LSTM -长短期记忆网络(RNN循环神经网络)
文章目录
-
-
- 基本概念及其公式
-
- 输入门、输出门、遗忘门
- 候选记忆元
- 记忆元
- 隐状态
- 从零开始实现 LSTM
-
- 初始化模型参数
- 定义模型
- 训练和预测
- 简洁实现
- 小结
-
基本概念及其公式
LSTM,即(long short-term Memory)长短期记忆网络,也是RNN循环神经网络的一种改进方法,是为了解决一般的RNN(循环神经网络)存在的长期依赖问题而专门设计出来的,在NLP领域具有很重要的作用。
LSTM 模型同 GRU 模型思想相像,也是依靠逻辑门思想来试图解决序列依赖的一种方法。不过 LSTM 的逻辑门实现方法与 GRU 模型有所不同。
LSTM 模型中共需要以下的逻辑门与记忆信息:
- 输入门 I t I_{t} It
- 输出门 O t O_{t} Ot
- 遗忘门 F t F_{t} Ft
- 候选记忆元 C t c a n C_{t}^{can} Ctcan
- 记忆元 C t C_t Ct
- 隐状态 H t H_{t} Ht
通过对以上参数进行组合即可实现LSTM模型,以下将详解这6个逻辑门与记忆信息的功能与计算方法。
输入门、输出门、遗忘门
如同在门控循环单元 GRU 中一样, 当前时间步的输入和前一个时间步的隐状态 作为数据送入长短期记忆网络的门中, 如下图所示。 它们由三个具有sigmoid激活函数的全连接层处理, 以计算输入门、遗忘门和输出门的值。 因此,这三个门的值都在 ( 0 , 1 ) (0, 1) (0,1) 的范围内。
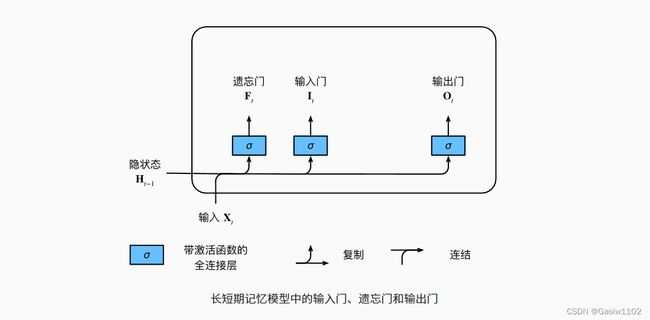
输入门、遗忘门和输出门的计算公式:
{ 输入门 I t = σ ( X i W x i + H t − 1 W h i + b i ) 输出门 O t = σ ( X i W x o + H t − 1 W h o + b o ) 遗忘门 F t = σ ( X i W x f + H t − 1 W h f + b f ) \begin {cases} 输入门 \quad I_{t} = \sigma(X_{i}W_{xi} + H_{t-1}W_{hi} + b_{i}) \\ 输出门 \quad O_{t} = \sigma(X_{i}W_{xo} + H_{t-1}W_{ho} + b_{o}) \\ 遗忘门 \quad F_{t} = \sigma(X_{i}W_{xf} + H_{t-1}W_{hf} + b_{f}) \\ \end {cases} ⎩ ⎨ ⎧输入门It=σ(XiWxi+Ht−1Whi+bi)输出门Ot=σ(XiWxo+Ht−1Who+bo)遗忘门Ft=σ(XiWxf+Ht−1Whf+bf)
候选记忆元
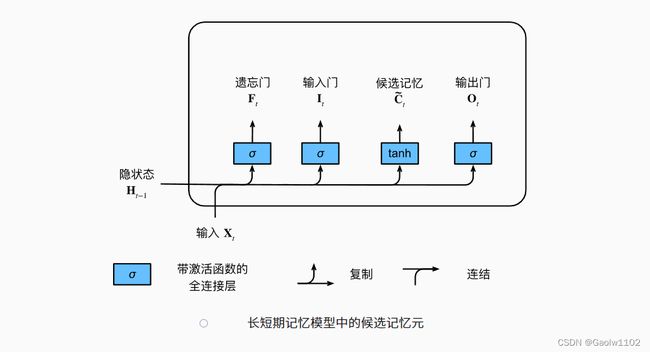
由于还没有指定各种门的操作,所以先介绍候选记忆元(candidate memory cell)$\tilde{\mathbf{C}}_t 。它的计算与上面描述的三个门的计算类似,但是使用 。它的计算与上面描述的三个门的计算类似,但是使用 。它的计算与上面描述的三个门的计算类似,但是使用\tanh 函数作为激活函数,函数的值范围为 函数作为激活函数,函数的值范围为 函数作为激活函数,函数的值范围为(-1, 1) 。下面导出在时间步 。下面导出在时间步 。下面导出在时间步t$处的方程:
候选记忆元 C ~ t = tanh ( X i W x c + H i − 1 W h c + b c ) 候选记忆元 \quad \tilde{C}_{t} = \tanh(X_{i}W_{xc} + H_{i-1}W_{hc} + b_{c}) 候选记忆元C~t=tanh(XiWxc+Hi−1Whc+bc)
候选记忆元的图示如下:
记忆元
在门控循环单元 GRU 中,有一种机制来控制输入和遗忘(或跳过)。类似地,在长短期记忆网络中,也有两个门用于这样的目的:输入门 I t \mathbf{I}_t It控制采用多少来自 C ~ t \tilde{\mathbf{C}}_t C~t的新数据,而遗忘门 F t \mathbf{F}_t Ft控制保留多少过去的记忆元 C t − 1 \mathbf{C}_{t-1} Ct−1的内容。 使用按元素乘法,得出:
C t = F t ⊙ C t − 1 + I t ⊙ C ~ t C_{t} = F_{t} \odot C_{t-1} + I_{t} \odot \tilde{C}_{t} Ct=Ft⊙Ct−1+It⊙C~t
如果遗忘门始终为 1 1 1且输入门始终为 0 0 0,则过去的记忆元 C t − 1 \mathbf{C}_{t-1} Ct−1将随时间被保存并传递到当前时间步。引入这种设计是为了缓解梯度消失问题,
并更好地捕获序列中的长距离依赖关系。
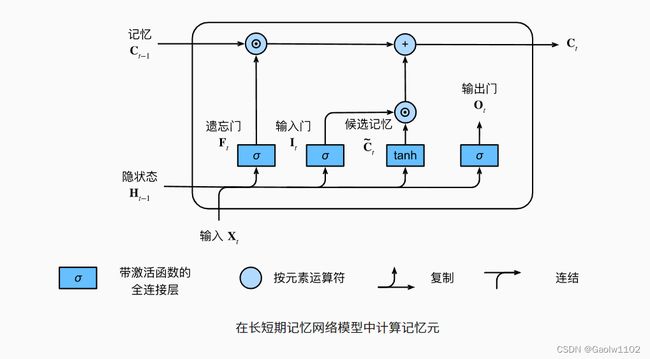
隐状态
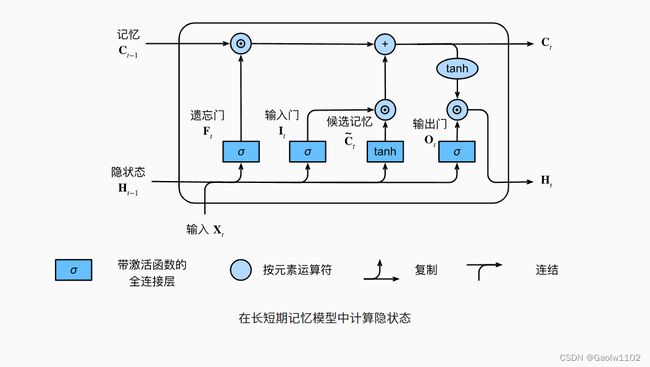
最后,我们定义如何计算隐状态 H t \mathbf{H}_t Ht,这就是输出门发挥作用的地方。在长短期记忆网络中,它仅仅是记忆元的 tanh \tanh tanh的门控版本。这就确保了 H t \mathbf{H}_t Ht的值始终在区间 ( − 1 , 1 ) (-1, 1) (−1,1)内:
H t = O t ⊙ t a n h ( C t ) H_{t} = O_{t} \odot tanh(C_{t}) Ht=Ot⊙tanh(Ct)
只要输出门接近 1 1 1,我们就能够有效地将所有记忆信息传递给预测部分,而对于输出门接近 0 0 0,我们只保留记忆元内的所有信息,而不需要更新隐状态。
其图示如下:
从零开始实现 LSTM
现在,我们从零开始实现长短期记忆网络。 与之前 RNN 模型的实验相同, 我们首先加载时光机器的数据集(目的是通过训练能够自动补全句子)。
import torch
from torch import nn
from d2l import torch as d2l
batch_size, num_steps = 32, 35 #批量大小32,序列步数35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
初始化模型参数
我们现在来定义和初始化模型参数。如之前一致,超参数num_hiddens定义隐藏单元的数量。 我们按照标准差 0.01 的高斯分布初始化权重,并将偏置项设为 0。
def get_lstm_params(vocab_size, num_hiddens, device):
#输入和输出一致
num_inputs = num_outputs = vocab_size
def normal(shape):
return torch.randn(shape, device=device)*0.01
def three():
return (normal((num_inputs, num_hiddens)),
normal((num_hiddens, num_hiddens)),
torch.zeros(num_hiddens, device=device))
#逻辑门参数
W_xi, W_hi, b_i = three() #输入门参数
W_xf, W_hf, b_f = three() #遗忘门参数
W_xo, W_ho, b_o = three() #输出门参数
W_xc, W_hc, b_c = three() #候选记忆元参数
#输出层参数
W_hq = normal((num_hiddens, num_outputs))
b_q = torch.zeros(num_outputs, device=device)
#列表存储参数信息
params = [W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc,
b_c, W_hq, b_q]
#增加梯度
for param in params:
param.requires_grad_(True)
return params
定义模型
在初始化函数中, 长短期记忆网络的隐状态需要返回一个额外的记忆元, 单元的值为0,形状为(批量大小,隐藏单元数)。 因此,我们得到以下的状态初始化。
def init_lstm_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device),
torch.zeros((batch_size, num_hiddens), device=device))
实际模型的定义与我们前面讨论的一样: 提供三个门和一个额外的记忆元。 请注意,只有隐状态才会传递到输出层, 而记忆元 C t C_t Ct不直接参与输出计算。
def lstm(inputs, state, params):
[W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c,
W_hq, b_q] = params
(H, C) = state
outputs = []
for X in inputs:
#逻辑门相关计算
I = torch.sigmoid((X @ W_xi) + (H @ W_hi) + b_i)
F = torch.sigmoid((X @ W_xf) + (H @ W_hf) + b_f)
O = torch.sigmoid((X @ W_xo) + (H @ W_ho) + b_o)
#候选记忆元计算
C_tilda = torch.tanh((X @ W_xc) + (H @ W_hc) + b_c)
#记忆元计算
C = F * C + I * C_tilda
#隐状态计算
H = O * torch.tanh(C)
#输出结果计算
Y = (H @ W_hq) + b_q
outputs.append(Y)
return torch.cat(outputs, dim=0), (H, C)
训练和预测
让我们通过实例化之前引入的RNNModelScratch类详情查看这里(RNN从零开始实现)来训练一个长短期记忆网络, 就如我们在之前所做的一样。
vocab_size, num_hiddens, device = len(vocab), 256, d2l.try_gpu()
num_epochs, lr = 500, 1
model = d2l.RNNModelScratch(len(vocab), num_hiddens, device, get_lstm_params,
init_lstm_state, lstm)
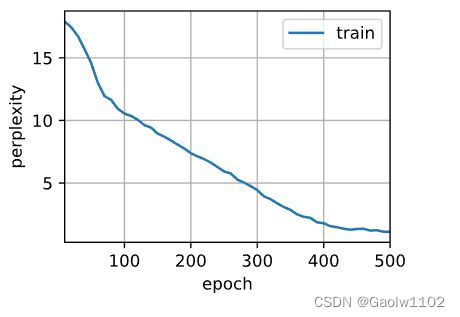
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
perplexity 1.1, 8249.8 tokens/sec on cpu
time traveller for so it will be convenient to speak one wroch a
travelleryou can show black is white by argument said filby
简洁实现
使用高级API,我们可以直接实例化LSTM模型。 高级API封装了前文介绍的所有配置细节。 这段代码的运行速度要快得多, 因为它使用的是编译好的运算符而不是Python来处理之前阐述的许多细节。
num_inputs = vocab_size
lstm_layer = nn.LSTM(num_inputs, num_hiddens) #定义LSTM层
model = d2l.RNNModel(lstm_layer, len(vocab)) #定义RNN模型
model = model.to(device)
#训练模型
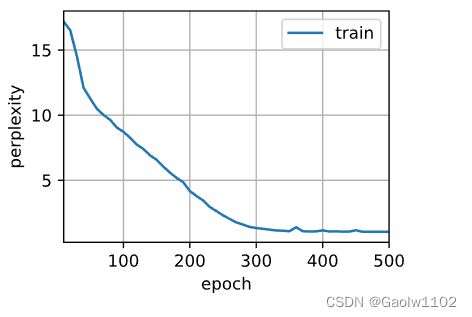
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
perplexity 1.0, 7963.8 tokens/sec on cpu
time traveller for so it will be convenient to speak of himwas e
travelleryou can show black is white by argument said filby
小结
1、长短期记忆网络有三种类型的门:输入门、遗忘门和输出门。
2、长短期记忆网络的隐藏层输出包括“隐状态”和“记忆元”。只有隐状态会传递到输出层,而记忆元完全属于内部信息。
3、长短期记忆网络可以缓解梯度消失和梯度爆炸。