabor 滤波器组来分析织物纹理。然后,我们利用先进的深度学习算法自动编码器,从 Gabor 滤波器组的输出中学习一般特征表示。最后,我们开发了一个最近邻密度估计器来定位潜在缺陷并将它们绘制在织物图像上。我们通过在各种类型的织物(如平纹织物、图案织物和旋转织物)上对其进行测试,证明了所提出模型的有效性和稳健性。 |
| Residual Mixture of Experts Authors Lemeng Wu, Mengchen Liu, Yinpeng Chen, Dongdong Chen, Xiyang Dai, Lu Yuan Mixture of Experts MoE 能够有效地扩大视觉转换器的规模。但是,它需要禁止计算资源来训练大型 MoE 转换器。在本文中,我们提出了 Residual Mixture of Experts RMoE,这是一种用于 MoE 视觉转换器在下游任务(例如分割和检测)上的有效训练管道。 RMoE 与上限 MoE 训练取得了可比较的结果,而与下限非 MoE 训练管道相比,仅引入了少量的额外训练成本。我们的关键观察结果支持效率,MoE 变压器的权重可以分解为与输入无关的核心和与输入相关的残差。与权重核心相比,权重残差可以用更少的计算资源进行有效训练,例如对下游数据进行微调。我们表明,与当前的教育部培训管道相比,我们获得了可比的结果,同时节省了 30 多个培训成本。 |
| De-biasing facial detection system using VAE Authors Vedant V. Kandge, Siddhant V. Kandge, Kajal Kumbharkar, Prof. Tanuja Pattanshetti 基于 AI ML 的系统中的偏见是一个普遍存在的问题,AI ML 系统中的偏见可能会对社会产生负面影响。系统存在偏见的原因有很多。偏差可能是由于我们用于解决问题的算法,也可能是由于我们使用的数据集,其中有一些特征被过度表示。在人脸检测系统中,主要是由于数据集导致的偏差。有时模型只学习数据中过度表示的特征,而忽略数据中的稀有特征,从而导致偏向于那些过度表示的特征。在现实生活中,这些有偏见的系统对社会是危险的。所提出的方法使用最适合从数据集中学习潜在特征潜在变量的生成模型,并通过使用这些学习到的特征模型尝试减少由于系统中的偏差而存在的威胁。在算法的帮助下,可以消除数据集中存在的偏差。 |
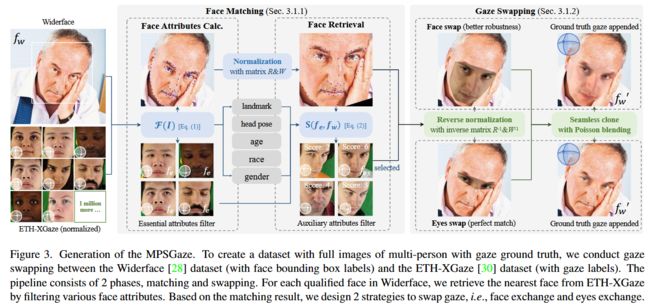
| GazeOnce: Real-Time Multi-Person Gaze Estimation Authors Mingfang Zhang, Yunfei Liu, Feng Lu 基于外观的注视估计旨在从单个图像预测 3D 眼睛注视方向。虽然最近基于深度学习的方法已经展示了出色的性能,但它们通常假设每个输入图像中都有一张经过校准的人脸,并且不能实时输出多人注视。然而,对于现实世界的应用来说,同时对野外多人进行注视估计是必要的。在本文中,我们提出了第一个阶段的端到端注视估计方法 GazeOnce,它能够同时预测图像中多个人脸 10 的注视方向。此外,我们设计了一个复杂的数据生成管道,并提出了一个新的数据集 MPSGaze,其中包含具有 3D 凝视基本事实的多人的完整图像。实验结果表明,与最先进的方法相比,我们的统一框架不仅提供了更快的速度,而且还提供了更低的注视估计误差。 |
| THORN: Temporal Human-Object Relation Network for Action Recognition Authors Mohammed Guermal, Rui Dai, Francois Bremond 大多数动作识别模型将人类活动视为单一事件。然而,人类活动往往遵循一定的等级制度。事实上,许多人类活动都是组合性的。此外,这些动作主要是人类对象交互。在本文中,我们建议通过利用定义动作的一组交互来识别人类动作。在这项工作中,我们提出了一个端到端网络 THORN,它可以利用重要的人类对象和对象对象交互来预测动作。该模型建立在 3D 骨干网络之上。我们模型的关键组件是 1 用于建模对象的对象表示过滤器。 2 一个对象关系推理模块,用于捕获对象关系。 3 用于预测动作标签的分类层。为了展示 THORN 的稳健性,我们在 EPIC Kitchen55 和 EGTEA Gaze 这两个最大和最具挑战性的第一人称和人类对象交互数据集上对其进行了评估。 |
| STAU: A SpatioTemporal-Aware Unit for Video Prediction and Beyond Authors Zheng Chang, Xinfeng Zhang, Shanshe Wang, Siwei Ma, Wen Gao 视频预测旨在通过对视频中复杂的时空动态进行建模来预测未来的帧。然而,大多数现有方法仅以独立的方式对视频的时间信息和空间信息进行建模,而没有充分探索这两个术语之间的相关性。在本文中,我们通过探索视频中显着的时空相关性,提出了一种用于视频预测及其他方面的时空感知单元 STAU。一方面,从空间状态中学习运动感知注意力权重,以帮助聚合时间域中的时间状态。另一方面,外观感知注意力权重是从时间状态中学习的,以帮助聚合空间域中的空间状态。通过这种方式,时间信息和空间信息可以在两个域中极大地相互感知,在此期间,时空感受野也可以大大拓宽,以实现更可靠的时空建模。实验不仅在传统的视频预测任务上进行,还对视频预测之外的其他任务进行,包括早期动作识别和对象检测任务。 |
| GIMO: Gaze-Informed Human Motion Prediction in Context Authors Yang Zheng, Yanchao Yang, Kaichun Mo, Jiaman Li, Tao Yu, Yebin Liu, Karen Liu, Leonidas J. Guibas 预测人体运动对于辅助机器人和 AR VR 应用至关重要,在这些应用中,与人类的交互需要安全和舒适。同时,准确的预测取决于对场景上下文和人类意图的理解。尽管许多作品研究了场景感知人类运动预测,但由于缺乏以自我为中心的观点来揭示人类意图以及运动和场景的有限多样性,后者在很大程度上还没有被充分探索。为了缩小差距,我们提出了一个大规模的人体运动数据集,该数据集提供高质量的身体姿势序列、场景扫描以及以眼睛注视作为推断人类意图的代理的以自我为中心的视图。通过使用惯性传感器进行动作捕捉,我们的数据收集不依赖于特定场景,这进一步增强了从我们的受试者观察到的运动动态。我们对利用眼睛注视和各种最先进的架构进行以自我为中心的人体运动预测的好处进行了广泛的研究。此外,为了充分发挥凝视的潜力,我们提出了一种新颖的网络架构,可以实现凝视和运动分支之间的双向通信。由于来自注视的意图信息和运动调制的去噪注视特征,我们的网络在所提出的数据集上实现了人体运动预测的最佳性能。 |
| DAM-GAN : Image Inpainting using Dynamic Attention Map based on Fake Texture Detection Authors Dongmin Cha, Daijin Kim 深度神经的进步最近为图像修复领域带来了显着的图像合成性能。生成对抗网络 GAN 的适应尤其加速了高质量图像重建的重大进展。然而,尽管已经提出了许多著名的基于 GAN 的网络用于图像修复,但在生成过程中仍然会在合成图像中出现像素伪影或颜色不一致,这通常被称为假纹理。为了减少由假纹理导致的像素不一致混乱,我们引入了一个基于 GAN 的模型,使用动态注意力图 DAM GAN。我们提出的 DAM GAN 专注于检测虚假纹理和产品动态注意力图,以减少生成器中特征图的像素不一致性。 |
| Hephaestus: A large scale multitask dataset towards InSAR understanding Authors Nikolaos Ioannis Bountos, Ioannis Papoutsis, Dimitrios Michail, Andreas Karavias, Panagiotis Elias, Isaak Parcharidis 合成孔径雷达 SAR 数据和干涉 SAR InSAR 产品尤其是地球观测数据的最大来源之一。 InSAR 提供有关各种地球物理过程和地质学以及人造结构岩土特性的独特信息。然而,利用大量 InSAR 数据和深度学习方法来提取此类知识的应用程序数量有限。主要障碍是缺乏经过整理和注释的大型 InSAR 数据集,该数据集的创建成本很高,并且需要一个在 InSAR 数据解释方面经验丰富的跨学科专家团队。在这项工作中,我们努力创建并提供同类中第一个手动注释数据集,该数据集由 19,919 个单独的 Sentinel 1 干涉图组成,这些干涉图在全球 44 座不同的火山中采集,分为 216,106 个 InSAR 补丁。 |
| FenceNet: Fine-grained Footwork Recognition in Fencing Authors Kevin Zhu, Alexander Wong, John McPhee 目前加拿大奥运会击剑队的数据分析主要由教练和分析师手动完成。由于围栏中高度重复但动态和微妙的运动,手动数据分析可能效率低下且不准确。我们提出 FenceNet 作为一种新颖的架构,可以自动对击剑中的细粒度步法技术进行分类。 FenceNet 将 2D 姿势数据作为输入,并使用基于骨架的动作识别方法对动作进行分类,该方法结合了时间卷积网络以捕获时间信息。我们在击剑步法数据集 FFD 上训练和评估 FenceNet,其中包含 10 名击剑手执行 6 种不同的步法动作,每 652 个视频重复 10 11 次。 FenceNet 在 10 倍交叉验证下达到了 85.4 的准确率,其中每个击剑手都被排除在测试集之外。该精度与当前最先进的方法 JLJA 86.3 相差 1 倍以内,该方法从骨架数据、深度视频和惯性测量单元中选择和融合设计的特征。 BiFenceNet 是 FenceNet 的一种变体,它通过两个独立的网络捕获人类运动的双向性,达到 87.6 的准确度,优于 JLJA。由于 FenceNet 和 BiFenceNet 都不需要来自可穿戴传感器的数据,与 JLJA 不同,它们可以直接应用于大多数击剑视频,使用 2D 姿势数据作为从现成的 2D 人体姿势估计器中提取的输入。 |
| PP-Matting: High-Accuracy Natural Image Matting Authors Guowei Chen, Yi Liu, Jian Wang, Juncai Peng, Yuying Hao, Lutao Chu, Shiyu Tang, Zewu Wu, Zeyu Chen, Zhiliang Yu, Yuning Du, Qingqing Dang, Xiaoguang Hu, Dianhai Yu 自然图像抠图是一项基本且具有挑战性的计算机视觉任务。它在图像编辑和合成中有许多应用。最近,基于深度学习的方法在图像抠图方面取得了很大的进步。但是,它们中的大多数都需要用户提供的 trimap 作为辅助输入,这限制了现实世界中的抠图应用。尽管已经提出了一些无 trimap 的方法,但与基于 trimap 的方法相比,抠图质量仍然不能令人满意。如果没有 trimap 引导,抠图模型容易受到前景背景模糊的影响,并且还会在过渡区域产生模糊的细节。在这项工作中,我们提出了 PP Matting,这是一种无 trimap 架构,可以实现高精度的自然图像抠图。我们的方法应用了一个高分辨率细节分支 HRDB,它在保持特征分辨率不变的情况下提取前景的细粒度细节。此外,我们提出了一个语义上下文分支 SCB,它采用语义分割子任务。它可以防止由于语义上下文丢失导致的局部歧义的细节预测。此外,我们对两个众所周知的基准组合 1k 和区别 646 进行了广泛的实验。结果证明了 PP Matting 优于以前的方法。此外,我们对我们的人体抠图方法进行了定性评估,显示了其在实际应用中的出色表现。 |
| A Mobile Food Recognition System for Dietary Assessment Authors eymanur Akt , Marwa Qaraqe, Haz m Kemal Ekenel 食物识别是各种应用的一项重要任务,包括管理健康状况和帮助视障人士。几项食物识别研究都集中在通用类型的食物或特定菜系上,然而,关于中东菜系的食物识别仍未探索。因此,在本文中,我们专注于开发一种移动友好的、以中东美食为重点的食品识别应用程序,用于辅助生活。为了实现低延迟、高精度的食品分类系统,我们选择使用 Mobilenet v2 深度学习模型。由于某些食物比其他食物更受欢迎,因此使用的中东食物数据集中每个类别的样本数量相对不平衡。为了弥补这个问题,数据增强方法应用于代表性不足的类。实验结果表明,使用 Mobilenet v2 架构来完成这项任务在准确性和内存使用方面都是有益的。 |
| HRPose: Real-Time High-Resolution 6D Pose Estimation Network Using Knowledge Distillation Authors Qi Guan, Zihao Sheng, Shibei Xue 实时 6D 对象姿态估计对于许多现实世界的应用至关重要,例如机器人抓取和增强现实。为了实时从 RGB 图像中实现准确的对象姿态估计,我们提出了一种有效且轻量级的模型,即高分辨率 6D 姿态估计网络 HRPose。我们采用高效且小型的 HRNetV2 W18 作为特征提取器,以减少计算负担,同时生成准确的 6D 姿势。与最先进的模型相比,我们的 HRPose 只有 33 倍的模型大小和更低的计算成本,实现了可比的性能。此外,通过输出和特征相似性蒸馏将知识从大型模型转移到我们提出的 HRPose,我们的 HRPose 的性能在有效性和效率上得到了提高。 |
| Video Moment Retrieval from Text Queries via Single Frame Annotation Authors Ran Cui, Tianwen Qian, Pai Peng, Elena Daskalaki, Jingjing Chen, Xiaowei Guo, Huyang Sun, Yu Gang Jiang 视频时刻检索旨在找到由给定自然语言查询描述的视频时刻部分的开始和结束时间戳。完全监督的方法需要完整的时间边界注释才能获得有希望的结果,这是昂贵的,因为注释者需要观察整个时刻。弱监督方法仅依赖于配对视频和查询,但性能相对较差。在本文中,我们更深入地研究了注释过程,并提出了一种称为 Glance annotation 的新范式。这种范式只需要一个随机帧的时间戳,我们称之为一瞥,在完全监督的对应物的时间边界内。我们认为这是有益的,因为与弱监督相比,增加了微不足道的成本,但提供了更多的性能潜力。在glance annotation设置下,我们提出了一种基于对比学习的基于Glance Annotation ViGA的视频时刻检索方法。 ViGA 将输入视频切割成剪辑,并在剪辑和查询之间进行对比,其中一目了然的高斯分布权重分配给所有剪辑。 |
| A Probabilistic Time-Evolving Approach to Scanpath Prediction Authors Daniel Martin, Diego Gutierrez, Belen Masia 人类视觉注意力是一个复杂的现象,已经研究了几十年。在其中,扫描路径预测的特定问题提出了挑战,尤其是由于观察者间和内部的可变性以及其他原因。此外,大多数现有的扫描路径预测方法都集中在优化先前的注视点预测。在这项工作中,我们提出了一种基于贝叶斯深度学习的概率时间演化方法来预测扫描路径。我们使用基于 Kullback Leibler 散度和动态时间规整的新型时空损失函数优化我们的模型,同时考虑扫描路径的空间和时间维度。 |
| Epistemic Uncertainty-Weighted Loss for Visual Bias Mitigation Authors Rebecca S Stone, Nishant Ravikumar, Andrew J Bulpitt, David C Hogg 深度神经网络极易受到视觉数据中学习偏差的影响。尽管已经提出了各种方法来减轻这种偏差,但大多数方法都需要明确了解训练数据中存在的偏差才能减轻这种偏差。我们认为探索完全不知道存在任何偏见但能够识别和减轻偏见的方法的相关性。此外,我们建议使用具有认知不确定性加权损失函数的贝叶斯神经网络来动态识别单个训练样本中的潜在偏差并在训练期间对其进行加权。我们发现受偏见影响的样本与较高的认知不确定性之间存在正相关。 |
| Attentive Dual Stream Siamese U-net for Flood Detection on Multi-temporal Sentinel-1 Data Authors Ritu Yadav, Andrea Nascetti, Yifang Ban 由于气候和土地利用变化,近年来洪水等自然灾害不断增加。及时可靠的洪水检测和测绘有助于应急响应和灾害管理。在这项工作中,我们提出了一个使用双向 SAR 采集的洪水检测网络。所提出的分割网络有一个编码器解码器架构,带有两个用于洪水前后图像的连体编码器。使用注意块融合和增强网络的特征图,以实现对洪水区域的更准确检测。我们提出的网络在公开可用的 Sen1Flood11 基准数据集上进行评估。该网络的性能优于现有的最先进的单时洪水检测方法 6 IOU。 |
| Cyber-Forensic Review of Human Footprint and Gait for Personal Identification Authors Kapil Kumar Nagwanshi 人类足迹具有一组独特的脊线,任何其他人都无法比拟,因此它可以用于不同的身份证件,例如出生证明、印度生物识别系统 AADHAR 卡、驾驶执照、PAN 卡和护照。在犯罪现场有很多情况下,被告必须四处走动并留下鞋印和赤脚印,因此,从识别罪犯中恢复脚印非常重要。基于足迹的生物识别技术是一种相当新的个人识别技术。指纹、视网膜、虹膜和人脸识别是人员考勤记录最有用的方法。这一次,世界面临着全球恐怖主义的问题。识别恐怖分子是一项挑战,因为他们的生活和公民一样有规律。他们的软目标包括国防、硅和纳米技术芯片制造单位、制药行业等特殊利益行业。他们假装自己是宗教人士,所以寺庙和其他圣地,即使是在市场上也是他们的目标。这些是人们可以快速获得足迹的地方。步态本身足以预测嫌疑人的行为。 |
| Utilizing unsupervised learning to improve sward content prediction and herbage mass estimation Authors Paul Albert, Mohamed Saadeldin, Badri Narayanan, Brian Mac Namee, Deirdre Hennessy, Aisling H. O Connor, Noel E. O Connor, Kevin McGuinness 草地物种组成估计是一项繁琐的工作。草本植物必须在田间采集,手动分离成成分,干燥并称重以估计物种组成。使用神经网络的深度学习方法已在之前的工作中使用,通过仅从牧场的图片中估计生物量信息来提出更快、更具成本效益的替代方案。然而,深度学习方法难以推广到遥远的地理位置,需要进一步收集数据以在不同的气候条件下重新训练和发挥最佳性能。在这项工作中,我们通过在训练神经网络时减少对真实 GT 图像的需求来增强深度学习解决方案。 |
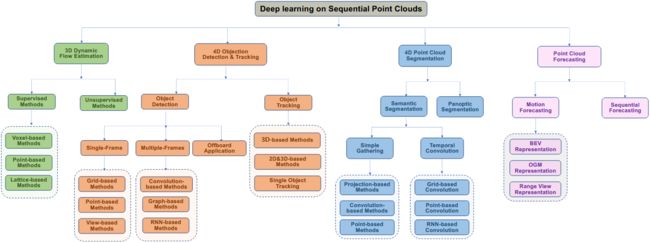
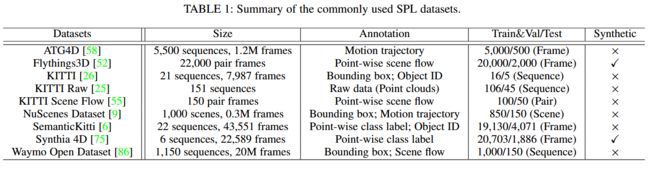
| Sequential Point Clouds: A Survey Authors Haiyan Wang, Yingli Tian 点云已经引起了越来越多的研究关注以及现实世界的应用。但是,其中许多应用程序,例如自动驾驶和机器人操作实际上是基于顺序点云,即四个维度,因为静态点云数据所能提供的信息仍然有限。最近,研究人员在顺序点云上投入了越来越多的精力。本文对基于深度学习的顺序点云研究方法进行了广泛的回顾,包括动态流估计、对象检测跟踪、点云分割和点云预测。本文进一步总结和比较了审查方法在公共基准数据集上的定量结果。 |
| NFormer: Robust Person Re-identification with Neighbor Transformer Authors Haochen Wang, Jiayi Shen, Yongtuo Liu, Yan Gao, Efstratios Gavves 人员重新识别旨在跨不同的摄像机和场景检索高度变化的环境中的人员,其中鲁棒和有区别的表示学习至关重要。大多数研究都考虑从单个图像中学习表示,忽略它们之间的任何潜在交互。然而,由于内部身份差异很大,忽略这种交互通常会导致异常特征。为了解决这个问题,我们提出了一个 Neighbor Transformer Network,或 NFormer,它显式地对所有输入图像之间的交互进行建模,从而抑制异常特征并导致整体上更稳健的表示。由于对大量图像之间的交互进行建模是一项具有很多干扰因素的艰巨任务,因此 NFormer 引入了两个新颖的模块:Landmark Agent Attention 和 Reciprocal Neighbor Softmax。具体来说,Landmark Agent Attention 通过低秩分解和特征空间中的一些地标有效地建模图像之间的关系图。此外,Reciprocal Neighbor Softmax 实现了对相关而非所有邻居的稀疏关注,这减轻了不相关表示的干扰并进一步减轻了计算负担。在四个大型数据集的实验中,NFormer 达到了新的技术水平。 |
| Self-supervised Learning for Sonar Image Classification Authors Alan Preciado Grijalva, Bilal Wehbe, Miguel Bande Firvida, Matias Valdenegro Toro 自监督学习已被证明是一种无需大型标记数据集即可学习图像表示的强大方法。对于水下机器人而言,设计计算机视觉算法以提高感知能力(例如声纳图像分类)具有极大的兴趣。由于声纳成像的机密性和解释声纳图像的难度,创建公共大型标记声纳数据集来训练监督学习算法具有挑战性。在这项工作中,我们研究了三种自我监督学习方法 RotNet、去噪自动编码器和 Jigsaw 在不需要人工标签的情况下学习高质量声纳图像表示的潜力。我们在现实生活中的声纳图像数据集上展示预训练和迁移学习结果。我们的结果表明,在所有三种方法的几个镜头迁移学习设置中,自我监督预训练产生的分类性能与监督预训练相当。 |
| Logarithmic Morphological Neural Nets robust to lighting variations Authors Guillaume Noyel LHC , Emile Barbier Renard LHC , Michel Jourlin LHC , Thierry Fournel LHC 形态神经网络允许在知道所需输出图像的情况下学习结构化函数的权重。然而,这些网络本质上对具有光学原因(例如光强度变化)的图像中的照明变化并不鲁棒。在本文中,我们介绍了一种形态学神经网络,它对光照变化具有这种鲁棒性。它基于最近的对数数学形态学 LMM 框架,即用对数图像处理 LIP 模型定义的数学形态学。该模型具有 LIP 加法定律,可在图像中模拟光强度的变化。我们特别学习了对这些变化具有鲁棒性的 LMM 算子的结构函数,即 LIP 加性 Asplund 距离的映射。 |
| NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video: Dataset, Methods and Results Authors Ren Yang, Radu Timofte, Meisong Zheng, Qunliang Xing, Minglang Qiao, Mai Xu, Lai Jiang, Huaida Liu, Ying Chen, Youcheng Ben, Xiao Zhou, Chen Fu, Pei Cheng, Gang Yu, Junyi Li, Renlong Wu, Zhilu Zhang, Wei Shang, Zhengyao Lv, Yunjin Chen, Mingcai Zhou, Dongwei Ren, Kai Zhang, Wangmeng Zuo, Pavel Ostyakov, Vyal Dmitry, Shakarim Soltanayev, Chervontsev Sergey, Zhussip Magauiya, Xueyi Zou, Youliang Yan Pablo Navarrete Michelini, Yunhua Lu, Diankai Zhang, Shaoli Liu, Si Gao, Biao Wu, Chengjian Zheng, Xiaofeng Zhang, Kaidi Lu, Ning Wang, Thuong Nguyen Canh, Thong Bach, Qing Wang, Xiaopeng Sun, Haoyu Ma, Shijie Zhao, Junlin Li, Liangbin Xie, Shuwei Shi, Yujiu Yang, Xintao Wang, Jinjin Gu, Chao Dong, Xiaodi Shi, Chunmei Nian, Dong Jiang, Jucai Lin, Zhihuai Xie, Mao Ye, Dengyan Luo, Liuhan Peng, Shengjie Chen, Xin Liu, Qian Wang, Xin Liu, Boyang Liang, Hang Dong, Yuhao Huang, Kai Chen, Xingbei Guo, Yujing Sun, Huilei Wu, Pengxu Wei, Yulin Huang, Junying Chen, Ik Hyun Lee, Sunder Ali Khowaja, Jiseok Yoon 本文回顾了 NTIRE 2022 压缩视频的超分辨率和质量增强挑战赛。在本次挑战赛中,我们提出了 LDV 2.0 数据集,其中包括 LDV 数据集 240 个视频和 95 个附加视频。这个挑战包括三个轨道。 Track 1 旨在增强 HEVC 以固定 QP 压缩的视频。 Track 2 和 Track 3 同时针对 HEVC 压缩视频的超分辨率和质量增强。它们分别需要 x2 和 x4 超分辨率。这三个赛道共吸引了 600 多个注册。在测试阶段,8支队伍、8支队伍和12支队伍分别向1、2、3赛道提交了最终成绩。所提出的方法和解决方案衡量了压缩视频的超分辨率和质量增强的最新技术。 |
| Attention in Attention: Modeling Context Correlation for Efficient Video Classification Authors Yanbin Hao, Shuo Wang, Pei Cao, Xinjian Gao, Tong Xu, Jinmeng Wu, Xiangnan He 由于使用了透视上下文,注意力机制显着提高了视频分类神经网络的性能。然而,当前对视频注意力的研究通常侧重于采用上下文的特定方面,例如通道、时空或全局上下文来细化特征,而在计算注意力时忽略了它们的潜在相关性。这导致不完全的上下文利用,因此具有性能改进有限的弱点。为了解决这个问题,本文提出了一种高效的注意力 AIA 方法来进行元素特征细化,该方法研究了将通道上下文插入时空注意力学习模块(称为 CinST)及其反向变体(称为为 STinC。具体来说,我们将视频特征上下文实例化为沿特定轴聚合的动态,具有全局平均和最大池操作。 AIA 模块的工作流程是,第一个注意块使用一种上下文信息来指导针对另一个上下文的第二个注意的门控权重计算。此外,注意力单元中的所有计算操作都作用于池化维度,这导致计算成本增加很少 0.02 。为了验证我们的方法,我们将其密集地集成到两个经典的视频网络主干中,并在几个标准视频分类基准上进行了广泛的实验。 |
| Adaptive Non-linear Filtering Technique for Image Restoration Authors S. K. Satpathy, S. Panda, K. K. Nagwanshi, S. K. Nayak, C. Ardil 从任何处理过的图像中去除噪声非常重要。应以保留图像重要信息的方式去除噪声。本文提出了一种基于决策的非线性图像消除算法,用于消除图像中的带线、下降线、标记、带丢失和脉冲。该算法同时执行两个操作,即检测损坏像素和评估新像素以替换损坏像素。可以在不破坏边缘和细节的情况下去除这些伪影。然而,当噪声过多时,受限的窗口大小会降低中值运算的效率,在这种情况下,所提出的算法会自动切换到均值滤波。从均方误差MSE、峰值信噪比PSNR、信噪比改进的SNRI、噪声衰减PONA百分比和像素损坏百分比POSP等方面分析了算法的性能。这与已经在使用的标准算法进行了比较,并提出了改进的算法性能。 |
| Image Restoration in Non-Linear Filtering Domain using MDB approach Authors S. K. Satpathy, S. Panda, K. K. Nagwanshi, C. Ardil 本文提出了一种基于非线性Minmax Detector Based MDB滤波器的图像恢复新技术。图像增强的目的是从损坏的图像中重建真实图像。图像采集的过程经常导致退化,数字化图像的质量变得比原始图像差。图像退化可能是由于在原始图像中添加了不同类型的噪声。图像噪声可以建模为多种类型,脉冲噪声就是其中之一。脉冲噪声会生成灰度值与其局部邻域不一致的像素。它在图像中显示为光点和暗点或仅光点。过滤是一种增强图像的技术。线性滤波器是输出像素的值是邻域值的线性组合的滤波,它可以在图像中产生模糊。因此,已经开发了多种非线性的平滑技术。中值滤波器是最流行的非线性滤波器之一。当考虑一个小邻域时,它是高效的,但对于大窗口并且在高噪声的情况下,它会导致图像更加模糊。中心加权平均 CWM 滤波器的平均性能优于中值滤波器。然而,在高噪声条件下,原始像素被破坏,降噪效果显着。因此,这种技术也会对图像产生模糊影响。 |
| A 3-stage Spectral-spatial Method for Hyperspectral Image Classification Authors Raymond H. Chan, Ruoning Li 高光谱图像通常具有数百个不同波长的光谱带,由记录土地覆盖的飞机或卫星捕获。由于高光谱图像的光谱和空间分辨率的增强,识别像素的详细类别变得可行。在这项工作中,我们提出了一种新颖的框架,该框架利用空间和光谱信息对高光谱图像中的像素进行分类。该方法包括三个阶段。在第一阶段,预处理阶段,使用嵌套滑动窗口算法通过增强相邻像素的一致性来重构原始数据,然后使用主成分分析来降低数据的维数。在第二阶段,训练支持向量机以使用来自图像的光谱信息来估计每个类别的像素级概率图。最后,通过确保图像中的空间连通性,应用平滑的总变化模型来平滑类概率向量。我们在六个基准高光谱数据集上展示了我们的方法相对于三种最先进算法的优越性,每个类别有 10 到 50 个训练标签。结果表明,我们的方法在准确性方面总体表现最佳。特别是,当标记像素的数量减少时,我们的精度增益会增加,因此我们的方法更适合应用于小训练集的问题。 |
| Human-Object Interaction Detection via Disentangled Transformer Authors Desen Zhou, Zhichao Liu, Jian Wang, Leshan Wang, Tao Hu, Errui Ding, Jingdong Wang 人体对象交互检测解决了人体对象交互的联合定位和分类问题。现有的 HOI 变换器要么采用单个解码器进行三元组预测,要么利用两个并行解码器分别检测单个对象和交互,并通过匹配过程组成三元组。相比之下,我们将三元组预测解耦为人类对象对检测和交互分类。我们的主要动机是检测人类对象实例和准确分类交互需要学习关注不同区域的表示。为此,我们提出了 Disentangled Transformer,其中编码器和解码器都被解开以促进两个子任务的学习。为了将解缠结解码器的预测联系起来,我们首先为 HOI 三元组与基本解码器生成统一表示,然后将其用作每个解缠结解码器的输入特征。大量实验表明,我们的方法在两个公共 HOI 基准上的表现优于先前的工作相当大的优势。 |
| Reinforced Structured State-Evolution for Vision-Language Navigation Authors Jinyu Chen, Chen Gao, Erli Meng, Qiong Zhang, Si Liu 视觉和语言导航 VLN 任务需要具体代理按照自然语言指令导航到远程位置。以前的方法通常采用序列模型,例如 Transformer 和 LSTM 作为导航器。在这样的范例中,序列模型通过维护的导航状态预测每一步的动作,该状态通常表示为一维向量。然而,关键的导航线索,即体现导航任务的对象级环境布局被丢弃,因为维护的向量本质上是非结构化的。在本文中,我们提出了一种新颖的结构化状态演化 SEvol 模型,以有效维护 VLN 的环境布局线索。具体来说,我们利用基于图的特征来表示导航状态,而不是基于向量的状态。因此,我们设计了一个强化布局线索 Miner RLM,通过定制的强化学习策略来挖掘和检测长期导航最关键的布局图。此外,提出了结构化演化模块 SEM,以在导航期间保持基于结构化图的状态,其中状态逐渐演化以学习对象级时空关系。 |
| Situational Perception Guided Image Matting Authors Bo Xu, Jiake Xie, Han Huang, Ziwen Li, Cheng Lu, Yandong Guo 大多数自动抠图方法都试图将突出的前景与背景分开。然而,当前现有的抠图数据集数量不足和主观偏见,使得难以充分探索给定图像中对象与对象和对象与环境之间的语义关联。在本文中,我们提出了一种情境感知引导的图像抠图 SPG IM 方法,该方法可以减轻抠图注释的主观偏差,并捕获足够的情境感知信息,从而更好地从视觉到文本任务中提炼出全局显着性。 SPG IM 可以更好地将对象间和对象与环境显着性相关联,并补偿图像抠图的主观性及其昂贵的注释。我们还引入了一个文本语义转换 TST 模块,该模块可以有效地转换和集成语义特征流以指导视觉表示。此外,提出了一种自适应焦点变换 AFT 细化网络,以自适应地切换多尺度感受野和焦点,以增强全局和局部细节。大量实验证明了从视觉到文本任务的情景感知指导在图像抠图上的有效性,我们的模型优于最先进的方法。我们还分析了模型中不同组件的重要性。 |
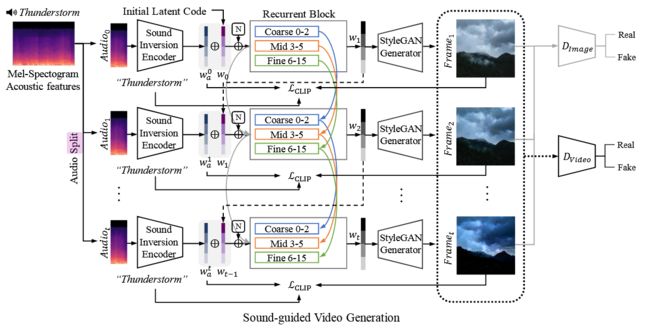
| Sound-Guided Semantic Video Generation Authors Seung Hyun Lee, Gyeongrok Oh, Wonmin Byeon, Jihyun Bae, Chanyoung Kim, Won Jeong Ryoo, Sang Ho Yoon, Jinkyu Kim, Sangpil Kim StyleGAN 最近的成功表明,预训练的 StyleGAN 潜在空间对于逼真的视频生成很有用。然而,由于在 StyleGAN 潜在空间中难以确定方向和幅度,视频中生成的运动通常没有语义意义。在本文中,我们提出了一个利用多模态声音图像文本嵌入空间生成逼真视频的框架。由于声音提供了场景的时间上下文,我们的框架学习生成在语义上与声音一致的视频。首先,我们的声音反转模块将音频直接映射到 StyleGAN 潜在空间。然后我们结合基于 CLIP 的多模态嵌入空间来进一步提供视听关系。最后,所提出的帧生成器学习在潜在空间中找到与相应声音相一致的轨迹,并以分层方式生成视频。我们为声音引导视频生成任务提供了新的高分辨率风景视频数据集视听对。实验表明,我们的模型在视频质量方面优于最先进的方法。 |
| A Survey of Video-based Action Quality Assessment Authors Shunli Wang, Dingkang Yang, Peng Zhai, Qing Yu, Tao Suo, Zhan Sun, Ka Li, Lihua Zhang 人体动作识别与分析在视频监控、视频检索、人机交互等领域有着巨大的需求和重要的应用意义。人类动作质量评价任务要求智能系统自动、客观地评价人类完成的动作。动作质量评价模型可以减少动作评价所花费的人力物力,降低主观性。在本文中,我们对现有的基于视频的动作质量评估论文进行了全面调查。与人类动作识别不同,动作质量评估的应用场景相对狭窄。现有的大部分工作都集中在运动和医疗方面。我们首先介绍人类行为质量评估的定义和挑战。然后我们介绍现有的数据集和评估指标。此外,我们根据模型类别和出版机构,根据两个领域的特点,总结了体育和医疗的方法。 |
| Solving The Long-Tailed Problem via Intra- and Inter-Category Balance Authors Renhui Zhang, Tiancheng Lin, Rui Zhang, Yi Xu 视觉识别的基准数据集假设数据是均匀分布的,而现实世界的数据集服从长尾分布。当前的方法处理长尾问题,通过重新采样或重新加权策略将长尾数据集转换为均匀分布。这些方法强调尾部类,而忽略头部类中的难示例,从而导致性能下降。在本文中,我们提出了一种具有类别自适应精度的梯度协调机制,以解耦长尾问题中的难度和样本量不平衡,并通过类别内和类别间平衡策略相应地解决。具体而言,类内平衡侧重于每个类别中的硬样本以优化决策边界,而类间平衡旨在以每个类别为单位来纠正决策边界的偏移。 |
| Visual-based Positioning and Pose Estimation Authors Somnuk Phon Amnuaisuk, Ken T. Murata, La Or Kovavisaruch, Tiong Hoo Lim, Praphan Pavarangkoon, Takamichi Mizuhara 深度学习和计算机视觉的最新进展为研究高级视觉分析任务(例如人体定位和人体姿势估计)提供了绝佳机会。尽管在最近的报道中,人体定位和人体姿态估计的性能得到了显着改善,但它们并不完美,并且在视频帧中可能会出现错误的定位和姿态估计。仍然缺乏将这些技术集成到对这些错误引入的噪声具有鲁棒性的通用管道的研究。本文填补了缺失的研究。我们探索并开发了两个适合基于视觉的定位和姿势估计任务的工作管道。在羽毛球比赛中对提议的管道进行了分析。我们证明了通过检测进行跟踪的概念可以很好地工作,并且位置和姿势的错误可以通过使用来自附近帧的信息的线性插值技术来有效地处理。 |
| Dark Spot Detection from SAR Images Based on Superpixel Deeper Graph Convolutional Network Authors Xiaojian Liu, Yansheng Li 合成孔径雷达SAR是探测海面浮油的主要仪器。在 SAR 图像中,一些受海洋现象影响的区域,例如雨池、上升流和内波,或溢油排放的区域在图像上显示为暗点。暗点检测是检测漏油的第一步,然后成为浮油候选。暗点分割的准确性最终影响着浮油识别的准确性。尽管一些以像素为处理单元的先进深度学习方法在遥感图像语义分割中表现良好,但从嘈杂的 SAR 图像中检测出一些边界较弱的暗点仍然是一个巨大的挑战。本文提出了一种基于超像素深度图卷积网络SGDCN的暗点检测方法,该方法以超像素为处理单元,为每个超像素提取特征。从超像素区域计算的特征比从固定像素邻域计算的特征更稳健。为了降低学习任务的难度,我们丢弃不相关的特征并获得最优的特征子集。超像素分割后,将图像转化为以超像素为节点的图,输入更深的图卷积神经网络进行节点分类。该图神经网络使用可微聚合函数来聚合节点和邻居的特征,形成更高级的特征。这是第一次将其用于暗点检测。 |
| K-LITE: Learning Transferable Visual Models with External Knowledge Authors Sheng Shen, Chunyuan Li, Xiaowei Hu, Yujia Xie, Jianwei Yang, Pengchuan Zhang, Anna Rohrbach, Zhe Gan, Lijuan Wang, Lu Yuan, Ce Liu, Kurt Keutzer, Trevor Darrell, Jianfeng Gao 最近最先进的计算机视觉系统从自然语言监督训练,从简单的对象类别名称到描述性标题。这种自由形式的监督确保了学习的视觉模型的高度通用性和可用性,基于对数据收集的广泛启发式,以涵盖尽可能多的视觉概念。或者,利用关于图像的外部知识学习是一种很有前途的方法,它利用了更加结构化的监督来源。在本文中,我们提出了 K LITE 知识增强语言图像训练和评估,这是一种利用外部知识构建可迁移视觉系统的简单策略。在训练中,它通过 WordNet 和维基词典知识丰富了自然语言中的实体,从而实现了一种高效且可扩展的方法学习可以理解视觉概念及其知识的图像表示在评估中,自然语言也增加了外部知识,然后用于参考学习的视觉概念或描述新的视觉概念,以实现预训练模型的零镜头和少量镜头转移.我们研究了 K LITE 在两个重要的计算机视觉问题(图像分类和对象检测)上的性能,分别在 20 个和 13 个不同的现有数据集上进行了基准测试。 |
| Vision System of Curling Robots: Thrower and Skip Authors Seongwook Yoon, Gayoung Kim, Myungpyo Hong, Sanghoon Sull 我们建立了一个冰壶机器人的视觉系统,可以预期与人类冰壶运动员一起玩。基本上,我们分别为投掷机器人和跳跃机器人构建了两种类型的视觉系统。首先,投掷机器人驶向冰壶片的给定点以释放石头。我们在投掷机器人中的视觉系统在二维冰壶片上初始化 3DoF 位姿并更新位姿以决定投掷石块的决定。其次,跳跃机器人站在投掷机器人的对面,监控比赛状态以做出战略决策。我们在跳跃机器人中的视觉系统可以精确识别卷发纸上的每一块石头。由于视点非常透视,许多石头相互遮挡,因此很难估计石头的准确位置。因此,我们使用透视霍夫变换识别石头手柄轮廓的椭圆以找到石头的确切中点。此外,我们对抛掷的石头进行跟踪,以生成用于冰况分析的轨迹。最后,我们在两个移动机器人上实现了我们的视觉系统,并成功地执行了单回合甚至是谨慎的游戏。 |
| Efficient Progressive High Dynamic Range Image Restoration via Attention and Alignment Network Authors Gaocheng Yu, Jin Zhang, Zhe Ma, Hongbin Wang HDR是计算摄影技术的重要组成部分。在本文中,我们针对挑战 NTIRE 2022 HDR Track 1 和 Track 2 提出了一种称为 Efficient Attention 和对齐引导的 Progressive Network EAPNet 的轻量级神经网络。我们引入了一个多维轻量级编码模块来提取特征。此外,我们提出了渐进式扩张U形块PDUB,它可以是一个渐进式即插即用模块,用于动态调整MAccs和PSNR。最后,我们使用快速和低功耗的特征对齐模块来代替耗时的可变形卷积网络 DCN 来处理未对齐问题。实验表明,与最先进的方法相比,我们的方法在具有更好的 mu PSNR 和 PSNR 的 MAccs 上实现了大约 20 倍的压缩。在测试阶段,我们获得了两条赛道的第二名。图1。 |
| Interventional Multi-Instance Learning with Deconfounded Instance-Level Prediction Authors Tiancheng Lin, Hongteng Xu, Canqian Yang, Yi Xu 在应用多实例学习 MIL 对实例包进行预测时,实例的预测准确性通常不仅取决于实例本身,还取决于其在相应包中的上下文。从因果推理的角度来看,这种包上下文先验作为一个混杂因素,可能会导致模型的鲁棒性和可解释性问题。针对这个问题,我们提出了一种新颖的介入式多实例学习 IMIL 框架来实现去混淆的实例级预测。与传统的基于似然的策略不同,我们设计了一种基于因果干预的期望最大化 EM 算法,在训练阶段提供了稳健的实例选择,并抑制了由袋子上下文先验引起的偏差。 |
| NTIRE 2022 Challenge on Stereo Image Super-Resolution: Methods and Results Authors Longguang Wang, Yulan Guo, Yingqian Wang, Juncheng Li, Shuhang Gu, Radu Timofte 在本文中,我们总结了第一个 NTIRE 挑战,即立体图像超分辨率恢复一对低分辨率立体图像中丰富的细节,重点关注新的解决方案和结果。该挑战有 1 条轨道,针对标准双三次退化下的立体图像超分辨率问题。共有 238 名参赛者成功注册,21 支队伍参加了最后的测试阶段。在这些参与者中,有 20 个团队成功提交了 PSNR RGB 分数优于基线的结果。 |
| Reconstruction-Aware Prior Distillation for Semi-supervised Point Cloud Completion Authors Zhaoxin Fan, Yulin He, Zhicheng Wang, Kejian Wu, Hongyan Liu, Jun He 现实世界传感器扫描的点云总是不完整的、不规则的和嘈杂的,这使得点云完成任务变得越来越重要。尽管已经提出了许多点云补全方法,但大多数都需要大量成对的完整不完整点云进行训练,耗费大量人力。相比之下,本文提出了一种名为 RaPD 的新型 Reconstruction Aware Prior Distillation 半监督点云补全方法,该方法利用两阶段训练方案来减少对大规模配对数据集的依赖。在训练阶段 1,使用重建感知预训练过程从未配对的完整点云和未配对的不完整点云中学习所谓的深度语义先验。在训练阶段 2 中,我们引入了半监督先验蒸馏过程,其中通过仅使用少量配对训练样本将先验提取到网络中来训练基于编码器解码器的完成网络。进一步引入自监督补全模块,挖掘大量未配对不完整点云的价值,从而提高网络性能。 |
| On the Performance Evaluation of Action Recognition Models on Transcoded Low Quality Videos Authors Aoi Otani, Ryota Hashiguchi, Kazuki Omi, Norishige Fukushima, Toru Tamaki 在设计动作识别模型时,数据集中视频的质量是一个重要问题,但质量和性能之间的权衡往往被忽略。一般来说,动作识别模型是在高质量视频上训练和测试的,但在实际部署动作识别模型的情况下,有时可能不会假设输入视频是高质量的。在这项研究中,我们报告了对与 JPEG 和 H.264 AVC 转码相关的质量下降的动作识别模型的定性评估。显示了用于评估预训练模型在 Kinetics400 的转码验证视频上的性能的实验结果。这些模型还使用转码的训练视频进行训练。 |
| Multi-Camera Multiple 3D Object Tracking on the Move for Autonomous Vehicles Authors Pha Nguyen, Kha Gia Quach, Chi Nhan Duong, Ngan Le, Xuan Bac Nguyen, Khoa Luu 自动驾驶汽车的发展为拥有一套完整的摄像头传感器捕捉汽车周围环境提供了机会。因此,目标检测和跟踪以应对新的挑战非常重要,例如在摄像机视图中实现一致的结果。为了应对这些挑战,这项工作提出了一种新的具有链接预测方法的全局关联图模型,通过交叉注意力运动建模和外观重新识别来预测现有轨迹位置和链接检测与轨迹。这种方法旨在解决由不一致的 3D 对象检测引起的问题。此外,我们的模型利用提高标准 3D 对象检测器在 nuScenes 检测挑战中的检测精度。 |
| RangeUDF: Semantic Surface Reconstruction from 3D Point Clouds Authors Bing Wang, Zhengdi Yu, Bo Yang, Jie Qin, Toby Breckon, Ling Shao, Niki Trigoni, Andrew Markham 我们提出 RangeUDF,一种新的基于隐式表示的框架,用于从点云中恢复连续 3D 场景表面的几何和语义。与只能模拟封闭 3D 表面的占用场或有符号距离场不同,我们的方法不限于任何类型的拓扑。与现有的无符号距离场不同,我们的框架没有任何表面模糊性。此外,我们的 RangeUDF 可以联合估计连续表面的精确语义。我们方法的关键是范围感知无符号距离函数以及面向表面的语义分割模块。大量实验表明,RangeUDF 明显优于在四个点云数据集上进行表面重建的最先进方法。 |
| Diverse Imagenet Models Transfer Better Authors Niv Nayman, Avram Golbert, Asaf Noy, Tan Ping, Lihi Zelnik Manor 一个普遍接受的假设是,Imagenet 上精度更高的模型在其他下游任务上表现更好,导致大量研究致力于优化 Imagenet 精度。最近,这一假设受到了证据的挑战,这些证据表明,尽管自监督模型的 Imagenet 准确性较差,但它们的迁移比监督模型更好。这需要在 Imagenet 准确性之上确定使模型可转移的其他因素。在这项工作中,我们展示了模型学习到的特征的高度多样性与 Imagenet 准确性共同促进了可迁移性。受最近自监督模型的可迁移性结果的鼓舞,我们提出了一种将自监督和监督预训练相结合的方法,以生成具有高多样性和高精度的模型,从而具有高可迁移性。 |
| Optical Remote Sensing Image Understanding with Weak Supervision: Concepts, Methods, and Perspectives Authors Jun Yue, Leyuan Fang, Pedram Ghamisi, Weiying Xie, Jun Li, Jocelyn Chanussot, Antonio J Plaza 近年来,监督学习已广泛应用于光学遥感图像理解的各种任务,包括遥感图像分类、逐像素分割、变化检测和目标检测。基于监督学习的方法需要大量高质量的训练数据,其性能很大程度上取决于标签的质量。然而,在实际的遥感应用中,获取具有高质量标签的大规模数据集通常是昂贵且耗时的,这导致缺乏足够的监督信息。在某些情况下,只能获得粗粒度的标签,导致缺乏精确的监督。此外,人工获得的监督信息可能是错误的,导致缺乏准确的监督。因此,遥感图像理解往往面临监督信息不完整、不准确、不准确等问题,这将影响遥感应用的广度和深度。为了解决上述问题,研究人员探索了弱监督下的遥感图像理解中的各种任务。本文总结了遥感领域弱监督学习的研究进展,包括三种典型的弱监督范式 1 不完全监督,只标注训练数据的一个子集 2 不精确监督,只给训练数据的粗粒度标注 |
| Behind the Machine's Gaze: Biologically Constrained Neural Networks Exhibit Human-like Visual Attention Authors Leo Schwinn, Doina Precup, Bj rn Eskofier, Dario Zanca 总的来说,现有的视觉注意力计算模型默认假设完美的视觉和对刺激的完全访问,从而偏离中心凹的生物视觉。此外,建模自上而下的注意力通常被简化为语义特征的集成,而不包含已显示部分引导人类注意力的高级视觉任务的信号。我们提出神经视觉注意 NeVA 算法以自上而下的方式生成视觉扫描路径。使用我们的方法,我们探索了神经网络的能力,我们在神经网络上施加了中央凹视觉的生物约束来生成类似人类的扫描路径。因此,生成扫描路径以最大化关于底层视觉任务(即分类或重建)的性能。大量实验表明,所提出的方法在与人类扫描路径的相似性方面优于最先进的无监督人类注意模型。此外,框架的灵活性允许定量研究不同任务在生成的视觉行为中的作用。 |
| 4D-MultispectralNet: Multispectral Stereoscopic Disparity Estimation using Human Masks Authors Philippe Duplessis Guindon, Guillaume Alexandre Bilodeau 多光谱立体视觉是一个新兴领域。在经典立体学方面已经做了很多工作,但多光谱立体学的研究并不那么频繁。这种立体视觉可用于自动驾驶汽车,以完成 RGB 摄像头给出的信息。当条件较为困难时,例如在夜景中,它有助于识别周围的物体。本文重点介绍 RGB LWIR 光谱。 RGB LWIR 立体镜与经典立体镜具有相同的挑战,即遮挡、无纹理表面和重复图案,以及与不同模式相关的特定挑战。在两个光谱之间寻找匹配增加了另一层复杂性。颜色、纹理和形状更可能因光谱而异。为了解决这个额外的挑战,本文着重于估计场景中存在的人的差异。鉴于人的形状在 RGB 和 LWIR 中都被捕获,我们提出了一种新方法,该方法在两个光谱中使用人类的分割掩码,然后在连体网络的第一层之前将它们连接到原始图像。 |
| Photometric single-view dense 3D reconstruction in endoscopy Authors Victor M. Batlle, J.M.M. Montiel, Juan D. Tardos 人体内的视觉SLAM将为内窥镜的计算机辅助导航开辟道路。然而,由于空间限制,医用内窥镜只能提供单眼图像,导致系统缺乏真实的规模。在本文中,我们利用结肠镜检查中的受控照明,在校准的单目内窥镜上使用光度立体首次实现人体结肠的体内 3D 重建。我们的方法在真实的医疗环境中工作,提供合适的原位校准程序和适应结肠管状几何形状的深度估计技术。我们在模拟结肠镜检查中验证了我们的方法,深度估计的平均误差为 7,平均低于 3 毫米。 |
| Detection of Tool based Edited Images from Error Level Analysis and Convolutional Neural Network Authors Abhishek Gupta, Raunak Joshi, Ronald Laban 图像伪造是图像取证的一个问题,可以使用深度学习来利用它的检测。在本文中,我们提出了一种使用具有错误级别分析和卷积神经网络的图像编辑工具来识别真实和篡改图像的方法。该过程在 CASIA ITDE v2 数据集上执行,并分别训练 50 和 100 个 epoch。 |
| Embodied Navigation at the Art Gallery Authors Roberto Bigazzi, Federico Landi, Silvia Cascianelli, Marcella Cornia, Lorenzo Baraldi, Rita Cucchiara 经过训练以探索和导航室内逼真环境的具体代理在标准数据集和基准测试中取得了令人印象深刻的结果。到目前为止,实验和评估已经涉及办公室、公寓和房屋等家庭和工作场景。在本文中,我们构建并发布了一个具有独特特征的新的3D空间,它是一个完整的艺术博物馆。我们将此环境命名为 ArtGallery3D AG3D 。与现有的 3D 场景相比,采集到的空间更宽敞,视觉特征更丰富,并且提供了非常稀疏的占用信息。对于通常在拥挤的家庭环境中训练并具有大量占用信息的基于占用的代理而言,此功能具有挑战性。此外,我们还标注了博物馆内主要景点的坐标,例如绘画、雕像和其他物品。由于这个手动过程,我们在这个新空间内为 PointGoal 导航提供了新的基准。该数据集中的轨迹远比 Gibson 和 Matterport3D 中现有的地面实况导航路径复杂和冗长。我们使用我们的新评估空间进行广泛的实验评估,并证明现有方法很难适应这种情况。 |
| Assembly Planning from Observations under Physical Constraints Authors Thomas Chabal, Robin Strudel, Etienne Arlaud, Jean Ponce, Cordelia Schmid 本文解决了使用从单张照片中提取的信息来复制具有已知形状和外观的未知图元组合的问题,该信息通过现成的目标检测和姿势估计程序进行。所提出的算法使用物理稳定性约束、凸优化和蒙特卡洛树搜索的简单组合来将装配计划为由 STRIPS 运算符表示的拾取和放置操作序列。它是有效的,最重要的是,对于任何真实机器人系统中不可避免的目标检测和姿态估计误差具有鲁棒性。 |
| Hierarchical BERT for Medical Document Understanding Authors Ning Zhang, Maciej Jankowski 医学文档理解近来备受关注。一项具有代表性的任务是国际疾病分类 ICD 诊断代码分配。现有工作采用 RNN 或 CNN 作为骨干网络,因为普通 BERT 不能很好地处理 2000 到 kens 的长文档。所有这些方法共有的一个问题是它们过于特定于 ICD 代码分配任务,失去了给出整个文档级别和句子级别嵌入的通用性。因此,将它们引导到其他下游 NLU 任务并不是直接的。受这些观察的启发,我们提出 Medical Document BERT MDBERT 用于长时间的医学文档理解任务。 MDBERT 不仅在学习不同语义级别的表示方面有效,而且通过利用自下而上的层次结构来有效编码长文档。与普通 BERT 解决方案 1 相比,MDBERT 在 MIMIC III 数据集上将性能提升至相对 20,使其与当前的 SOTA 解决方案相当 2,它将自我注意模块的计算复杂度降低到 1100 以下。除了 ICD 代码 |
| Fast and Robust Femur Segmentation from Computed Tomography Images for Patient-Specific Hip Fracture Risk Screening Authors Pall Asgeir Bjornsson, Alexander Baker, Ingmar Fleps, Yves Pauchard, Halldor Palsson, Stephen J. Ferguson, Sigurdur Sigurdsson, Vilmundur Gudnason, Benedikt Helgason, Lotta Maria Ellingsen 骨质疏松症是一种常见的骨病,会增加骨折的风险。基于有限元分析的髋部骨折风险筛查方法依赖于分段计算机断层扫描 CT 图像,然而,当前的股骨分割方法需要手动描绘大型数据集。在这里,我们提出了一种深度神经网络,用于从 CT 中全自动、准确和快速地分割股骨近端。 |
| Fetal Brain Tissue Annotation and Segmentation Challenge Results Authors Kelly Payette, Hongwei Li, Priscille de Dumast, Roxane Licandro, Hui Ji, Md Mahfuzur Rahman Siddiquee, Daguang Xu, Andriy Myronenko, Hao Liu, Yuchen Pei, Lisheng Wang, Ying Peng, Juanying Xie, Huiquan Zhang, Guiming Dong, Hao Fu, Guotai Wang, ZunHyan Rieu, Donghyeon Kim, Hyun Gi Kim, Davood Karimi, Ali Gholipour, Helena R. Torres, Bruno Oliveira, Jo o L. Vila a, Yang Lin, Netanell Avisdris, Ori Ben Zvi, Dafna Ben Bashat, Lucas Fidon, Michael Aertsen, Tom Vercauteren, Daniel Sobotka, Georg Langs, Mireia Aleny , Maria Inmaculada Villanueva, Oscar Camara, Bella Specktor Fadida, Leo Joskowicz, Liao Weibin, Lv Yi, Li Xuesong, Moona Mazher, Abdul Qayyum, Domenec Puig, Hamza Kebiri, Zelin Zhang, Xinyi Xu, Dan Wu, KuanLun Liao, YiXuan Wu, JinTai Chen, Yunzhi Xu, Li Zhao, Lana Vasung, Bjoern Menze, Meritxell Bach Cuadra, Andras Jakab 子宫内胎儿 MRI 正在成为诊断和分析发育中的人类大脑的重要工具。发育中胎儿大脑的自动分割是在研究和临床背景下定量分析产前神经发育的重要步骤。然而,大脑结构的手动分割非常耗时,并且容易出现错误和观察者间的变异性。因此,我们在 2021 年组织了胎儿组织注释 FeTA 挑战赛,以鼓励在国际水平上开发自动分割算法。该挑战利用了 FeTA 数据集,这是一个开放的胎儿大脑 MRI 重建数据集,被分割成七种不同的组织,外部脑脊液、灰质、白质、心室、小脑、脑干、深部灰质。本次挑战赛共有 20 支国际团队参与,共提交 21 种算法进行评估。在本文中,我们从技术和临床角度对结果进行了详细分析。所有参与者都依赖于深度学习方法,主要是 U Nets,在网络架构、优化以及图像前后处理方面存在一些可变性。大多数团队使用现有的医学成像深度学习框架。提交的主要区别在于训练期间进行的微调,以及执行的特定预处理和后处理步骤。挑战结果表明,几乎所有提交的作品都表现相似。前五名团队中有四个使用了集成学习方法。然而,一个团队的算法表现明显优于其他提交,并且由不对称的 U Net 网络架构组成。 |
| Cross-view Brain Decoding Authors Subba Reddy Oota, Jashn Arora, Manish Gupta, Raju S. Bapi 大脑如何跨多个视图捕获语言刺激的含义仍然是神经科学中一个关键的悬而未决的问题。考虑概念公寓 1 图片 WP 的三个不同视图,其中包含目标词标签,2 个使用目标词的句子 S,以及包含目标词和其他语义相关词的 3 个词云 WC。与之前仅关注单视图分析的努力不同,在本文中,我们研究了大脑解码在零镜头交叉视图学习设置中的有效性。此外,我们提出了在跨视图翻译任务(如图像字幕 IC、图像标记 IT、关键字提取 KE 和句子形成 SF)的新上下文中进行大脑解码。通过广泛的实验,我们证明了跨视图零镜头大脑解码是实用的,导致跨视图对的平均成对精度为 0.68。此外,解码的表示足够详细,以实现交叉视图翻译任务的高精度,具有以下成对精度 IC 78.0、IT 83.0、KE 83.7 和 SF 74.5。对不同大脑网络贡献的分析揭示了令人兴奋的认知见解 1 高比例的视觉体素参与图像字幕和图像标记任务,高比例的语言体素参与句子形成和关键字提取任务。 |
| Special Session: Towards an Agile Design Methodology for Efficient, Reliable, and Secure ML Systems Authors Shail Dave, Alberto Marchisio, Muhammad Abdullah Hanif, Amira Guesmi, Aviral Shrivastava, Ihsen Alouani, Muhammad Shafique 机器学习 ML 的现实世界用例在过去几年中呈爆炸式增长。然而,当前的计算基础设施不足以支持所有现实世界的应用和场景。除了高效率要求外,现代机器学习系统还有望在硬件故障以及对抗和 IP 窃取攻击方面具有高度可靠性。隐私问题也正在成为首要问题。 |
| Case-Aware Adversarial Training Authors Mingyuan Fan, Yang Liu, Wenzhong Guo, Ximeng Liu, Jianhua Li 神经网络 NN 成为各种信号处理应用中最热门的模型之一。然而,NNs 极易受到对抗样本 AEs 的影响。为了防御 AE,对抗性训练 AT 被认为是最有效的方法,而由于计算量大,AT 仅限于在大多数应用中应用。在本文中,为了解决这个问题,我们设计了一种通用且高效的 AT 改进方案,即案例感知对抗训练 CAT。具体来说,直觉源于这样一个事实,即非常有限的一部分信息样本可以对大部分模型性能做出贡献。或者,如果在 AT 中只使用信息量最大的 AE,我们可以在保持防御效果的同时显着降低 AT 的计算复杂度。为此,CAT 实现了两项突破。首先,提出了一种估计对抗样本信息度的方法,用于AE过滤。其次,为了进一步丰富 NN 可以从 AE 获得的信息,CAT 涉及基于权重估计和类级别平衡的采样策略,以增加 AT 在每次迭代中的多样性。 |
| Adversarial Scratches: Deployable Attacks to CNN Classifiers Authors Loris Giulivi, Malhar Jere, Loris Rossi, Farinaz Koushanfar, Gabriela Ciocarlie, Briland Hitaj, Giacomo Boracchi 越来越多的工作表明,深度神经网络容易受到对抗样本的影响。这些采取应用于模型输入的小扰动的形式,这会导致不正确的预测。不幸的是,大多数文献都侧重于应用于数字图像的视觉上难以察觉的扰动,而这些扰动通常在设计上是不可能部署到物理目标上的。我们提出对抗性划痕是一种新颖的 L0 黑盒攻击,它采用图像中的划痕的形式,并且比其他最先进的攻击具有更大的可部署性。对抗性划痕利用 B zier 曲线来减少搜索空间的维度,并可能将攻击限制在特定位置。我们在几个场景中测试对抗性划痕,包括公开可用的 API 和交通标志图像。 |
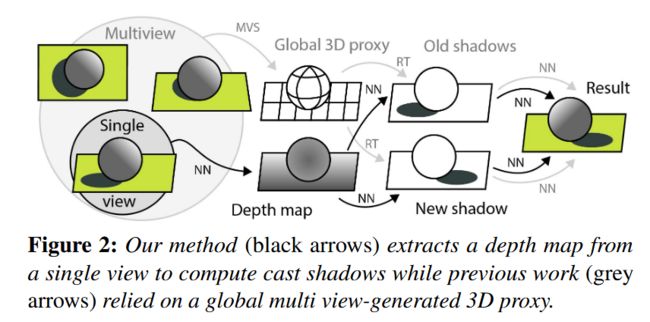
| OutCast: Outdoor Single-image Relighting with Cast Shadows Authors David Griffiths, Tobias Ritschel, Julien Philip 我们提出了一种户外图像的重新照明方法。我们的方法主要侧重于从单个图像预测任意新颖照明方向的投射阴影,同时还考虑了阴影和全局效应,例如太阳光颜色和云。该问题的先前解决方案依赖于重建遮挡几何,例如使用多视图立体,这需要场景的许多图像。相反,在这项工作中,我们利用现成的噪声单幅图像深度图估计作为几何来源。虽然这对于某些光照效果来说是一个很好的指南,但最终的深度图质量不足以直接对阴影进行光线追踪。为了解决这个问题,我们提出了一个学习图像空间光线行进层,它将近似深度图转换为深度 3D 表示,该表示使用学习遍历融合到遮挡查询中。我们提出的方法首次实现了最先进的重新照明结果,仅使用单个图像作为输入。 |
| Unsupervised Domain Adaptation for Cardiac Segmentation: Towards Structure Mutual Information Maximization Authors Changjie Lu, Shen Zheng, Gaurav Gupta 无监督域适应方法最近在各种医学图像分割任务中取得了成功。报告的工作通常通过对齐域不变特征和最小化域特定差异来解决域偏移问题。当特定域之间和不同域之间的差异很小时,该策略很有效。然而,这些模型在不同成像模式上的泛化能力仍然是一个重大挑战。本文介绍了 UDA VAE,这是一种用于心脏分割的无监督域自适应框架,具有紧凑的损失函数下界。为了估计这个新的下界,我们开发了一种新颖的结构互信息估计 SMIE 模块,该模块具有全局估计器、局部估计器和先验信息匹配估计器,以最大化重建和分割任务之间的互信息。具体来说,我们设计了一种新颖的顺序重新参数化方案,可以实现从低分辨率潜在空间到高分辨率潜在空间的信息流和方差校正。对基准心脏分割数据集的综合实验表明,我们的模型在质量和数量上都优于以前的最新技术。 |
| SpiderNet: Hybrid Differentiable-Evolutionary Architecture Search via Train-Free Metrics Authors Rob Geada, Andrew Stephen McGough 神经架构搜索 NAS 算法旨在消除手动神经网络设计的负担,并已证明能够为各种众所周知的问题设计出色的模型。然而,这些算法需要用户配置或硬编码决策形式的各种设计参数,这限制了可以发现的网络种类。这意味着 NAS 算法不会消除模型设计调整,它们只是转移需要应用调整的地方的负担。在本文中,我们介绍了 SpiderNet,这是一种混合可微进化和硬件感知算法,可快速有效地生成最先进的网络。更重要的是,SpiderNet 是最小配置 NAS 算法的概念证明,其他算法中的大多数设计选择都被纳入 SpiderNet 的动态演化搜索空间,将用户选择的数量减少到只有两个减少单元数和初始通道数. |
| A Deeper Look into Aleatoric and Epistemic Uncertainty Disentanglement Authors Matias Valdenegro Toro, Daniel Saromo 神经网络在许多任务中无处不在,但相信它们的预测是一个悬而未决的问题。许多应用都需要对不确定性进行量化,而解开的任意和认知不确定性是最好的。在本文中,我们概括了产生解缠结不确定性的方法,以与不同的不确定性量化方法一起工作,并评估它们产生解缠结不确定性的能力。我们的结果表明,学习任意不确定性和认知不确定性之间存在相互作用,这是出乎意料的并且违反了对任意不确定性的假设,Flipout 等一些方法产生零认知不确定性,任意不确定性在分布外设置中是不可靠的,而 Ensembles 提供了总体最好的解开质量。我们还探讨了采样 softmax 函数中样本超参数数量产生的误差,推荐 N 100 个样本。 |
| Uncertainty-based Cross-Modal Retrieval with Probabilistic Representations Authors Leila Pishdad, Ran Zhang, Konstantinos G. Derpanis, Allan Jepson, Afsaneh Fazly 概率嵌入已被证明可用于捕获多义词的含义,以及图像匹配中的歧义。在本文中,我们研究了概率嵌入在跨模态设置(即文本和图像)中的优势,并提出了一种简单的方法,该方法将现有图像文本匹配模型中的标准向量点嵌入替换为参数学习的概率分布。我们的指导假设是,概率嵌入中编码的不确定性捕获了输入实例中的跨模态模糊性,并且正是通过捕获这种不确定性,概率模型才能在下游任务中表现更好,例如图像到文本或文本到图像恢复。 |
| Does Interference Exist When Training a Once-For-All Network? Authors Jordan Shipard, Arnold Wiliem, Clinton Fookes Once For All OFA 方法提供了一个极好的途径,可以通过利用超网子网架构将经过训练的神经网络模型部署到多个目标平台中。一旦经过训练,子网可以从超网络的架构和训练的权重中派生出来,并直接部署到目标平台,几乎不需要重新训练或微调。为了训练子网人口,OFA 使用一种称为 Progressive Shrinking PS 的新型训练方法,旨在限制训练期间干扰的负面影响。人们认为,训练期间较高的干扰会导致较低的子网人口准确度。在这项工作中,我们再看一下这种干扰效应。令人惊讶的是,我们发现干扰缓解策略对整体子网人口性能没有太大影响。相反,我们发现训练期间的子网架构选择偏差是一个更重要的方面。为了证明这一点,我们提出了一种简单而有效的方法,称为随机子网采样 RSS,它没有减轻干扰效应。尽管没有缓解措施,RSS 能够在四个中小型数据集中产生比 PS 更好的子网种群,这表明干扰效应在这些数据集中并不起关键作用。由于其简单性,与 PS 相比,RSS 的训练时间减少了 1.9 倍。当 RSS 训练 epoch 的数量减少时,也可以通过合理的性能下降来实现 6.1 倍的减少。 |
| Learned Monocular Depth Priors in Visual-Inertial Initialization Authors Yunwen Zhou, Abhishek Kar, Eric Turner, Adarsh Kowdle, Chao X. Guo, Ryan C. DuToit, Konstantine Tsotsos 视觉惯性里程计 VIO 是当今学术界和工业界大多数 AR VR 和自主机器人系统的姿态估计主干。然而,这些系统对传感器偏差、重力方向和公制比例等关键参数的初始化非常敏感。在很少满足高视差或可变加速度假设的实际场景中,例如悬停的空中机器人,智能手机 AR 用户没有用手机做手势,经典的视觉惯性初始化公式经常变得不适或无法有意义地收敛。在本文中,我们专门针对这些在野外使用中至关重要的低激发场景的视觉惯性初始化。我们建议通过结合新的基于学习的测量作为更高级别的输入来规避运动 SfM 初始化中经典视觉惯性结构的限制。我们利用学习到的单目深度图像单深度来约束特征的相对深度,并通过联合优化其尺度和移位将单深度升级到公制尺度。我们的实验表明,与视觉惯性初始化的经典公式相比,问题条件得到了显着改进,并且在公共基准测试中,特别是在运动受限场景下,相对于现有技术,我们的实验显示了显着的准确性和鲁棒性改进。 |
| Importance is in your attention: agent importance prediction for autonomous driving Authors Christopher Hazard, Akshay Bhagat, Balarama Raju Buddharaju, Zhongtao Liu, Yunming Shao, Lu Lu, Sammy Omari, Henggang Cui 轨迹预测是自动驾驶中的一项重要任务。最先进的轨迹预测模型通常使用注意力机制来模拟代理之间的交互。在本文中,我们展示了来自此类模型的注意力信息也可用于衡量每个代理相对于自我车辆未来计划轨迹的重要性。 |
| PR-DAD: Phase Retrieval Using Deep Auto-Decoders Authors Leon Gugel, Shai Dekel 相位检索是一个众所周知的病态逆问题,其中一个人试图恢复图像,只给定其傅里叶变换的幅度值作为输入。近年来,基于深度学习的新算法被提出,提供了超越经典方法结果的突破性结果。在这项工作中,我们提供了一种新颖的深度学习架构 PR DAD Phase Retrieval Using Deep Auto Decoders,其组件是基于相位检索问题的数学建模精心设计的。 |
| Domain-Invariant Representation Learning from EEG with Private Encoders Authors David Bethge, Philipp Hallgarten, Tobias Grosse Puppendahl, Mohamed Kari, Ralf Mikut, Albrecht Schmidt, Ozan zdenizci 众所周知,基于深度学习的脑电图 EEG 信号处理方法由于数据分布的变化而具有较差的测试时间泛化性。当对隐私保护表示学习感兴趣时,例如在临床环境中,这将成为一个更具挑战性的问题。为此,我们提出了一种多源学习架构,我们从数据集特定的私有编码器中提取域不变表示。我们的模型利用基于最大平均差异 MMD 的域对齐方法来为编码表示施加域不变性,这优于基于 EEG 的情感分类中的最新方法。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页
pic from pexels.com