表情识别综述论文《Deep Facial Expression Recognition: A Survey》中文翻译
本篇博客为论文《Deep Facial Expression Recognition: A Survey》的中文翻译,如有翻译错误请见谅,同时希望您能为我提出改正建议,谢谢!
论文链接:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9039580
人脸表情识别综述论文《Deep Facial Expression Recognition: A Survey》中文翻译
- 1、简介
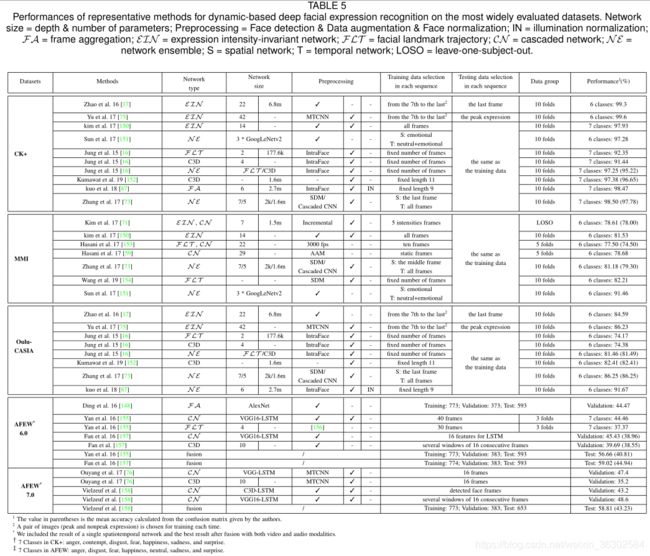
- 2. 人脸表情识别数据集
- 3. 深度表情识别
-
- 3.1 预处理
-
- 3.1.1 人脸对齐
- 3.1.2 数据增强
- 3.1.3 人脸正则化
- 3.2 深度特征学习网络
- 3.3 人脸表情分类
- 4. 先进方法
-
- 4.1 预训练和微调
- 4.2 网络输入多样化
- 4.3 用于静态图像的深度人脸表情识别
-
- 4.3.1 辅助块
- 4.3.2 损失层
- 4.3.3 网络集成
- 4.3.4 多任务网络
- 4.3.5 级联网络
- 4.3.6 生成对抗网络
- 4.3.7 讨论
- 4.4 用于动态图像序列的深度FER网络
-
- 4.4.1 帧聚合
- 4.4.2 表情强度不变网络
- 4.4.3 深度时空FER网络
- 4.4.4 讨论
- 5. 其他未决问题
-
- 5.1 咬合非额头姿势
- 5.2 三维静态和动态数据的FER
- 5.3 面部表情合成
- 5.4 可视化技术
- 5.5 其他新问题
- 6. 挑战与未来方向
-
- 6.1 面部表情数据集
- 6.2 数据集偏倚和不均衡分布
- 6.3 结合其他情感模式
- 6.4 多模态情感识别
- 参考文献
摘要:随着面部表情识别(FER)从实验室控制向更具有挑战性的自然环境表情识别的转变,以及近年来深度学习技术在各个领域的成功,深度神经网络越来越多地被用于学习进行自动表情识别的鉴别表征。最近的深度FER系统通常关注两个重要的问题:由于缺乏足够的训练数据而导致的过度拟合问题和与表情无关的变化因素,如光照、头部姿势和身份偏差。这篇论文中针对深度学习FER进行了全面综述,内容包括关于FER数据集和算法,同时为这些内在的问题提供见解。在该论文中,首先将介绍了广泛使用的FER数据集,并为这些数据集提供了公认的数据选择和评价原则。在此基础上,结合相关的背景知识和各阶段适用的实现建议,描述了一个深度学习FER系统的标准处理流程。针对深度神经网络的研究现状,本文综述了基于静态图像和动态图像序列的新型深度神经网络和相关的训练策略,并讨论了它们的优点和局限性;该论文还总结了广泛使用的基准测试的竞争性能;然后将调查FER扩展到其他相关问题和相关应用场景;最后回顾了该领域中剩余的挑战和相应的机遇,并设想了未来更为鲁棒的FER系统的设计方向。
1、简介
表情是人类表达情感状态和意图的最有力、最自然、最普遍的信号之一。由于自动面部表情分析在社交机器人、医疗、驾驶员疲劳监测和许多其他人机交互系统中具有重要的实际意义,因此有许多研究人员对其进行了大量的研究。在计算机视觉和机器学习领域,已经开发了各种面部表情识别系统来从面部表征中编码表情信息。早在二十世纪,Ekman和Friesen[3]在跨文化研究[4]的基础上定义了六种基本情绪,该研究表明,人类对某些基本情绪的感知方式是相同的,与文化无关。这些典型的面部表情是愤怒、厌恶、恐惧、快乐、悲伤和惊讶。轻蔑随后被添加为一种基本情绪[5]。然而,最近神经科学和心理学的高级研究认为,六种基本情绪的模型是特定文化的,而不是普遍的
上述基于基本情绪的情绪模型用于表达日常情感的复杂性和微表情的能力是有限的,而其他情感描述模型,比如面部动作编码系统和连续情绪模型,被认为是能表示更广泛情感的情感分类模型,但由于离散情绪模型有大量的开拓性研究及其对面部表情的直接和直观的定义,用离散情绪模型来描述情绪仍然是FER最受欢迎的方法。在本次综述中,我们将基于离散情绪模型对FER进行讨论。
根据特征表示方式的不同,可将图像自动检测系统分为两大类:静态图像自动检测系统和动态序列自动检测系统。在静态方法中,特征表示只使用当前单幅图像的空间信息进行编码,而动态方法考虑了输入面部表情序列中相邻帧之间的时间关系。除了这两种基于视觉的方法,其他的模态,如声音和生理信号通道,也可以被用于多模态系统来辅助表情的识别。
大多数传统方法使用手工特征或浅学习(如局部二元模式(LBP)、三正交平面上的LBP (LBP- top)、非负矩阵分解(NMF)和稀疏学习)进行FER。然而,自2013年以来,FER2013[21]和自然环境下的情绪识别(EmotiW)等情绪识别比赛从具有挑战性的真实场景中收集了相对充足的训练数据,这间接地促进了FER从实验室环境向自然环境的过渡。同时,由于芯片处理能力大幅度提高(例如,GPU)和更为完善的网络体系结构,各领域研究重心已经开始转移到深度学习方法,因此而实现了更高的识别精度,大幅超过了以往的研究结果。同样,随着更有效的面部表情训练数据的出现,深度学习技术越来越多地应用于处理自然环境情绪识别。图1展示了FER在算法和数据集方面的发展过程。

近年来已经发表了很多关于自动表情分析的综述文献,这些综述充分回顾以往的关于FER的标准算法流程,但它们大多更侧重于总结传统的方法,而深度学习很少被回顾。最近,文献[31]中针对基于深度学习的FER系统进行了综述,但没有介绍FER数据集和关于deep FER的技术细节。因此,本文对基于静态图像和视频(图像序列)的深度学习FER任务进行了系统的研究,目标是帮助初入此领域的人更快地了解基于深度学习的FER系统框架和主要方法。
尽管深度学习具有强大的特征学习能力,但在应用于FER时仍然存在问题。首先,深度神经网络需要大量的训练数据以避免过拟合问题。然而,在目标识别任务中,现有的面部表情数据库还不足以训练得到一个优异的具有深度结构的知名神经网络。此外,由于年龄、性别、民族背景和表达能力[32]等个人属性的不同,也存在较高的被试间差异除了受试者身份偏差,姿态变化,光照和遮挡在无约束的面部表情场景中是常见的。这些因素与面部表情之间存在非线性耦合关系,因此有必要应用深度网络以解决大的类内变异,并学习有效的特定表情表征。
本文介绍了近年来解决上述问题的研究进展,以供深入研究。我们检查了在以前的调查论文中没有被总结过的最新研究结果。本文的其余部分组织如下。第2节介绍了常用的表情数据库。第3节确定了深度FER系统所需的三个主要步骤,并描述了相关背景。第4节详细介绍了基于静态图像和动态图像序列的新型神经网络体系结构和专门为FER设计的网络训练技巧。然后,我们将在第5节中介绍其他相关问题和其他实用场景。第6节讨论了该领域的一些挑战和机会,并确定了潜在的未来方向
2. 人脸表情识别数据集
拥有足够的标记训练数据,包括尽可能多的人群和环境的变化,这对设计深度表情识别系统很重要。在本节中,我们将讨论包含基本表情的公开可用数据库,这些表情在我们的综述论文中广泛用于深度学习算法评估。我们还介绍了最新发布的数据库,其中包含了从现实世界收集的大量情感图像,这有利于深度神经网络的训练。表1概述了这些数据集,包括主要参考文献、受试者数量、图像或视频样本数量、采集环境、表情分布和附加信息。图2展示了从实验室和现实环境中收集的面部表情图像。

CK+:Extended Cohn-Kanade (CK+)数据库是评价FER系统最广泛使用的实验室环境数据库。CK+包含从中性表情到峰值表情的序列。为了进行评价,最常用的数据选择方法是提取每个序列的最后一至三帧有峰的帧和第一帧。然后,将受试者分为n组进行独立的n折交叉验证实验,通常选择的n值为5、8和10。
MMI : MMI数据库也是实验室环境的。与CK+不同的是,MMI中的序列是onset-apex-offset标记的,即序列以中性表情开始,在中间附近达到一个峰值,然后返回中性表情。在实验中,最常见的方法是选择第一帧(中性脸)和每个正面序列中的三个峰值帧进行( person-independent)的10折交叉验证。
Oulu-CASIA : Oulu-CASIA数据库包括2880个受试者的图像序列。每一个视频都是在三种不同的光照条件下,用两种成像系统之一,即近红外(NIR)或可见光(VIS)捕捉的。与CK+类似,第一帧是中性的,最后一帧是峰值表情。一般情况下,只使用VIS系统在正常室内照明下收集的480个视频中的最后三个峰值帧和第一帧(中性脸)进行10倍交叉验证实验。
JAFFE : The Japanese Female Facial Expression (JAFFE) database包含了来自10位日本女性的213个姿势表情样本。每个人都有3 ~ 4张图像,每一张都有6个基本的面部表情和一张中性表情的图像。通常情况下,所有的图像都被用来做留一被试(leave-one-subject-out)实验。
FER2013 : FER2013是一个由谷歌图像搜索API自动收集的大规模无约束数据库。剔除不正确标记的帧并调整裁剪区域后,对所有图像进行配准并调整大小为48*48像素。FER2013包含28,709个训练图像,3,589个验证图像和3,589个测试图像,带有7个表达标签。
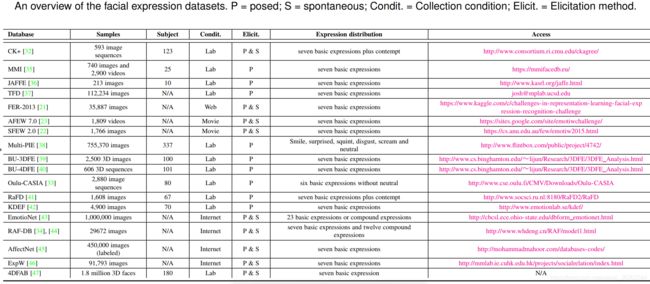
AFEW和SFEW : The Acted Facial Expressions in The Wild (Afew)数据库包含了从不同的电影中收集的视频片段,其中有自发的表情、不同的头部姿势、遮挡和光照。AFEW是一个时间和多模态数据库,在音频和视频中提供了非常不同的环境条件。AFEW按主题和电影/电视来源独立划分为三个数据分区,确保三个集合中的数据属于相互排斥的电影和演员。The Static Facial Expressions in the Wild (SFEW)是通过从AFEW数据库中选择静态帧创建的。最常用的版本SFEW 2.0被分为三组:训练集、验证集和测试集。训练和验证集的表情标签是公开的,而测试集的表情标签是由挑战组织者保留的。
Multi-Pie:CMU Multi-Pie数据库包含来自337名受试者的755,370张图像,在15个视点和19个光照条件下,在最多4个录音会话中。每个面部图像都有六种表情中的一种。该数据集通常用于多视图面部表情分析。
BU-3DFE和BU-4DFE:The Binghamton University 3D Facial Expression(BU-3DFE)包含了来自100人的606个面部表情序列。以不同的方式和不同的强度引出每个受试者的六个面部表情。与Multi-PIE相似,该数据集通常用于多视图3D面部表情分析。为了从静态三维空间到动态三维空间分析人脸行为,构建了包含606个三维人脸表情序列的BU4DFE模型,共包含约60600个帧模型
EmotioNet : EmotioNet是一个大型数据库,包含从互联网上收集的100万张面部表情图像。使用其中的自动动作单元(AU)检测模型对95万幅图像进行标注,其余25000幅图像采用11个AUs进行手动标注。EmotioNet挑战[50]的第二版提供了6个基本表情和10个复合表情[51],并提供了2478张带有表情标签的图片。
RAF-DB:The Real-world Affective Face Database (RAF-DB)是一个真实世界的数据库,包含29,672张从互联网上下载的高度多样化的面部图像。通过人工众源标注和可靠估计,为样本提供了7个基本情感标签和11个复合情感标签。具体来说,15339幅基本情绪集的图像被分为两组(12,271个训练样本和3,068个测试样本)进行评估。
AffectNet:AffectNet包含超过100万张来自互联网的图片,它们是通过使用与情绪相关的标签查询不同的搜索引擎获得的。它是迄今为止提供两种不同情感模型(分类模型和维度模型)的面部表情的最大数据库,其中45万张图像为8种基本表情手工标注了标签。
ExpW:The Expression in-the-Wild Database (ExpW)包含91,793张人脸图像,使用谷歌图像搜索下载。每一张人脸图像都被手工标注为七个基本表情类别之一。在标注过程中去除非人脸图像。
4DFAB : 4DFAB是一个拥有超过180万张高分辨率3D人脸的大型数据库,它记录了180个受试者在5年的时间里在四个不同的会话中捕捉到的信息。它包含被试自发和姿势的6种基本表情的面部行为的4D动态视频。
3. 深度表情识别
在本节中,我们将描述自动深度挖掘中常见的三个主要步骤,即预处理、深度特征学习和深度特征分类。我们简要总结了每个步骤中广泛使用的算法,并根据参考文献推荐了现有的最佳FER系统实现。
3.1 预处理
与面部表情无关的变化,如不同的背景、照明和头部姿势,在不受约束的场景中相当常见。因此,在训练深度神经网络学习有意义的特征之前,通常需要对人脸传递的视觉语义信息进行对齐和归一化预处理。
3.1.1 人脸对齐
我们列出了一些在deep FER中广泛使用的知名方法和公开可用的人脸对齐实现。给定一系列的训练数据,第一步是检测人脸,然后去除背景和非人脸区域。Viola-Jones (V&J)人脸检测器是一种经典的、被广泛应用的人脸检测实现,它具有鲁棒性,计算简单,用于检测近正面的人脸。
人脸检测是实现特征学习的唯一不可或缺的步骤,而进一步使用局部关键点进行人脸对齐可以显著提高FER性能[14],这一步是至关重要的,因为它可以减少面部大小的变化和面内旋转。表2研究了在深度正则化算法中广泛使用的人脸关键点检测算法,并对它们的效率和性能进行了比较。一般来说,与深度网络相结合的级联回归由于其速度快、精度高,已经成为最流行和最先进的人脸对齐方法。
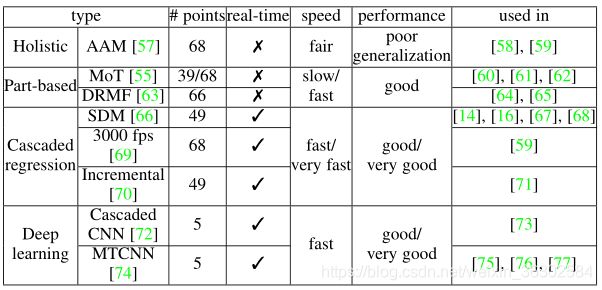
与仅使用一个检测器进行人脸对准不同,一些方法提出了结合多个检测器来更好地进行关键点估计,当处理具有挑战性的无约束环境下的人脸时。Yu等人[53]将三个不同的面部关键点探测器串联起来,互相补充。Kim等人[54]考虑了不同的输入(原始图像和直方图均衡化图像)和不同的人脸检测模型(V&J[52]和MoT[55]),选择面内[56]预测的置信度最高的关键点结果进行人脸对齐
3.1.2 数据增强
深度神经网络需要足够的训练数据来确保对给定识别任务的通用性。然而,大多数公开可用的FER数据库并没有足够数量的图像用于训练。因此,数据增强是深度学习研究的重要步骤。数据增强方法可分为两种类型:实时数据增强和离线数据增强。
通常,动态数据增强被嵌入到深度学习工具包中,以缓解过拟合。在训练过程中,从图像的中心和四角随机裁剪输入样本,然后水平翻转,这样可以得到一个比原始训练数据大十倍的数据集。在测试过程中采用两种常见的预测模式,一种是只使用人脸的中心patch进行预测,另一种是将预测值对所有10种操作结果取平均
除了基本的实时数据增强之外,还设计了各种离线数据增强操作,以进一步扩展数据的大小和多样性。最常用的操作包括随机扰动和变换,例如旋转、移动、倾斜、缩放、噪声、对比和颜色抖动。多种操作的组合可以产生更多训练样本,使网络对人脸偏差和旋转更有鲁棒性。此外,基于深度学习的技术可以应用于数据增强。例如,Li等人创建了一个带有3D卷积神经网络(CNN)的合成数据生成系统,用于创建表情饱和度不同的面孔。生成对抗网络(GAN)[82]还可以通过生成不同姿态和表情的不同外观来增强数据(见4.3.6节)。
3.1.3 人脸正则化
光照和头部姿态的变化会导致图像的巨大变化,从而影响FER的性能。因此,我们引入了两种典型的人脸归一化方法来改善这些变化:光照归一化和姿态归一化。
光照归一化:即使是同一个人的同一表情,在不同的图像中,光照和对比度也会发生变化,特别是在不受约束的环境中,这会导致很大的类内差异。光照归一化可以使用各种算法,如基于各向同性扩散(IS)的归一化、基于离散余弦变换(DCT)的归一化、基于高斯差分(DoG)的归一化和基于同态滤波的归一化[64]、[83]。此外,相关研究表明,直方图均衡化结合光照归一化的人脸识别性能优于单独使用光照归一化的人脸识别性能。deep FER的很多文献研究都采用直方图均衡化来增加图像的全局对比度进行预处理。该方法在背景和前景亮度相似的情况下是有效的。然而,直接应用直方图均衡化可能会过度强调局部对比度。为了解决这个问题,[87]提出了一种将直方图均衡化和线性映射相结合的加权求和方法。
姿态归一化:姿态变化是另一个常见且难以解决的问题。一些研究使用姿势规范化技术来获得FER的正面面部视图,其中最流行的是由Hassner等人提出的。具体来说,在确定了人脸关键点后,生成一个适用于所有人脸的三维纹理模型来估计可见的人脸成分。然后,通过将每个输入人脸图像反向投影到参考坐标系中,合成出初始的正面图像。另外,Sagonas等人提出了一种统计模型,可以同时定位关键点并仅使用正面面孔来转换面部姿态。最近,一系列基于GAN的深度模型被提出用于正面视图的合成,并展现了有前景的性能。
3.2 深度特征学习网络
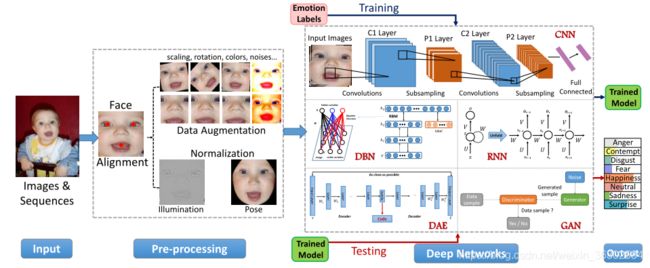
深度学习最近已经成为一个热门的研究课题,并在各种应用中取得了最先进的性能[92]。深度学习试图通过多种非线性转换和表示的层次结构来捕获高层次的抽象。在本节中,我们将简要介绍一些用于FER的深度学习技术。这些深度神经网络的传统架构如图3所示。
3.3 人脸表情分类
在学习了深层特征后,FER的最后一步是将给定的图像分类为一个基本的情感类别。
与传统方法中特征提取步骤和特征分类步骤是独立的不同,深度网络可以以端到端的方式执行FER。具体来说,在网络的末端增加损耗层来调节反向传播误差;然后,网络可以直接输出每个样本的预测概率。在CNN中,softmax是最常用的函数,它使估计的类概率和ground-truth分布之间的交叉熵最小。另外,[93]论证了端到端训练使用线性支持向量机(SVM)的好处,它最大限度地减少了基于边际的损失,而不是交叉熵。同样,[94]研究了深度神经森林(NFs)的适应性[95],它用NFs取代了softmax损失,并为FER取得了具有竞争性的结果。
除了端到端学习方法外,另一种选择是使用深度神经网络(特别是CNN)作为特征提取工具,然后对提取的表示应用额外的独立分类器,如SVM或随机森林。此外,[98]、[99]表明,在DCNN特征上计算协方差描述符,并在对称正定义(SPD)流形上使用高斯核进行分类,比使用softmax层的标准分类效率更高。
4. 先进方法
在本节中,我们首先介绍专门的预训练和微调技巧以及为FER设计的各种网络输入。然后,我们根据数据类型将文献中提出的工作分为两大类:用于静态图像的深度学习FER网络和用于动态图像序列的深度学习FER网络,并讨论了这两大类中提出的不同网络类型。此外,我们提供了当前深FER系统的网络结构和性能方面的概述。
4.1 预训练和微调
如前所述,在相对较小的面部表情数据集上直接训练深度网络容易发生过拟合。为了缓解这一问题,许多研究使用额外的任务导向数据,从零开始对自建网络进行预训练,或在知名的预训练模型(如AlexNet , VGG, VGG-face和GoogleNet)上进行微调。Kahou等人]指出,使用额外的数据可以在不进行过拟合的情况下获得大容量的模型,从而提高FER性能。
为了选择合适的辅助数据,可以选择大规模的人脸识别(FR)数据集或较大的FER数据集。Kaya等人认为,经过FR训练的VGG-Face比为目标识别而开发的ImageNet要好。Knyazev等人观察到的另一个有趣的结果是,在更大的FR数据集上进行预训练可以对情绪识别性能产生积极的影响,进一步使用额外的FER数据集进行微调有助于提高性能。
与直接使用预先训练或微调的模型来提取目标数据集上的特征相比,多级微调策略[67]可以获得更好的性能;在使用FER2013对预训练的模型进行第一阶段微调后,使用目标数据库的训练集(EmotiW)进行第二阶段微调,使模型更适应特定的数据集(即目标数据集)。
尽管对外部FR数据进行预训练和微调可以间接避免训练数据量小的问题,但网络是独立于FER进行训练的,面部主导信息仍然存在于学习特征中,这可能会削弱学习特征的表情识别能力。为了消除这种影响,【68】提出了两阶段训练算法FaceNet2ExpNet。微调的人脸网络作为表情识别网络的一个合适的初始化,仅用于监督卷积层的训练。利用表情信息从零开始训练全连接层,使目标网络的训练规范化。
4.2 网络输入多样化
传统的做法通常使用整个对齐的RGB图像的脸作为网络的输入来学习FER的特征。然而,这些原始数据缺乏重要的信息,如均匀或规则的纹理和图像缩放、旋转、遮挡和光照的不变性,这可能是FER的混淆因素。一些方法采用各种手工特征及其扩展作为网络输入,以加强网络对常见干扰的鲁棒性,并迫使网络更多地关注具有表达信息的面部区域。
底层表征:(1)对给定RGB图像中的小区域特征进行编码,然后将这些特征与局部直方图进行聚类和池化,这对光照变化和小的配准误差具有鲁棒性。(2)一个新的映射LBP特征【79】被提出用于光照不变的FER。尺度不变特征变换(SIFT)【118】对图像进行缩放和旋转,进而获得具有鲁棒性的特征【119】可被用于多视图FER任务。(3)结合轮廓、纹理、角度、颜色等不同的描述符作为输入数据也有助于提高的深层网络性能【58】【120】。
此外,局部表征方法根据目标任务提取特征,从整个图像中去除非关键部件,利用对任务敏感的关键部件。研究指出,三个兴趣区域(ROIs),即眉毛、眼睛和嘴,与面部表情变化密切相关。其他研究提出利用注意力机制自动学习面部表情的关键部分(显著特征)
4.3 用于静态图像的深度人脸表情识别
由于数据处理的便捷性以及相关训练和测试数据的可获得性,现有的大量研究在不考虑时间信息的情况下基于静态图像进行表情识别任务。对于每个最频繁使用的数据集,表3显示了该领域中当前(2018年)最先进的方法。
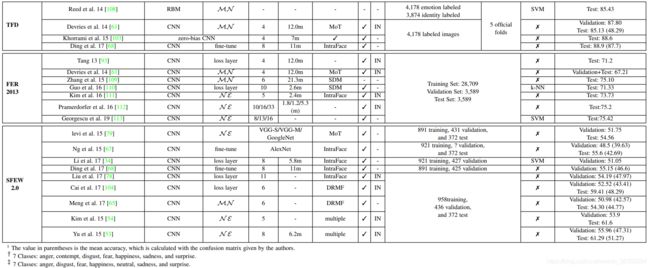
4.3.1 辅助块
基于CNN的基础架构,一些研究提出了添加精心设计的辅助块或层来增强学习特征的表达相关表示能力。
一种新颖的为FER设计的CNN架构HoloNet[88],其中CReLU[128]与残差结构相结合,在不降低效率的情况下增加网络深度,并专门为FER设计了一个起始残差块,用于学习多尺度和表情判别特征。另一个CNN模型,supervised scoring ensemble(SSE)[89],为带加强监督程度,介绍了三种监督模块被嵌入在早期的主流CNN的隐藏层浅、中层和深层监督(见图4)。有趣的是,曾等人[129]指出,不同的FER数据库之间的注释不一致是不可避免的,这导致当合并多个数据集来扩大训练集时会影响性能。为了解决这个问题,作者提出了一种不一致的潜在真相伪注释(Inconsistent Pseudo Annotations to Latent Truth,IPA2LT)框架。在IPA2LT中,设计了一个端到端的可训练LTNet,通过最大化这些不一致注释的对数可能性,从从不同数据集训练的人类注释和机器注释中发现潜在的真相。
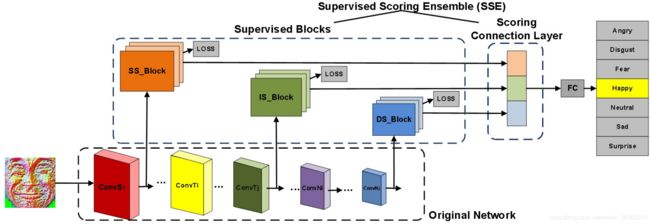
4.3.2 损失层
传统的CNNs的softmax损耗层简单地迫使不同类别的特征保持分离,而在现实条件下,FER不仅类间相似性高,类内差异也大。因此,一些著作提出了新的损失层来缓解这一问题。
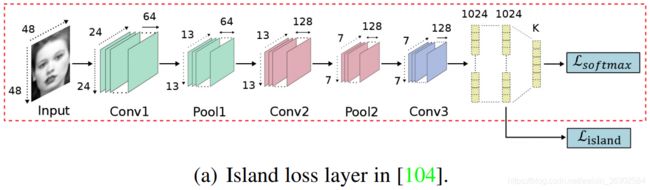
受中心损失(center loss)[130]的启发,即惩罚深层特征与其对应的类中心之间的距离,提出了两种变体来辅助监督softmax损失,以获得更具判别性的特征。在[104]中,隔离损失(island loss)被形式化,以增加不同类中心之间的成对距离(见图5(a))。具体来说,特征提取层计算的island loss和决策层计算的softmax loss被结合来监督CNN的训练。在[34]中,形式化了局部保持丢失(locality-preserving loss,LP loss),将同一类的局部邻近特征拉到一起,使每个表情的类内局部簇更接近。将这种损失与softmax损失进行联合训练,可以极大地增强被学习特征的辨别能力。
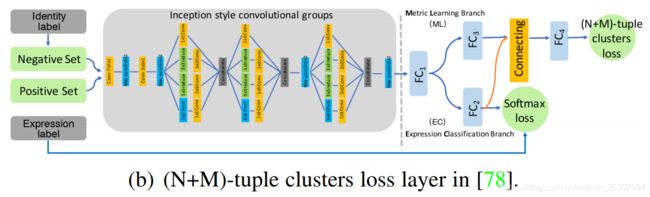
三元组损失(triplet loss)[131]要求一个正例比一个负例更接近锚点,且有固定的间隙。基于此,我们提出了两种变化来替代或协助监督softmax损失。在[110]中,基于指数三元组(exponential triplet-based loss)的损失被形式化,在更新网络时给困难的样本更多的权重。在[78]中,(N+M)元组簇丢失被形式化,以减轻恒等不变FER三元组丢失中锚点选择和阈值验证的难度(见图5(b))。在训练过程中,使用基于身份感知的困难负样本挖掘和在线正样本挖掘两种方法来减少同一表达中身份间的差异。
4.3.3 网络集成
以前的研究表明,多个网络的组合比单个网络的性能更好[132]。在实现网络集成时,需要考虑两个关键因素:(1)网络的多样性保证互补性;(2)适当的融合方法能有效地聚合组合网络。
对于第一个因素,考虑使用不同种类的训练数据和不同的网络参数或架构来生成不同的组合。有几种预处理方法增加网络多样性[111],如(1)变形和归一化;(2)4.2节中描述的方法可以生成不同的数据来训练不同的网络;(3)通过改变滤波器的大小、神经元的数量和网络的层数,并应用多个随机种子进行权值初始化[54],[133];(4)此外,不同的网络结构可以用来增强多样性。例如,[106]将一个有监督的CNN和一个无监督的卷积自动编码器结合。
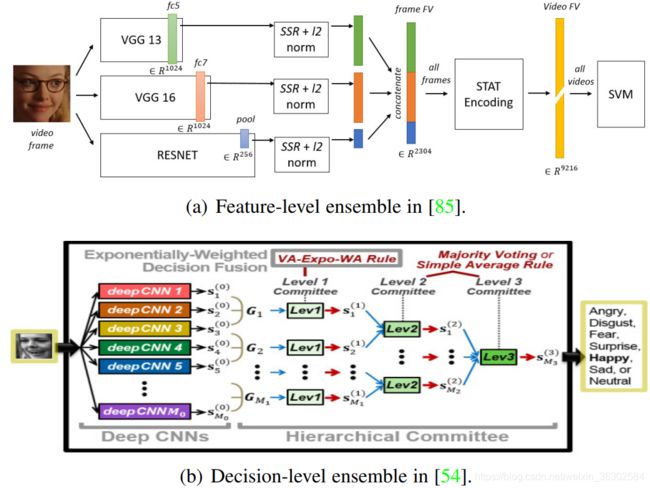
对于第二个因素,组合网络的每个成员都可以在两个不同的层次上融合:特征层和决策层。(1)对于特征级融合,最常用的策略是连接从不同网络学习到的特征[85],[113],[134]。例如[85]将从不同网络学习到的特征连接起来,得到一个单一的特征向量来描述输入图像(见图6(a)),此外,该文献还提出了feature loss[135],将手工制作的feature信息嵌入到训练过程中,为深度学习的feature提供补充信息。(2)对于决策级融合,主要有三种广泛使用的规则:多数投票、简单平均和加权平均。加权平均法认为每个个体有对应的重要性和置信度,许多加权平均方法被提出来寻找网络集成的最优权值集(如随机搜索[60],对数似损失和铰链损失[53],指数加权平均(图6 (b))[54]和可训练的CNN[133])。
4.3.4 多任务网络
许多现有的FER网络只关注单个任务,并学习对表情敏感的特征,而不考虑其他潜在因素之间的相互作用。然而,在现实世界中,FER与各种因素交织在一起,如头部姿势、光照和主体身份(面部形态)。为了解决这一问题,引入了多任务学习,从其他相关任务中转移知识,并消除干扰因素。
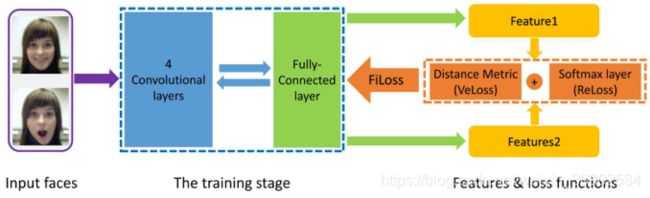 图7 代表性的多任务FER网络。在本文提出的MSCNN[73]中,在训练过程中,将一对图像送入MSCNN。将交叉熵损失的表情识别任务和对比熵损失的人脸验证任务结合起来训练MSCNN,前者学习表情间变化较大的特征,后者减少表情内特征的变化。
图7 代表性的多任务FER网络。在本文提出的MSCNN[73]中,在训练过程中,将一对图像送入MSCNN。将交叉熵损失的表情识别任务和对比熵损失的人脸验证任务结合起来训练MSCNN,前者学习表情间变化较大的特征,后者减少表情内特征的变化。
Reed等[108]构造了一种高阶玻尔兹曼机器(disBM)来学习表情相关因子的流形坐标,并提出了训练解纠缠策略,使与表情相关的隐藏单元对人脸形态具有不变量性。其他研究[61]、[136]提出,将FER与其他任务同时进行,如面部关键点定位和面部AU[137]检测,可以共同提高FER的性能。此外,一些研究[65],[73]采用了多任务学习的身份不变(identity-invariant )FER。在[65]中,提出了一种具有两个相同子CNN的身份感知CNN (IACNN)。一个流使用表情敏感损失(expression-sensitive loss )来识别表情特征,另一个流使用身份敏感损失(identity-sensitive loss)来学习与身份相关的特征来识别身份不变(identity-invariant )的FER。在[73],一个在FER和脸部验证任务监督下训练的多信号CNN(multisignal CNN , MSCNN)被提出,促使模型关注表情信息(图7)。此外,[138]提出了一个一体化的CNN模型,同时解决一系列多样化的分析任务,包括微笑检测。类似的,SmileNet[139]被提出学习人脸检测和微笑识别,它不需要包括人脸检测和注册在内的预归一化步骤。
上面提到的传统监督多任务学习需要为所有任务标记的训练样本。为了解决这个问题,[46]提出了一种新的属性传播方法,即使不同数据集的分布不同可以利用面部表情和其他异构属性之间的固有对应。
4.3.5 级联网络
在级联网络中,针对不同任务的各个模块按顺序组合,形成一个更深层的网络,其中前一个模块的输出被后一个模块利用。相关研究提出,通过组合不同的结构来学习一个特征层次,可以逐渐过滤掉与表达无关的变异因素。
最常见的是,不同的网络或学习方法按顺序和单独结合,每一种都有不同的层次贡献。在[140]中,训练DBNs首先检测面部表情相关区域。然后,这些解析面的组件被堆叠的自动编码器分类。在[141]中,提出了一种多尺度压缩卷积网络(CCNET)来获得局部平移不变(local-translation-invariant, LTI)表示,然后设计了一个收缩式自动编码器,将情感相关因素从主体身份和姿态中分层分离出来。在[101],[102]中,首先使用CNN体系结构学习过完全表示,然后利用多层RBM为FER学习更高级别的特征(见图8)。
Liu等人[13]提出了一种增强DBN (BDBN),在统一的环路状态下迭代地进行特征表示、特征选择和分类器构建,而不是简单地将不同网络的输出连接起来。与无反馈的连接方法相比,这种循环框架将分类错误向后传播,交替地开始特征选择过程,直到收敛。因此,在此迭代过程中,可显著提高对FER的判别能力。
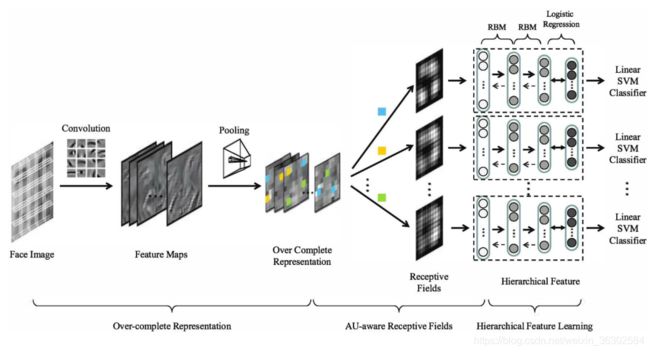 图8 代表性的FER级联网络:AUaware深度网络(AUDN)[101]由三个顺序模型组成,第一个模型训练一个2层CNN,以获得一个编码所有可能位置的所有表情判别变量的超完整表示;第二个模型包含一个au感知的接受域层,用于搜索过完全表示的子集;最后一个模型是一个学习层次特征的多层RBM。
图8 代表性的FER级联网络:AUaware深度网络(AUDN)[101]由三个顺序模型组成,第一个模型训练一个2层CNN,以获得一个编码所有可能位置的所有表情判别变量的超完整表示;第二个模型包含一个au感知的接受域层,用于搜索过完全表示的子集;最后一个模型是一个学习层次特征的多层RBM。
4.3.6 生成对抗网络
近年来,基于GAN的方法已成功地应用于图像合成中,生成真实面孔、数字和各种各样的图像类型,这有利于训练数据的增强和相应的识别任务。
一些著作提出了新的基于GAN的恒等不变FER模型。对于位姿不变的FER, Lai等[142]提出了一种基于GAN的人脸正面化框架,其中生成器在保留身份和表情特征的同时对输入人脸图像进行正面化,识别器将真实图像与生成的正面人脸图像进行区分。Zhang等人[143]提出了一种基于GAN的模型,可以在多视角下生成任意姿态下具有不同表情的图像。对于恒等不变的FER, yang等[144]提出了一种由两部分组成的恒等自适应生成(IA-gen)模型。上半部分使用cGANs生成同一主体不同表情的图像。然后,下半部分对每个单身份子空间进行FER,不涉及其他个体;因此,身份变异可以很好地缓解。Chen等人[145]提出了一种保护隐私的表示学习变分GAN (PPRL-VGAN),它结合了V AE和GAN来学习一种身份不变的表示,该表示明确地从身份信息中分离出来,并生成用于保持表情的人脸图像合成。yang等人[105]提出了一种用于探索表达信息的反表达残余学习(deexpression residual learning, DeRL)方法,该方法在反表达过程中被过滤掉,但仍然嵌入到生成器中。然后,模型从生成器中直接提取这些信息,以减轻主题变化的影响,并提高FER性能。
4.3.7 讨论
现有构建良好的deep FER系统主要关注两个关键问题:缺乏丰富多样的训练数据和与表情无关的变化,如照明、头部姿势和身份。表4显示了这些不同类型方法在两个开放问题(数据大小需求和表情无关的变化)和其他重点(计算效率、性能和网络训练的难度)方面的相对优势和劣势。
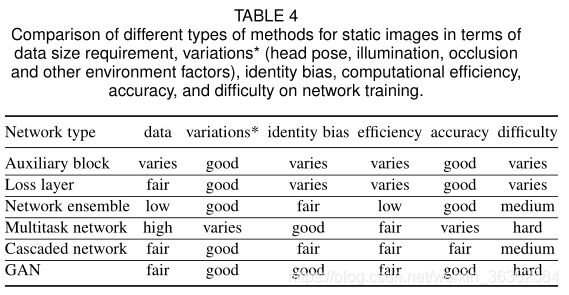
针对FER专门设计了各种辅助块和损耗层,取代了目前流行的网络架构,提高了网络的监督程度,并学习了更强大的特征,具有区分类间可分性和类内紧凑性。但是,额外的块可能会影响整个网络的计算效率。它需要时间来学习新的损失的额外超参数,并在不同的损失层之间找到适当的权衡。
训练具有大量隐含层和灵活过滤器的深度宽网络是学习对目标任务具有区分性的深度高级特征的有效方法。然而,这个过程容易受到训练数据的影响,如果没有足够的训练数据来学习新的参数,则可能表现不佳。将多个相对较小的网络并联或串联起来是克服这一问题的自然研究方向。网络集成是将不同的网络在特征或决策层面上进行集成,以结合它们的优势,通常用于情感竞赛中以提高性能。然而,设计不同类型的网络来相互补偿,明显地增加了计算成本和存储需求。此外,每个子网的权值通常是根据原始训练数据的性能来学习的,导致对新出现的测试数据过拟合。多任务网络考虑目标FER任务与其他次要任务(如人脸关键点定位、人脸非标区识别和人脸验证)之间的交互作用,联合训练多个网络;这样,就可以很好地分离出与表达无关的因素,包括身份偏见。这种方法的缺点是,它需要所有任务的标记数据,而且随着涉及的任务越来越多,训练变得越来越麻烦。或者,级联网络以分层的方式依次训练多个网络,这样学习到的特征的判别能力就会不断增强。总的来说,该方法可以缓解过拟合问题,并逐步分离出与面部表情无关的因素。一个值得考虑的不足是,目前大多数级联系统的子网都是单独训练,没有反馈,对于提高训练效果和性能[13],端到端训练策略更可取。
理想情况下,深度网络,尤其是cnn,擅长解决头部姿态的变化,但目前大多数FER网络还没有明确解决这些变化,也没有在现实条件下进行测试。生成对抗网络(GANs)可以通过在保留表情特征的同时正面化人脸图像来解决这个问题[142],或者合成任意姿态来帮助训练姿态不变网络[143]。gan的另一个优点是,通过生成相应的中性人脸图像[105]或合成不同的表情,可以明确地解开身份变化,同时为身份不变的FER保留身份信息[144]。此外,gan可以帮助增加训练数据的规模和多样性。gan的主要缺点是训练的不稳定性和视觉质量和图像多样性之间的权衡。
4.4 用于动态图像序列的深度FER网络
虽然以前的模型大多集中在静态图像上,但FER可以从序列中连续帧的时间相关性中获益。我们首先介绍了现有的帧聚合技术,将从静态FER网络中学习到的深度特征战略性地结合起来。然后,考虑到在视频流中,人们通常以不同的强度显示相同的表情,我们进一步回顾了使用不同表达强度状态的图像进行强度不变FER的方法。最后,我们引入深度FER网络,该网络考虑视频帧中的时空运动模式和从时间结构中提取的学习特征。对于每个最频繁评估的数据集,表5显示了在个人独立协议中执行的当前最先进的方法。
4.4.1 帧聚合
因为给定视频剪辑中的帧可能在表达强度上有所不同,直接测量每帧的错误不会产生令人满意的性能。为了提高性能,人们提出了各种方法来聚合每个序列中帧的网络输出。我们将这些方法分为两类:决策级框架聚合和特征级框架聚合。
在决策级帧聚合中,对序列中每一帧的n类概率向量进行集成。最方便的方法是直接连接这些帧的输出。然而,每个序列中的帧数可能不同。我们考虑了两种聚合方法来为每个序列[60]生成固定长度的特征向量[146]:帧平均和帧扩展。另一种不需要固定帧数的方法是应用统计编码。平均、最大、平方的平均、最大抑制向量的平均等等都可以用来总结每个序列中的执行帧概率。
特征级帧聚合是对序列中帧学习到的特征进行聚合。该方案可以应用许多基于统计的编码模块。一种简单而有效的方法是在所有帧上连接特征的均值、方差、最小值和最大值[85]。或者,基于矩阵的模型,如特征向量、协方差矩阵和多维高斯分布也可以用于聚合[147],[148]。此外,多实例学习也被用于视频级表示[149],其中聚类中心由辅助数据计算,然后为每个视频帧袋获得词袋表示。
4.4.2 表情强度不变网络
大多数方法(在4.3节中介绍)侧重于识别峰值高强度表情,而忽略了细微的低强度表情。在本节中,我们介绍表情强度不变网络,该网络以不同强度的训练样本作为输入,从不同强度的序列中挖掘表情之间的内在相关性。
在表情强度不变网络中,使用带有强度标签的图像帧进行训练。在测试过程中,使用不同表达强度的数据来验证网络的强度不变能力。Zhao等人[17]提出了一种峰导深度网络(peak- guided deep network, PPDN),该网络以一对具有相同表情和主体身份的峰和非峰图像作为输入,利用l2范数损失来最小化两幅图像之间的距离。在反向传播过程中,提出了峰梯度抑制(peak gradient suppression, PGS),使非峰表情的学习特征向峰表情的学习特征转变,同时避免了反向传播。因此,可以提高网络对低强度表情的判别能力(见图9)。Y u等人[75]提出了一种更深级联峰导网络(DCPN),该网络使用更深更大的架构来提高学习到的表示的鉴别能力,并采用了一种称为级联微调的集成训练方法来避免过拟合。在[71]中,使用了更多的强度状态(onset, onset to apex transition, apex, apex to offset transition and offset),并采用了5个loss function来调节网络训练,最小化表达分类错误、类内表达变异、强度分类错误和强度内变异。编码中等强度。
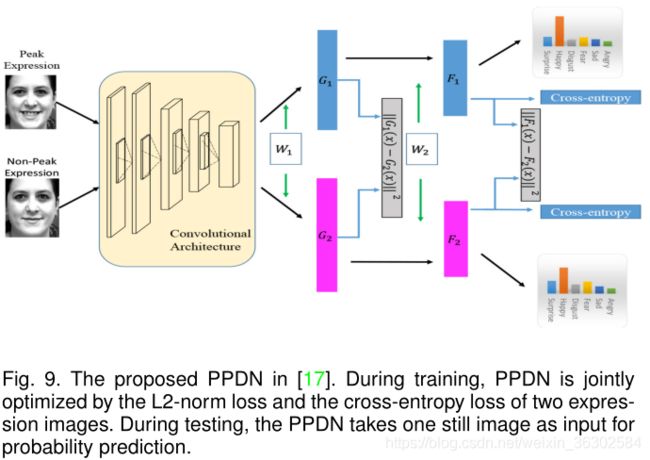
考虑到现实世界中并不总是有不同表达强度的图像,已有多篇作品提出自动获取强度标签或生成具有目标强度的新图像。例如,在[159],峰值和中性帧序列的自动选择两个阶段:一个集群阶段把所有帧分成其药效组和中性组使用k - means算法和分类阶段检测峰值和中性帧使用semisupervised SVM。在[150]中,通过两个步骤提出了一个深度生成对比模型:一种生成器,通过卷积编码器-解码器和对比网络为每个样本生成参考(非表情)人脸,通过对比度量损失和监督重建损失共同过滤掉与表情无关的信息。
4.4.3 深度时空FER网络
虽然帧聚合可以集成视频序列中的帧,但关键的时间依赖性没有被明确地利用。相比之下,时空FER网络在不了解表达强度的前提下,将时间窗口中的一系列帧作为独立的输入,利用纹理和时间信息对更细微的表达进行编码。
RNN和C3D: RNN通过挖掘连续数据的特征向量在语义上是相互联系的,因此相互依赖的这一事实,可以从序列中稳健地获取信息。改进的LSTM可以灵活地处理变长度的顺序数据,计算成本更低。由RNN推导而来的RNN由ReLUs组成并初始化为单位矩阵(IRNN)[160],用来提供一个简单的机制来解决爆炸和消失梯度问题[84]。双向rnn (brnn)[161]被用于学习原始方向和反向方向的时间关系[73],[155]。最近,提出了一种嵌套LSTM[77],包含两个子LSTM。即T-LSTM对学习到的特征的时间动态进行建模,C-LSTM对所有T-LSTM模型的输出进行整合,获得多级表示。[162]采用二维网格卷积的ConvLSTM编码空间相关性,并为输入表情序列建立时空关系模型。
与RNN相比,CNN更适合于计算机视觉应用;因此,其派生的C3D[163]使用沿时间轴共享权值的3D卷积核来代替传统的2D核,已被广泛用于基于动态的FER(如[76],[81],[157],[162],[164],[165])来捕获时空特征。在C3D的基础上,针对FER设计了许多衍生结构。在[166]中,3D CNN与dpm启发的[167]变形面部动作约束相结合,以同时编码动态运动和基于鉴别部位的表示。在[16]中,提出了一种深度时序外观网络(DTAN),该网络采用三维滤波器,不沿时间轴共享权值;因此,每个过滤器的重要性随时间而变化。同样,我们提出了一种加权C3D[158],从每个序列中提取多个连续帧的窗口,并根据它们的预测分数进行加权。[168]没有直接使用C3D进行分类,而是使用C3D进行时空特征提取,然后与DBN级联进行预测。在[169]中,C3D也被用作特征提取器,然后是一个NetVLAD层[170],通过学习聚类中心来聚合运动特征的时间信息。
面部标志性轨迹:相关的心理学研究表明,表情会被特定面部部位(如眼睛、鼻子和嘴)的动态运动激活,这些部位包含最能描述表情的信息。为了获得更准确的FER面部动作,提出了面部关键点轨迹模型,从连续帧中捕捉面部成分的动态变化。
提取关键点轨迹表示,最直接的方法是将人脸关键点点的坐标随着时间的推移进行归一化,为每个序列[16]生成一维的轨迹信号,或者形成类似图像的地图作为CNN的输入[155]。此外,每个关键点在连续帧内的相对距离变化也可以用来捕获时间信息[171]。此外,一种基于部分的模型根据面部的物理结构将面部关键点分为若干部分,然后分别分层次地送入网络,被证明对局部低层次和全局高层次特征编码都是有效的73。而不是单独提取轨迹特性,然后输入到网络,Hasani等。[153]将轨迹特性代替快捷的剩余单位原来的3 d Inception-ResNet elementwise乘法的面部关键点和输入剩余单位的张量。因此,基于关键点的网络可以端到端进行训练。
级联网络:通过结合强大的感知视觉表征的力量从cnn LSTM变长输入和输出,多纳休等。[172]提出了时空上深度模型的输出级联cnn与LSTMs各种视觉任务涉及时变输入和输出。与这种混合网络类似,许多级联网络也被提出用于FER(如[71]、[157]、[162]、[173])。
除了将LSTM与CNN的全连接层连接起来,一个基于超列的系统[174]提取最后一个卷积层特征作为LSTM的输入,在不丢失全局相干性的情况下实现更长的距离依赖性。大多数CNN-LSTM方法训练模型需要预测等待直到完整序列可用,可能导致测试时间延迟。因此[175]提出了一种利用部分表达序列学习时空特征并获得更高识别率的在线预测网络。
除了CNN,其他网络框架也可以用来学习空间特征,如卷积稀疏自编码器[176]、3D incep- resnet (3DIR)[153]和加权C3D[158]。同样,在LSTM的基础上,采用条件随机场模型[59]来区分输入序列的时间关系。
整体网络:动作识别的二束CNN视频,训练一个流的多帧上的CNN密集的时间信息和其他光学流流CNN的外观特性的静态图像融合两个流的输出,介绍了由Simonyan et al。[177]。受此体系结构的启发,提出了几种用于FER的网络集成模型。
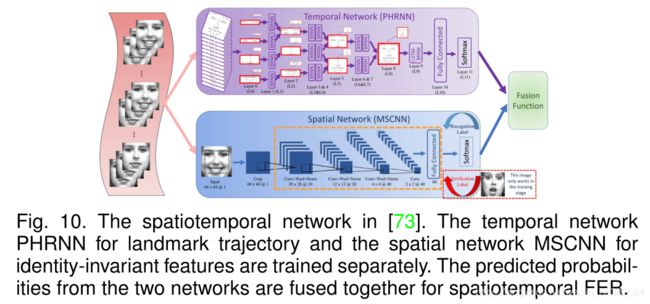
Sun等[151]提出了一种多通道网络,从表达情绪的人脸中提取空间信息,从情绪和中性人脸之间的变化中提取时间信息(光流),并研究了三种特征融合策略:评分平均融合、基于支持向量机的融合和基于神经网络的融合。Zhang等[73]将时间网络PHRNN(在“Landmark trajectory”中讨论)和空间网络MSCNN(在4.3.4中讨论)融合,提取FER的部分-整体、几何-外观、静态-动态信息(见图10)。而不是直接融合网络输出与预先计算的重量,可能会导致过度拟合问题在测试阶段,荣格等。[16]提出了一种联合共同训练DTAN微调方法(“RNN C3D”中讨论),在DTGN(在讨论“里程碑式的轨迹”)和集成网络,优于加权和策略。
4.4.4 讨论
在现实世界中,人们的面部表情呈现是一个动态的过程,从细微到明显,对序列/视频数据进行FER已经成为一种趋势。表6总结了不同类型的动态数据处理方法在表示时空信息的能力、对训练数据大小和帧长度(可变或固定)的要求、计算效率和性能等方面的相对优点。
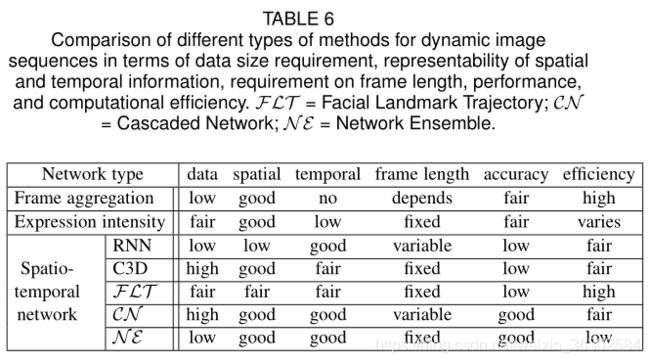
采用帧聚合的方法,将学习到的每个帧的特征或预测概率组合成一个序列级的结果。每个帧的输出可以简单地连接(每个序列需要固定长度的帧)或统计聚合以获得视频级表示(可变长度的帧可处理)。该方法计算简单,在目标数据集的时间变化不复杂的情况下可以获得中等的性能。
表情强度不变网络根据视频序列中表情强度随时间变化的特点,考虑了非峰表情图像,进一步利用了峰和非峰表情之间的动态相关性。通常,需要特定强度状态的图像帧进行强度不变的FER。
尽管这些方法具有优势,但帧聚合处理帧时不考虑时间信息和细微的外观变化,而表达强度不变的网络需要表达强度的先验知识,这在现实场景中是不可用的。相比之下,深度时空网络的设计目的是在连续帧中编码时间依赖关系,并已被证明受益于学习空间特征与时间特征结合。RNN及其变体(如LSTM、IRNN和BRNN)和C3D是学习时空特征的基础网络。然而,这些网络的性能勉强令人满意。RNN无法捕获强大的卷积特征。C3D中的3D过滤器应用于非常短的视频剪辑,忽略了长期的动态。此外,训练如此庞大的网络是一个计算问题,特别是对于视频数据不足的动态FER。另一种方法是基于面部形态变化的物理结构提取形状特征,捕捉动态的面部成分活动,然后应用深度网络进行分类。该方法计算简单,能够消除光照变化。然而,该算法对配准误差敏感,需要精确的人脸关键点检测,而在无约束条件下很难实现。因此,该方法性能较差,更适合于补充外观表示。利用网络集成对多个网络进行时空信息训练,最后对网络输出进行融合。光流和面部关键点轨迹可以作为时间表征来协作空间表征。该框架的缺点之一是光流或关键点轨迹矢量的预计算和存储消耗。大多数相关研究随机选择定长视频帧作为输入,导致有用的时间信息丢失。级联网络首先提取面部表情图像的判别表示,然后将这些特征输入序列网络,以加强时间信息的编码。但是,该模型引入了额外的参数来捕获序列信息,并且目前工作中的特征学习网络(如CNN)和时间信息编码网络(如LSTM)没有联合训练,可能导致参数设置不理想。以端到端方式进行培训仍然任重道远。
与静态数据上的深度网络相比,表3和表5显示了深度时空网络的强大能力和流行趋势。例如,在广泛评估的基准上(如CK+和MMI)的比较结果表明,基于序列数据和分析帧之间的时间依赖性的训练网络可以进一步提高性能。此外,在2015年EmotiW挑战赛中,只有一个系统在FER中使用了深度空间网络,而在2017年EmotiW挑战赛中,7个被评审的系统中有5个依赖于这种网络。
5. 其他未决问题
除了上面回顾的最流行的基本表情分类任务外,我们还进一步介绍了一些依赖于深度神经网络和原型表情相关知识的相关问题。
5.1 咬合非额头姿势
遮挡和非额头姿势可能会改变原始面部表情的视觉外观,是自动FER的两个主要障碍,特别是在现实场景中。
对于面部遮挡,Ranzato等人[178]提出了一种深度生成模型,使用dbn建模像素级特征。Cheng等人[179]采用多层rbm结合预处理和微调过程来压缩遮挡面部的特征。Xu等人[180]将两个具有相同结构但在不同数据集上预训练的高阶学习特征连接起来。最近,Li等人[126]提出了一种具有注意机制(ACNN)的CNN,该CNN可以感知人脸的遮挡区域,并聚焦于最具区别性的未遮挡区域。
对于多视角FER, Zhang等人[119]在CNN中引入了投影层,该投影层通过在二维SIFT特征矩阵中加权不同的面部关键点来学习鉴别特征,而不需要人脸姿态估计。Liu等人[181]提出了一种多通道姿态感知CNN (MPCNN),该CNN包含三个级联部分,通过最小化姿态和表情识别的条件关节损失来预测表情标签。此外,[142]、[143]采用生成对抗网络(generative adversarial network, GAN)技术生成任意姿态下不同表情的人脸图像用于多视角FER。
5.2 三维静态和动态数据的FER
尽管2D FER取得了重大进展,但它未能解决两个主要问题:光照变化和姿态变化[28]。3D FER使用带有深度信息的3D面部形状模型,可以捕捉细微的面部变形,对于姿态和灯光变化具有天然的鲁棒性。
深度图像和视频[182],[183]根据距离深度相机的距离记录面部像素的强度,其中包含面部几何关系的关键信息。为了强调面部表情运动的动态变形模式,[184]利用动态几何图像网络探索了4D FER (3D FER using dynamic data)。此外,[185]提出了使用CNN从图像强度中估计三维表达系数,而不需要人脸关键点检测。因此,该模型对极端的外观变化具有高度的鲁棒性,包括面外头部旋转、缩放变化和遮挡。为了进一步增强对姿态变化的鲁棒性,[186]提出了一种快速和光流形CNN,增强几何表示,突出表情的形状特征。
近年来,越来越多的作品倾向于结合2D和3D数据来提高性能。Oyedotun等[187]利用CNN从RGB和深度地图潜模中联合学习面部表情特征。Li等人[188]提出了一种深度融合CNN来探索多模态2D+3D FER。具体来说,首先从三维人脸扫描图中提取出6种二维人脸属性图,然后联合输入特征提取和特征融合子网,学习二维和三维人脸表征的最优组合权重。为了改进这项工作,[189]提出了从纹理和深度图像中提取的不同面部部位提取深度特征,然后将这些特征融合在一起,通过反馈将它们连接起来。
5.3 面部表情合成
真实感面部表情合成是一个研究热点,它可以为交互界面生成多种面部表情。Susskind等人[190]证明,DBN有能力捕获表现性外观的大范围变化,可以在大型但标记稀疏的数据集上进行训练。基于这项工作,[178],[191],[192]使用无监督学习的DBN构建面部表情合成系统。Kaneko等人[115]提出了一种具有状态识别和关键点定位的多任务深度网络,自适应地产生视觉反馈来改善FER。随着深度生成模型(deep generative adversarial models,如变分自编码器(variational autoencoders, V AEs)、对抗式自编码器(generative adversarial autoencoders, AAEs)和生成式对抗网络(generative adversarial networks, GANs)的成功,一系列基于这些模型的面部表情合成系统(如[193]、[194]、[195]、[196]、[197]和[198])被开发出来。面部表情合成也可以用于数据增强,而无需人工收集和标记大型数据集。Masi等人[199]通过增加特定面部的外观变化,如3D纹理人脸模型中的表情,利用CNN合成新的人脸图像。
5.4 可视化技术
除了利用CNN拿来,几个作品(例如,[103],[200],[201])采用可视化技术[202]在学会了CNN特性定性分析CNN拿来的外貌的学习过程,有助于定性解读部分面临产量最歧视的信息。反卷积结果均表明,学习到的特征上的某些特定滤波器的激活与人脸区域对应的人脸区域具有很强的相关性。
5.5 其他新问题
我们进一步讨论了在原型表达类别的基础上已经探讨的几个需要更广泛探索的新问题。FG2017挑战[203]研究了显性情绪和互补情绪,以识别比基本情绪更详细的情绪,并观察不同的显性情绪如何影响互补情绪的识别。在ChaLearn Looking at People挑战[204]中已经研究了真实与虚假表达情绪识别,以确定一种情绪是否是虚假的。深度学习技术已经被这两个挑战的参与者(例如,[205],[206],[207])彻底应用。最近,人脸表情相似性问题(更好地模仿人类视觉偏好)在[208]中被探索,用于开发各种应用,如表情检索和情感识别。
6. 挑战与未来方向
6.1 面部表情数据集
随着FER文献的研究重心转移到具有挑战性的野外环境条件,许多研究者致力于利用深度学习技术来解决诸如光照变化、遮挡、非额位姿态、身份偏差和低强度表情的识别等难题。鉴于FER是一项数据驱动的任务,而训练一个深度足够的网络来捕捉与表情相关的微妙变形需要大量的训练数据,深度FER系统面临的主要挑战是在数量和质量上都缺乏训练数据。
由于不同年龄、文化和性别的人以不同的方式展示和解释面部表情,理想的面部表情数据集应该包括丰富的样本图像,并具有精确的面部属性标签,不只是表情,还包括年龄、性别和种族等其他属性,这将促进使用深度学习技术,如多任务深度网络和迁移学习等跨年龄、跨性别和跨文化FER的相关研究。此外,尽管遮挡和多姿态问题在深度人脸识别领域得到了相对广泛的关注,但遮挡鲁棒和姿态不变问题在深度人脸识别领域受到的关注较少。其中一个主要原因是缺乏足够的具有遮挡类型和头部姿态标注的面部表情数据集。
另一方面,对自然场景变化大、复杂的大量图像数据进行准确标注,是构建表达数据集的明显障碍。一种合理的方法是在专家注释者的指导下采用众包模型[34],[45],[209]。此外,一个由专家精制的全自动标记工具[43]是提供近似但有效注释的替代方案。在这两种情况下,后续可靠的估计或标记学习过程是必要的,以过滤噪声注释。特别是,最近很少有考虑现实世界场景并包含广泛面部表情的相对大规模数据集公开可用,即EmotioNet [43], RAFDB[34],[44]和AffectNet[45],我们预计随着技术的进步和互联网的普及,构建更多互补的面部表情数据集,促进深度FER的发展。
6.2 数据集偏倚和不均衡分布
由于不同的采集条件和标注的主观性,不同的面部表情数据集之间存在着数据偏差和标注不一致的现象。最近的研究通常在特定的数据集中评估他们的算法,可以获得令人满意的性能[210]。然而,通过数据库内部协议评估的算法缺乏对看不见的测试数据的通用性,由于现有的差异,跨数据集设置的性能大大恶化。此外,由于表情标注不一致,直接合并多个数据集来扩大训练数据时,FER性能无法持续提高[129]。跨数据库性能是评价FER系统通用性和实用性的重要标准。深度领域适应和知识提炼是解决这一偏见的有希望的趋势[211],[212]。
另一个常见的问题是面部表情中类别分布不平衡,这是样本获取实用性的结果。例如,收集和注释一张笑脸很简单;然而,识别厌恶、恐惧和其他不太常见的表达的信号可能非常困难。如表3和表5所示,与准确性标准相比,平均精度(对所有类别分配相同的权重)评估的性能下降,这种下降在真实数据集(如SFEW 2.0和AFEW)中尤其明显。一种解决方案是在预处理阶段使用数据增强和合成,根据每个类的样本数量重新采样并平衡类分布[213]。另一种选择是开发一个成本敏感的损失层,以便在网络培训期间重新加权。
6.3 结合其他情感模式
另一个需要考虑的主要问题是,虽然分类模型中的FER已经得到了广泛的承认和研究,但原型表达的定义只涵盖了特定类别的一小部分,并不能捕获现实互动的全部表达行为。另外两个模型被开发出来描述更大范围的情感场景:FACS模型[10][137]结合了各种面部肌肉AUs来描述面部表情的可见外观变化,而维度模型[11][214]提出了两个连续值变量,即效值和唤醒值,来连续编码情绪强度的微小变化。另一种新的定义,即复合表情,是由Du等人提出的,他认为几种面部表情实际上是一种以上基本表情的组合。这些作品改善了面部表情的表征,在一定程度上补充了范畴模型。
例如,如上所述,cnn的可视化结果表明,学习到的表征与AUs定义的面部区域之间存在一定的一致性。因此,我们可以设计深度神经网络过滤器,根据不同面部肌肉动作部位的重要程度来分配不同的权重。此外,作为处理连续数据的一种更自然的方式,情感维度模型的组合将变得更加相关。深度学习研究的另一个当前方向是基于视觉注意的网络,它可以通过注意机制突出与auc最相关的区域,并允许模型学习表情辨别表征。
6.4 多模态情感识别
最后,在现实应用中,人类的表达行为涉及到不同角度的编码,面部表情只是其中一种形态。随着社交媒体和用户生成内容的发展,大量的数据由用户从各种平台上传,如文本(如Twitter和Facebook),图像(如Flickr和Instagram),音频(如podcast)和视频(如Y ouTube)。多模态情感分析在处理这些不同的模态和分析人类对某个实体的看法(通常是积极的或消极的)方面越来越受欢迎[215],[216]。
近年来,多模态情感分析方法以深度神经网络为核心,提出了多种不同的多传感器数据融合方法。融合方法一般分为决策级融合和特征级融合[217]。在决策级融合中,不同模型的结果将在后期聚合在一起。在特征级融合中,每个模态的特征在早期是独立提取的,然后联合起来形成一个完整的表示。例如,CNN with multiple kernel learning (MKL)[218],[219]被用来融合声学、视觉和文本特征。其他相关研究建议探索不同模态之间的相互作用,从而在多模态分析中获得更好的性能。例如,[220]使用词级模态融合将每个词与相应的视频帧和音频片段对齐。并且[221]提出了一个张量融合网络来同时建模模态内和模态间的动力学。最近,[222]将从每个情态中提取的特征投影到一个四维情感空间中,并使用卷积模糊情感分类器预测情感空间中特定情感的程度。因此,复杂的部分情绪可以以较低的计算复杂度可视化。
此外,由于人脸表情具有很强的互补性和良好的人机交互(HCI)应用价值,红外图像、三维人脸模型深度信息和生理数据的融合正成为一个有前景的研究方向。
参考文献
[1] C. Darwin and P . Prodger, The expression of the emotions in man and animals. Oxford University Press, USA, 1998.
[2] Y .-I. Tian, T. Kanade, and J. F. Cohn, “Recognizing action units for facial expression analysis,” IEEE Transactions on pattern analysis and machine intelligence, vol. 23, no. 2, pp. 97–115, 2001.
[3] P . Ekman and W. V . Friesen, “Constants across cultures in the face and emotion.” Journal of personality and social psychology, vol. 17, no. 2, pp. 124–129, 1971.
[4] P . Ekman, “Strong evidence for universals in facial expressions: a reply to russell’s mistaken critique,” Psychological bulletin, vol. 115, no. 2, pp. 268–287, 1994.
[5] D. Matsumoto, “More evidence for the universality of a contempt expression,” Motivation and Emotion, vol. 16, no. 4, pp. 363–368, 1992.
[6] R. E. Jack, O. G. Garrod, H. Y u, R. Caldara, and P . G. Schyns, “Facial expressions of emotion are not culturally universal,” Proceedings of the National Academy of Sciences, vol. 109, no. 19, pp. 7241–7244, 2012.
[7] Z. Zeng, M. Pantic, G. I. Roisman, and T. S. Huang, “A survey of affect recognition methods: Audio, visual, and spontaneous expressions,” IEEE transactions on pattern analysis and machine intelligence, vol. 31, no. 1, pp. 39–58, 2009.
[8] E. Sariyanidi, H. Gunes, and A. Cavallaro, “Automatic analysis of facial affect: A survey of registration, representation, and recognition,” IEEE transactions on pattern analysis and machine intelligence, vol. 37, no. 6, pp. 1113–1133, 2015.
[9] B. Martinez and M. F. V alstar, “Advances, challenges, and opportunities in automatic facial expression recognition,” in Advances in Face Detection and Facial Image Analysis. Springer, 2016, pp. 63–100.
[10] P . Ekman, “Facial action coding system (facs),” A human face, 2002.
[11] H. Gunes and B. Schuller, “Categorical and dimensional affect analysis in continuous input: Current trends and future directions,” Image and Vision Computing, vol. 31, no. 2, pp. 120–136, 2013.
[12] C. Shan, S. Gong, and P . W. McOwan, “Facial expression recognition based on local binary patterns: A comprehensive study,” Image andVision Computing, vol. 27, no. 6, pp. 803–816, 2009.
[13] P . Liu, S. Han, Z. Meng, and Y . Tong, “Facial expression recognition via a boosted deep belief network,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2014, pp. 1805–1812.
[14] A. Mollahosseini, D. Chan, and M. H. Mahoor, “Going deeper in facial expression recognition using deep neural networks,” in Applications of Computer Vision (WACV), 2016 IEEE Winter Conference on. IEEE, 2016, pp. 1–10.
[15] G. Zhao and M. Pietikainen, “Dynamic texture recognition using local binary patterns with an application to facial expressions,” IEEE trans- actions on pattern analysis and machine intelligence, vol. 29, no. 6, pp. 915–928, 2007.
[16] H. Jung, S. Lee, J. Yim, S. Park, and J. Kim, “Joint fine-tuning in deep neural networks for facial expression recognition,” in Computer Vision (ICCV), 2015 IEEE International Conference on. IEEE, 2015, pp. 2983–2991.
[17] X. Zhao, X. Liang, L. Liu, T. Li, Y . Han, N. V asconcelos, and S. Yan, “Peak-piloted deep network for facial expression recognition,” in European conference on computer vision. Springer, 2016, pp. 425–442.
[18] C. A. Corneanu, M. O. Simón, J. F. Cohn, and S. E. Guerrero, “Survey on rgb, 3d, thermal, and multimodal approaches for facial expression recognition: History, trends, and affect-related applications,” IEEE transactions on pattern analysis and machine intelligence, vol. 38, no. 8, pp. 1548–1568, 2016.
[19] R. Zhi, M. Flierl, Q. Ruan, and W. B. Kleijn, “Graph-preserving sparse nonnegative matrix factorization with application to facial expression recognition,” IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), vol. 41, no. 1, pp. 38–52, 2011.
[20] L. Zhong, Q. Liu, P . Yang, B. Liu, J. Huang, and D. N. Metaxas, “Learning active facial patches for expression analysis,” in Computer Vision and Pattern Recognition (CVPR), 2012 IEEE Conference on. IEEE, 2012, pp. 2562–2569.
[21] I. J. Goodfellow, D. Erhan, P . L. Carrier, A. Courville, M. Mirza, B. Hamner, W. Cukierski, Y . Tang, D. Thaler, D.-H. Lee et al., “Challenges in representation learning: A report on three machine learning contests,” in International Conference on Neural Information Processing. Springer, 2013, pp. 117–124.
[22] A. Dhall, O. Ramana Murthy, R. Goecke, J. Joshi, and T. Gedeon, “Video and image based emotion recognition challenges in the wild: Emotiw 2015,” in Proceedings of the 2015 ACM on International Conference on Multimodal Interaction. ACM, 2015, pp. 423–426.
[23] A. Dhall, R. Goecke, S. Ghosh, J. Joshi, J. Hoey, and T. Gedeon, “From individual to group-level emotion recognition: Emotiw 5.0,” in Proceedings of the 19th ACM International Conference on Multimodal Interaction. ACM, 2017, pp. 524–528.
[24] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classifica- tion with deep convolutional neural networks,” in Advances in neural information processing systems, 2012, pp. 1097–1105.
[25] K. Simonyan and A. Zisserman, “V ery deep convolutional networks for large-scale image recognition,” arXiv preprint arXiv:1409.1556, 2014.
[26] C. Szegedy, W. Liu, Y . Jia, P . Sermanet, S. Reed, D. Anguelov, D. Erhan, V . V anhoucke, and A. Rabinovich, “Going deeper with convolutions,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 1–9.
[27] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778.
[28] M. Pantic and L. J. M. Rothkrantz, “Automatic analysis of facial expressions: The state of the art,” IEEE Transactions on pattern analysis and machine intelligence, vol. 22, no. 12, pp. 1424–1445, 2000.
[29] B. Fasel and J. Luettin, “Automatic facial expression analysis: a survey,” Pattern recognition, vol. 36, no. 1, pp. 259–275, 2003.
[30] P . V . Rouast, M. Adam, and R. Chiong, “Deep learning for human affect recognition: Insights and new developments,” IEEE Transactions on Affective Computing, pp. 1–1, 2019.
[31] M. F. V alstar, M. Mehu, B. Jiang, M. Pantic, and K. Scherer, “Meta- analysis of the first facial expression recognition challenge,” IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), vol. 42, no. 4, pp. 966–979, 2012.
[32] P . Lucey, J. F. Cohn, T. Kanade, J. Saragih, Z. Ambadar, and I. Matthews, “The extended cohn-kanade dataset (ck+): A complete dataset for action unit and emotion-specified expression,” in Computer Vision and Pattern Recognition Workshops (CVPRW), 2010 IEEE Computer Society Conference on. IEEE, 2010, pp. 94–101.
[33] G. Zhao, X. Huang, M. Taini, S. Z. Li, and M. PietikäInen, “Facial
expression recognition from near-infrared videos,” Image and Vision
Computing, vol. 29, no. 9, pp. 607–619, 2011.
[34] S. Li, W. Deng, and J. Du, “Reliable crowdsourcing and deep locality-
preserving learning for expression recognition in the wild,” in 2017
IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
IEEE, 2017, pp. 2584–2593.
[35] M. V alstar and M. Pantic, “Induced disgust, happiness and surprise: an
addition to the mmi facial expression database,” in Proc. 3rd Intern.
Workshop on EMOTION (satellite of LREC): Corpora for Research on
Emotion and Affect, 2010, p. 65.
[36] M. Lyons, S. Akamatsu, M. Kamachi, and J. Gyoba, “Coding facial
expressions with gabor wavelets,” in Automatic Face and Gesture
Recognition, 1998. Proceedings. Third IEEE International Conference
on. IEEE, 1998, pp. 200–205.
[37] J. M. Susskind, A. K. Anderson, and G. E. Hinton, “The toronto face
database,” Department of Computer Science, University of Toronto,
Toronto, ON, Canada, Tech. Rep, vol. 3, 2010.
[38] R. Gross, I. Matthews, J. Cohn, T. Kanade, and S. Baker, “Multi-pie,”
Image and Vision Computing, vol. 28, no. 5, pp. 807–813, 2010.
[39] L. Yin, X. Wei, Y . Sun, J. Wang, and M. J. Rosato, “A 3d facial
expression database for facial behavior research,” in Automatic Face and
Gesture Recognition, 2006. 7th International Conference on. IEEE,
2006, pp. 211–216.
[40] L. Yin, X. Chen, Y . Sun, T. Worm, and M. Reale, “A high-resolution
3d dynamic facial expression database,” in The 8th International Con-ference on Automatic Face and Gesture Recognition. Amsterdam, The
Netherlands. IEEE, 2008.
[41] O. Langner, R. Dotsch, G. Bijlstra, D. H. Wigboldus, S. T. Hawk, and
A. van Knippenberg, “Presentation and validation of the radboud faces
database,” Cognition and Emotion, vol. 24, no. 8, pp. 1377–1388, 2010.
[42] D. Lundqvist, A. Flykt, and A.Öhman, “The karolinska directed
emotional faces (kdef),” CD ROM from Department of Clinical Neu-
roscience, Psychology section, Karolinska Institutet, no. 1998, 1998.
[43] C. F. Benitez-Quiroz, R. Srinivasan, and A. M. Martinez, “Emotionet:
An accurate, real-time algorithm for the automatic annotation of a
million facial expressions in the wild,” in Proceedings of IEEE Interna-
tional Conference on Computer Vision & Pattern Recognition (CVPR),
Las V egas, NV , USA, 2016.
[44] S. Li and W. Deng, “Reliable crowdsourcing and deep locality-
preserving learning for unconstrained facial expression recognition,”
IEEE Transactions on Image Processing, vol. 28, no. 1, pp. 356–370,
Jan 2019.
[45] A. Mollahosseini, B. Hasani, and M. H. Mahoor, “Affectnet: A database
for facial expression, valence, and arousal computing in the wild,” IEEE
Transactions on Affective Computing, vol. PP , no. 99, pp. 1–1, 2017.
[46] Z. Zhang, P . Luo, C. L. Chen, and X. Tang, “From facial expression
recognition to interpersonal relation prediction,” International Journal
of Computer Vision, vol. 126, no. 5, pp. 1–20, 2018.
[47] S. Cheng, I. Kotsia, M. Pantic, and S. Zafeiriou, “4dfab: A large scale
4d database for facial expression analysis and biometric applications,”
in Proceedings of the IEEE conference on computer vision and pattern
recognition, 2018, pp. 5117–5126.
[48] A. Dhall, R. Goecke, S. Lucey, T. Gedeon et al., “Collecting large, richly
annotated facial-expression databases from movies,” IEEE multimedia,
vol. 19, no. 3, pp. 34–41, 2012.
[49] A. Dhall, R. Goecke, S. Lucey, and T. Gedeon, “Static facial expression
analysis in tough conditions: Data, evaluation protocol and benchmark,”
in Computer Vision Workshops (ICCV Workshops), 2011 IEEE Interna-
tional Conference on. IEEE, 2011, pp. 2106–2112.
[50] C. F. Benitez-Quiroz, R. Srinivasan, Q. Feng, Y . Wang, and A. M.
Martinez, “Emotionet challenge: Recognition of facial expressions of
emotion in the wild,” arXiv preprint arXiv:1703.01210, 2017.
[51] S. Du, Y . Tao, and A. M. Martinez, “Compound facial expressions of
emotion,” Proceedings of the National Academy of Sciences, vol. 111,
no. 15, pp. E1454–E1462, 2014.
[52] P . Viola and M. Jones, “Rapid object detection using a boosted cascade
of simple features,” in Computer Vision and Pattern Recognition,
2001. CVPR 2001. Proceedings of the 2001 IEEE Computer Society
Conference on, vol. 1. IEEE, 2001, pp. I–I.
[53] Z. Y u and C. Zhang, “Image based static facial expression recognition
with multiple deep network learning,” in Proceedings of the 2015 ACM
on International Conference on Multimodal Interaction. ACM, 2015,
pp. 435–442.
[54] B.-K. Kim, H. Lee, J. Roh, and S.-Y . Lee, “Hierarchical committee
of deep cnns with exponentially-weighted decision fusion for static
facial expression recognition,” in Proceedings of the 2015 ACM on
International Conference on Multimodal Interaction. ACM, 2015,
pp. 427–434.
[55] X. Zhu and D. Ramanan, “Face detection, pose estimation, and land-
mark localization in the wild,” in Computer Vision and Pattern Recogni-
tion (CVPR), 2012 IEEE Conference on. IEEE, 2012, pp. 2879–2886.
[56] F. De la Torre, W.-S. Chu, X. Xiong, F. Vicente, X. Ding, and J. F. Cohn,
“Intraface,” in IEEE International Conference on Automatic Face and
Gesture Recognition (FG), 2015.
[57] T. F. Cootes, G. J. Edwards, and C. J. Taylor, “Active appearance mod-
els,” IEEE Transactions on Pattern Analysis & Machine Intelligence,
no. 6, pp. 681–685, 2001.
[58] N. Zeng, H. Zhang, B. Song, W. Liu, Y . Li, and A. M. Dobaie,
“Facial expression recognition via learning deep sparse autoencoders,”
Neurocomputing, vol. 273, pp. 643–649, 2018.
[59] B. Hasani and M. H. Mahoor, “Spatio-temporal facial expression recog-
nition using convolutional neural networks and conditional random
fields,” in Automatic Face & Gesture Recognition (FG 2017), 2017
12th IEEE International Conference on. IEEE, 2017, pp. 790–795.
[60] S. E. Kahou, C. Pal, X. Bouthillier, P . Froumenty, C ¸ . Gülc ¸ehre,
R. Memisevic, P . Vincent, A. Courville, Y . Bengio, R. C. Ferrari
et al., “Combining modality specific deep neural networks for emotion
recognition in video,” in Proceedings of the 15th ACM on International
conference on multimodal interaction. ACM, 2013, pp. 543–550.
[61] T. Devries, K. Biswaranjan, and G. W. Taylor, “Multi-task learning of
facial landmarks and expression,” in Computer and Robot Vision (CRV),
2014 Canadian Conference on. IEEE, 2014, pp. 98–103.
[62] B. Sun, L. Li, G. Zhou, and J. He, “Facial expression recognition in
the wild based on multimodal texture features,” Journal of Electronic
Imaging, vol. 25, no. 6, p. 061407, 2016.
[63] A. Asthana, S. Zafeiriou, S. Cheng, and M. Pantic, “Robust discrimina-
tive response map fitting with constrained local models,” in Computer
Vision and Pattern Recognition (CVPR), 2013 IEEE Conference on.
IEEE, 2013, pp. 3444–3451.
[64] M. Shin, M. Kim, and D.-S. Kwon, “Baseline cnn structure analysis
for facial expression recognition,” in Robot and Human Interactive
Communication (RO-MAN), 2016 25th IEEE International Symposium
on. IEEE, 2016, pp. 724–729.
[65] Z. Meng, P . Liu, J. Cai, S. Han, and Y . Tong, “Identity-aware convo-
lutional neural network for facial expression recognition,” in Automatic
Face & Gesture Recognition (FG 2017), 2017 12th IEEE International
Conference on. IEEE, 2017, pp. 558–565.
[66] X. Xiong and F. De la Torre, “Supervised descent method and its appli-
cations to face alignment,” in Computer Vision and Pattern Recognition
(CVPR), 2013 IEEE Conference on. IEEE, 2013, pp. 532–539.
[67] H.-W. Ng, V . D. Nguyen, V . V onikakis, and S. Winkler, “Deep learning
for emotion recognition on small datasets using transfer learning,” in
Proceedings of the 2015 ACM on international conference on multi-
modal interaction. ACM, 2015, pp. 443–449.
[68] H. Ding, S. K. Zhou, and R. Chellappa, “Facenet2expnet: Regularizing
a deep face recognition net for expression recognition,” in Automatic
Face & Gesture Recognition (FG 2017), 2017 12th IEEE International
Conference on. IEEE, 2017, pp. 118–126.
[69] S. Ren, X. Cao, Y . Wei, and J. Sun, “Face alignment at 3000 fps
via regressing local binary features,” in Proceedings of the IEEE
Conference on Computer Vision and Pattern Recognition, 2014, pp.
1685–1692.
[70] A. Asthana, S. Zafeiriou, S. Cheng, and M. Pantic, “Incremental face
alignment in the wild,” in Proceedings of the IEEE conference on
computer vision and pattern recognition, 2014, pp. 1859–1866.
[71] D. H. Kim, W. Baddar, J. Jang, and Y . M. Ro, “Multi-objective based
spatio-temporal feature representation learning robust to expression in-
tensity variations for facial expression recognition,” IEEE Transactions
on Affective Computing, vol. 10, no. 2, pp. 223–236, 2019.
[72] Y . Sun, X. Wang, and X. Tang, “Deep convolutional network cascade
for facial point detection,” in Computer Vision and Pattern Recognition
(CVPR), 2013 IEEE Conference on. IEEE, 2013, pp. 3476–3483.
[73] K. Zhang, Y . Huang, Y . Du, and L. Wang, “Facial expression recognition
based on deep evolutional spatial-temporal networks,” IEEE Transac-
tions on Image Processing, vol. 26, no. 9, pp. 4193–4203, 2017.
[74] K. Zhang, Z. Zhang, Z. Li, and Y . Qiao, “Joint face detection and
alignment using multitask cascaded convolutional networks,” IEEE
Signal Processing Letters, vol. 23, no. 10, pp. 1499–1503, 2016.
[75] Z. Y u, Q. Liu, and G. Liu, “Deeper cascaded peak-piloted network for
weak expression recognition,” The Visual Computer, pp. 1–9, 2017.
[76] X. Ouyang, S. Kawaai, E. G. H. Goh, S. Shen, W. Ding, H. Ming, and
D.-Y . Huang, “Audio-visual emotion recognition using deep transfer
learning and multiple temporal models,” in Proceedings of the 19th
ACM International Conference on Multimodal Interaction. ACM,
2017, pp. 577–582.
[77] Z. Y u, G. Liu, Q. Liu, and J. Deng, “Spatio-temporal convolutional
features with nested lstm for facial expression recognition,” Neurocom-
puting, vol. 317, pp. 50–57, 2018.
[78] X. Liu, B. Kumar, J. Y ou, and P . Jia, “Adaptive deep metric learning
for identity-aware facial expression recognition,” in Proc. IEEE Conf.
Comput. Vis. Pattern Recognit. Workshops (CVPRW), 2017, pp. 522–
531.
[79] G. Levi and T. Hassner, “Emotion recognition in the wild via convolu-
tional neural networks and mapped binary patterns,” in Proceedings of
the 2015 ACM on international conference on multimodal interaction.
ACM, 2015, pp. 503–510.
[80] W. Li, M. Li, Z. Su, and Z. Zhu, “A deep-learning approach to
facial expression recognition with candid images,” in Machine Vision
Applications (MVA), 2015 14th IAPR International Conference on.
IEEE, 2015, pp. 279–282.
[81] I. Abbasnejad, S. Sridharan, D. Nguyen, S. Denman, C. Fookes, and
S. Lucey, “Using synthetic data to improve facial expression analysis
with 3d convolutional networks,” in Proceedings of the IEEE Confer-
ence on Computer Vision and Pattern Recognition, 2017, pp. 1609–
1618.
[82] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley,
S. Ozair, A. Courville, and Y . Bengio, “Generative adversarial nets,” in
Advances in neural information processing systems, 2014, pp. 2672–
2680.
[83] J. Li and E. Y . Lam, “Facial expression recognition using deep neural
networks,” in Imaging Systems and Techniques (IST), 2015 IEEE
International Conference on. IEEE, 2015, pp. 1–6.
[84] S. Ebrahimi Kahou, V . Michalski, K. Konda, R. Memisevic, and C. Pal,
“Recurrent neural networks for emotion recognition in video,” in Pro-
ceedings of the 2015 ACM on International Conference on Multimodal
Interaction. ACM, 2015, pp. 467–474.
[85] S. A. Bargal, E. Barsoum, C. C. Ferrer, and C. Zhang, “Emotion
recognition in the wild from videos using images,” in Proceedings of the
18th ACM International Conference on Multimodal Interaction. ACM,
2016, pp. 433–436.
[86] D. A. Pitaloka, A. Wulandari, T. Basaruddin, and D. Y . Liliana,
“Enhancing cnn with preprocessing stage in automatic emotion recog-
nition,” Procedia Computer Science, vol. 116, pp. 523–529, 2017.
[87] C.-M. Kuo, S.-H. Lai, and M. Sarkis, “A compact deep learning model
for robust facial expression recognition,” in Proceedings of the IEEE
Conference on Computer Vision and Pattern Recognition Workshops,
2018, pp. 2121–2129.
[88] A. Yao, D. Cai, P . Hu, S. Wang, L. Sha, and Y . Chen, “Holonet: towards
robust emotion recognition in the wild,” in Proceedings of the 18th ACM
International Conference on Multimodal Interaction. ACM, 2016, pp.
472–478.
[89] P . Hu, D. Cai, S. Wang, A. Yao, and Y . Chen, “Learning supervised
scoring ensemble for emotion recognition in the wild,” in Proceedings
of the 19th ACM International Conference on Multimodal Interaction.
ACM, 2017, pp. 553–560.
[90] T. Hassner, S. Harel, E. Paz, and R. Enbar, “Effective face frontalization
in unconstrained images,” in Proceedings of the IEEE Conference on
Computer Vision and Pattern Recognition, 2015, pp. 4295–4304.
[91] C. Sagonas, Y . Panagakis, S. Zafeiriou, and M. Pantic, “Robust sta-
tistical face frontalization,” in Proceedings of the IEEE International
Conference on Computer Vision, 2015, pp. 3871–3879.
[92] L. Deng, D. Y u et al., “Deep learning: methods and applications,”
F oundations and Trends R ? in Signal Processing, vol. 7, no. 3–4, pp.
197–387, 2014.
[93] Y . Tang, “Deep learning using linear support vector machines,” arXiv
preprint arXiv:1306.0239, 2013.
[94] A. Dapogny and K. Bailly, “Investigating deep neural forests for facial
expression recognition,” in Automatic Face & Gesture Recognition (FG
2018), 2018 13th IEEE International Conference on. IEEE, 2018, pp.
629–633.
[95] P . Kontschieder, M. Fiterau, A. Criminisi, and S. Rota Bulo, “Deep
neural decision forests,” in Proceedings of the IEEE international
conference on computer vision, 2015, pp. 1467–1475.
[96] J. Donahue, Y . Jia, O. Vinyals, J. Hoffman, N. Zhang, E. Tzeng, and
T. Darrell, “Decaf: A deep convolutional activation feature for generic
visual recognition,” in International conference on machine learning,
2014, pp. 647–655.
[97] A. S. Razavian, H. Azizpour, J. Sullivan, and S. Carlsson, “Cnn features
off-the-shelf: an astounding baseline for recognition,” in Computer
Vision and Pattern Recognition Workshops (CVPRW), 2014 IEEE Con-
ference on. IEEE, 2014, pp. 512–519.
[98] N. Otberdout, A. Kacem, M. Daoudi, L. Ballihi, and S. Berretti, “Deep
covariance descriptors for facial expression recognition,” in BMVC,
2018.
[99] D. Acharya, Z. Huang, D. Pani Paudel, and L. V an Gool, “Covariance
pooling for facial expression recognition,” in Proceedings of the IEEE
Conference on Computer Vision and Pattern Recognition Workshops,
2018, pp. 367–374.
[100] S. Ouellet, “Real-time emotion recognition for gaming using deep
convolutional network features,” arXiv preprint arXiv:1408.3750, 2014.
[101] M. Liu, S. Li, S. Shan, and X. Chen, “Au-aware deep networks for facial
expression recognition,” in Automatic Face and Gesture Recognition
(FG), 2013 10th IEEE International Conference and Workshops on.
IEEE, 2013, pp. 1–6.
[102] ——, “Au-inspired deep networks for facial expression feature learn-
ing,” Neurocomputing, vol. 159, pp. 126–136, 2015.
[103] P . Khorrami, T. Paine, and T. Huang, “Do deep neural networks learn
facial action units when doing expression recognition?” arXiv preprint
arXiv:1510.02969v3, 2015.
[104] J. Cai, Z. Meng, A. S. Khan, Z. Li, J. O’Reilly, and Y . Tong, “Island loss
for learning discriminative features in facial expression recognition,” in
Automatic Face & Gesture Recognition (FG 2018), 2018 13th IEEE
International Conference on. IEEE, 2018, pp. 302–309.
[105] H. Yang, U. Ciftci, and L. Yin, “Facial expression recognition by de-
expression residue learning,” in Proceedings of the IEEE Conference on
Computer Vision and Pattern Recognition, 2018, pp. 2168–2177.
[106] D. Hamester, P . Barros, and S. Wermter, “Face expression recognition
with a 2-channel convolutional neural network,” in Neural Networks
(IJCNN), 2015 International Joint Conference on. IEEE, 2015, pp.
1–8.
[107] X. Liu, B. V . Kumar, P . Jia, and J. Y ou, “Hard negative generation for
identity-disentangled facial expression recognition,” Pattern Recogni-
tion, vol. 88, pp. 1 – 12, 2019.
[108] S. Reed, K. Sohn, Y . Zhang, and H. Lee, “Learning to disentangle fac-
tors of variation with manifold interaction,” in International Conference
on Machine Learning, 2014, pp. 1431–1439.
[109] Z. Zhang, P . Luo, C.-C. Loy, and X. Tang, “Learning social relation
traits from face images,” in Proceedings of the IEEE International
Conference on Computer Vision, 2015, pp. 3631–3639.
[110] Y . Guo, D. Tao, J. Y u, H. Xiong, Y . Li, and D. Tao, “Deep neural
networks with relativity learning for facial expression recognition,” in
Multimedia & Expo Workshops (ICMEW), 2016 IEEE International
Conference on. IEEE, 2016, pp. 1–6.
[111] B.-K. Kim, S.-Y . Dong, J. Roh, G. Kim, and S.-Y . Lee, “Fusing aligned
and non-aligned face information for automatic affect recognition in
the wild: A deep learning approach,” in Proceedings of the IEEE
Conference on Computer Vision and Pattern Recognition Workshops,
2016, pp. 48–57.
[112] C. Pramerdorfer and M. Kampel, “Facial expression recognition us-
ing convolutional neural networks: State of the art,” arXiv preprint
arXiv:1612.02903, 2016.
[113] M.-I. Georgescu, R. T. Ionescu, and M. Popescu, “Local learning with
deep and handcrafted features for facial expression recognition,” IEEE
Access, vol. 7, pp. 64 827–64 836, 2019.
[114] O. M. Parkhi, A. V edaldi, A. Zisserman et al., “Deep face recognition.”
in BMVC, vol. 1, no. 3, 2015, p. 6.
[115] T. Kaneko, K. Hiramatsu, and K. Kashino, “Adaptive visual feedback
generation for facial expression improvement with multi-task deep
neural networks,” in Proceedings of the 2016 ACM on Multimedia
Conference. ACM, 2016, pp. 327–331.
[116] H. Kaya, F. Gürpınar, and A. A. Salah, “Video-based emotion recogni-
tion in the wild using deep transfer learning and score fusion,” Image
and Vision Computing, vol. 65, pp. 66–75, 2017.
[117] B. Knyazev, R. Shvetsov, N. Efremova, and A. Kuharenko, “Convolu-
tional neural networks pretrained on large face recognition datasets for
emotion classification from video,” arXiv preprint arXiv:1711.04598,
2017.
[118] D. G. Lowe, “Object recognition from local scale-invariant features,” in
Computer vision, 1999. The proceedings of the seventh IEEE interna-
tional conference on, vol. 2. Ieee, 1999, pp. 1150–1157.
[119] T. Zhang, W. Zheng, Z. Cui, Y . Zong, J. Yan, and K. Yan, “A deep neural
network-driven feature learning method for multi-view facial expression
recognition,” IEEE Transactions on Multimedia, vol. 18, no. 12, pp.
2528–2536, 2016.
[120] Z. Luo, J. Chen, T. Takiguchi, and Y . Ariki, “Facial expression recogni-
tion with deep age,” in Multimedia & Expo Workshops (ICMEW), 2017
IEEE International Conference on. IEEE, 2017, pp. 657–662.
[121] L. Chen, M. Zhou, W. Su, M. Wu, J. She, and K. Hirota, “Softmax
regression based deep sparse autoencoder network for facial emotion
recognition in human-robot interaction,” Information Sciences, vol. 428,
pp. 49–61, 2018.
[122] V . Mavani, S. Raman, and K. P . Miyapuram, “Facial expression
recognition using visual saliency and deep learning,” arXiv preprint
arXiv:1708.08016, 2017.
[123] B.-F. Wu and C.-H. Lin, “Adaptive feature mapping for customizing
deep learning based facial expression recognition model,” IEEE Access,
2018.
[124] Y . Liu, X. Y uan, X. Gong, Z. Xie, F. Fang, and Z. Luo, “Conditional
convolution neural network enhanced random forest for facial expres-
sion recognition,” Pattern Recognition, vol. 84, pp. 251 – 261, 2018.
[125] W. Sun, H. Zhao, and Z. Jin, “A visual attention based roi detection
method for facial expression recognition,” Neurocomputing, vol. 296,
pp. 12 – 22, 2018.
[126] Y . Li, J. Zeng, S. Shan, and X. Chen, “Occlusion aware facial expression
recognition using cnn with attention mechanism,” IEEE Transactions on
Image Processing, vol. 28, no. 5, pp. 2439–2450, 2019.
[127] S. Xie, H. Hu, and Y . Wu, “Deep multi-path convolutional neural
network joint with salient region attention for facial expression recog-
nition,” Pattern Recognition, vol. 92, pp. 177 – 191, 2019.
[128] W. Shang, K. Sohn, D. Almeida, and H. Lee, “Understanding and
improving convolutional neural networks via concatenated rectified
linear units,” in International Conference on Machine Learning, 2016,
pp. 2217–2225.
[129] J. Zeng, S. Shan, and X. Chen, “Facial expression recognition with
inconsistently annotated datasets,” in Proceedings of the European
Conference on Computer Vision (ECCV), 2018, pp. 222–237.
[130] Y . Wen, K. Zhang, Z. Li, and Y . Qiao, “A discriminative feature
learning approach for deep face recognition,” in European Conference
on Computer Vision. Springer, 2016, pp. 499–515.
[131] F. Schroff, D. Kalenichenko, and J. Philbin, “Facenet: A unified embed-
ding for face recognition and clustering,” in Proceedings of the IEEE
conference on computer vision and pattern recognition, 2015, pp. 815–
823.
[132] D. Ciregan, U. Meier, and J. Schmidhuber, “Multi-column deep neural
networks for image classification,” in Computer vision and pattern
recognition (CVPR), 2012 IEEE conference on. IEEE, 2012, pp. 3642–
3649.
[133] G. Pons and D. Masip, “Supervised committee of convolutional neural
networks in automated facial expression analysis,” IEEE Transactions
on Affective Computing, vol. 9, no. 3, pp. 343–350, 2018.
[134] K. Liu, M. Zhang, and Z. Pan, “Facial expression recognition with cnn
ensemble,” in Cyberworlds (CW), 2016 International Conference on.
IEEE, 2016, pp. 163–166.
[135] G. Zeng, J. Zhou, X. Jia, W. Xie, and L. Shen, “Hand-crafted feature
guided deep learning for facial expression recognition,” in Automatic
Face & Gesture Recognition (FG 2018), 2018 13th IEEE International
Conference on. IEEE, 2018, pp. 423–430.
[136] G. Pons and D. Masip, “Multi-task, multi-label and multi-domain
learning with residual convolutional networks for emotion recognition,”
arXiv preprint arXiv:1802.06664, 2018.
[137] P . Ekman and E. L. Rosenberg, What the face reveals: Basic and applied
studies of spontaneous expression using the Facial Action Coding
System (F ACS). Oxford University Press, USA, 1997.
[138] R. Ranjan, S. Sankaranarayanan, C. D. Castillo, and R. Chellappa, “An
all-in-one convolutional neural network for face analysis,” in Automatic
Face & Gesture Recognition (FG 2017), 2017 12th IEEE International
Conference on. IEEE, 2017, pp. 17–24.
[139] Y . Jang, H. Gunes, and I. Patras, “Smilenet: registration-free smiling
face detection in the wild,” in Proceedings of the IEEE International
Conference on Computer Vision, 2017, pp. 1581–1589.
[140] Y . Lv, Z. Feng, and C. Xu, “Facial expression recognition via deep
learning,” in Smart Computing (SMARTCOMP), 2014 International
Conference on. IEEE, 2014, pp. 303–308.
[141] S. Rifai, Y . Bengio, A. Courville, P . Vincent, and M. Mirza, “Disentan-
gling factors of variation for facial expression recognition,” in European
Conference on Computer Vision. Springer, 2012, pp. 808–822.
[142] Y .-H. Lai and S.-H. Lai, “Emotion-preserving representation learning
via generative adversarial network for multi-view facial expression
recognition,” in Automatic Face & Gesture Recognition (FG 2018),
2018 13th IEEE International Conference on. IEEE, 2018, pp. 263–
270.
[143] F. Zhang, T. Zhang, Q. Mao, and C. Xu, “Joint pose and expression
modeling for facial expression recognition,” in Proceedings of the IEEE
Conference on Computer Vision and Pattern Recognition, 2018, pp.
3359–3368.
[144] H. Yang, Z. Zhang, and L. Yin, “Identity-adaptive facial expression
recognition through expression regeneration using conditional genera-
tive adversarial networks,” in Automatic Face & Gesture Recognition
(FG 2018), 2018 13th IEEE International Conference on. IEEE, 2018,
pp. 294–301.
[145] J. Chen, J. Konrad, and P . Ishwar, “Vgan-based image representation
learning for privacy-preserving facial expression recognition,” in Pro-
ceedings of the IEEE Conference on Computer Vision and Pattern
Recognition Workshops, 2018, pp. 1570–1579.
[146] S. E. Kahou, X. Bouthillier, P . Lamblin, C. Gulcehre, V . Michal-
ski, K. Konda, S. Jean, P . Froumenty, Y . Dauphin, N. Boulanger-
Lewandowski et al., “Emonets: Multimodal deep learning approaches
for emotion recognition in video,” Journal on Multimodal User Inter-
faces, vol. 10, no. 2, pp. 99–111, 2016.
[147] M. Liu, R. Wang, S. Li, S. Shan, Z. Huang, and X. Chen, “Combining
multiple kernel methods on riemannian manifold for emotion recogni-
tion in the wild,” in Proceedings of the 16th International Conference
on Multimodal Interaction. ACM, 2014, pp. 494–501.
[148] W. Ding, M. Xu, D. Huang, W. Lin, M. Dong, X. Y u, and H. Li,
“Audio and face video emotion recognition in the wild using deep
neural networks and small datasets,” in Proceedings of the 18th ACM
International Conference on Multimodal Interaction. ACM, 2016, pp.
506–513.
[149] B. Xu, Y . Fu, Y .-G. Jiang, B. Li, and L. Sigal, “Video emotion
recognition with transferred deep feature encodings,” in Proceedingsof the 2016 ACM on International Conference on Multimedia Retrieval.
ACM, 2016, pp. 15–22.
[150] Y . Kim, B. Y oo, Y . Kwak, C. Choi, and J. Kim, “Deep generative-
contrastive networks for facial expression recognition,” arXiv preprint
arXiv:1703.07140, 2017.
[151] N. Sun, Q. Li, R. Huan, J. Liu, and G. Han, “Deep spatial-temporal
feature fusion for facial expression recognition in static images,” Pattern
Recognition Letters, 2017.
[152] S. Kumawat, M. V erma, and S. Raman, “Lbvcnn: Local binary volume
convolutional neural network for facial expression recognition from
image sequences,” in Proceedings of the IEEE Conference on Computer
Vision and Pattern Recognition Workshops, 2019, pp. 0–0.
[153] B. Hasani and M. H. Mahoor, “Facial expression recognition using
enhanced deep 3d convolutional neural networks,” in Computer Vision
and Pattern Recognition Workshops (CVPRW), 2017 IEEE Conference
on. IEEE, 2017, pp. 2278–2288.
[154] S. Wang, Z. Zheng, S. Yin, J. Yang, and Q. Ji, “A novel dynamic model
capturing spatial and temporal patterns for facial expression analysis,”
IEEE Transactions on Pattern Analysis and Machine Intelligence, pp.
1–1, 2019.
[155] J. Yan, W. Zheng, Z. Cui, C. Tang, T. Zhang, Y . Zong, and N. Sun,
“Multi-clue fusion for emotion recognition in the wild,” in Proceedings
of the 18th ACM International Conference on Multimodal Interaction.
ACM, 2016, pp. 458–463.
[156] Z. Cui, S. Xiao, Z. Niu, S. Yan, and W. Zheng, “Recurrent shape regres-
sion,” IEEE Transactions on Pattern Analysis and Machine Intelligence,
2018.
[157] Y . Fan, X. Lu, D. Li, and Y . Liu, “Video-based emotion recognition
using cnn-rnn and c3d hybrid networks,” in Proceedings of the 18th
ACM International Conference on Multimodal Interaction. ACM,
2016, pp. 445–450.
[158] V . Vielzeuf, S. Pateux, and F. Jurie, “Temporal multimodal fusion for
video emotion classification in the wild,” in Proceedings of the 19th
ACM International Conference on Multimodal Interaction. ACM,
2017, pp. 569–576.
[159] J. Chen, R. Xu, and L. Liu, “Deep peak-neutral difference feature for
facial expression recognition,” Multimedia Tools and Applications, pp.
1–17, 2018.
[160] Q. V . Le, N. Jaitly, and G. E. Hinton, “A simple way to ini-
tialize recurrent networks of rectified linear units,” arXiv preprint
arXiv:1504.00941, 2015.
[161] M. Schuster and K. K. Paliwal, “Bidirectional recurrent neural net-
works,” IEEE Transactions on Signal Processing, vol. 45, no. 11, pp.
2673–2681, 1997.
[162] D. A. AL CHANTI and A. Caplier, “Deep learning for spatio-temporal
modeling of dynamic spontaneous emotions,” IEEE Transactions on
Affective Computing, pp. 1–1, 2018.
[163] D. Tran, L. Bourdev, R. Fergus, L. Torresani, and M. Paluri, “Learning
spatiotemporal features with 3d convolutional networks,” in Computer
Vision (ICCV), 2015 IEEE International Conference on. IEEE, 2015,
pp. 4489–4497.
[164] P . Barros and S. Wermter, “Developing crossmodal expression recogni-
tion based on a deep neural model,” Adaptive behavior, vol. 24, no. 5,
pp. 373–396, 2016.
[165] J. Zhao, X. Mao, and J. Zhang, “Learning deep facial expression
features from image and optical flow sequences using 3d cnn,” The
Visual Computer, pp. 1–15, 2018.
[166] M. Liu, S. Li, S. Shan, R. Wang, and X. Chen, “Deeply learning
deformable facial action parts model for dynamic expression analysis,”
in Asian conference on computer vision. Springer, 2014, pp. 143–157.
[167] P . F. Felzenszwalb, R. B. Girshick, D. McAllester, and D. Ramanan,
“Object detection with discriminatively trained part-based models,”
IEEE transactions on pattern analysis and machine intelligence, vol. 32,
no. 9, pp. 1627–1645, 2010.
[168] D. Nguyen, K. Nguyen, S. Sridharan, A. Ghasemi, D. Dean, and
C. Fookes, “Deep spatio-temporal features for multimodal emotion
recognition,” in Applications of Computer Vision (WACV), 2017 IEEE
Winter Conference on. IEEE, 2017, pp. 1215–1223.
[169] S. Pini, O. B. Ahmed, M. Cornia, L. Baraldi, R. Cucchiara, and B. Huet,
“Modeling multimodal cues in a deep learning-based framework for
emotion recognition in the wild,” in Proceedings of the 19th ACM
International Conference on Multimodal Interaction. ACM, 2017,
pp. 536–543.
[170] R. Arandjelovic, P . Gronat, A. Torii, T. Pajdla, and J. Sivic, “Netvlad:
Cnn architecture for weakly supervised place recognition,” in Pro-
ceedings of the IEEE Conference on Computer Vision and Pattern
Recognition, 2016, pp. 5297–5307.
[171] D. H. Kim, M. K. Lee, D. Y . Choi, and B. C. Song, “Multi-modal
emotion recognition using semi-supervised learning and multiple neural
networks in the wild,” in Proceedings of the 19th ACM International
Conference on Multimodal Interaction. ACM, 2017, pp. 529–535.
[172] J. Donahue, L. Anne Hendricks, S. Guadarrama, M. Rohrbach, S. V enu-
gopalan, K. Saenko, and T. Darrell, “Long-term recurrent convolutional
networks for visual recognition and description,” in Proceedings of the
IEEE conference on computer vision and pattern recognition, 2015, pp.
2625–2634.
[173] D. K. Jain, Z. Zhang, and K. Huang, “Multi angle optimal pattern-based
deep learning for automatic facial expression recognition,” Pattern
Recognition Letters, 2017.
[174] S. Kankanamge, C. Fookes, and S. Sridharan, “Facial analysis in the
wild with lstm networks,” in Image Processing (ICIP), 2017 IEEE
International Conference on. IEEE, 2017, pp. 1052–1056.
[175] W. J. Baddar and Y . M. Ro, “Learning spatio-temporal features with
partial expression sequences for on-the-fly prediction,” in Thirty-Second
AAAI Conference on Artificial Intelligence, 2018.
[176] M. Baccouche, F. Mamalet, C. Wolf, C. Garcia, and A. Baskurt, “Spatio-
temporal convolutional sparse auto-encoder for sequence classification.”
in BMVC, 2012, pp. 1–12.
[177] K. Simonyan and A. Zisserman, “Two-stream convolutional networks
for action recognition in videos,” in Advances in neural information
processing systems, 2014, pp. 568–576.
[178] J. Susskind, V . Mnih, G. Hinton et al., “On deep generative models
with applications to recognition,” in Computer Vision and Pattern
Recognition (CVPR), 2011 IEEE Conference on. IEEE, 2011, pp.
2857–2864.
[179] Y . Cheng, B. Jiang, and K. Jia, “A deep structure for facial expression
recognition under partial occlusion,” in Intelligent Information Hiding
and Multimedia Signal Processing (IIH-MSP), 2014 Tenth International
Conference on. IEEE, 2014, pp. 211–214.
[180] M. Xu, W. Cheng, Q. Zhao, L. Ma, and F. Xu, “Facial expression recog-
nition based on transfer learning from deep convolutional networks,” in
Natural Computation (ICNC), 2015 11th International Conference on.
IEEE, 2015, pp. 702–708.
[181] Y . Liu, J. Zeng, S. Shan, and Z. Zheng, “Multi-channel pose-aware con-
volution neural networks for multi-view facial expression recognition,”
in Automatic Face & Gesture Recognition (FG 2018), 2018 13th IEEE
International Conference on. IEEE, 2018, pp. 458–465.
[182] E. P . Ijjina and C. K. Mohan, “Facial expression recognition using kinect
depth sensor and convolutional neural networks,” in Machine Learning
and Applications (ICMLA), 2014 13th International Conference on.
IEEE, 2014, pp. 392–396.
[183] M. Z. Uddin, M. M. Hassan, A. Almogren, M. Zuair, G. Fortino, and
J. Torresen, “A facial expression recognition system using robust face
features from depth videos and deep learning,” Computers & Electrical
Engineering, vol. 63, pp. 114–125, 2017.
[184] W. Li, D. Huang, H. Li, and Y . Wang, “Automatic 4d facial expression
recognition using dynamic geometrical image network,” in Automatic
Face & Gesture Recognition (FG 2018), 2018 13th IEEE International
Conference on. IEEE, 2018, pp. 24–30.
[185] F.-J. Chang, A. T. Tran, T. Hassner, I. Masi, R. Nevatia, and G. Medioni,
“Expnet: Landmark-free, deep, 3d facial expressions,” in Automatic
Face & Gesture Recognition (FG 2018), 2018 13th IEEE International
Conference on. IEEE, 2018, pp. 122–129.
[186] Z. Chen, D. Huang, Y . Wang, and L. Chen, “Fast and light manifold
cnn based 3d facial expression recognition across pose variations,” in
2018 ACM Multimedia Conference on Multimedia Conference. ACM,
2018, pp. 229–238.
[187] O. K. Oyedotun, G. Demisse, A. E. R. Shabayek, D. Aouada, and
B. Ottersten, “Facial expression recognition via joint deep learning
of rgb-depth map latent representations,” in 2017 IEEE International
Conference on Computer Vision Workshop (ICCVW), 2017.
[188] H. Li, J. Sun, Z. Xu, and L. Chen, “Multimodal 2d+ 3d facial expression
recognition with deep fusion convolutional neural network,” IEEE
Transactions on Multimedia, vol. 19, no. 12, pp. 2816–2831, 2017.
[189] A. Jan, H. Ding, H. Meng, L. Chen, and H. Li, “Accurate facial parts
localization and deep learning for 3d facial expression recognition,” in
Automatic Face & Gesture Recognition (FG 2018), 2018 13th IEEE
International Conference on. IEEE, 2018, pp. 466–472.
[190] J. M. Susskind, G. E. Hinton, J. R. Movellan, and A. K. Anderson,
“Generating facial expressions with deep belief nets,” in Affective
Computing. InTech, 2008.
[191] M. Sabzevari, S. Toosizadeh, S. R. Quchani, and V . Abrishami, “A
fast and accurate facial expression synthesis system for color face
images using face graph and deep belief network,” in Electronics andInformation Engineering (ICEIE), 2010 International Conference On,
vol. 2. IEEE, 2010, pp. V2–354.
[192] V . Mnih, J. M. Susskind, G. E. Hinton et al., “Modeling natural images
using gated mrfs,” IEEE transactions on pattern analysis and machine
intelligence, vol. 35, no. 9, pp. 2206–2222, 2013.
[193] R. Yeh, Z. Liu, D. B. Goldman, and A. Agarwala, “Semantic
facial expression editing using autoencoded flow,” arXiv preprint
arXiv:1611.09961, 2016.
[194] H. Ding, K. Sricharan, and R. Chellappa, “Exprgan: Facial expres-
sion editing with controllable expression intensity,” in AAAI, 2018, p.
6781–6788.
[195] L. Song, Z. Lu, R. He, Z. Sun, and T. Tan, “Geometry guided adversarial
facial expression synthesis,” in 2018 ACM Multimedia Conference on
Multimedia Conference. ACM, 2018, pp. 627–635.
[196] A. Pumarola, A. Agudo, A. M. Martinez, A. Sanfeliu, and F. Moreno-
Noguer, “Ganimation: Anatomically-aware facial animation from a
single image,” in Proceedings of the European Conference on Computer
Vision (ECCV), 2018, pp. 818–833.
[197] F. Qiao, N. Yao, Z. Jiao, Z. Li, H. Chen, and H. Wang, “Geometry-
contrastive generative adversarial network for facial expression synthe-
sis,” arXiv preprint arXiv:1802.01822, 2018.
[198] Z. Geng, C. Cao, and S. Tulyakov, “3d guided fine-grained face
manipulation,” in The IEEE Conference on Computer Vision and Pattern
Recognition (CVPR), June 2019.
[199] I. Masi, A. T. Tran, T. Hassner, J. T. Leksut, and G. Medioni, “Do we
really need to collect millions of faces for effective face recognition?”
in European Conference on Computer Vision. Springer, 2016, pp.
579–596.
[200] N. Mousavi, H. Siqueira, P . Barros, B. Fernandes, and S. Wermter,
“Understanding how deep neural networks learn face expressions,” in
Neural Networks (IJCNN), 2016 International Joint Conference on.
IEEE, 2016, pp. 227–234.
[201] R. Breuer and R. Kimmel, “A deep learning perspective on the origin
of facial expressions,” arXiv preprint arXiv:1705.01842, 2017.
[202] M. D. Zeiler and R. Fergus, “Visualizing and understanding convolu-
tional networks,” in European conference on computer vision. Springer,
2014, pp. 818–833.
[203] I. Lüsi, J. C. J. Junior, J. Gorbova, X. Baró, S. Escalera, H. Demirel,
J. Allik, C. Ozcinar, and G. Anbarjafari, “Joint challenge on dominant
and complementary emotion recognition using micro emotion features
and head-pose estimation: Databases,” in Automatic Face & Gesture
Recognition (FG 2017), 2017 12th IEEE International Conference on.
IEEE, 2017, pp. 809–813.
[204] J. Wan, S. Escalera, X. Baro, H. J. Escalante, I. Guyon, M. Madadi,
J. Allik, J. Gorbova, and G. Anbarjafari, “Results and analysis of
chalearn lap multi-modal isolated and continuous gesture recognition,
and real versus fake expressed emotions challenges,” in ChaLearn LaP ,
Action, Gesture, and Emotion Recognition Workshop and Competitions:
Large Scale Multimodal Gesture Recognition and Real versus Fake
expressed emotions, ICCV, vol. 4, no. 6, 2017.
[205] Y .-G. Kim and X.-P . Huynh, “Discrimination between genuine versus
fake emotion using long-short term memory with parametric bias and
facial landmarks,” in Computer Vision Workshop (ICCVW), 2017 IEEE
International Conference on. IEEE, 2017, pp. 3065–3072.
[206] L. Li, T. Baltrusaitis, B. Sun, and L.-P . Morency, “Combining sequential
geometry and texture features for distinguishing genuine and deceptive
emotions,” in Proceedings of the IEEE Conference on Computer Vision
and Pattern Recognition, 2017, pp. 3147–3153.
[207] J. Guo, S. Zhou, J. Wu, J. Wan, X. Zhu, Z. Lei, and S. Z. Li, “Multi-
modality network with visual and geometrical information for micro
emotion recognition,” in Automatic Face & Gesture Recognition (FG
2017), 2017 12th IEEE International Conference on. IEEE, 2017, pp.
814–819.
[208] R. V emulapalli and A. Agarwala, “A compact embedding for facial
expression similarity,” in The IEEE Conference on Computer Vision
and Pattern Recognition (CVPR), June 2019.
[209] E. Barsoum, C. Zhang, C. C. Ferrer, and Z. Zhang, “Training deep
networks for facial expression recognition with crowd-sourced label
distribution,” in Proceedings of the 18th ACM International Conference
on Multimodal Interaction. ACM, 2016, pp. 279–283.
[210] “Chapter 19 - affective facial computing: Generalizability across do-
mains,” in Multimodal Behavior Analysis in the Wild, X. Alameda-
Pineda, E. Ricci, and N. Sebe, Eds. Academic Press, 2019, pp. 407 –
441.
[211] X. Wei, H. Li, J. Sun, and L. Chen, “Unsupervised domain adaptation
with regularized optimal transport for multimodal 2d+ 3d facial expres-sion recognition,” in Automatic Face & Gesture Recognition (FG 2018),
2018 13th IEEE International Conference on. IEEE, 2018, pp. 31–37.
[212] S. Li and W. Deng, “Deep emotion transfer network for cross-database
facial expression recognition,” in Pattern Recognition (ICPR), 2018
26th International Conference. IEEE, 2018, pp. 3092–3099.
[213] R. L. Testa, C. G. Corrêa, A. Machado-Lima, and F. L. S.
Nunes, “Synthesis of facial expressions in photographs: Characteristics,
approaches, and challenges,” ACM Comput. Surv., vol. 51, no. 6, pp.
124:1–124:35, 2019.
[214] J. A. Russell, “A circumplex model of affect.” Journal of personality
and social psychology, vol. 39, no. 6, p. 1161, 1980.
[215] M. Soleymani, D. Garcia, B. Jou, B. Schuller, S.-F. Chang, and
M. Pantic, “A survey of multimodal sentiment analysis,” Image and
Vision Computing, vol. 65, pp. 3–14, 2017.
[216] I. Chaturvedi, E. Cambria, R. E. Welsch, and F. Herrera, “Distinguishing
between facts and opinions for sentiment analysis: Survey and chal-
lenges,” Information Fusion, vol. 44, pp. 65–77, 2018.
[217] S. Poria, E. Cambria, and A. Gelbukh, “Deep convolutional neural
network textual features and multiple kernel learning for utterance-level
multimodal sentiment analysis,” in Proceedings of the 2015 conference
on empirical methods in natural language processing, 2015, pp. 2539–
2544.
[218] S. Poria, I. Chaturvedi, E. Cambria, and A. Hussain, “Convolutional mkl
based multimodal emotion recognition and sentiment analysis,” in 2016
IEEE 16th international conference on data mining (ICDM). IEEE,
2016, pp. 439–448.
[219] S. Poria, H. Peng, A. Hussain, N. Howard, and E. Cambria, “Ensemble
application of convolutional neural networks and multiple kernel learn-
ing for multimodal sentiment analysis,” Neurocomputing, vol. 261, pp.
217–230, 2017.
[220] M. Chen, S. Wang, P . P . Liang, T. Baltruˇ saitis, A. Zadeh, and L.-P .
Morency, “Multimodal sentiment analysis with word-level fusion and
reinforcement learning,” in Proceedings of the 19th ACM International
Conference on Multimodal Interaction, 2017, pp. 163–171.
[221] A. Zadeh, M. Chen, S. Poria, E. Cambria, and L.-P . Morency, “Tensor
fusion network for multimodal sentiment analysis,” arXiv preprint
arXiv:1707.07250, 2017.
[222] I. Chaturvedi, R. Satapathy, S. Cavallari, and E. Cambria, “Fuzzy
commonsense reasoning for multimodal sentiment analysis,” Pattern
Recognition Letters, vol. 125, no. 264-270, 2019.